
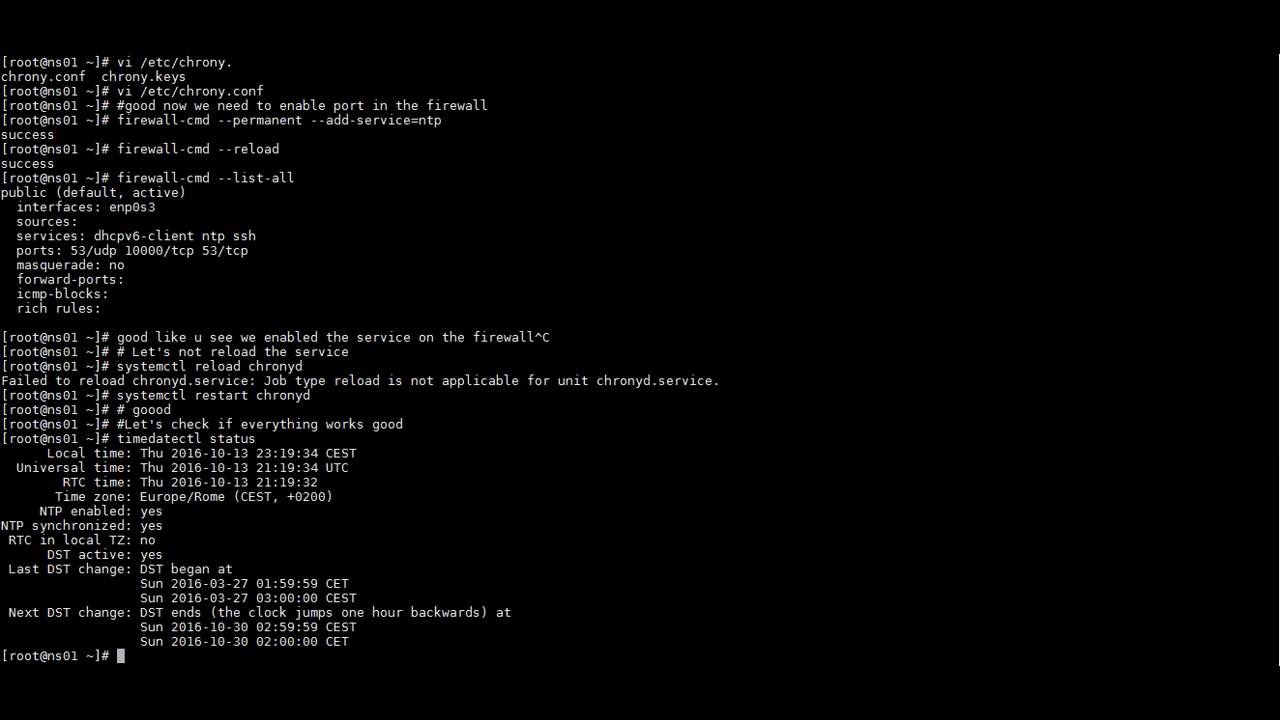
Ubuntu зависает reached target cloud init target
Понимание процедуры загрузки в Linux RHEL7/CentOS
Следующие шаги суммируют, как процедура загрузки происходит в Linux.
1. Выполнение POST: машина включена. Из системного ПО, которым может быть UEFI или классический BIOS, выполняется самотестирование при включении питания (POST) и аппаратное обеспечение, необходимое для запуска инициализации системы.
2. Выбор загрузочного устройства: В загрузочной прошивке UEFI или в основной загрузочной записи находится загрузочное устройство.
3. Загрузка загрузчика: с загрузочного устройства находится загрузчик. На Red Hat/CentOS это обычно GRUB 2.
4. Загрузка ядра: Загрузчик может представить пользователю меню загрузки или может быть настроен на автоматический запуск Linux по умолчанию. Для загрузки Linux ядро загружается вместе с initramfs . Initramfs содержит модули ядра для всего оборудования, которое требуется для загрузки, а также начальные сценарии, необходимые для перехода к следующему этапу загрузки. На RHEL 7/CentOS initramfs содержит полную операционную систему (которая может использоваться для устранения неполадок).
5. Запуск /sbin/init: Как только ядро загружено в память, загружается первый из всех процессов, но все еще из initramfs . Это процесс /sbin/init , который связан с systemd . Демон udev также загружается для дальнейшей инициализации оборудования. Все это все еще происходит из образа initramfs .
6. Обработка initrd.target: процесс systemd выполняет все юниты из initrd.target , который подготавливает минимальную операционную среду, в которой корневая файловая система на диске монтируется в каталог /sysroot . На данный момент загружено достаточно, чтобы перейти к установке системы, которая была записана на жесткий диск.
7. Переключение на корневую файловую систему: система переключается на корневую файловую систему, которая находится на диске, и в этот момент может также загрузить процесс systemd с диска.
8. Запуск цели по умолчанию (default target): Systemd ищет цель по умолчанию для выполнения и запускает все свои юниты. В этом процессе отображается экран входа в систему, и пользователь может проходить аутентификацию. Обратите внимание, что приглашение к входу в систему может быть запрошено до успешной загрузки всех файлов модуля systemd . Таким образом, просмотр приглашения на вход в систему не обязательно означает, что сервер еще полностью функционирует.
На каждом из перечисленных этапов могут возникнуть проблемы из-за неправильной настройки или других проблем. Таблица суммирует, где настроена определенная фаза и что вы можете сделать, чтобы устранить неполадки, если что-то пойдет не так.
Передача аргементов в GRUB 2 ядру во время загрузки
Если сервер не загружается нормально, приглашение загрузки GRUB предлагает удобный способ остановить процедуру загрузки и передать конкретные параметры ядру во время загрузки. В этой части вы узнаете, как получить доступ к приглашению к загрузке и как передать конкретные аргументы загрузки ядру во время загрузки.
Когда сервер загружается, вы кратко видите меню GRUB 2. Смотри быстро, потому что это будет длиться всего несколько секунд. В этом загрузочном меню вы можете ввести e, чтобы войти в режим, в котором вы можете редактировать команды, или c, чтобы ввести полную командную строку GRUB.

После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz , за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:

После ввода параметров загрузки, которые вы хотите использовать, нажмите Ctrl + X, чтобы запустить ядро с этими параметрами. Обратите внимание, что эти параметры используются только один раз и не являются постоянными. Чтобы сделать их постоянными, вы должны изменить содержимое файла конфигурации /etc/default/grub и использовать grub2-mkconfig -o /boot/grub2/grub.cfg , чтобы применить изменение.
Когда у вас возникли проблемы, у вас есть несколько вариантов (целей), которые вы можете ввести в приглашении загрузки GRUB:
■ rd.break Это останавливает процедуру загрузки, пока она еще находится в стадии initramfs .
Эта опция полезна, если у вас нет пароля root.
■ init=/bin/sh или init=/bin/bash Указывает, что оболочка должна быть запущена сразу после загрузки ядра и initrd . Это полезный вариант, но не лучший, потому что в некоторых случаях вы потеряете консольный доступ или пропустите другие функции.
■ systemd.unit=rescue.target Команда запускает еще несколько системных юнитов, чтобы привести вас в более полный рабочий режим. Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество юнит-файлов, вы можете ввести команду systemctl list-units .
Запуск целей(targets) устранения неполадок в Linux
1. (Пере)загружаем Linux. Когда отобразиться меню GRUB, нажимаем e ;
2. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=rescue.target и удаляем rhgb quit ;
3. Жмем Ctrl+X, чтобы начать загрузку с этими параметрами. Вводим пароль от root;
4. Вводим systemctl list-units и смотрим. Будут показаны все юнит-файлы, которые загружены в данный момент и соответственно загружена базовая системная среда;
5. Вводим systemctl show-environment . Видим переменные окружения в режиме rescue.target;
6. Перезагружаемся reboot ;
7. Когда отобразится меню GRUB, нажимаем e . Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=emergency.target и удаляем rhgb quit ;
8. Снова вводим пароль от root;
9. Система загрузилась в режиме emergency.target;
10. Вводим systemctl list-units и видим, что загрузился самый минимум из юнит-файлов.
Устранение неполадок с помощью загрузочного диска Linux
Еще один способ восстановления работоспособности Linux использовать образ операционки.
Если вам повезет меньше, вы увидите мигающий курсор в системе, которая вообще не загружается. Если это произойдет, вам нужен аварийный диск. Образ восстановления по умолчанию для Linux находится на установочном диске. При загрузке с установочного диска вы увидите пункт меню "Troubleshooting". Выберите этот пункт, чтобы получить доступ к параметрам, необходимым для ремонта машины.
- Install CentOS 7 in Basic Graphics Mode: эта опция переустанавливает систему. Не используйте её, если не хотите устранить неполадки в ситуации, когда обычная установка не работает и вам необходим базовый графический режим. Как правило, вам никогда не нужно использовать эту опцию для устранения неисправностей при установке.
- Rescue a CentOS System: это самая гибкая система спасения. Это должен быть первый вариант выбора при использовании аварийного диска.
- Run a Memory Test: если вы столкнулись с ошибками памяти, это позволяет пометить плохие микросхемы памяти, чтобы ваша машина могла нормально загружаться.
- Boot from local drive: здесь я думаю всё понятно.
Пример использования "Rescue a CentOS System"
1. Перезагружаем сервер с установочным диском Centos 7. Загружаемся и выбираем "Troubleshooting".
2. В меню траблшутинга выбираем "Rescue a CentOS System" и загружаемся.

3. Система восстановления теперь предлагает вам найти установленную систему Linux и смонтировать ее в /mnt/sysimage . Выберите номер 1, чтобы продолжить:
4. Если была найдена правильная установка CentOS, вам будет предложено, чтобы система была смонтирована в /mnt/sysimage . В этот момент вы можете дважды нажать Enter, чтобы получить доступ к оболочке восстановления.

5. Ваша система Linux на данный момент доступна через каталог /mnt/sysimage . Введите chroot /mnt/sysimage . На этом этапе у вас есть доступ к корневой файловой системе, и вы можете получить доступ ко всем инструментам, которые необходимы для восстановления доступа к вашей системе.
Переустановка GRUB с помощью аварийного диска
Одна из распространенных причин, по которой вам нужно запустить аварийный диск, заключается в том, что загрузчик GRUB 2 не работает. Если это произойдет, вам может понадобиться установить его снова. После того, как вы восстановили доступ к своему серверу с помощью аварийного диска, переустановить GRUB 2 несложно, и он состоит из двух этапов:
- Убедитесь, что вы поместили содержимое каталога /mnt/sysimage в текущую рабочую среду.
- Используйте команду grub2-install , а затем имя устройства, на котором вы хотите переустановить GRUB 2. Если это виртуальная машина KVM используйте команду grub2-install /dev/vda и на физическом сервере или виртуальная машина VMware, HyperV или Virtual Box, это grub2-install /dev/sda .
Повторное создание Initramfs с помощью аварийного диска
Иногда initramfs также может быть поврежден. Если это произойдет, вы не сможете загрузить свой сервер в нормальном рабочем режиме. Чтобы восстановить образ initramfs после загрузки в среду восстановления, вы можете использовать команду dracut . Если используется без аргументов, эта команда создает новый initramfs для загруженного в данный момент ядра.
Кроме того, вы можете использовать команду dracut с несколькими опциями для создания initramfs для конкретных сред ядра. Существует также файл конфигурации с именем /etc/dracut.conf , который можно использовать для включения определенных параметров при повторном создании initramfs .
- /usr/lib/dracut/dracut.conf.d/*.conf содержит системные файлы конфигурации по умолчанию.
- /etc/dracut.conf.d содержит пользовательские файлы конфигурации dracut.
- /etc/dracut.conf используется в качестве основного файла конфигурации.
Исправление общих проблем
В пределах статьи, подобной этой, невозможно рассмотреть все возможные проблемы, с которыми можно столкнуться при работе с Linux. Однако есть некоторые проблемы, которые встречаются чаще, чем другие. Ниже некоторые наиболее распространенные проблемы.
Переустановка GRUB 2
Код загрузчика не исчезает просто так, но иногда может случиться, что загрузочный код GRUB 2 будет поврежден. В этом случае вам лучше знать, как переустановить GRUB 2. Точный подход зависит от того, находится ли ваш сервер в загрузочном состоянии. Если это так, то довольно просто переустановить GRUB 2. Просто введите grub2-install и имя устройства, на которое вы хотите его установить. У команды есть много различных опций для точной настройки того, что именно будет установлено, но вам, вероятно, они не понадобятся, потому что по умолчанию команда устанавливает все необходимое, чтобы ваша система снова загрузилась. Становится немного сложнее, если ваш сервер не загружается.Если это произойдет, вам сначала нужно запустить систему восстановления и восстановить доступ к вашему серверу из системы восстановления. После монтирования файловых систем вашего сервера в /mnt/sysimage и использования chroot /mnt/sysimage , чтобы сделать смонтированный образ системы вашим корневым образом: Просто запустите grub2-install , чтобы установить GRUB 2 на желаемое установочное устройство. Но если вы находитесь на виртуальной машине KVM, запустите grub2-install /dev/vda , а если вы находитесь на физическом диске, запустите grub2-install /dev/sda .
Исправление Initramfs
В редких случаях может случиться так, что initramfs будет поврежден. Если вы тщательно проанализируете процедуру загрузки, вы узнаете, что у вас есть проблема с initramfs , потому что вы никогда не увидите, как корневая файловая система монтируется в корневой каталог, и при этом вы не увидите запуска каких-либо системных модулей. Если вы подозреваете, что у вас есть проблема с initramfs , ее легко создать заново. Чтобы воссоздать его, используя все настройки по умолчанию (что в большинстве случаев нормально), вы можете просто запустить команду dracut --force . (Без --force команда откажется перезаписать ваши существующие initramfs .)
При запуске команды dracut вы можете использовать файл конфигурации /etc/dracut.conf , чтобы указать, что именно записывается в initramfs . В этом файле конфигурации вы можете увидеть такие параметры, как lvmconf = «no» , которые можно использовать для включения или выключения определенных функций. Используйте эти параметры, чтобы убедиться, что у вас есть все необходимые функции в initramfs .
Восстановление после проблем с файловой системой
Мой Ubuntu 16.04 зависает при выключении / перезапуске, требуя, чтобы я нажал и удерживал кнопку питания, чтобы выключить машину . Я не знаю, как сообщить об этом как об ошибке и какие команды запустить, чтобы показать необходимый журнал оборудования / системного журнала Информация? Любая помощь будет принята с благодарностью!
Те же проблемы здесь. > Blockquote Отключение устаревшего режима USB 3.0 в BIOS работало для меня. > Blockquote Как отключить устаревший режим USB 3.0? Видя эту проблему в действии, мне было бы стыдно больше рекомендовать Ubuntu пользователю Windows . Это раздражительно! Почему эта простая задача перестала работать . Все исправления, которые я нашел, не работают, включая добавление в строку grub, отключение подкачки и даже изменение графических драйверов и возврат к более старым ядрам. НИЧЕГО НЕ РАБОТАЕТ. Это такая любительская ошибка. ОС должна быть в состоянии выключить!У меня тоже была эта проблема. Кажется, это ошибка в нескольких дистрибутивах.
Моим простым исправлением было редактирование /etc/default/grub строки:
Работает каждый раз сейчас. Я использую ноутбук Lenovo G50. Я уверен, что я изменил эту строку в Grub с предыдущими (другими) дистрибутивами linux на этом ноутбуке.
Это просто избавляет вас от нажатия <kbd> ESC </ kbd> для просмотра информации о журнале выключения. Никакого другого эффекта. (Возможно, обновление, иначе регенерирующее grub-файлы исправило что-то еще). Я попробовал update-grub первый, который не сработал. Затем я изменил его на GRUB_CMDLINE_LINUX_DEFAULT = "acpi = force", и это решило мою проблему. @Ernesto: Это сработало для меня .. Чтобы подтвердить, я сделал 2-3 раза перезагрузки / выключения, и все время он загружался без каких-либо проблем. Спасибо! Это сработало. Может быть, это связано с более новой версией ядра после запуска dist-upgrade ?После того, как вы закончили свою работу и завершили закрытие всех ваших приложений, чтобы завершить работу или перезагрузить вашу ОС, пожалуйста, выполните следующие шаги, чтобы уменьшить разочарования.
Обновить
У меня были эти зависания в течение довольно долгого времени, но в конечном итоге я узнал, что мой жесткий диск начинает выходить из строя секторов и т. Д. Итак, пришло время для нового жесткого диска и его переустановки. Я переустановил ОС на одном загрузочном жестком диске с Swap в качестве 1-го, Root как 2-го и Home в качестве 3-го логических разделов в соответствии с рекомендациями Ubuntu. Технически, sda1 - это Grub, sda2 - это Extended, sda5, sda6, sda7 - это swap, root и home соответственно; sda3 и sda4 нет. С тех пор этой проблемы не было во вновь установленной ОС на жестком диске, примерно 9 месяцев. На данный момент я работаю 16.04.02 LTS без каких-либо зависаний при перезапуске или выключении. Предыдущая ОС была двойной установкой Win7 / Ubuntu, а раздел Swap находился в конце жесткого диска.
Я не утверждаю, что эта проблема связана с двойной загрузкой, неисправным жестким диском или порядком, в котором я разместил разделы, но в моем случае существовал один, два или все эти факторы. Теперь я не страдаю обострением зависания «Достигнута цель».
freebsd команды, настройка, установка сервера и не только
Sep 19 10:07:37 ugrt cloud-init[731]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'init-local' at Sat, 19 Sep 2020 10:05:29 +0000. Up 49.94 seconds.
Sep 19 10:07:37 ugrt cloud-init[753]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'init' at Sat, 19 Sep 2020 10:07:31 +0000. Up 171.83 seconds.
Sep 19 10:09:28 ugrt cloud-init[1858]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'modules:config' at Sat, 19 Sep 2020 10:09:27 +0000. Up 288.17 seconds.
Sep 19 10:09:31 ugrt cloud-init[1885]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'modules:final' at Sat, 19 Sep 2020 10:09:30 +0000. Up 291.32 seconds.
Sep 19 10:09:31 ugrt cloud-init[1885]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 finished at Sat, 19 Sep 2020 10:09:31 +0000. Datasource DataSourceNone. Up 291.81 seconds
Sep 19 10:09:31 ugrt systemd[1]: Reached target Cloud-init target.
Sep 19 11:00:41 ugrt systemd[1]: Stopped target Cloud-init target.
Sep 19 11:01:49 ugrt cloud-init[609]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'init-local' at Sat, 19 Sep 2020 11:01:42 +0000. Up 21.63 seconds.
Sep 19 11:01:49 ugrt cloud-init[620]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'init' at Sat, 19 Sep 2020 11:01:45 +0000. Up 25.22 seconds.
Sep 19 11:02:00 ugrt cloud-init[878]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'modules:config' at Sat, 19 Sep 2020 11:01:59 +0000. Up 39.00 seconds.
Sep 19 11:02:01 ugrt cloud-init[885]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 running 'modules:final' at Sat, 19 Sep 2020 11:02:01 +0000. Up 40.54 seconds.
Sep 19 11:02:01 ugrt cloud-init[885]: Cloud-init v. 20.2-45-g5f7825e2-0ubuntu1
20.04.1 finished at Sat, 19 Sep 2020 11:02:01 +0000. Datasource DataSourceNone. Up 40.83 seconds
Sep 19 11:02:01 ugrt systemd[1]: Reached target Cloud-init target.
Система Linux загружается так быстро, что большая часть вывода слишком быстро прокручивается, чтобы прочитать текст (показывая запущенные службы), отправленные на консоль.
Поэтому наблюдение за проблемами загрузки / ошибками становится для нас проблемой.
В этой статье мы кратко объясним различные этапы процесса загрузки системы Linux, а затем узнаем, как установить и решить проблемы с загрузкой.
Краткое описание процесса загрузки Linux
В случае ошибки (отсутствие / неисправное оборудование), это сообщается на экране.
Во время POST BIOS также ищет загрузочное устройство, на котором установлен диск (обычно первый жесткий диск, однако мы можем настроить его как DVD, USB, сетевую карту и т. д).
Затем система подключится к диску и выполнит поиск основной загрузочной записи (размером 512 байт), в которой хранится загрузчик (размер 446 байт), а остальная часть пространства хранит информацию о дисковых разделах (четыре максимум) и MBR.
После загрузки ядра он запускает init (или systemd на более новых дистрибутивах Linux), первый процесс с PID 1, который, в свою очередь, запускает все остальные процессы в системе.
Это также последний процесс, который должен быть выполнен при завершении работы системы.
Как уже упоминалось ранее, процессы загрузки Linux происходят быстро, и мы не можем даже четко прочитать большую часть вывода, отправленного на консоль.
Поэтому, принимая во внимание проблемы с загрузкой / ошибки, администратор системы обращается к некоторым важным файлам определенными командами.
К ним относятся:
Это, вероятно, первый файл, который вам надо изучить, чтобы просмотреть все, что было во время загрузки системы.
Вместо того, чтобы так пристально следить за выводом на экране во время загрузки, мы можем просмотреть этот файл после завершения процесса загрузки, чтобы помочь нам в определении и устранении проблем / ошибок загрузки.
Мы используем команду cat для этой задачи следующим образом (ниже приведен пример этого файла):
Из вышеприведенного вывода видно, что проблемы с загрузкой существуют и указаны отдельно ниже:
Проблема: проблема с разделом подкачки; система либо не прочитала файл подкачки / устройство / раздел, либо его нет.
Давайте проверим, использует ли система пространство подкачки с командой free.
Кроме того, мы можем запустить команду swapon, чтобы просмотреть сводку использования пространства подкачки системы (мы не получим никакого вывода).
Мы можем решить эту проблему, создав пространство подкачки в Linux.
Примечание. Содержимое этого файла очищается при завершении работы системы: новые данные хранятся в нем при новой загрузке.
Чтобы просмотреть его, введите:
Поскольку этот файл может быть относительно длинным, мы можем просмотреть его постранично, используя команду more (которая даже показывает проценты):
Поэтому старые файлы сжимаются и сохраняются в системе для последующей проверки, как показано ниже.
Команда dmesg может показывать операции после завершения процесса загрузки, такие как параметры командной строки, переданные ядру; обнаруженные аппаратные компоненты, события при добавлении нового USB-устройства или ошибки, такие как сбои сетевого адаптера (Network Interface Card), что драйверы не сообщают о активности канала в сети и о многом другом.
При попытке создания новой виртуальной машины Azure (VM) распространенными ошибками являются сбои или сбои распределения.
- Сбой подготовки происходит, когда изображение ОС не загружается либо из-за неправильных подготовительных действий, либо из-за выбора неправильных параметров во время захвата изображения с портала.
- Сбой распределения приводит к, когда кластер или регион либо не имеют ресурсов, либо не могут поддерживать запрашиваемую величину VM.
Подготовка устранения неполадок
Затем вы увидите состояние VM, отмеченное как failed .
Почему происходят сбои в подготовках?
Обычно сбои в подготовках могут происходить по нескольким причинам, таким как:
Отсутствующий агент подготовка /неправильно настроенный
- Необходимо убедиться, что агент присутствует и работает правильно, следует использовать cloud-init или если ваше изображение не будет поддерживать это, вы можете просмотреть эти действия.
Неправильная конфигурация изображения
- У нас есть рекомендации по настройке изображений с помощью облачного и инауча и других требований к изображениям Azure,пожалуйста, ознакомьтесь с этим.
Устранение сбоев в обеспечении безопасности
Чтобы определить причину сбой в обеспечении, необходимо начать с серийного журнала, это доступно вам, развернув VM с помощью диагностики Azure Boot.
Вам потребуется развернуть новый VM с включенной диагностикой загрузки для VM с неумелой картинкой для доступа к событиям подготовка в серийном журнале.
Чтобы просмотреть серийный журнал, можно перейти на портал или запустить команду ниже, чтобы скачать журнал "serialConsoleLogBlobUri":
Понимание последовательного журнала для событий системы и событий подготовка
Когда VM создается впервые, облачный инициат запустится и попытается установить ISO, установить сетевое подключение, задайте свойства, переданные во время создания VM, установите эфемерный диск (на поддерживаемых размерах VM) и отдайте сигнал платформе Azure о том, что начальная конфигурка ОС завершена.
18.04.1-Ubuntu SMP Tue Oct 6 10:03:22 UTC 2020 (Ubuntu 5.4.0-1031.32
18.04.1 running 'init-local' at Wed, 28 Oct 2020 17:46:30 +0000. Up 21.23 seconds.
[ 28.357120] cloud-init[837]: Cloud-init v. 20.3-2-g371b392c-0ubuntu1
18.04.1 running 'init' at Wed, 28 Oct 2020 17:46:34 +0000. Up 24.52 seconds.
[ 50.421009] cloud-init[1445]: Cloud-init v. 20.3-2-g371b392c-0ubuntu1
18.04.1 running 'modules:config' at Wed, 28 Oct 2020 17:46:57 +0000. Up 48.21 seconds.
[ 51.338792] cloud-init[1541]: Cloud-init v. 20.3-2-g371b392c-0ubuntu1
18.04.1 running 'modules:final' at Wed, 28 Oct 2020 17:47:00 +0000. Up 51.01 seconds.
[ 51.366837] cloud-init[1541]: Cloud-init v. 20.3-2-g371b392c-0ubuntu1
Распространенные ошибки
Драйвер UDF, задекланный в черный список
Ошибка: В серийном журнале:
Причина. Драйвер UDF не загружается в ядро, это необходимо для обеспечения VM, см. требования к изображению.
При первом выпуске VM в Azure хост Azure представляет "диск iso cdrom" для VM. Этот диск подготовка обычно представлен vM через /dev/sr0. В диске подготовка имеется манифест подготовка, содержащий сведения о продюсинге VM. Ожидается, что агент по подготовкам в VM будет смонтировать диск подготовка, прочитать манифест продюсинга и соответствующим образом продюсировать VM.
Так как подготовка диска — это драйвер Linux UDF, необходимый ядром для успешной установки cdrom iso disk этого диска. Об этом сообщается в документации Майкрософт по изображениям Linux. Для этого VM журналы указывают на то, что не удалось установить диск подготовка, из-за чего подготовка VM не удалась. Наиболее вероятной причиной является отсутствие или блокировка драйверов UDF.
Решение. Убедитесь, что драйвер UDF настроен для загрузки в ядро.
Распространенный способ блокировки драйверов UDF — это конфигураторы внутри /etc/modprobe.d/ . Чтобы убедиться, что драйверы UDF Linux присутствуют и не блокируются, обратитесь к владельцу клиента и изображения. Проконсультируйтесь в этой статье о блокировке и разблокировке драйверов ядра.
символы единой кодировки в проблеме тегов VM
Ошибка. В cloud-init.log:
Причина. Это происходит из-за <>
Решение. Для решения <>
Пароль с символами единого кода
Ошибка. В cloud-init.log:
Причина. Это происходит из-за <>
Решение. Для решения <>
разрешение dhclient
Ошибка. В cloud-init.log:
Причина: Более старые версии облачного init (до версии 20.3) выполняют DHCP путем копирования и выполнения dhclient внутри /var/tmp . Если VM устанавливается /var/tmp как noexec (без выполнения), то DHCP не выполняется из-за того, что у него нет разрешений dhclient на выполнение в пределах /var/tmp .
Версии Cloud-init >= 20.3 содержат исправление, которое отпадает и выполняет "as-is" (не копируя и не исполняя его при проблемах с dhclient /var/tmp разрешениями).
Решение. Для VMs, работающих с облачным и init старше версии 20.3, настройте VM так, чтобы он не /var/tmp устанавливался как noexec . Кроме того, обновите пакет облачного init VM до версии >= 20.3.
Получение дополнительных журналов
Если вам нужно больше журналов из VM, чтобы разобраться в проблемах, вы можете использовать SSH в VM с помощью последовательной консоли с помощью пользователя, который выпекается на изображении. Если у вас нет пользователя, вы можете либо воссоздать изображение с пользователем, либо использовать средство восстановления AZ VM, которое будет смонтировать диск ОС VM, который не был предусмотрен, в другой VM.
Понимание облачного init.log
Если у вас есть доступ к журналам облачной иницы, просмотрите документацию по устранению неполадок с облачным иным доступом.
Получение поддержки
Если вы ссылались на руководство и все еще не можете устранить проблему, можно открыть дело поддержки. При этом выберите правильную тему продукта и поддержки, при этом будет задействована правильная группа поддержки.
Выбор продукта для дела:
Сбор журналов действий
Чтобы начать устранение неполадок, соберете журналы действий, чтобы определить ошибку, связанную с проблемой. Следующие ссылки содержат подробные сведения о последующем процессе.
Проблема: настраиваемый образ; ошибки в подготовках
Ошибки подготовки возникают, если вы загружаете или захватываете обобщенное изображение VM в качестве специализированного изображения VM или наоборот. Первый приведет к ошибке времени предварительного провокирования, а второй приведет к сбою в подготовках. Чтобы развернуть настраиваемый образ без ошибок, необходимо убедиться, что тип изображения не меняется во время процесса захвата.
В следующей таблице перечислены возможные сочетания обобщенных и специализированных изображений, тип ошибок, с которыми вы столкнетесь, и что необходимо сделать для устранения ошибок.
В следующей таблице перечислены возможные комбинации отправки и захвата обобщенных и специализированных изображений ОС Linux. Комбинации, которые будут обрабатываться без ошибок, указываются Y, а те, которые будут бросать ошибки, указываются N. Причины и решения различных ошибок, с которых вы будете работать, приведены ниже таблицы.
| OS | Upload спецификации. | Upload. | Спецификация захвата. | Захват gen. |
|---|---|---|---|---|
| Linux gen. | N 1 | Да | N 3 | Да |
| Спецификация Linux. | Да | N 2 | Да | N 4 |
Y: Если осмия обобщена и загружена и/или захвачена с обобщенным параметром, то ошибок не будет. Аналогичным образом, если ОС является специализированной Linux, и она загружается и/или захватывается с помощью специализированного параметра, то ошибок не будет.
Upload Ошибки
N 1 : Если осмия обобщена и загружена как специализированная, вы получите ошибку времени подготовки, так как VM застрял на этапе подготовки.
N 2: Если ОС является специализированной Linux и загружена в обобщенном качестве, вы получите ошибку сбоя подготовки, так как новый VM работает с оригинальным именем компьютера, именем пользователя и паролем.
Разрешение — Upload ошибка
Чтобы устранить обе эти ошибки, загрузите исходный VHD, доступный на локальной основе, с тем же параметром, что и для ОС (обобщенный или специализированный). Чтобы загрузить, как обобщено, не забудьте запустить -deprovision в первую очередь.
Ошибки захвата
N 3: Если осмия обобщена и запечатлена как специализированная, вы получите ошибку времени подготовки, так как исходный VM не может быть использовать, так как он помечен как обобщенный.
N 4: Если ОС является специализированной Linux, и она захвачена как обобщенная, вы получите ошибку отказа подготовки, так как новый VM работает с оригинальным именем компьютера, именем пользователя и паролем. Кроме того, исходный VM не может быть использовать, так как он помечен как специализированный.
Разрешение — ошибка захвата
Чтобы устранить обе эти ошибки, удалите текущее изображение с портала и отвоейте его из текущих VHD с тем же параметром, что и для ОС (обобщенный или специализированный).
Проблема: пользовательский/ галерея/ изображение на рынке; Сбой выделения
Эта ошибка возникает в ситуациях, когда новый VM-запрос закреплен в кластере, который либо не может поддерживать запрашиваемую величину VM, либо не имеет свободного пространства для размещения запроса.
Причина 1
Кластер не может поддерживать запрашиваемую величину VM.
Разрешение 1
Повторное просмотр запроса с использованием меньшего размера VM.
Если размер запрашиваемого VM не может быть изменен:
- Остановите все VMs в наборе доступности. Щелкните Группы ресурсов группы ресурсов Ресурсы, набор доступности > > > > виртуальных машин для > виртуальной машины > Stop.
- После остановки всех VMs создайте новый VM в нужном размере.
- Сначала запустите новый VM, а затем выберите каждый из остановленных VMs и нажмите кнопку Начните.
Причина 2
У кластера нет свободных ресурсов.
Разрешение 2
- Повторное просмотр запроса в более позднее время.
- Если новый VM может быть частью другого набора доступности
- Создайте новый VM в другом наборе доступности (в том же регионе).
- Добавьте новый VM в ту же виртуальную сеть.
Главные проблемы
Следующие главные проблемы могут помочь решить проблему. Чтобы начать устранение неполадок, просмотрите следующие действия:
Кластер не может поддерживать запрашиваемую величину VM
- Повторное просмотр запроса с использованием меньшего размера VM.
- Если размер запрашиваемого VM не может быть изменен:
- Остановите все VMs в наборе доступности. Щелкните группы ресурсов > группы ресурсов > Ресурсы > набор доступности > виртуальных > виртуальной машины > Stop.
- После остановки всех VMs создайте VM в нужном размере.
- Сначала запустите новый VM, а затем выберите каждый из остановленных VMs и нажмите кнопку Начните.
Кластер не имеет бесплатных ресурсов
- Повторить запрос позже.
- Если новый VM может быть частью другого набора доступности
- Создайте VM в другом наборе доступности (в том же регионе).
- Добавьте новый VM в ту же виртуальную сеть.
Вопросы и ответы
Как активировать ежемесячный кредит для visual studio Enterprise (BizSpark)
Чтобы активировать ежемесячный кредит, см. в этой статье.
Почему нельзя установить драйвер GPU для VM NV Ubuntu?
В настоящее время поддержка GPU Linux доступна только для VMs Azure NC под управлением Ubuntu Server 16.04 LTS. Дополнительные сведения см. в выпуске Настройка драйверов GPU для VMs N-series под управлением Linux.
Мои драйверы отсутствуют для моего VM Linux N-Series
Инструкции по установке драйверов для VMs на основе Linux размещены здесь.
Я не могу найти экземпляр GPU в своем VM N-Series
Чтобы воспользоваться возможностями GPU VMs Azure N-series, необходимо установить графические драйверы на каждый VM после развертывания. Сведения о настройке драйвера доступны здесь.
Доступны ли VMs N-Series в моем регионе?
Вы можете проверить доступность из продуктов, доступных в таблице регионов,и цены здесь.
Я не могу видеть семейство VM Size, которое нужно при повторном размере VM
Когда VM запущен, он развертывается на физическом сервере. Физические серверы в регионах Azure сгруппируются в кластеры общего физического оборудования. Размер VM, который требует, чтобы VM перемещался в различные аппаратные кластеры, отличается в зависимости от того, какая модель развертывания использовалась для развертывания VM.
VMs, развернутые в классической модели развертывания, развертывание облачных служб должно быть удалено и передиплойно, чтобы изменить VMs на размер в другом семейство размеров.
VMs, развернутые в модели развертывания Resource Manager, необходимо остановить все VMs в наборе доступности, прежде чем изменить размер любого VM в наборе доступности.
Указанный размер VM не поддерживается при развертывании в наборе доступности
Выберите размер, поддерживаемый в кластере набора доступности. Рекомендуется при создании набора доступности выбрать самый большой размер VM, который, по вашему мнению, необходим, и это будет ваше первое развертывание в наборе доступности.
Какие дистрибутивы и версии Linux поддерживаются в Azure?
Можно ли добавить существующий классический VM в набор доступности?
Да. Можно добавить существующий классический VM в новый или существующий набор доступности. Дополнительные сведения см. в статью Добавление существующей виртуальной машины в набор доступности.
Классические VMs будут отменены 1 марта 2023 г.
Если вы используете ресурсы IaaS из ASM, выполните миграцию до 1 марта 2023 г. Мы рекомендуем вам сделать переключатель быстрее, чтобы воспользоваться многими улучшениями функций в Azure Resource Manager.
Дополнительные сведения см. в дополнительных сведениях о переносе ресурсов IaaS в Azure Resource Manager до 1 марта 2023 г.
Читайте также: