
Robots txt закрыть доступ к файлу
Полностью разбираем один из самых важных файлов сайта - robots.txt, ведь от него зависит корректная индексация страниц и продвижение всего сайта в целом.
Закрыть и открыть сайт
Закрыть от индексации сайт
Запрещаем индексацию сайта всем роботам:
Открыть к индексации сайт
Разрешаем всем роботам индексацию сайта:
Директива – это некое указание для поисковых роботов на то, что необходимо индексировать.
Кроме файла robots.txt закрыть или открыть сайт (страницы сайта) можно с помощью специального meta тега robots, однако данный тег не освобождает владельца сайта от необходимости иметь на сервере отдельный файл robot.txt
Директива User-agent
User-agent – самая первая директива, которая позволяет обратиться к роботам поисковых систем. Рядом с ней указывается название поисковой системы или * (звездочка).
* (звездочка) в директиве User-agent позволяет обращаться ко всем поисковым системам сразу.
| Система | Запись в User-agent | Описание |
| GoogleBot | Робот Google | |
| Яндекс | YandexBot | Основной робот Яндекса |
| Яндекс | YandexMobileBot | Мобильный робот Яндекса |
| Яндекс | Yandex | Робот, который будет использовать все другие боты от Яндекса (основной и мобильый) – используется чаще всего. |
| Bing | BingBot | Основной робот от поисковой системы bing.com |
| Mail.ru | Mail.ru | Робот от поисковой системы mail |
| Rambler | StackRambler | Робот от поисковой системы rambler |
В большинстве своих проектов нам достаточно лишь:
Директива Disallow
Директива Disallow – означает запрет к индексации страницы, раздела или файла.
* (звездочка) означает то, что перед нашим названием файла (папки) может стоять все, что угодно.
Директива Allow
Директива Allow – означает допуск к индексации страницы, раздела или файла.
Как открыть к индексации страницу или раздел:
На данном примере мы открыли раздел /uploads.
Как открыть файл из закрытого раздела:
В этом примере мы запрещаем индексировать все страницы, в которых содержится слово bitrix, но разрешаем индексировать страницы, в которых есть и bitrix и jpg, однако все другие страницы со словом bitrix в url адресе, которые не содержат символов jpg будут закрыты.
Директива Host
Директива Host – ранее в ней указывалось главное зеркало, но сейчас данная директива не используется поисковыми системами и ее можно не прописывать в файле robots.txt, т.к. сейчас все роботы смотрят на корректную настройку 301 редиректа, а не на то, что написано в директиве host. Информацию по этому поводу можно прочитать в статье Яндекса. Если вы добавите данную директиву в свой файл robots.txt, то ничего страшного от этого не произойдет, главное не забудьте настроить правильно зеркала.
Директива Sitemap
Sitemap – директива, служащая для указания на xml карту сайта, которая также обязательно должна быть на любом сайте (даже одностраничном). В карте сайта указывается список страниц, которые должны быть проиндексированы поисковой системой.
Директива указывается в самом конце файла robots.txt в виде url-адреса до файла карты сайта .xml
Спецсимволы *, $ в robots.txt
В файле robots.txt при указании путей можно использовать символы * и $ , задавая определенные регулярные выражения.
* означает любую последовательность символов. По-умолчанию к концу каждого правила, описанного в файле роботс тхт, приписывается спецсимвол *
$ данный спецсимвол служит для отмены * на конце.
Примеры:
Disallow /*visit/
Для данного правила:
Disallow /*visit/$
Как проверить robots.txt
Чтобы проверить правильное заполнение файла robots.txt можно воспользоваться сервисом Яндекс.Webmaster, в который уже должен быть добавлен ваш сайт.
На странице Инструменты -> Анализ robots.txt
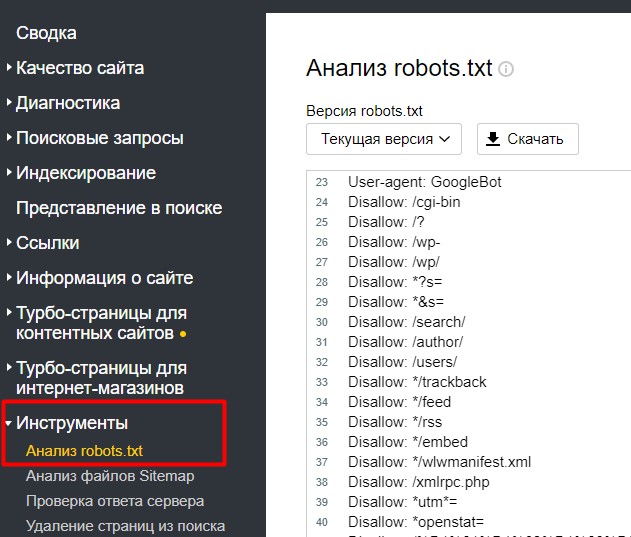
Внизу есть поле для проверки страницы (доступна она для индексации или нет).
Вы можете скопировать интересующий вас url адрес вашего сайта в данную форму и проверить – доступна страница к индексации или нет.
Например, для одного нашего туристического проекта на кириллическом домене «рф» проскакивали адреса на латинице вида cashback.html на конце (это была особенность разработки и системы управления). Эти url-адреса нужно было, во-первых закрыть от индексации, во-вторых настроить 301 редирект.
и вот, что получилось:
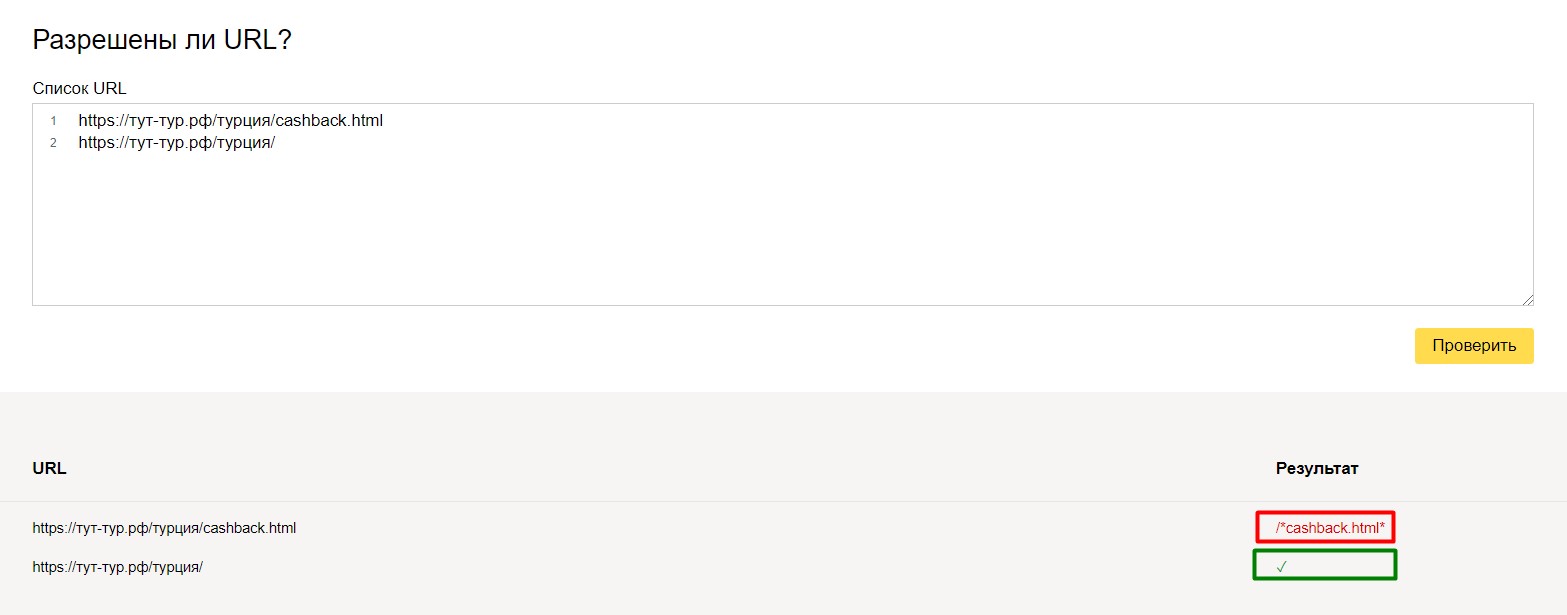
url адрес с cashback.html выдал ошибку (то, что нам и нужно было), а url-адрес с обычным url – проверку прошел. Всего-лишь одной небольшой командой мы избавились от проблемы. И в идеальном случае нужно было бы доработать систему и отфильтровать адреса (эта задача поставлена на будущее), но на данный момент мы отделались «малой кровью», настроив корректно редиректы и установив запрет к индексации.
Для перепроверки, можно производить различные тесты над вашим файлом robots.txt.
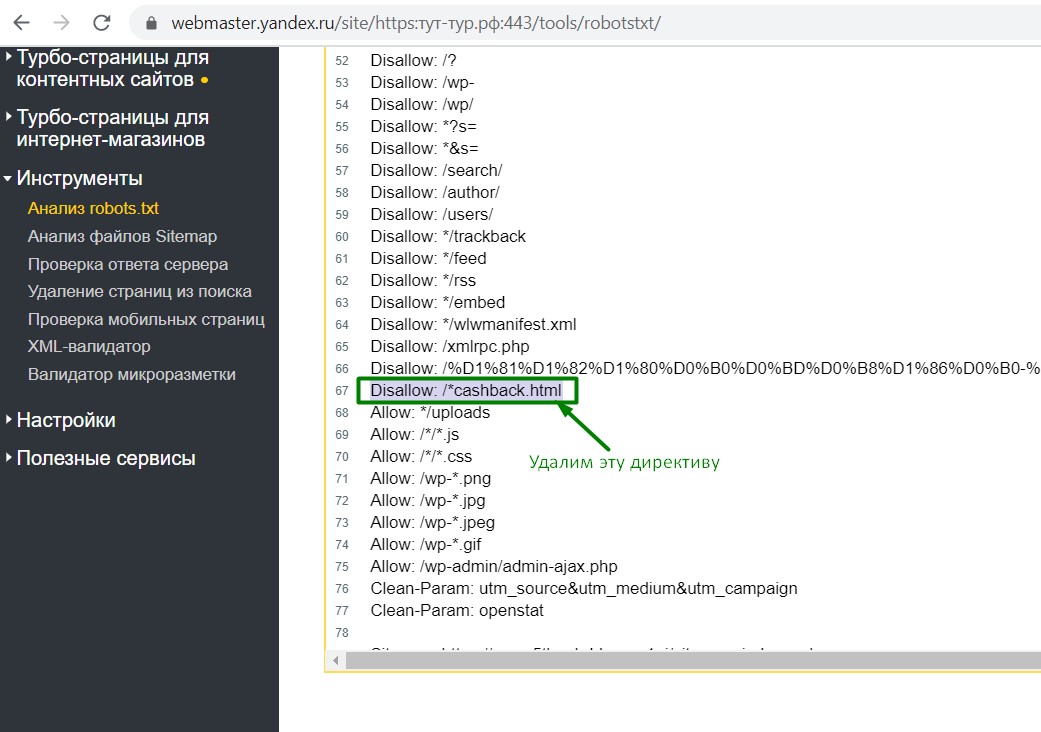
и вот, что у нас получилось:
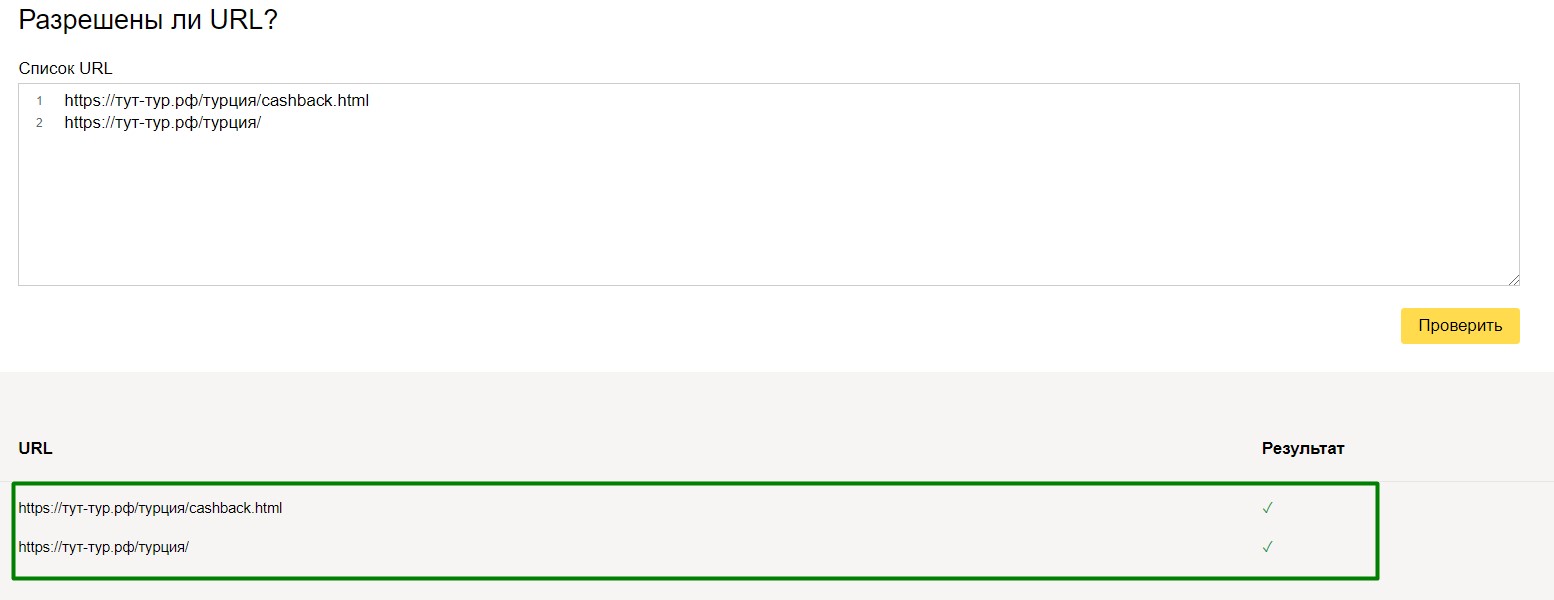
Все страницы доступны к индексации.
Данные методы тестирования применимы как к небольшим, так и к крупным проектам. Особенно, если есть мультиязычная версия и добавлено много правил.
Например, нам нужно, чтобы не индексировалась страница /travelguides/, но индексировалась travelguides/austria/. В этом случае мы создаем такое правило:
Кириллица в файле Robots
Что нужно обязательно закрывать в robots.txt
В файле robots.txt обязательно закрываем дубли страниц (в том числе дубли главной страницы), служебные страницы, неинформативные страницы, «хвосты» платных каналов и рекламы, динамические url, которых нет в структуре сайта.
Динамические страницы можно закрыть с помощью «маски», то есть с помощью шаблона, который применим для определенного количества страниц сайта.
Например, мы видим, что в платном канале используются url с хвостами, где содержится параметр param=id
Мы не будем закрывать каждую страницу от индексации, а используем маску:
то есть мы закрыли тем самым от индексации станицы, которые содержат param=id , т.к. это является дублями.
Также, необходимо закрывать от индексации страницы с результатами поиска, фильтрации, страницам печати, страницы пагинации и т.п.
Например, закрываем страницу с выводами результатов поиска:
Для данного примера конструкция закрытия от индексации будет:
тем самым мы закрыли страницу результатов поиска и все дополнительные «хвосты», связанные с ней.
Также, необходимо закрыть «служебные» страницы, например, страницу с корзиной.
Иностранная версия сайта
Если сайт содержит в себе иностранную версию страниц и контент на этих страницах полностью дублирует русскоязычную версию, то обязательно нужно закрывать данную страницу от индексации (если только это не является русскоязычным переводом).
Иногда нужно, чтобы страницы сайта или размещенные на них ссылки не появлялись в результатах поиска. Скрыть содержимое сайта от индексирования можно с помощью файла robots.txt , HTML-разметки или авторизации на сайте.
Запретить индексирование сайта, раздела или страницы
Если какие-то страницы или разделы сайта не должны индексироваться (например, со служебной или конфиденциальной информацией), ограничьте доступ к ним следующими способами:
Используйте авторизацию на сайте. Рекомендуем этот способ, чтобы скрыть от индексирования главную страницу сайта. Если главная страница запрещена в файле robots.txt или с помощью метатега noindex , но на нее ведут ссылки, страница может попасть в результаты поиска.Запретить индексирование части текста страницы
Скрыть от индексирования часть текста можно несколькими способами:
В HTML-код страницы добавьте элемент noindex . Например:
Элемент не чувствителен к вложенности — может находиться в любом месте HTML-кода страницы. Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.
При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
В HTML-код страницы добавьте элемент noscript . Например:
Элемент noscript , как и noindex , запрещает индексирование, но при этом скрывает содержимое сайта от пользователя, если его браузер поддерживает технологию JavaScript.
Примечание. JavaScript поддерживают все популярные браузеры, если эта функция не отключена пользователем специально.Посмотреть отчет о наличии JavaScript можно в Яндекс.Метрике .
Скрыть от индексирования ссылку на странице
- Скрыть разные типы ссылок
- Скрыть все ссылки на странице
Можно комбинировать несколько значений. Пример:
Значения атрибута rel воспринимаются роботом как рекомендация не принимать ссылку во внимание.
Чтобы скрыть от индексирования все ссылки на странице, укажите в HTML-коде страницы метатег robots с директивой nofollow. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.При использовании любого из перечисленных указаний ссылка может быть обработана роботом и отобразиться в Вебмастере как внутренняя или внешняя. Само отображение или отсутствие ссылки в Вебмастере не указывает на то, что поисковые алгоритмы учитывают ее.
В рубрике "HTML" Вы найдете бесплатные уроки по работе с этим языком гипертекстовой разметки, который лежит в основе большинства сайтов.
Данная рубрика заменит Вам полноценный «HTML учебник». Здесь Вы сможете найти ответы на большинство вопросов, связанных с HTML и DHTML.
Бесплатные уроки HTML для начинающих
Помимо текстовых уроков, Вы также сможете найти на нашем сайте полезные видео уроки по HTML. Простые и понятные примеры и объяснения помогут Вам в кратчайшие сроки освоить этот базовый язык «сайтостроения».
Лайфхак: наиполезнейшая функция var_export()
При написании или отладки PHP скриптов мы частенько пользуемся функциями var_dump() и print_r() для вывода предварительных данных массив и объектов. В этом посте я бы хотел рассказать вам о функции var_export(), которая может преобразовать массив в формат, пригодный для PHP кода.
Автор/переводчик: Станислав Протасевич17 бесплатных шаблонов админок
Парочка бесплатных шаблонов панелей администрирования.
Автор/переводчик: Станислав Протасевич30 сайтов для скачки бесплатных шаблонов почтовых писем
Создание шаблона для письма не такое уж простое дело. Предлагаем вам подборку из 30 сайтов, где можно бесплатно скачать подобные шаблоны на любой вкус.
Автор/переводчик: Станислав ПротасевичКак осуществить задержку при нажатии клавиши с помощью jQuery?
К примеру у вас есть поле поиска, которое обрабатывается при каждом нажатии клавиши клавиатуры. Если кто-то захочет написать слово Windows, AJAX запрос будет отправлен по следующим фрагментам: W, Wi, Win, Wind, Windo, Window, Windows. Проблема?.
Автор/переводчик: Станислав Протасевич15 новых сайтов для скачивания бесплатных фото
Подборка из 15 новых сайтов, где можно скачать бесплатные фотографии для заполнения своих сайтов.
Автор/переводчик: Станислав Протасевич50+ бесплатных Bootstrap 3 шаблонов и элементов UI
Подборка бесплатных UI материалов и Bootstrap 3 шаблонов за уходящий месяц.
Автор/переводчик: Станислав ПротасевичЗум слайдер
Сегодняшний черновик - это простой слайдер с возможностью раскрытия подробной информации о каждом элементе.
Пример полного доступа на индексацию сайта без ограничений:
Применение в SEO
По умолчанию поисковые роботы сканируют все страницы сайта, к которым они имеют доступ. Попасть на страницу поисковый робот может из карты сайта, ссылки на другой странице, наличии трафика на данной странице и т.п.. Не все страницы, которые были найден поисковым роботом следует показывать в результатах поиска.
Файл robots.txt позволяет закрыть от индексации дубли страниц, технические файлы, страницы фильтрации и поиска. Любая страница на сайте может быть закрыта от индексации, если на это есть необходимость..
Правила синтаксиса robots.txt
Логика и структура файла robots.txt должны строго соблюдаться и не содержать лишних данных:
Проверка robots.txt
Поисковые системы Яндекс и Google дают возможность проверить корректность составления robots.txt:
- В Вебмастер.Яндекс - анализ robots.txt.
- В Google Search Console - ссылка, необходимо сначала добавить сайт в систему.
Примеры настройки robots.txt
Первой строкой в robots.txt является директива, указывающая для какого робота написаны исключения.
Директива User-agent
Все директивы следующие ниже за User-agent распространяют свое действие только на указанного робота. Для указания данных другому роботу следует еще раз написать директиву User-agent. Пример с несколькими User-agent:
Использование нескольких User-agent
Сразу после указания User-agent следует написать инструкции для выбранного робота. Нельзя указывать пустые сроки между командами в robots.txt, это будет не правильно понято сканирующими роботами.
Разрешающие и запрещающие директивы
Для запрета индексации используется директива "Disallow", для разрешения индексации "Allow":
Указано разрешение на индексацию раздела /abc/ и запрет на индексацию /blog/. По умолчанию все страницы сайта разрешены на индексацию и не нужно указывать для всех папок директиву Allow. Директива Allow необходима при открытии на индексацию подраздела. Например открыть индексацию для подраздела с ужатыми изображениями, но не открывать доступ к другим файлам в папке:
Последовательность написания директив имеет значение. Сначала закрывается все папка от индексации, а затем открывается её подраздел.
Запрещение индексации - Disallow
Директива для запрета на сканирование - Disallow, индексация запрещается в зависимости от параметров, указанных в директиве.
Полный запрет индексации
Сайт закрывается от сканирования всех роботов.
Существуют специальные символы "*" и "$", которые позволяют производить более тонкое управление индексацией:
Символ звездочка означает любое количество любых символов, которые могут идти следом. Вторая директива имеет тот же смысл.
Запрещает индексацию всех Url, где встречается значение внутри звездочек.
Закрывает от индексации раздел и все вложенные файлы и подразделы.
Разрешение индексации - Allow
Задача директивы Allow открывать для индексации url, которые подходят под условие. Синтаксис Allow сходен с синтаксисом Disallow.
Весь сайт закрыт от индексации, кроме раздел /fuf/.
Директива Host
Данная директива нужна для роботов поисковой системы Яндекс. Она указывает главное зеркало сайта. Если сайт доступен по нескольким доменам, то это позволяет поисковой системе определить дубли и не включать их в поисковый индекс.
В файле robots.txt директиву Host следует использовать только один раз, последующие указания игнорируются.
Директива Sitemap
Для ускорения индексации страниц сайта поисковым роботам можно передать карту сайта в формате xml. Директива Sitemap указывает адрес, по которому карта сайта доступна для скачивания.
Исключение страниц с динамическими параметрами
Директива Clean-param позволяет бороться с динамическими дублями страниц, когда содержимое страницы не меняется, но добавление Get-параметра делает Url уникальным. При составлении директивы сначала указывается название параметра, а затем область применения данной директивы:
Данная директива будет работать для раздела /catalog/, можно сразу прописать действие директивы на весь сайт:
Снижение нагрузки - Crawl-delay
Если сервер не выдерживает частое обращение поисковых роботов, то директива Crawl-delay поможет снизить нагрузку на сервер. Поисковая система Яндекс поддерживает данную директиву с 2008 года.
Поисковый робот будет делать один запрос, затем ждать 4 секунды и снова делать запрос.
Читайте также: