
Как сделать фио раздельно в эксель
Как поставить фамилию после имени и отчества в ячейках Экселя? Например, изначально ФИО стоит так: "Собачкин Андрей Олегович". Мне надо получить "Андрей Олегович Собачкин". Нужна формула, а не макрос.
Я правильно понял, что Вы хотите, чтобы Эксель как то сам в правильном порядке поставил фамилию, имя и отчество, независимо от того, в каком порядке это напечатал пользователь? Тогда я советую добавить тег Эксель - если тут есть такой. а то люди далекие от "офиса" могут просто не въехать, про какие такие ячейки идёт речь. И, кстати, я сомневаюсь, что есть такая формула, и даже такой макрос.
S.H., да, в экселе. Порядок важен. Пользователь уже расписал ФИО в порядке "фамилия, имя, отчество". А мне нужно, что было так: "имя отчество фамилия". Для этого мне нужна формула, а то у меня аж 150 таких ФИО в экселе
3 ответа 3
На выбор. Ищем первый пробел и по нему делим текст:
Функция пользователя ( UDF ), позволяющая расставлять три слова в любом порядке или возвращать повторы слов.
Параметры, передаваемые в функцию: ссылка на ячейку (или текст) и три числа, устанавливающие порядок слов. Ссылка обязательна, числа - опционально (по умолчанию слова переставляются в порядке 2, 3, 1 (второе, третье, первое). Порядок по умолчанию можно поменять, изменив значения переменных jx
Функция записывается в общий модуль в редакторе VBA . В ячейке вызывать функцию формулой.
Примеры для исходного текста Первый Второй Третий
=fShiftName(A2) - с параметрами по умолчанию: Второй Третий Первый
=fShiftName(A2;;;1) - то же, что и по умолчанию: Второй Третий Первый
=fShiftName("Первый Второй Третий";3;1;2) - другая перестановка: Третий Первый Второй
=fShiftName("Первый Второй Третий";3;;3) - повтор слова: Третий Третий Третий
Действительно при работе с программой эксель, может потребоваться разделить ФИО по отдельным столбцам. Сделать это с помощью специальных функций довольно просто, рассмотрим последовательность действий на простом примере.
Перед нами таблица, в которой в одной ячейке сразу указаны ФИО, необходимо их поделить на три столбца.

Первый шаг. Добавим два дополнительных столбца, чтобы в них затем попали имена и отчества.



Четвертый шаг. Форматируем шапку столбца, регулируем размеры ячеек, после получаем готовую таблицу с разделенными ФИО по разным ячейкам.
Для начала скажу, что я зарабатываю через вот этого брокера , проверен он временем! А вот хороший пример заработка , человек зарабатывает через интернет МНОГО МНОГО МНОГО и показывает все на примерах, переходи и читай! Добавь страницу в закладки. А теперь читаете информацию ниже и пишите свой отзыв
Раннее мы рассматривали возможность разделить текст по столбцам на примере деления ФИО на составные части.
Видео: Разделить текст по столбцам в Excel / Text to Columns (Урок 6) [Eugene Avdukhov, Excel Для Всех]
Несомненно, это очень важный и полезный и инструмент в Excel, который значительно может упростить множество задач. Но у данного способа есть небольшой недостаток.
Если вам, например, постоянно присылают данные в определенном виде, а вам постоянно необходимо их делить, то это занимает определенное время, кроме того, если данные вам прислали заново, то вам снова нужно будет проделать все операции.
Содержание
- 1 Пример 1. Делим текст с ФИО по столбцам с помощью формул
- 1.1 Приступаем к делению первой части текста — Фамилии
- 1.2 Приступаем к делению второй части текста — Имя
- 1.3 Приступаем к делению третьей части текста — Отчество
- 2 Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Пример 1. Делим текст с ФИО по столбцам с помощью формул Если рассматривать на примере деления ФИО, то разделить текст можно будет с помощью текстовых формул Excel, используя функцию ПСТР и НАЙТИ, которую мы рассматривали в прошлых статьях.
В этом случае вам достаточно вставить данные в определенный столбец, а формулы автоматически разделят текст так как вам необходимо. Давайте приступит к рассмотрению данного примера. У нас есть столбец со списком ФИО, наша задача разместить фамилию, имя отчество по отдельным столбцам.
Попробуем очень подробно описать план действия и разобьем решение задачи на несколько этапов. Первым делом добавим вспомогательные столбцы, для промежуточных вычислений, чтобы вам было понятнее, а в конце все формулы объединим в одну.
и протянем вниз. Теперь нам необходимо найти порядковый номер второго пробела. Формула будет такая же, но с небольшим отличием. Если прописать такую же формулу, то функция найдет нам первый пробел, а нам нужен второй пробел.
Значит на необходимо поменять третий аргумент в функции НАЙТИ — начальная позиция — то есть позиция с которой функция будет искать искомый текст.
Мы видим, что второй пробел находится в любом случае после первого пробела, а позицию первого пробела мы уже нашли, значит прибавив 1 к позиции первого пробелам мы укажем функции НАЙТИ искать пробел начиная с первой буквы после первого пробела.
Функция будет выглядеть следующим образом:
Далее протягиваем формулу и получаем позиции 1-го и 2-го пробела.
Приступаем к делению первой части текста — Фамилии
Для этого мы воспользуемся функцией ПСТР, напомню синтаксис данной функции:
=ПСТР(текст- начальная_позиция- число_знаков), где
- текст — это ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае это 1, то есть начиная с первой буквы;
- число_знаков — мы видим, что фамилия состоит из всех знаков, начиная с первой буквы и до 1-го пробела. А позиция первого пробела нам уже известна. Это и будет количество знаков минус 1 знак самого пробела.
Формула будет выглядеть следующим образом:
Приступаем к делению второй части текста — Имя
Снова используем функцию =ПСТР(текст- начальная_позиция- число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае Имя начинается с первой буква после первого пробела, зная позицию этого пробела получаем H2+1;
- число_знаков — число знаков, то есть количество букв в имени. Мы видим, что имя у нас находится между двумя пробелами, позиции которых мы знаем. Если из позиции второго пробела отнять позицию первого пробела, то мы получим разницу, которая и будет равна количеству символов в имени, то есть I2-H2
Получаем итоговую формулу:
Приступаем к делению третьей части текста — Отчество
И снова функция =ПСТР(текст- начальная_позиция- число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — Отчество у нас находится после 2-го пробелам, значит начальная позиция будет равна позиции второго пробела плюс один знак или I2+1;
- — в нашем случае после Отчества никаких знаков нет, поэтому мы просто может взять любое число, главное, чтобы оно было больше возможного количества символов в Отчестве, я взял цифру с большим запасом — 50
Видео: Формулы в Эксель
Далее выделяем все три ячейки и протягиваем формулы вниз и получаем нужный нам результат. На этом можно закончить, а можно промежуточные расчеты позиции пробелов прописать в сами формулы деления текста.
Смотрим первую формулу выделения Фамилии и смотрим где здесь встречается H2 или I2 и меняем их на формулы в этих ячейках, аналогично с Именем и Фамилией
Теперь промежуточные вычисления позиции пробелом можно смело удалить. Это один из приемов, когда для простоты сначала ищутся промежуточные данные, а потом функцию вкладывают одну в другую. Согласитесь, если писать такую большую формулу сразу, то легко запутаться и ошибиться.
Надеемся, что данный пример наглядно показал вам, как полезны текстовые функции Excel для работы с текстом и как они позволяют делить текст автоматически с помощью формул однотипные данные.
Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Рассмотрим второй пример, который так же очень часто встречался на практике. Пример похож предыдущий, но данных которые нужно разделить значительно больше. В этом примере я покажу прием, который позволит достаточно быстро решить вопрос и не запутаться.
Допустим у нас есть список чисел, перечисленных через запятую, нам необходимо разбить текст таким образом, чтобы каждое число было в отдельной ячейке (вместо запятых это могут быть любые другие знаки, в том числе и пробелы). То есть нам необходимо разбить текст по словам.
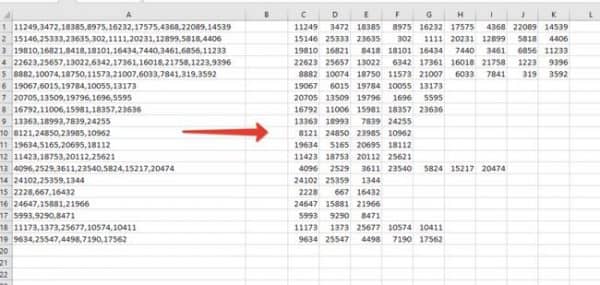
Напомним, что вручную (без формул) это задача очень просто решается с помощью инструмента текст по столбцам, который мы уже рассматривали. В нашем же случае требуется это сделать с помощью формул. Для начала необходимо найти общий разделить, по которому мы будет разбивать текст.
В нашем случае это запятая, но например в первой задаче мы делили ФИО и разделитель был пробел. Наш второй пример более универсальный (более удобный при большом количестве данных), так например мы удобно могли бы делить не только ФИО по отдельным ячейкам, а целое предложение — каждое слово в отдельную ячейку.
Собственно такой вопрос поступил в комментариях, поэтому было решено дополнить эту статью. Для удобства в соседнем столбце укажем этот разделитель, чтобы не прописывать его в формуле а просто ссылаться на ячейку. Это так же позволит нам использовать файл для решения других задач, просто поменяв разделитель в ячейках.
Теперь основная суть приема.
Шаг 1. В вспомогательном столбце находим позицию первого разделителя с помощью функции НАЙТИ. Описывать подробно функцию не буду, так как мы уже рассматривали ее раннее. Пропишем формулу в D1 и протянем ее вниз на все строки
То есть ищем запятую, в тексте, начиная с позиции 1
Шаг 2. Далее в ячейке E1 прописываем формулу для нахождения второго знака (в нашем случае запятой). Формула аналогичная, но с небольшими изменениями.
- Во-первых: закрепим столбец искомого значения и текста, чтобы при протягивании формулы вправо ссылки на ячейки не сдвигалась. Для этого нужно написать доллар перед столбцом B и A — либо вручную, либо выделить A1 и B1, нажать три раза клавишу F4, после этого ссылки станут не относительными, а абсолютными.
- Во-вторых: третий аргумент — начало позиции мы рассчитаем как позиция предыдущего разделителя (мы его нашли выше) плюс 1 то есть D1+1 так как мы знаем, что второй разделитель точно находится после первого разделителя и нам его не нужно учитывать.
Пропишем формулу и протянем ее вниз.
Шаг 4. Отделяем первое число от текст с помощью функции ПСТР.
Начальная позиция у нас 1, количество знаков мы рассчитываем как позиция первого разделителя минус 1: D1-1 протягиваем формулу вниз

Шаг 5. Находимо второе слово так же с помощью функции ПСТР в ячейке P1
Начальная позиция второго числа у нас начинается после первой запятой. Позиция первой запятой у нас есть в ячейке D1, прибавим единицу и получим начальную позицию нашего второго числа.
Количество знаков это есть разница между позицией третьего разделителя и второго и минус один знак, то есть E1-D1-1 Закрепим столбец A исходного текста, чтобы он не сдвигался при протягивании формулы право.
Шаг 6. Протянем формулу полученную на шаге 5 вправо и вниз и получим текст в отдельных ячейках.
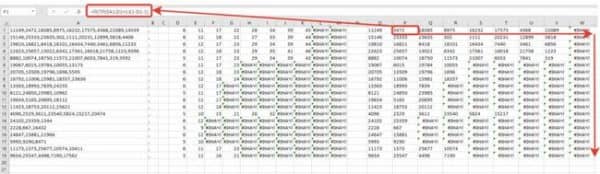
Шаг 7. В принципе задача наша уже решена, но для красоты все в той же ячейке P1 пропишем формула отлавливающую ошибку заменяя ее пустым значением.
Так же можно сгруппировать и свернуть вспомогательные столбцы, чтобы они не мешали. Получим итоговое решение задачи
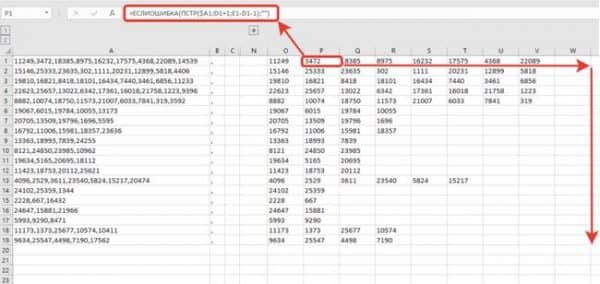
Примечание. Первую позицию разделителя и первое деление слова мы делали отлично от других и из-за этого могли протянуть формулу только со вторых значений.
Во время написания задачи я заметил, что можно было бы упростить задачу. Для этого в столбце С нужно было прописать 0 значения первого разделителя. После этого находим значение первого разделителя
а первого текста как
После этого можно сразу протягивать формулу на остальные значения. Именно этот вариант оставляю как пример для скачивания. В принципе файлом можно пользоваться как шаблоном.
Внимание! В комментариях заметили, что так как в конце текста у нас нет разделителя, то у нас не считается количество символов от последнего разделителя до конца строки, поэтому последний разделенный текст отсутствует.
Чтобы решить вопрос можно либо на первом шаге добавить вспомогательный столбец радом с исходным текстом, где сцепить этот текст с разделителем. Таким образом у нас получится что на конце текста будет разделитель, значит наши формулы посчитают его позицию и все будет работать.
Либо второе решение — это на шаге 3, когда мы составляем формулу вычисления позиций разделителей дополнить ее. Сделать проверку, если ошибка, то указываем заведомо большое число, например 1000.
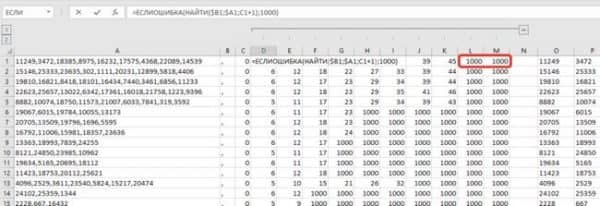
Таким образом последний текст будет рассчитываться начиная от последней запятой до чуть меньше 1000 знаков, то есть до конца строки, что нам и требуется.
Всем привет на связи Джон Винсент. Сегодня на моей основной работе я увидел как мой коллега вручную переделывает список сотрудников где указаны полные Имя и Отчество в список где указаны только инициалы. Но я то знаю способ как это сделать быстро и особо не напрягаясь. И решил поделиться этим знанием и с вами.
Существует два способа: встроенный (самый простой) и через формулу (немного посложней).
Встроенный.
Если в вашем распоряжении есть Microsoft Excel одной из последних версий, вам повезло. Так как там реализовать задуманное будет очень просто. К примеру мы имеем список с полными Именем и Отчеством, а нам надо чтобы вместо полного имени и фамилии были лишь инициалы. Для этого мы просто в соседнем столбике пишем нужный нам вариант, можно кстати инициалы как после фамилии так и до. И после того как мы написали нужный нам вариант нажимаем сочетание клавиш CTRL+E и до конца всего списка мы получаем нужные нам варианты.
Excel: выделение имени, отчества, инициалов из ФИО
- Фамилия
- Имя Отчество
- И.О. (инициалы)
- Фамилия И.О.
- Имя
- Отчество

Будем использовать формулы с текстовыми функциями.
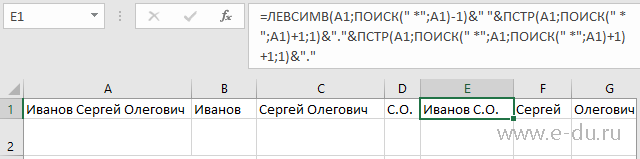
Будем предполагать, что исходные данные (ФИО) содержатся в ячейке A1 - "Иванов Сергей Олегович".
1. Выделение фамилии из ФИО
Формула извлечения фамилии (в ячейке B1):

2. Выделение Имени Отчества из ФИО
Формула извлечения Имени Отчества (в ячейке C1):

3. Выделение инициалов (И.О.) из ФИО
Формула извлечения И.О. (в ячейке D1):

4. Выделение фамилии и инициалов из ФИО
Формула извлечения в виде Фамилия И.О. (в ячейке E1):
5. Выделение имени из ФИО
Формула извлечения имени из ФИО (в ячейке F1):
Если имеется ячейка с именем отчеством (C1 в нашем примере), то формула схожа с формулой выделения фамилии:
6. Выделение отчества из ФИО
Формула извлечения отчества из ФИО (в ячейке G1):

Если Вам понравилась статья, пожалуйста, поставьте лайк, сделайте репост или оставьте комментарий. Если у Вас есть какие-либо замечания, также пишите комментарии.
17 комментариев :

Этот комментарий был удален автором.
Огромное Спасибо! Всё хорошо, кроме последней формулы: вытянуть отчество из "Александр Иванович" не получается, а выходит "др Иванович". С другими именами и отчествами (какие у меня есть) получилось.
Пожалуйста. А в ячейке "Александр Иванович" случайно нет лишнего пробела в начале фразы? Из-за этого может быть ошибка.
Исправление к последней формуле - =ПРАВСИМВ(C1;ДЛСТР(C1)-ПОИСК(" *";C1))
Подскажите, пожалуйста, для русских ФИО и т.п. все понятно, а вот если Киргиз, у неких есть фамилия типу Иванов Уулу, а имя Аданбек, отчество может быть, может не быть. Можно ли как-то под них тоже автоматизировать процесс?
А как система должна понять, что в строке "Иванов Уулу Аданбек" - Уулу - это не имя, а Аданбек - не отчество? В таком случае нужен дополнительный параметр, который будет указывать, что в данном случае надо менять правила обработки строки. Например, добавить еще колонку, которая будет задавать "признак отличия ФИО" (может гражданство или еще как-то), а затем в формуле добавить условие, допустим, если признак "не РФ", то рассчитывать по другой формуле. Иначе никак. Когда разрабатываю какую-либо систему, всегда задаю хранение отдельно имени, отдельно отчества, отдельно фамилии, чтобы не было таких проблем. Формулами из данной статьи приходится пользоваться, если кто-то прислал списки, где ФИО в одной строке, тогда и сложности.
Читайте также: