
Correctable ecc logging limit reached assert ошибка в vmware
На терминале работает около 50 человек, но BSODы происходили всегда в часы наименьшей нагрузки (рано утром или поздно вечером, когда активно 5-10 человек, не более).
Работают с офисом, акробатом, и браузером (ie 11, chrome) звук, видео. Как правило проблема возникает после длительной работы, когда висит уже много браузерных процессов (вкладок) с видео и анимацией.
Принтеров и сканеров к терминалу не подключено, только проброшены клиентские.
Судя по анализу дампа проблема в dxgkrnl.sys (DirectX Graphics Kernel)
SYSTEM_SERVICE_EXCEPTION (3b)
This error has been linked to excessive paged pool usage and may occur due to user-mode graphics drivers crossing over and passing bad data to the kernel code.
В данный момент видеодрайвер VMware SVGA 3D (02.12.2014 8.14.1.6).
В настройках VMware Video Card total video memory стоит 4, чекбокс Enable 3D Support снят.
Может имеет смысл увеличить видео память до 128? Или в терминальном режиме она не используется?
Есть ли более новые версии видеодрайвера? Может быть вообще его удалить и поставить стандартный виндовый?
Use !analyze -v to get detailed debugging information.
Probably caused by : dxgkrnl.sys ( dxgkrnl!DxgkQueryAdapterInfo+500 )
SYSTEM_SERVICE_EXCEPTION (3b)
An exception happened while executing a system service routine.
Arguments:
Arg1: 00000000c0000005, Exception code that caused the bugcheck
Arg2: fffff8000155acd0, Address of the instruction which caused the bugcheck
Arg3: ffffd00027031f70, Address of the context record for the exception that caused the bugcheck
Arg4: 0000000000000000, zero.
EXCEPTION_CODE: (NTSTATUS) 0xc0000005 - <Unable to get error code text>
ANALYSIS_VERSION: 6.3.9600.17336 (debuggers(dbg).150226-1500) amd64fre
LAST_CONTROL_TRANSFER: from fffff802dffd44b3 to fffff8000155acd0
STACK_COMMAND: .cxr 0xffffd00027031f70 ; kb
Да. в терминальном режиме видеопамять и сама видеокарта не используются. совсем.
видеодрайвер терминальному серверу не нужен. можно смело удалить.
Есть пара варнингов:
официальная позиция VMware - никак, есть сторонние утилиты, надо пробовать. Я пробовал, ничего не получилось, но вдруг повезет

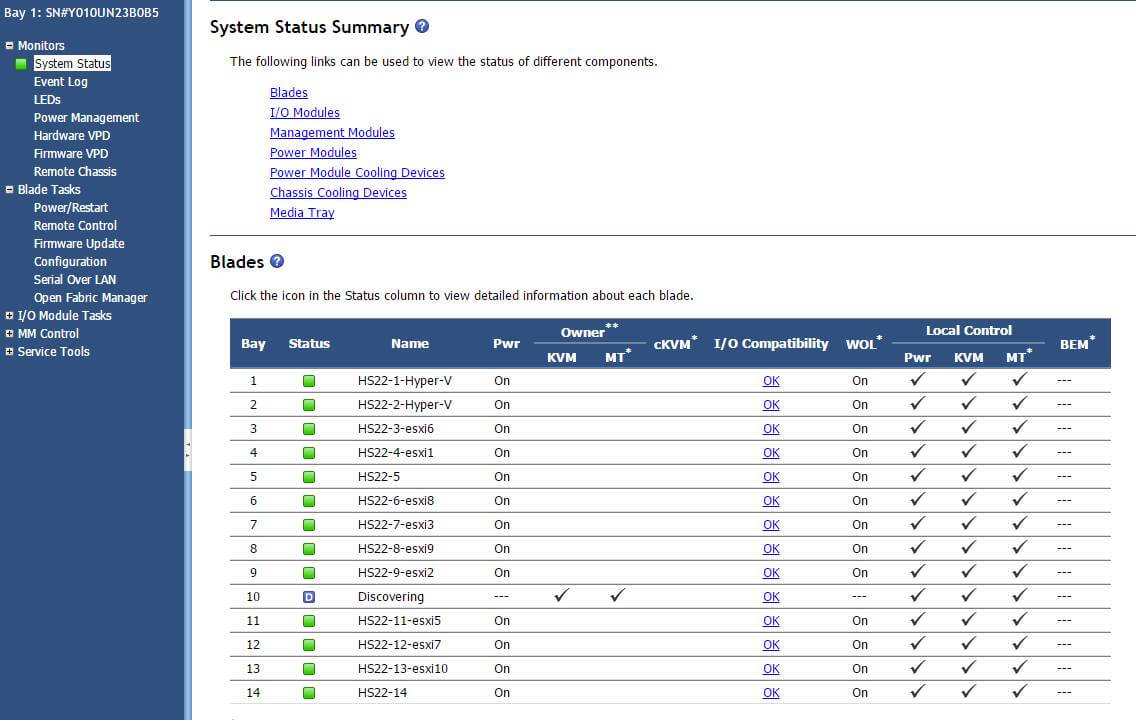
Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.

В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ "DRAM Errors in the Wild: A Large-Scale Field Study" посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.

(на фото, кстати, подлинный вид серверной платформы Google, именно из таких «кирпичиков» собираются гугловские кластеры, размером в многие тысячи узлов, впрочем, про них тут уже писалось)
Результаты такого анализа и представлены в опубликованной работе. И результаты во многом удивительные, заставляющие по-иному смотреть на вопросы надежности и привычные допущения в области надежности серверного оборудования.
Исследование со всей убедительностью продемонстрировало, что влияние отказов в оперативной памяти существенно недооценивается, что отказы оперативной памяти случаются куда чаще, чем до этого это было принято считать, наконец, многие допущения, например что оперативная память практически не «стареет», как «стареют», повышая вероятность отказов, компоненты с движущимися частями, такие как, например, жесткие диски, или что перегрев губительно сказывается на работе ОЗУ, являются неверными, и требуют пересмотра.
Несомненно тот факт, что в последние несколько лет, в связи со сравнительным удешевлением DRAM, и широким распространением систем серверной виртуализации, крайне охочих до объемов памяти, концентрация в одной серверной системе все больших и больших объемов ОЗУ, повышает и требования к ее надежности.
В сравнении с ранее опубликованным исследованием, работа группы Шрёдер резко повысила «ожидания» сбоев. Так, они оценили события отказов в 25-70 тысяч сбоев на миллиард часов работы сервера, что почти в пятнадцать раз превышает более раннюю оценку, сделанную на меньшей популяции.
С отказами в результате неисправимых (uncorrectable, неисправленных ECC или Chipkill) встретились 1,3% серверов в год, или около 0,22% DIMM.
Системы, использующие «многобитные» механизмы, такие как Chipkill, имели число отказов в 4-10 раз меньше, по сравнению с обычным ECC.
Другие интересные выводы, сделанные в опубликованной работе это:
Рабочая температура, и ее повышение крайне мало коррелирует с вероятностью сбоя в DRAM. Это еще один факт, который указывает, что бытующее до сих пор в индустрии мнение о губительности повышенной температуры на полупроводники и компьютерное оборудование (мнение, основанное на исследовании 80-х годов) на сегодняшний день следует радикально пересмотреть. Это еще одно подтверждение этому факту, который уже был установлен, например в работе о жестких дисках. Парадоксальным образом там было установлено, что наименьшее количество отказов HDD наблюдалось при температурах в районе 40-45 градусов, а ее понижение количество отказов увеличивало (!).
В случае DRAM кореляция между температурой (в наблюдавшемся диапазоне около 20 градусов между самой низкой и самой высокой) и отказами была крайне незначительной.

Однако существенно коррелировали отказы с загрузкой памяти и интенсивностью обмена с ней (отчасти высокая загрузка памяти влияет и на ее температуру, конечно, но не всегда). Вполне вероятно, что интенсивный обмен и большой относительный объем заполненных данными памяти значительно повышает вероятность быстрого обнаружения сбоя.

Было установлено, что вероятность получить повторный сбой в уже ранее сбоившем модуле памяти в сотни раз выше, по сравнению с не сбоившем ранее. Это может быть вызвано как наличием плохо выявляемого технологического брака, так и тем, что отказ, например пробой заряженной частицей космических лучей, не проходит для памяти бесследно, даже если ошибка была скорректирована ECC.
70-80% случаях, когда регистрировалась неисправимая ошибка в модуле памяти, это модуль уже имел исправимый ECC или Chipkill отказ в этом или предыдущем месяце.

Было установлено, что сравнительно новые модули, выполненные с более высокой плотностью и более тонкими техпроцессами, не показывают более высокого уровня отказов. По-видимому пока в технологии DRAM технологический предел, близ которого начинаются проблемы с надежностью, пока не достигнут. В наблюдаемом парке модулей было примерно шесть разных типов и поколений памяти (DDR1, DDR2 и FBDIMM разных типов), и корреляции между высокой плотностью и числом отказов и сбоев выявлено не было.
Наконец, с пугающей ясностью был продемонстрирован эффект «старения» в модулях DRAM. Более того, в памяти он проявился куда более явно, чем, напрмер, в HDD, где порог, после которого отказы растут в разы, составил примерно 3-4 года.

Парадоксальным образом статистика демонстрирует увеличивающиеся темпы роста correctable errors с увеличением возраста модулей, но снижающийся темп для Uncorrectable errors, однако скорее всего это просто результат плановой замены памяти в серверах, которые были замечены за сбоями.

Удивительным образом, DRAM, лишенная каких-либо движущихся частей, показывает существенный и продолжающийся рост correctable отказов уже после года-полутора эксплуатации.
Подводя итоги, хотелось бы отметить, что приведенные статистические данные заставляют пересмотреть привычные для многих, основанные на «житейском опыте» принципы построения серверных платформ и эксплуатации датацентров, и позиция «чем холоднее — тем лучше», «память не изнашивается», «если север правильно собран, то он не ломается» и «ECC DRAM — ненужная трата денег, ведь у меня десктоп работает без ECC, и ничего». И чем скорее будут изжиты подобные шапкозакидательские настроения в столь серьезной области, как построение датацентров, тем, в итоге, будет лучше.
А занимающимся темой хочу порекомендовать неизбывный источник сладости, интеллектуального упражнения и пищи для мозгов, как публикации ежегодных конференций группы USENIX, это вам, господа, не маркетинговый булшит, столь привычный нам уже всем, а настоящая серьезная наука, от которой не отмахнешься.
Войти
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
VMWare vCenter: отключаем предупреждение о самоподписанном сертификате
VMWare vCenter: отключаем предупреждение о самоподписанном сертификате | Windows для системных администраторов
При подключении к серверу VMWare vCenter с помощью браузера появляется предупреждение об использовании самоподписанного сертификата, выданного недоверенным центром сертификации. В Firefox и других браузерах это предупреждение убирается простым добавление сайта vCenter в список исключений, в Internet Explorer все несколько сложнее.
SSL сертификаты, устанавливаемые по умолчанию с серверами ESXi и vCenter являются самоподписанными, и, соответственно, другие системы не доверяют им, выдавая предупреждение или блокируя соединение с такими сайтами. Чтобы отключить предупреждение о самоподписанном сертификате, можно добавить самоподписанный сертификат в список доверенных или заменить сертификат на собственный, выданный доверенным центром сертификации. Мы рассмотрим первый вариант, процедура в общем-то достаточно тривиальная, но есть несколько не вполне очевидных моментов.
Итак, при открытии веб страницы сервера vCenter в браузере появляется окно со следующим предупреждением:
There is a problem with this website’s security certificate.The security certificate presented by this website was not issued by a trusted certificate authority.
The security certificate presented by this website was issued for a different website’s address.
Security certificate problems may indicate an attempt to fool you or intercept any data you send to the server.
Нажав на ссылку Continue to this website link (not recommended) , можно перейти на стартовую страницу vCenter. Чтобы скачать сертификат, нажмите на ссылку Download trusted root CA certificates .
Сохраните файл в произвольный каталог. Имя файла download (у файла нет расширения).
Затем меняем расширение файла download на download . zip и распакуем его с помощью встроенного архиватора ( Extract All ).
Внутри содержимого архива cert находиться 2 файла, у одного расширение .0 , у второго . r0 . Изменим расширение файла .0 на .cer .
Осталось добавить данный сертификат корневого CA в список доверенных. Предположим мы хотим, чтобы этому сертификату было доверие только у текущей учетной записи. Откроем консоль certmgr. msc , перейдем в раздел Certificates > Trusted Root Certification Authorities . И в контекстном меню откроем мастер импорта сертификата ( Import ).
Выберем файл сертификата, полученный ранее, и поместим его в хранилище Trusted Root Certification Authorities .
Подтверждаем добавление сертификата.
Новый сертификат с именем CA должен появиться в списке.
Еще раз откроем страницу vCenter в браузере. Предупреждение не должно появиться.
Примечание . При необходимости, чтобы распространить данный сертификат на компьютеры домена, можно воспользоваться возможностями групповой политики (Установка сертификата на компьютеры с помощью GPO).Указанная инструкция применима к vCenter Server Appliance , в случае использования Windows vCenter Server , скачать файл сертфиката таким образом не удастся, т.к. ссылка на загрузку архива с сертификатом будет отсутствовать. Этот файл хранится на сервере vCenter Server (под Windows) в каталоге C:\ProgramData\VMware\SSL\ . (в более старый версиях C:\Programdata\VMware\VMware VirtualCenter\SSL). Сертификат из этого каталога аналогичным образом нужно импортировать на клиенте.
Примечание:
Проблема: Иногда DataStor (Хранилище) все равно после проведенных действий не позволяет добавлять файлы. Замечено на vSphere 6.5 / 6.7
Решение: добавьте вышеуказанный сертификат не только в Доверенные корневые центры сертификации, но и в Личное хранилище сертификатов:



При установке VMware ESXi на SD карту или USB флешку (или при использовании метода загрузки Boot from SAN) в консоли клиента vCenter данный хост будет отображаться с желтым восклицательным значком, а на вкладке Summary выводиться предупреждение:

Предупреждение esx.problem.syslog.nonpersistent означает, что система пишет логи (scratch) на USB устройство и при перезагрузке хоста они не будут сохранены. Таким образом в случае проблем с хостом вы не сможете изучить его логи или предоставить данные в техподдержку VMWare. Чтобы убрать это предупреждение, вам нужно в настройках ESXi хоста изменить путь хранения логов на локальный диск или VMFS хранилище (или настроить syslog сервер).
Эта инструкция для нового HTML5 клиента vSphere 6.7. В предыдущих версиях vSphere все настраивается по аналогии, но могут незначительно отличаться названия пунктов и разделов.
Вы также можете изменить путь к каталогу хранения логов из командной строке PowerCLI:
Читайте также: