
Как распознать текст в pdf adobe acrobat
Adobe Acrobat Export PDF — это онлайн-сервис Acrobat. С его помощью можно легко конвертировать файлы PDF в редактируемые документы Word, Excel и RTF (расширенный текстовый формат).
Сервис Adobe Acrobat Export PDF не позволяет редактировать файлы PDF. Для редактирования файлов PDF используйте Acrobat DC. Перейдите на страницу продукта Acrobat.
Adobe Acrobat Export PDF поддерживает оптическое распознавание символов (OCR) при конвертации файла PDF в форматы Word (.doc и .docx), Excel (.xlsx) и RTF (расширенный текстовый формат). OCR — это преобразование изображений текста (отсканированный текст) в редактируемые текстовые данные, поддерживающие возможности поиска, исправления и копирования.
При включенной функции OCR Adobe Acrobat Export PDF выполняет оптическое распознавание символов в файлах PDF, содержащих изображения, векторную графику, скрытый текст или любое сочетание этих элементов. Оптическое распознавание символов выполняется для файлов PDF, созданных из отсканированных документов. Кроме того, Adobe Acrobat Export PDF выполняет оптическое распознавание символов в тексте, который не удается интерпретировать из-за неправильной кодировки, заданной в исходном приложении.
Adobe Acrobat Export PDF поддерживает OCR для текста на следующих языках.

По умолчанию функция OCR работает с языком, выбранным в диалоговом окне «Моя информация». Модуль OCR использует выбранный язык для обработки отсканированного текста. Выбор правильного языка повышает точность преобразования, так как модуль OCR использует словари для этого языка. Если кодировка языка отлична от латиницы (например, японский), то неверный выбор языковых параметров приведет к невозможности распознавания и преобразования текста с помощью модуля OCR.
Для включения функции OCR при преобразовании файла PDF в Adobe Acrobat Export PDF выполните следующие действия.
Выполните вход в веб-интерфейс Adobe Acrobat Export PDF и нажмите Выбрать файлы PDF для экспорта.
Нажмите Выбрать файлы на моем компьютере и найдите нужный файл PDF. Кроме того, можно перетащить файл на панель. Чтобы выбрать файл из Document Cloud, нажмите Document Cloud в области слева и выберите файл.
ПРИМЕЧАНИЕ. Можно выбрать несколько файлов для экспорта.

В раскрывающемся списке Экспорт в выберите формат, в который требуется экспортировать файл PDF.
В раскрывающемся списке Язык документа выберите язык для распознавания текста документа.
Выбранный файл PDF загрузится на сервер, и содержимое экспортируется в указанный формат. Нажмите на значок Загрузить, чтобы сохранить файл на компьютере или устройстве.

Можно также использовать бесплатное приложение Acrobat Reader для ПК, чтобы экспортировать файлы в PDF. Приложение использует онлайн-сервис Acrobat Export PDF в фоновом режиме.
Откройте файл PDF, который необходимо преобразовать в Acrobat Reader, и нажмите Adobe Acrobat Export PDF на панели справа.
Проверьте язык документа для распознавания над кнопкой Преобразовать - Язык документа: <выбранный язык>. Если язык выбран правильно, перейдите к следующему шагу.
В противном случае измените выбранный язык.
1. Нажмите ссылку Изменить.

2. В диалоговом окне Параметры модуля OCR выберите нужный язык в списке Распознавать текст в и нажмите ОК.
Нажмите Преобразовать, чтобы начать преобразование.
Как Adobe Reader, так и Adobe Acrobat поддерживают оптическое распознавание символов в файлах PDF. OCR может распознавать и преобразовывать такие символы, как английские буквы или китайские символы на изображениях машинописного текста, в машинный код, которым вы можете манипулировать. Adobe Reader позволяет подписанным пользователям использовать OCR для преобразования документов. Adobe Acrobat позволяет использовать распознавание текста с процедурой оптимизации.

Используйте OCR для чтения текста в изображении. Кредит: Предоставлено Adobe
Включить распознавание текста в Adobe Reader

Нажмите Tools.credit: Предоставлено Adobe
Откройте файл PDF и нажмите инструменты из строки меню.

Нажмите + Изменить под Экспорт PDF раздел для распознавания текста в документе.

Выберите язык. Кредит: Предоставлено Adobe
Выберите язык для текста в документе под Распознать текст в и нажмите ХОРОШО. Например, выберите Английский (США) если текст в файле PDF на английском языке. Вы также можете отключить функцию OCR в этом окне, переключая Отключить распознавание текста кнопка.

Войдите в свою учетную запись Adobe и преобразуйте файл PDF в другие типы документов. Кредит: Предоставлено Adobe.
Войдите в свою учетную запись Adobe, чтобы преобразовать файл PDF в документы других типов, например Microsoft Word. Нажмите Перерабатывать экспортировать файл. Откройте файл в Word и отредактируйте его как хотите.
Включить распознавание текста в Adobe Acobat

Нажмите Tools.credit: Предоставлено Adobe
Откройте файл PDF в Adobe Acrobat и нажмите инструменты в строке меню.

Нажмите Оптимизировать сканированный PDF под Обработка документов настроить параметры оптимизации для PDF.

Как изменить цвет инструмента выделения текста в Adobe Acrobat

Панель ввода планшета Windows 7: ввод текста и распознавание рукописного ввода

Панель ввода планшета преобразует практически любой почерк в печатный текст, который могут использовать ваши приложения. В этом уроке мы научимся быстро и точно вводить текст.
Как настроить windows hello распознавание лиц для входа в windows 10

Windows Hello - это быстрый, безопасный и футуристический способ входа в Windows с использованием вашего лица, глаз или отпечатков пальцев.


Сочетание клавиш для запуска диалога правописания - F7.credit: Изображение предоставлено Adobe
Откройте PDF в полной версии Adobe Acrobat или Acrobat Reader, выберите редактировать меню, а затем Проверять орфографию, Единственный выбор для проверки правописания В комментариях и полях.

Adobe Acrobatcredit: Изображение предоставлено Adobe
Нажмите Начните в диалоге проверки орфографии.


Как использовать проверку орфографии в Microsoft Word

Узнайте, как запустить инструмент проверки орфографии и грамматики в Word и как проверить орфографию и грамматику для отдельных слов или фраз.
Как обозначить исправления орфографии звездочками

Как использовать проверку орфографии на Mac

Пошаговое руководство по использованию встроенной функции проверки орфографии в Mac OSX для Notes, Pages и других приложений.

Рассмотрев ранее, как можно создавать PDF-документ, разными способами: и онлайн, и оффлайн и даже средствами Microsoft Office, пришло время рассказать, как произвести обратное действие.
Рассмотрим, как вытащить из PDF-документа текст, так чтобы можно было потом его редактировать в Word и подобных ему текстовых редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
Adobe Reader и аналоги
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
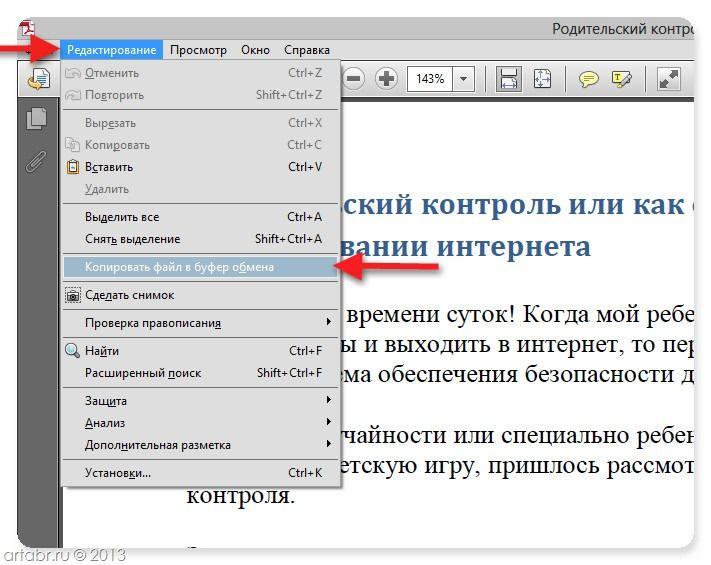
А дальше, стандартные действия: открываем Word, создаем новый документ и нажимаем кнопку Вставить или воспользуемся быстрыми клавишами (Ctrl+V).
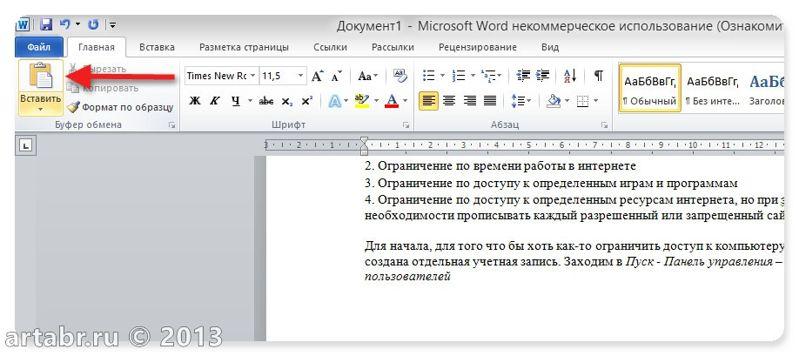
Все, можно спокойно редактировать полученный текст.
Обратите внимание, при использовании данного метода не сохраняется форматирование текста и нет возможности вытащить изображения.Если вам, все таки, во что бы то ни стало нужно извлечь изображение из PDF-документа, чтобы не использовать какие-нибудь программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого вы скопировали текст, но не получилось скопировать картинку.
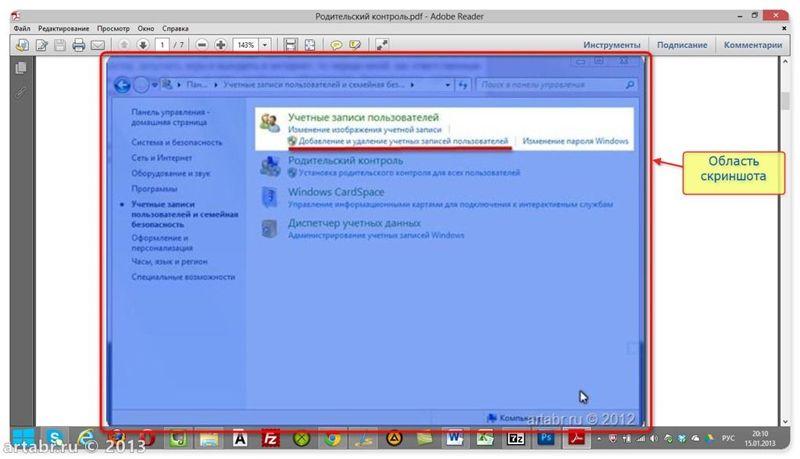
И полученное изображение вставьте в Word. Должно получиться вот так:
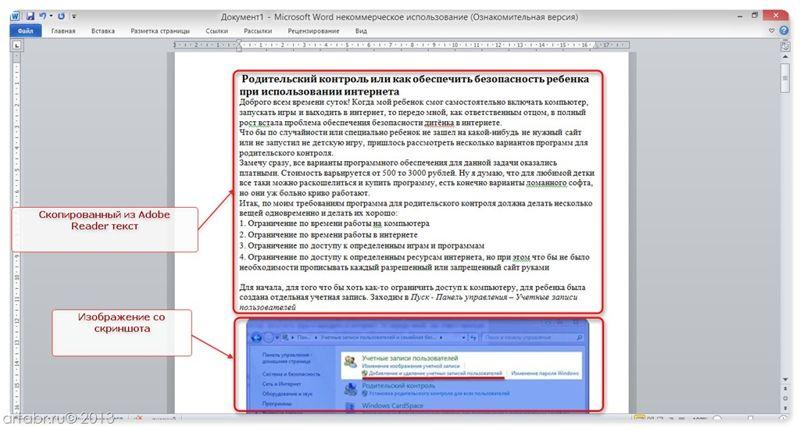
Понятно, что качество изображения будет оставлять желать лучшего, но как запасной вариант вполне подойдет.
В других просмотрщиках нужно будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда Выделить текст):
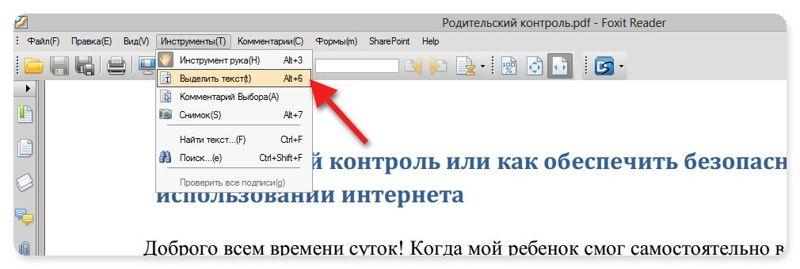
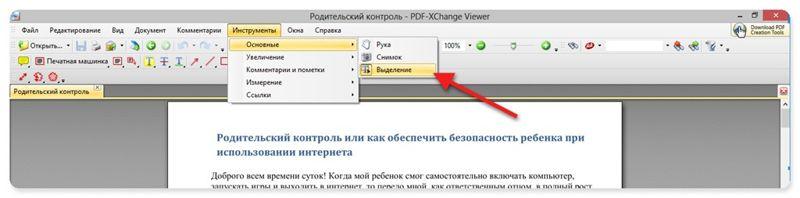
А вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
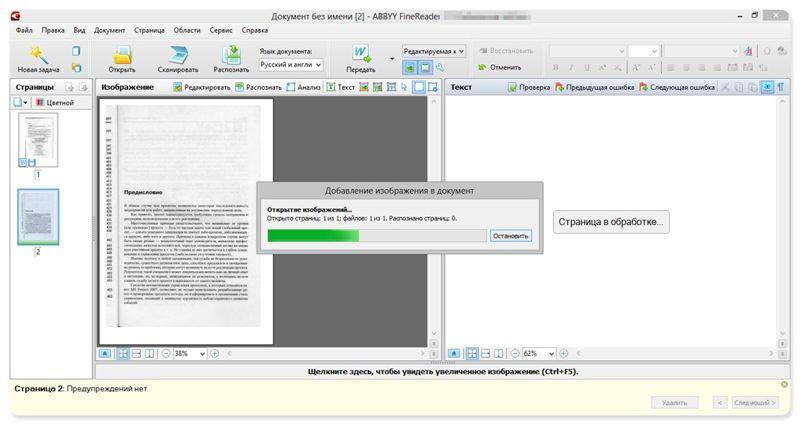
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
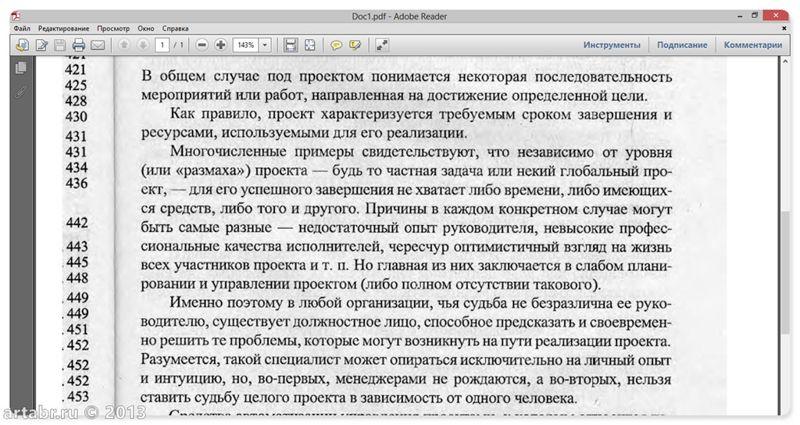
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
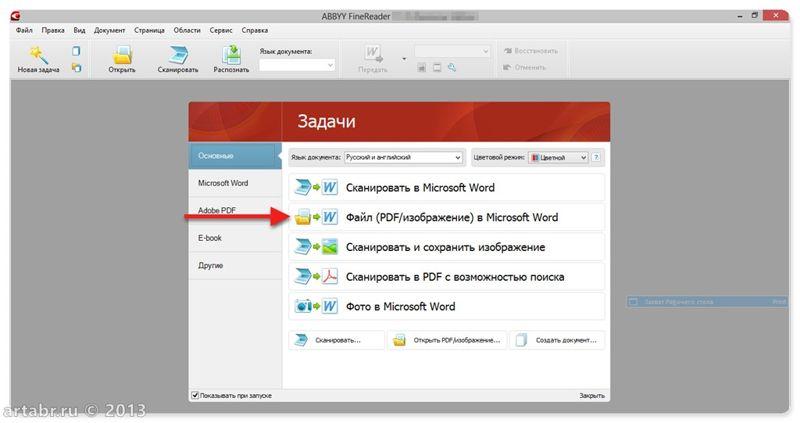
И все! Система сама распознает текст и отправляет его в Word

Онлайн-сервисы для конвертирования PDF-файлов
Вариант с онлайн-сервисами я уже описывал, единственно, что могу добавить еще пару подобных сервисов:
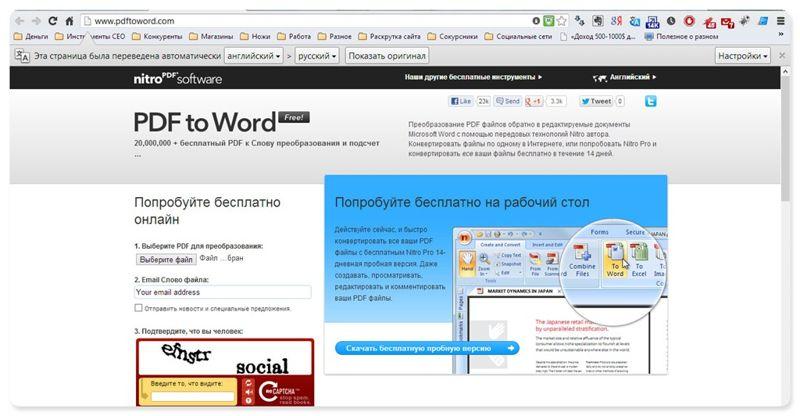
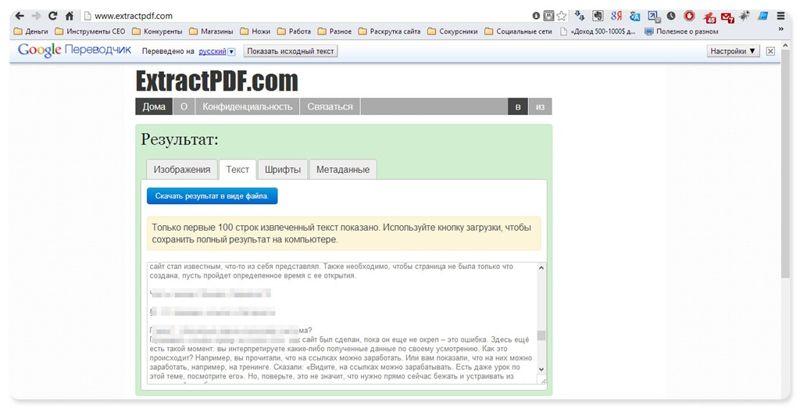
И опять же, ни один из онлайн-сервисов не работает с изображениями, и если текст у вас отсканирован и сохранен в формате PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но остальные имеют право на существование, потому что не каждый день требуется преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ преобразования PDF-файлов, напишите мне в комментариях.
Спасибо за внимание!
P.S. Лирическое отступление:
( 7 оценок, среднее 4.71 из 5 )В прошлом занимался руководством организации по монтажу сложного технологического оборудования и трубопроводов.
Сегодня разработчик WordPress и WooCommerce. Пишу плагины, разрабатываю сайты, собираю ножи.
Являюсь автором и ведущим проекта Финты WordPress.
Приветствую, друзья! Мне намедни сделали предложение написать обзор программы для конвертирования PDF-файлов в редактируемый формат. Естественно, Приветствую всех! Возвращаясь к теме создания PDF-документов, хочу открыть небольшие секреты создания документов с навигацией. Привет, всем! Частенько сталкиваясь по работе с распечаткой PDF-файлов на разных устройствах, от принтеров И снова, здрасте! Это опять я, и мы снова говорим про формат PDF. А Доброго времени суток! Как и обещал, рассказываю о еще одном способе создания PDF-документов. Правда Приветствую всех! Продолжая тему создания документов в формате PDF, в этой статье поговорим о
Вот такое искажение текста идет, если через буфер обмена
oaenoiaie .aaaeoi.; yeaeo.iiiay oaaeeoa; nenoaia oi.aaeaiey
aacaie aaiiuo; i.ia.aiia aiaeeca e ninoaaeaiey .anienaiee;
i.ia.aiia i.acaioaoee; a.aoe.aneee .aaaeoi.; i.ia.aiia ia-
neo.eaaiey oaen-iiaaia; naoaaia i.ia.aiiiia iaania.aiea:
yeaeo.iiiay ii.oa, eiiiu.oa.iua e oaeaeiioa.aioee e a..;
i.ia.aiiu ia.aaiaa; niaoeaeece.iaaiiua i.ia.aiiu oi.aa-
eai.aneie aayoaeuiinoe: aaaaiey aieoiaioia, eiio.iey ca en-
iieiaieai i.eeacia e a..
2 4 Eioaa.e.iaaiiue iaeao
Приветствую! В вашем случае есть масса вариантов. Это может быть и версия ридеров и офиса не подходит, и кодировка кривая или вообще файл защищен от копирования. Сложно что-то сказать-сделать когда файла перед глазами нет. Свяжитесь со мной по почте. Постараюсь помочь.
Скажите пожалуйста, я правильно понял если в документе установлен запрет на копирование, то я ничего сделать не смогу кроме как распознавать платной программой?
Да, правильно. Можно попробовать сломать, но проще распознать. Fine Reader имеет 30 дневный доступ бесплатный, думаю этого должно хватить чтобы распознать несколько файлов
добрый день, подскажите пожалуйста как Вы сделали такой вид статей? Или это так и было уже в готовом виде шаблона?
Добрый день! В принципе все было в шаблоне, я только немного допили. Хотел уточнить: а какой такой вид?
Пробуйте изменить шрифт, скорее всего в документе используется шрифт, который не поддерживает кириллицу.
Читайте также: