
Linux поиск строки в gz
Я хотел бы найти в этом архиве «строку».
Один Grep, похоже, не делает этого. Я также попробовал SearchMonkey.
использовать zgrep : zgrep - search possibly compressed files for a regular expressionЕсли вы хотите рекурсивно выполнять grep во всех файлах .eml.gz в текущем каталоге, вы можете использовать:
Вы должны убежать от первого, * чтобы оболочка не интерпретировала его. -print0 говорит find для печати нулевого символа после каждого найденного файла; xargs -0 читает из стандартного ввода и запускает команду после него для каждого файла; zgrep работает как grep , но сначала распаковывает файл.
«-print0» и «-0» не являются обязательными. xargs по умолчанию использует '\ n'. Они необходимы, если в путях могут быть пробелы; нет никакой другой причины, кроме сложности, чтобы не использовать их. zgrep на самом деле кажется быстрее, чем grep работать с несжатыми файлами. Это должно быть потому, что сжатые файлы могут быть прочитаны с жесткого диска и распакованы быстрее, чем чтение несжатого файла с жесткого диска. @JaimeM. по умолчанию xargs использует пробелы (пробелы). Конечно, в файлах почти никогда не бывает символов новой строки, но пробелы не являются неслыханными (даже если большинство типов UNIXy недовольны ими). Тем не менее, вы можете упростить, не беспокоясь о пробелах, еще проще: find . -name '*.eml.gz' -exec zgrep "STRING" <> + это получает столько же аргументов за запуск xargs , безопасность -print0 / -0 и все без дополнительных затрат на запуск и процессирование процесса, и довольно лаконично. -exec with + - это POSIX, поэтому, насколько мне известно, это должно быть в большинстве последних UNIX-подобных систем.Здесь много путаницы, потому что ее нет zgrep . У меня есть две версии в моей системе, zgrep из gzip и zgrep из zutils . Первый - это просто скрипт-обертка, который вызывает gzip -cdfq . Он не поддерживает -r, --recursive переключатель. 1
Последняя представляет собой c++ программу , и она поддерживает в -r, --recursive опции.
Запуск zgrep --version | head -n 1 покажет, какой из них (если есть) является значением по умолчанию:
это cpp исполняемый файл.
Если у вас есть последний, вы можете запустить:
В любом случае, как и предполагалось, find + zgrep будет одинаково хорошо работать с любой версией zgrep :
Если zgrep отсутствует в вашей системе (очень маловероятно), вы можете попробовать с:
но есть существенный недостаток: вы не будете знать, где находятся совпадения, так как к совпадающим строкам нет имени файла.
Это руководство покажет вам, как искать в сжатых файлах строку текста или конкретное выражение.
Как искать и фильтровать результаты с помощью команды Grep
Вы можете использовать grep для поиска шаблонов по содержимому файла или выводу другой команды.
Например, если вы запустите следующую команду ps, вы увидите список процессов, запущенных на вашем компьютере.
Результаты быстро прокручиваются на экран, и если результатов обычно много. Это делает просмотр информации особенно болезненным.
Конечно, вы могли бы использовать команду more для вывода одной страницы результатов за раз следующим образом:
Хотя вывод вышеприведенной команды лучше, чем предыдущей, вам все равно придется пролистать результаты, чтобы найти то, что вы ищете.
Команда grep позволяет фильтровать результаты на основе критериев, которые вы ей отправляете. Например, для поиска всех процессов с UID, установленным в «root», выполните следующую команду:
Команда grep также работает с файлами. Представьте, что у вас есть файл со списком названий книг. Представьте, что вы хотите увидеть, содержит ли файл «Красная Шапочка». Вы можете искать файл следующим образом:
Команда grep очень мощная, и с ней можно использовать множество полезных ключей.
Как искать сжатые файлы с помощью команды zgrep
Малоизвестным, но очень мощным инструментом является zgrep. Команда zgrep позволяет вам искать содержимое сжатого файла без предварительного извлечения содержимого.
Команда zgrep может использоваться для файлов zip или файлов, сжатых с помощью команды gzip.
В чем разница? Zip-файл может содержать несколько файлов, тогда как файл, сжатый с помощью команды gzip, содержит только исходный файл.
Для поиска текста в файле, сжатом с помощью gzip, вы можете просто ввести следующую команду:
Например, представьте, что список книг был сжат с помощью gzip. Вы можете найти текст «маленькая красная шапочка» в сжатом файле с помощью следующей команды:
Вы можете использовать любое выражение и все параметры, доступные через команду grep, как часть команды zgrep.
Как искать сжатые файлы с помощью команды zipgrep
Команда zgrep хорошо работает с файлами, сжатыми с помощью gzip, но не очень хорошо работает с файлами, сжатыми с помощью утилиты zip.
Вы можете использовать zgrep, если zip-файл содержит один файл, но большинство zip-файлов содержат более одного файла.
Команда zipgrep используется для поиска шаблонов в zip-файле.
В качестве примера представьте, что у вас есть файл с названием books со следующими заголовками:
- Гарри Поттер и тайная комната
- Укрощение строптивой
- О мышах и людях
- Автостопом по Галактике
- Гарри Поттер и Орден Феникса
Также представьте, что у вас есть файл с именами фильмов со следующими названиями:
Теперь представьте, что эти два файла были сжаты с использованием формата zip в файл с именем media.zip.
Вы можете использовать команду zipgrep, чтобы найти шаблоны во всех файлах внутри zip-файла. Например:
Например, представьте, что вы хотите найти все вхождения «Гарри Поттера», используйте следующую команду:
Вывод будет следующим:
книги: Гарри Поттер и Тайная комната
книги: Гарри Поттер и Орден Феникса
фильмы: «Гарри Поттер и Тайная комната»
фильмы: «Гарри Поттер и Кубок огня»
Так как вы можете использовать любое выражение с zipgrep, которое вы можете использовать с grep, это делает инструмент очень мощным и делает поиск в zip-файлах намного проще, чем распаковка, поиск и последующее сжатие снова.
Если вы хотите искать только определенные файлы в zip-файле, вы можете указать файлы для поиска в zip-файле как часть команды следующим образом:
Вывод теперь будет следующим
фильмы: «Гарри Поттер и Тайная комната»
фильмы: «Гарри Поттер и Кубок огня»
Если вы хотите найти все файлы, кроме одного, вы можете использовать следующую команду:

Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
Элементы в квадратных скобках не являются обязательными.- OPTIONS - Ноль или более вариантов. Grep включает в себя ряд параметров, которые контролируют его поведение.
- PATTERN - Шаблон поиска.
- FILE - Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Основное использование grep команды - поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Чтобы отобразить линии, которые не соответствуют шаблону, используйте параметр -v (или --invert-match ).
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона, grep используйте -r опцию (или --recursive ). Когда эта опция используется, grep будет выполняться поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы перейти по всем символическим ссылкам , вместо этого -r используйте -R опцию (или --dereference-recursive ).
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете -R опцию, grep перейдите по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается -r из-за того, что файлы в sites-enabled каталоге Nginx являются символическими ссылками на файлы конфигурации внутри sites-available каталога.
Показывать только имя файла
Чтобы подавить grep вывод по умолчанию и печатать только имена файлов, содержащих сопоставленный шаблон, используйте параметр -l (или --files-with-matches ).
Команда ниже просматривает все файлы, заканчивающиеся .conf в текущем рабочем каталоге, и печатает только имена файлов, содержащих строку baks.dev :
Вывод будет выглядеть примерно так:
-l Вариант обычно используется в сочетании с рекурсивной опции -R :
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Чтобы игнорировать регистр при поиске, grep используйте -i опцию (или --ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра, используя -i опцию, он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр -w (или --word-regexp ).
Символов слова включают в себя буквенно - цифровые символы ( a-z , A-Z и 0-9 ) и подчеркивание ( _ ). Все остальные символы рассматриваются как несловесные символы.Если вы выполните ту же команду, что и выше, включая -w опцию, grep команда вернет только те строки, которые gnu включены в качестве отдельного слова.
Показать номера строк
Опция -n (или --line-number ) указывает grep показывать номер строки, содержащей строку, которая соответствует шаблону. Когда эта опция используется, grep печатает совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
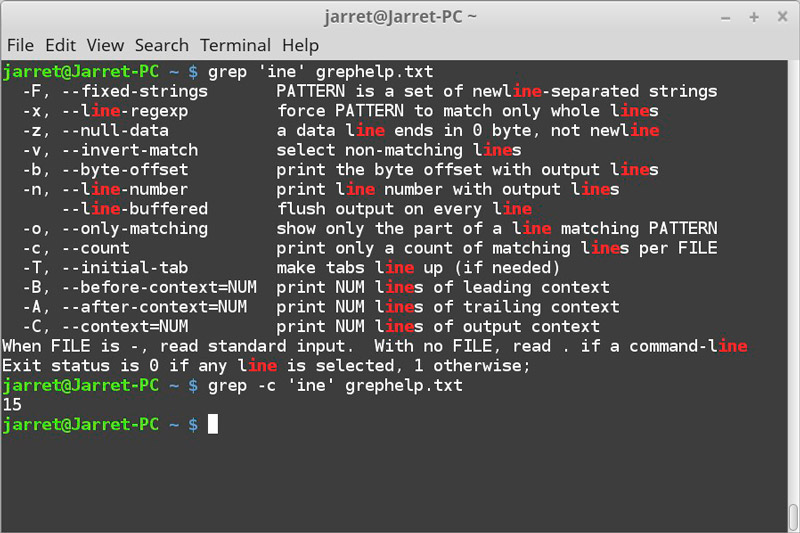
Чтобы напечатать количество совпадающих строк в стандартный вывод, используйте параметр -c (или --count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
-q (Или --quiet ) говорит , grep чтобы работать в скрытом режиме , чтобы не показывать ничего на стандартный вывод. Если совпадение найдено, команда завершается со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте $ символ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте . символ (точка), чтобы соответствовать любому отдельному символу. Например, для сопоставления всего, что начинается с kan двух символов и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используется [^ ] для соответствия любому отдельному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и так далее, но не будет совпадать со строками, содержащими cola ,
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Ниже приведены некоторые примеры:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
Два или более шаблонов поиска могут быть объединены с помощью оператора ИЛИ | .
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
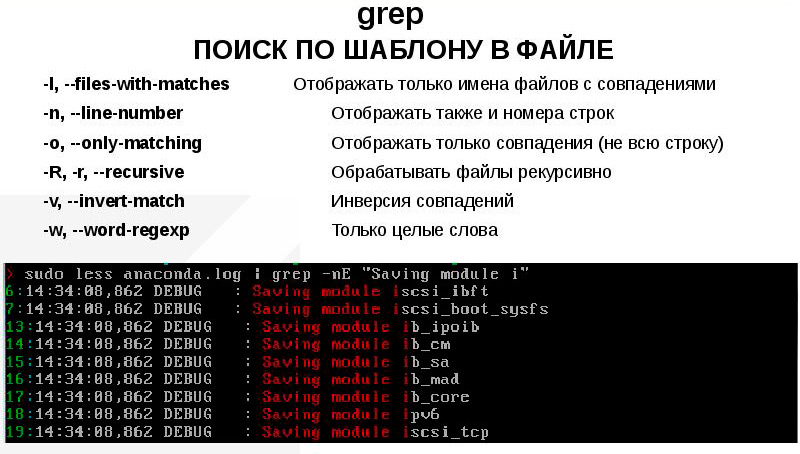
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в журнале Nginx файл ошибки:
Если вы используете опцию расширенного регулярного выражения -E , оператор | не должен быть экранирован, как показано ниже:
Печать строк перед сопоставлением
Чтобы напечатать определенное количество строк перед сопоставлением строк, используйте параметр -B (или --before-context ).
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Чтобы напечатать определенное количество строк после сопоставления строк, используйте параметр -A (или --after-context ).
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Изначально операционные системы Unix/Linux не имели графического интерфейса, поскольку были ориентированы на серверное применение. Сегодня в этом плане они мало в чём уступают Windows, из-за чего пользователи, использующие эту ОС, редко знают синтаксис и назначение основных команд Linux. Между тем это весьма мощный инструмент, позволяющий быстро выполнять операции, которые с помощью базовых средств ОС выполнить проблематично или невозможно. Сегодня вы познакомитесь с операторами find и grep, являющимися базовыми для файловой системы всех дистрибутивов Linux.
Назначение операторов find и grep
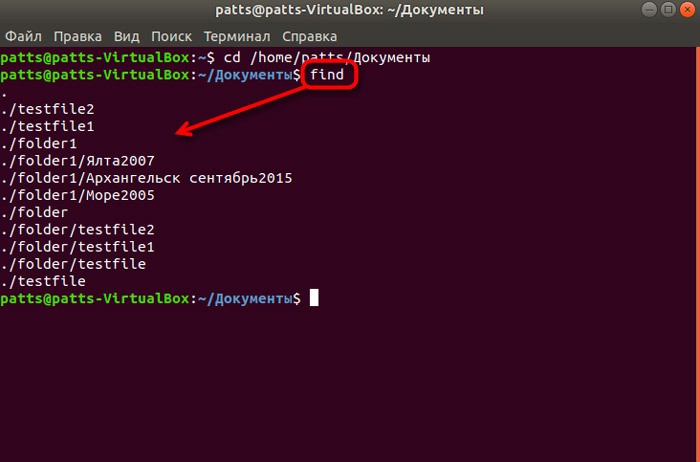
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Синтаксис grep и find
Начнём с оператора find. Синтаксис файловой поисковой команды выглядит так:
find [где искать] [параметры] [-опции] [действия]
Некоторые употребительные параметры:
- -depth : поиск в текущей папке и подкаталогах;
- -version : вывести версию команды;
- -print : показывать полные имена файлов (в Linux они могут быть сколь угодно большими);
- -type f : поиск исключительно файлов;
- -type d – поиск только директорий (папок).
Перечень доступных опций (указываются через дефис):
- name : файловый поиск по имени;
- user : поиск по имени владельца файла;
- perm : по атрибуту «режим доступа»;
- mtime : по времени последнего изменения (редактирования) файла;
- group : по группе;
- atime : по дате последнего открытия файла;
- newer : поиск файла с датой, более новой, чем заданная в шаблоне директивы;
- size : по размеру файла в байтах;
- nouser : поиск файлов, не имеющих введённого атрибута «владелец».
grep [опции] шаблон [где искать]
Под опциями следует понимать дополнительные уточняющие параметры, например, использование инверсного режима или поиск заданного количество строк.
В шаблоне указывается, что нужно искать, используя непосредственно заданную строку или регулярное выражение.
Возможность использования регулярных выражений позволяет существенно расширить возможности поиска. Указание стандартного вывода может оказаться полезным, если стоит задача отфильтровать ошибки, записанные в логи, или для поиска PID процесса в результатах выполнения команды ps, которые могут быть многостраничными.
Рассмотрим наиболее употребительные параметры grep:
- -b : выводить номер блока перед выдачей результирующей строки;
- -c : необходимо подсчитать число вхождений искомого фрагмента;
- -i : поиск без учёта регистра;
- -n : выдавать на стандартное устройство вывода номер строки, в которой найден искомый фрагмент или шаблон;
- – l : в результате выдачи должны присутствовать только имена файлов с найденным поисковым фрагментом;
- -s : игнорировать вывод ошибок;
- -w : поиск фрагмента, опоясанного с двух сторон пробелами;
- -v : инвертированный поиск, то есть отображение всех строк, не содержащих заданный фрагмент;
- -e : параметр указывает, что далее следует регулярное выражение, имеющее собственный синтаксис;
- -An : вывод искомого фрагмента и предыдущих n строк;
- -Bn : то же, но со строками, идущими после шаблона.
Теперь имеет смысл перейти от теоретической части к практической.3
Примеры использования утилит
Если вы знаете, что такое комбинаторика, то должны представлять истинное количество возможных комбинаций команд поиска. Мы ограничимся только наиболее полезными примерами, которые могут вам пригодиться при работе.
Поиск текста в файлах
Пускай мы имеем права администратора и перед нами поставлена задача отыскать конкретного пользователя в огромном файле паролей. Нам понадобится довольно простая команда с указанием пути размещения файла:
grep NameUser /etc/passwd
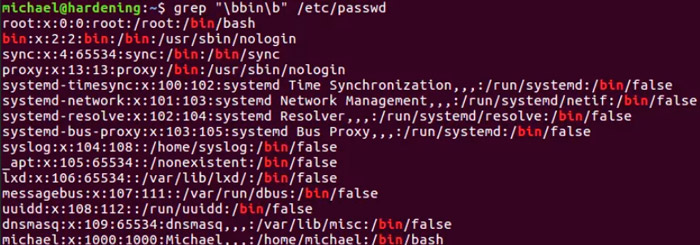
Если результат поиска будет положительным, мы получим результирующую строку примерно следующего вида:
NameUser:x:1021:1021: NameUser. /home/User:/bin/bash
Если потребуется осуществить поиск фрагмента текста без учёта регистра символов, команда будет выглядеть так:
grep -i "nameuser" /etc/passwd
В этом случае будет найден и пользователь NameUser, и его «однофамилец» nameuser, а также все другие возможные комбинации.
Вывод нескольких строк
Пускай нам нужно вывести все ошибки из лога оконной оболочки Xorg.log. Задача осложняется тем, что после ошибочной может следовать строка, содержащая ценные сведения. Она решается, если мы заставим команду отображать несколько строк, используя в качестве шаблона строку «РР»:
grep –A5 "РР" /var/log/xorg.0.log
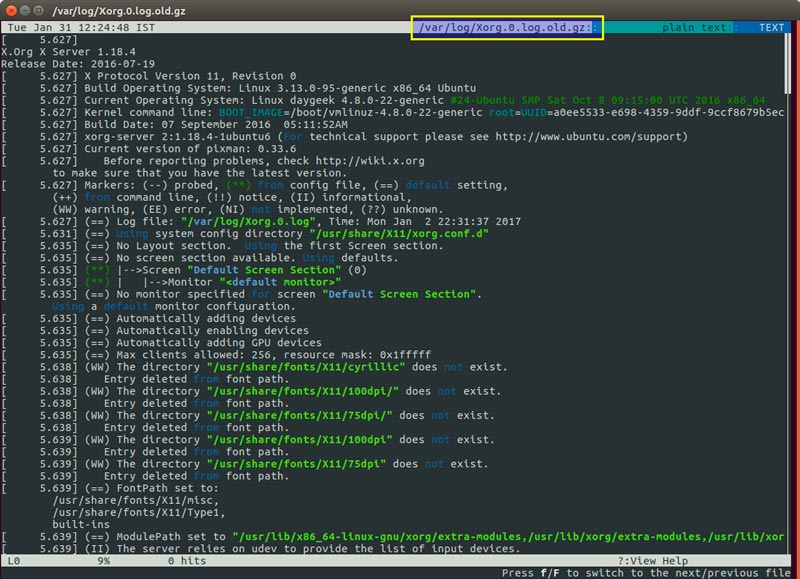
Получим строку, содержащую шаблон и 5 строк после неё.
grep –C3 "РР" /var/log/xorg.0.log
Вывод строки с фрагментом текста и тремя строками до и после.
Использование в grep регулярных выражений
Это один из самых мощных инструментов Linux, существенно расширяющий возможности формирования поискового шаблона. Регулярные выражения имеют свой синтаксис, достаточно сложный. Мы не будем в него углубляться, ограничившись примером использования РВ. Как вы уже знаете, для указания, что далее используется регулярное выражение, используется параметр -e.
Пускай нам в файле messages.2 нужно выловить все строки за сентябрь:
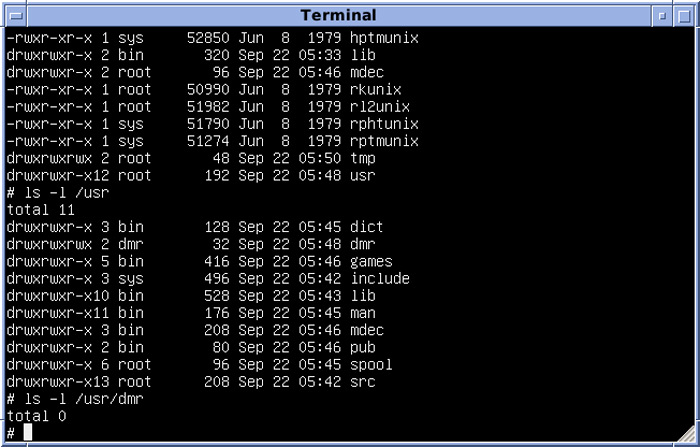
Итог будет примерно таким:
Sep 09 01:11:45 gs124 ntpd[2243]: time reset +0.197579 s
Sep 09 01:19:10 gs124 ntpd[2243]: time reset +0.203484 s
grep "term.$" messages
Jun 17 19:01:19 cloneme kernel: Log daemon term.
Sep 11 06:30:54 cloneme kernel: Log daemon term.
А вот пример использования регулярного выражения, позволяющего выполнить поиск строк, содержащих любые цифры, кроме нуля:
grep "8" /var/log/Xorg.1.log
Использование рекурсивного поиска в grep
grep -r "namedomain.org" /etc/apache1/
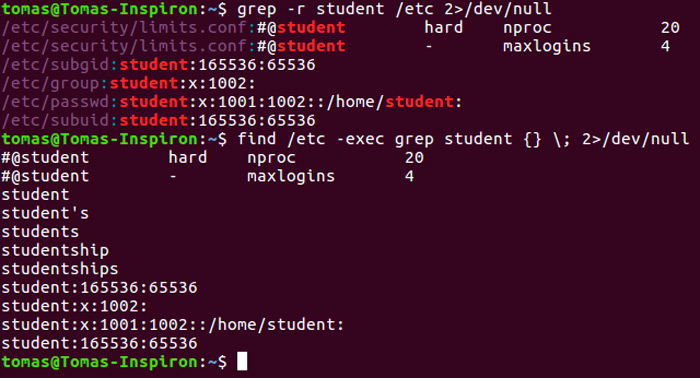
Результат может быть примерно таким:
Если показ имени файла не требуется, используем опцию -h:
grep -h -r "namedomain.org" /etc/apache1/
Поиск слов
Стандартно поиск фрагмента qwe завершится выдачей всех слов, в которых встречается этот фрагмент: kbqwe, qwe123, aafrqwe32. Чтобы ограничить поиск только заданным фрагментом, нужно использовать параметр -w:
grep -w "qwe" где_искать
Поиск двух или нескольких слов
Усложним задачу: нам нужно найти все строки, где встречается два слова. Команда будет такой:
grep -w "word01|word02" где_искать
Количество вхождений строки
Если требуется подсчитать. Сколько раз искомый фрагмент встречается в файле, используем конструкцию с параметром -c:
grep -c "'text» где_искать
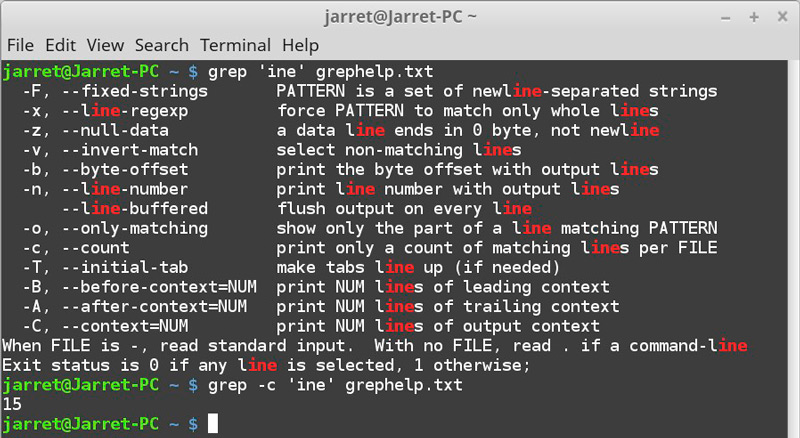
Параметр -n поможет узнать, в какой строке встречается искомый шаблон:
grep -n "nuser" /etc/passwd
Инвертированный поиск с помощью grep
Иногда задача поиска с использованием grep по содержимому файлов имеет цель найти не само вхождение, а строки, где этот фрагмент отсутствует. Нам поможет опция –v:
grep -v "txt" где_искать
Вывод имени файла
grep -l "secondary" /etc
Цветной вывод с использованием grep
Выделение другим цветом – отличный способ визуализировать искомое вхождение, существенно снижающий нагрузку на глаза, если операция выполняется часто. Оказывается, grep имеет опцию и для такого вывода результатов поиска:
grep --color "secondary" /etc
Переходим к рассмотрению примеров использования утилиты find в Linux.
Поиск всех файлов
Для вывода списка файлов, расположенных в текущем каталоге, используем команду в следующем формате:
Если необходимо показать полное имя файлов, используем команду
Вывод файлов в заданном каталоге
Для поиска файлов в определенной пользователем папке используем команду
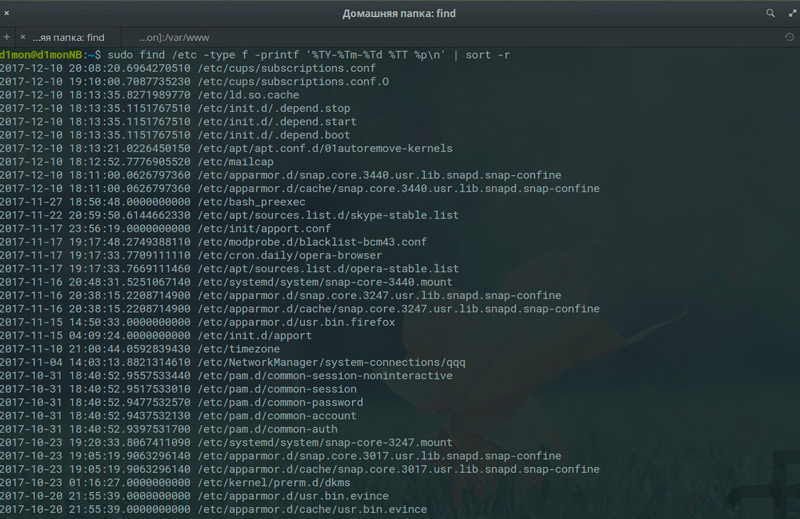
А вот как можно найти файлы, содержащие в имени заданный фрагмент, в текущем каталоге:
Если поиск нужно осуществить без учёта регистра, команду нужно модифицировать:
Не учитывать регистр при поиске по имени:
find . -iname "*.jpg"
Ограничение глубины поиска
Ещё одна достаточно типичная задача – поиск файлов в конкретной папке по заданному имени:
find . –maxdepth01 1 -name "*.html"
Инвертирование шаблона
Мы уже рассматривали аналог команды для поиска строк, не содержащих заданный фрагмент. Точно так же можно поступить и с файлами, не соответствующими заданному шаблону:
find . -not -name "user*"
Поиск по нескольким критериям
Приводим пример командной строки с использованием утилиты find для поиска по двум критериям с использованием оператора not (исключение):
find . -name "user" -not -name "*.html"
В этом случае будут найдены файлы, имя которых включает фрагмент user, но у которых расширение – не html. Вместо оператора исключения можно использовать логическое «И»/»ИЛИ»:
find -name "*.js" -o -name "*.sql"
В этом случае мы получим полный список файлов с обоими расширениями, расположенными в текущей директории.
Поиск в нескольких каталогах
Если нам нужно найти файлы в двух каталогах, просто указываем из через пробел:
find -type f ./test01 ./test02 -name "*.sql"
Поиск скрытых файлов
В Linuxе, как и в Виндовс, существуют скрытые файлы, которые при использовании команды find без специального символа показываться не будут. Этот символ – «тильда», а директива будет иметь следующий вид:
Поиск файлов в Linux по разрешениям
Иногда возникает потребность фильтрации каталога по определённой маске прав. Например, если нам нужно найти файлы с атрибутом 0661, используем команду:
find . -perm 0661
Задача фильтрации файлов с атрибутом «только для чтения» решается так:
find /etc/user -perm /u=r
А вот как будет выглядеть поиск исполняемых файлов в каталоге etc:
find /etc -perm /a=x
Поиск файлов по группах/пользователях
Администратору часто приходится сталкиваться с задачей поиска файлов, являющихся собственностью конкретного пользователя и/или группы. Поиск по юзеру:
find . -user slavko
Для групп пользователей используется другой параметр:
find /var -group devs
Поиск по дате последней модификации
Видимый формат даты файла в ОС Linux как раз и относится к дате его модификации (такой же принцип используется и в Windows). Для формирования списка по дате применяется опция mtime. Допустим, нам нужно отыскать файлы, изменённые два месяца назад:
find /home -mtime 60

В числе атрибутов файла есть и дата его последнего открытия (без внесения изменений). Такие файлы выводятся следующей командой:
find /home -atime 60
Можно также задавать промежуток времени. Для поиска файлов, модифицированных в промежутке от четырёх до двух месяцев назад, используем директиву:
find /home -mtime +60 –mtime -120
А вот как найти свежеизменённые файлы (двухчасовой давности):
find /home -cmin 120
Поиск файлов по размеру
Подозреваете, что кто-то использует диск для размещения фильмов? Ищем файлы размером 1.4 ГБ:
find / -size 1400M
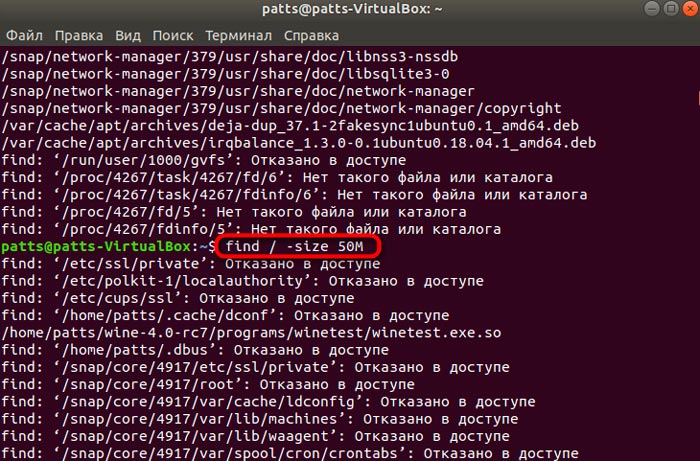
Или используем диапазон:
find / -size +1400M -size -2800M
Поиск пустых файлов/каталогов
Да, не удивляйтесь. Задача наведения порядка на носителе характерна не только для ОС Android. В Linux она решается с помощью такой директивы:
find /var -type f -empty
Пример действий с найденными файлами
В Linux команда find рекурсивно может выполнять определённые действия с теми файлами, поиск которых вы ведёте. Для выполнения файловых команд нужно использовать параметр exec. Так, директива для показа информации обо всех файлах с использованием команды ls будет выглядеть так:
find . -exec ls -l <> \;
А вот как просто можно удалить временные файлы с заданной маской в директории /home/temp:
find /tmp -type f -name “*.html” -exec rm -f <> \;
Безусловно, для новичка использование для поиска командной строки с огромным числом опций покажется несколько вычурным способом, но в Linux это в порядке вещей. А как бы вы решали описанные здесь задачи в Windows? То-то же. В этом аспекте Linux явно впереди.
Читайте также: