
Степень ассоциативности кэш памяти как узнать
Кэш-память играет важную роль. Без нее от высокой тактовой частоты процессора не было бы никакого проку. Кэш позволяет использовать в компьютере любую, даже самую "медленную" оперативную память, без ощутимого ущерба для его производительности.
О том, что такое кэш-память процессора, как она работает и какое влияние оказывает на быстродействие компьютера, читатель узнает из этой статьи.
Содержание статьи
Что такое кэш-память процессора
Решая любую задачу, процессор компьютера получает из оперативной памяти необходимые блоки информации. Обработав их, он записывает в память результаты вычислений и получает для обработки следующие блоки. Это продолжается, пока задача не будет выполнена.
Все упомянутые операции производятся на очень высокой скорости. Однако, даже самая быстрая оперативная память работает медленнее любого "неторопливого" процессора. Каждое считывание из нее информации и обратная ее запись отнимают много времени. В среднем, скорость работы оперативной памяти в 16 – 17 раз ниже скорости процессора.
Не смотря на такой дисбаланс, процессор не простаивает и не ожидает каждый раз, когда оперативная память "выдает" или "принимает" данные. Он почти всегда работает на максимальной скорости. И все благодаря наличию у него кэш-памяти.
Кэш-память процессора – это небольшая, но очень быстрая память. Она встроена в процессор и является своеобразным буфером, сглаживающим перебои в обмене данными с более медленной оперативной памятью. Кэш-память часто называют сверхоперативной памятью.
Кэш нужен не только для выравнивания дисбаланса скорости. Процессор обрабатывает данные более мелкими порциями, чем те, в которых они хранятся в оперативной памяти. Поэтому кэш-память играет еще и роль своеобразного места для "перепаковки" и временного хранения информации перед ее передачей процессору, а также возвращением результатов обработки в оперативную память.
Устройство кэш-памяти процессора
Система кэш-памяти процессора состоит из двух блоков - контроллера кэш-памяти и собственно самой кэш-памяти.
Контроллер кэш памяти
Контроллер кэш памяти – это устройство, управляющее содержанием кэша, получением необходимой информации из оперативной памяти, передачей ее процессору, а также возвращением в оперативную память результатов вычислений.
Когда ядро процессора обращается к контроллеру за какими-то данными, тот проверяет, есть ли эти данные в кэш-памяти. Если это так, ядру моментально отдается информация из кэша (происходит так называемое кэш-попадание).
В противном случае ядру приходится ожидать поступления данных из медленной оперативной памяти. Ситуация, когда в кэше не оказывается нужных данных, называется кэш-промахом.
Задача контроллера – сделать так, чтобы кэш-промахи происходили как можно реже, а в идеале – чтобы их не было вообще.
Размер кэша процессора по сравнению с размером оперативной памяти несоизмеримо мал. В нем может находиться лишь копия крошечной части данных, хранимых в оперативной памяти. Но, не смотря на это, контроллер допускает кэш-промахи не часто. Эффективность его работы определяется несколькими факторами:
• размером и структурой кэш-памяти (чем больше ресурсов имеет в своем распоряжении контроллер, тем ниже вероятность кэш-промаха);
• эффективностью алгоритмов, по которым контроллер определяет, какая именно информация понадобится процессору в следующий момент времени;
• сложностью и количеством задач, одновременно решаемых процессором. Чем сложнее задачи и чем их больше, тем чаще "ошибается" контроллер.
Кэш-память процессора
Кэш-память процессора изготавливают в виде микросхем статической памяти (англ. Static Random Access Memory, сокращенно - SRAM). По сравнению с другими типами памяти, статическая память обладает очень высокой скоростью работы.

Впервые кэш размером 8 KB был встроен в процессор Intel i486 в 1989 г.
Однако, эта скорость зависит также от объема конкретной микросхемы. Чем значительней объем микросхемы, тем сложнее обеспечить высокую скорость ее работы.
Учитывая указанную особенность, кэш-память процессора изготовляют в виде нескольких небольших блоков, называемых уровнями. В большинстве процессоров используется трехуровневая система кэша:
• Кэш-память первого уровня или L1 (от англ. Level - уровень) – очень маленькая, но самая быстрая и наиболее важная микросхема памяти. Ни в одном процессоре ее объем не превышает нескольких десятков килобайт. Работает она без каких-либо задержек. В ней содержатся данные, которые чаще всего используются процессором.
Количество микросхем памяти L1 в процессоре, как правило, равно количеству его ядер. Каждое ядро имеет доступ только к своей микросхеме L1.
• Кэш-память второго уровня (L2) немного медленнее кэш-памяти L1, но и объем ее более существенный (несколько сотен килобайт). Служит она для временного хранения важной информации, вероятность запроса которой ниже, чем у информации, находящейся в L1.
• Кэш-память третьего уровня (L3) – еще более объемная, но и более медленная схема памяти. Тем не менее, она значительно быстрее оперативной памяти. Ее размер может достигать нескольких десятков мегабайт. В отличие от L1 и L2, она является общей для всех ядер процессора.
Уровень L3 служит для временного хранения важных данных с относительно низкой вероятностью запроса, а также для обеспечения взаимодействия ядер процессора между собой.
Встречаются также процессоры с двухуровневой кэш-памятью. В них L2 совмещает в себе функции L2 и L3.
Влияние кэш-памяти процессора на быстродействие компьютера
При выполнении запроса на предоставление данных ядру, контроллер памяти ищет их сначала в кэше первого уровня, затем - в кэше второго и третьего уровней.
По статистике, кэш-память первого уровня любого современного процессора обеспечивает до 90 % кэш-попаданий. Второй и третий уровни - еще 90% от того, что осталось. И только около 1 % всех запросов процессора заканчиваются кэш-промахами.
Указанные показатели касаются простых задач. С повышением нагрузки на процессор число кэш-промахов увеличивается.
Эффективность кэш-памяти процессора сводит к минимуму влияние скорости оперативной памяти на быстродействие компьютера. Например, компьютер одинаково хорошо будет работать с оперативной памятью 1066 МГц и 2400 МГц. При прочих равных условиях разница производительности в большинстве приложений не превысит 5%.
Пытаясь оценить эффективность кэш-памяти, пользователи чаще всего ищут ответы на следующие вопросы:
Какая структура кэш-памяти лучше: двух- или трехуровневая?
Трехуровневая кэш-память более эффективна.
Чтобы определить, как сильно L3 влияет на работу процессора, сайтом Tom’s Hardware был проведен эксперимент. Заключался он в замере производительности процессоров Athlon II X4 и Phenom II X4. Оба процессора оснащены одинаковыми ядрами. Первый отличается от второго лишь отсутствием кэш-памяти L3 и более низкой тактовой частотой.
Приведя частоты обеих процессоров к одинаковому показателю, было установлено, что наличие кэш-памяти L3 повышает производительность процессора Phenom на 5,8 %. Но это средний показатель. В одних приложениях он был почти равен нулю (офисные программы), в других – достигал 8% и даже больше (компьютерные 3D игры, архиваторы и др.).
Как влияет размер кэша на производительность процессора?
Оценивая размер кэш-памяти, нужно учитывать характеристики процессора и круг решаемых им задач.
Кэш-память двуядерного процессора редко превышает 3 MB. Тем более, если его тактовая частота ниже 3 Ггц. Производители прекрасно понимают, что дальнейшее увеличение размера кэша такого процессора не принесет прироста производительности, зато существенно повысит его стоимость.
В процессорах Intel алгоритм наполнения кэш-памяти построен по так называемой инклюзивной схеме, когда содержимое кэшей верхнего уровня (L1, L2) полностью или частично дублируется в кэше нижнего уровня (L3). Это в определенной степени уменьшает полезный объем его пространства. С другой стороны, инклюзивная схема позитивно сказывается на взаимодействии ядер процессора между собой.

Объем внутренней кэш-памяти некоторых моделей серверных процессоров Intel Xeon
составляет 37,5 MB
В целом же, эксперименты свидетельствуют, что в среднестатистическом "домашнем" процессоре влияние размера кэша на производительность находится в пределах 10 %, и его вполне можно компенсировать, например, высокой частотой.
Эффект от большого кэша наиболее ощутим при использовании архиваторов, в 3D играх, во время кодирования видео. В "не тяжелых" же приложениях разница стремится к нулю (офисные программы, интернет-серфинг, работа с фотографиями, прослушивание музыки и др.).
Многоядерные процессоры с большим кэшем необходимы на компьютерах, предназначенных для выполнения многопоточных приложений, одновременного решения нескольких сложных задач.
Особенно актуально это для серверов с высокой посещаемостью. В некоторых высоконагружаемых серверах и суперкомпьютерах предусмотрена даже установка кэш-памяти четвертого уровня (L4). Изготавливается она в виде отдельных микросхем, подключаемых к материнской плате.
Как узнать размер кэш-памяти процессора?

Существуют специальные программы, предоставляющие подробную информацию о процессоре компьютера, в том числе и о его кэш-памяти. Одной из них является программа CPU-Z.
Программа не требует установки. После ее запуска нужно перейти на вкладку "Caches" (см. изображение).
На примере видно, что проверяемый процессор оснащен трехуровневой кэш-памятью. Размер кэша L3 у него составляет 3 MB, L2 – 512 KB (256x2), L1 – 128 KB (32x2+32x2).
Можно ли как-то увеличить кэш-память процессора?
Как уже было сказано в одном из предыдущих пунктов, возможность увеличения кэш-памяти процессора предусмотрена в некоторых серверах и суперкомпьютерах, путем ее подключения к материнской плате.
В домашних же или офисных компьютерах такая возможность отсутствует. Кэш-память является внутренней неотъемлемой частью процессора, имеет очень маленькие физические размеры и не подлежит замене. А на обычных материнских платах нет разъемов для подключения дополнительной кэш-памяти.
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная памятьАрхитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Ассоциативная память
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
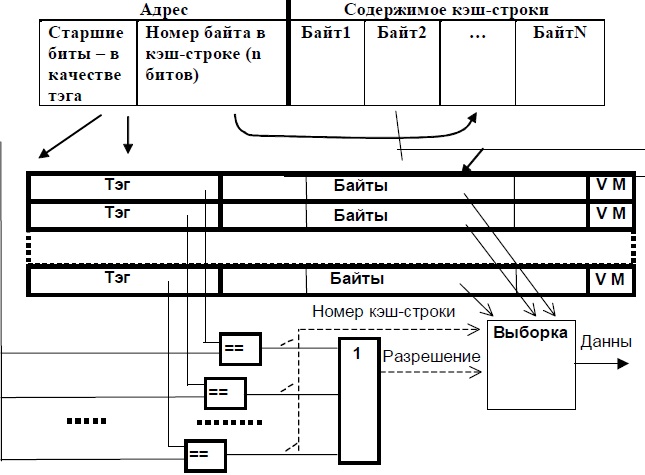
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования ( LRU — Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" ( FIFO — First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти ( ассоциативная память ) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
Кэш-память (КП), или кэш, представляет собой организованную в виде ассоциативного запоминающего устройства (АЗУ) быстродействующую буферную память ограниченного объема, которая располагается между регистрами процессора и относительно медленной основной памятью и хранит наиболее часто используемую информацию совместно с ее признаками (тегами), в качестве которых выступает часть адресного кода.
В процессе работы отдельные блоки информации копируются из основной памяти в кэш - память . При обращении процессора за командой или данными сначала проверяется их наличие в КП. Если необходимая информация находится в кэше, она быстро извлекается. Это кэш-попадание. Если необходимая информация в КП отсутствует ( кэш-промах ), то она выбирается из основной памяти, передается в микропроцессор и одновременно заносится в кэш - память . Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи.
Зададимся вопросом: "А как определить наиболее часто используемую информацию? Неужели сначала кто-то анализирует ход выполнения программы, определяет, какие команды и данные чаще используются, а потом, при следующем запуске программы, эти данные переписываются в кэш - память и уже тогда программа выполняется эффективно?" Конечно нет. Хотя в современных микропроцессорах имеется определенный механизм, который позволяет в некоторой степени реализовать этот принцип. Но в основном, конечно, кэш - память сама отбирает информацию, которая чаще всего используется. Рассмотрим, как это происходит.
Механизм сохранения информации в кэш-памяти
При включении микропроцессора в работу вся информация в его кэш-памяти недостоверна.
При обращении к памяти микропроцессор, как уже отмечалось, сначала проверяет, не содержится ли искомая информация в кэш-памяти.
Для этого сформированный им физический адрес сравнивается с адресами ячеек памяти, которые были ранее кэшированы из ОЗУ в КП.
При первом обращении такой информации в кэш -памяти, естественно, нет, и это соответствует кэш-промаху. Тогда микропроцессор проводит обращение к оперативной памяти, извлекает нужную информацию, использует ее в своей работе, но одновременно записывает эту информацию в кэш .
Если бы в кэш - память заносилась только востребованная микропроцессором в данный момент информация , то, скорее всего, при следующем обращении вновь произошел бы кэш-промах: вряд ли следующее обращение произойдет к той же самой команде или к тому же самому операнду. Кэш-попадания происходили бы лишь после того, как в КП накопится достаточно большой фрагмент программы, содержащий некоторые циклические участки кода, или фрагмент данных, подлежащих повторной обработке. Для того чтобы уже следующее обращение к КП приводило как можно чаще к кэш-попаданиям, передача из оперативной памяти в кэш - память происходит не теми порциями (байтами или словами), которые востребованы микропроцессором в данном обращении, а так называемыми строками. То есть кэш - память и оперативная память с точки зрения кэширования организуются в виде строк. Длина строки превышает максимально возможную длину востребованных микропроцессором данных. Обычно она составляет от 16 до 64 байт и выровнена в памяти по границе соответствующего раздела (рис. 4.1).
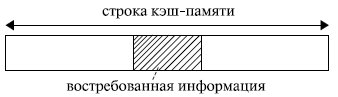
Рис. 4.1. Организация обмена между оперативной и кэш-памятью
Высокий процент кэш-попаданий в этом случае обеспечивается благодаря тому, что в большинстве случаев программы обращаются к ячейкам памяти, расположенным вблизи от ранее использованных. Это свойство, называемое принципом локальности ссылок, обеспечивает эффективность использования КП. Оно подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным).
Например, микропроцессору для своей работы потребовалось 2 байта информации. Если строка имеет длину 16 байт , то в кэш переписываются не только нужные 2 байта, но и некоторое их окружение. Когда микропроцессор обращается за новой информацией, в силу локальности ссылок, скорее всего, обращение произойдет по соседнему адресу. Затем опять по соседнему, опять по соседнему и т. д. Таким образом, ряд следующих обращений будет происходить непосредственно к кэш -памяти, минуя оперативную память (кэш-попадания). Когда очередной сформированный микропроцессором физический адрес выйдет за пределы строки кэш -памяти (произойдет кэш-промах ), будет выполнена подкачка в кэш новой строки, и вновь ряд последующих обращений вызовет кэш-попадания.
Чем длиннее используемая при обмене между оперативной и кэшпамятью строка, тем больше вероятность того, что следующее обращение произойдет в пределах этой строки. Но в то же время чем длиннее строка, тем дольше она будет перекачиваться из оперативной памяти в кэш . И если очередная команда окажется командой перехода или выборка данных начнется из нового массива, то есть следующее обращение произойдет не по соседнему адресу, то время, затраченное на передачу длинной строки, будет использовано напрасно. Поэтому при выборе длины строки должен быть разумный компромисс между соотношением времени обращения к оперативной и кэш -памяти и вероятностью достаточно удаленного перехода от текущего адреса при выполнении программы. Обычно длина строки определяется в результате моделирования аппаратно-программной структуры системы .
После того как в КП накопится достаточно большой объем информации, увеличивается вероятность того, что формирование очередного адреса приведет к кэш-попаданию. Особенно велика вероятность этого при выполнении циклических участков программы.
Старая информация по возможности сохраняется в кэш -памяти. Ее замена на новую определяется емкостью, организацией и стратегией обновления кэша.
Типы кэш-памяти
Если каждая строка ОЗУ имеет только одно фиксированное место , на котором она может находиться в кэш -памяти, то такая кэш - память называется памятью с прямым отображением.
Предположим, что ОЗУ состоит из 1000 строк с номерами от 0 до 999, а кэш - память имеет емкость только 100 строк. В кэш -памяти с прямым отображением строки ОЗУ с номерами 0, 100, 200, . 900 могут сохраняться только в строке 0 КП и нигде иначе, строки 1, 101, 201, …, 901
ОЗУ - в строке 1 КП, строки ОЗУ с номерами 99, 199, …, 999 сохраняются в строке 99 кэш -памяти (рис. 4.2). Такая организация кэш -памяти обеспечивает быстрый поиск в ней нужной информации: необходимо проверить ее наличие только в одном месте. Однако емкость КП при этом используется не в полной мере: несмотря на то, что часть кэш -памяти может быть не заполнена, будет происходить вытеснение из нее полезной информации при последовательных обращениях, например, к строкам 101, 301, 101 ОЗУ .
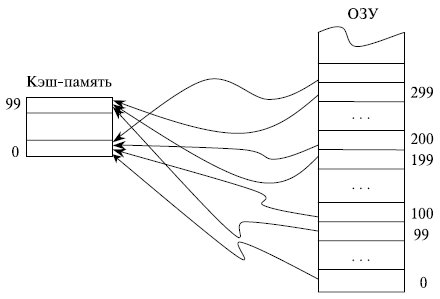
Рис. 4.2. Принцип организации кэш-памяти с прямым отображением
Кэш - память называется полностью ассоциативной, если каждая строка ОЗУ может располагаться в любом месте кэш -памяти.
В полностью ассоциативной кэш -памяти максимально используется весь ее объем: вытеснение сохраненной в КП информации проводится лишь после ее полного заполнения. Однако поиск в кэш -памяти, организованной подобным образом, представляет собой трудную задачу.
Компромиссом между этими двумя способами организации кэш -памяти служит множественно-ассоциативная КП, в которой каждая строка ОЗУ может находиться по ограниченному множеству мест в кэш -памяти.
При необходимости замещения информации в кэш -памяти на новую используется несколько стратегий замещения. Наиболее известными среди них являются:
- LRU - замещается строка, к которой дольше всего не было обращений;
- FIFO - замещается самая давняя по пребыванию в кэш-памяти строка;
- Random - замещение проходит случайным образом.
Последний вариант, существенно экономя аппаратные средства по сравнению с другими подходами, в ряде случаев обеспечивает и более эффективное использование кэш -памяти. Предположим, например, что КП имеет объем 4 строки, а некоторый циклический участок программы имеет длину 5 строк. В этом случае при стратегиях LRU и FIFO кэш - память окажется фактически бесполезной ввиду отсутствия кэш -попаданий. В то же время при использовании стратегии случайного замещения информации часть обращений к КП приведет к кэш -попаданиям.
Некоторые эвристические оценки вероятности кэш -промаха при разных стратегиях замещения (в процентах) представлены в табл. 4.1.
Анализ таблицы показывает, что:
- увеличением емкости кэша, естественно, уменьшается вероятность кэш-промаха, но даже при незначительной на сегодняшний день емкости кэш-памяти в 16 Кбайт около 95 % обращений происходят к КП, минуя оперативную память;
- чем больше степень ассоциативности кэш-памяти, тем больше вероятность кэш-попадания за счет более полного заполнения КП (время поиска информации в КП в данном анализе не учитывается);
- механизм LRU обеспечивает более высокую вероятность кэш-попадания по сравнению с механизмом случайного замещения Random , однако этот выигрыш не очень значителен.
Соответствие между данными в оперативной памяти и в кэш -памяти обеспечивается внесением изменений в те области ОЗУ , для которых данные в кэш -памяти подверглись изменениям. Существует два основных способа реализации этих действий: со сквозной записью ( writethrough ) и с обратной записью ( write-back ).
При считывании оба способа работают идентично. При записи кэширование со сквозной записью обновляет основную память параллельно с обновлением информации в КП. Это несколько снижает быстродействие системы, так как микропроцессор впоследствии может вновь обратиться по этому же адресу для записи информации, и предыдущая пересылка строки кэш -памяти в ОЗУ окажется бесполезной. Однако при таком подходе содержимое соответствующих друг другу строк ОЗУ и КП всегда идентично. Это играет большую роль в мультипроцессорных системах с общей оперативной памятью.
Кэширование с обратной записью модифицирует строку ОЗУ лишь при вытеснении строки кэш -памяти, например, в случае необходимости освобождения места для записи новой строки из ОЗУ в уже заполненную КП. Операции обратной записи также инициируются механизмом поддержания согласованности кэш -памяти при работе мультипроцессорной системы с общей оперативной памятью.
Промежуточное положение между этими подходами занимает способ, при котором все строки, предназначенные для передачи из КП в ОЗУ , предварительно накапливаются в некотором буфере. Передача осуществляется либо при вытеснении строки, как в случае кэширования с обратной записью, либо при необходимости согласования кэш -памяти нескольких микропроцессоров в мультипроцессорной системе, либо при заполнении буфера. Такая передача проводится в пакетном режиме, что более эффективно, чем передача отдельной строки.
Читайте также: