
Ubuntu low latency что это
Не так давно появилась информация, что планировщик BFQ разработчики подготавливают к внесению в основную ветку ядра. В связи с этим я решил сделать обзор планировщиков и провести бенчмарки, чтобы понять, в каких ситуациях выгоднее использовать тот или иной из них.
Введение
Для начала вспомним, что такое планировщик ввода/вывода. Он отвечает за распределение дисковых операций по процессам. В ранних ядрах Linux (как минимум в ядре 2.4) существовал только один планировщик — Linus Elevator. Он был слишком примитивным, и поэтому в ядре 2.6 появились еще три планировщика, часть из которых ныне уже ушла в небытие. Таким образом, сейчас в ядре существует три планировщика, а в ближайшее время, возможно, прибавится еще и четвертый:
- NOOP — наиболее простой планировщик. Он банально помещает все запросы в очередь FIFO и исполняет их вне зависимости от того, пытаются ли приложения читать или писать. Планировщик этот, тем не менее, пытается объединять однотипные запросы для сокращения операций ввода/вывода.
- CFQ был разработан в 2003 году. Заключается его алгоритм в следующем. Каждому процессу назначается своя очередь запросов ввода/вывода. Каждой очереди затем присваивается квант времени. Планировщик же циклически обходит все процессы и обслуживает каждый из них, пока не закончится очередь либо не истечет заданный квант времени. Если очередь закончилась раньше, чем истек выделенный для нее квант времени, планировщик подождет (по умолчанию 10 мс) и, в случае напрасного ожидания, перейдет к следующей очереди. Отмечу, что в рамках каждой очереди чтение имеет приоритет над записью.
- Deadline в настоящее время является стандартным планировщиком, был разработан в 2002 году. В основе его работы, как это ясно из названия, лежит предельный срок выполнения — то есть планировщик пытается выполнить запрос в указанное время. В дополнение к обычной отсортированной очереди, которая появилась еще в Linus Elevator, в нем есть еще две очереди — на чтение и на запись. Чтение опять же более приоритетно, чем запись. Кроме того, запросы объединяются в пакеты. Пакетом называется последовательность запросов на чтение либо на запись, которая идет в сторону б?льших секторов («алгоритм лифта»). После его обработки планировщик смотрит, есть ли запросы на запись, которые не обслуживались длительное время, и в зависимости от этого решает, создавать ли пакет на чтение либо же на запись.
- BFQ (Budget Fair Queueing) — относительно новый планировщик. Базируется на CFQ. Если не вдаваться в технические подробности, каждой очереди (которая, как и в CFQ, назначается попроцессно) выделяется свой «бюджет», и, если процесс интенсивно работает с диском, данный «бюджет» увеличивается.
Но, как говорится, не все грибочки одинаково полезны — планировщик для домашнего компьютера (который мы и попытаемся выбрать в статье) отличается от планировщика для сервера.
В FreeBSD имеется фреймворк (GEOM scheduler framework), позволяющий создавать планировщики ввода/вывода. На текущий момент, однако, на нем базируется только планировщик rr.
Подготовка
Первым делом скачаем ядро и наложим патч BFQ (на момент написания статьи существовал для ядер по версию 3.13 включительно):
Затем включим этот планировщик в Enable the block layer -> IO Schedulers (планировщик по умолчанию можно оставить стандартный — все равно их можно переключать как во время работы, так и используя опции ядра) и скомпилируем ядро:
Перед этим нужно убедиться, что в файле /etc/kernel-pkg.conf стоит многопоточная сборка (параметр CONCURRENCY_LEVEL в идеале должен быть равен количеству ядер процессора плюс один).

Включение планировщика BFQ в menuconfig
Следом же устанавливаем получившиеся пакеты:
Помимо ядра, нужно установить некоторые пакеты для собственно бенчмаркинга:
Наконец можно приступать к тестированию.

Установка Bonnie++
Тюнинг планировщиков
Как правило, планировщики не требуют тонкой подстройки. Однако если тебе захочется поэкспериментировать — такая возможность у нас есть. Рассмотрим некоторые параметры подстройки BFQ, находящиеся (в моем случае) в каталоге /sys/block/sda/queue/iosched:
- slice_idle — время ожидания поступления запросов (в миллисекундах). По умолчанию 8;
- quantum — число запросов ввода/вывода, передаваемых дисковому контроллеру за один раз (тем самым ограничивая длину очереди). Нужно соблюдать осторожность при его увеличении, поскольку при высокой нагрузке система может начать тормозить. По умолчанию 4;
- low_latency — для интерактивных процессов и процессов мягкого реального времени при значении по умолчанию пытается дать меньшую задержку, чем для других процессов. Процессы эти определяются эвристически;
- max_budget — максимальный бюджет для очереди, измеряющийся в секторах. Разумеется, этот бюджет применяется для очереди с учетом всех временных лимитов. Значение по умолчанию равно нулю и включает автоматическую подстройку данного параметра.
Тестирование
Прежде чем приступить к проведению бенчмарков, нужно рассказать о тестовом стенде. Железо: материнская плата ASUS Sabertooth 990FX R2.0, 16 Гб RAM, Seagate ST3000DM001-1CH166. ПО: Xubuntu 13.10 x64 с ядром 3.13.7. Также в моем случае имело смысл создать отдельный раздел как минимум вдвое большего объема, чем вся доступная оперативная память, что я и сделал, создав таковой в размере 35 Гб с файловой системой ext4. Сначала удостоверимся, что текущий планировщик для диска — Deadline, для чего наберем следующую команду:
Текущий планировщик выделяется квадратными скобками.
Первый бенчмарк, который я проведу, будет тест чтения с помощью утилиты hdparm — хотя предназначена она для тонкой подстройки параметров HDD, в ней есть и бенчмарк.
Для более точного результата лучше запускать эту команду три — пять раз.
Следующим бенчмарком будет тест с помощью команды dd. Этот тест тоже достаточно полезен для оценки производительности ввода/вывода, хоть и кажется примитивным.
Затем нужно будет очистить кеш, записав цифру 3 в файл /proc/sys/vm/drop_caches. Запись этой цифры в данный файл очищает как страничный кеш, так и кеш инод с dentry. Лишь после очистки можно будет запустить вторую часть теста:
Как и в случае с hdparm, обе части теста лучше запустить несколько раз.
Переходим к очередному тесту — им у нас будет распаковка архива с ядром. Скачиваем его и запускаем распаковку (опять же три — пять раз):
Следующий тест будет сделан с помощью утилиты Bonnie++, о которой стоит рассказать подробнее. Это крайне гибкий набор бенчмарков для тестирования производительности ввода/вывода. Операции с файлами, к сожалению, не сводятся только к последовательному чтению/записи одного файла или к распаковке архива, поэтому приведенные тесты не дают однозначного результата для всех ситуаций. Bonnie++ же, хоть и является синтетическим тестом, более реалистично симулирует обращения к подсистеме ввода/вывода. Так, в число тестов входит симуляция работы СУБД — в данном случае создается файл (либо файлы, если указан размер больший, чем 1 Гб) и производится как последовательное, так и рандомное чтение/запись, при этом чтение в несколько потоков. Помимо этого теста есть еще тест на создание/изменение/удаление тысяч маленьких файлов. Опции у данного приложения следующие:
- -d — каталог для работы программы;
- -s — размер файла в мегабайтах для первого теста (симуляция работы СУБД). Как я уже сказал, если размер будет указан больший, чем 1 Гб, файлов будет больше одного;
- -n — количество файлов для второго теста (симуляция работы Squid или какого-нибудь сервера электронной почты, использующего для хранения писем файлы). Формат аргумента таков: num:max_size:min_size:num_dirs, где num — количество файлов, кратное 1024, max_size и min_size — соответственно, максимальный и минимальный размер в байтах для создаваемых файлов (по умолчанию оба этих размера равны нулю, если же их установить, размер файлов будет задаваться рандомно), а num_dirs — количество каталогов, в которых файлы будут размещаться;
- -x — количество проходов тестов;
- -q — «тихий» режим. Кроме результатов теста и ошибок, ничего не выводится;
- -u — пользователь, под которым запускать тесты. Поскольку они сильно нагружают, пользователь root не рекомендуется — во избежание всяческих ошибок.
Итоговые команды будут следующими:
То есть запускаем пять проходов тестов в текущей директории с количеством файлов 115*1024, максимальным размером 25 381 байт, количеством каталогов 27 в «тихом» режиме. Затем нужно преобразовать этот самый CSV в удобочитаемый вид, для чего в составе пакета есть утилиты — можно преобразовывать как в txt, так и в HTML:
Напомню, что данные тесты нужно проводить на всех планировщиках, а не только на текущем. Для их переключения есть два способа. Первый способ — использовать параметр загрузки ядра elevator. При этом нужно будет редактировать файл /etc/default/grub и обновлять загрузочный конфиг GRUB. Второй способ не требует перезагрузки и состоит в указании планировщика через sysfs. Например, для указания планировщика CFQ на устройстве /dev/sda достаточно следующей команды:
Лично мне в конечном итоге оказалось проще написать скрипт, который запускает по пять проходов каждого теста (за исключением Bonnie++ — в нем указывается параметр -x) для каждого планировщика. Посмотрим же, что у нас получилось.

Скрипт для бенчмарка
Немного о процессе добавления BFQ в основную ветку ядра
Я начал работу над BFQ вместе с Фабио Чеккони (Fabio Checconi) в 2008 году. Фабио написал первую версию кода. Затем мы протестировали его, исправили ошибки и немного улучшили функционал. Мы думали, что этого будет достаточно для добавления в ядро:
Однако BFQ не приняли в основную ветку ядра, несмотря на позитивный отклик общественности. Причиной тому послужили замечания Дженса Аксбо (Jens Axboe). С одной стороны, он был обеспокоен сложностью движка планировщика, сетовал на то, что эта сложность обернется проблемами с поддержкой кода, если его добавят в ядро. С другой — он был убежден, что в Linux должен быть только один главный планировщик ввода/вывода. Им был (и есть) CFQ.
Хотя BFQ не вошел в ядро, некоторые продвинутые пользователи стали скачивать его с нашего сайта. BFQ также был включен в некоторые модифицированные ядра, например Zen Kernel.
Тем временем я наткнулся на одну занимательную ветку LKML по теме ввода/вывода. В ней обсуждалось время старта некоторых популярных приложений, таких как Firefox и терминал. Я был поражен, насколько оно может быть мало. По сути, такое время достигалось только при последовательном чтении соответствующего бинарного файла. Я вдохновился этой идеей и придумал новую фичу для планировщика: необходимо определять и давать привилегии интерактивным приложениям. После добавления этого и некоторых других незначительных улучшений я представил BFQ-v1 в июле 2010-го.
С этого момента BFQ начал набирать обороты: за прошедшие годы некоторые модифицированные Linux-ядра, Android-ядра, дистрибутивы Linux приняли BFQ в качестве планировщика по умолчанию или дополнительного планировщика (pf-kernel, многие ядра для Android, CyanogenMod, Sabayon, Gentoo Linux, Arch Linux, OpenMandriva, Rosa, ныне Manjaro). Кроме того, по моим данным, в течение последних нескольких лет каждый день планировщик скачивают несколько десятков пользователей разных дистрибутивов.
Между тем я продолжал добавлять новые функции и усовершенствования, например эвристические методы распознавания интерактивных приложений. Я добавил поддержку новых характеристик жестких дисков, например NCQ, а также оптимизировал работу с SSD. К счастью, в этой работе мне помогали такие хорошие люди, как Франческо Аллертсен (Francesco Allertsen), Мауро Андреолини (Mauro Andreolini) и особенно Арианна Аванцини (Arianna Avanzini). За несколько лет она внесла большой вклад в проект BFQ, разработала новые решения и подготовила патчи для множеств версий ядра.
Все расширения для правильной обработки новых устройств, которые Арианна и я добавили в BFQ, были до этого добавлены и в CFQ. Вместе с этим в CFQ появлялись некоторые другие полезные функции. Мы не только портируем все эти функции в BFQ, но и по возможности дорабатываем их для улучшения пропускной способности, времени отклика и быстроты исполнения. Так, нами был разработан унифицированный механизм обработки ввода/вывода QEMU для достижения высоких показателей пропускной способности.
Поддерживать такую высокую скорость разработки совсем не легко. Без поддержки Арианны проект, скорее всего, пришлось бы закрыть. Однако с выходом версии v7r3 мы в конце концов сделали это: теперь BFQ поддерживает весь спектр популярных устройств для хранения информации. Кроме этого, весь функционал, который я планировал реализовать, теперь работает стабильно. Наконец-то код выглядит зрелым и достаточно стройным.
Вот почему я думаю, что сейчас BFQ готов для представления в LKML. С этой целью мы уже подготовили патчсет для ревью. Но, прежде чем приступить к добавлению в основную ветку, нам нужно закончить тестирование версии v7r3 и выпустить релиз. Надеюсь, мы сможем это сделать в ближайшую неделю.
Паоло Валенте (Paolo Valente), основатель планировщика BFQ
Анализ результатов тестирования
Поскольку написание статьи связано с планировщиком BFQ, сосредоточимся именно на нем.
Запись с помощью dd у меня заняла в среднем 137,71 с, что, конечно, немного больше, чем при использовании планировщика Deadline (в среднем 136,89 с), но меньше, чем при использовании других планировщиков, — например, при сравнении с CFQ BFQ опережает его почти на 4 с.
Чтение же с помощью dd столь значительной разницы не показало. Тем не менее в этом тесте BFQ впереди планеты всей, а CFQ опять аутсайдер.
Тесты с помощью hdparm (чтение как из кеша, так и из дискового буфера) по неизвестным причинам вывели на первое место планировщик Deadline. Впрочем, полагаться на результат именно этого теста особого смысла нет — выглядит он слишком уж синтетическим.
Замер общего времени выполнения распаковки ядра с помощью команды time снова вывел BFQ на второе место — хотя и этот тест выглядит не менее синтетическим, чем предыдущий.
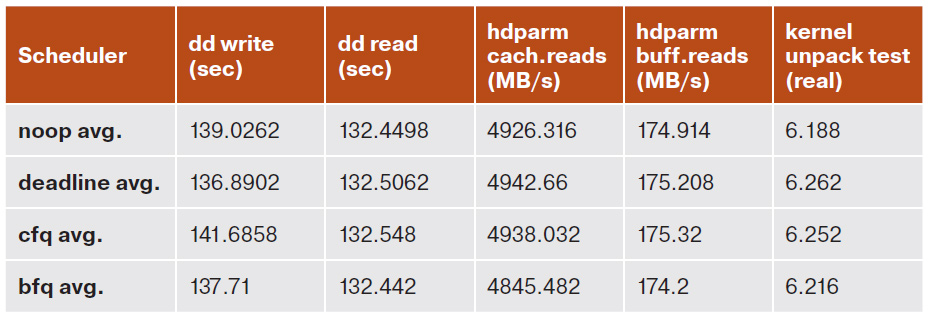
Таблица результатов моих собственных тестов
А теперь перейдем к результатам Bonnie++. Результатов там много, но я покажу только самые основные. Рассматривать я буду исключительно максимальную задержку для одной операции (опять же усредненную). При использовании функции putc() задержка у нашего кандидата на включение в ядро составляет 12 901 мкс, что выводит его на первое место. То же самое можно сказать и про запись блока — при данном тесте BFQ вырывается далеко вперед. А вот при чтении блока выигрывает CFQ с его 9082,6 мкс, BFQ же в этом тесте (как и в тесте на перезапись блока) стоит на втором месте. В тесте последовательного создания файлов BFQ на втором месте, зато в тестах рандомного создания/удаления он вновь лидирует.
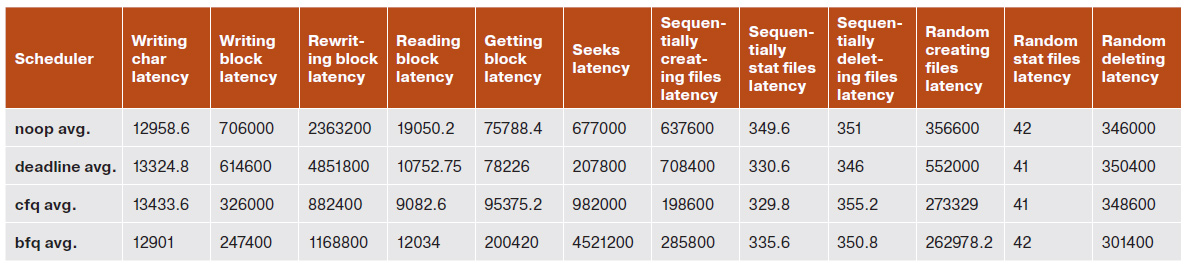
Таблица результатов (среднее значение задержки) для Bonnie++
Как видим, в среднем BFQ уверенно занимает первое-второе место. К сожалению, у меня нет возможности проверить SSD-накопители, так что трудно сказать, какой из планировщиков подходит в случае их использования, но для жестких дисков BFQ определенно неплох, так что его можно смело включать в качестве планировщика по умолчанию на большинстве домашних компьютеров.
После установки Ubuntu Studio 12.04 я обнаружил, что она использует ядро с низкой задержкой. Я искал, почему и как изменить обратно на реальный или общий. Но похоже, что эта часть Linux не так много освещена.
В: Почему ядро с малой задержкой предпочитает обычное ядро или ядро реального времени?
PS: я уже прочитал ответы на этот вопрос и этот пост.
+1 потому что это должно быть довольно хороший вопрос, если все в тупике. Я все еще не знаю разницы между ядрами с малой задержкой, универсальными и в реальном времени. Если -realtime это в реальном времени, то что означает -rt ? А что там с -preempt ядром? Я буду благодарен gemue2010, он проделал довольно хорошую работу, объясняя это, но это все еще не объясняет все.- Если для вашей системы не требуется низкая задержка, используйте ядро -generic.
- Если вам нужна система с низкой задержкой (например, для записи звука), пожалуйста, используйте ядро -preempt в качестве первого выбора. Это уменьшает задержку, но не жертвует функциями энергосбережения. Он доступен только для 64-битных систем (также называемых amd64).
- Если ядро -preempt не обеспечивает достаточно низкой задержки для ваших нужд (или у вас 32-битная система), вам следует попробовать ядро -lowlatency.
- Если ядра -lowlatency недостаточно, вам следует попробовать ядро -rt
- Если ядро -rt недостаточно стабильно для вас, вам следует попробовать ядро -realtime
Так что это зависит от того, что вы будете делать с вашим студийным дистрибутивом. Для большинства пользователей, которым требуется быстрое время отклика конечного пользователя, универсальный режим подойдет просто, для других, которым необходимо профессиональное редактирование видео, где даже простое удаление кадра недопустимо, требуется ядро реального времени.
Для более полного и понятного поста в блоге, прочитайте эту ссылку
Я уже прочитал предыдущую статью, которую вы опубликовали. Во-вторых, насколько достоверны эти факты? Ну, упомянутые там тесты говорят сами за себя. Если команда Ubuntu в первую очередь выбрала Latency, это должно быть причиной для этого. Итак, вы хотели знать различия, теперь вы делаете. Задача решена ? Нет .. Я не думаю, что проблема решена. Если ваш ответ что-то делает, это еще больше увеличивает мое любопытство. Все ли это по-прежнему актуально в 2015 году? В -preempt , -rt и -realtime ядра не-больше не существуетНо в настоящее время процессоры имеют много ядер, поэтому, когда мало процессов, требующих внимания, их можно легко разместить на другом ядре, а не ждать, пока ядро его возьмёт.
Так что, как правило, я бы сказал: если ваш процессор является мощным высокочастотным четырехъядерным процессором, работающим с большими числами, и вы обычно не открываете тонны веб-страниц при кодировании / декодировании / играх (да), вы могли бы просто попробуйте стандартное (или i686, или amd64, если они существуют) ядро и имеют максимально возможную пропускную способность (т. е. необработанное вычисление числа, которое способен процессор). Если у вас возникли проблемы (они действительно должны быть незначительными) или ваша машина немного менее мощная, чем вершина рынка, выберите вариант -preempt.
Если вы работаете на младшей машине с одним или двумя ядрами, попробуйте опцию -lowlatency. Вы также можете попробовать -realtime, но вы обнаружите, что он имеет тенденцию блокировать процессы, пока те, которые работают в режиме реального времени, не закончили свою работу. Я считаю, что ядро реального времени не является «ванильным», но имеет патч CONFIG_PREEMPT_RT. Я думаю, что ядра реального времени предназначены только для тех, кому нужно создавать одно приложение на встраиваемых системах, поэтому обычные пользователи настольных компьютеров не должны иметь реальных преимуществ, потому что они обычно запускают достаточное количество приложений одновременно.
Наконец, наиболее подходящие параметры ядра, если вы хотите самостоятельно перекомпилировать ядро, чтобы иметь рабочий стол с низкой задержкой:
Один из вопросов, который он задал вам, - это имя «System mail name». Вы хотите это изменить.
- мягкая система реального времени даст уменьшенная средняя задержка, но не гарантированное максимальное время ответа.
- Жесткая система в режиме реального времени всегда соблюдает требуемые сроки (100 процентов), даже при нагрузке на систему в худшем случае.
- Согласно Ягмуру [4], «в режиме реального времени имеют дело с гарантиями, а не с необработанной скоростью».
В статье говорится, что жесткое ядро в реальном времени не реагирует или ограничение по времени является наиболее важным свойством, поэтому иногда они задерживают некритическую активность, которая приводит к задержке, но для низкого уровня задержки или другого мягкого ядра в реальном времени пытаются уменьшить общую задержку, которая помогает в большинстве случаев. Из-за уменьшенного времени ожидания система работает быстро. Внимательно прочитайте статью.
Кстати: preempt-, low latency или rt kernel не сделают вашу систему быстрее. Они немного медленнее , чем общее ядро.
Это несколько простых рекомендаций, которые помогут вам понять, какое ядро и в каком порядке вам следует протестировать в соответствии с вашим вариантом использования.
- Если вам не требуется низкая задержка для вашей системы, используйте ядро -generic.
- Если вам нужна система с низкой задержкой (например, для записи звука), пожалуйста, используйте ядро -preempt в качестве первого выбора. Это уменьшает задержку, но не жертвует функциями энергосбережения. Он доступен только для 64-битных систем (также называемых amd64).
- Если ядро -preempt не обеспечивает достаточно низкой задержки для ваших нужд (или у вас 32-битная система), вам следует попробовать ядро -lowlatency.
- Если ядра -lowlatency недостаточно, вам следует попробовать ядро -rt
- Если ядро -rt недостаточно стабильно для вас, вам следует попробовать ядро -realtime [ 1111]
Я полагаю, это зависит от того, что вы будете делать со своим студийным дистрибутивом. Для некоторых пользователей generic просто подойдет, для других - нет.
Но в настоящее время процессоры имеют много ядер, поэтому, когда мало процессов, требующих внимания, их можно легко разместить на другом ядре, а не ждать, пока ядро его возьмёт.
Итак, как правило, я бы сказал: если ваш процессор представляет собой мощный высокочастотный четырехъядерный процессор, работающий с большими числами, и вы обычно не открываете тонны веб-страниц при кодировании / декодировании / играх (да) Вы можете просто попробовать универсальное (или i686, или amd64, если они существуют) ядро и иметь максимально возможную пропускную способность (т. е. с обработкой необработанных чисел процессором способен). Если у вас возникли проблемы (они действительно должны быть незначительными) или ваша машина немного менее мощная, чем вершина рынка, выберите вариант -preempt.
Если вы находитесь на младшей машине, которая имеет только одно или два ядра, попробуйте -lowlatency. Вы также можете попробовать -realtime, но вы обнаружите, что он имеет тенденцию блокировать процессы, пока те, которые работают в режиме реального времени, не закончили свою работу. Я считаю, что ядро реального времени не "ванильное", но имеет патч CONFIG_PREEMPT_RT. Я думаю, что ядра реального времени предназначены только для тех, кому нужно создавать одно приложение на встраиваемых системах, поэтому обычные пользователи настольных компьютеров не должны иметь реальных преимуществ, потому что они обычно запускают достаточное количество приложений одновременно.
И наконец, наиболее подходящие параметры ядра, если вы хотите самостоятельно перекомпилировать ядро, чтобы иметь рабочий стол с низкой задержкой:
В зависимости от частоты процессора, объема свободной оперативной памяти и скорости работы видеоподсистемы стандартное ядро Linux имеет время отклика в диапазоне от 10 до 100 мс (ядра серии 2.2.* даже до 150 мс), чего вполне достаточно для обычного использования. Но существуют задачи, для которых такая латентность считается невероятно большой. Например, обработка звука требует задержки не более 5 мс суммарно для всей системы, включая реакцию периферийных устройств. Давай разбираться, как можно уменьшить это значение в пингвине.
О чем это мы?
Используем подручные средства
Как известно, жизнь системе дают процессы, которые играют ключевую роль в любой операционной системе. Ядро не резиновое, и, несмотря на заоблачные гигагерцовые частоты, в единицу времени можно выполнить инструкции только одного процесса (при этом время использования процессора называют квантом), а самих процессов в системе может быть очень много. Итак, чтобы уменьшить задержки, количество процессов необходимо свести к минимуму. Для этого нужно не только убрать все лишние программы и отключить все неиспользуемые демоны, но и пересобрать ядро, оставив лишь действительно необходимый функционал.
Для того чтобы культурно распределить ресурсы и никого при этом не обделить, в любой системе имеется своя подсистема управления процессами, работающая по принципу «каждому по способностям, каждому по труду». Процесс может работать в двух режимах: в режиме ядра (kernel mode) и в пользовательском режиме (user mode), где он выполняет простые инструкции, не требующие особых «системных» данных. Но когда такие услуги понадобятся, процесс перейдет в режим ядра, хотя инструкции по-прежнему будут выполняться от имени процесса. Все это сделано специально, чтобы защитить рабочее пространство ядра от пользовательского процесса. Остальные процессы либо готовятся к
запуску, ожидая, когда планировщик их выберет, либо находятся в режиме сна (asleep), дожидаясь недоступного на данный момент времени ресурса. С последним все просто. Когда поступает сигнал с подконтрольного устройства, процесс объявляет себя TASK_RUNNING и становится в очередь готовности к запуску. Если он имеет высший приоритет, то ядро переключается на его выполнение.
Но есть еще одна заковырка. При предоставлении процессу системных ресурсов происходит так называемое переключение контекста (context switch), сохраняющее образ текущего процесса (на что, кстати, тоже требуется какое-то время, поэтому латентность даже в идеальном случае не будет равна нулю). Так вот переключение контекста, когда процесс находится в режиме ядра, может привести к краху всей системы. Поэтому высокоприоритетному процессу придется терпеливо подождать момента перехода в режим задачи, а это может произойти в двух случаях: работа сделана или необходимый ресурс недоступен. То есть, чтобы обеспечить меньшее время отклика, необходимо свести к минимуму число ядерных
задач. Но за такое решение приходится платить общей стабильностью и «тяжестью» кода. В микроядрах это, кстати, реализовано значительно лучше - имеется базовый минимальный набор, остальное навешивается модульно, как на новогоднюю елку, что обеспечивает универсальность и позволяет конструировать системы под конкретные задачи.
Что касается планирования процессов, то оно завязано на приоритете. Планировщик попросту выбирает следующий процесс, имеющий наивысший приоритет. При этом менее приоритетный процесс, выполняющийся в тот момент, может даже полностью не отработать свой квант до конца. Каждый процесс имеет два вида приоритета: относительный (p->nice, по умолчанию до 100 уровней приоритетов), устанавливаемый при запуске приложения, и текущий, на основании которого и происходит планирование. Значение текущего приоритета не является фиксированным, а вычисляется динамически и напрямую зависит от nice. Значение, устанавливаемое пользователем, может находиться в пределах от -20 до +19, при этом приложению с более
высоким приоритетом соответствует значение -20, а +10 (по умолчанию) и выше считаются уже низкоприоритетными задачами. Например, для запуска программы с более высоким, чем обычно, приоритетом, делаем так:
$ sudo nice --20 mplayer
А с более низким:
$ sudo nice -20 job &
Чтобы изменить относительный приоритет процесса, следует использовать идентификатор процесса, а не название:
$ sudo renice --20 PID
Кстати, уменьшить время отклика можно, отказавшись от использования утилиты hdparm для дисковых устройств (исключение составляют случаи, когда предвидятся интенсивные операции ввода/вывода, например, обработка аудио- или видеоданных). Так мы получим выигрыш в районе 2 мс.
Текущий приоритет зависит от nice и времени использования системных ресурсов. Он пересчитывается с каждым тиком и во время выхода из режима ядра. В разных системах это происходит по своим формулам, в простейшем случае приоритет просто делится на 2 и при достижении нулевого значения полностью пересчитывается заново (восстанавливается). Такой механизм позволяет получить свое время и низкоприоритетным приложениям, но в итоге высокоприоритетные получают большую его часть.
Каждый компьютер имеет системные часы, которые генерируют аппаратное прерывание через определенные промежутки времени. Интервал между этими прерываниями называется тиком (clock tick). В различных операционных системах тик имеет свое значение. В Linux, как и в большинстве никсов, он составляет 10 мс. Значение можно подсмотреть в файле заголовков include/linux/param.h, в константе HZ. Для тика 10 мс значение HZ равно 100. Чем эта цифра больше, тем чаще тикает планировщик. Тик - одна из высокоприоритетных задач, которая должна занимать минимум времени. За время тика происходит просмотр статистики использования процессора, перепланирование процессов, обновление системного
времени (CLOCKS_PER_SEC), отработка необходимых системных процессов, отложенных вызовов и алармов (посылка определенного сигнала процессу через запрашиваемое им время).
Для того чтобы указать на приложение, которое требует особого внимания со стороны процессора, можно использовать и заложенный в спецификации POSIX real-time вызов SCHED_FIFO (нечто вроде перехода в режим «мягкого» реального времени). Подобный результат достигается при использовании вызовов SCHED_RR, CAP_IPC_LOCK, CAP_SYS_NICE или через подмену значения sys_sched_get_priority_max - функции, возвращающей максимальный real-time приоритет. Именно использование SCHED_FIFO приводит к тому, что проигрыватель xmms, запущенный под root, практически не заикается даже при запредельных нагрузках на систему.
Выгружаемое ядро
Основной проблемой real-time является возможность захвата ресурсов у низкоприоритетного процесса, особенно если он выполняется в режиме ядра. Ведь даже на переключение контекста тратится некоторое время. Сотни разработчиков по всему миру пытались применить милиарды технологий: от возможности прерывания во время исполнения в ядерном режиме (preemptible kernel, выгружаемое ядро) до временного наследования (inherit) приоритета реального времени низкоприоритетным приложением, чтобы он мог поскорее закончить критический раздел кода и отдать управление.
Тема выгружаемого ядра заинтересовала общественность еще в период господства ветки 2.2. Линус Торвальдс сказал, что real-time - плохая идея, и до поры preemptible реализовывалось исключительно с помощью патчей. Но уже при подготовке ветки 2.6 в исходный код была добавлена возможность сделать ядро выгружаемым (PREEMPT_RT). Preemptible-kernel реализуется, как правило, в виде второго ядра. Если процесс обращается к нему с запросом, основная система фактически блокируется на время его выполнения. Исполняется все это в виде загружаемого модуля, который подменяет/перехватывает наиболее критичные функции, способные привести к задержкам. Но не все так просто. В своем интервью один
из инженеров MontaVista (компании-разработчика одного из real-time решений на базе Linux) заявил, что в ядре 2.6 около 11 000 участков кода просто невозможно сделать preemptible.
Патчим ядро
Для тестирования задержек следует использовать специальные утилиты. В Сети можно найти несколько решений. Например, latencytest, которая разрабатывалась как раз для измерения общих задержек при обработке мультимедийных данных во время различных потрясений, которые могут возникнуть на обычном десктопе (загрузка процессора сложными вычислениями; трудоемкие операции ввода/вывода: запись, копирование, считывание файла размером 350 Мб; вывод большого количества графики; доступ к системе процессов /proc с обновлением через 0,01 с). Эта утилита считается уже устаревшей, зато вся информация выводится с помощью
наглядных графиков, что очень удобно при сравнении результатов. К современным бенчмаркам можно отнести rt-test и pi_tests.
На стандартном ядре запускаем утилиту rt-test, только запустив, мы получаем значение 0,125 мс, при увеличении нагрузки оно возрастает до 15,402 мс. Следует обратить внимание на параметр Criteria, который равен 100 микросекунд. В нашем случае результат теста - FAIL, то есть до real-time еще далеко. Ставим lowlatency-ядро - обычное ядро, но с таймером 1000 HZ и уменьшенным временем отклика:
$ sudo apt-get install linux-lowlatency
Перезагружаемся и запускаем rt-test еще раз.
$ sudo rt-test all
Стартовое значение латентности теперь равно 0,073 мс, а максимальное – 2,907 мс. Уже лучше. Хотя Criteria по-прежнему FAIL, но музычка в Amarok'е при приличной загрузке системы больше не прерывается.
После перезагрузки системы, введя dmesg, можно увидеть, что ядро стало PREEMPT RT, таймер часов работает нестабильно («Clocksource tsc unstable»), а ps aux показывает наличие большого числа новых процессов. Но нас больше интересует результат работы rt-test. Так вот все наши ухищрения привели к тому, что максимальное значение латентности теперь не превышает 0,07 мс. Вуаля, тест пройден!

Полную версию статьи
читай в ноябрьском номере Хакера!
Читайте также: