
Как узнать кодировку rtf файла
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или --mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
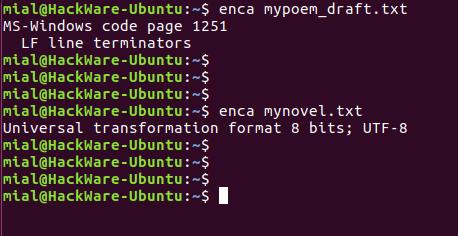
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
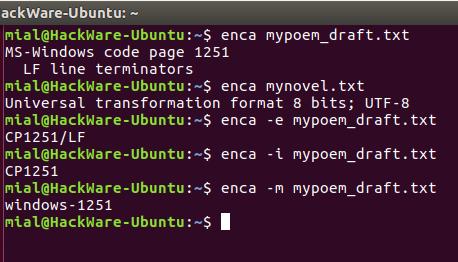
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.

то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или --from-code означает кодировку исходного файла -t или --to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
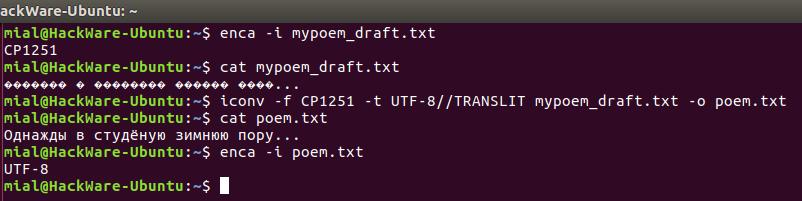
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке "Кириллица (Windows)" знаку "Й" соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка "Кириллица (Windows)", компьютер считывает число 201 и выводит на экран знак "Й".
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка "Западноевропейская (Windows)", знак "Й" из исходного текстового файла на основе кириллицы будет отображен как "É", поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Выполните одно из указанных ниже действий.
В Windows 7
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке "Китайская традиционная (Big5)". В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке "Кириллица (Windows)", текст на иврите не отобразится, а если сохранить его в кодировке "Иврит (Windows)", то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
В моей файловой системе (Windows 7) у меня есть несколько текстовых файлов (это файлы сценариев SQL, если это имеет значение).
При открытии с помощью Notepad ++ в меню «Кодировка» сообщается, что некоторые из них имеют кодировку «UCS-2 Little Endian», а некоторые - «UTF-8 без BOM».
В чем здесь разница? Все они кажутся совершенно правильными сценариями. Как я могу сказать, какие кодировки у файла без Notepad ++?
Существует довольно простой способ использования Firefox. Откройте файл, используя Firefox, затем выберите «Просмотр»> «Кодировка символов». Подробно здесь . использовать эвристику. Оформить заказ enca и chardet для систем POSIX. Я думаю, что альтернативный ответ - TRIAL и ERROR. iconv в частности это полезно для этой цели. По сути, вы перебираете поврежденные строки символов / текста в различных кодировках, чтобы увидеть, какой из них работает. Вы выигрываете, когда персонажи больше не портятся. Я хотел бы ответить здесь, с программным примером. Но это, к сожалению, защищенный вопрос. FF использует детекторы Mozilla Charset . Еще один простой способ - открыть файл с помощью MS word, он будет правильно угадывать файлы даже для различных древних китайских и японских Если chardet или chardetect не доступно в вашей системе, вы можете установить пакет через менеджер пакетов (например, apt search chardet - на ubuntu / debian, обычно называемый пакетом python-chardet или python3-chardet ), или через pip с pip install chardet (или pip install cchardet для более быстрой версии c-optimized).Файлы обычно указывают свою кодировку с заголовком файла. Есть много примеров здесь . Однако даже читая заголовок, вы никогда не можете быть уверены, какую кодировку файл действительно использует .
Например, файл с первыми тремя байтами 0xEF,0xBB,0xBF , вероятно , является файлом в кодировке UTF-8. Однако это может быть файл ISO-8859-1, который начинается с символов  . Или это может быть совершенно другой тип файла.
Notepad ++ делает все возможное, чтобы угадать, какую кодировку использует файл, и в большинстве случаев он делает это правильно. Хотя иногда это не так - поэтому меню «Кодировка» есть, поэтому вы можете отменить его лучшее предположение.
Для двух кодировок вы упоминаете:
- Файлы "Little Endian UCS-2" - это файлы UTF-16 (основанные на том, что я понимаю из информации здесь ), поэтому, вероятно, начнем с 0xFF,0xFE первых 2 байтов. Из того, что я могу сказать, Notepad ++ описывает их как «UCS-2», поскольку он не поддерживает определенные аспекты UTF-16.
- Файлы «UTF-8 без BOM» не имеют байтов заголовков. Вот что означает бит «без спецификации».
Тебе нельзя. Если бы вы могли это сделать, не было бы так много веб-сайтов или текстовых файлов со «случайным бредом». Вот почему кодирование обычно отправляется вместе с полезной нагрузкой в виде метаданных.
В противном случае все, что вы можете сделать, - это «умное предположение», но результат часто неоднозначен, поскольку одна и та же последовательность байтов может быть допустимой в нескольких кодировках.
В моей файловой системе (Windows 7) у меня есть несколько текстовых файлов (это файлы сценариев SQL, если это имеет значение).
При открытии с помощью Notepad ++ в меню «Кодировка» сообщается, что некоторые из них имеют кодировку «UCS-2 Little Endian», а некоторые - «UTF-8 без BOM».
В чем здесь разница? Все они кажутся совершенно правильными сценариями. Как я могу сказать, какие кодировки у файла без Notepad ++?
Существует довольно простой способ использования Firefox. Откройте файл, используя Firefox, затем выберите «Просмотр»> «Кодировка символов». Подробно здесь . использовать эвристику. Оформить заказ enca и chardet для систем POSIX. Я думаю, что альтернативный ответ - TRIAL и ERROR. iconv в частности это полезно для этой цели. По сути, вы перебираете поврежденные строки символов / текста в различных кодировках, чтобы увидеть, какой из них работает. Вы выигрываете, когда персонажи больше не портятся. Я хотел бы ответить здесь, с программным примером. Но это, к сожалению, защищенный вопрос. FF использует детекторы Mozilla Charset . Еще один простой способ - открыть файл с помощью MS word, он будет правильно угадывать файлы даже для различных древних китайских и японских Если chardet или chardetect не доступно в вашей системе, вы можете установить пакет через менеджер пакетов (например, apt search chardet - на ubuntu / debian, обычно называемый пакетом python-chardet или python3-chardet ), или через pip с pip install chardet (или pip install cchardet для более быстрой версии c-optimized).Файлы обычно указывают свою кодировку с заголовком файла. Есть много примеров здесь . Однако даже читая заголовок, вы никогда не можете быть уверены, какую кодировку файл действительно использует .
Например, файл с первыми тремя байтами 0xEF,0xBB,0xBF , вероятно , является файлом в кодировке UTF-8. Однако это может быть файл ISO-8859-1, который начинается с символов  . Или это может быть совершенно другой тип файла.
Notepad ++ делает все возможное, чтобы угадать, какую кодировку использует файл, и в большинстве случаев он делает это правильно. Хотя иногда это не так - поэтому меню «Кодировка» есть, поэтому вы можете отменить его лучшее предположение.
Для двух кодировок вы упоминаете:
- Файлы "Little Endian UCS-2" - это файлы UTF-16 (основанные на том, что я понимаю из информации здесь ), поэтому, вероятно, начнем с 0xFF,0xFE первых 2 байтов. Из того, что я могу сказать, Notepad ++ описывает их как «UCS-2», поскольку он не поддерживает определенные аспекты UTF-16.
- Файлы «UTF-8 без BOM» не имеют байтов заголовков. Вот что означает бит «без спецификации».
Тебе нельзя. Если бы вы могли это сделать, не было бы так много веб-сайтов или текстовых файлов со «случайным бредом». Вот почему кодирование обычно отправляется вместе с полезной нагрузкой в виде метаданных.
В противном случае все, что вы можете сделать, - это «умное предположение», но результат часто неоднозначен, поскольку одна и та же последовательность байтов может быть допустимой в нескольких кодировках.
Читайте также: