
Как создать функцию в r studio
Недавно мы рассказали, для чего нужен и что умеет язык R. Теперь познакомимся с ним поближе и посмотрим, из чего он состоит и как на нём пишутся программы. На самом деле здесь 9 конструкций, но 10 звучит круче.
👉 Точка с запятой в R не ставится.
Комментарии
Для комментариев в R используют решётку, как и в большинстве языков:
Переменные и векторы
Чтобы объявить переменную, достаточно объявить её имя и присвоить ей что-нибудь, а R сам разберётся, какой тип тут нужен:
Если говорить совсем точно, то в R существует много структур данных: векторы, матрицы, списки, факторы и так далее. Самым важным считается вектор — это набор элементов, у которых одинаковый тип данных.
Сами типы векторов такие:
- логический (logical),
- целочисленный (integer),
- вещественный (double),
- комплексный (complex),
- символьный (character),
- двоичные данные (raw).
👉 С векторами можно делать любые операции из векторной алгебры. Если что — у нас есть отличный цикл про векторы и матрицы. Матрицы в R тоже есть.
Внешние модули
Сила языка R — во внешних модулях или пакетах, которые существенно расширяют возможности базового набора команд. Они позволяют быстрее строить нейросети, вторые — анализировать данные, а третьи заточены на работу со статистикой.
Чтобы подключить внешний модуль, используют команду library():
Ввод и вывод
Для вывода значения переменной достаточно просто написать её имя:
Если нужно вывести график функции, можно использовать стандартную команду plot() — она построит график в виде точек, гистограмм или соединит всё линиями.
Так как R предназначен для работы с большими объёмами данных, то ввод данных идёт не с клавиатуры, а из файлов:
Но если нужен ввод с клавиатуры, используйте команду readline():
Присваивание и сравнение
Сравнение обозначается как обычно, двойным знаком равно:
А вот присваивания есть два, стрелка и знак равенства.
Если не вдаваться в нюансы использования, то стрелка отвечает за глобальное использование переменной, чтобы она была видна всем, а знак равенства — за локальное использование, то есть внутри какой-то подпрограммы.
Условный оператор if
В нём никаких сюрпризов: фигурные скобки, как в JavaScript, и скобки для выражения, которое проверяем:
Цикл for
А вот цикл for похож уже на Python с его диапазоном для организации шага цикла. Остальное всё то же самое — фигурные скобки тоже нужны для группировки нескольких команд:
Функции
Работают и объявляются точно так же, как и в других языках высокого уровня. Единственное отличие в том, что функция объявляется не сама по себе, а как бы отправляется в переменную (как стрелочная функция в JavaScript):
Классы, методы и объекты
R — полностью объектно-ориентированный язык. Каждый элемент в нём — это объект, даже функции и таблицы. Поэтому всё, что работает в ООП (классы, методы и объекты), работает и в R, но на более сложном уровне абстракции.
В R можно посмотреть список всех доступных методов для любого объекта с помощью команды methods(). Например, если нам нужно понять, какие методы есть у команды plot(), которая рисует нам график, то нам нужно написать в консоли среды разработки: methods(plot)
В ответ мы получим все доступные методы:
Кстати, метод default срабатывает, когда plot() получает на обработку объект неизвестного ей класса.
Общий подход к функции состоит в том, чтобы использовать часть аргумента в качестве входных данных , передать часть тела и, наконец, вернуть выходные данные . Синтаксис функции следующий:
В этом уроке мы узнаем
R важные встроенные функции
В R. Есть много встроенных функций в R. R сопоставляет ваши входные параметры с аргументами функции, либо по значению, либо по положению, а затем выполняет тело функции. Аргументы функции могут иметь значения по умолчанию: если вы не укажете эти аргументы, R примет значение по умолчанию.
Примечание . Исходный код функции можно увидеть, запустив имя самой функции в консоли.

Мы увидим три группы функций в действии
- Общая функция
- Математическая функция
- Статистическая функция
Общие функции
Мы уже знакомы с общими функциями, такими как функции cbind (), rbind (), range (), sort (), order (). Каждая из этих функций имеет определенную задачу, принимает аргументы для возврата вывода. Ниже приведены важные функции, которые нужно знать:
функция diff ()
Если вы работаете с временными рядами , вам нужно фиксировать ряды, принимая их значения запаздывания . Стационарный процесс позволяет постоянно среднее значение, дисперсия и автокорреляция с течением времени. Это в основном улучшает прогнозирование временного ряда. Это легко сделать с помощью функции diff (). Мы можем построить случайные данные временных рядов с трендом, а затем использовать функцию diff () для стационарного ряда. Функция diff () принимает один аргумент, вектор и возвращает подходящую задержанную и повторенную разницу.
Примечание : нам часто нужно создавать случайные данные, но для изучения и сравнения мы хотим, чтобы числа были одинаковыми на разных машинах. Чтобы все мы генерировали одни и те же данные, мы используем функцию set.seed () с произвольными значениями 123. Функция set.seed () генерируется в процессе генерации псевдослучайных чисел, которая заставляет все современные компьютеры иметь одинаковую последовательность чисел. Если мы не используем функцию set.seed (), мы все будем иметь разную последовательность чисел.

функция length ()
Во многих случаях мы хотим знать длину вектора для вычисления или для использования в цикле for. Функция length () считает количество строк в векторе x. Следующие коды импортируют набор данных автомобилей и возвращают количество строк.
Примечание : length () возвращает количество элементов в векторе. Если функция передается в матрицу или фрейм данных, возвращается число столбцов.
Вывод:
Вывод:
Математические функции
R имеет массив математических функций.
| оператор | Описание |
|---|---|
| абс (х) | Принимает абсолютное значение х |
| Журнал (х, база = у) | Принимает логарифм x с основанием y; если база не указана, возвращает натуральный логарифм |
| ехр (х) | Возвращает экспоненту х |
| SQRT (х) | Возвращает квадратный корень из х |
| факториала (х) | Возвращает факториал x (x!) |
Вывод:
Вывод:
Вывод:
Статистические функции
Стандартная установка R содержит широкий спектр статистических функций. В этом уроке мы кратко рассмотрим наиболее важную функцию.
Основные статистические функции
Среднее значение х
Стандартное отклонение х
Стандартные оценки (Z-оценки) х
Резюме x: среднее, минимальное, максимальное и т. Д.
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
До этого момента мы узнали много встроенных функций R.
Примечание : будьте осторожны с классом аргумента, то есть с числовым, логическим или строковым. Например, если нам нужно передать строковое значение, нам нужно заключить строку в кавычку: «ABC».
Написать функцию в R
В некоторых случаях нам нужно написать собственную функцию, потому что мы должны выполнить определенную задачу, а готовой функции не существует. Пользовательская функция включает в себя имя , аргументы и тело .
Примечание . Рекомендуется называть пользовательскую функцию отличной от встроенной функции. Это позволяет избежать путаницы.
Функция с одним аргументом
В следующем фрагменте мы определяем простую квадратную функцию. Функция принимает значение и возвращает квадрат значения.
Объяснение кода:
Когда вы закончите использовать функцию, мы можем удалить ее с помощью функции rm ().
Окружающая среда
В R среда представляет собой набор объектов, таких как функции, переменные, фрейм данных и т. Д.
R открывает окружение каждый раз, когда запрашивается Rstudio.
Доступной средой верхнего уровня является глобальная среда , называемая R_GlobalEnv. И у нас есть местная среда.
Мы можем перечислить содержимое текущей среды.
Вывод
Вы можете увидеть все переменные и функции, созданные в R_GlobalEnv.
Приведенный выше список будет отличаться для вас в зависимости от исторического кода, который вы выполняете в R Studio.
Обратите внимание, что аргумент функции square_function n не находится в этой глобальной среде .
Новая среда создается для каждой функции. В приведенном выше примере функция square_function () создает новую среду внутри глобальной среды.
Чтобы прояснить разницу между глобальной и локальной средой , давайте изучим следующий пример
Эти функции принимают значение x в качестве аргумента и добавляют его к y, определяемому снаружи и внутри функции.

Функция f возвращает результат 15. Это потому, что у определяется в глобальной среде. Любая переменная, определенная в глобальной среде, может использоваться локально. Переменная y имеет значение 10 во время всех вызовов функций и доступна в любое время.
Посмотрим, что произойдет, если переменная y определена внутри функции.
Нам нужно сбросить `y` перед запуском этого кода, используя rm r

Выход также равен 15, когда мы вызываем f (5), но возвращает ошибку, когда мы пытаемся вывести значение y. Переменная y не находится в глобальной среде.
Наконец, R использует самое последнее определение переменной для передачи внутри тела функции. Давайте рассмотрим следующий пример:

R игнорирует значения y, определенные вне функции, потому что мы явно создали переменную y внутри тела функции.
Функция нескольких аргументов
Мы можем написать функцию с более чем одним аргументом. Рассмотрим функцию под названием «раз». Это простая функция, умножающая две переменные.
Вывод:
Когда мы должны написать функцию?
Специалист по данным должен сделать много повторяющихся задач. Большую часть времени мы копируем и вставляем куски кода многократно. Например, нормализация переменной настоятельно рекомендуется, прежде чем мы запустим алгоритм машинного обучения. Формула для нормализации переменной:
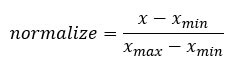
Мы продолжим в два шага, чтобы вычислить функцию, описанную выше. На первом шаге мы создадим переменную с именем c1_norm, которая будет масштабировать c1. На втором шаге мы просто копируем и вставляем код c1_norm и меняем его на c2 и c3.
Деталь функции со столбцом c1:
Номинатор:: data_frame $ c1 -min (data_frame $ c1))
Знаменатель: max (data_frame $ c1) -min (data_frame $ c1))
Следовательно, мы можем разделить их, чтобы получить нормализованное значение столбца c1:
Мы можем создать c1_norm, c2_norm и c3_norm:
Вывод:
Оно работает. Мы можем скопировать и вставить
затем измените c1_norm на c2_norm и c1 на c2. Мы делаем то же самое, чтобы создать c3_norm
Мы отлично перемасштабировали переменные c1, c2 и c3.
Однако этот метод подвержен ошибкам. Мы могли бы скопировать и забыть изменить имя столбца после вставки. Поэтому рекомендуется писать функцию каждый раз, когда вам нужно вставить один и тот же код более двух раз. Мы можем преобразовать код в формулу и вызывать его всякий раз, когда это необходимо. Чтобы написать нашу собственную функцию, нам нужно дать:
- Название: нормализовать.
- количество аргументов: нам нужен только один аргумент, который является столбцом, который мы используем в наших вычислениях.
- Тело: это просто формула, которую мы хотим вернуть.
Мы продолжим шаг за шагом, чтобы создать функцию нормализации.
Шаг 1) Создаем номинатор , который есть. В R мы можем хранить знаменатель в переменной следующим образом:
Шаг 2) Вычислим знаменатель: . Мы можем повторить идею шага 1 и сохранить вычисления в переменной:
Шаг 3) Мы выполняем разделение между знаменателем и знаменателем.
Шаг 4) Чтобы вернуть значение вызывающей функции, нам нужно передать нормализацию внутри return (), чтобы получить выходные данные функции.
Шаг 5) Мы готовы использовать функцию, завернув все в скобки.
Давайте проверим нашу функцию с переменной c1:
Работает отлично. Мы создали нашу первую функцию.
Функции являются более всеобъемлющим способом выполнения повторяющихся задач. Мы можем использовать формулу нормализации для разных столбцов, как показано ниже:
Хотя пример прост, мы можем вывести силу формулы. Приведенный выше код легче читается и особенно позволяет избежать ошибок при вставке кодов.
Функции с условием
Иногда нам нужно включить условия в функцию, чтобы код мог возвращать разные выходные данные.
В задачах машинного обучения нам нужно разделить набор данных между набором поездов и тестовым набором. Набор поездов позволяет алгоритму учиться на данных. Чтобы протестировать производительность нашей модели, мы можем использовать тестовый набор для возврата показателя производительности. R не имеет функции для создания двух наборов данных. Мы можем написать нашу собственную функцию для этого. Наша функция принимает два аргумента и называется split_data (). Идея проста: мы умножаем длину набора данных (т.е. количество наблюдений) на 0,8. Например, если мы хотим разделить набор данных 80/20, а наш набор данных содержит 100 строк, тогда наша функция умножит 0,8 * 100 = 80. 80 строк будут выбраны, чтобы стать нашими данными обучения.
Мы будем использовать набор данных airquality для проверки нашей пользовательской функции. Набор данных airquality состоит из 153 строк. Мы можем видеть это с кодом ниже:
Вывод:
Мы будем действовать следующим образом:
Наша функция имеет два аргумента. Поезд аргументов является логическим параметром. Если установлено значение TRUE, наша функция создает набор данных train, в противном случае создает тестовый набор данных.
Мы можем действовать так же, как и в случае с функцией normalize (). Мы пишем код, как если бы это был только одноразовый код, а затем помещаем все с условием в тело для создания функции.
Шаг 1:
Нам нужно вычислить длину набора данных. Это делается с помощью функции nrow (). Nrow возвращает общее количество строк в наборе данных. Мы называем переменную длину.
Вывод:
Шаг 2:
Умножаем длину на 0,8. Он вернет количество строк для выбора. Должно быть 153 * 0,8 = 122,4
Вывод:
Мы хотим выбрать 122 строки среди 153 строк в наборе данных качества воздуха. Мы создаем список, содержащий значения от 1 до total_row. Мы сохраняем результат в переменной с именем split
Вывод:
split выбирает первые 122 строки из набора данных. Например, мы можем видеть, что наша переменная split собирает значения 1, 2, 3, 4, 5 и так далее. Эти значения будут индексом, когда мы выберем строки для возврата.
Шаг 3:
Нам нужно выбрать строки в наборе данных airquality на основе значений, хранящихся в переменной split. Это делается так:
Вывод:
Шаг 4:
Вывод:
Шаг 5:
Мы можем создать условие внутри тела функции. Помните, у нас есть последовательность аргументов, которая по умолчанию имеет логическое значение TRUE для возврата набора поездов. Чтобы создать условие, мы используем синтаксис if:
Вот и все, мы можем написать функцию. Нам нужно только изменить airquality на df, потому что мы хотим попробовать нашу функцию для любого фрейма данных, а не только для airquality:
Давайте попробуем нашу функцию для набора данных airquality. у нас должен быть один поезд с 122 рядами и тестовый набор с 31 строкой.
В базовом пакете base есть функция read.table , которая отвечает за чтение текстовых файлов. Она имеет множество параметров, что позволяет гибко управлять процессом чтения. Эта функция возвращает data.frame.
При написании команд и функций удобно пользоваться возможность автодополнения. Для этого наберите часть команды, или имени функции или параметра и нажмите сочетание клавиш Ctrl+Пробел. В выпадающем списке можно выбрать подходящую команду.
При написании путей к папкам и файлам можно использовать либо абсолютный либо относительный путь. Например, предыдущий вызов можно оформить как
Для представления пути используются либо символы слэша (/) либо удвоенные символы обратного слэша (\). Это обусловлено тем, что обратный слэш в R это спецсимвол и добавление второго слэша его экранирует и указываает R, что следующий за ним символ надо вопринимать как обычный.
Т.е. обе эти записи пути эквивалетны: "D:/Teaching/R/introduction/md/data/sol_y1.txt" или "D:\\Teaching\\R\\introduction\\md\\data\\sol_y1.txt"
Посмотрим на данные, которые были загружены. Сделать это можно несколькими способами, вот некоторые из них
Функция read.table является не очень эффективной с точки зрения производительности. Файлы, содержащие большое число столбцов считываются очень медленно. Если попробовать прочитать файл sol_x1.txt , который содержит 4058 дескрипторов для 800 соединений, то это займет заметное время.
Можете попробовать выполнить следующий код
Для преодоления этого недостатка есть несколько вариантов, вот два из них:
1. Использовать экспериментальную функцию fread из пакета data.table .
2. Конвертировать текстовые файлы в бинарный формат и в дальнейшем работать с этими файлами.
Чтение текстовых файлов с использованием функции fread (пакет data.table)
Для просмотра загруженной таблицы в RStudio можно использовать команду
или кликнуть по имени переменной x1 в списке
Результат в обоих случаях будет одинаковым
Проверим объект какого класса получился при загрузке таблицы с использованием функции fread
Приведем объект x1 к типу data.frame
Отметим, что первая колонка содержит названия соединений. Переместим значения этой колонки в поле rownames
Проверим, что получилось.
Сохранение данных в бинарном формате
Любые объекты созданные в R можно сохранить в бинарном формате в виде файлов .RData . Это позволяет осуществлять быструю загрузку и доступ к сохраненным данным.
Таким образом можно сохранить данные из однажды прочитанного текстового файла в бинарном формате и в дальнейшем загружать эти данные из него.
Чтобы сохранить содержимое переменной x1 используем следующий вызов (указание ключевого слова file является обязательным)
Очистка рабочей области от загруженных и используемых переменных
Перед загрузкой данных, только что сохраненных в файл sol_x1.RData , сперва очистим рабочую область (удалим все загруженные переменные). Сделать это можно либо функцией rm . Приведенный вызов удалит все загруженные объекты.
Либо кликнув по кнопке Clear .
Объекты также можно удалять выборочно, указывая их названия.
Иногда при длительной работе и загрузке удалении больших объемом данных бывает полезно вызывать сборщик мусора, который принудительно очищает память от уже неиспользуемых данных.
Чтение данных в бинарном формате
Загрузим ранее сохраненный файл sol_x1.RData
Как вы могли заметить в списке загруженных переменных появилась новая с именем x1 как у ранее сохраненного data.frame.
Однако если в разных файлах сохранены объекты с одинаковым названием, то для их одновременной загрузки эти объекты необходио переименовать. Это можно во время загрузки данных, использовав следующий набор команд:
Проверим загруженный объект x1.1 на идентичность с x1
Сохранение данных в текстовом формате
Функция write.table сохраняет данные в текстовом формате. Она имеет много параметров для гибкой настройки вида сохраняемого файла.
Другие функции для работы с текстовыми файлами
Существуют различные дополнительные функции для чтения и записи текстовых файлов с определенным стилем форматирования. Подробную информацию о них можно найти в справочной системе R.
Другие способы ввода-вывода
Помимо текстовых и бинарных данных R может читать данные из различных баз данных, а также файлов MS Excel, для чего используется подключение дополнительных пакетов. В частности пакет xlsx позволяет работать с данными, сохраненными в одноименном формате.
Создание пользовательских функций
Если часто используется одна и та же последовательность команд, то целесообразнее создать функцию, которая бы их выполняла автоматически. Это существенно упрощает текст программы, делает его более модульным, читабельным и простым для внесения изменений.
Создадим простейшую функцию рассчитывающую разность двух векторов
Важно отметить, что при передаче параметров в функции, можно не использовать названия параметров только в том случае, если соблюдается порядок следования параметров. В противном случае необходимо указывать названия параметров.
Продемонстрируем области видимости переменных на примере собственных функций.
Создадим вектор x и вызовем созданную нами функцию. Результат функции это измененный вектор x , однако сам вектор x не изменился.
Таким образом все что передается в функцию попадает в локальную области видимости только этой функции как и все изменения.
Реализуем собственную функцию загрузки бинарных файлов
Ключевое слово return в завершении функции писать не обязательно. По умолчанию функция возвращает результат последней операции.
Для того чтобы сохранить созданную функцию текст функции посещается в (новый) файл R script, который можно создать вызвав меню File - New file - R script или нажав комбинацию Ctrl + Shift + N. После чего пишется текст функции и файл сохраняется с расширением “.R”.
Для загрузки функции из файла используется функция source . Но предварительно очистим содержимое рабочей области.
После чего для загрузки бинарного файла достаточно вызвать
Ранее для чтения текстового файла с дескрипторами мы использовали следующий вызов.
Если часто использовать ее для чтения файлов, то удобнее создать собственную функцию. Создадим два варианта.
Первый вариант
Троеточие используется для передачи дополнительных параметров внутрь функций.
Тогда для загрузки файлов с дескрипторами достаточно вызвать
Какие достоинства и недостатки у каждого из вариантов?
Задания
- Создать функцию, которая будет считывать текстовый файл, содержащий дескрипторы, с использованием функции fread, и возвращать data.frame.
- Прочитать с использованием функции из п.1 и сохранить в бинарном формате файл sol_x2.txt .
- Прочитать файл sol_y1.txt , конвертировать загруженные данные в именованный вектор и сохранить его в бинарном формате. Создать для этого соответствующую функцию.
- Повторить операции п.3 для файла sol_y2.txt
Манипуляции с данными
Векторы
Загрузим файл sol_y1.RData и определим среднее значение растворимости в выборке, медианное значение, максимальное и минимальное значения.
Все приведенные функции векторизированы, поэтому расчет происходит очень быстро и эффективно.
Функция summary возвращает всю вышеприведенную статистику в виде одного вектора значений.
Помимо этих есть еще множество функций рассчета различных статистических характеристик.
Data.frames
Продемонстрируем работу с data.frames на примере.
Есть два набора соединений с рассчитанными дескрипторами и их необходимо объединить в один data.frame.
Загрузим оба имеющихся файла данных:
Проверим размерность загруженных данных. Функция dim возвращает размерность данных (число строк и число столбцов), другими словами число соединений и число дескрипторов.
Поскольку число дескрипторов отличается, то выясним какие дескрипторы отсутствуют в каждом из наборов данных.
Функция setdiff возвращает элементы первого вектора, которые отсутствуют во втором
var.names1 содержит имена дескрипторов, которые присутствуют в x1 и отсутствуют в x2 . Аналогично для var.names2 .
Посмотрим сколько таких дескриптров в каждом случае
Т.е. первый набор данных содержит 923 дескриптора, которые отсутствуют вов втором наборе, а второй - 383, которые отсутствуют в первом.
Поскольку мы используем фрагментные дескрипторы, то их отсутствие фактически означает, что число дескриторов данного вида равно нулю. Следовательно мы должны добавить отсутствующие дескрипторы в каждый набор данных и приравнять все их значения нулю.
Чтобы добавить нулевые значения этим дескрипторам мы вызываем их для соответствующего data.frame и присваиваем значение 0 .
Проверям размерность полученных данных
Число колонок (дескрипторов) теперь идентично. Проверим порядок следования дескриптров в каждом наборе, используя следующую конструкцию
Выражение в скобках возвращает вектор логических значений, который содержит TRUE в случае если на одинаковых позициях находятся одинаковые значения и FALSE в противном случае. Функция all возвращает TRUE , если все значения логического вектора равны TRUE .
Проверим действительно ли имена дескрипторов в обоих data.frames совпадают и мы ничего не упустили. Используем для этого функцию %in% , которая принимает два вектора, и если значение первого вектора присутствует во втором, то для этого элемента возвращается значение TRUE . Таким образом выражение записанное ниже можно прочитать как “все ли названия колонок первого набора данных присутствуют во втором наборе”
Аналогично выполняется проверка для второго набора
Две эти проверки можно заменить одной, если предварительно отсортировать имена колонок в обоих наборах почле чего сравнить их
Теперь перед объединением строк обоих data.frames необходимо расположить колонки в одинаковом порядке. Воспользуемся для этого свойством индексов и расположим колонки в x2 в той же последовательности что и в x1
Теперь колонки расположены в одной последовательности. Проверим
Полученные data.frames теперь можно объединить в один с использованием функции rbind - объединение данных по строкам (row bind).
Аналогично когда надо объединить данные по колонкам используется функция cbind .
Загрузим и объединим значения свойства для двух наборов данных
Посмотрим на распределение значений свойства
Простейшие функции для работы с графикой
Базовый пакет R имеет в своем составе много функций для визуализации данных. Остановимся только на некоторых, которые могут быть полезны при первом знакомстве с данными.
Функция hist - строит гистограмму распределения какой-либо величины. Может помочь составить первое впечатление о нормальности распределения данных. Применим эту функцию к свойству y .
Если стандартное отображение не устраивает, то можно его изменить, например, сделав интервалы меньше.
Во всех случаях очевидно, что распределение данных отличается от нормального. Чтобы проверить это можно воспользоваться следующими двумя функциями, которые строят график зависимости между квантилями нормального распределения и квантилями исследуемого набора значений y . Чем сильнее отличие распределения от прямой, тем больше отклонение распределения от нормального.
Для более подробного знакомства с возможностями базовых функций графического отображения рекомендую ознакомиться со следующими источниками:
Семейство функций apply
apply
Семейство функций apply является более удобным аналогом цикла for .
Рассмотрим пример - необходимо найти среднее значение каждой колонки в data.frame.
Решение с использованием цикла for
Решение с использованием функции apply
Правда короче и проще? Кроме того вектор с результатами содержит названия переменных.
А вот выражение, которое вычисляет среднее значение по строкам
На самом деле для операции нахождения среднего и суммы по строкам/столбцам есть отдельные векторизированные функции rowMeans , rowSums и т.д.
Общий вид вызова функции apply
X - матрица, массив или data.frame
MARGIN - порядковый номер размерноси, к которой будет применяться функция FUN (1 для строк, 2 для колонок)
FUN - применяемая функция
Результатом будет являться вектор (если используемая функция возвращает одно значение), массив (если функция возвращает вектор значений) или список (если функция возвращает результат в виде более сложной структуры данных, например data.frame или матрица).
ВАЖНО! При применении функции apply к data.frame, data.frame неявно приводится к матрице. Матрицы как мы помним содержат данные только одного типа. Это означеат что если в data.frame 9 числовых колонок и 1 текстовая, то будет произведена конвертация в текстовую матрицу, и следовательно все действия будут производиться над текстовой матрицей.
Пример
Чуть более сложный пример - надо посчитать для каждой колонки среднее значение и извлечь из него квадратный корень. выполним это с использованием функции apply
Предложите альтернативный вариант расчета.
sapply & lapply
Помимо функции apply есть еще функции sapply и lapply , отличие которых состоит в том, что на вход они могут принимать вектор или список и возвращают вектор/матрицу ( sapply ) или список ( lapply ).
Вспомним, что data.frame является списком векторов-столбцов. Тогда предыдущий пример можно переписать как
Использование lapply вернет уже список
Возведем значения каждой колонки в степень, соответствующую номеру этой колонки - результатом будет новая матрица.
Обратите внимание, что в этом случае в качестве первого параметра передается не data.frame, а вектор индексов колонок, по которым происходит итерация.
Функция seq_along возвращает вектор индексов с первого до последнего элемента вектора/списка.
Использование функций семейства apply позволяет делать код более простым и читабельным.
Например, надо определить класс каждой колонки в data.frame
Как видим в отличие от apply фугкция sapply не производит неявной конвертации data.frame в матрицу и типы данных в колонках остаются неизменными.
Проверить совпадает ли порядок следования имен соединений в x и y .
Создать функцию, которая читала бы формат файлов дескрипторов dat/cds. Подсказка: можно использовать функцию readBin .
Создать функцию, которая будет объединять два набора фрагментных дескрипторов.

Я сам изучал R в течение последних нескольких недель.
В своей статье я рассказываю о языке программирования R и его главных концепциях, которые пригодятся каждому исследователю данных.
Сфера науки о данных и развивающихся вычислений требуют от нас всё время адаптироваться и вырабатывать новые навыки. Причина в том, что эта область меняется очень быстро. А ещё в ней в целом высокая планка требований. В профессиональной жизни каждого исследователя данных приходит время, когда нужно бы знать больше, чем один язык программирования. Так я и выбрал R.
Я очень советую именно R по многим причинам.
R ст а новился всё известнее и известнее, пока не стал одним из самых популярных языков программирования. Его создали статистики (специалисты по статистике) для статистиков. Он хорошо сочетается с другими языками программирования, например с C++, Java, SQL. Более того, его воспринимают как язык, который отлично подходит для работы со статистикой. А в результате большое количество финансовых организаций и крупных вычислительных компаний применяют R в своих исследованиях и разработках.
Python — язык для решения задач общего характера, а R — язык программирования для аналитики.
Этот текст объяснит следующие ключевые области языка R:
- Что такое R?
- Как установить R?
- Где писать код на R?
- Что такое R-скрипт и R-пакет?
- Какие типы данных есть в R?
- Как декларировать переменные и их область действия в R?
- Как писать комментарии?
- Что такое векторы?
- Что такое матрица?
- Что собой представляют списки?
- Что такое датафреймы?
- Различные логические операции в R.
- Функции в R.
- Циклы в R.
- Считывание и запись внешних данных в R.
- Как производить статистические вычисления в R.
- Построение графиков и диаграмм в R.
- Объектно-ориентированное программирование в R.
- Знаменитые библиотеки R.
- Как установить внешние библиотеки R.
Приступим же!…
Я буду объяснять язык программирования, начиная с основ, в таком стиле, чтобы вам было легче разобраться. Стоит сказать, что ключ к прогрессу в разработке — это постоянная практика. Чем больше, чем лучше.
Этот материал должен стать целостной базой для вас — читателей.
- R — это бесплатный язык программирования с лицензией GNU. В сущности R — это статистическая среда.
- R в основном используется для статистических вычислений. Он имеет набор алгоритмов, которые углубленно применяются в области машинного обучения. А конкретнее — в анализе временных рядов, классификации, кластеризации, линейном моделировании и т.д.
- Также R — это среда, в которой есть набор программных пакетов, с которыми можно производить вычисления для построения диаграмм и для манипуляций с данными.
- R значительно применяется в проектах статистических исследований.
- R очень похож на другой язык программирования — S.
- R компилируется и запускается на UNIX, Windows, MacOS, FreeBSD и Linux.
- В R есть большое количество структур данных, операторов и параметров. Он включает многое: от массивов до матриц, от циклов до рекурсии вместе с интеграцией с другими ЯП, например с C, C++ и Fortran.
- C можно использовать для обновления объектов в R напрямую.
- R можно дополнять новыми пакетами.
- R — интерпретатор.
- Авторы R вдохновлялись S+, так что, если вы знакомы с S, изучение R будет для вас простым следующим шагом.
Преимущества R:
Вдобавок к плюсам, о которых я написал выше:
- R просто выучить.
- В среде есть очень много бесплатных пакетов с открытым исходным кодом для статистики, аналитики и графики.
- Богатство различных научных трудов вместе с их применением в R в вашем распоряжении.
- Лучшие мировые университеты учат своих студентов R, следовательно, он стал принятым стандартом, продолжит расти и развиваться.
- Широкие возможности интеграции с другими языками.
- Огромная поддержка в сообществе специалистов.
Ограничения R:
Также есть и некоторые ограничения:
- R не такой быстрый, как C++. К тому же, есть проблемы с его защищённостью и управлением памятью.
- R имеет много пространств имен. Иногда такое впечатление, что их даже слишком много. Тем не менее ситуация улучшается.
- Так как R — это статистический язык, то он не такой интуитивный, как Python, и в нём не так просто работать с ООП, как в Python.
А теперь я представлю вам язык R в формате кратких описательных разделов.
Можете установить R на эти платформы:
Первый шаг — загрузите R:
Вот вам и линки:
Есть разные графические интерфейсы. Очень советую R-Studio.

Загрузите десктопную версию RStudio:
Если вы работаете на Windows, в процессе установки R Studio по умолчанию попадет сюда:
Это два ключевых компонента в языке. В этом разделе поверхностно расскажу о концепциях.
Пакет R
Так как R — это ЯП с открытым кодом, важно понимать, что тут подразумевается под пакетом. Пакет в сущности группирует и упорядочивает код, а также другие функции. Пакет — это библиотека, в которой содержится большое количество файлов.
Специалисты по данным могут писать и делиться своим кодом с другими. Будь это их собственный код с нуля или расширение пакетов других авторов. Пакеты позволяют специалистам по данным переиспользовать код и распространять его среди остальных.
Пакеты созданы, чтобы контейнировать функции и наборы данных.
Специалист по данным может создать пакет, чтобы упорядочить код, документацию, тесты, наборы данных и так далее, и потом этими пакетами можно делиться с другими людьми.
В интернете в открытом доступе есть десятки тысяч пакетов R. Эти пакеты собраны в центральном репозитории. Вообще есть разные репозитории. Это и CRAN, и Bioconductor, и любимый Github.
Одно хранилище заслуживает отдельного упоминания. Это CRAN. Это сеть серверов, которые хранят большое количество версий кода и документации для R.
Пакет содержит файл с описанием, где нужно указать дату, зависимости, автора и версию пакета, а также другие данные. Файл-описание помогает пользователям получить важную информацию о пакете.
Чтобы загрузить пакет, напечатайте:
Чтобы пользоваться функциональностью пакета, напишите в его имени::название функции.
Например, если мы хотим применить функцию “AdBCDOne” из пакета “carat”, можем сделать следующее:
R Script
Скрипт R — это место, где специалист по данным может писать статистический код. Это текстовый файл с расширением .R, например мы может назвать скрипт tutorial.R.
Можем создать много скриптов в пакете.
В качестве примера, если вы создали два скрипта R:
- blog.R (для блога)
- publication.R (для публикации)
И если вы хотите вызвать функции publication.R в blog.R, то вам стоит пользоваться командой source(“target R script”). Она импортирует publication.R в blog.R:
Создаём пакет скрипта
Процесс относительно простой. В сущности вот, что нужно сделать:
- Создайте файл описания.
- Создайте R.scripts и добавьте любые датасеты, документацию, тесты, которые должны быть в этом пакете.
- Напишите свои функции в скриптах R.
- Можем применить devtools и roxygen2, чтобы создать пакеты R с помощью такой команды:
Очень важно разобраться в разных типах данных и структурах в R. Так вы сможете пользоваться языком эффективно. В этом разделе я опишу концепции.
Типы данных
Вот базовые типы данных в R:
- символ (character): может быть таким “abc” или таким “a”
- целочисленный (integer): например 5L
- числовой (numeric): например 10.5
- логический (logical): TRUE или FALSE
- комплексный (complex): например 5+4i
Ещё можем пользоваться командой typeof(variable), чтобы определить тип переменной.
Чтобы найти метаданные (атрибуты типа), используйте команду attributes(variable).
Структуры данных
В R достаточно много структур данных. Привожу самые важные:
- Вектор (vector): самая важная структура, которая в сущности является набором элементов.
- Матрица (matrix): похожая на таблицу структура со строками и колонками
- Датафрейм (data frame): табличная структура для статистических операций
- Списки (lists): набор, в котором может быть комбинация типов данных.
- Факторы (factors): для представления категориальных данных.
Я расскажу обо всех этих типах и структурах данных, так что начинаем строить фундамент.
Мы можем создать переменную и присвоить ей значение. Переменная может иметь любой тип данных и структуру данных, которые я привел выше. Есть, конечно, и другие структуры данных. Дополнительно разработчик может создавать и свои собственные пользовательские классы.
Переменная нужна, чтобы сохранять значение, которое может меняться в вашем коде.
Чтобы понять, важно запомнить, что такое окружение в R. В сущности окружение — это место, где хранятся переменные. Это набор пар, где первый элемент — это символ (переменная), а второй — её значение.
Окружение имеет иерархическую структуру (похожую на дерево). Следовательно, окружение может иметь родителя и множество дочерних ответвлений. Корневое окружение — это окружение без родителя.
Надо декларировать переменную и присвоить ей значение при помощи следующего:
После этого значение “my variable” будет присвоено переменной x. Функция print() выведет значение x, которое равно “my variable”.
Каждый раз, когда мы объявляем переменную и вызываем её, она ищется в текущем окружении, а также рекурсивно ищется в родительских окружениях до тех пор, пока значение не будет найдено.
Чтобы создать набор целых чисел, мы можем сделать следующее:
1 — первое значение, а 5 — последнее значение из набора.
В результате выведутся числа от 1 до 5.
Помните, что IDE R-Studio отслеживает переменные:

Функцию ls() можно писать, чтобы показать переменные и функции в текущем окружении.
Комментарии нужны в коде, чтобы помогать понимать его тем, кто будет с ним разбираться. Читателям, другим специалистам по данным и самому себе. Бывает и такое.
Помните, что нужно всегда убеждаться в том, что комментарии не загрязняют ваши скрипты.
Можем добавить комментарий одной строкой:
Можем добавить комментарий в несколько строк при помощи двойных кавычек:
Памятка: в R-Studio выделите код, который вы собираетесь закомментировать и нажмите сочетание клавиш Ctrl+Shift+C.
Так вы автоматически сделаете нужную часть программы комментарием.
Вектор считается одной из самых важных структур данных в R. В сущности вектор представляет собой набор элементов, где у всех элементов должен быть одинаковый тип данных: например, только логический (истинно/ложно — TRUE/FALSE), числовой, знаковый.
Также можем создать пустой вектор:
По умолчанию тип вектора логический. По команде ниже выведется слово “logical”, так как это и есть тип данных вектора:
Чтобы создать вектор со своими элементами, пишите функцию конкатенации (объединения строк):
Результат выполнения этого кода будет таким:
[1] “Farhad”
[2] “Malik”
[3] “FinTechExplained”
Если мы захотим найти длину вектора, можем воспользоваться функцией length():
Результат вывода строки выше будет 3. Потому что в заданном векторе x 3 элемента. Чтобы добавить элементы в вектор, можем комбинировать элемент с вектором.
Например, чтобы добавить слово “world” к началу вектора с одним элементом слова “hello”, нужно написать так:
В результате напечатается “world” “hello”.
Если мы смешиваем типы элементов, то R в свою очередь будет приспосабливать тип вектора в ответ на это. Тип вектора (режим) будет становиться таким, каким должен быть по своему расчёту, чтобы подходить этому вектору:
И хотя второй элемент имеет логическое значение, тип будет выведен как “character” (символ).
Над векторами можно производить операции.
Для примера, вот вам умножение скаляра на вектор:
В результате напечатается 2,4,6.
Также можем сложить два вектора:
Результат будет: 5 7 9
Если векторы — это знаки и мы хотим сложить их вместе, то:
Error in x + y : non-numeric argument to binary operator (ошибка в выражении x + y: нечисловой аргумент для бинарного оператора).
Читайте также: