
Regexp проверка расширения файла
Многие сайты, стремясь получить как можно больше информации о своих посетителях, предлагают пройти авторизацию. Как правило, от пользователя в таких случаях необходим e-mail и личный пароль. Что же происходит с этими данными дальше?
Информация поступает на сервер, где обрабатывается при помощи специального кода. Однако часто при некорректно введенных пользовательских данных, код не может обработать информацию и выдает ошибку. Поэтому для проверки адресов электронной почты и другой текстовой информации используются регулярные выражения.
Регулярные выражения представляют собой способ поиска совпадений шаблона с текстом. Такой шаблон поиска может состоять как из отдельного символа, так и более сложных символьных комбинаций и выражений, необходимых для сопоставления с оригинальным текстом. Для поиска используется строка-образец (шаблон/pattern), которая состоит из метасимволов, задающих правило поиска.
Например:
- /example/i — регулярное выражение;
- example — шаблон для поиска;
- i — модификатор, не учитывающий при поиске регистр. Могут использоваться также модификаторы g — глобальное сопоставление (находит все совпадения, не останавливаясь после первого) и m — многострочное сопоставление.
Для работы с регулярными выражениями в Java импортируется пакет java.util.regex с классами, которые помогают сопоставлять последовательности символов с шаблонами. Внутри — три основных класса:
- Pattern — скомпилированное представление регулярного выражения.
- Matcher — выполняет операции сопоставления с последовательностью символов путем интерпретации файла Pattern.
- PatternSyntaxException — является исключением, не выполняет проверку, но указывает на синтаксическую ошибку в шаблоне регулярного выражения.
Регулярные выражения имеют довольно широкую область применения. Они могут использоваться при поиске и замене текста, редактировании и управлении данными, распознавании номеров телефонов, e-mail адресов, имен пользователей (на кириллице и латинице), сопоставлении текста с рисунком, проверке ввода веб-форм, фильтровании информации и многом другом.
Как создать регулярное выражение
Существует два способа создания регулярного выражения:
- При помощи литерала (фиксированного значения). При анализе скрипта литералы вызывают регулярное выражение. Способ используется при постоянном регулярном выражении и позволяет увеличить производительность.
Например:
- Используя конструктор объектаRegExp. Компиляция регулярного выражения происходит во время выполнения скрипта. Способ стоит использовать при изменяемом регулярном выражении.
Например:
Как создать шаблон регулярного выражения
Чтобы быстро освоить регулярные выражения, можно воспользоваться генератором регулярных выражений , например, regex101.
Чтобы создать самое простое регулярное выражение, необходимо выбрать JavaScript в левой колонке Flavor и отключить флаги multi line и global.
Например: введите в поле регулярного выражения слово map, а в тестовую строку map, cap, maps, dap, sap, MAP, lap, map, rap, tap, zap.
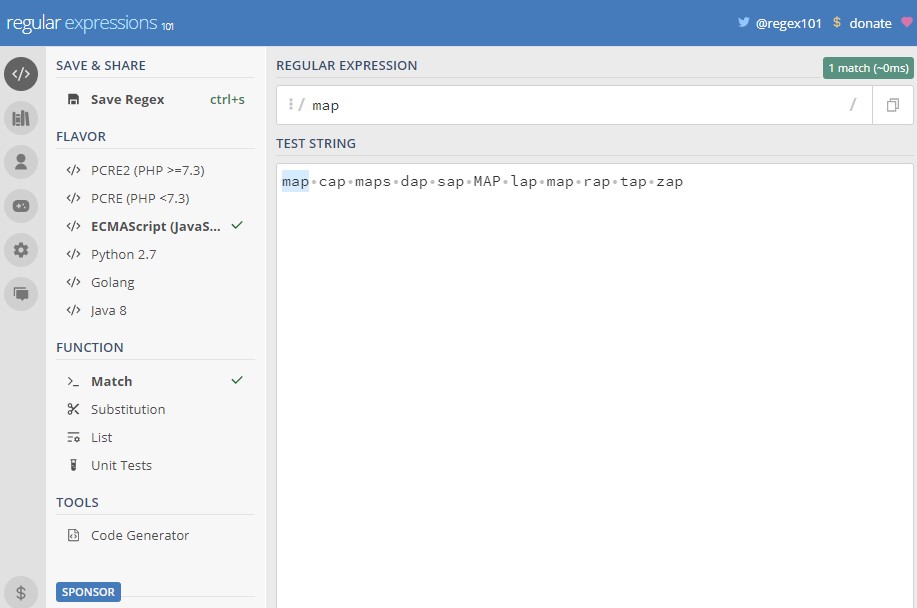
Как видим, некоторые строки в тестовой строке не совпадают. Это происходит потому, что регулярное выражение по умолчанию возвращает только первое найденное совпадение. Чтобы нашлись все совпадения, необходимо включить флаг global (g). Стоит обратить внимание, что шаблоны регулярных выражений учитывают регистр, потому следует также выбрать флаг insensitive (i).
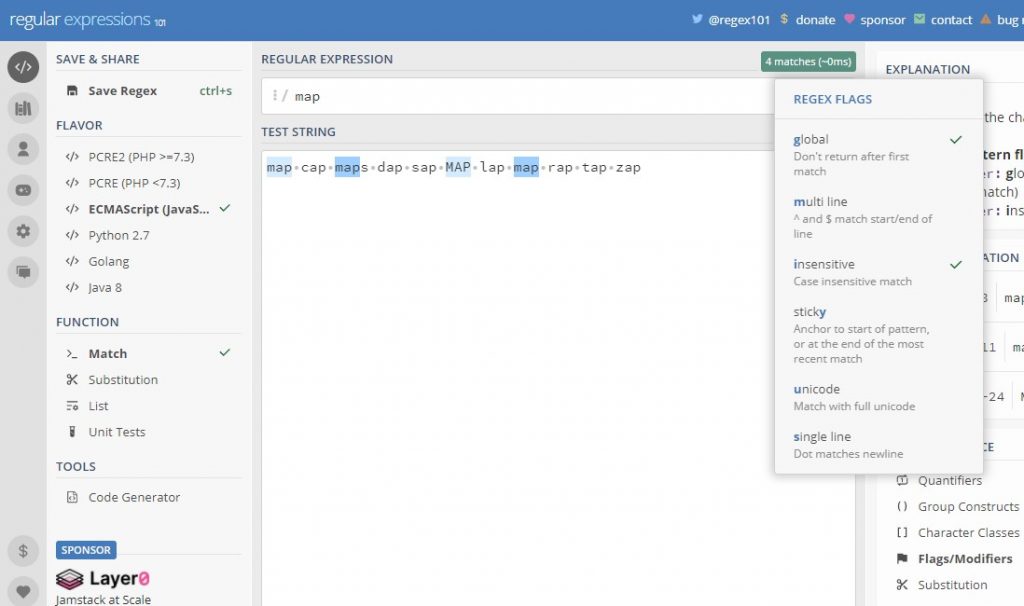
Регулярное выражение теперь имеет вид /map/gi
Регулярное выражение теперь имеет вид /map/gi, а в тестовой строке найдены все совпадения, в том числе в верхнем регистре.
Чтобы сопоставить слова map, cap, rap, необходимо расширить написание регулярного выражения и использовать наборы символов, поместив их в квадратные скобки []. Так, [mcr]ap будет соответствовать строкам:
![[mcr]ap будет соответствовать этим строкам](https://highload.today/wp-content/uploads/2021/06/image3.jpg)
[mcr]ap будет соответствовать этим строкам
Чтобы сопоставить все слова, которые заканчиваются на «-ap», есть возможность использовать диапазон [a-z]ap.![Использование диапазона [a-z]ap](https://highload.today/wp-content/uploads/2021/06/image1.jpg)
Использование диапазона [a-z]ap
Можно использовать следующие диапазоны:Использование специальных символов
Специальные символы используются для написания более сложных регулярных выражений. Они необходимы в тех случаях, когда стоит задача найти пробелы, повторяющиеся символы. Ниже предоставлен полный список таких символов.
Специальные символы регулярных выражений
● /\bbloo/ соответствует bloo в слове blood;
Работа с регулярными выражениями
В JavaScript регулярные выражения используются в методах: exec, test, match, search, replace, split.
Методы, которые используют регулярные выражения
| exec | При совпадении в строке возвращает массив и обновляет regexp. |
| test | Производит тестирование совпадений в строке. Может быть true или false. |
| match | Выполняет поиск совпадений. Возвращает массив, содержащий результаты этого поиска. |
| search | Производит тестирование совпадений в строке. Возвращает позицию первого символа в найденной строке. Если соответствие не найдено, вернет значение -1. |
| replace | Выполняет поиск совпадений в строке. Ищет строку для регулярного выражения и возвращает новую с измененными указанными значениями. |
| split | Выполняет разбиение строки с регулярным выражением в массив по указанному разделителю. |
Методы test и search позволяют узнать, есть ли в строке соответствия шаблону регулярного выражения. Для получения более полной информации используют методы exec и match.
Приведем в пример поиск совпадения в строке с использованием метода exec. Скрипт выглядит так:
Какими могут быть результаты выполнения регулярных выражений — рассмотрим в таблице ниже.
Результаты выполнения регулярного выражения
Флаги регулярных выражений
В регулярных выражениях могут применяться специальные флаги. Они влияют на поиск.
| Флаг | Описание |
| i | Осуществляется поиск без привязки к регистру. Найдет соответствия в верхнем и нижнем регистрах (D и d). |
| g | Глобальный поиск. Осуществляется поиск всех совпадений, а не только первого. |
| m | Многострочный поиск. Влияет на символы ^ (поиск совпадений в начале строки) и $ (поиск совпадений в конце строки). |
| y | Поиск по заданной позиции в исходной строке. |
| u | Поддержка Unicode. |
| s | Поиск любого символа, включая перенос строки \n. |
Флаги в шаблонах регулярных выражений используются с помощью синтаксисов:
Флаги указываются после шаблона/паттерна.
Примеры использования регулярных выражений
Проверка e-mail
Как проверить, действителен ли адрес электронной почты, введенный пользователем в соответствующее поле на сайте?
Регулярное выражение, которое соответствует любому e-mail адресу:
Проверка телефонных номеров
Этот пример может применяться для проверки любого телефонного номера:
Проверка телефонного номера с кодом конкретной страны (например, Украины):
Проверка строки с адресом видео на YouTube
Подходит для всех URL-адресов на YouTube:
Проверка формата URL
Проверка текста на повторяющиеся слова
Поиск соответствий на повторяющиеся слова:
\b — это граница слова, а \1 — ссылка на зафиксированное совпадение (первое слово).
Синтаксис поисковых запросов Google
Проверка имени пользователя
Проверка надежности паролей
Чтобы создать надежный пароль, необходимо придерживаться некоторых стандартов — использовать помимо букв и цифр другие символы в разных регистрах, а также спецзнаки. Это регулярное выражение уже содержит необходимые требования для проверки надежности паролей:
Проверка номера кредитной карты
С помощью регулярных выражений можно исключить номера платежных карт, в которых содержатся умышленные или случайные ошибки, неправильные последовательности введенных цифр:
Проверка цен
Цены имеют множество представлений и форматов. Единого регулярного выражения для них не существует. Приведем пример выражения для извлечения из текста цен в долларовом эквиваленте:
где — комбинация, которая указывает на то, что символ из 4 должен повториться дважды (дробная часть цены).
Внимание! Регулярные выражения имеют в своем арсенале специальные символы, которые в обязательном порядке необходимо экранировать. В этот список входят: . ^ $ * + ? < >[ ] \ | ( ). Перед каждым таким символом необходимо добавлять обратный слэш \.
Сервисы и приложения для проверки регулярных выражений
Чтобы не писать код с нуля, существуют специальные онлайн-инструменты, которые позволяют протестировать уже написанные регулярные выражения или используются для тренировки.
Один из лучших сервисов по созданию регулярных выражений. Позволяет сгенерировать и получить ссылку на код для JavaScript, PHP, Python. Содержит огромную библиотеку уже готовых шаблонов регулярных выражений.
Удобный онлайн-тестер для выполнения простых задач. Не генерирует код, но поддерживает замену по шаблону.
Десктопная программа с рядом преимуществ. Содержит большую библиотеку шаблонов, может генерировать код. Для удобства работа осуществляется в визуальном редакторе.
Плагин для IDE. Поддерживает замены и разделения по шаблону, включает в себя подсказки и описания используемых элементов. Не сохраняет регулярные выражения, но прекрасно подходит для их проверки перед тем, как добавить в код.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Простой метод измерения реальной скорости загрузки страниц у посетителей сайта
Как можно закэшировать данные и выиграть в производительности
Как работает Server-Sent API с примерами
Примеры применения Javascript в Nginx'e
Как просто сделать удобный дебаг и не лазить в код или как бородатые хакеры перехватывают ajax-запросы, нарушая вашу безопасность.
В своем блоге индийский разработчик Шашват Верма (Shashwat Verma) рассказал, как преобразовать веб-сайт или веб-страницу в прогрессивное веб-приложение (PWA).
Мне интересно, есть ли регулярное выражение, которое я могу использовать для поиска расширений файлов с помощью базового html.
Проблема заключается не в том, что мои изображения заканчиваются на .jpg.
Итак, я хотел бы, чтобы регулярное выражение могло найти все изображения, начинающиеся с малого и заканчивающиеся на .jpg , .jpg , .jpg , .jpg , .jpg и т.д. и в нижнем регистре и верхний регистр.
Есть ли простое регулярное выражение, которое я могу положить после "малого", чтобы найти все соответствующие файлы?
Я не уверен, что я делаю неправильно, но когда я пытаюсь сделать какие-либо предложения, вывод показывает только регулярное выражение, а не намеченные результаты. здесь мой текущий код
любая идея, что я делаю неправильно?
Для пояснения, вы пытаетесь вернуть имя файла small-filename.jpg или регулярное выражение, чтобы получить полный путь к файлу, например, images/pimage/27/small-filename.jpg ? Все имена файлов имеют небольшие имена. Некоторые из них small.jpg, некоторые small.JPG, small.jpg, small.jpg и т. Д.3 ответа
Регулярное выражение для захвата всех изображений, начинающихся с "малого" и заканчивающихся в любом расширении, которое вы указали:
.* - соответствует 0 или более символов
\. - соответствует периоду; \ - это escape-символ, который означает, что следующий символ должен интерпретироваться буквально, что необходимо, потому что символы . , ? , + и т.д. имеют смысл в regex в противном случае.
(a|b|c) - сопоставляет все, что содержится внутри круглых скобок (например, соответствует, если следующий символ a или b или c )
? - означает, что предыдущий символ может отображаться как ноль или один раз (например, jpe?g соответствует "jpeg", потому что он содержит один "e", а также соответствует "jpg", потому что "e" появляется нулевое время в этой позиции)
$ - обозначает конец шаблона, который нужно сопоставить
/your-regex-pattern/i - нечувствительные к регистру совпадения (верхний и нижний регистр)
Сбой для любого файла, содержащего точку, small.heart.jpg от периода до расширения (например, small.heart.jpg завершится ошибкой, даже если это допустимое имя файла). Кроме того, конец должен быть (jpg|jpeg|gif|png|tiff) (с использованием скобок, а не скобок). Наконец, вам может быть целесообразно указать $ в конце шаблона, чтобы убедиться, что после предполагаемого расширения файла нет никаких символов (например, ваши текущие шаблоны будут успешными для чего-то вроде: small.jpg.php или чего-либо еще, что следует действительное расширение изображения). Еще одна вещь, jpg|jpeg может быть сокращена до jpe?gВозможно, это поможет вам?
(знак точки и 1 (или более) символов класса слов в конце строки ввода)
(знак точки и 1 (или более) буквы в конце строки ввода)
(знак точки и от 1 до 4 букв в конце строки ввода)
Обратите внимание, что все параметры имеют вывод точечного знака.
Все регулярные выражения нечувствительны к регистру, так как существует i -flag.
Кроме того, к сожалению, JavaScript не поддерживает lookbehind, поэтому regexp
(1 или более букв после подстроки small. )
не будет работать; но, я думаю, это было бы лучшее regexp в этом случае.
Чтобы указать шаблон как нечувствительный к регистру, вы можете указать (?i) как начало нечувствительной к регистру части, а (?-i) - как конец нечувствительной к регистру части.
В вашей конкретной ситуации это означает, что следующий шаблон RegEx может быть эффективным: \.(?i)(png|gif|jpg|jpeg|ico|bmp|svg|tiff)(?-i)$ Очевидно, что вы захотите изменить этот шаблон на свои нужды, чтобы добавить или удалить типы файлов изображений.
В этом шаблоне: \. обозначает символ буквального периода ( . ); (?i) отключает чувствительность к регистру для всех следующих частей; (png|gif|jpg|jpeg|ico|bmp|svg|tiff) обозначает список опций, то есть расширение файла должно быть одним (и только одним) из опций в списке; (?-i) включает чувствительность к регистру; и $ обозначает конец строки, то есть не может быть никаких символов, следующих за расширением файла.
Если язык, который вы используете, поддерживает указание совпадающих флагов другим способом, я бы посоветовал вам указывать их любым способом, который рекомендует язык; однако, согласно приведенной выше странице информации RegEx, это правильный способ указать их в шаблоне (что не позволяет сделать весь шаблон без учета регистра, если вы решите добавить больше к шаблону).
EDIT: как предупреждение, похоже, что Javascript не поддерживает включение и выключение чувствительности к регистру внутри самого шаблона (используя (?i) и (?-i) ). Итак, если вы работаете с Javascript, вам придется обойти это, установив /i в качестве флага в конце вашего выражения или используя шаблон, такой как: \.([pP][nN][gG]|[jJ][pP][eE]?[gG]|[gG][iI][fF]|[iI][cC][oO]|[tT][iI][fF])$ . В этом шаблоне каждая буква в расширении указывается как в верхнем, так и в нижнем регистре. Это позволяет шаблону соответствовать расширению файла независимо от того, в каком случае он написан, но при этом остальная часть выражения имеет чувствительность к регистру.
Как мне написать регулярное выражение которое находило бы все эти файлы по расширению (-.txt, -.bin, -.html, -.cs, -.bat, -.reg, -.css) ? нужно только регулярное выражение(код шарпа уже есть) или хотя подсказка как писать подобное.
__________________Помощь в написании контрольных, курсовых и дипломных работ здесь
Регулярное выражение для поиска определённых файлов и копирование их в другую директорию
Здраствуйте! Столкнулся с регулярными выражениями. Но такое дело что в них ничего понять не могу.

Регулярное выражение для поиска слова
У меня есть файл, содержащий строки с текстом: Предложение номер один Второе предложение, оно.
Регулярное выражение для поиска email адреса
Здравствуйте дорогие форумчане!)) Составил регулярное выражение, но оно почему-то работает.
Извиняюсь, думал, что только расширение получить надо.
или использовать перегрузку GetFiles().
Спасибо тема исчерпанаменя запутал этот превьювер для регулярных выражений.
галочку global надо ставить, тогда нормально показывает.
Что у вас за ужасные ответы? Я так и не понял, как мне в строке SpiritAbsolute,
Хорошие у нас ответы, а главное правильные
А вот что у вас за вопрос не понятно, как вы хотите найти файлы в строке?
Каков вопрос, такой и ответ.
uaSky, вы проверяли своё регулярное выражение?Да и вообще, имя файла может содержать ещё и точки и запятые и прочие знаки. Поэтому правильнее для не разрывного пробелом имени файла использовать такой паттерн: это у Вас рег.выражение или строка с записей тёти Маши с магазина? Вы для начала свое проверьте а потом на дядинек незнакомых кидайтесь. и на будущее, первое - прочитайте задачу внимательно!
Второе - подумайте Сами! над решением, а потом, отталкиваясь от задачи, огласите решение. Удачи в начинаниях. uaSky, "дяденька", я в отличии от Вас, как раз таки проверяю, и что не мало важно, понимаю, что пишу.
Что касается задачи, то здесь, по всей видимости, Вы тоже чего-то не до глядели. Стоит вопрос, найти файлы следующего формата: "index.php", но это отнюдь не означает, что имя файла не может быть другим, а вот расширение - как раз таки и должно быть строгим. Посему мой паттерн (@"[^ ]+\.php"
), предполагает нахождение файлов с расширением .php и именем состоящий из символов неразрывных пробелом.
Ваш же паттерн (@"\w*[.php]$"), будет искать буквосочетания, состоящее из ноль (недопустимо для имени файла) или более числа подряд идущих печатных символов (латинские буквы, цифры и знак подчёркивания), плюс словосочетание из четырёх символов ".php" (где их порядок может быть любым), при этом всё это буквосочетание должно быть ВСЕГДА в конце входной строки (с чего бы это вдруг?), в итоге предположительный результат Вашего паттерна может быть и таким: fileName.ppp и таким fileName. или таким fileName.p.p. Как Вы считаете, такой результат целиком и полностью удовлетворяет условию задачи?
"предполагает нахождение файлов с расширением .php и именем состоящий из символов неразрывных пробелом" Сам ответил на свой косяк)
Добавлено через 8 минут
Если ты так уж "углубленно" изучил задачу и "заметил" в ответе незнакомого дяденьки , что его ответ НЕ "целиком и полностью удовлетворяет условию задачи". Ваш текст ". предполагает нахождение файлов с расширением .php и именем состоящий из символов неразрывных пробелом". А пробелы уже нельзя включать в названия? А теперь ,уважаемый, прочитал еще раз задание, а особенно последние 6 слов. и медленно ушёл в туман.
Взять то, что находится между тегами <title> и </title>
Обратите внимание: берется не нулевой элемент массива, а первый!
Если title будет встречаться несколько раз, то будет вырезан первый!
Найти текст, заключенный в какой-то тег и заменить его на другой тег
Например: <TITLE> . </TITLE> заменить аналогично на <МОЙ_ТЕГ> . </МОЙ_ТЕГ> в HTML-файле:Проверяем, является ли переменная числом
Запретим пользователю использовать в своем имени любые символы, кроме букв русского и латинского алфавита, знака "_" (подчерк), пробела и цифр:
Проверка адреса e-mail
Для поля ввода адреса e-mail добавим в список разрешенных символов знаки "@" и "." и "-", иначе пользователь не сможет корректно ввести адрес. Зато уберем русские буквы и пробел:
Проверка на число
Проверка имени файла
Проверка расширения файла
Программы (exe, xpi, . )
Изображения (jpg, png, . )
Выборка цен
Часто возникает проблема по парсингу интересующих программиста данных из HTML, который не всегда хорошего качества, все было бы терпимо, если бы еще не вставки на javascript'е, вот пример такого текста:
Те цифры, которые написаны через точку, являются ценами. Задача состоит в том, чтобы собрать все цены, которые находятся между тегами <a>. </a> Видим, что помимо цен между заданными тегами, есть такие, которые идут сразу после тега <TD>, а также стоят между тегами <B>. </B>. Ясно, что описать достаточно точно содержимое атрибутов тега <A> представляется задачей не самой легкой, поэтому надо ее упростить! Любой тег имеет закрывающий знак '>', наша задача описать, что этот знак идет перед ценой, но так как перед ценой может стоять тег <B> и тег <TD>, но эти цены нам не нужны. Каким образом мы узнаем, что цена стоит между тегами <A>. </A>? По тегу, который идет после цены, если это не тег </B>, то это будет либо тег </A> либо <BR>, а так же по тегу перед ценой если этот тег <TD>. Путем таких размышлений мы пришли к выводу, что должно стоять справа, а что должно стоять слева искомой строки, которая описывается как цифры, разделенные точкой: \d*\.\d* То, что должно совпасть слева, мы описали как символ '>', записываем: (?<=>) - выглядит немного странно, но совпадение справа записывается вот так (?<=), а внтури него после ?<= идет символ '>' То, что должно совпасть справа описывается (?=) внутри мы пишем </A>. Теперь опишем, что не должно стоять перед ценой: (?<!<TD>) перед ценой не должен стоять тег <TD>, это и есть негативная ретроспективная проверка. При помощи негативной опережающей проверки опишем, что не должно стоять справа цены: (?!<\/B>) справа от цены не должен стоять тег </B>. Результирующее регулярное выражение, которое описывает все приведенные условия выглядит вот так:
После рассмотрения первого примера стоит сделать замечания и пояснения по поводу использования позиционных проверок.
1. Написанные друг за другом проверки применяются независимо друг от друга в одной точке, не меняя ее. Естественно, что совпадение будет найдено, если все проверки совпадут. В нашем примере это были точки перед и после цены. С точки зрения логики применения проверок нет никакой разницы, будет ли стоять проверка на тег <TD> перед проверкой на знак '>'. Правда, с точки зрения оптимизации первой позиционной проверкой должна идти та, которая имеет наибольшую вероятность несовпадения.
2. Совпавшие значения ретроспективных проверок не сохраняются. Т.е. если в нашем примере совпадает опережающая проверка, которая указывает, что после цены идет тег </A>, то сам тег </A>, который заключен в конструкцию (?=) не будет запоминаться в специальных перменных /1,/2 и т.д. Сделано это из-за того, что позиционная проверка совпадает не со строкой, а с местом в строке (она описывает место, где произошло совпадение, а не символы, которые совпали).
3. Нужно указать что PCRE не позволяет делать проверки на совпадение текста произвольной длинны. То есть нельзя делать, например, такую проверку: /(?<=\d+)
Механизм поиска совпадения в ретроспективной проверке реализован так, что при поиске механизму должна подаваться строка фиксированной длины, для того, чтобы в случае несовпадения, механизм мог вернуться назад на фиксированое количество символов и продолжить поиск совпадений в других позиционных проверках. Думаю, что сразу это понять сложно, но представьте себе как происходит поиск совпадения в части (?)(?<=>) вышеописанного регулярного выражения. Берется строка, в которой происходит поиск, отсчитывается от начала столько символов, сколько символов будет в совпадении позиционной проверки, в нашем варианте это 4: <, T, D, > с этого места происходит "заглядывание назад" (ретроспективные проверки на английском языке звучит как lookbhind assertions), т.е. все предыдущие 4 символа проверяются на совпадение со строкой <TD>, если механизм не нашел совпадения, то ему надо вернуться на 4 символа назад, выполнить тоже самое с проверкой (?<=>), т.е. отсчитать один символ, "заглянуть" назад, попробовать найти проверку предыдущего символа с символом '>'. Представьте себе, что условие совпадения состоит из строки нефиксированной длинны: (??) подобная запись должна означать, что перед ценой, не должен стоять тег <TD> в количестве максимимум один экземпляр (либо вообще не стоять). Вот и получается, что после того, как механизм отсчитает 4 символа от начала, он проверит на совпадение с <TD>, но в условии указано, что тега может и не быть вообще, тогда возникает вопрос, на сколько знаков верунться назад, чтобы проверить на совпадение другие проверки. На 4 или вообще не возвращаться? Сразу возникает вопрос, а зачем идти вперед, чтобы потом "заглянуть" назад? Делается это для того, чтобы в случае совпадения всех проверок сразу же начать проверку тех символов, которые идут после позиционных проверок.
Выбрать все изображения со страницы
Как-то мне нужно было получить все изображения, которые использовались на сайте. Что для этого надо сделать? Правильно, надо в браузере нажать на "Сохранить как", указать куда сохранить страницу. Появится файл с исходным кодом страницы и папка с изображениями. Но вы никогда не сохраните в эту папку изображения, которые прописаны в стилях объектов по крайней мере в эксплорере:
Для проведения вышеописанной операции надо:
1. попросить хозяина хоста использовать контент, размещенный на его сайте.
2. найти в тексте все строки, подобные приведенной выше, и выделить в них относительный путь к файлу
3. сформировать файл в котором будут выводиться изображения при помощи:
<img src=полный_путь_к_изображению>
Делаем: В переменную $content получаем исходный код страницы. А дальше используя регулярные выражения ищем относительные пути, которые прописаны в стилях. Каждый раз, когда я описываю, как я реализовал пример, я сначала тщательно описываю, что ищем, и тщательно описываю, в каком контексте происходит поиск. Проанализировав исходный код страницы стало понятно, что кроме как в описании стилей относительные пути к изображениям нигде не используются. Слева от относительного пути идет последовательность символов: url( Справа от относительного пути стоит закрывающаяся круглая скобка. Между этими последовательностями символов могут быть буквы латинского алфавита, цифры и слеши, а также точка перед расширением файла.
Начнем с простого. Символы латинского алфавита, цифры, точка и слеш описываются символьным классом: [a-z.\/] их может быть сколько угодно, на самом деле больше 3 (имя файла, минимум один символ, точка, расширение, минимум один символ), но в данном случае, зная контекст, это некритично, поэтому указываем квантификатор * [a-z.\/]* Слева должны идти 'url(' и мы это описываем при помощи позитивной ретроспективной проверки: (?<=url() Но обратите внимание на то, что скобка в регулярных выражениях является спецсимволом группировки, поэтому чтобы она стала символом, надо перед ней поставить другой спецсимвол - слеш. (?<=url\() Справа от относительного пути должна стоять закрывающаяся круглая скобка. Это условие описывается при помощи позитивной опережающей проверки: (?=\)) Как видите, перед одной из скобок стоит слеш, что означает, что она интепретируется не как спецсимвол, а как литерал. Ниже приведен полный код на PHP, который выполняет все действия, кроме вопроса о разрешении использовать контент:
Парсер всех внешних и внутренних ссылок со страницы
В массиве $vnut только ссылки внутренние, в массиве $vnech только внешние ссылки.
Является ли строка числом, длиной до 77 цифр:
Состоит ли строка только из букв, цифр и "_", длиной от 8 до 20 символов:
Проверка строки на допустимость
Есть ли в строке любые символы, кроме допустимых. Допустимыми считаются буквы, цифры и "_". Длину тут проверять нельзя, разве что просто дополнительным условием strlen($string). Не путайте с предыдущим примером - хоть результат и одинаковый, но метод другой, "от противного"Для регистро независимого сравнения используйте preg_match с модификатором i().
Читайте также: