
Abbyy finereader 12 что это
Система оптического распознавания текстов FineReader в представлении не нуждается и широко известна во всем мире. За 21 год своего существования на рынке (первая версия программы увидела свет в 1993 году) флагманский продукт ABBYY сумел не только завоевать доверие более чем 20 миллионов пользователей, но и задать новые стандарты качества и направления развития решений класса Optical Character Recognition (OCR). Успело приложение закрепиться и в компьютерной терминологии, о чем свидетельствует прочно вошедшее в обиход и ставшее привычным для многих людей выражение «распознать с помощью FineReader». Система из года в год демонстрирует свою востребованность на рынке электронного документооборота, и нет ничего удивительного в том, что специалисты ABBYY стараются уделять максимум внимания продукту и совершенствованию задействованных в нем технологий.

ABBYY FineReader: смена поколений
В новой, двенадцатой по счету версии OCR-пакета разработчики добавили поддержку распознавания русского языка с ударениями и внесли ряд улучшений в движок системы, в результате чего удалось добиться увеличения скорости обработки документов, точности определения их структуры и распознавания символов. По результатам проведенных ABBYY тестов, FineReader 12 демонстрирует возросшую на 10-15% производительность по сравнению с предыдущей редакцией продукта, точнее воссоздает и сохраняет структуру таблиц (на 40%), диаграмм и графиков (на 33%) плюс лучше справляется с текстами, написанными на иврите, арабском, а также китайском, японском и корейском языках. Все это стало возможным благодаря доработкам адаптивной технологии распознавания документов ADRT (Adaptive Document Recognition Technology), играющей ключевую роль в процессе предварительного анализа изображений и последующей сборки обработанных данных в единое целое.
Не остался без внимания программистов компании ABBYY интерфейс приложения — он стал более «собранным», получил новые диалоги открытия и сохранения файлов, выполнен в единой с Windows 8 стилистике и адаптирован для устройств с сенсорными экранами. FineReader 12 получил не только укрупненные элементы управления, но и поддержку мультитач-жестов, позволяющих пользователям планшетных компьютеров быстро изменять масштаб открытого в программе документа, пролистывать страницы и выполнять прочие операции простым движением пальцев.

Пользовательский интерфейс ABBYY FineReader 12
Серьезно изменились механизмы обработки многостраничных документов и средства извлечения из них фрагментов текста. Операции, которые раньше могли выполняться достаточно длительное время и блокировали доступ пользователя к интерфейсу программы, в новой версии FineReader выполняются в фоновом режиме. Теперь можно просматривать документ, корректировать области распознавания, изменять порядок страниц, заходить в меню программы и выполнять прочие действия, не дожидаясь, пока OCR-система обработает загруженный файл.
В обновленном FineReader нет необходимости дожидаться распознавания всего документа целиком. Можно сразу перейти к нужной странице, выделить необходимую область (картинки, текст, таблицы) и нажать «Копировать». Программа автоматически распознает содержимое и сохранит его в буфер обмена.

В FineReader 12 реализована удобная работа с многостраничными документами и фрагментами текста
Для улучшения качества исходных изображений в FineReader 12 добавлены новые инструменты предобработки графических файлов. В программе появились средства автоматической обрезки фотографий с исправлением геометрических искажений, выравнивания яркости и цвета фона, а также удаления следов печатей и пометок на черно-белых изображениях. Возможности встроенного редактора изображений позволяют изменить разрешение обрабатываемых фотографий, устранить перекосы строк, поменять ориентацию страниц и многое другое, причем все эти настройки можно сделать автоматическими.

Улучшения в предобработке изображений
Усовершенствованиям подвергся также инструментарий для ручной корректировки результатов распознавания. Появилась возможность корректировать форматирование текста в окне «Проверка» — указывать тип шрифта, его размер и начертание, вставлять специальные символы из таблицы Unicode. Для удобства работы с большими объемами текста был добавлен переход между словами с помощью «горячих» клавиш клавиатуры.

Улучшения в окне «Проверка»
В настройках двенадцатой версии FineReader появилась возможность отключать генерацию таких элементов структуры, как колонтитулы, сноски, содержание, нумерованные списки. Деактивация распознавания определенных структурных составляющих позволяет ускорить перевод документов в электронный вид и избежать проблем при их последующей обработке сторонними продуктами (например, системами перевода или конверторами в e-book). Кроме того, пользователь может выбрать один из двух режимов распознавания — с приоритетом скорости или качества. Первый режим позволяет обрабатывать документы до 50% быстрее и рекомендуется для распознавания больших объемов документов с простым оформлением и хорошим качеством печати. Второй режим требует больше времени, но обеспечивает лучшее качество распознавания. Он пригоден для распознавания сложных документов, содержащих текст на цветном фоне, таблицы и прочие элементы оформления.

Настройки OCR-движка FineReader 12
Претерпели изменения в FineReader 12 также инструменты сохранения обработанных документов и их конвертирования в различные форматы. Из наиболее значимых новшеств можно отметить функцию создания файлов EPub, соответствующих стандартам спецификации 2.0.1 или 3.0, а также тесную интеграцию с Google Drive, Dropbox и SkyDrive — теперь перечисленные облачные хранилища отображаются в диалоге сохранения файлов и всегда находятся под рукой. При сохранении в PDF стало возможным использование новой технологии Precise Scan, улучшающей внешний вид отсканированного документа посредством сглаживания изображения символов и устраняющей эффект пикселизации при увеличении масштаба страницы. При конвертации документов в формат XLSX отныне доступны опции сохранения картинок, удаления форматирования текста, а также сохранения каждой страницы документа на отдельном листе Excel. Кроме того, в корпоративной версии FineReader отныне поддерживается экспорт непосредственно в SharePoint Online и Microsoft Office 365, что тоже положительным образом отражается на скорости работы с программой.

Улучшения при сохранении в PDF
Таковы основные отличительные особенности обновленной линейки FineReader, определенно заслуживающей внимания тех, кто часто занимается оцифровкой бумажных документов. Программа представлена на рынке в редакциях Professional и Corporate, распознает документы на 190 мировых языках, совместима со всеми популярными моделями сканеров и многофункциональных устройств (МФУ) и позволяет распознавать текст, полученный с фотоаппарата или встроенной камеры смартфона. Для корректной работы пакета необходим функционирующий под управлением Windows компьютер с тактовой частотой процессора 1 ГГц или выше и объемом оперативной памяти не менее одного гигабайта (для обладателей компьютеров Apple предусмотрен FineReader Pro для Mac).
И последнее. Прилагаемый к FineReader 12 Professional лицензионный договор допускает использование одной копии приложения на одном стационарном компьютере и одном портативном ПК при условии, что оба устройства принадлежат приобретшему продукт пользователю. Таким образом, программу можно установить и на рабочий ноутбук, и на домашний компьютер, не нарушая тем самым условий лицензионного соглашения с компанией ABBYY.

Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.
Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями.
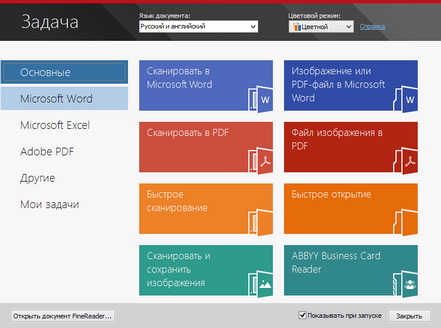
ABBYY FineReader: как работать
Для эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск.
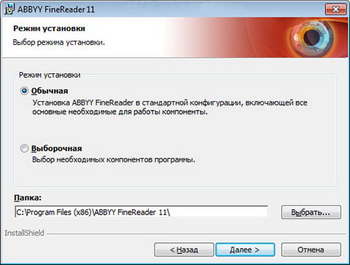
Как установить ABBYY FineReader 11
Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.

Как запустить ABBYY FineReader
Запустить ярлык с рабочего стола компьютера
Выбрать в меню Пуск раздел Программы и запустить ABBYY FineReader
Если вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программы
Выберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader».
Как настроить ABBYY FineReader 12 Professional
Профессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
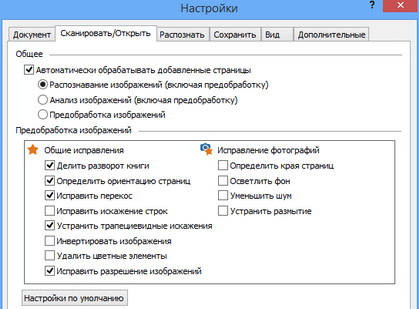
Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла.
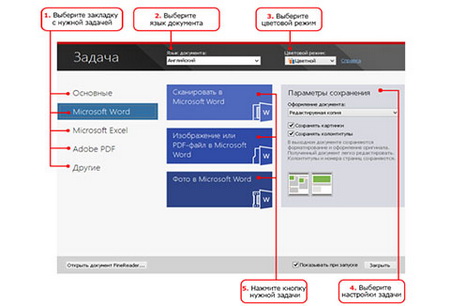
ABBYY FineReader - как переводить
Для качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
ABBYY FineReader: как распознать текст
Для качественной конвертации полученной информации в PDF-формат, программа должна ее распознать. В ABBYY FineReader можно установить режим автоматического распознавания текста или ручного. Качество отсканированного документа можно отрегулировать настройками распознавания, такими как: режим сканирования, язык распознавания, тип печати и многое другое. Перед распознаванием текста, на этапе сканирования программа будет работать по одному из стандартных сценариев, который можно выбрать.
В меню выберите «Сервис», перейдите в «Опции» и укажите режим распознавания: тщательное или быстрое распознавание. Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.
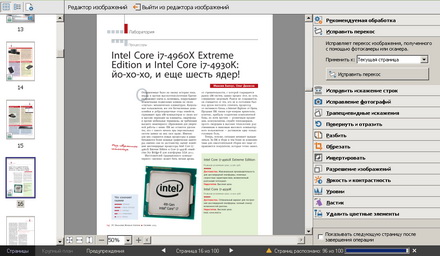
Как в ABBYY FineReader изменить текст
Чтобы не возникало сложностей при редактировании в ABBYY FineReader 12, как изменить текст в этой программе, разработчики создали интуитивно понятный интерфейс и удобную навигацию по пунктам. Отредактировать текст можно двумя способами: непосредственно в окне «Текст», либо выбрав на панели инструментов «Сервис» и далее «Проверка». Доступные средства для изменения текста находятся над окном «Текст» и включают в себя стандартный набор для редактирования шрифта, его размера, отступов и замены символов. Для редактирования непосредственно PDF-изображения, нужно зайти в меню в «Редактор изображений» и выбрать из списка нужную функцию.

Мы строили-строили и, наконец, построили!
Как понятно из названия, мы недавно обрелизились. В связи с этим под катом постараемся простым русским языком объяснить, чем хорош FineReader 12, чтобы те, кому он нужен, могли понять, бежать уже сейчас в онлайн-магазин за новой версией или спокойно ждать пару лет появления счастливой тринадцатой.
Про интерфейс

Начну с того, что обязательно бросится в глаза пользователям старых версий. То есть с интерфейса. Нет, мы не достигли идеала, как на левой картинке, но планомерно к нему двигаемся. Очередными шагами в этом движении стали фичи с внутренними именами «немодальность» и «быстрое открытие».

Кроме того, в новой версии предусмотрен сценарий цитирования. Он предполагает, что пользователю нужен не весь документ в виде файла(/-ов), а только отдельные его куски для дальнейшего их копипащения куда-нибудь. Честно говоря, если в вашей обычной работе речь идёт о цитировании одного-двух абзацев, то я бы рекомендовал использовать наш Screenshot Reader (кстати, он не только продаётся отдельно, но и входит в состав FineReader в виде бонуса). Однако, если из 100-страничного документа надо получить 15 конкретных абзацев, то новая фича будет как нельзя кстати. Ощутимым плюсом в таком сценарии будет то, что FineReader вполне прилично выделяет блоки, а значит, остаётся только найти нужную страницу и нажать Copy на целевом блоке. Если у вас не Pentium 3, а что-нибудь посвежее, то, скорее всего, дело займёт не больше секунды.
Справку мы теперь держим в онлайне. Продукт, как справедливо заметил aram_pakhchanian, нашпигован возможностями, а это очевидным образом обязывает справку быть точной и актуальной. Онлайновость тут — идеальный выход: сегодня тестируем встраивание доперевода, а завтра любой пользователь уже пользуется актуализированной информацией.
Кроме того, у нас теперь есть механизм автообновления. Конечно же, скачивать придётся не целый дистрибутив, а только патч (единицы мегабайт). FineReader сам всё сделает, разве что уточнит, хочет ли пользователь обновиться.
Я, вообще-то тестированием занимаюсь, поэтому продукт вижу уже давно и, честно говоря, даже не знаю, что ещё добавить — привык я уже к его новому виду и новым фичам. В связи с этим вот вам обзор на 3dnews, а я передаю микрофон 57ded, который поведает о том, почему качество распознавания растёт с 98% уже много лет на 30-40% в продуктовый цикл, но всё ещё не достигло 200%.
Про технологии

Про новые или хорошо забытые старые функции обработки изображений всё понятно. С одной стороны, мы, наконец, сделали удаление цветных печатей на офисных документах как на картинке справа, что, IMHO, вполне приемлемо и соответствует нынешнему уровню достижений науки и технологий.
С другой стороны сдули толстый слой нафталина с функций восстановления баланса белого и прочего «визуального улучшения» изображения, впервые представленных ещё в далёком 2007 в рамках FineReader 8. Помимо этого официально объявлено об улучшении работы на документах с таблицами и диаграммами. Насчёт диаграмм замечу, что, скорее всего, здесь к диаграммам из-за какого-то то ли недоразумения, то ли нежелания разбираться в деталях, отнесли документы с картинками, где на картинке был скриншот – эту-то задачу мы как раз решали целенаправленно.
Как гласит анонс FineReader’ а (ссылку давать не будем, анонсам тут не место, правда) достигнуты улучшения в “up to” 33% на диаграммах со скриншотами и «до» 40% на таблицах. Ни один нормальный заинтересованный скептик не пропустит просто так эти цифры, потому поясним, откуда они взялись. Капитан Очевидность подсказывает, что точность распознавания обычно меряют, сравнивая результат работы программы OCR с неким эталоном «как должно быть». Если мы меряем точность распознавания текста, когда уже известно, где именно этот текст расположен (задача, пленяющая многих своих красотой и так и зовущая применить всю мощь теории классификаций), то измерить, насколько результат близок к оригиналу, не представляет вообще никаких проблем.
Для задачи выделения текстовых зон так просто результат померить не получится: к примеру, потому, что можно как объединять текст и заголовок к нему в один блок, так и делать на этом два текстовых блока. Сейчас в мире многим нужно измерить качество работы выделителя текстовых зон, все меряют немного по-разному, но общая идея очень проста. В эталоне храним все таблицы, тексты и картинки на страницы. Следим, чтобы в результатах распознавания таблицы и картинки оказались на месте, а текст оказался внутри текстовых зон. И далее разными хитрыми способами запрещаем разное нехорошее. Скажем, нельзя объединять две колонки в один блок (потеряется порядок чтения), нельзя разрывать строки посерёдке и отрывать буквицу от текста (по той же причине), не надо объединять в один блок чёрный текст на белом фоне и белый на чёрном.
Теперь, чтобы померить точность для таблиц и диаграммо-скриншотиков, осталось всего ничего: посмотреть, сколько таблиц не находила предыдущая версия, сравнить с количеством таблиц, с которыми не справилась нынешняя, «недостачу» таблиц прошлой версии принять за 100% и получить искомый результат… Упс…, снова не всё так просто.
Во-первых, таблицу нужно не просто найти, её нужно разметить на ячейки. Когда границы ячеек никак не обозначены, это становится непростой задачей. Но, как мы уже упоминали, значительного прогресса здесь мы достигли ещё в прошлой версии, так что в нынешней мы могли позволить себе двигаться «по инерции». Кстати, измерить качество разделения таблиц на ячейки – довольно простая задача. Как правило, можно твёрдо сказать, есть ли в данном месте граница ячеек или нет, так что для оценки качества FineReader’а требуется посчитать количество недостающих границ ячеек и добавить количество излишних.
потерю границы между столбцами таблицы следует считать более значимой ошибкой, чем случайное деление одной ячейки в заголовке таблицы, так что мы считаем именно что границы каждой ячейки – то есть вес вертикального разделителя равен количеству ячеек, которые он делит.Во-вторых, довольно сложно разметить достаточно большую базу изображений. Немного поясним здесь, в чём именно трудность. Предположим, мы разметили одну страницу из какого-то документа. На ней размещено хорошо если одна табличка, может быть пара картинок и довольно много текста. Для измерения точности распознавания мы получим несколько тысяч символов и сотни слов, а для задачи поиска таблиц – да, всего одну таблицу. Вряд ли здесь имеет смысл дальше ныть на тему, как всё непросто, вы уже и сами всё поняли.
В-третьих (вы что, всерьёз полагаете, что загвоздки у меня уже кончились?), в некоторых случаях человечество не может точно сказать, таблица перед нами, или текст. Скажем, как на картинке справа.
В таких случаях примем соломоново решение «И так, и так правильно».
Применив упомянутое колдунство, мы пришли к выводу, что на нашей базе…
«Стоп!» — справедливо возмутится любой оппонент, — «Использовать обучающую базу в качестве тестовой – это за гранью добра и зла. ». Что ж, придётся с ним согласиться. Действительно, сравнительное тестирование нужно проводить на совершенно новой базе свежескачанных или свежеотсканированных изображений, чтобы была гарантия, что программисты на них и не пытались настроиться. Но тут-то как раз мы и вспоминаем, что размечать эту базу недёшево. Пока что решение состоит в следующем:
- Уж какую смогли базу, ту и приспособили для честного тестирования;
- Точно измерить цифры улучшения не получится – так и пишем «улучшили на треть» или «улучшили на две пятых» — что в маркетинговых материалах превращается в 30-33-40 % (иногда мне кажется, что их авторы соревнуются в частоте употребления слова «процент»). Оттуда и наши стыдливые «до» или “up to”.
- Но зато раз уж база маленькая – можем провести «субъективный» тест – глазами просмотреть эту пару сотен изображений и сказать, какая из версий лучше на них отработала. Упомянутые цифры нашли субъективное подтверждение, что укрепляет нас в уверенности, что это правда.
На этом разрешите откланяться, предложив на прощание ознакомиться с триалом нашего чудо-продукта.
Один из популярнейших функционалов по работе со сканированием и обработкой файлов различного типа — Файн Ридер. Функционал программного продукта был разработан российской компанией ABBYY, он позволяет не только распознавать, но и обрабатывать документы (переводить, менять форматы и другое). Многие пользователи могут только установить, а как пользоваться ABBYY FineReader, сразу разобраться не могут. На многие вопросы вы сможете найти ответы в этой статье.

Что представляет собой приложение от ABBYY?
Чтобы подробно разобраться, что это за программа ABBYY FineReader 12, необходимо подробно рассмотреть все её возможности. Первой и самой простой функцией является сканирование документа. Существует два варианта сканирования: с распознаванием и без него. В случае обычного сканирования печатного листа вы получите изображение, которое сканировали в указанной папке на вашем компьютерном устройстве.
ВНИМАНИЕ. Лист нужно класть на сканирующую часть принтера ровно, по указанным на принтере контурам. Не допускайте заламывания исходника, это может привести к плохому качеству итогового скана.
Поместите документ в сканер для того, чтобы перевести его в электронный вид
Вы должны самостоятельно решить, для чего нужен FineReader именно вам, так как утилита имеет значительный функционал, например, вы можете самостоятельно выбрать в каком цвете хотите получить изображение, есть возможность перевести все фото в чёрно-белый. В чёрно-белом цвете распознавание происходит быстрее, качество обработки возрастает.
Если же вас интересует функция распознавания текста ABBYY FineReader, перед сканированием вам нужно нажать специальную кнопку. В этом случае есть несколько вариантов получения информации. Стандартно на ваш экран выведется распознанный кусок листа, который вы сможете скопировать или отредактировать вручную.
Если вы выберите другие функции, то сможете сразу получить файл Word-документом или Excel-таблицей. Выбирать функции очень просто, меню интуитивно понятно, легко настраивается благодаря тому, что все нужные вам кнопки перед глазами.
ВАЖНО. Перед тем как распознать текст ABBYY FineReader, вам необходимо точно подобрать язык обработки. Несмотря на то, что утилита работает полностью автоматически, бывает, что низкое качество исходника не позволяет понять, что за язык был в исходнике. Это сильно снижает качество итоговых результатов работы приложения.Несколько режимов работы
Чтобы полностью разобраться, как пользоваться ABBYY FineReader 12, необходимо попробовать два режима работы «Тщательный» и «Быстрое распознавание». Второй режим подходит для высококачественных изображений, а первый — для низкокачественных файлов. Режим «Тщательный» в 3–5 раз дольше обрабатывает файлы.
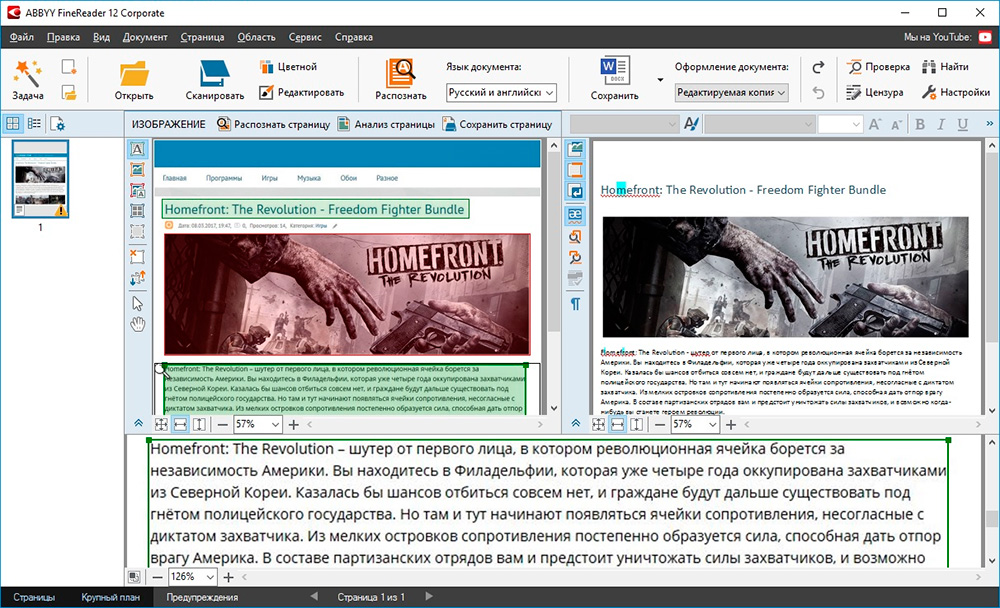
Какие ещё есть функции?
Распознавание текста в программе ABBYY FineReader не единственная полезная функция. Для большего удобства пользователей имеется возможность переводить документ в необходимые пользователю форматы (pdf, doc, xls и др.).
Изменение текста
Чтобы понять, как в Файн Ридере изменить текст, пользователю необходимо открыть вкладку «Сервис» — «Проверка». После этого откроется окно, которое позволит редактировать шрифт, менять символы, цвета и др. Если вы редактируете изображение, то стоит открыть «Редактор изображений», он практически полностью соответствует простой рисовалке Paint, но сделать минимальные правки позволит.
ВНИМАНИЕ. Если вы так и не смогли разобраться, как продуктивно пользоваться ABBYY FineReader, вы можете прочесть раздел «Помощь», который можно найти в окне приложения, во вкладке «О программе».Теперь вы знаете, для каких целей служит программа FineReader, и сможете правильно её применять у себя дома или в офисе. Функционал приложения огромен, воспользуйтесь им и вы сможете убедиться в незаменимости этого программного продукта при обработке документов и файлов во время офисной работы.
Читайте также: