
Какие данные считаются самыми точными при оценке посещаемости данные лог файлов
Термины Редактор: Дмитрий Сокол 20441 22 мин Аудио
Лог-файлы (файлы регистрации, журнальные файлы) на Linux - это текстовые файлы о событиях, произошедших на сайте: информация о параметрах посещений сайта и ошибках, которые возникали на нем.
Вебмастерам нужно получать информацию о том, как работает их сайт и сервер. Это можно узнать из log-файлов.
На виртуальном хостинге владельцы сайтов работают с логами web-сервера, доступ к которым предоставляет провайдер.
На VPS/VDS и выделенных серверах можно работать с самыми разнообразными логами, которые записывают все работающие на сервере службы.
Информация, хранящаяся в лог-файлах, служит основой для диагностики работы различных системных служб, а также для разнообразной аналитики, например, о посещаемости сайта или о попытках взлома системы.
На платформе Windows также имеется служба журналирования событий, но там информация записывается не в текстовые файлы, а в журналы специального формата, доступ к информации которых возможен через службу Event Viewer.
Log-файлы и виртуальный хостинг
Провайдер хостинга обеспечивает доступ к лог-файлам web-сервера через панель управления. Например, у провайдера Beget это выглядит так.

Также доступ к лог-файлам конкретного сайта можно получить через файл-менеджер (или по протоколу FTP).
У провайдера Beget в менеджере файлов их можно найти здесь.

При использовании популярной панели ISPmanager log-файлы доступны пользователю и располагаются в каталоге /log. Для каждого из сайтов присутствуют два лог-файла:
- посещений (doman.name.access.log);
- ошибок (domain.name.error.log).

Виды лог-файлов
Все программы и сервисы Linux ведут log-файлы.
Самые важные - это логи:
- веб-сервера;
- почтового сервера (maillog);
- FTP-сервера;
- сервера базы данных;
- подсистемы авторизации (auth.log)
- логи самой системы (messages, syslog).
Log-файлы на сервере хранятся в специальном каталоге /var/log, внутри которого создаются отдельные файлы и папки для того или иного сервиса.
Различие в хранении log-файлов по версиям Linux
Дистрибутивы Linux имеют разный набор программного обеспечения и различные правила хранении log-файлов. В настоящее время наибольшее распространение получили два семейства дистрибутивов Linux:
- системы, основанные на Debian (например, Ubuntu);
- основанные на RedHat (Centos, Fedora).
Конкретная версия операционной системы для VPS/VDS выбирается у провайдера в личном кабинете пользователя перед заказом виртуального сервера.
Общие принципы для всех систем Linux одинаковы: log-файлы хранятся в папке /var/log. Разница проявляется лишь в наименовании отдельных файлов и каталогов для определенных подсистем, что зависит не только от версии Linux, но и от используемой панели управления хостингом.
Системные log-файлы
Опишем наиболее важные системные лог-файлы, хранящиеся в каталоге /var/log.
1. Общий системный журнал, в зависимости от версии Linux, записывается в файлы /var/log/syslog (Debian) или /var/log/messages (Redhat). В него пишется информация, начиная от старта системы:
2. Логи авторизации: /var/log/auth.log (Debian) или /var/log/secure (Redhat). Сюда записывается информация об авторизации пользователей, включая неудачные попытки входа в систему.
4. /var/log/boot.log - log загрузки операционной системы Linux.
5. /var/log/cron - отчет службы запуска по расписанию CRON.
Почти все log-файлы Linux представляют собой текстовые файлы, в которых каждая строчка содержит метку времени и описывает определенное событие. Исключение - это бинарный файл “wtmp”, в котором содержится информация о последних заходах пользователей на сервер.
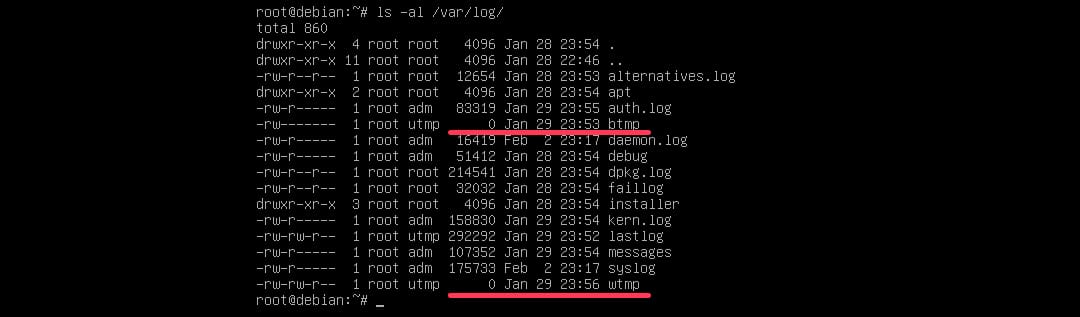
Пример: содержимое каталога /var/log на Linux-системе. Видны текстовые .log-файлы системы, а также двоичный файл wtmp.
Логи web-сервера
Как правило, сайты на сервере работают под управлением web-сервера Apache или Nginx. Также их можно применять на сервере вместе, что позволит использовать сильные стороны каждой программы.
И Apache, и Nginx создают по два файла: один - для записи посещений, второй - для хранения информации об ошибках.
Также к логам веб-сервера относятся лог-файлы интерпретатора PHP (php-fpm) и файлы ошибок PHP.
Логи web-сервера Apache
Web-сервер Apache создает два лог-файла:
Для удобства эти файлы могут создаваться по отдельности для каждого сайта, размещенного на сервере. Тогда они имеют названия “domain.name_access.log” и “domain.name_error.log”.

Пример лог-файла посещений Apache. Список файлов в каталоге показывается командой linux “ls -l”
Для чтения информации из log-файла можно использовать команду “cat имя-лог-файла” или “tail имя-log-файла”.

В зависимости от конкретной панели управления файлами, внутри этого каталога могут находиться папки domains или domlogs, в которых будут записываться лог-файлы отдельно для каждого сайта.
Логи web-сервера Nginx
Nginx также создает два лог-файла для посещений и ошибок. Они располагаются в каталоге /var/log/nginx . В случае совместной работы с Apache лог-файлы Nginx иногда объединяются в один файл с логами Apache, но это несколько неудобно, с точки зрения обнаружения ошибок.
Если Nginx настроен для обслуживания нескольких сайтов, то его лог-файлы записываются отдельно для каждого сайта.
В случае использования Nginx совместно с панелью управления Vesta, log-файлы для отдельных сайтов хранятся в папке /var/log/nginx/domains , а в папке конкретного пользователя в каталоге logs создаются псевдонимы для этих файлов.

Пример: вывод командой “ls *.log” списка log-файлов web-сервера nginx в папке /var/log/nginx/domains (на снимке экрана видно, что там хранятся файлы сразу нескольких сайтов)
Логи интерпретатора PHP
В PHP есть возможность записи ошибок для определенной страницы сайта в отдельный лог-файл (это делается через файл .htaccess). В таком случае файлы ошибок PHP располагаются в одном каталоге с конкретной страницей сайта и имеют вид “php_error.log” или просто “error.log”.
Ротация log-файлов
Для посещаемого сайта размеры лог-файлов могут достигать сотен мегабайт. Рано или поздно они начинают занимать много дискового пространства, поэтому на серверах Linux используется механизм ротации log-файлов.
Как это работает?
1. Данные о посетителях (или ошибках) сайта записываются в файл с обычным названием, например, access.log.
2. Раз в сутки (обычно в ночное время) этот файл автоматически переименовывается в “access.log.1” и сжимается архиватором Gzip.
3. Имя файла становится вида “access.log1.gz”.
4. Вместо этого файла web-сервер начинает записывать информацию в новый файл access.log.
5. Еще через сутки архивный файл “access.log.1.gz” переименовывается в “access.log.2.gz”, и вместо него создается новый архив “access.log.1.gz” из текущего log-файла web-сервера и так далее.
Всего на сервере хранятся сжатые log-файлы за последний месяц.
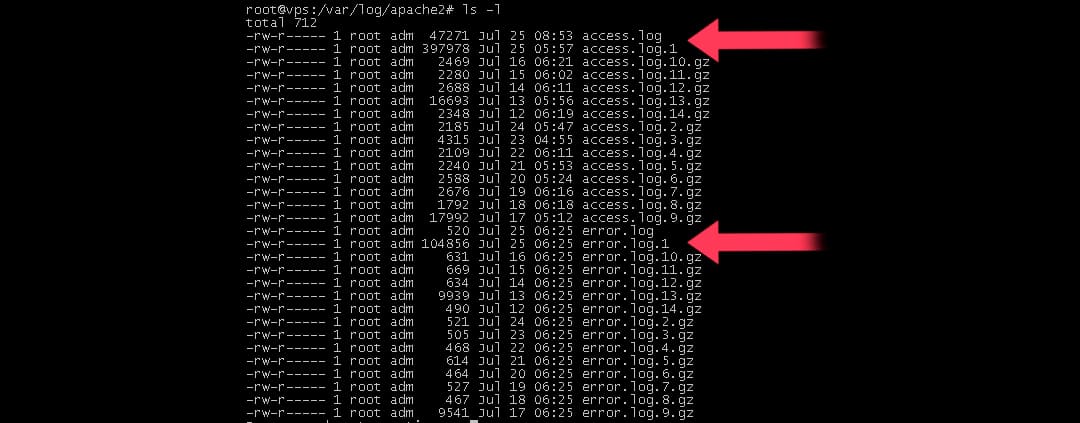
Пример: на снимке экрана виден список log-файлов web-сервера. Среди них присутствуют как текущие файлы access.log и error.log за сегодняшний день, так и файлы за предыдущие дни access.log.1, error.log.1 и так далее.
То же происходит и с log-файлами других сервисов: почта, FTP, системные логи - все они проходят через ротацию.
Таким образом, ротация файлов помогает сохранять место на диске. Зная общий принцип, по которому именуются сжатые лог-файлы, системный администратор может найти нужную информацию за конкретный период времени.
Log-файлы почтовой системы
На сервере Linux могут быть установлены разнообразные программы для работы почтовой подсистемы. В последнее время большинство панелей управления хостингом (VestaCP, cPanel, ISPmanager) используют связку из почтовой программы Exim для отправки и приема писем (протокол SMTP) и другой почтовой программы Dovecot - для доступа пользователей к почтовым ящикам (протоколы IMAP/POP3).

Пример: log-файлы сервера Exim в папке /var/log/exim. На снимке экрана - вывод списка файлов командой ls -l
Log-файлы FTP-сервера
Вариантов программного обеспечения для FTP Linux много, но принцип хранения log-файлов примерно одинаковый. В папке /var/log создаются log-файлы FTP-сервера, например, vsftpd.log или proftpd.log. Также практически всеми FTP-серверами создается файл xferlog, в котором записывается информация о файлах, скачанных с сервера или закачанных на сервер по протоколу FTP.

Пример: log-файлы FTP-сервера vsftpd. На снимке экрана - вывод команды списка файлов, созданных FTP-сервером (vsftpd.log и xferlog)
Log-файлы сервера базы данных
Популярный сервер базы данных MySQL также ведет log-файл “mysqld.log”. Он располагается в папке /var/log/mysql или /var/log/mariadb, в зависимости от используемой версии MySQL.
Также сервер MySQL может создавать в этой папке файл отладки медленных запросов к базе данных. Обычно он называется “mysql_slow.log”.

Пример: содержимое файла медленных запросов MySQL. Вывод содержимого log-файла командой “tail mysql_slow.log”
Использование log-файлов для отладки работы web-сайтов
Если, например, конкретный web-сайт показывает в браузере ошибку 500, то можно зайти в этот файл и посмотреть, что именно происходит на сервере.

Пример: просмотр лог-файла ошибок web-сервера из панели провайдера Beget через файл-менеджер

При работе с лог-файлами web-сервера на виртуальном сервере необходимо знать, в каком каталоге находятся log-файлы для того или иного сайта. Это зависит от установленного на сервере программного обеспечения, в частности, - от конкретной панели управления.

Пример: содержимое рабочего каталога панели VestaCP. Виден каталог logs, в котором хранятся log-файлы
- проблему с файлом .htaccess;
- ошибку подключения к серверу базы данных;
- ошибку языка PHP.

Использование log-файлов для аналитики
Любому владельцу сайта нужно знать аудиторию своих посетителей. Эта информация содержится в лог-файлах посещений web-сервера (access.log). Для удобной обработки информации провайдеры хостинга, а также панели управления предлагают такие системы: Webalizer и AWStats.
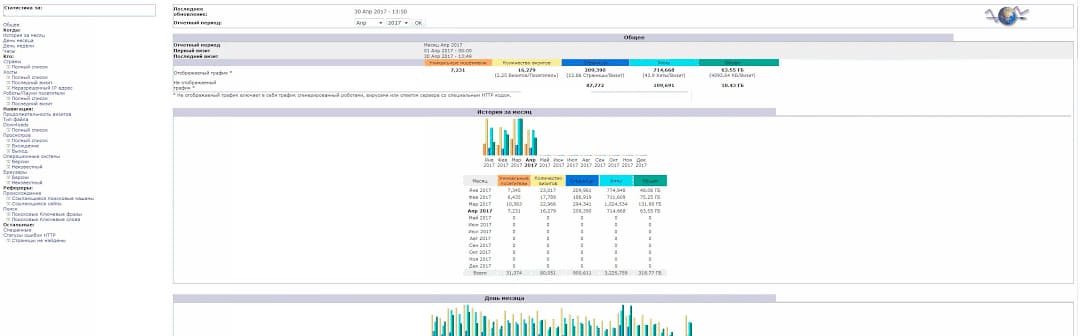
Пример: аналитика посещений web-сайта с использованием системы AWStats
Также на основе лог-файлов можно получить представление о распределении нагрузки на сайт по времени суток, следить за ошибками ненайденных страниц, вести мониторинг безопасности.
Любому владельцу интернет-ресурса необходимо знать, насколько он информативен, удобен в работе и популярен у посетителей. А значит, как минимум, нужно получить представление о посещаемости ресурса, о наиболее востребованных его разделах, а также о том, не уходят ли с сайта посетители, не достигнув цели (то есть по причине того, что нужную им страницу не удалось загрузить или на нее непросто попасть). Тем же, кто связывает со своим проектом далекоидущие коммерческие планы, необходимо иметь больше информации о сайте и его посетителях. Например, следует учитывать аудиторию — то есть идентифицировать пришедших на сайт пользователей (имя хоста1, браузер, система), фиксировать ресурсы, с которых они пришли, сколько времени провели на исследуемом ресурсе, сколько страниц посетили, куда перешли и т.п. Нужно также контролировать действия посетителей, в частности выявлять, к какой информации они проявляют повышенный интерес, что загружают, по каким ссылкам щелкают и пр., а кроме того, оценивать результативность проведения рекламных кампаний, вести учет эффективности партнерских ссылок, контролировать окупаемость инвестиций (ROI2 ) и т.д. В случае же позиционирования сайта в сфере электронной торговли спектр анализируемых параметров еще шире (в таком случае требуется применение специализированных решений, которые в данной статье не рассматриваются, за исключением Google Analytics).
В общем, разработка любого успешного интернет-проекта немыслима без точных инструментов анализа его работы, которые помогут принять верные решения относительно дальнейшего развития сайта, лучше понять предпочтения клиентов, повысить отдачу от рекламы и т.п.
Методы подсчета статистики посещаемости сайта
Теоретически существует два основных метода подсчета статистики: использование анализатора логов и применение счетчика посещений. Каждый из названных методов имеет свои плюсы и минусы, однако в большинстве случаев более просты в применении и подходят для широкого круга пользователей именно счетчики, а лог-анализаторы, как правило, сложны в настройке (требуется специальная подготовка конфигурационных файлов), а потому в большей степени ориентированы на профессионалов. Хотя при желании можно отыскать и простые в применении анализаторы логов (правда, все подобные решения оказываются платными и чаще всего достаточно дорогими), и не совсем банальные в использовании счетчики. При этом ни один из методов не обеспечивает полной достоверности статистических данных, и на практике показания счетчиков и лог-анализаторов могут различаться в десятки раз. Оптимальным решением является комбинация обоих методов сбора информации, поскольку только в этом случае возможно получить наиболее близкие к реальности данные.
В отличие от анализаторов, счетчики посещений собирают данные для анализа самостоятельно, правда для этого требуется разместить на страницах исследуемого сайта специальный код, по которому при обращении к странице (когда наряду с содержимым сайта загружается еще и внешний элемент — чаще всего картинка) записываются данные о посетителе. Счетчики ведут общую статистику посещаемости с детальным распределением по времени, фиксируют хосты и хиты, выявляют уникальных посетителей (с подробной информацией о каждом из них — IP-адрес, браузер, ОС, новый/старый и др.) вкупе с количеством посещенных ими страниц и временем пребывания на каждой из них. Кроме того, счетчики фиксируют рефереров, нередко могут запоминать данные о путях перемещения посетителя по сайту, начиная с точки захода на сайт и заканчивая точкой выхода, могут определять информацию о цветности, разрешении экрана, языке браузера и пр.
Счетчики бывают внешними и внутренними. Первые реализованы как веб-сервисы и управляются с удаленного сервера, на которых и хранится вся собираемая информация. Данный тип статистики широко распространен и прельщает многих пользователей относительной бесплатностью (на самом деле никакой благотворительности тут нет, так как на сайте размещается картинка с логотипом соответствующего сервиса, по сути представляющая собой его рекламу) и простотой использования. Внешние счетчики не обеспечивают получение статистики в режиме реального времени (они выдают ее с некоторым опозданием) и не умеют отслеживать роботов. Кроме того, собираемая ими информация хранится на внешнем сервере, а это небезопасно. Для бесплатных счетчиков можно назвать еще ряд минусов. Во-первых, никто не гарантирует бесперебойной работы счетчика (или хотя бы uptime в 99%) и высокой скорости загрузки сайта со счетчиком. Во-вторых, на сайт придется устанавливать видимые картинки счетчика с логотипом соответствующего веб-сервиса, которые, как правило, совсем не вписываются в дизайн сайта. В-третьих, не всегда есть возможность получить услугу анонимно, то есть без регистрации в различных рейтингах и каталогах.
Внутренние счетчики (или внутренние системы статистики) управляются с собственного сервера и представлены отдельными модулями, которые устанавливаются со стороны клиента либо интегрируются в систему управления сайтом. Они обеспечивают доступ к статистике в режиме реального времени и гарантируют конфиденциальность информации. Разработчики сайтов для установки подобных счетчиков пишут требуемые модули самостоятельно либо прибегают к независимым коммерческим решениям, которые в большинстве своем обеспечивают получение очень широкого спектра статистической информации, важной как для администраторов сайтов, так и для маркетологов.
Лог-анализаторы
Наиболее известными из существующих некоммерческих анализаторов логов, наверное, стоит признать пакеты Analog, Webalizer и AWStats. Они широко применяются даже несмотря на то, что давно не развиваются — исключение составляет AWStats, у которого иногда выходят обновления. В частности, данные лог-анализаторы нередко предлагают хостинговые компании в качестве бесплатного сервиса, обеспечивающего доступ к детальной информации серверных логов. Из коммерческих продуктов в качестве примеров лог-анализаторов можно привести такие решения, как Deep Log Analyzer, WebLog Expert и AlterWind Log Analyzer. Мы рассмотрим пакет AlterWind Log Analyzer, созданный российскими разработчиками и хорошо известный не только в России, но и во всем мире.
Помимо специальных пакетов для анализа логов работать с серверными логами иногда могут и другие решения — например пакеты, предназначенные для аудита и оптимизации сайтов (см. статью «Обзор решений для поисковой оптимизации»), в частности Page Promoter и Semonitor. Функциональность всех названных решений отражена в табл. 1.
Что мы получили в итоге.

1. Подготовка исходных данных.

Дальнейшее изложение посвящено наше попытке анализа логов на примере логов nginx — как самых информативных и объемных в нашей системе на данный момент.
2. Сбор логов в единый центр.
На нашей площадке исходно была решена вторая часть задачи — все логи изначально пишутся на сетевое хранилище. Для упрощения в прототипе своего анализатора мы просто читаем логи по nfs. Чем это плохо в принципе — запись логов тратит ресурсы всей системы круглые сутки, доступность логов зависит от исправности сетевого хранилища (у Вас никогда не падал NetApp посреди рабочего дня?), буферизация записи усложняет алгоритм разбора логов. Также в лог файл пишется строка в текстовом формате, если пересылать данные о запросе в сериализованном виде — избежим затрат на парсинг на стороне приемника.
2.5 Парсинг логов.
- если файлов много — храните дескрипторы, вместо открытия файла всякий раз, не так много по времени, но хранилищу станет приятней
- reg exp по нашему формату обрабатывал 700 строк в секунду, после перехода на формат со стандартным разделителем и заменой регулярки на split скорость возросла до 10-20 тысяч строк в секунду. Здесь цифры говорят лучше внутренних убеждений
- если время итерации меньше двух-трех секунд — сделайте небольшой sleep, хранилищу станет еще приятней, что его не дергают на stat сотен файлов каждую секунду
- batch_insert сделает приятно базе, но у mongo есть ограничение в 16MB на один вызов insert (4MB до 2.2)
Всех этих прелестей можно избежать отсылая данные по udp.
3. Временное хранилище для обсчета аналитики и поиска.
Хранить все данные за много времени вместе с индексами можно, но ОЧЕНЬ дорого. В реальной жизни используется временное хранилище с возможностью строить аналитику с данными за последние несколько часов — сутки. Для оперативной диагностики больше данных не имеют смысла, глобально исторические отчеты всегда можно построить по сырым данным.
Мы используем MongoDB потому что … нам так захотелось. Грубо, но это так — Вы можете выбрать любой инструмент, в котором Вы будете готовы реализовывать подобную систему. Чем более удобно и быстро реализуется группировка записей и обновление данных в хранилище, тем лучше.
- capped collections — fifo коллекция записей, в нашем случае пока вполне хватает коллекции в 3GB, файлы которой лежат на ramdisk
- aggregation framework — новая фишка с версии 2.2, под наши задачи группирует посекундные 1.200-10.000 за 50-200мс
- ttl collections — коллекции, где можно указать время жизни записей (аналог expire в memcache), imho несколько сыро
- скорость записи в один поток — 5-6 тысяч записей в секунду, можно масштабировать несколькими потоками записи
- в версии 2.2.0-rc0 в aggregation $project можно было передавать в оператор $add строки, таким образом формировался ключ группы из нескольких полей, в версии 2.2.0-rc1 и выше такой возможности нет, а оператор $concat обещается в 2.3.x без каких-либо сроков. Пришлось обходить на уровень выше, в парсере — записью группового ключа в каждую запись
- чем больше индексов будет создано, тем медленней будет вставка. Чем меньше индексов — тем меньше возможностей для поиска. У нас сейчас два индекса — системный идентификатор и timestamp из записи. Больше на тестовом стенде мы себе позволить не можем.
- capped collection не шардится встроенными средствами, это придется делать на уровне приложения.
Несмотря на вторую граблю относительно сложный запрос “выяснить top-50 IP по числу запросов, нагрузке на бекенд, трафику за последнюю минуту” вычисляется за 800-1200мс. В нашем случае одна железяка обслуживает запись данных и их вытеснение (master), на вторую идет реплика, чтобы обсчет аналитики не тормозил запись.
- memory based база данных
- встроенный язык lua для хранимых процедур
- доступность автора на русском языке и high perfomance тусовках в Москве
4. Агрегаты, персентили …
На прошлых этапах мы получили массив записей из лог файлов узлов нашей системы, доступный для быстрого поиска и группировки по необходимым правилам. Наш тестовый скрипт на Perl подготавливает данные следующим куском
На выходе получаем ссылку на массив предварительно сгруппированных данных, которые в дальнейшем превращаем в конечные метрики. В нашем случае нас интересуют общие метрики крутости=нагруженности площадки, показатели времени ответа конечным пользователям в целом/по типам контента, эффективность наших кешей, число ошибок. Примерная картина по площадке в целом может выглядеть как на скрине в начале поста. Наборы попроектных/посистемных метрик формируются из пожеланий службы эксплуатации, администраторских групп (у нас например отдельный экран посвящен запросам к полнотекстовому индексу из разных проектов — чтобы видеть источник нагрузки на узел), разработчиков, владельцев сайтов и непосредственного руководства. После первой демонстрации у нас из пожеланий стали формироваться один-два экрана в неделю.
Ключевое требование к обсчету — время обсчета временного интервала и загрузки в системы мониторинга должно быть меньше этого интервала.
У нас это время порядка 100-200мс на секундный интервал. Секундный интервал выбран на этапе сборки конструктора, чтобы обкатать все в самых жестких условиях. В реальных условиях больше прав на жизнь имеют 5/10/30/60-секундные средние значения.
5. Посчитали мы и что дальше?
- не решает вопросов произвольного формирования набора графиков на страницу конечным пользователем
- не приспособлен для задач мониторинга в принципе (нет отслеживания граничных значений, подсчета доступности сервиса по SLA и т.д.)
- обеспечил WOW-эффект
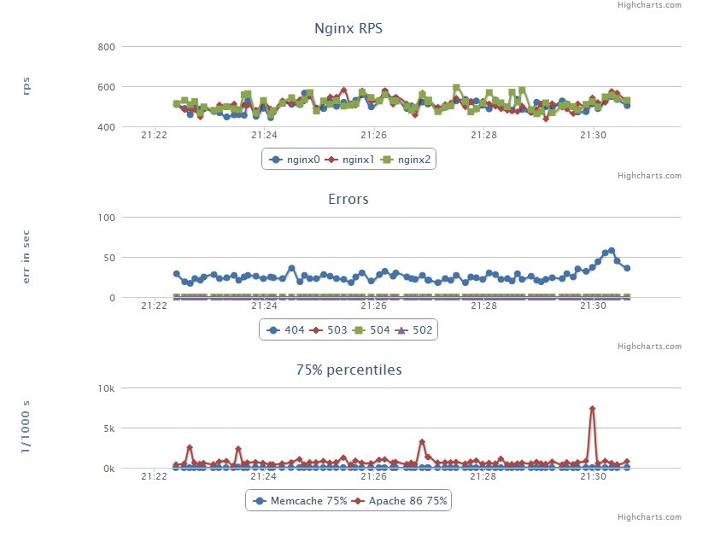
В дальнейшем оформились ключевые пожелания к системе мониторинга, куда мы грузили бы данные
- возможность заводить свои метрики
- загружать их снаружи (api/софт для загрузки)
Не так уж много, нам вполне подошел zabbix, который и показан на заглавном скрине. Здесь, как и с mongo, все зависит от личных предпочтений и конкретной ситуации. Свои метрики заводятся с типом zabbix trapper, а данные загружаются утилитой zabbix_sender в batch режиме, в качестве базы mysql. Загрузка сотни значений занимает 1-2мс.
6. Итоги
- актуальная информация по выбранным метрикам с задержкой в 90 секунд (время гарантированной записи сквозь буферы, парсинг, запись в монго, репликация на slave, обсчет)
- возможность отслеживать обработку запроса пользователя по всем узлам системы (ngx_request_id)
- понимание на самом нижнем уровне — db, чем ее грузят сверху (проброс host, request_uri, request_id внутрь информации о сессиях)
- статистика использования сервиса полнотекстового поиска проектами
- взгляд на площадку с позиции предоставляемого сервиса — генерации и раздачи контента множеством проектов
- метрики-маяки проблем, специфичные для отдельных проектов и площадки в целом
- красивые картинки для руководства
- платформа для реализации большинства возможных хотелок (должно стоять нулевым пунктом на нынешней стадии)
- отслеживать как пули долетают до конечного пользователя (время загрузки и отображения всех элементов страницы)
- сокращение окна с 90 до 30 секунд
- алгоритмы отслеживания постепенной деградации сервиса
- поиск по сырым данным — здесь нам собирают тестовый стенд со splunk и нашими данными за две недели
- адаптация xhprof под наши пожелания
Если есть желание подробней окунуться в тему — на профи тусовках за последний год тема мониторинга и профайлинга поднималась неоднократно, если в комментах будут ссылки на подобные публикации — буду только рад.
В данной заметке очерчены основные контуры нашей системы, которая только начинает обрастать конкретикой. Начальные шаги самые важные и я буду рад услышать, что положено в основу Ваших систем — принципы и технологии.

Любое обращение к серверу сайта со стороны пользователей или поисковых ботов фиксируется в специальном файле логов. Благодаря этой первичной информации у SEO-оптимизатора появляется возможность делать определенные выводы, на основе которых в будущем строится или корректируется стратегия продвижения в поисковых системах. Рассказываем, как правильно провести анализ логов сайта.
ТОП-10лучших компаний интернет-продвижения России 2020
Принципы работы web server log file
Логи сервера (журнал посещений) – текстовый файл с расширением .log (или без расширения), в котором хранится системная информация о результатах обращений к серверу, как со стороны пользователей, так и со стороны различных краулеров. Сам файл располагается в отдельной папке logs или в корне сайта, попасть туда можно либо по протоколу FTP, либо через веб-интерфейс хостинг-провайдера.
Польза изучения log-файла для SEO
Анализ логов для SEO-оптимизатора поможет понять техническое состояние сайта, получив таким образом полезные данные об отношении поисковиков к ресурсу.
Что даст эта информация:
Чем больше промежуток времени за который собраны логи (желательно не меньше месяца), тем более полную картину в итоге удастся получить.
Это поможет найти максимум закономерностей и слабых мест, а также понять общие тенденции процессов. Для определения последних, логи нужно просматривать регулярно, не реже двух раз в месяц.
Содержание и структура лог-файла
Независимо от типа сервера и его конфигурации, в файле логов присутствуют следующие данные:
- IP-адрес с которого был сделан запрос.
- Дата + время посещения.
- Пользовательский агент.
- Метод (тип) запроса:
- GET – получение содержимого страницы.
- POST – обработка и отправка чего-либо, например, комментирование или ввод других данных.
- URL-адрес (объект), к которому был совершен запрос.
- Тип браузера.
- Протокол.
- Код ответа.
Программы для анализа логов
Проводить анализ логов вручную – дело бессмысленное в большинстве случаев. Подойдет, если необходимо найти конкретно взятое посещение, но увидеть общие тенденции и прочие детали не получится. Поэтому ниже рассмотрим специализированный софт, позволяющий получить максимальное количество полезной информации.
Excel
На случай изучения логов, Excel имеет скудный инструментарий и крайне неудобную структуру просмотра данных. Подойдет для небольшого количества вводной информации, но будет сложно сформировать сводные отчеты или агрегировать выбранный тип данных.

Изучение логов в Excel
GoAccess

GoAccess
Утилита для анализа логов Apache с широким функционалом, есть возможность отслеживания и визуализации результатов в реальном времени. Имеет удобный интерфейс, предоставляющий внушительное количество информации. Больше подходит для опытных пользователей.
Splunk
Платформа, позволяющая собирать, обрабатывать и анализировать машинные данные, в том числе логи сайтов. В области анализа предоставляются широчайшие возможности по обработке целевых данных. На базе Splunk можно развернуть индивидуальный модуль по анализу логов, удобной для вас визуализацией и т.д. Не смотря на сложность решения, у платформы имеется большое сообщество, которое предлагает массу бесплатных решений.
В бесплатной версии доступна индексация данных, объемом до 500 Мб в сутки – для небольшого проекта этого будет достаточно.
Loggly

Loggly
Позволяет анализировать данные из разных источников, в том числе журналы посещений сайтов. Подходит для построения информационных дашбордов, отображающих визуализацию данных в реальном времени. Большое количество фильтров, отличная система поиска и возможность реализации оповещений на электронную почту, делают этот сервис одним из лидеров своей отрасли.
Logstash
Бесплатный сборщик логов с открытым кодом (open source), написанный на языке JRuby. Процесс работы основан на шаблонах фильтров. Сложен в освоении.
Power BI
Известный программный комплекс для всевозможной аналитики данных. Позволяет загружать их автоматически и интерпретировать в гибко настраиваемом виде. Для частного использования бесплатен, но требует некоторых знаний по настройке сбора и вывода отчетов.
Screaming Frog Log Analyzer
Screaming Frog Log Analyzer – приложение, с интуитивно понятным интерфейсом, открывает широкие возможности для чтения и аналитики log-файлов. Есть бесплатная и платная версии (99 £/год). Бесплатная имеет ограничение в 1000 строк для загружаемого файла, подойдет для изучения логов небольших сайтов с низкой посещаемостью.
Рассмотрим подробнее то, как анализировать логи сайта в этой программе.
1. Для начала работы, находим файл логов в файловой структуре сайта. В нашем случае он находится в папке «Logs» и имеет название «access.log». Многие хостинги (или сервера) разбивают журнал посещений по месяцам, мы же будем использовать файл с большим количеством данных (с 2015-2020 года). При использовании Screaming Frog Log Analyzer, помните об ограничениях для бесплатной версии.
2. После установки и запуска программы, перед нами открывается главное окно, в левой колонке которого будут отображаться прошлые проекты. Для начала работы с файлом логов, необходимо простым перетаскиванием поместить его в область Drag&Drop, после чего начнется загрузка данных.

Перемещаем файл в область Drag&Drop

Дождаться окончания загрузки
3. Сразу после загрузки файла, появятся сводные данные по разным событиям:

Графики данных
4. Пройдемся по основным вкладкам.

Вкладка URLs

Вкладка User Agents

Вкладка «События»
- Раздел «Directories» позволяет отобразить файловую структуру сайта глазами поисковых (и не только) ботов. Каждую папку можно раскрыть и посмотреть по ней дополнительную информацию в событиях.

Раздел «Directories»
- «IP» – отображает список ip-адресов, которые приходили на сайт, по каждому из них доступны данные о посещенных URL-адресах.

Анализ по «IP»
Хочется отметить несколько функций программы, которые доступны в любой вкладке, и облегчающие процесс аналитики логов. Данные в Screaming Frog Log Analyzer представляются в виде таблицы, выделив каждую из строк, получаем доступ к расширенной информации. Каждый из двух блоков можно экспортировать в файлы Excel (.csv/.xls/.xlsx).

Экспорт данных из Screaming Frog Log Analyzer
Программа изначально заточена на аналитику под SEO, поэтому имеет специальный фильтр для сортировки ботов поисковых систем:
- Googlebot.
- Googlebot Smartphone.
- Bingbot.
- Yandex.
- Baidu.

Фильтр для сортировки ботов
Как упоминалось выше, хостинг-провайдеры часто дробят log-файлы по временным отрезкам. Поэтому, если требуется к проекту импортировать дополнительные логи, то достаточно перейти в одноименную вкладку и загрузить файлы.

Дополнительная загрузка файла
Не забываем о возможности выделять диапазоны дат, удобно при большом количестве данных.

Выбираем нужные даты
Теперь понятен принцип сбора и формирования файла логов сайта и его практическое значение в разрезе поисковой оптимизации. Приведен список наиболее популярных решений, позволяющих интерпретировать данные из журнала посещений, а также разобран пошаговый процесс аналитики log-файла в программе Screaming Frog Log Analyzer.
Читайте также: