
Admission control vmware настройка
Delphi site: daily Delphi-news, documentation, articles, review, interview, computer humor.
Настройки VMware HA показаны на рис. 7.1.
Host Monitoring Status - если флажок Enable Host Monitoring не стоит, то HA не работает. Снятие его пригодится, если вы планируете какие-то манипуляции с сетью, на которые HA может отреагировать, а вам бы этого не хотелось. Альтернатива снятию данного флажка - снятие флажка VMware HA для кластера (Cluster Features), но это повлечет за собой удаление агентов HA с серверов и сброс настроек. Это неудобно, если функционал HA нужно восстановить после завершения манипуляций. Также VMware рекомендует отключать HA снятием флажка Enable Host Monitoring, когда вы добавляете группы портов и виртуальные коммутаторы на серверы или помещаете часть серверов в режим обслуживания.
Admission Control - это настройка резервирования ресурсов на случай сбоя. Вариант «Allow VMs to be powered on. » отключает какое-либо резервирование, то есть HA кластер не ограничивает количество запущенных виртуальных машин. Иначе - HA будет самостоятельно резервировать какое-то количество ресурсов.

Рис. 7.1. Основные настройка кластера HA
Настройка способа высчитывания необходимого количества ресурсов делается в пункте Admission Control Policy.
Admission Control Policy - как именно HA должен обеспечивать резервирование ресурсов. Если мы хотим доверить HA кластеру контроль за этим и выбрали Admission Control = «Prevent VMs from being powered on. », то здесь выбираем один из трех вариантов резервирования ресурсов:
- Host failures cluster tolerates - выход из строя какого числа серверов должен пережить кластер. При выборе этого варианта настройки HA следит за тем, чтобы ресурсов всех серверов минус указанное здесь число хватало бы на работу всех ВМ. В подсчете необходимых для этого ресурсов HA оперирует понятием «слот». О том, что это и как считает ресурсы HA, - чуть далее;
- Percentage of cluster resources - в этом случае HA просто резервирует указанную долю ресурсов всех серверов. Для расчетов текущего потребления используются настройки reservation каждой ВМ, или константы 256 Мб для памяти и 256 МГц для процессора, что больше. Кстати, 100% ресурсов в данном случае - это не физические ресурсы сервера, а ресурсы так называемого «root resource pool», то есть все ресурсы сервера минус зарезервированные гипервизором для себя;
- Specify a failover host - указанный сервер является «запаской». На этом сервере нельзя будет включать виртуальные машины - только HA сможет включить на нем ВМ с отказавших серверов. На него нельзя будет мигрировать ВМ с помощью VMotion, и DRS не будет мигрировать ВМ на этот сервер. Если включение ВМ на указанном запасном сервере не удалось (например, потому что он сам отказал), то HA будет пытаться включить ВМ на прочих серверах.
Обратите внимание на рис. 7.2.

Рис. 7.2. Информация на закладке Summary для HA кластера Здесь вы видите три варианта информации с закладки Summary для кластера с включенным HA. Эти три варианта соответствуют трем вариантам настройки Admission Control. Строка Configures failover capacity напоминает о том,
какое значение вы дали настройке резервирования ресурсов. В моем примере, сверху вниз:
- отказоустойчивость в один сервер настроена и отказоустойчивость в один сервер есть - на последнее указывает Current failover capacity. По нажатии ссылки Advanced Runtime Info открывается окно с дополнительной информацией по текущему состоянию кластера;
- резервирование 25% ресурсов указано, а свободно в данный момент 88% для процессора и 47% для памяти;
Какой из вариантов резервирования ресурсов использовать?
Я бы рекомендовал или вообще отключить Admission Control, или использовать третий вариант резервирования - резервирование конкретного сервера.
Отключение Admission Control оправдано в том случае, когда серверы вашей виртуальной инфраструктуры всегда не загружены больше, чем процентов на 80. Если ресурсы процессора и памяти у вас в избытке, или вы сами следите за тем, чтобы загрузка не превышала тех самых 80% (плюс-минус), то дополнительно что-то резервировать средствами HA просто незачем.
Использование резервирования целого сервера нравится мне тем, что это очень понятный вариант. На одном сервере нет ни одной виртуальной машины, на всех остальных серверах HA не вмешивается. Однако далеко не в любой инфраструктуре можно себе позволить держать свободным целый один сервер.
Резервирование ресурсов по процентам не нравится мне тем, что резервирование делается не для реальных аппетитов виртуальных машин, а для их reservation. То есть если HA резервирует 25% ресурсов, то это означает, что сервер может быть загружен и на 100%, а 75% относится к сумме reservation виртуальных машин. Это означает, что если для всех или большинства ВМ вы настройку reservation не делали, то такой вариант резервирования ресурсов вообще бесполезен.
Наконец, вариант резервирования по слотам. Его подробное описание - чуть ниже, а краткая характеристика вот какова: он плох, если виртуальные машины нашей инфраструктуры сильно отличаются по своей конфигурации. Это связано с тем, что HA рассчитывает размер некоего слота (количество мегагерц и мегабайт), которое необходимо для работы ВМ. И размер слота - один на всех. Я рискну предположить, что в большинстве инфраструктур такое приближение будет слишком грубым.
Virtual Machine Options. Это следующая группа настроек кластера HA (рис. 7.3).
Здесь нам доступно следующее:
- VM restart priority - приоритет рестарта для ВМ кластера, здесь указываем значение по умолчанию. Очевидно, что первыми должны стартовать ВМ, от которых зависят другие. Например, сервер БД должен стартовать до сервера приложений, использующего данные из БД. Обратите внимание, что если одновременно отказали хотя бы два сервера, то перезапуск

Рис. 7.3. Virtual Machine Options
ВМ с них производится последовательно. То есть сначала запустятся все ВМ с одного из отказавших, в порядке приоритета. Затем все ВМ со второго, опять же в порядке приоритета;
- Host Isolation response - должен ли сервер выключить свои виртуальные машины, если он оказался в изоляции (isolation). Что такое изоляция, см. чуть далее;
- Virtual Machine Settings - здесь можем обе предыдущие настройки указать индивидуально для каждой ВМ.
High Availability – технология кластеризации, созданная для повышения доступности системы, и позволяющая, в случае выхода из строя одного из узлов ESXi, перезапустить его виртуальные машины на других узлах ESXi автоматически, без участия администратора.
Общие сведения High Availability
В прошлый раз шла речь о технологиях, используемых в VMware для обеспечения отказоустойчивой системы, в этой же статье подробнее остановимся на VMware HA – VMware High Availability (механизме высокой доступности).
Для того чтобы создать HA кластер, нам необходимо, чтобы все виртуальные машины этого кластера хранились на общем хранилище данных*. При этом если у нас выходит из строя один из узлов ESXi, все виртуальные машины с этого узла будут запущены на свободных слотах (мощностях) других ESXi узлов кластера.
*Общее хранилище данных может представлять собой не только «железную» СХД, но и быть программным. У VMware для этой цели есть продукт vSAN (virtual storage area network). У RedHat есть GlusterFS и т.д.
Список терминов
Isolation response (IR) – параметр, определяющий действие ESXi-хоста при прекращении им получения сигналов доступности кластера. При создании кластера на каждый ESXi-хост устанавливается HA Agent, который будет обмениваться сигналами доступности (Heartbeat);
Reservation – параметр, рассчитывающийся на основе максимальных отдельных характеристик всех ВМ в кластере и в дальнейшем использующийся для расчета Failover Capacity;
Failover Capacity (FCap) – параметр, определяющий реальную отказоустойчивость. Измеряется в целых числах и обозначает, какое максимальное количество серверов в кластере может выйти из строя, после чего сам кластер всё еще будет продолжать функционировать;
Number of host failures allowed (NHF) – параметр задается администратором. Определяет целевой уровень отказоустойчивости. Такое количество узлов ESXi может одновременно выйти из строя;
Состояние Admission Control (состояние ADC) – автоматически рассчитывается как отношение Failover Capacity к Number of host failures allowed;
Параметр Admission Control (параметр ADC) – назначается администратором. Определяет поведение виртуальных машин при недостаточности слотов для их запуска;
Restart Priority (RP) – приоритет запуска машин после падения одного из узлов ESXi, входящих в кластер.
Последовательность создания VMware HA кластера
Определяем количество и размер слотов на узлах ESXi (Reservation); Устанавливаем значение Number of host failures allowed (NHF); Сравниваем NHF и FCap. Если NHF больше FCap, нам необходимо: Либо установить параметр ADC в Allow virtual machine to be started even if they violate availability constraints; Устанавливаем параметр Admission Control в одно из состояний; Определяем поведение хоста при прекращении получения сигналов доступности от остальных узлов (Isolation Response);Isolation Response
Действия при прекращении получения сигналов доступности в кластере HA определяются значением Isolation Response, определяющим действие узла ESXi при прекращении им получения сигналов доступности кластера (Heartbeat). Прекращение получения сигналов доступности происходит из-за «изоляции» ESXi, например, в случае отказа сетевой карты.
Существует несколько предполагаемых сценариев развития событий:
Сбой отправки/получения сигналов доступности, но сама сеть продолжает функционировать; Перестала работать сеть между узлом ESXi и остальными узлами кластера, но ESXi продолжает функционировать;В первом случае, стоит выбрать значение параметра Isolation Response - Leave powered on, тогда все машины, продолжат свою работу, невзирая на то, что прекратят получать сигналы доступности.
Во втором случае следует выбрать Isolation Response – Power off либо Shutdown (установлен по умолчанию), если ESXi-хост перестал получать сигналы доступности, HA перенесет с общего хранилища ВМ, хранившиеся на этом хосте ESXi, на свободные ESXi-хосты. ESXi-хост должен автоматически выключаться, чтобы не возникало конфликтов двух одинаковых хостов.
По умолчанию Isolation Response установлен в режиме Power off. Мы не знаем как будут развиваться события в момент гипотетического отказа, поэтому мы рекомендуем оставлять значение IR в состоянии Power off, чтобы избежать риска появления в сети конфликтующих машин с одинаковыми сетевыми настройками.
Резервация ресурсов (Reservation)
При расчете параметра Failover Capacity кластер HA сначала создает слоты, определяемые параметром Reservation. Этот параметр рассчитывается по размеру максимальной из виртуальных машин, работающих на узлах кластера.
Параметр Failover Capacity
После расчета слотов определяется сам параметр Failover Capacity. Он измеряется в целых числах и обозначает, какое максимальное количество узлов в кластере одновременно может выйти из строя. При этом все машины должны продолжать функционировать.
Иллюстрируем параметр Failover Capacity. Возьмем два случая (по вертикали: 1-й случай - отказ одного узла ESXi, 2-й случай - отказ 2-х узлов ESXi).
Первый случай: 3 узла ESXi, по 4 слота на каждом, 6 виртуальных машин.
В этом случае при выходе из строя одного узла (например, №3), ВМ 4,5,6 будут запущены на других узлах (в нашем случае №2, показаны стрелками), однако, при выходе из строя еще одного узла, свободных слотов под запуск ВМ не останется.
Второй случай: 3 узла ESXi, по 4 слота на каждом, 4 виртуальные машины.
В этом случае, свободных слотов хватит, даже если упадет сразу 2 узла ESXi(в нашем случае, ВМ перенесутся на хост №1).
Технически параметр Failover Capacity рассчитывается следующим образом: из количества всех узлов в кластере мы вычитаем отношение количества виртуальных машин в кластере к количеству слотов на одном узле ESXi. Если получается не целое число, округляем вниз.
Для первого случая: 3-6/4=1.5 Округляем до 1;
Для второго случая: 3-4/4=2 Так и остается 2;
Admission Control
Admission Control мы условно разделили на состояние Admission Control (состояние ADC) и параметр Admission Control (параметр ADC).
Состояние ADC определяется соотношением реального уровня отказоустойчивости (FCap) и установленного администратором (NHF). Если FCap больше NHF, то кластер настроен корректно и проблем ожидать не следует. Если наоборот, то мы должны устанавливать параметр ADC.
Параметр ADC определяется администратором и может иметь два состояния:
Do not power on virtual machines if they violate availability constraints – не включать виртуальные машины, если не достаточно слотов для обеспечения целевого уровня отказоустойчивости; Allow virtual machine to be started even if they violate availability constraints – разрешить запуск виртуальных машин, несмотря на возможную нехватку ресурсов для их запуска;При выборе параметра ADC следует заранее понять, как будет устроен кластер и для каких целей он необходим:
Если наша основная задача – это надежность самого кластера, несмотря на то, какие ВМ будут включены, нам следует установить Admission Control в состояние Do not power on….; Если же нам важно работа всех ВМ в кластере, нам придется установить Admission Control в состояние Allow VM to be started….;Во втором случае, поведение кластера может стать непредсказуемым (в худшем случае может дойти до такого, что ВМ опустят значение ADC до нулевого значения, тем самым сделав бесполезным технологию HA)
Рекомендации по созданию кластера vSphere HA
Мы представим общие рекомендации по созданию кластера HA:
Для кластера с включенной службой HA необходимо, чтобы все виртуальные машины и их данные находились на общем хранилище данных (Fibre Channel SAN, iSCSI SAN, or SAN iSCI NAS). Это необходимо, чтобы включать ВМ на любом из хостов кластера. Это также означает, что узлы должны быть настроены для доступа к тем же самым сетям виртуальной машины, совместно используемой памяти и другим ресурсам; Каждый сервер ESXi в кластере HA производит мониторинг узлов сети для обнаружения сбоев серверов. Чтобы сигналы доступности не прерывались, рекомендуется устанавливать резервные сетевые пути. Если первое сетевое соединение узла перестало функционировать, сигналы доступности (heartbeats) начнут передаваться по второму соединению. Для повышения отказоустойчивости, рекомендуется использовать два и более физических сетевых адаптерах на каждом узле; Если нужно использовать службу DRS совместно с HA для распределения нагрузок по узлам, узлы кластера должны быть частью сети vMotion. Если узлы не включены в vMotion, то DRS может неверно распределять нагрузку на узлы;esxi cluster
| Backup для виртуальных машин | Arcserve для VMware |

Работая с нами Вы, получите:
Наши цены ниже по целому ряду причин:
V-GRADE - является Официальным Партнером VMware уровня Advanced;
Работаем без посредников , напрямую с VMware, Veeam, Arcserve для VMware.
Наши эксперты:
У нас есть конфигуратор VMware, лучшие цены, актуальные статьи. лучшие эксперты.

Что такое HA Admission control в ESXI 5.x.x
Конспект по принципам работы HA admission control.
Почти все, что нужно знать об admission control, умещается в одном предложении:
vCenter Server использует admission control, чтобы обеспечить достаточное количество ресурсов для отказоустойчивости и выполнения требований резервирования ресурсов.
Это утверждение делится на две задачи для admission control:
- обеспечить достаточное количество ресурсов на случай сбоя;
- обеспечить соблюдение резервирования ресурсов для виртуальных машин (CPU reservations, memory reservations).
Т.о. admittion control - это резервирование ресурсов, а не управление ими.
При расчетах admission control учитывает только включенные виртуальные машины и активные хосты.
Admission control имеет три политики, каждая из которых по разному резервирует ресурсы кластера:
1. Host failures the cluster tolerates;
2. Percentage of cluster resorces reserved as failover spare capacity;
3. Specify failover hosts.
Политика Specify failover hosts наиболее проста для понимания. Она позволяет определить хост, который будет использоваться в случае сбоя. Этот хост будет стоять и ждать своего часа. Простой оборудования - основной минус этой политики.
Две другие политики рассчитывают резервы на отказоустойчивость, исходя в основном из значений резервов CPU и памяти, выставленных на включенных виртуальных машинах.
Политика Host failures the cluster tolerates (количество сбоев хостов, на которое рассчитан кластер) ведет расчет ресурсов с помощью так называемых слотов и учитывает наихудший сценарий событий. Слот состоит из двух компонентов:
- Memory slot (слот памяти);
- CPU slot (слот CPU).
При расчете слота памяти учитывается включенная виртуальная машина в кластере, которая имеет самый большой резерв памяти, и ее overhead. Размер слота памяти равен memory overhead + memory rezervation.
Размер слота CPU определяется по наибольшему значению резерва CPU для включенной виртуальной машины, либо берется значение по умолчанию 32MHz для vSphere 5.0, 256MHz для более ранних версий.
Разделив общее количество ресурсов на размер слота HA admission control получает количество свободных слотов. Между числом слотов памяти и числом слотов CPU выбирается наименьшее. Например, имеем 80 слотов памяти и 120 слотов CPU, значит, фактически имеем 80 слотов. Из этого числа отнимаем количество слотов на самом мощном хосте, т.к. на нем этих самых слотов помещается больше всего (т.е. потеря этого хоста - это и есть наихудший сценарий). Т.о. если у нас 5 хостов, и на каждом по 10 слотов памяти и CPU, то мы имеем не 50, а 40 слотов для работы при "Host failures the cluster tolerates" = 1.
Очевидно, что алгоритм этой политики "reservations -> slot size -> worst case" (резерв -> размер слота -> наихудший случай) очень сильно зависит от значений резервирования, выставленных на виртуальных машинах.
Политика Percentage of cluster resorces reserved as failover spare capacity дает возможность установить размер резерва ресурсов под отказоустойчивость. В vSphere 5.0 этот резерв устанавливается отдельно для памяти и CPU. В этой политике сравниваются текущее значение ресурсов, доступных для включения новых виртуальных машин (Current Failover Capacity), с заданным резервом ресурсов под отказоустойчивость (Configured Failover Capacity). Если Current меньше Configured, виртуальная машина не включится. Грубо принцип такой: если в кластере из четырех хостов Configured Failover Capacityустановлен 25%, то ресурсы, эквивалентные ресурсам одного хоста, резервируются под отказоустойчивость.
Расчеты выглядят так
Current Failover Capacity = (root resource pool - resource requirements) / root resource pool,
где
root resource pool - общее число ресурсов хостов минус расходы на гипервизор (т.е. это не все физические ресурсы хостов);
resource requirements - ресурсы, необходимые для работы включенных виртуальных машин.
Resource requirements - это сумма требований к ресурсам от каждой включенной виртаульной машины:
- для памяти: memory overhead + memory rezervation;
- для CPU берется установленный резерв либо значение по умолчанию 32MHz для vSphere 5.0, 256MHz для более ранних версий.
Например,
- кластер состоит из трех хостов по 9GHz и 24GB (расходы на гипервизор уже учтены);
- в нем 4 включенных виртуальных машины:
- VM1 использует 2GHz и 1GB (без резерва),
- VM2 использует 2GHz и 2GB (резерв 2GB),
- VM3 использует 1GHz и 2GB (резерв 2GB),
- VM4 использует 3GHz и 6GB (резерв 1GHz и 2GB);
- memory overhead для каждой виртуальной машины 100MB;
- Configured CPU Failover Capacity - 25%, Configured Memory Failover Capacity - 25%.
Получаем
root resource pool CPU = 9GHz+9GHz+9GHz = 27GHz,
root resource pool memory = 24GB+24GB+24Gb=72GB,
-
CPU resource requirements = 32MHz+32MHz+32MHz+1GHz= 1.096GHz,
Memory resource requirements = 0+100+2048+100+2048+100+2048+100= 6544MB = 6.4GB;
-
Current CPU Failover Capacity = (27GHz-1.096GHz)/27= 95.94%=96%,
Current Memoty Failover Capacity = (72GB – 6.4Gb)/72= 91%.
-
Из этих ресурсов мы можем использовать на новые виртуальные машины:
CPU = 96-25 = 71%,
Memory = 91- 25 = 66%.
Логично было бы параметры Configured Failover Capacity настраивать при изменении количества хостов в кластере.
Самой прозрачной и логичной выглядит политика Specify failover hosts. Используем ее, если не душит жаба по поводу простаивающих мощностей.
Между политиками Host failures the cluster tolerates и Percentage of cluster resorces reserved as failover spare capacity есть смысл выбрать вторую, как наиболее гибкую и простую. Собственно, из всех трех политик заокеанские гуру как правило рекомендуют выбирать Percentage of cluster resorces reserved as failover spare capacity.
Тут собираю интересное по интересующей меня теме виртуализации.
- Главная страница
- Книга по vSphere
- Performance - как правильно мониторить
- VMware Certification
- Курсы VMware
- Подборка важных материалов
Подпишись на обновления по RSS
Посты по email
Обо мне
Рекомендую
Последние комментарии
Подпишись на комментарии
Комментарии КомментарииПопулярные посты за месяц
Intel купил McAfee. по рассказам знающих тему все было вот так: - Так. Нам нужен антивирус. Купите кто-нибудь McAfee. Вечером: .
Популярные посты за все время


Архив блога
Ярлыки
пятница, 3 июня 2011 г.
HA admission control
Последние несколько недель у меня происходило довольно много дискуссий по поводу вроде бы довольно банального VMware HA. Дело в том, что в какой-то момент я задумался над некоторыми его настройками, и нашел их менее очевидными, чем это мне казалось. И вот по этому поводу и хотелось бы немного вбросить.
- При планировании инфраструктуры.
- При эксплуатации инфраструктуры.
- Запас на пиковые нагрузки;
- Запас на рост на будущее;
- Запас на случай отказа одного из серверов;
- Запас на неправильные расчеты исходных ресурсов ВМ.

Или в ситуации, когда администратор vSphere не обладает достаточными возможностями по продавливанию бюджета на очередной сервер.
У кластера HA есть соответствующая настройка - Admission Control (рис.2).

Самый простой вариант. Мы сами выбираем тот один сервер, на котором HA не позволит работать ни одной виртуальной машине. Даже DRS или мы сами не сможем мигрировать на него ВМ или включить. Но сам сервер работать будет все время, пустым. А остальные сервера HA не будет контролировать никак (рис. 4).

Кстати, если вдруг откажут одновременно два сервера, один из которых - сервер запаска, то HA будет распихивать виртуальные машины по наиболее свободным серверам кластера из оставшихся в живых.
То же самое, насколько я понимаю, должно произойти если на сервере-запаске кончатся ресурсы, например из-за бут-шторма.

Проблем две.
Первая, не очень острая - а сколько процентов надо указать?
Вторая проблема возникает в правильном понимании этих процентов. Как вы думаете, что они означают?

Для правильного понимания ситуации давайте немного отвлечемся.

Правы те, кто ответил Reservation.
Т.е. резервирование 25% ресурсов каждого сервера означает, что на каждом сервере сумма резервов включенных виртуальных машин должна быть меньше-равна 75% ресурсов сервера.
А максимальное или реальное потребление ресурсов виртуальными машинами НЕ_УЧИТЫВАЕТСЯ_НИКАК.
Правильный ответ: До задницы много. Порядка 450 если учитывать только резервирования памяти.
Это означает, что
По той простой причине, что нам не очень радостно от того, что HA нам позволяет включить сотую ВМ, хотя уже на тридцатой сервер стал нагружен на 100%.
Кстати говоря, а какой должна быть настройка reservation?

Именно на уровне каждой ВМ, не только пулов ресурсов или vApp!
В этом варианте резервирования мы указываем число серверов (рис. 9), смерть которого кластер должен пережить без тормозов виртуальных машин.

Так или иначе размер слота выбран, теперь считаем статистику нашего кластера (рис. 10).



В каждом шасси не более четырех серверов, потому что HA гарантированно переживает отказ максимум четырех серверов.
И теперь нас интересует настройка резервирования ресурсов для каждого кластера независимо. К сожалению, если отказ шасси влечет за собой отказ более одного сервера кластера, то простого способа гарантировать достаточность ресурсов для ВМ после сбоя нет. Ну или я не вижу :-)
Насколько я знаю, при старте каждой виртуальной машины тот хост, который выполняет роль Failover Coordinator, выбирает на каком сервере ей стартовать. Выбор идет в зависимости от нагрузки на процессор и память серверов.
Если ручной контроль запаса ресурсов на случай отказа сервера нам не подходит, то следует пользоваться автоматическим.
Обратите внимание - по данным опроса в прошлом посте 169 из 184 (на момент написания) ответивших не используют reservation для широкого круга ВМ - т.е. если у этих 92% ответивших настроен первый или второй вариант Admission Control - это бессмысленно.
Еще одним вариантом является добавление логики к работе HA при помощи самописных скриптов. Но это уже нефиговое такое джедайство, и я тут ничего конкретного посоветовать не могу.
понедельник, 16 июля 2012 г.
vSphere Admission Control
Когда мы говорим про контроль доступа, или же admission control, мы обычно имеем в виду политики HA, хотя это не единственная функция, использующая контроль доступа. DRS, Storage DRS, да и сами ESXi хосты имеют свой собственный механизм контроля доступа. Предлагаю детально взглянуть на то, чем же является механизм контроля доступа, и какое участие он принимает в запуске виртуальной машины.
Какова же основная функция контроля доступа? Мне нравится называть эту функцию командой виртуальных балансировщиков. Admission control разработан, чтобы гарантировать предоставление виртуальной машине требуемое и настроенное количество ресурсов. Последняя часть предыдущей фразы и объясняет суть контроля доступа.
Во время запуска или перемещения ВМ контроль доступа проверяет наличие достаточно количества незарезервированных ресурсов, доступных для данной ВМ. Если у виртуальной машины настроены резервы ЦПУ, памяти или обоих компонентов сразу, то admission control должен удостовериться, что кластер хранилищ, вычислительный кластер, ресурсный пул и сам хост могут выделить требуемые ресурсы. И если гарантированное выделение ресурсов какого-либо из компонентов невозможно, необходимо чтобы система могла это учитывать. Именно для этого и разработан контроль доступа.
Так как разные компоненты vSphere могут быть настроены по-разному, то каждая функция использует свой собственный механизм контроля доступа, так как очень опасно использовать взаимную зависимость в таком важном компоненте. Ниже представлена схема работы admission control и контрольные точки.
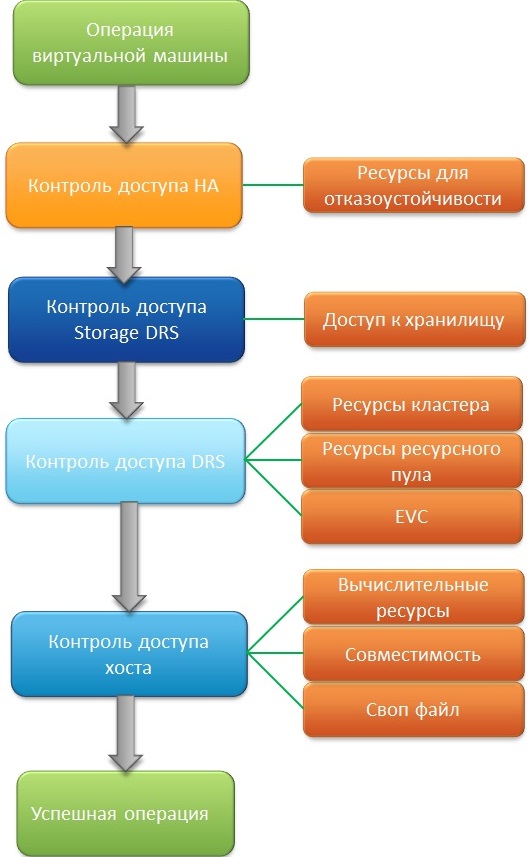
HA admission control: во время запуска ВМ данная функция проверяет может ли данная операция быть проведена не забирая ресурсы, зарезервированные на случай аварии. Согласно политикам и настройкам НА проверяет, может ли кластер предоставить требуемое, не зарезервированное для восстановление в случае аварии, количество ресурсов.
Читайте также: