
Что такое иерархическая модель организации данных объясните ее суть на примере каталога файловой
Цель лекции: Уяснить разницу между моделями организации БД . Ознакомиться с их достоинствами и недостатками. Понять, как организовываются связи в этих моделях, как применяются операции изменения в той или иной модели.
Различают три основные модели базы данных - это иерархическая, сетевая и реляционная. Эти модели отличаются между собой по способу установления связей между данными.
1. Иерархический подход к организации баз данных. Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными - одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых, все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель - единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково - таблицами. Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элемент модели - реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления ( полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL .
Третий элемент реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности . Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор , называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты - текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных , не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем - реализация сложных типов данных , связь с языками программирования и т.п. - на ближайшее время превосходство реляционных СУБД гарантировано.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных
Иерархические базы данных - самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений "предок- потомок ". Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных - невозможность реализовать отношения " многие-ко-многим ", а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных . Иерархические базы данных графически могут быть представлены как перевернутое дерево , состоящее из объектов различных уровней. Верхний уровень ( корень дерева ) занимает один объект , второй - объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка ( объект , более близкий к корню) к потомку ( объект более низкого уровня), при этом объект -предок может не иметь потомков или иметь их несколько, тогда как объект - потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
Иерархической базой данных является Каталог папок Windows , с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол . На втором уровне находятся папки Мой компьютер , Мои документы, Сетевое окружение и Корзина , которые являются потомками папки Рабочий стол , а между собой является близнецами. В свою очередь , папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков ( Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам ( сканер , bluetooth и.т.д.) - на рис. 4.1.
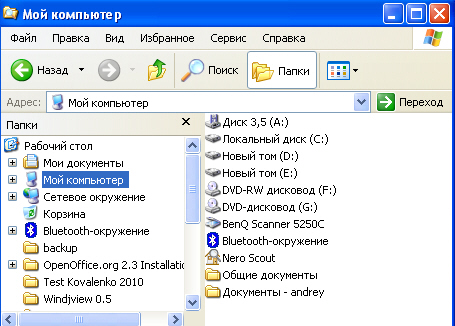
Рис. 4.1. Иерархическая база данных Каталог папок Windows
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись ( группа ), групповое отношение , база данных .
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами ( диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись .
Пример
Рассмотрим следующую модель данных предприятия (см. рис. 4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) ( рис. 4.2 b).
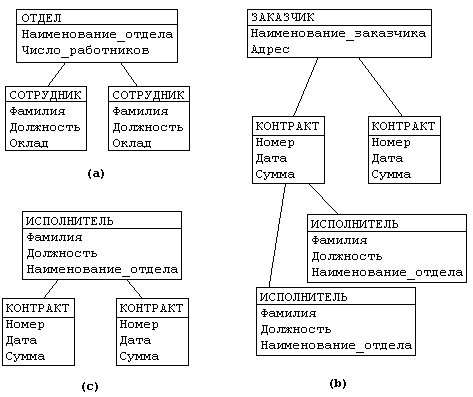
Из этого примера видны недостатки иерархических БД :
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение , в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней ( рис. 4.2 c). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели :
- Добавить в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- Изменить значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- Удалить некоторую запись и все подчиненные ей записи.
- Извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей.
- Извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева ).
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 10 тысяч руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных ). Такой подход к манипулированию данных получил название "навигационного".
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разные иерархии.
Иерархическая база данных. Иерархическая модель данных
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.

Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):

Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня.
Новые вопросы в Информатика
Моделью какого объекта является макет в мастерской архитектора? Земного шара Воображения мастера Рисунка на картине Застройки города Чем является инфо … рмационная модель объекта моделирования? Уменьшенной копией Рисунком Описанием Виртуальной копией Что из перечисленного является информационной моделью человека? Манекен Гравюра Рисунок человека Личные карточки, анкеты Что из перечисленного является информационной моделью корабля? Деревянная модель Уменьшенная копия Чертёж Что из перечисленного является натуральной моделью? Карта Таблица Муляж Схема На каком языке осуществляется описание объекта моделирования для информационной модели? На формальном языке На естественном языке На математическом языке На русском языке
Пж помогите срочно. Дам 20 баллов! Команды восьмиклассников и семиклассников сражались в игре пейнтбол. Каждая команда должна была в течение заданн … ого времени поразить как можно больше участников команды-противника, выстрелив в соперника шариком с краской. По окончании игры оказалось, что каждый семиклассник сумел отметить краской 4 восьмиклассников, а каждый восьмиклассник – 5 семиклассников, при этом в обеих командах были ученики, в которых соперники попадали неоднократно. Какое наибольшее количество участников могло быть в обеих командах вместе, если известно, что общее количество участников не превышает 100 и обе команды израсходовали одинаковое количество «пуль». В ответе запишите одно число – общее количество участников двух команд. Формат вывода В ответе запишите одно число – общее количество участников двух команд.
отдам 50 баллов за решение всех 2 задач. во 2 надо найти: Дано, Найти, формула.
Команды восьмиклассников и семиклассников сражались в игре пейнтбол. Каждая команда должна была в течение заданного времени поразить как можно больше … участников команды-противника, выстрелив в соперника шариком с краской. По окончании игры оказалось, что каждый семиклассник сумел отметить краской 4 восьмиклассников, а каждый восьмиклассник – 5 семиклассников, при этом в обеих командах были ученики, в которых соперники попадали неоднократно. Какое наибольшее количество участников могло быть в обеих командах вместе, если известно, что общее количество участников не превышает 100 и обе команды израсходовали одинаковое количество «пуль». В ответе запишите одно число – общее количество участников двух команд.Формат выводаВ ответе запишите одно число – общее количество участников двух команд.
Команды восьмиклассников и семиклассников сражались в игре пейнтбол. Каждая команда должна была в течение заданного времени поразить как можно больше … участников команды-противника, выстрелив в соперника шариком с краской. По окончании игры оказалось, что каждый семиклассник сумел отметить краской 4 восьмиклассников, а каждый восьмиклассник – 5 семиклассников, при этом в обеих командах были ученики, в которых соперники попадали неоднократно. Какое наибольшее количество участников могло быть в обеих командах вместе, если известно, что общее количество участников не превышает 100 и обе команды израсходовали одинаковое количество «пуль». В ответе запишите одно число – общее количество участников двух команд. Формат вывода В ответе запишите одно число – общее количество участников двух команд.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока "Иерархические БД"
На этом уроке мы с вами вспомним, что такое иерархическая структура и из каких элементов она состоит. Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с рассмотрения иерархической структуры базы данных.
Иерархическая структура – это многоуровневая форма организации объектов со строгой соотнесённостью объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно сказать, что иерархическая структура напоминает собой пирамиду, в которой объекты более низкого уровня подчиняются объектам более высокого уровня.
Из этого можно сделать вывод, что в иерархической структуре существуют отношения между её объектами (элементами).
Ещё иерархическую структуру называют древовидной. К примерам можно отнести содержание учебника.
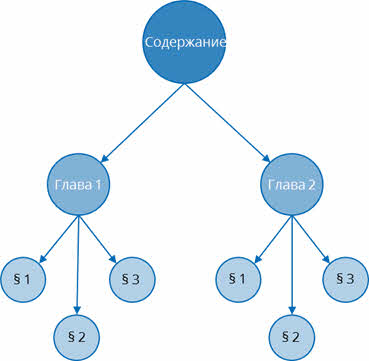
А сейчас рассмотрим иерархическую структуру более подробно на примере.
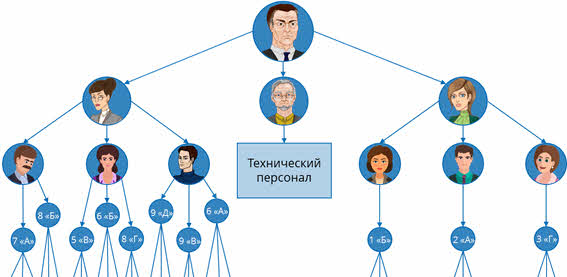
Давайте построим иерархическую структуру школы.
Во главе всегда находится директор школы. Далее будут идти завуч старших классов, завуч младших классов, заведующий хозяйственной деятельностью. После завучей идут учителя, которые, соответственно, делятся на преподавателей младших и старших классов. Не будем расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему по хозяйственной деятельности будет подчиняться весь технический персонал. Его мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он является классным руководителем, а в каждом классе – ученики. В свою очередь, учителя старших классов ведут уроки и в других классах. Давайте отобразим несколько таких классов в нашей структуре. Если же всю эту структуру расписывать более подробно, то нам понадобится очень много места, так как объектов в этой системе очень большое количество.
Итак, во главе любой иерархической структуры всегда находится один элемент (объект). В нашем случае – это директор школы. Он является корнем вершины и находится на верхнем (первом) уровне.
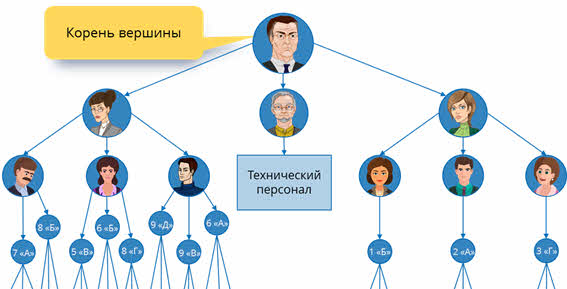
Далее идёт второй уровень, на котором находятся заместители.
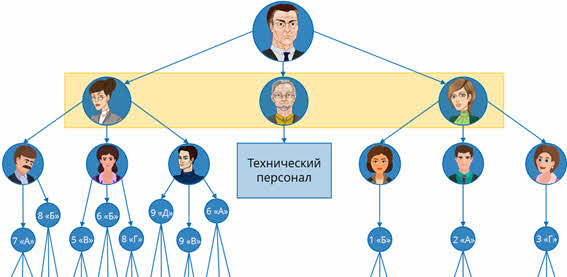
На третьем уровне находятся учителя и технический персонал, на четвёртом – классы и на пятом – ученики.
Как говорилось ранее, между всеми объектами существуют связи. Каждый объект более высокого уровня может включать в себя несколько объектов более низкого уровня. Давайте снова обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех учителей, которые ведут уроки в старших классах. А заведующий хозяйственной деятельностью управляет всем техническим персоналом школы. Такие объекты находятся в отношении предка (объект более высокого уровня) к потомку (объект более низкого уровня). То есть завуч старшей школы и заведующий хозяйственной деятельностью являются предками, а учителя и технический персонал – потомками.
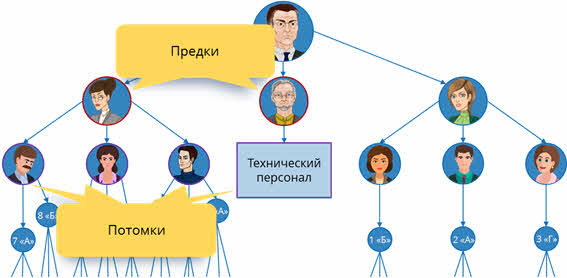
Также мы можем видеть, что у объекта-предка может быть несколько потомков. Но в то же время у объекта-потомка может быть только один предок. Объекты, которые находятся на одном уровне и у которых один общий предок, называются близнецами.
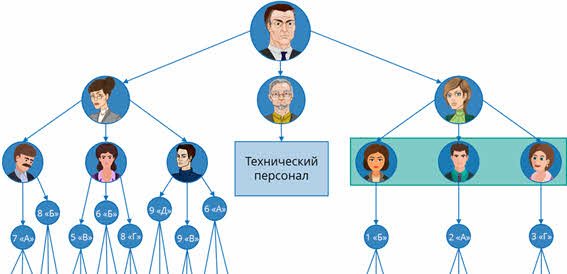
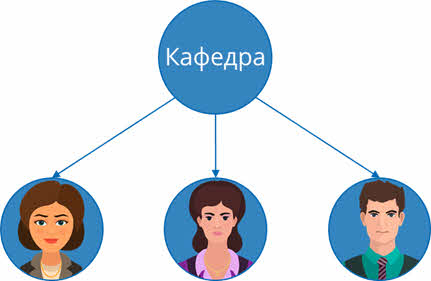
Рассмотрим ещё один пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков Игорь Сергеевич преподаёт французский язык.

Корневой вершиной в этой структуре будет являться кафедра. Изобразим её в виде круга. Она включает в себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому преподавателю проведём стрелки.
Далее у каждого преподавателя есть свои предметы, которые он ведёт. Также изобразим их схематично и проведём стрелки.
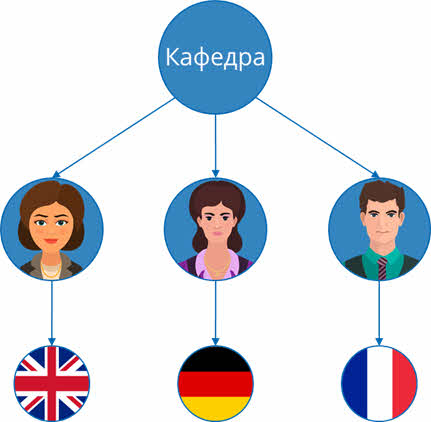
Таким образом мы получили графическое отображение иерархической структуры кафедры.
Корневой вершиной является кафедра.
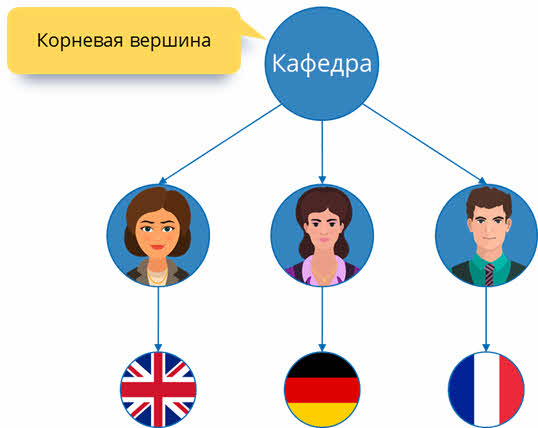
Учителя являются потомками по отношению к кафедре и предками по отношению к предметам, которые они преподают. Также они между собой являются близнецами, так как находятся на одном уровне структуры и имеют одного предка – кафедру.
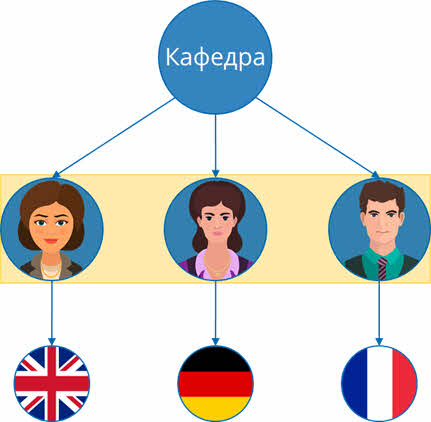
У нас получилось несколько определений.
Корень – это единственный объект, который стоит на вершине иерархической системы и является её первым уровнем.
Предок – это объект, который стоит более близко к корню системы и у него может быть несколько потомков.
Потомок – это объект, который стоит на более низком уровне по отношению к предку и у него может быть только один предок.
Близнецы – это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё несколько примеров.
Начнём с иерархической базы данных папки Windows.
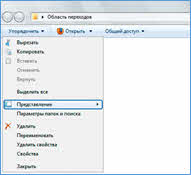
Иерархической базой данных является каталог папок Windows. Перед вами рисунок системного диска. Для того, чтобы увидеть древовидную структуру в проводнике в Windows 7, необходимо выбрать кнопку «Упорядочить», далее из появившегося списка – «Представления», а затем «Область переходов». Это в том случае, если данная область не отображается.
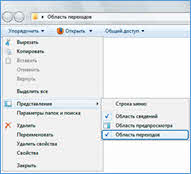
А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид», выбрать «Область навигации» и из списка снова «Область навигации».
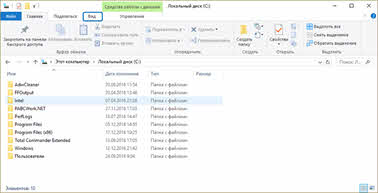
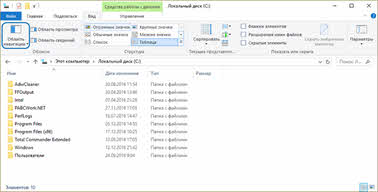
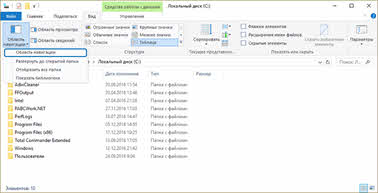
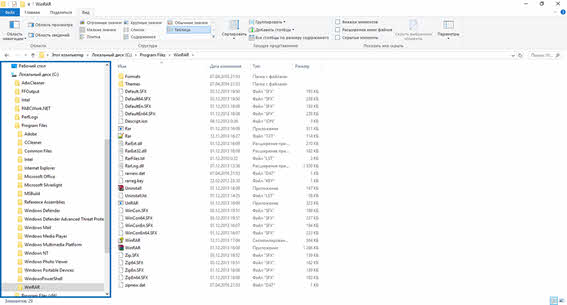
На рисунке представлен проводник операционной системы Windows 10.
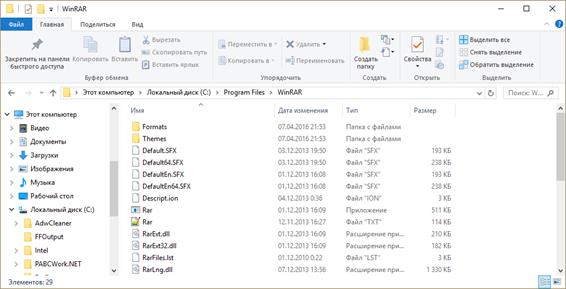
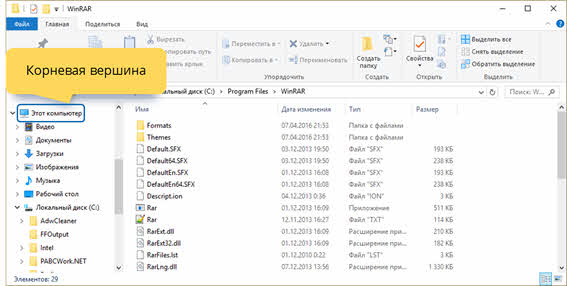
Итак, корневой является папка «Этот компьютер».
Далее, на втором уровне на представленном рисунке находится локальный диск С, который включает в себя несколько папок третьего уровня.
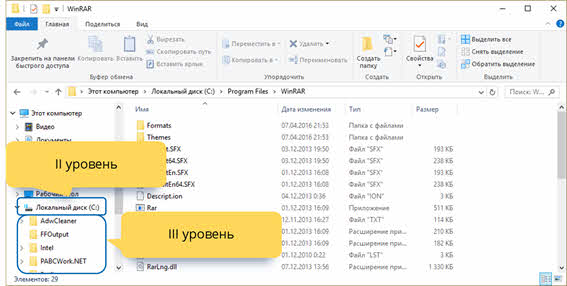
В нашем случае выбрана папка «Program Files». Она в себя включает несколько папок-потомков.
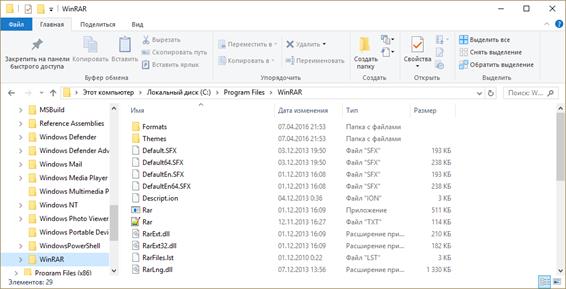
Исходя из этого можно сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному диску С), и предком (по отношению к остальным папкам, которые она в себя включает). Файл «Rar.txt» является потомком папки «WinRAR». В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также, например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером иерархической базы данных является файловая система Linux.
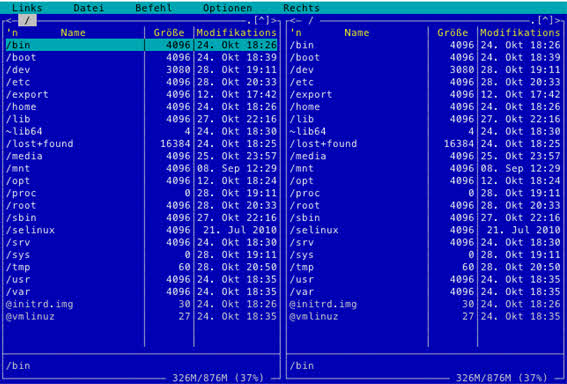
Мы ранее её рассматривали. В ней существует одна корневая папка, все остальные папки являются потомками. В корневой папке содержатся все системные файлы. А вот, например, каталоги логических томов и запоминающих устройств содержатся в составе других каталогов. Директории томов жёсткого диска содержатся в папке «mnt». Другие запоминающие устройства находятся в папке «media». В свою очередь, папки «mnt» и «media» содержатся в одном системном корневом каталоге. Таким образом, папки «mnt» и «media» являются и потомками (по отношению к основному корневому каталогу), и предками (по отношению к каталогам логических томов и запоминающих устройств). Помимо этого, эти две папки являются близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».
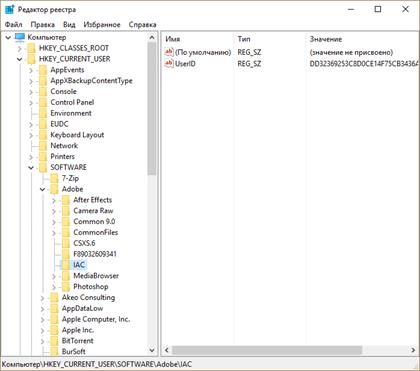
В этой иерархической базе данных хранится вся информация, которая нужна для нормального функционирования компьютерной системы. То есть в этой базе данных содержится информация о настройках компьютера, установленных драйверах, настройках графического интерфейса, сведения о программах, которые установлены на компьютере, и многое другое.
Вся эта информация автоматически обновляется при установке нового оборудования, удалении или установке программ и так далее.
Давайте рассмотрим рисунок.
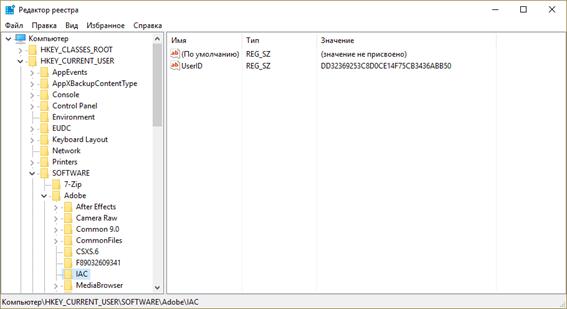
Корневым объектом является сам компьютер. Папка «Adobe» является потомком по отношению к папке «SOFTWARE» и предком для всех остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID» является потомком папки «IAC». В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе Linux как такового реестра нет. Вместо этого в ней существует папка «etc».
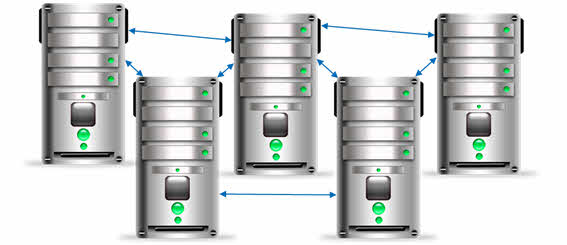
А сейчас мы с вами рассмотрим иерархическую базу данных «Доменная система имён». Эта система получила название DNS.
DNS – это распределённая база данных, которая поддерживает иерархическую систему имён для идентификации узлов сети Интернет.
Эта служба предназначена для автоматического поиска IP-адреса по известному символьному имени узла. То есть в этой базе данных содержится информация о всех компьютерах, подключённых к сети Интернет.
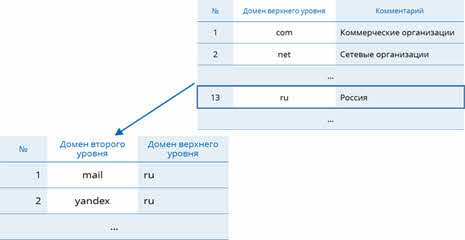
Корневой вершиной в этой системе является табличная база данных, которая содержит перечень доменов верхнего уровня.
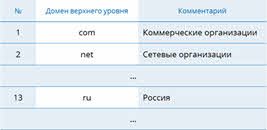
Сам же корень управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Для обозначения стран используются трёхбуквенные и двухбуквенные аббревиатуры.
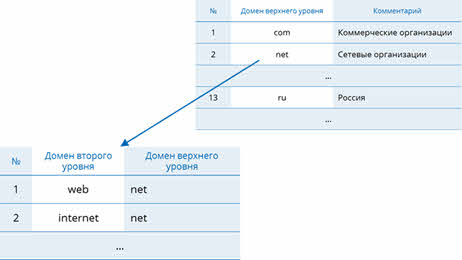
На втором уровне находятся также табличные базы данных, но они уже в себя включают перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне содержатся табличные базы данных и таблицы. Табличные базы данных содержат перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в свою очередь, содержат IP-адреса компьютеров, которые находятся в домене второго уровня.
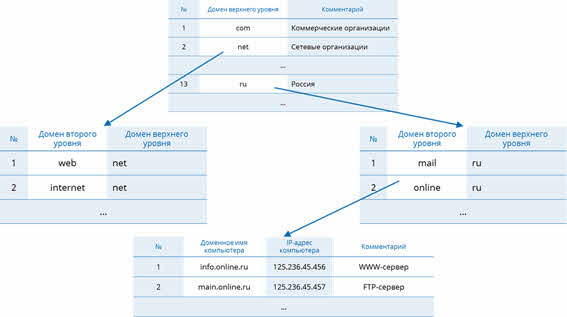
А теперь представьте, какой большой будет база данных, которая должна включать в себя информацию о всех компьютерах, подключенных к Интернету. Как вы думаете, много ли места она будет занимать?
Такая база данных огромна по своим размерам и соответственно она не будет умещаться в памяти одного компьютера, а если бы и можно было загрузить такую базу данных в один компьютер, то работа в Интернете была бы очень медленной. Представьте себе количество запросов, которые поступают от пользователей всего мира в течение, например, 1 минуты. Их количество огромно. А теперь представьте, что все эти запросы должен принять и обработать один компьютер. Это просто невозможно, так как приведёт не только к медленной работе компьютера, но также и к зависанию, если не к поломке. Таким образом, размещение базы данных доменной системы имён на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между собой. Такая иерархическая база данных является распределённой базой данных.
А сейчас давайте рассмотрим, как происходит поиск информации в такой огромной иерархической распределённой базе данных.
Например, вам нужно зайти на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.

Ваш запрос сначала отправляется на DNS-сервер вашего провайдера, с которого он переадресуется на DNS -сервер верхнего уровня базы данных.
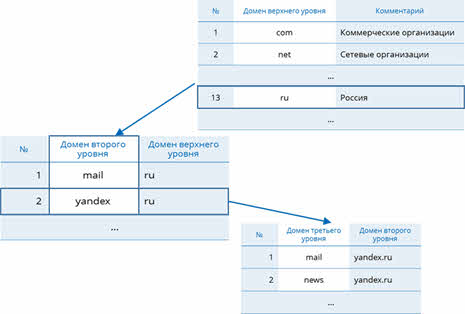
В таблице третьего уровня будет найден домен «mail», и запрос будет переадресован на DNS-сервер четвёртого уровня.
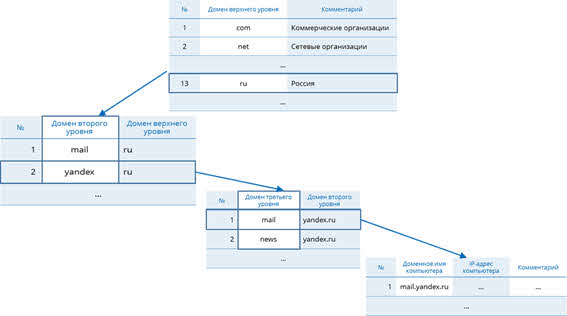
В таблице четвёртого уровня будет найдена запись, которая соответствует доменному имени, содержащемуся в запросе. После этого поиск в самой базе данных «Доменная система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.
Пришла пора подвести итоги урока.
Сегодня мы с вами узнали, что такое иерархическая структура и построили такую структуру на примере. Более подробно познакомились с элементами иерархической базы данных: корнем, предком, потомком, близнецами.
Рассмотрели несколько иерархических баз данных на примере Windows и Linux, а также реестра Windows.
Узнали, как составлена и работает иерархическая база данных «Доменная система имён».
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Содержание
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Структурная часть иерархической модели
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Известные иерархические СУБД
- Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM.
- Time-Shared Date Management System (TDMS) компании Development Corporation;
- Mark IV MultiAccess Retrieval System компании Control Data Corporation;
- System 2000 разработки SAS Institute;
- Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
- По принципу иерархической БД построены иерархические файловые системы и Реестр Windows.
- InterSystems Caché Datastore API
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием её в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Читайте также: