
Указатель для браузера что сайт имеет несколько ip адресов
Под любым именем сайта всегда скрывается конкретный цифровой идентификатор в виде номера IP. Даже если сайт не имеет доменного имени, то его всегда можно открыть, набрав в браузере его «Айпи». Нередко бывает, что большие сайты устанавливают на одно имя несколько разных адресов IP. В случае необходимости определения адреса «Айпи» какого-либо интернет ресурса — это можно быстро сделать с применением встроенных инструментов Windows либо через некоторые браузеры, обладающие требуемым функционалом. О том, как узнать ip адрес сайта, вышеперечисленными способами изложено в этой статье в виде удобных пошаговых инструкций.
Способ 1. Определение IP через командную строку
Это самый быстрый и удобный метод для определения адреса «Айпи» любого интернет-ресурса.
Необходимо выполнить следующие последовательные шаги:
- Удерживая кнопку «Windows» надо нажать на «R»;
- Далее в отобразившемся окошке напечатать «CMD»;
- Затем щелкнуть «Ok»;
- После этого в новом отобразившемся окошке напечатать «PING», потом нажать клавишу «Пробел» и напечатать наименование сайта, как показано на рисунке ниже;
- Далее кликнуть «Ввод»;
- Готово! Отобразится «Айпи» сайта, который было необходимо узнать.
Примечание: в случае ввода вместо «PING» — «TRACERT», пользователю будет доступна информация не только об «Айпи» домена, но и весь путь от ПК до сервера.
Способ 2. С использованием браузера «Mozzilla Firefox»
Алгоритм последовательных действий состоит из следующих этапов:
- Открыть браузер и войти в меню «Инструменты»;
- Далее кликнуть на строчку «Дополнения»;
- Затем перейти во вкладку «Получить дополнения»;
- В поле поиска напечатать «show ip»;
- Щелкнуть «Ввод»;
- Далее нажать «Установить»;
- Дождаться завершения инсталляции и перезагрузить браузер, т. е. закрыть его и потом сразу вновь открыть;
- Теперь после входа на страницу какого-либо сайта, в нашем примере на рисунке «Google», в нижней части окна будет отображаться его «Айпи».

Примечание: если кликнуть на надпись «ip», то появятся более подробные сведения.
Способ 3. С использованием браузера «Google Chrome»
Требуется произвести следующие действия:

Способ 4. Определение IP через специальные онлайн-сервисы
Для выполнения поставленной задачи надо осуществить лишь несколько следующих шагов:

Заключение
Обычно вопросом «Как узнать ip адрес сайта» задаются администраторы, но имея подробные и несложные инструкции, доступом к этой информации об IP сайте (домене) могут владеть и простые пользователи. В статье изложены наиболее доступные четыре метода для решения рассматриваемой проблемы.
![]()
Меня всегда напрягало то, как навязчиво Google AdSense подсовывал контекстную рекламу в зависимости от моих старых запросов в поисковике. Вроде бы и времени с момента поиска прошло достаточно много, да и куки и кеш браузера чистились не раз, а реклама оставалась. Как же они продолжали отслеживать меня? Оказывается, способов для этого предостаточно.
Небольшое предисловие
Идентификация, отслеживание пользователя или попросту веб-трекинг подразумевает под собой расчет и установку уникального идентификатора для каждого браузера, посещающего определенный сайт. Вообще, изначально это не задумывалось каким-то вселенским злом и, как и все, имеет обратную сторону, то есть призвано приносить пользу. Например, позволить владельцам сайта отличить обычных пользователей от ботов или же предоставить возможность хранить предпочтения пользователей и применять их при последующем визите. Но в то же самое время данная возможность очень пришлась по душе рекламной индустрии. Как ты прекрасно знаешь, куки — один из самых популярных способов идентификации пользователей. И активно применяться в рекламной индустрии они начали аж с середины девяностых годов.
Явные идентификаторы
Данный подход довольно очевиден, все, что требуется, — сохранить на стороне пользователя какой-то долгоживущий идентификатор, который можно запрашивать при последующем посещении ресурса. Современные браузеры предоставляют достаточно способов выполнить это прозрачно для пользователя. Прежде всего это старые добрые куки. Затем особенности некоторых плагинов, близкие по функционалу к кукам, например Local Shared Objects во флеше или Isolated Storage в силверлайте. HTML5 также включает в себя несколько механизмов хранения на стороне клиента, в том числе localStorage , File и IndexedDB API . Кроме этих мест, уникальные маркеры можно также хранить в кешированных ресурсах локальной машины или метаданных кеша ( Last-Modified , ETag ). Помимо этого, можно идентифицировать пользователя по отпечаткам, полученным из Origin Bound сертификатов, сгенерированных браузером для SSL-соединений, по данным, содержащимся в SDCH-словарях, и метаданным этих словарей. Одним словом — возможностей полно.
Cookies
Local Shared Objects

Удаление данных из localStorage в Firefox
Изолированное хранилище Silverlight
Программная платформа Silverlight имеет довольно много общего с Adobe Flash. Так, аналогом флешевого Local Shared Objects служит механизм под названием Isolated Storage . Правда, в отличие от флеша настройки приватности тут никак не завязаны с браузером, поэтому даже в случае полной очистки куков и кеша браузера данные, сохраненные в Isolated Storage , все равно останутся. Но еще интересней, что хранилище оказывается общим для всех окон браузера (кроме открытых в режиме «Инкогнито») и всех профилей, установленных на одной машине. Как и в LSO, с технической точки зрения здесь нет каких-либо препятствий для хранения идентификаторов сессии. Тем не менее, учитывая, что достучаться до этого механизма через настройки браузера пока нельзя, он не получил такого широкого распространения в качестве хранилища для уникальных идентификаторов.

Где искать изолированное хранилище Silverlight
HTML5 и хранение данных на клиенте

Настройка локального хранилища для Flash Player
Кешированные объекты
ETag и Last-Modified

Сервер возвращает клиенту ETag
HTML5 AppCache
Application Cache позволяет задавать, какая часть сайта должна быть сохранена на диске и быть доступна, даже если пользователь находится офлайн. Управляется все с помощью манифестов, которые задают правила для хранения и извлечения элементов кеша. Подобно традиционному механизму кеширования, AppCache тоже позволяет хранить уникальные, зависящие от пользователя данные — как внутри самого манифеста, так и внутри ресурсов, которые сохраняются на неопределенный срок (в отличие от обычного кеша, ресурсы из которого удаляются по истечении какого-то времени). AppCache занимает промежуточное значение между механизмами хранения данных в HTML5 и обычным кешем браузера. В некоторых браузерах он очищается при удалении куков и данных сайта, в других только при удалении истории просмотра и всех кешированных документов.
SDCH-словари
SDCH — это разработанный Google алгоритм компрессии, который основывается на использовании предоставляемых сервером словарей и позволяет достичь более высокого уровня сжатия, чем Gzip или deflate. Дело в том, что в обычной жизни веб-сервер отдает слишком много повторяющейся информации — хидеры/футеры страниц, встроенный JavaScript/CSS и так далее. В данном подходе клиент получает с сервера файл словаря, содержащий строки, которые могут появиться в последующих ответах (те же хидеры/футеры/JS/CSS). После чего сервер может просто ссылаться на эти элементы внутри словаря, а клиент будет самостоятельно на их основе собирать страницу. Как ты понимаешь, эти словари можно с легкостью использовать и для хранения уникальных идентификаторов, которые можно поместить как в ID словарей, возвращаемые клиентом серверу в заголовке Avail-Dictionary , так и непосредственно в сам контент. И потом использовать подобно как и в случае с обычным кешем браузера.
Прочие механизмы хранения
Протоколы
Помимо механизмов, связанных с кешированием, использованием JS и разных плагинов, в современных браузерах есть еще несколько сетевых фич, позволяющих хранить и извлекать уникальные идентификаторы.
Характеристики машины
Все рассмотренные до этого способы основывались на том, что пользователю устанавливался какой-то уникальный идентификатор, который отправлялся серверу при последующих запросах. Есть другой, менее очевидный подход к отслеживанию пользователей, полагающийся на запрос или измерение характеристик клиентской машины. Поодиночке каждая полученная характеристика представляет собой лишь несколько бит информации, но если объединить несколько, то они смогут уникально идентифицировать любой компьютер в интернете. Помимо того что такую слежку гораздо сложнее распознать и предотвратить, эта техника позволит идентифицировать пользователя, сидящего под разными браузерами или использующего приватный режим.
«Отпечатки» браузера
Наиболее простой подход к трекингу — это построение идентификаторов путем объединения набора параметров, доступных в среде браузера, каждый из которых по отдельности не представляет никакого интереса, но совместно они образуют уникальное для каждой машины значение:
Сетевые «отпечатки»
Еще ряд признаков кроется в архитектуре локальной сети и настройке сетевых протоколов. Такие знаки будут характерны для всех браузеров, установленных на клиентской машине, и их нельзя просто скрыть с помощью настроек приватности или каких-то security-утилит. Они включают в себя:
Поведенческий анализ и привычки
Еще один вариант — взглянуть в сторону характеристик, которые привязаны не к ПК, а скорее к конечному пользователю, такие как региональные настройки и поведение. Такой способ опять же позволит идентифицировать клиентов между различными сессиями браузера, профилями и в случае приватного просмотра. Делать выводы можно на основании следующих данных, которые всегда доступны для изучения:
И это лишь очевидные варианты, которые лежат на поверхности. Если копнуть глубже — можно придумать еще.
Подытожим
Как видишь, на практике существует большое число различных способов для трекинга пользователя. Какие-то из них являются плодом ошибок в реализации или упущений и теоретически могут быть исправлены. Другие практически невозможно искоренить без полного изменения принципов работы компьютерных сетей, веб-приложений, браузеров. Каким-то техникам можно противодействовать — чистить кеш, куки и прочие места, где могут храниться уникальные идентификаторы. Другие работают абсолютно незаметно для пользователя, и защититься от них вряд ли получится. Поэтому самое главное — путешествуя по Сети даже в приватном режиме просмотра, помнить, что твои перемещения все равно могут отследить.
Вопрос № 2
На месте преступления были обнаружены четыре обрывка бумаги. Следствие установило, что на них записаны фрагменты одного IP-адреса. Криминалисты обозначили эти фрагменты цифрами 1, 2, 3 и 4.
Восстановите IP-адрес.
1) 2341;
2) 3214;
3) 2413;
4) 4231.
Вопрос № 4
Компьютер, подключенный к Интернету, обязательно имеет:
1) доменное имя;
2) домашнюю Web-страницу;
3) IP-адрес;
4) сервер.
Вопрос № 5
Совокупность технических устройств, обеспечивающих передачу сигнала от источника к получателю, – это:
1) канал передачи данных (канал связи);
2) источник информации;
3) носитель информации;
4) приёмник информации.
Вопрос № 6
Указатель, содержащий название протокола, доменное имя сайта и адрес документа – это:
1) IP-адрес;
2) URL;
3) WWW;
4) протокол.
Вопрос № 7
Адрес компьютера, записанный четырьмя десятичными числами, разделенными точками, – это:
1) WWW;
2) URL;
3) IP-адрес;
4) протокол.
Вопрос № 8
Максимальная скорость передачи данных по модемному протоколу V.92 составляет 56000 бит/c. Какое максимальное количество байт можно передать за 15 секунд по этому протоколу?
1) 105;
2) 84000;
3) 105000;
4) 840000.
Вопрос № 9
Компьютер, предоставляющий свои ресурсы в пользование другим компьютерам при совместной работе, называется:
1) модемом;
2) сетевой картой;
3) сервером;
4) коммутатором.
Вопрос № 11
Программа, с помощью которой осуществляется просмотр Web-страниц, – это:
1) URL;
2) браузер;
3) ICQ;
4) модем.
Вопрос № 12
Количество информации, передаваемое за единицу времени, – это:
1) бит в секунду (бит/с);
2) скорость передачи информации;
3) передача информации;
4) источник информации.
Вопрос № 13
Запросы к поисковому серверу закодированы буквами А, Б, В, Г. Расположите обозначения запросов в порядке возрастания количества страниц, которые найдет поисковый сервер по каждому запросу.
А) Пушкин | Лермонтов | поэзия
Б) Пушкин | Лермонтов | поэзия | проза
В) Пушкин | Лермонтов
Г) Пушкин & Лермонтов & проза
1) АБВГ
2) АВГБ
3) ГВАБ
4) БАВГ
Вопрос № 15
Услуга, предназначенная для прямого общения в Интернет в режиме реального времени, это:
1) электронная почта;
2) почтовый клиент;
3) ICQ;
4) URL.
Вопрос № 16
Набор правил, позволяющий осуществлять соединение и обмен данными между включёнными в сеть компьютерами, – это:
1) WWW;
2) протокол;
3) URL;
4) IP-адрес;
Вопрос № 17
IP-адресу 64.129.255.32 соответствует 32-битное представление:
1) 01111111 11000000 01111111 11000000
2) 10000000 01000000 11111111 10100000
3) 01000000 10000001 11111111 00100000
4) 10000000 01000000 11111111 10010000
Вопрос № 18
Cервис для хранения, поиска и извлечения разнообразной взаимосвязанной информации, включающей в себя текстовые, графические, видео-, аудио- и другие информационные ресурсы, – это:
1) WWW;
2) протокол;
3) URL;
4) IP-адрес
Вопрос № 19
HTML-страница, с которой начинается работа браузера при его включении – это:
1) доменное имя;
2) домашняя страница;
3) URL;
4) IP-адрес.
Вопрос № 20
Скорость передачи данных через ADSL-соединение равна 128000 бит/с. Сколько времени (в минутах) займет передача файла объемом 5 Мбайт по этому каналу?
1) 41;
2) 40;
3) 5,5;
4) 328.

Узнать IP адрес любого интернет сайта можно очень просто.
Первый способ – это воспользоваться командной строкой Windows, введя в нее знакомую многим команду ping.
Второй вариант – использование специализированных сайтов, предоставляющих такую информацию. Думаю, этих двух способов будет вполне достаточно. А теперь обо всем этом поподробнее.
Итак, как узнать IP-адрес сайта с помощью командной строки?
Заходим на своем компьютере в “Пуск” – “Выполнить” (или можно нажать на клавиатуре одновременно клавиши Win+R). Набираем команду cmd и жмем “ОК”:В открывшемся черном окне пишем команду ping и через пробел название интересующего нас сайта:После этого нажимаем клавишу Enter на клавиатуре. Через мгновение мы увидим IP-адрес этого сайта:

Второй способ узнать IP-адрес сайта – зайти на один из специальных онлайн-сервисов. Таких ресурсов очень много. Я приведу в пример лишь три из них – можете воспользоваться любым:
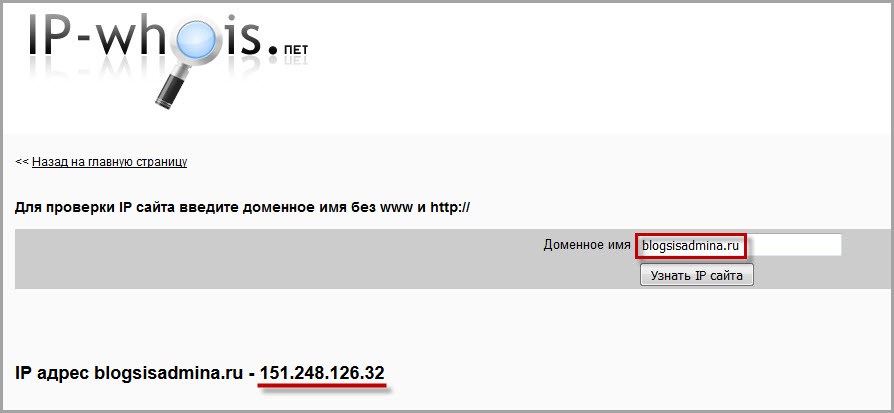
На данных сервисах необходимо лишь ввести название интересующего вас сайта в специальную строку. После этого мы увидим его IP-адрес. Он будет таким же, который нам выдала команда ping на нашем копьютере:
Случается и обратное: один IP-адрес могут делить между собой сразу несколько сайтов, расположенных на одном сервере. Для виртуальных хостингов это обычная ситуация. Вы наверное слышали, что Роскомнадзор сейчас стал блокировать различные сайты, содержащие информацию, запрещенную в нашей стране? Так вот, если на одном IP-адресе вместе с этим запрещенным сайтом располагается еще какой-нибудь сайт, то он может совершенно незаслуженно пострадать и также будет заблокирован. С этой проблемой должен будет разбираться уже сам владелец сайта. Но если вы хотите во что бы то ни стало попасть на этот заблокированный сайт, я расскажу, как это можно сделать. Правда уже в отдельной статье.
Читайте также: