
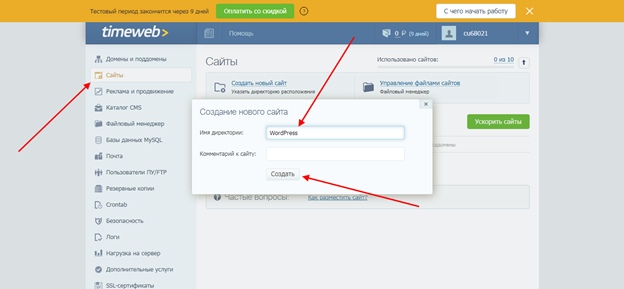
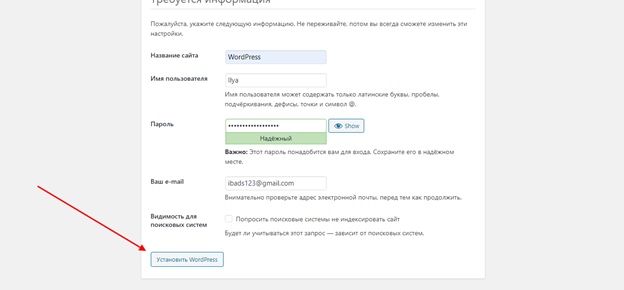
Как узнать url адрес приложения
Данная статья описывает Единый локатор ресурсов или Uniform Resource Locators (URLs), объясняет, что это такое, и описывает его структуру.
| Предварительно: | Вам нужно узнать как работает интернет, что такое Веб сервер (en-US) and что лежит в основе веб ссылок . |
|---|---|
| Цель: | Вы узнаете, что такое URL и как они работают в вебе. |
Введение
URL обозначает Uniform Resource Locator. URL это лишь адрес, который выдан уникальному ресурсу в интернете. В теории, каждый корректный URL ведёт на уникальный ресурс. Такими ресурсами могут быть HTML-страница, CSS-файл, изображение и т.д. На практике, существуют некоторые исключения, когда, например, URL ведёт на ресурс, который больше не существует или который был перемещён. Поскольку ресурс, доступный по URL, а также сам URL обрабатываются веб-сервером, его владелец должен внимательно следить за размещаемыми ресурсами и связанными с ними URL.
Активное обучение
Подробная информация
Основы: анатомия URL
Вот несколько примеров URL:
Каждый из этих URLs могут быть напечатаны в адресной строке браузера, чтобы заставить его загрузить связанную страницу (ресурс).
URL состоит из различных частей, некоторые из которых являются обязательными, а некоторые - факультативными. Рассмотрим наиболее важные части на примере:
Вам стоит представлять URL как обычный почтовый адрес: протокол обозначает почтовый транспорт, который вы собираетесь использовать,доменное имя - это город, порт - это почтовый индекс; адрес - это номер дома;параметры представляют собой дополнительную информацию, как, например, номер квартиры; и, наконец, якорь представляет собой конкретного получателя, которому вы адресуете своё письмо.
Как использовать URL
Каждый URL может быть напечатан напрямую в адресной строке браузера, чтобы сразу получить запрошенный ресурс. Но это только вершина айсберга!
Язык HTML — который будет обсуждать позже (en-US) — позволяет активно использовать URL для:
- создания ссылок на другие документы с помощью тега <a> ;
- связывания документа с его дополнительными файлами, например с помощью тегов <link> или <script> ;
- отображения медиа-элементов, например изображений (с помощью тега <img> ), видео (с помощью тега <video> ), звуков и музыки (с помощью тега <audio> ) и так далее;
- отображения других HTML-документов внутри текущего с помощью тега <iframe> (en-US).
Другие технологии, такие как CSS или JavaScript, также активно используют URL, так что это реально основа веба.
Абсолютные и относительные URL
Все, что мы изучали выше - это абсолютные URL. Но так же существуют и относительные URL. Изучим их.
Когда URL используется в документе, например в HTML-странице, ситуация отличается. Потому что браузер уже знает URL текущего документа и он может использовать эти сведения для дополнения недостающих частей любого адреса, указанного в документе. Простейший пример относительного URL - указание только адресной части URL. А если адрес в URL начинается с символа "/ ", браузер запросит ресурс от корня сервера, без отсылки к контексту текущего документа.
Разберём это на примерах.
Примеры абсолютных URL
Полный URL (такой же, как обсуждали в начале статьи) Скрыт протоколВ этом случае браузер использует тот же протокол, что использовался для загрузки текущего документа.
Это наиболее частый пример использования абсолютного URL в HTML-документе. Браузер использует тот же протокол и то же доменное имя, как у текущего документа. Примечание: не возможно скрыть домен, не скрывая при этом протокол, только вместе.
Примеры относительных URL
Семантические URL
Помимо своего технического значения, URL представляют собой человеко-читаемые записи о местоположении документов на веб-ресурсе. Они могут быть запомнены и любой может ввести их в адресную строку своего браузера. Веб создавался для людей и распространённой практикой является принцип записи URL, который называется семантические URL. Семантические URL используют в своём составе слова, значение которых может быть понято любым человеком, даже тем, кто не разбирается в технических нюансах.
Семантика, разумеется, плохо распознаётся компьютерами. Вы наверняка видели URL, которые выглядят как куча случайных символов. Но у семантических URL есть много преимуществ:
Я бы хотел найти базовый url моего приложения, поэтому я могу автоматически ссылаться на другие файлы в моем дереве приложений.
Так что заданный файл config.php в базе моего приложения, если файл в подкаталоге включает его, знает, что префикс url с.
Итак, при доступе к http://www.example.com/application/admin/something.php я хочу, чтобы он мог знать, что файл css находится в $approot/css/style.css . В этом случае $approot есть " /application ", но я хотел бы знать, установлено ли приложение в другом месте.
Я не уверен, если это возможно, многие приложения (phpMyAdmin, Squirrelmail, я думаю) должны установить конфигурационную переменную для начала. Это было бы более удобным для пользователя, если бы оно просто знало.
ОТВЕТЫ
Ответ 1
Я использую следующее в структуре homebrew. Поместите это в файл в корневую папку вашего приложения и просто включите его.
Приведенный выше код определяет две константы. ABSPATH содержит абсолютный путь к корню приложения (локальная файловая система), в то время как URLADDR содержит полный URL-адрес приложения. Он работает в ситуациях mod_rewrite.
Ответ 2
Вы можете найти базовый url с следующим кодом:
Короткий и лучший.
Ответ 3
REQUEST_URI в сочетании с dirname() может сообщить вам ваш текущий каталог, относящийся к URL-адресу:
So http://example.com/test/test.php печатает "/test" или http://example.com/ печатает "/", который вы можете использовать для генерации ссылок для ссылки на другие страницы относительно текущего пути.
EDIT: только что понятый при повторном чтении, что вы можете спрашивать о пути на диске, а не о пути URL. В этом случае вы хотите вместо PHP getcwd():
Ответ 4
Если вы не отследите это самостоятельно, я не верю, что это будет определение. Вернее, вы просите PHP отслеживать то, что вы произвольно определяете.
Долгое и короткое, если я правильно понимаю ваш вопрос, я не верю, что то, о чем вы просите, существует, по крайней мере, не как "основной" PHP; данная структура может предоставить "корневой" URL-адрес относительно структуры каталогов, которую он понимает.
Это имеет смысл?
Ответ 5
Поместите это в свой config.php(который находится в корневом каталоге вашего приложения):
Я думаю, что это сделаю.
Ответ 6
URL-адрес приложения можно найти по
этот код вернет URL-адрес любого приложения, будь он онлайн или на автономном сервере.
Я не сделал надлежащую проверку для правильного '/'. Пожалуйста, измените его для косой черты.
этот файл должен быть помещен в корневой каталог.
пример: если URL приложения:
то этот код вернет
Ответ 7
Одним из решений было бы использовать относительные пути для всего, так что не имеет значения, где установлено приложение. Например, чтобы перейти к вашей таблице стилей, используйте это:
Ответ 8
Если вам нужен путь к файловой системе, вы можете использовать $_SERVER['DOCUMENT_ROOT']
Если вам просто нужен путь к файлу, который появляется в URL-адресе после использования домена $_SERVER['REQUEST_URI']
Ответ 9
Я никогда не нашел способ сделать это так.
Я всегда устанавливаю конфигурационную переменную с пулом сервера на один уровень выше веб-корня. Тогда это:
- $configVar. 'public/whatever/' для файлов внутри root,
- но вы также можете включить извне с помощью $configVar. 'phpInc/db.inc.php/' и т.д.
Ответ 10
Это работает как прелесть для меня, везде, где я развертываю, с правилами перезаписи или без них:
$baseDir = 'http://'.$_SERVER [' HTTP_HOST ']. (dirname ($ _SERVER [' SCRIPT_NAME '])! ='/'? dirname ($ _ SERVER [ "SCRIPT_NAME" ]).'/':'/');
Ответ 11
Это то, что я использовал в своем приложении, которое отлично работает, я также использую пользовательский порт, поэтому мне тоже пришлось это учитывать.

Английская аббревиатура URL расшифровывается как Uniform Resource Locator, что в переводе на русский означает «унифицированный указатель ресурса». Впервые URL стал применяться в 1990 году. Слава его изобретения принадлежит создателю Всемирной паутины — Тиму Бернерсу-Ли.
Что такое URL

Определить URL-адрес веб-страницы просто — он показан в адресной строке браузера. Оттуда его можно скопировать, кликнув по адресной строке правой кнопкой мыши (при этом адрес выделяется) и в контекстном меню выбрав команду «Копировать».
Чтобы скопировать адрес отдельного изображения на странице, нужно кликнуть правой кнопкой мыши по картинке и выбрать пункт «Копировать адрес изображения» или «Копировать URL картинки» (в разных браузерах название команды может отличаться).
Для копирования адреса документа в контекстном меню ведущей к нему ссылки следует выбрать команду «Копировать адрес ссылки».
Структура URL адреса
URL-адрес, который мы видим в адресной строке браузера, состоит из нескольких частей:
Затем указывается путь к странице (3), состоящий из каталогов и подкаталогов, который, в свою очередь, включает в себя ее название.
URL также может включать параметры, которые указываются после знака «?» и разделяются символом «&». Пример адреса страницы с результатами поиска по слову «url» в поисковой системе Google:
Виды URL
URL-адреса веб-страниц бывают статические и динамические.
С точки зрения SEO предпочтительнее статические ссылки, так как динамические URL имеют ряд недостатков:
- они бывают очень длинными, настолько, что могут не помещаться в строке поиска и обрезаться при копировании.
- динамические адреса сложно запоминаются и не дают пользователю понимания, какое содержимое отобразится на странице при переходе по ссылке;
- CTR (click-through rate — показатель кликабельности) у них ниже, чем у статических;
- в динамических URL не учитываются ключевые слова.
Форматы URL
Транслитерация
Для обозначения названий статей обычно используют транслитерацию. Такие адреса легко читаются и понятны для восприятия пользователей.
По такому адресу сразу можно судить, какое содержимое вы увидите на странице. Поисковые системы легко распознают в подобных адресах ключевые слова, что также оказывает положительное влияние на SEO. Если в URL используется транслитерация, становится четко видна структура сайта и, чтобы попасть в нужный раздел, пользователь просто может стереть в адресной строке часть адреса.
Латиница
Латинские URL представляют собой адреса, переведенные на английский язык. Например, вместо «/novosti/» в адресе будет значиться «/news/».
Такой формат УРЛ часто используется для обозначения веб-страниц категорий и рубрик. Этот вариант считается универсальным, так как легко воспринимается пользователями и без труда обрабатывается поисковыми роботами.
Кириллические URL
Такой формат URL чаще всего применяют в кириллических доменах или когда часть адреса не очень длинная.
К их преимуществам относятся:
- удобство и простота запоминания;
- достаточное количество свободных доменов из-за невысокой популярности кириллицы;
- возможность использования ключевых слов в УРЛ.
Это объясняется тем, что запись URL-адресов возможна только определенными символами из разрешенного набора, а символы кириллицы в него не входят. Поэтому адрес, в котором используется кириллица, шифруется, хотя при этом ссылка все равно будет работать.
К минусам кириллических УРЛов можно отнести и трудность для восприятия зарубежными пользователями, привыкшими к латинским символам, а также сложности при чтении адресов этого формата поисковыми роботами (такие URL приходится переводить в понятный для робота вид).
Человекопонятные URL
Кроме того, что они позволяют понять содержание веб-страницы еще до перехода по ссылке, подобные адреса имеют и другие преимущества:
При формировании ЧПУ на своем сайте следует придерживаться определенных правил:
- использовать транслитерацию в соответствии с приведенной ниже таблицей (с одним исключением — «ый» — транслитерируется как «iy»).

- пробелы, а также знаки препинания менять на дефис или нижнее подчеркивание, а два таких символа подряд заменять на один;
- удалять символ «-» в начале или в конце адреса;
- не использовать заглавные буквы, так как УРЛы чувствительны к регистру;
- стараться формировать короткие URL.
Рекомендации по созданию URL
- Правильно сформированный URL должен включать в себя ключевые слова, так как поисковые системы учитывают этот фактор при ранжировании. Однако не стоит злоупотреблять ими в УРЛ, чтобы поисковик не посчитал, что вы применяете спамные методы продвижения.
- Следует создавать максимально короткий URL, желательно не более 4-5 слов, а общая длина адреса не должна быть более 80 символов. Длинные ссылки не показываются в поисковой выдаче, адрес может обрезаться на середине.
- Чем дальше подраздел сайта или веб-страница находится от главной, тем длиннее будет URL конечной страницы. Поэтому иногда необходимо убирать из URL упоминания о категориях и рубриках.
- Латинские символы в URL более предпочтительны, чем символы кириллицы, так как такие сайты легче продвигать.
- Рекомендуется разделять слова в адресе веб-страницы символом дефиса «-», а не нижнего подчеркивания «_».
- Если вы хотите изменить адреса страниц, чтобы избежать их дублирования, вам обязательно нужно настроить 301 редирект.
Соблюдайте указанные выше рекомендации, формируйте человекопонятные URL, чтобы при прочих равных условиях получить преимущество над другими сайтами.
Схема - это протокол для перехода между страницами. Его можно использовать не только для перехода между приложениями, но и для перехода со страниц H5 на страницы приложений.
Независимо от Android или IOS, вы можете открыть локальное приложение, открыв адрес протокола схемы на странице H5.
В URL-схемах есть два слова:
Вы можете понять URL-адрес мобильного приложения точно так же, как вы понимаете URL-адрес веб-страницы, то есть ее URL-адрес. Возьмите веб-сайт Apple и приложение WeChat для простого сравнения:
- схема: требуется название протокола
- хост: требуется адрес протокола
- порт: порт протокола, можно оставить пустым
- path: путь протокола, доступно / несколько подключений
- запрос: параметры могут быть перенесены и несколько подключений
- фрагмент: якорь
Example:
- weixin: название протокола : Доменное имя
- 8080: порт
- / dl / news / open: путь к странице
- data, params: переданные параметры
Пример URI и его компонентов.
Различные схемы URL
Базовые схемы URL, Относится к части схемы URL-адреса, такой как упомянутый выше WeChat. Единственная функция этой части - открыть соответствующее приложение без возможности перехода к какой-либо функции.
Сложные схемы URL Есть два типа: один - напрямую открыть определенную функцию приложения, а другой - напрямую ввести предустановленные символы после открытия определенной функции.
Преобразование схем URL Это означает, что некоторые приложения используют правила схем URL и некоторые встроенные функции системы для расширенияСложные схемы URL, И сделайте так, чтобы часть, которая должна вводить символы или параметры, можно было предварительно установить или перескакивать после ввода, дополнительно уменьшая шаги.
x-callback-URL
Если мы по-прежнему хотим, чтобы приложение отвечало на разные результаты, нам нужно использовать x-callback-URL. Например, если последняя схема URL-адресов выполняется успешно, хочу ли я вернуться в приложение до перехода? По-прежнему необходимо предпринять другое действие (подключить другую схему URL-адресов, чтобы открыть определенную функцию другого приложения)? Перепрыгиваете ли вы обратно к предыдущему приложению или открываете другое действие, если вы хотите использовать новые схемы URL-адресов для выполнения следующих действий после запуска схем URL-адресов, вы должны полагаться на x-callback-URL, который исправлен. Синтаксис:
- Следуйте схемам URL &x-success , Что означает, что делать дальше после успешного ввода предыдущего URL;
- Следуйте схемам URL &x-error , Что означает, что делать дальше после сбоя предыдущего URL;
- Следуйте схемам URL &x-cancel , Что означает, что делать дальше после отмены результата операции предыдущего URL;
- остался один &x-source Давай поговорим об этом при встрече.
Кодировка URL (кодирование)
Если параметры в URL-адресе содержат специальные символы, он должен быть закодирован заранее, иначе URL-адрес может быть не открыт.
Символы в URL-адресе можно разделить на две категории, некоторые из которых могут нормально отображаться в ссылке, например буквы, цифры и / Подождите, пока появится часть символа. Кроме того, все они не могут отображаться нормально, и их необходимо закодировать, чтобы они отображались как часть URL-адреса. Например, пробел должен быть выражен как %20 Вам не нужно вдаваться в правила конвертации. В Интернете есть множество инструментов (например,FeHelperПредоставьте функции кодирования и декодирования URL-адресов, которые могут декодировать закодированный беспорядочный URL-адрес в символы, которые мы можем освежить:
Конечно, эти инструменты также могут, в свою очередь, преобразовывать наши часто используемые символы в символы, которые можно использовать в URL-адресах.
Так что теоретически все символы, которые URL не поддерживает, должны быть закодированы. Задача кодирования настолько проста: заменить символы, не поддерживаемые URL-адресом, на символы, которые он поддерживает. В таком случае почему бы иногда не писать код? Потому что, когда вам не нужно кодировать, приложение сделает это за вас в частном порядке.
Как найти URL
Среди них основные схемы URL-адресов можно запросить вручную.Все приложения, поддерживающие базовые схемы URL-адресов, могут найти свои основные схемы URL-адресов следующими способами.. Поскольку другие схемы URL-адресов записаны в код, вам необходимо запросить документацию для каждого приложения и обратиться к примерам, чтобы создать URL-адреса в соответствии с вашими потребностями.
Найдите основные схемы URL
- IOS: основной метод поиска схем URL-адресов можно найти в приложении. info.plist Запросить
- AOS: найдите в файле AndroidManifest.xml.
Сложный / деформированный / x-callback-URL
Если вы хотите знать все, вы можете запрашивать только документы.
Три типа схем URL-адресов, сложный / деформированный / x-callback-URL, записаны в коде и не могут быть получены путем запроса файла .plist. Однако разработчики приложений, которые поддерживают эти три схемы URL-адресов, добавляют эти функции в свои приложения, как правило, для использования пользователями, поэтому для тех функций, которые пользователи хотят, чтобы пользователи использовали, они будут писать специальные документы, чтобы сообщить читателям, как их использовать.
Если вы хотите найти сложный / преобразованный / x-callback-URL любого приложения, вам просто нужно выполнить поиск Схемы URL названий приложений , Обычно вы можете найти страницу документации по схемам URL в приложении. В то же время вы можете перейти непосредственно на официальные сайты этих приложений, чтобы найти соответствующие веб-страницы.
Универсальная ссылка
Универсальные ссылки предоставляют вам несколько основных преимуществ, которые вы не можете получить при использовании пользовательских схем URL. В частности, универсальная ссылка:
Android не поддерживает Universal Link.
H5 Процесс открытия приложения
- В AOS, поскольку унифицированная схема использования универсального канала связи не поддерживается, если в системе установлено приложение, откройте приложение, в противном случае ответа нет.
- В IOS9 +, если в приложении есть универсальная ссылка, используйте универсальную ссылку, если в системе установлена (Система автоматического распознавания) Приложение открывает приложение, в противном случае открывает веб-страницу; IOS без универсальных ссылок и IOS, не поддерживающий универсальные ссылки, совместимы с AOS;
Как определить, установлено ли в системе соответствующее приложение?
Насчет этого H5 не может.
Как реализовать описанный выше сценарий, не зная, установлена ли система с соответствующим приложением?
Почему некоторые приложения не могут проснуться в WeChat и им нужно «открываться в браузере»?
Браузер WeChat использует схему URL-адресов вашего собственного приложения для удовлетворения двух условий
Воспользуйтесь сервисом микрозагрузки на открытой платформе Tencent,
Приложение должно быть приложением уровня S на платформе.
Добавьте схему своего приложения в официальный белый список WeChat
Если два вышеуказанных условия не выполняются, пользователям следует только открывать в других браузерах.
PS: Для загрузки apk WeChat блокирует любое приложение, поэтому, если вы хотите предоставить ссылку для скачивания, вы не сможете избежать простого способа открытия ее в браузере.
И именно URL является тем базовым параметром атрибута href, с помощью которого создаются гиперссылки, входящие в состав гипертекста как основы Мировой Паутины. Благодаря урлу все пользователи получают возможность посетить нужный сайт и получить искомую информацию.

Кроме этого, разберем на наглядных примерах, из чего состоят урлы, какого вида они бывают и как находить адреса изображений, страниц сайта, видео и копировать их для своих нужд.
Что такое URL адрес и из чего он состоит?

URI является более общей системой идентификации. Она может включать в себя либо URN, либо URL, либо оба идентификатора вместе. То есть, URN и URL являются частными случаями URI. Попробую объяснить, что значит каждый термин, на наглядном примере из реальной жизни.
Допустим, имеется конкретный адрес (г. Нижний, ул. Верхняя, д.4, кв.15), до которого возможно добраться различными способами в зависимости от степени удаления пункта отправления. Имя владельца квартиры Василий Васильевич Пупкин.
Скажем, сосед Пупкина доберется к нему пешком (это будет в данном случае методом доступа к объекту). А родственнику, живущему за несколько тысяч километров, придется задействовать комплексный вариант (прилететь на самолете, приехать по нужному адресу на такси и дойти оставшееся расстояние пешком). Способ доступа в этом случае будет другим (самолет - такси - пешком). В контексте выше сказанного это и есть URL (адрес + метод доступа к объекту).
Нас интересует в первую очередь унифицированный указатель, поскольку именно он является основной идентификационной системой, используемой широко на практике в глобальной сети. Поэтому далее мы и уделим основное время описанию структурных особенностей URL.
Структура УРЛ и некоторые особенности для вебмастеров
Итак, мы с вами определили в общих чертах, что же такое URL адрес. Это путь до любого файла (вебстраницы сайта, картинки, видео и др.). Начнем с простого примера. Вот как может выглядеть локатор в общем виде для одного из файлов, находящегося в определенной директории (папке):
В качестве реального примера привожу урл адрес файла, который содержит логотип этого блога:
Тогда наблюдается присутствие в интернете двух разных ресурсов (с WWW и без) с одинаковым содержанием. С точки зрения поисковых систем это зеркала, являющиеся по своей сути дублями, которые жутко мешают продвижению проекта как в Яндексе, так и в Гугле.
К тому же, обратные ссылки, проставленные на ваш сайт с доноров, могут быть распределены в неизвестных пропорциях между зеркалами. Поэтому надо предпринять действия по определению главного домена и склейке зеркал, в том числе посредством 301-ого редиректа.
С доменным именем мы разобрались. Кстати, при создании сайта домен вашего веб-проекта будет считаться корневой папкой с точки зрения файловой структуры веб-сервера. Вследствие этого цепочку после двойного слеша можно воспринимать как последовательность вложенных друг в друга папок (их может быть несколько), где на конце урла находится нужный файл:
Для полноты картины нужно еще упомянуть об адресах страниц сайтов в интернете. Чаще всего встречаются урлы трех видов (ЧПУ), которые наиболее предпочтительны во всех смыслах:
Вроде бы, первый вариант больше всего отвечает разобранной нами схеме. Но в случае с URL страницы не все так однозначно. В теории это состоит следующим образом (попробую объяснить все на примере обычного блога, по-моему, он достаточно наглядный и понятный большинству).
При стандартных серверных настройках каждый URL, соответствующий каталогу (папке), должен заканчиваться слэшем, в этом случае обработчик "поймет", что необходимо отобразить листинг всех файлов, которые там содержатся, а не какой-то конкретный объект, поиск которого будет осуществляться, если слеша не будет (таким образом вы экономите ресурсы сервера).
В соответствии с этими рассуждениями локатор главной должен заканчиваться на «/», поскольку домен является корневой директорией:
По этой же причине такой же вид урла соответствует рубрикам сайта:
А вот статические или страницы записей выводятся в таком обличье:
Помните, чуть выше я упоминал о двух легитимных вариантах существования файлов в Unix-подобных операционных системах (с расширением и без)?
Однако, подобные рассуждения не совсем корректны в том числе и потому, что подавляющее большинство современных вебсайтов работает под управлением самых различных CMS, или, по-простому, движков, которые генерируют странички динамически "на лету" на базе имеющихся шаблонов с расширением .php, включающих комплекс соответствующих функций.
Если взять в качестве образца самый популярный в мире движок WordPress, то там все шаблоны, отвечающие за формирование различных страничек сайта (главной, рубрик, вебстраниц записей и т.д.) входят физически в одну директорию текущей темы.
Таким образом, содержание названных страниц в конечном виде существует лишь при просмотре в веб-браузере, а не физически на сервере. К слову, с файловым строением тем WP вы можете познакомиться перейдя по ссылке, этот материал даст вам дополнительные полезные сведения.
Кто привык копать глубоко и желает более подробно изучить этот архиважный аспект, отсылаю вас к очень качественному материалу, где он освещается на основе первоисточника в формате спецификации общего синтаксиса URL, и в котором красной нитью проходит утверждение, что урл вообще (вне зависимости от своего содержания) указывает на абстрактное местоположение ресурса, а не на его конкретное физическое расположение.
Резюмируя и суммируя все приведенные доводы, могу утверждать, что с точки зрения синтаксиса все образцы рассмотренных урлов для веб-страниц сайта (со слешем на конце, без него и с расширением .html) вполне корректны и пригодны для использования.
Более того, ни один из них не имеет сколь-нибудь заметного преимущества в глазах поисковых систем. Единственное, для обеспечения правильной индексации надо также установить 301 редирект в случае применения URL со слешем или без в конце.
Надеюсь, что предоставленная информация поможет вам определиться с настройкой урлов на своем сайте. Для проектов, работающих на WordPress, например, постоянные ссылки сайта можно легко настроить в соответствующем разделе админ-панели.
Важное замечание! Настройку ссылок желательно производить в начале создания проекта, дальнейшие изменения могут замедлить или приостановить продвижение сайта, поскольку переиндексация у поисковиков не происходит мгновенно.
Выше мы рассмотрели частные случаи различных типов локаторов, ну а общая блок-схема, демонстрирующая структуру URL, выглядит следующим образом:

Пожалуй, следует дать некоторые разъяснения по отдельным составляющим.
Для полноты информации вы можете ознакомиться с полным перечнем используемых схем на соответствующей страничке Википедии.
В таком случае для доступа к нужному файлу или папке понадобиться указать логин и пароль, а также порт (если он отличен от стандартного, применяемого по умолчанию):
А это и есть самые настоящие дубли, большое количество которых способно существенно снизить скорость индексирования страничек, а значит, и косвенным образом замедлить продвижение веб- ресурса. Поэтому, думаю, будет уместным в этом месте дать гиперссылку, перейдя по которой вы узнаете, как бороться с самым разнообразным дублированным контентом на Вордпресс.
К выше сказанному надо бы еще добавить, что в стандартных урлах рекомендуется использовать лимитированную выборку знаков: буквы латинского алфавита в нижнем регистре [a-z], цифры 3, точку [.], нижнее подчеркивание [_], и дефис [-].
Такие ограничения действуют со времени зарождения интернета, но с некоторых пор ввиду развития глобальной сети появилась необходимость формировать URL с применением символов национальных языков, включая русский. Такая возможность появилась, но для ее реализации требуется кодировка (encoding) любых знаков в формате ASCII, который понимают браузеры.
Кодирование и декодирование URL
Итак, после некоторых предпринятых соответствующими международными организациями усилий сайт может использовать для адресов своих страниц локаторы, включающие буквы практически любого языка. Нас интересует русский, поэтому можете проверить сие утверждение, введя в адресную строку браузера урл одной из страниц Русской Википедии:
Адрес корректно отобразится:

Это и есть закодированные русские буквы, которые web-браузер автоматически преобразует в читабельный текст на кириллице. Кстати, в сети есть немало сервисов, которые предлагают быстрое кодирование и декодирование содержания URL, например, вот этот:

Конечно, для пользователей рунета гораздо более привлекательным является текст на русском, содержащийся в локаторе (кстати, и доменное имя может быть кириллическим).
Однако, формировать урлы на кириллице для страниц своего сайта я все-таки советую только в том случае, если проект имеет какие-то свои особенности, вследствие которых именно русские символы в URL будут эффективнее привлекать посетителей, особенно целевую аудиторию.
В других случаях все же оптимальнее будет применять латиницу (а для WordPress использовать плагины транслитерации для автоматического преобразования русских букв в постоянных ссылках в латинские), поскольку это исключает некоторые возможные ошибки, а поисковые системы не делают языковых предпочтений в этом аспекте при ранжировании.
Как узнать URL изображения, видео или страницы сайта?
При работе в интернете да и просто во время сёрфинга или поиска информации в сети очень часто нужно просмотреть или скопировать адрес того или иного объекта. Где же взять нужный урл на открытой в браузере веб-страничке? Что касается URL страницы сайта, то его можно подсмотреть в адресной строке:



С помощью того же контекстного меню можно найти и скопировать также URL нужной вам гиперссылки, содержащейся в тексте:

Иногда нужно узнать урл размещенной в web-пространстве картинки. Для этого опять используйте тот же метод:


В случае присутствия видео в контенте веб-странички его URL- адрес можно получить с похожей легкостью (достаточно щелкнуть правой кнопкой мыши прямо по плейеру):

Таким вот образом вы легко можете получать и копировать URL-адрес практически любого объекта. Кстати, контекстное меню может принимать различный вид в зависимости от применяемого веб-браузера, но суть его опций остается практически идентичной.
Читайте также: