
Virtual machine memory usage vmware ошибка

Предупреждения о ОЗУ и CPU
Данные предупреждения и алерты, вы можете обнаружить как в vCenter server, так и на отдельном хосте ESXI. Выглядят эти алерты вот так:


Оба этих предупреждений на самом деле очень критичные, так как сообщают, что ваш ESXI хост использует всю или практически всю оперативную память или процессор, хорошо если это небольшая пиковая нагрузка, но если такая ситуация постоянная, есть повод серьезно задуматься над выделенными ресурсами (я уже высказывал свои мысли по этому поводу)
Если вы перейдет на вкладку "Summary", то в пункте "Resources" увидите шкалу загрузки по процессору

и оперативной памяти.

Пути решения данной ситуации такие:
- Вы ограничиваете потребление ресурсов для прожорливой виртуальной машины
- Либо более правильно перераспределяете их и дорабатываете план планирования, это дольше, но лучше, так как будет возможность предусмотреть будущий рост
Что плохого несут в себе эти предупреждения
- Ваш сервер быстрее изнашивается, так как при правильно планировании, он не должен использовать более 90 процентов ресурсов.
- Идет борьба за ресурсы между виртуальными машинами, в следствии чего уменьшается их производительность.
- Может привести к зависанию хоста или виртуальной машины
Советую к этим моментам отнестись более детально, от себя могу порекомендовать хорошую статью, про использовании памяти виртуальными машинами VMware vSphere и не доводите до такого.

Немного теории
Оперативная память виртуальных машин берется из памяти сервера, на которых работают ВМ. Это вполне очевидно:). Если оперативной памяти сервера не хватает для всех желающих, ESXi начинает применять техники оптимизации потребления оперативной памяти (memory reclamation techniques). В противном случае операционные системы ВМ падали бы с ошибками доступа к ОЗУ.
Какие техники применять ESXi решает в зависимости от загруженности оперативной памяти:
| Состояние памяти | Граница | Действия |
| High | 400% от minFree | После достижения верхней границы, большие страницы памяти разбиваются на маленькие (TPS работает в стандартном режиме). |
| Clear | 100% от minFree | Большие страницы памяти разбиваются на маленькие, TPS работает принудительно. |
| Soft | 64% от minFree | TPS + Balloon |
| Hard | 32% от minFree | TPS + Compress + Swap |
| Low | 16% от minFree | Compress + Swap + Block |
minFree — это оперативная память, необходимая для работы гипервизора.
До ESXi 4.1 включительно minFree по умолчанию было фиксированным — 6% от объема оперативной памяти сервера (процент можно было поменять через опцию Mem.MinFreePct на ESXi). В более поздних версиях из-за роста объемов памяти на серверах minFree стало рассчитываться исходя из объема памяти хоста, а не как фиксированное процентное значение.
Значение minFree (по умолчанию) считается следующим образом:
| Процент памяти, резервируемый для minFree | Диапазон памяти |
| 6% | 0-4 Гбайт |
| 4% | 4-12 Гбайт |
| 2% | 12-28 Гбайт |
| 1% | Оставшаяся память |
Например, для сервера со 128 Гбайт RAM значение MinFree будет таким:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 Мбайт = 1,88 Гбайт
Фактическое значение может отличаться на пару сотен МБайт, это зависит от сервера и оперативной памяти.
| Процент памяти, резервируемый для minFree | Диапазон памяти | Значение для 128 Гбайт |
| 6% | 0-4 Гбайт | 245,76 Мбайт |
| 4% | 4-12 Гбайт | 327,68 Мбайт |
| 2% | 12-28 Гбайт | 327,68 Мбайт |
| 1% | Оставшаяся память (100 Гбайт) | 1024 Мбайт |
Обычно для продуктивных стендов нормальным можно считать только состояние High. Для стендов для тестирования и разработки приемлемыми могут быть состояния Clear/Soft. Если оперативной памяти на хосте осталось менее 64% MinFree, то у ВМ, работающих на нем, точно наблюдаются проблемы с производительностью.
В каждом состоянии применяются определенные memory reclamation techniques начиная с TPS, практически не влияющего на производительность ВМ, заканчивая Swapping’ом. Расскажу про них подробнее.
Transparent Page Sharing (TPS). TPS — это, грубо говоря, дедупликация страниц оперативной памяти виртуальных машин на сервере.
ESXi ищет одинаковые страницы оперативной памяти виртуальных машин, считая и сравнивая hash-сумму страниц, и удаляет дубликаты страниц, заменяя их ссылками на одну и ту же страницу в физической памяти сервера. В результате потребление физической памяти снижается и можно добиться некоторой переподписки по памяти практически без снижения производительности.

Источник
По умолчанию ESXi выделяет память большим страницам. Разбивание больших страниц на маленькие начинается при достижении порога состояния High и происходит принудительно, когда достигается состояние Clear (см. таблицу состояний гипервизора).
Если же вы хотите, чтобы TPS начинал работу, не дожидаясь заполнения оперативной памяти хоста, в Advanced Options ESXi нужно установить значение “Mem.AllocGuestLargePage” в 0 (по умолчанию 1). Тогда выделение больших страниц памяти для виртуальных машин будет отключено.
С декабря 2014 во всех релизах ESXi TPS между ВМ по умолчанию отключен, так как была найдена уязвимость, теоретически позволяющая получить из одной ВМ доступ к оперативной памяти другой ВМ. Подробности тут. Информация про практическую реализацию эксплуатации уязвимости TPS мне не встречалось.
Политика TPS контролируется через advanced option “Mem.ShareForceSalting” на ESXi:
0 — Inter-VM TPS. TPS работает для страниц разных ВМ;
1 – TPS для ВМ с одинаковым значением “sched.mem.pshare.salt” в VMX;
2 (по умолчанию) – Intra-VM TPS. TPS работает для страниц внутри ВМ.
Однозначно имеет смысл выключать большие страницы и включать Inter-VM TPS на тестовых стендах. Также это можно использовать для стендов с большим количеством однотипных ВМ. Например, на стендах с VDI экономия физической памяти может достигать десятков процентов.
Memory Ballooning. Ballooning уже не такая безобидная и прозрачная для операционной системы ВМ техника, как TPS. Но при грамотном применении с Ballooning’ом можно жить и даже работать.
Вместе с Vmware Tools на ВМ устанавливается специальный драйвер, называемый Balloon Driver (он же vmmemctl). Когда гипервизору начинает не хватать физической памяти и он переходит в состояние Soft, ESXi просит ВМ вернуть неиспользуемую оперативную память через этот Balloon Driver. Драйвер в свою очередь работает на уровне операционной системы и запрашивает свободную память у нее. Гипервизор видит, какие страницы физической памяти занял Balloon Driver, забирает память у виртуальной машины и возвращает хосту. Проблем с работой ОС не возникает, так как на уровне ОС память занята Balloon Driver’ом. По умолчанию Balloon Driver может забрать до 65% памяти ВМ.
Если на ВМ не установлены VMware Tools или отключен Ballooning (не рекомендую, но есть KB:), гипервизор сразу переходит к более жестким техникам отъема памяти. Вывод: следите, чтобы VMware Tools на ВМ были.

Работу Balloon Driver’а можно проверить из ОС через VMware Tools.
Memory Compression. Данная техника применяется, когда ESXi доходит до состояния Hard. Как следует из названия, ESXi пытается сжать 4 Кбайт страницы оперативной памяти до 2 Кбайт и таким образом освободить немного места в физической памяти сервера. Данная техника значительно увеличивает время доступа к содержимому страниц оперативной памяти ВМ, так как страницу надо предварительно разжать. Иногда не все страницы удается сжать и сам процесс занимает некоторое время. Поэтому данная техника на практике не очень эффективна.
Memory Swapping. После недолгой фазы Memory Compression ESXi практически неизбежно (если ВМ не уехали на другие хосты или не выключились) переходит к Swapping’у. А если памяти осталось совсем мало (состояние Low), то гипервизор также перестает выделять ВМ страницы памяти, что может вызвать проблемы в гостевых ОС ВМ.
Вот как работает Swapping. При включении виртуальной машины для нее создается файл с расширением .vswp. По размеру он равен незарезервированной оперативной памяти ВМ: это разница между сконфигурированной и зарезервированной памятью. При работе Swapping’а ESXi выгружает страницы памяти виртуальной машины в этот файл и начинает работать с ним вместо физической памяти сервера. Разумеется, такая такая “оперативная” память на несколько порядков медленнее настоящей, даже если .vswp лежит на быстром хранилище.
В отличие от Ballooning’а, когда у ВМ отбираются неиспользуемые страницы, при Swapping’e на диск могут переехать страницы, которые активно используются ОС или приложениями внутри ВМ. В результате производительность ВМ падает вплоть до подвисания. ВМ формально работает и ее как минимум можно правильно отключить из ОС. Если вы будете терпеливы ;)
Если ВМ ушли в Swap — это нештатная ситуация, которую по возможности лучше не допускать.
Основные счетчики производительности памяти виртуальной машины
Вот мы и добрались до главного. Для мониторинга состояния памяти в ВМ есть следующие счетчики:
Active — показывает объем оперативной памяти (Кбайт), к которому ВМ получила доступ в предыдущий период измерения.
Usage — то же, что Active, но в процентах от сконфигурированной оперативной памяти ВМ. Рассчитывается по следующей формуле: active ÷ virtual machine configured memory size.
Высокий Usage и Active, соответственно, не всегда является показателем проблем производительности ВМ. Если ВМ агрессивно использует память (как минимум, получает к ней доступ), это не значит, что памяти не хватает. Скорее это повод посмотреть, что происходит в ОС.
Есть стандартный Alarm по Memory Usage для ВМ:

Shared — объем оперативной памяти ВМ, дедуплицированной с помощью TPS (внутри ВМ или между ВМ).
Granted — объем физической памяти хоста (Кбайт), который был отдан ВМ. Включает Shared.
Consumed (Granted — Shared) — объем физической памяти (Кбайт), которую ВМ потребляет с хоста. Не включает Shared.
Если часть памяти ВМ отдается не из физической памяти хоста, а из swap-файла или память отобрана у ВМ через Balloon Driver, данный объем не учитывается в Granted и Consumed.
Высокие значения Granted и Consumed — это совершенно нормально. Операционная система постепенно забирает память у гипервизора и не отдает обратно. Со временем у активно работающей ВМ значения данных счетчиков приближается к объему сконфигурированной памяти, и там остаются.
Zero — объем оперативной памяти ВМ (Кбайт), который содержит нули. Такая память считается гипервизором свободной и может быть отдана другим виртуальным машинам. После того, как гостевая ОС получила записала что-либо в зануленную память, она переходит в Consumed и обратно уже не возвращается.
Reserved Overhead — объем оперативной памяти ВМ, (Кбайт) зарезервированный гипервизором для работы ВМ. Это небольшой объем, но он обязательно должен быть в наличии на хосте, иначе ВМ не запустится.
Balloon — объем оперативной памяти (Кбайт), изъятой у ВМ с помощью Balloon Driver.
Compressed — объем оперативной памяти (Кбайт), которую удалось сжать.
Swapped — объем оперативной памяти (Кбайт), которая за неимением физической памяти на сервере переехала на диск.
Balloon и остальные счетчики memory reclamation techniques равны нулю.
Вот так выглядит график со счетчиками Memory нормально работающей ВМ со 150 ГБ оперативной памяти.

На графике ниже у ВМ явные проблемы. Под графиком видно, что для данной ВМ были использованы все описанные техники работы с оперативной памятью. Balloon для данной ВМ сильно больше, чем Consumed. По факту ВМ скорее мертва, чем жива.

ESXTOP
Как и с CPU, если хотим оперативно оценить ситуацию на хосте, а также ее динамику с интервалом до 2 секунд, стоит воспользоваться ESXTOP.
Экран ESXTOP по Memory вызывается клавишей «m» и выглядит следующим образом (выбраны поля B,D,H,J,K,L,O):

Интересными для нас будут следующие параметры:
Mem overcommit avg — среднее значение переподписки по памяти на хосте за 1, 5 и 15 минут. Если выше нуля, то это повод посмотреть, что происходит, но не всегда показатель наличия проблем.
В строках PMEM/MB и VMKMEM/MB — информация о физической памяти сервера и памяти доступной VMkernel. Из интересного здесь можно увидеть значение minfree (в МБайт), состояние хоста по памяти (в нашем случае, high).
В строке NUMA/MB можно увидеть распределение оперативной памяти по NUMA-нодам (сокетам). В данном примере распределение неравномерное, что в принципе не очень хорошо.
Далее идет общая статистика по серверу по memory reclamation techniques:
PSHARE/MB — это статистика TPS;
SWAP/MB — статистика использования Swap;
ZIP/MB — статистика компрессии страниц памяти;
MEMCTL/MB — статистика использования Balloon Driver.
По отдельным ВМ нас может заинтересовать следующая информация. Имена ВМ я скрыл, чтобы не смущать аудиторию:). Если метрика ESXTOP аналогична счетчику в vSphere, привожу соответствующий счетчик.
MEMSZ — объем памяти, сконфигурированный на ВМ (МБ).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.
GRANT — Granted в МБайт.
TCHD — Active в МБайт.
MCTL? — установлен ли на ВМ Balloon Driver.
MCTLSZ — Balloon в МБайт.
MCTLGT — объем оперативной памяти (МБайт), который ESXi хочет изъять у ВМ через Balloon Driver (Memctl Target).
MCTLMAX — максимальный объем оперативной памяти (МБайт), который ESXi может изъять у ВМ через Balloon Driver.
SWCUR — текущий объем оперативной памяти (МБайт), отданный ВМ из Swap-файла.
SWGT — объем оперативной памяти (МБайт), который ESXi хочет отдавать ВМ из Swap-файла (Swap Target).
Также через ESXTOP можно посмотреть более подробную информацию про NUMA-топологию ВМ. Для этого нужно выбрать поля D,G:

NHN – NUMA узлы, на которых расположена ВМ. Здесь можно сразу заметить wide vm, которые не помещаются на один NUMA узел.
NRMEM – сколько мегабайт памяти ВМ берет с удаленного NUMA узла.
NLMEM – сколько мегабайт памяти ВМ берет с локального NUMA узла.
N%L – процент памяти ВМ на локальном NUMA узле (если меньше 80% — могут возникнуть проблемы с производительностью).
Memory на гипервизоре
Если счетчики CPU по гипервизору обычно не представляют особого интереса, то с памятью ситуация обратная. Высокий Memory Usage на ВМ не всегда говорит о наличие проблемы с производительностью, а вот высокий Memory Usage на гипервизоре, как раз запускает работу техник управления памятью и вызывает проблемы с производительностью ВМ. За алармами Host Memory Usage надо следить и не допускать попадания ВМ в Swap.


Unswap
Если ВМ попала в Swap, ее производительность сильно снижается. Следы Ballooning’а и компрессии быстро исчезают после появления свободной оперативной памяти на хосте, а вот возвращаться из Swap в оперативную память сервера виртуальная машина совсем не торопится.
До версии ESXi 6.0 единственным надежным и быстрым способ вывода ВМ из Swap была перезагрузка (если точнее выключение/включение контейнера). Начиная с ESXi 6.0 появился хотя и не совсем официальный, но рабочий и надежный способ вывести ВМ из Swap. На одной из конференций мне удалось пообщаться с одним из инженеров VMware, отвечающим за CPU Scheduler. Он подтвердил, что способ вполне рабочий и безопасный. В нашем опыте проблем с ним также замечено не было.
Собственно команды для вывода ВМ из Swap описал Duncan Epping. Не буду повторять подробное описание, просто приведу пример ее использования. Как видно на скриншоте, через некоторое время после выполнения указанной команд Swap на ВМ исчезает.

Советы по управлению оперативной памятью на ESXi
Напоследок приведу несколько советов, которые помогут вам избежать проблем с производительностью ВМ из-за оперативной памяти:
-
Не допускайте переподписки по оперативной памяти в продуктивных кластерах. Желательно всегда иметь
Примерно 2,5 года назад вышел документ по решению проблем с производительностью в VMware vSphere 4.1.
В начале документа находится схема траблшутинга

Соответственно, есть две дальнейшие диаграммы: базовая и продвинутая.

Возможные проблемы упорядочены по принадлежности (с VMware Tools, CPU, etc) и по их влиянию (от 100% влияния на производительность до возможного).
Проверка VMware Tools.
Если VMware Tools не запущены, необходимо разбираться с гостевой операционной системой. Причина может скрываться в обновлении ядра Linux либо отключенной (кем-то) службе VMware Tools в Windows.
Если VMware Tools устарели, необходимо их обновить из контекстного меню vClient. Как правило, это случается после установки обновлений на хосты ESX/ESXi. После этого зачастую требуется обновить и VMware Tools.
Проверка загрузки процессора в пуле ресурсов (Resource Pool CPU Saturation).
Если используете пулы ресурсов и лимит на процессорные ресурсы пула, то читайте дальше. В противном случае сразу идите в следующий блок Host CPU Saturation.
Проверка CPU Ready:
На следующем рисунке проиллюстрирован этот пример

Проверка загрузки процессора хоста (Host CPU Saturation).
Проверка CPU Ready:
Схему анализа данного раздела также можно посмотреть на следующем рисунке:

Загрузка процессора ВМ (Guest CPU Saturation).
Проверка ВМ на активное использование свопа (Active VM Memory Swapping).
Также можно проверить это значение для конкретной ВМ хоста:
Примечание: если хост является частью DRS-кластера, следует оценить также загрузку по памяти остальных хостов.
Проверка ВМ на использование свопа в прошлом (VM Swap Wait).
Нехватка памяти в прошлом может вызвать выгрузку страниц памяти ВМ на диск сервера (Host Swap). ESXi не осуществляет загрузку неиспользуемой ВМ памяти обратно в память хоста, поэтому вы можете сталкиваться с замедлением в работе ВМ, пока такие страницы будут прочитаны с диска.
Примечание: если ВМ находится в пуле ресурсов DRS-кластера, следует оценить также загрузку остальных хостов.
Проверка перегруженности СХД (Overloaded Storage Device).
Проверка на отброс принимаемых пакетов (Dropped Receive Packets).
Проверка на отброс отправляемых пакетов (Dropped Transmit Packets).
Проверка, что во многопроцессорной ВМ используется только один vCPU (one vCPU in an SMP VM).
Если у ВМ несколько виртуальных процессоров (vCPU), возможно, гостевая ОС некорректно настроена и не использует все vCPU.
Проверка CPU Ready у ВМ на средне-нагруженном хосте.
Если на ВМ нагрузка появляется всплесками, то даже с невысокой средней загрузкой ЦП хоста ВМ может испытывать проблемы производительности.
Проверка медленного или перегруженного СХД.
Проверим наличие задержек на СХД:
Проверка задержки очередей:
Измерение задержек физического устройства:
Проверка пиковых нагрузок на СХД.
Проверка наличия пиков в передаче данных на сеть.
Проверка низкой загрузки процессора ВМ.
Если загрузка процессора ВМ низкая, но ВМ тормозит, могут быть некоторые проблемы с конфигурацией.
Проверка того, что память ВМ в прошлом была помещена в своп (Past VM Memory Swapping).
Проверка нехватки памяти в пуле ресурсов.
Проверяем использование ballooning:
Проверка нехватки памяти на хосте.
Нехватка памяти для гостевой ОС (High Guest Memory Demand).

Для решения вышеуказанных проблем мы будем использовать esxtop.
Проверка наличия проблем с прерываниями (High Timer-Interrupt Rates).
Проверяем наличие косяков с NUMA.
Проверка большого времени отклика у ВМ со снапшотами.
Рекомендации по решению проблем ждите в следующей статье/переводе.
Спасибо!
Убедился в своей проблеме с производительностью (СХД).
>>Если да, мы имеем дело с перегруженным по вводу/выводу СХД. Идите в набор решений для СХД (ниже в документе).
Добавить комментарий Отменить ответ
Так уже откатили же, даже не скачать.
Я не расист. но после того как VMware стала упралвяться и поддерживаться индусами, стабильность продукта сдохла как бобик.
Перейти с Порше на Жигули - такое себе решение!
Мысли в слух " а может перейти на proxmox " Что-то в последняя время ESXi не стабильно стал по обновлениям.…
Memory management
В полете из солнечной Москвы в прохладный Баку
у меня появилось вдохновение для написания сего текста.
Лично мне он понравился.
Несколько общих слов
Memory Overcomitment

Memory Overcomitment достигается на ESX(i) за счет нескольких технологий. Перечислим их:
- выделение по запросу;
- transparent memory page sharing:
- balloon driver или его еще можно обозвать vmmemctl;
- memory compression (новинка 4.1);
- vmkernel swap.
Что это? Каково место этих технологий? Насколько они офигенны? Насколько они бесполезны? Давайте поразмышляем.
Вводная к размышлениям
Рискну предположить, что в наших инфраструктурах можно выделить несколько групп виртуалок, по разному потребляющих память.
Попробую предложить классификацию. Она примерна, потому что тут я ее предлагаю лишь для иллюстрации своих размышлений.
Давайте теперь рассмотрим эти группы виртуальных машин в контексте механизмов работы с памятью.
Выделение по запросу
Насколько часто это применяется к разным группам виртуальных машин
transparent memory page sharing

Насколько часто это применяется к разным группам виртуальных машин
Сложный вопрос. Сложность во все более широко используемом механизме Large Pages. Если у вас Windows 7/2008 + Nehalem, и используются страницы памяти по 2 МБ, теория гласит что эффект от page sharing будет маленьким. Хотя в реальности там довольно сложный алгоритм:
Именно производительность негативного эффекта не испытывает. Тем более что ESX(i) знает, что такое архитектура NUMA, и если сервер у нас этой архитектуры, то дедупликация страниц памяти идет внутри каждого одного NUMA узла независимо, чтобы виртуалке не приходилось за отдельными, дедуплицированными страницами лазать в память другого процессора.

UPD. от июня 2011 - отключение Large Pages позволяет сэкономить треть ОЗУ, есть такое мнение - TPS vs. Large Pages in real life.
balloon driver / vmmemctl

Насколько часто это применяется к разным группам виртуальных машин
Итак, из чего может взяться ситуация, когда у одной ВМ память надо отнять, чтобы отдать другой? Я вижу несколько вариантов:
- когда у нас memory overcommitment. и сразу у многих ВМ наступили пики нагрузки, что привело к загрузке сервера на 100%. Это, кстати говоря, причина пользоваться MO аккуратно. Впрочем, совсем отказываться от MO, как призывает нас делать Майкрософт, по моему мнению, тоже не стоит.
- когда у нас ломается один из серверов кластера HA. Например, у нас 10 серверов, все загружены по памяти(днем, в будни) процентов на 70.
Вы знаете, что HA все упавшие ВМ перезапустит на одномиз оставшихся серверов? Т.е. виртуалкам потребуется 140% его памяти.
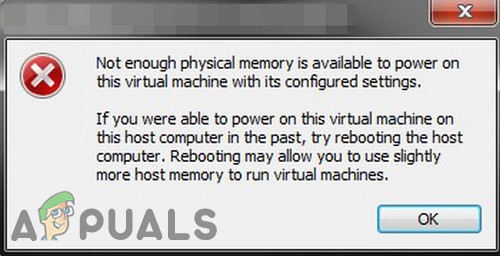
Что вызывает ошибку «Недостаточно физической памяти» в VMware?
Прежде чем приступить к решению, приведенному ниже, убедитесь, что в вашей системе достаточно оперативной памяти для запуска VMware. Если нет, то добавьте больше памяти в вашу систему и установите размер файла подкачки не менее 16 ГБ.
1. Используйте безопасный режим или чистую загрузку Windows
Могут быть приложения, которые могут мешать нормальной работе VMware, особенно другие приложения виртуальной среды, такие как Virtual Box и т. Д. Чтобы исключить это, используйте встроенный безопасный режим Windows или чистую загрузку Windows.
- Чистая загрузка Windows или загрузка Windows в безопасном режиме.
- Запустите VMware, чтобы проверить, работает ли он без проблем.
Если VMware работает нормально в среде чистой загрузки или в безопасном режиме, попробуйте найти конфликтующее приложение и попытаться решить проблему между приложениями.
2. Удалите конфликтующее обновление Windows
Microsoft выпускает обновления для своих продуктов для улучшения функций и исправления лазеек. Но у Microsoft есть известная история выпуска обновлений с ошибками. Если ошибка VMware из-за недостатка физической памяти начала возникать сразу после обновления Windows, то удаление этого обновления может помочь нам.
Предупреждение: отключение обновления не рекомендуется, так как это может стать угрозой безопасности; действовать на свой страх и риск.
- Нажмите клавишу Windows, затем введите «Настройки» и в появившемся списке нажмите «Настройки».Открыть настройки в Windows Search
- Теперь нажмите «Обновление и безопасность».Откройте «Обновление и безопасность» в настройках Windows
- Теперь нажмите на Центр обновления Windows, а затем на Просмотр истории обновлений.Просмотреть историю обновлений Windows
- Нажмите Удалить обновления, чтобы удалить последние обновления из вашей системы.Удалить обновления в истории обновлений
- Теперь выберите обновление, которое, по вашему мнению, создает проблему, нажмите «Удалить» и следуйте инструкциям на экране, чтобы завершить процесс удаления.
- Перезагрузите систему, а затем проверьте, нормально ли начал работать VMware.
Помните, что вы должны удалить последние обновления Windows по одному и проверять VMware, пока не найдете проблемное обновление. После удаления проблемного обновления переустановите другие обновления и скрывайте это конкретное обновление, пока проблема не будет решена Microsoft или VMware.
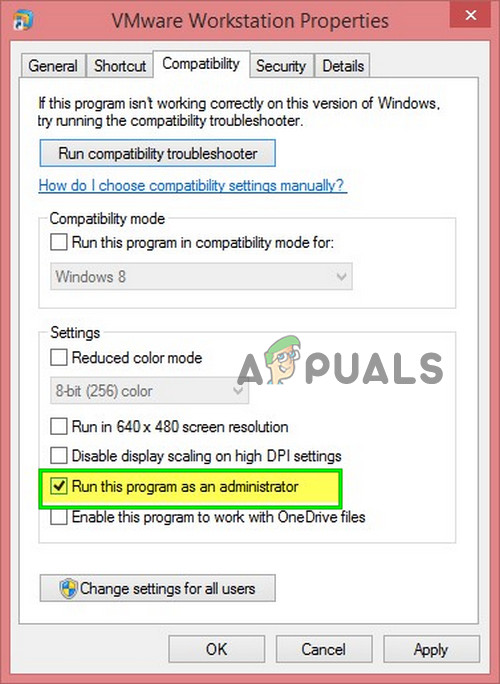
3. Запустите VMware от имени администратора
VMware необходим неограниченный доступ к различным системным файлам, сервисам и ресурсам. Если безопасность Windows ограничивает доступ VMware к определенным файлам, службам и ресурсам, то VMware выдаст ошибку «Недостаточно физической памяти». В этом случае запуск VMware с правами администратора может решить проблему.
- Выключите VMware.
- Нажмите клавишу Windows и введите VMware Workstation.
- Щелкните правой кнопкой мыши VMware Workstation и выберите «Открыть местоположение файла».
- Щелкните правой кнопкой мыши значок VMware Workstation и выберите «Свойства».
- Затем перейдите на вкладку «Совместимость» и установите флажок «Запускать эту программу от имени администратора».Проверьте Запуск от имени администратора
- Нажмите Применить, а затем ОК.
- Теперь запустите VMware Workstation, чтобы проверить, работает ли он нормально без каких-либо проблем.
4. Обновите VMware до последней сборки
Обычно, когда доступно обновление, пользователи получают приглашение при запуске VMware. Пользователи также могут использовать пользовательский интерфейс рабочей станции и выбрать «Справка»> «Обновления программного обеспечения». Но если у вас возникли проблемы с использованием VMware, выполните следующие действия.

- Откройте веб-браузер вашей системы и перейдите к Официальная страница загрузки VMware Workstation,
- Теперь нажмите Download Now согласно вашей ОС.Загрузите последнюю версию VMware Workstation
- Ознакомьтесь с лицензионным соглашением с конечным пользователем и нажмите «Принять», чтобы принять лицензионное соглашение.
- Нажмите Загрузить сейчас и дождитесь завершения процесса загрузки.
- Затем щелкните правой кнопкой мыши загруженный файл и выберите «Запуск от имени администратора».
- Следуйте инструкциям на экране для завершения процесса установки.
- Затем запустите VMware, чтобы убедиться, что в нем недостаточно физической памяти.
5. Измените настройки VMware на Оптимальные
Настройки VMware позволяют пользователю настроить систему по своему вкусу. Но во время этого процесса пользователи иногда устанавливают неоптимальные настройки VMware, что в конечном итоге приводит к тому, что VMware выдает ошибку нехватки физической памяти.
- Выключите гостевую ОС.
- Запустите VMware Workstation, затем нажмите «Изменить» и выберите «Настройки».
- Теперь в левой части окна «Настройки» нажмите «Память».
- Поместить всю память виртуальной машины в зарезервированную хост-память: этот параметр следует выбирать, если у вас большая память
- Разрешить замену большей части памяти виртуальной машины: этот параметр следует выбирать, если у вас немного больше памяти и вы хотите, чтобы виртуальная машина работала более плавно.
- Разрешить обмен некоторой памяти виртуальной машины: этот параметр следует выбирать, если у вас мало памяти.
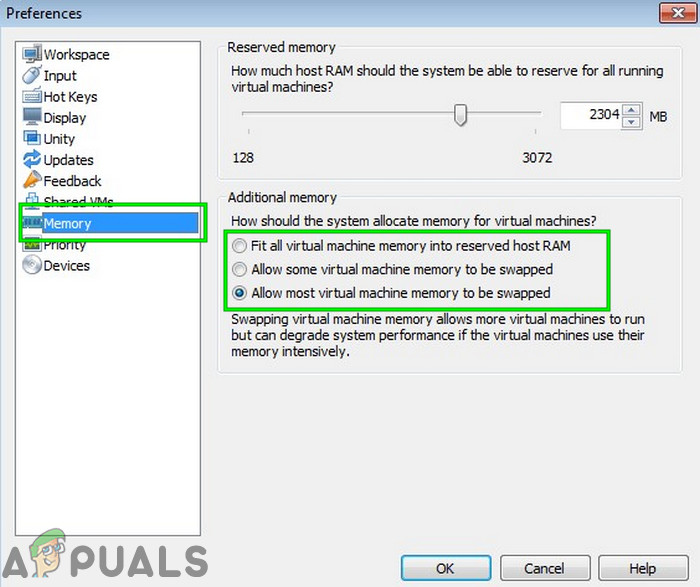
Включите параметр «Разрешить обмен большей части памяти виртуальной машины»
В данном сценарии вы должны выбрать второй или третий вариант в соответствии с вашим состоянием, но мы рекомендуем использовать третий вариант.
6. Измените файл config.ini
Если до сих пор у вас ничего не получалось, проблема может быть решена путем добавления или изменения файла конфигурации, чтобы ограничить использование VMware Workstation в процентах от доступной оперативной памяти хоста. Это гарантирует, что виртуальная машина будет использовать только 75% оперативной памяти хоста.
- Завершите работу всех гостевых операционных систем и закройте рабочую станцию VMware.
- Перейдите по следующему пути
C: ProgramData VMware VMware Workstation.
и откройте файл config.ini. Если его там нет, создайте его.
- Прокрутите до конца файла и добавьте туда следующую строку:
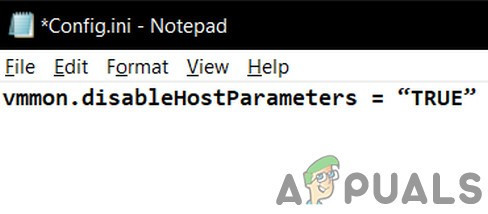
vmmon.disableHostParameters = «ИСТИНА».Изменить файл Config.ini
Затем сохраните файл и перезагрузите систему.
-
После перезапуска системы щелкните правой кнопкой мыши значок VMware на рабочем столе и выберите «Запуск от имени администратора».
Если у вас по-прежнему возникают проблемы с работой гостевой ОС, то вам может помочь создание новой виртуальной машины с правильным объемом памяти и последующее подключение существующего жесткого диска к новой виртуальной машине.
Читайте также: