Управление браузером через api
API, которые мы рассмотрели до сих пор, встроены в браузер, но не все API таковы. Многие крупные веб-сайты и сервисы, такие как Google Maps, Twitter, Facebook, PayPal и т. д., Предоставляют API-интерфейсы, позволяющие разработчикам использовать свои данные (например, показывать ваш твиттер-поток в вашем блоге) или сервисы (например, отображение пользовательских карт Google на вашем сайте, или использование логина Facebook для входа в систему ваших пользователей). В этой статье рассматривается различие между API-интерфейсами браузера и сторонними API и показано типичное использование последних.
| Необходимые условия: | Основы JavaScript (см. первые шаги, структурные элементы, объекты JavaScript), the основы клиентских API |
|---|---|
| Задача: | Изучить, как работают сторонние API, и как использовать их для улучшения ваших сайтов. |
Что такое сторонние API?
Сторонние API - это API, предоставляемые третьими лицами — как правило, такими компаниями, как Facebook, Twitter, or Google — чтобы вы могли получить доступ к их функциям с помощью JavaScript и использовать его на своём собственном сайте. Как мы показали в нашей вводной статье об API, одним из наиболее очевидных примеров является использование Google Maps APIs для отображения пользовательских карт на ваших страницах.
Давайте снова посмотрим на наш пример карты (см. исходный код на GitHub; см. это в действии), и используем его для иллюстрации того, как сторонние API отличаются от API-интерфейсов браузера.
Примечание: По умолчанию использование сторонних API на вашем сайте позволит им отслеживать файлы cookie своих доменов, устанавливать файлы cookie в исходное состояние, получать заголовки ссылок, определяющие посещаемые страницы, и разрешать им выполнять JavaScript на страницах, на которых они загружаются с теми же разрешениями (например, выполнить запросы AJAX на ваши серверы с теми же кукисами сеанса). Должны быть оценены вопросы регулирования, безопасности и конфиденциальности.
Примечание: Возможно, вы захотите сразу получить все наши примеры кода, в этом случае вы можете просто искать репо для файлов примеров, которые вам нужны в каждом разделе.
Они находятся на сторонних серверах
API браузера встроены в браузер - вы можете получить к ним доступ сразу из JavaScript. Например, API геолокации, доступный в нашем примере, осуществляется с использованием свойства геолокации объекта Navigator , которое возвращает объект Geolocation . Этот пример использует метод getCurrentPosition() этого объекта, для запроса текущего положения устройства:
Сторонние API, с другой стороны, расположены на сторонних серверах. Чтобы получить доступ к ним из JavaScript, вам сначала нужно подключиться к функциям API и сделать его доступным на вашей странице. Обычно это связано с первой ссылкой на библиотеку JavaScript, доступную на сервере через элемент <script> , как показано в нашем примере:
Затем вы можете начать использовать объекты, доступные в этой библиотеке. Например:
Здесь мы создаём новый объект LatLng , используя конструктор google.maps.LatLng() , который содержит широту и долготу местоположения, которое мы хотим показать, полученные из API геолокации. Затем мы создаём объект опций ( myOptions ), содержащий эту и другую информацию, связанную с отображением карты. Наконец, мы фактически создаём карту, используя конструктор google.maps.Map() , который принимает в качестве параметров элемент, на котором мы хотим нарисовать карту, и объект опций.
Это вся информация, которую API Карт Google требует для построения простой карты. Сервер, к которому вы подключаетесь, обрабатывает все сложные вещи, такие как отображение правильных фрагментов карты для отображаемой области и т. д.
Разрешения обрабатываются по-разному
Безопасность API-интерфейсов браузеров, как правило, обрабатывается запросами разрешения, как описано в нашей первой статье. Целью этого является то, что пользователь знает, что происходит на сайтах, которые он посещает, и с меньшей вероятностью может стать жертвой того, кто использует API, злонамеренно.
Сторонние API имеют немного другую систему разрешений - они, как правило, используют ключевые коды, чтобы позволить разработчикам получить доступ к функциям API. Просмотрите URL-адрес библиотеки API Карт Google, с которой мы связались:
Параметр URL, указанный в конце URL-адреса, является ключом разработчика - разработчик приложения должен применять его для получения ключа, а затем включать его в свой код определённым образом, чтобы иметь доступ к функциям API. В случае с Картами Google (и другими API Google) вы подаёте заявку на получение ключа на Google Cloud Platform.
Другие API могут потребовать, чтобы вы включили ключ немного по-другому, но шаблон для большинства из них довольно схож.
Требование к ключу заключается в том, что не каждый может использовать функциональность API без какой-либо подотчётности. Когда разработчик зарегистрировался для ключа, они затем известны поставщику API, и действие может быть предпринято, если они начинают делать что-то вредоносное с помощью API (например, отслеживать местоположение пользователей или пытаться спамить API с множеством запросов для остановки его работы, например). Самое простое действие - просто отменить их привилегии API.
Расширенный пример Карт Google
Теперь когда мы рассмотрели пример API Карт Google и посмотрели, как он работает, добавим ещё несколько функций, чтобы показать, как использовать некоторые другие функции API.
Чтобы начать этот раздел, сделайте себе копию исходного файла Карт Google, в новой папке. Если вы уже клонировали репозиторий примеров, у вас уже есть копия этого файла, которую вы можете найти в папке the javascript/apis/third-party-apis/google-maps.
Затем получите свой собственный ключ разработчика, выполнив следующие шаги:
Примечание: Получение ключей API, связанных с Google, может быть немного затруднительным: в Менеджере API Google Cloud Platform много разных экранов, и рабочий процесс может немного отличаться в зависимости от того, как у вас уже установлена учётная запись. Если у вас возникнут проблемы с этим шагом, мы будем рады помочь — Свяжитесь с нами.
Adding a custom marker
Adding a marker (icon) at a certain point on the map is easy — you just need to create a new marker using the google.maps.Marker() constructor, passing it an options object containing the position to display the marker at (as a LatLng object), and the Map object to display it on.
Add the following just below the var map . line:
Now if you refresh your page, you'll see a nice little marker pop up in the centre of the map. This is cool, but it is not exactly a custom marker — it is using the default marker icon.
To use a custom icon, we need to specify it when we create the marker, using its URL. First of all, add the following line above the previous block you added:
This defines the base URL where all the official Google Maps icons are stored (you could also specify your own icon location if you wished).
The icon location is specified in the icon property of the options object. Update the constructor like so:
Here we specify the icon property value as the iconBase plus the icon filename, to create the complete URL. Now try reloading your example and you'll see a custom marker displayed on your map!
Note: See Customizing a Google Map: Custom Markers for more information.
Note: See Map marker or Icon names to find out what other icons are available, and see what their reference names are. Their file name will be the icon name they display when you click on them, with ".jpg" added on the end.
Displaying a popup when the marker is clicked
Another common use case for Google Maps is displaying more information about a place when its name or marker is clicked (popups are called info windows in the Google Maps API). This is also very simple to achieve, so let's have a look at it.
First of all, you need to specify a JavaScript string containing HTML that will define the content of the popup. This will be injected into the popup by the API and can contain just about any content you want. Add the following line below the google.maps.Marker() constructor definition:
Next, you need to create a new info window object using the google.maps.InfoWindow() constructor. Add the following below your previous line:
There are other properties available (see Info Windows), but here we are just specifying the content property in the options object, which points to the source of the content.
Finally, to get the popup to display when the marker is clicked, we use a simple click event handler. Add the following below the google.maps.InfoWindow() constructor:
Inside the function, we simply invoke the infowindow's open() function, which takes as parameters the map you want to display it on, and the marker you want it to appear next to.
Now try reloading the example, and clicking on the marker!
Controlling what map controls are displayed
Inside the original google.maps.Map() constructor, you'll see the property disableDefaultUI: true specified. This disables all the standard UI controls you usually get on Google Maps.
Try setting its value to false (or just removing the line altogether) then reloading your example, and you'll see the map zoom buttons, scale indicator, etc.
Now undo your last change.
You can show or hide the controls in a more granular fashion by using other properties that specify single UI features. Try adding the following underneath the disableDefaultUI: true (remember to put a comma after disableDefaultUI: true , otherwise you'll get an error):
Now try reloading the example to see the effect these properties have. You can find more options to experiment with at the MapOptions object reference page.
That's it for now — have a look around the Google Maps APIs documentation, and have some more fun playing!
A RESTful API — NYTimes
An approach for using third-party APIs
Below we'll take you through an exercise to show you how to use the NYTimes API, which also provides a more general set of steps to follow that you can use as an approach for working with new APIs.
Find the documentation
Get a developer key
Let's request a key for the "Article Search API" — fill in the form, selecting this as the API you want to use.
Next, wait a few minutes, then get the key from your email.
Now, to start the example off, make copies of nytimes_start.html and nytimes.css in a new directory on your computer. If you've already cloned the examples repository, you'll already have a copy of these files, which you can find in the javascript/apis/third-party-apis/nytimes directory. Initially the <script> element contains a number of variables needed for the setup of the example; below we'll fill in the required functionality.
The app will end up allowing you to type in a search term and optional start and end dates, which it will then use to query the Article Search API and display the search results.

Connect the API to your app
First, you'll need to make a connection between the API, and your app. This is usually done either by connecting to the API's JavaScript (as we did in the Google Maps API), or by making requests to the correct URL(s).
In the case of this API, you need to include the API key as a get parameter every time you request data from it.
Find the following line:
Replace INSERT-YOUR-API-KEY-HERE with the actual API key you got in the previous section.
Add the following line to your JavaScript, below the " // Event listeners to control the functionality " comment. This runs a function called fetchResults() when the form is submitted (the button is pressed).
Now add the submitSearch() and fetchResults() function definitions, below the previous line:
submitSearch() sets the page number back to 0 to begin with, then calls fetchResults() . This first calls preventDefault() on the event object, to stop the form actually submitting (which would break the example). Next, we use some string manipulation to assemble the full URL that we will make the request to. We start off by assembling the parts we deem as mandatory for this demo:
- The base URL (taken from the baseURL variable).
- The API key, which has to be specified in the api-key URL parameter (the value is taken from the key variable).
- The page number, which has to be specified in the page URL parameter (the value is taken from the pageNumber variable).
- The search term, which has to be specified in the q URL parameter (the value is taken from the value of the searchTerm text <input> ).
- The document type to return results for, as specified in an expression passed in via the fq URL parameter. In this case, we just want to return articles.
Next, we use a couple of if() statements to check whether the startDate and endDate <input> s have had values filled in on them. If they do, we append their values to the URL, specified in begin_date and end_date URL parameters respectively.
So, a complete URL would end up looking something like this:
Note: You can find more details of what URL parameters can be included in the Article Search API reference.
Note: The example has rudimentary form data validation — the search term field has to be filled in before the form can be submitted (achieved using the required attribute), and the date fields have pattern attributes specified, which means they won't submit unless their values consist of 8 numbers ( pattern="5" ). See Form data validation for more details on how these work.
Requesting data from the API
Now we've constructed our URL, let's make a request to it. We'll do this using the Fetch API.
Add the following code block inside the fetchResults() function, just above the closing curly brace:
Here we run the request by passing our url variable to fetch() , convert the response body to JSON using the json() function, then pass the resulting JSON to the displayResults() function so the data can be displayed in our UI.
Displaying the data
OK, let's look at how we'll display the data. Add the following function below your fetchResults() function.
There's a lot of code here; let's explain it step by step:
- The while loop is a common pattern used to delete all of the contents of a DOM element, in this case, the <section> element. We keep checking to see if the <section> has a first child, and if it does, we remove the first child. The loop ends when <section> no longer has any children.
- Next, we set the articles variable to equal json.response.docs — this is the array holding all the objects that represent the articles returned by the search. This is done purely to make the following code a bit simpler.
- The first if() block checks to see if 10 articles are returned (the API returns up to 10 articles at a time.) If so, we display the <nav> that contains the Previous 10/Next 10 pagination buttons. If less than 10 articles are returned, they will all fit on one page, so we don't need to show the pagination buttons. We will wire up the pagination functionality in the next section.
- The next if() block checks to see if no articles are returned. If so, we don't try to display any — we just create a <p> containing the text "No results returned." and insert it into the <section> .
- If some articles are returned, we, first of all, create all the elements that we want to use to display each news story, insert the right contents into each one, and then insert them into the DOM at the appropriate places. To work out which properties in the article objects contained the right data to show, we consulted the Article Search API reference. Most of these operations are fairly obvious, but a few are worth calling out:
- We used a for loop ( for(var j = 0; j < current.keywords.length; j++) < . >) to loop through all the keywords associated with each article, and insert each one inside its own <span> , inside a <p> . This was done to make it easy to style each one.
- We used an if() block ( if(current.multimedia.length > 0) < . >) to check whether each article actually has any images associated with it (some stories don't.) We display the first image only if it actually exists (otherwise an error would be thrown).
- We gave our <div> element a class of "clearfix", so we can easily apply clearing to it (this technique is needed at the time of writing to stop floated layouts from breaking.)
If you try the example now, it should work, although the pagination buttons won't work yet.
Wiring up the pagination buttons
To make the pagination buttons work, we will increment (or decrement) the value of the pageNumber variable, and then re-rerun the fetch request with the new value included in the page URL parameter. This works because the NYTimes API only returns 10 results at a time — if more than 10 results are available, it will return the first 10 (0-9) if the page URL parameter is set to 0 (or not included at all — 0 is the default value), the next 10 (10-19) if it is set to 1, and so on.
This allows us to easily write a simplistic pagination function.
Below the existing addEventListener() call, add these two new ones, which cause the nextPage() and previousPage() functions to be invoked when the relevant buttons are clicked:
Below your previous addition, let's define the two functions — add this code now:
The first function is simple — we increment the pageNumber variable, then run the fetchResults() function again to display the next page's results.
The second function works nearly exactly the same way in reverse, but we also have to take the extra step of checking that pageNumber is not already zero before decrementing it — if the fetch request runs with a minus page URL parameter, it could cause errors. If the pageNumber is already 0, we simply return out of the function, to avoid wasting processing power (If we are already at the first page, we don't need to load the same results again).
YouTube example
We also built another example for you to study and learn from — see our YouTube video search example. This uses two related APIs:
- The YouTube Data API to search for YouTube videos and return results.
- The YouTube IFrame Player API to display the returned video examples inside IFrame video players so you can watch them.
![]()
We are not going to say too much more about this example in the article — the source code has detailed comments inserted inside it to explain how it works.
Summary
This article has given you a useful introduction to using third party APIs to add functionality to your websites.
От автора: статья дает обзор концепций, технологий и техник программирования, связанных с автоматическим запуском тестов под управлением WebDriverJS на Windows 10 и Microsoft Edge. Ручное прокликивание разных браузеров, пока они запускают ваш код, локально или удаленно – быстрый способ проверить код. Так можно визуально проверить, что все работает ровно так, как вы предполагали с точки зрения макета и функциональности. Тем не менее, это не решение для тестирования полного кода сайта во всех браузерах и на всех типах устройств, доступных клиентов. Здесь нам поможет автоматизированное тестирование WebDriver API.
Автоматизированное веб-тестирование, возглавляемое проектом Selenium, представляет собой набор инструментов для авторизации, управления и запуска тестов в браузерах на разных платформах.
WebDriverJS API Link
WebDriver API – стандарт, который абстрагирует специфические привязки устройств/браузеров от разработчика, чтобы написанные вами тесты (на выбранном вами языке) можно было один раз написать и запускать в нескольких разных браузерах через WebDriver. В некоторые браузеры уже встроены возможности WebDriver, для других необходимо загружать исполняемый файл для пары браузер/ОС.
![Автоматизированное браузерное тестирование с помощью WebDriver API]()
Управление браузером через WebDriver API
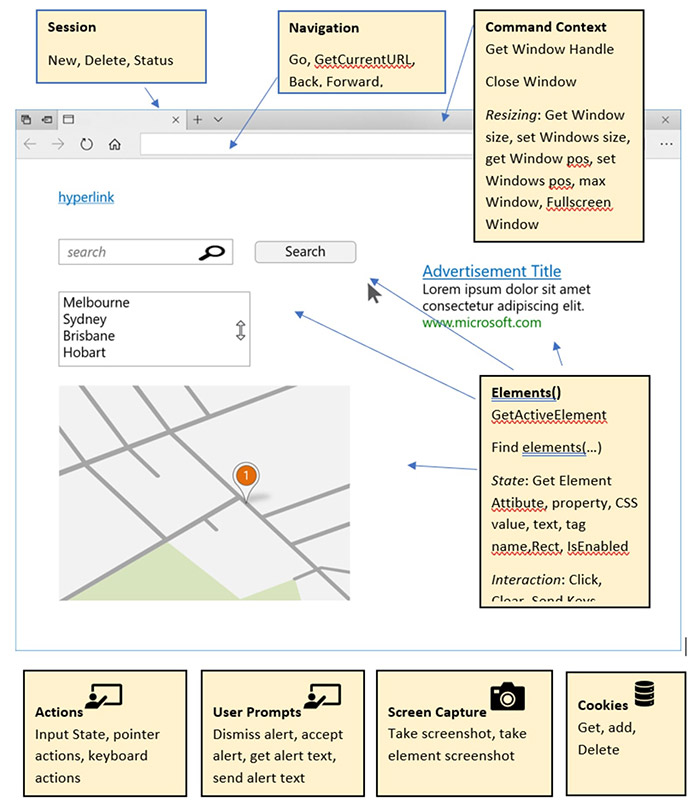
В спецификации WebDriver на W3C задокументированы API, доступные разработчикам для программного управления браузером. На рисунке ниже показан пример страницы с основными коллекциями WebDriver и API, с помощью которых можно получать/устанавливать свойства браузера.
![]()
JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
![Автоматизированное браузерное тестирование с помощью WebDriver API]()
Написание тестов
У вас есть выбор из поддерживаемых языков в WebDriver. Языки, поддерживаемые главным проектом Selenium/WebDriverJS:
JavaScript (via Node)
Тесты могут быть разные: от проверки макета страницы, возвращаемых с сервера значений, ожидаемого поведения при взаимодействии до проверки рабочего потока (например, проверка корректности работы корзины).
Позже мы сможем продемонстрировать запуск тестов для React примера и примеров Backbone.js и Vue.js простой сменой URL.
Для демонстрации мы напишем тесты на JS, запускаемые на узле, которые:
Добавят элементы to-do и проверят, что введенный элементы создались.
Изменят элементы с помощью двойного клика, нажатия клавиши backspace и ввода дополнительного текста.
Удалят элемент через API мыши.
Пометят элемент списка, как выполненный.
Настройка базового окружения для автоматизированного тестирования
Начнем с настройки машины на Windows 10 под запуск WebDriver через JS. Вызовы WebDriver с машины почти всегда будут асинхронные. Чтобы код было легче читать, мы использовали ES2016 async/await, а не Promises или колбеки.
Вам понадобится install node.js новее v7.6 или Babel для кросскомпиляции для поддержки функции async/await. Редактирование и отладку кода будем выполнять в Visual Studio Code.
WebDriverJS для Microsoft Edge
У каждого браузера будет бинарный файл, который должен будет храниться локально для взаимодействия с браузером. Этот бинарный файл будет вызываться вашим кодом через Selenium WebDriver API. Последние загрузки и документацию для Microsoft Edge WebDriver можно найти по ссылке.
Версия Edge, под которой вы хотите запускать тесты, должна совпадать с версией MicrosoftWebDriver.exe. Мы будем использовать стабильную версию Edge (16.16299) с соответствующим файлом MicrosoftWebDriver.exe версии 5.16299.
Поместите MicrosoftWebDriver.exe в папку, из которой будет запускаться тест. Если запустить бинарный файл, откроется окно консоли с URL и портом, через который WebDriverJS будет обрабатывать посылаемые запросы.
WebDriverJS для других браузеров
WebDriverJS легко может запускать другой браузер, если установить конфиг переменную и скачать подходящий бинарный драйвер для браузера. Найти все можно здесь:
Apple Safari: Вместе с Safari 10+
Microsoft Internet Explorer: IEDriver для Selenium project
Selenium WebDriverJS для JavaScript
Чтобы взаимодействовать с только что скачанным через JS бинарным файлом, необходимо установить библиотеку автоматизации Selenium WebDriver. Ее можно легко установить как node пакет:
Начнём с рассмотрения того что представляют собой API на высоком уровне и выясним, как они работают, как их использовать в своих программах и как они структурированы. Также рассмотрим основные виды API и их применение.
Необходимые знания: Базовая компьютерная грамотность, понимание основ HTML и CSS, основы JavaScript (см. первые шаги, building blocks, объекты JavaScript). Цель: Познакомиться с API, выяснить что они могут делать и как их использовать. Что такое API?
Интерфейс прикладного программирования (Application Programming Interfaces, APIs) - это готовые конструкции языка программирования, позволяющие разработчику строить сложную функциональность с меньшими усилиями. Они "скрывают" более сложный код от программиста, обеспечивая простоту использования.
Для лучшего понимания рассмотрим аналогию с домашними электросетями. Когда вы хотите использовать какой-то электроприбор, вы просто подключаете его к розетке, и всё работает. Вы не пытаетесь подключить провода напрямую к источнику тока — делать это бесполезно и, если вы не электрик, сложно и опасно.
![]()
Точно также, если мы хотим, например, программировать 3D графику, гораздо легче сделать это с использованием API, написанных на языках высокого уровня, таких как JavaScript или Python.
Note: Смотрите также API в словаре.
API клиентской части JavaScript
Для JavaScript на стороне клиента, в частности, существует множество API. Они не являются частью языка, а построены с помощью встроенных функций JavaScript для того, чтобы увеличить ваши возможности при написании кода. Их можно разделить на две категории:
- API браузера встроены в веб-браузер и способны использовать данные браузера и компьютерной среды для осуществления более сложных действий с этими данными. К примеру, API Геолокации (Geolocation API) предоставляет простые в использовании конструкции JavaScript для работы с данными местоположения, так что вы сможете, допустим, отметить своё расположение на карте Google Map. На самом деле, в браузере выполняется сложный низкоуровневый код (например, на C++) для подключения к устройству GPS (или любому другому устройству геолокации), получения данных и передачи их браузеру для обработки вашей программой, но, как было сказано выше, эти детали скрыты благодаря API.
- Сторонние API не встроены в браузер по умолчанию. Такие API и информацию о них обычно необходимо искать в интернете. Например, Twitter API позволяет размещать последние твиты (tweets) на вашем веб-сайте. В данном API определён набор конструкций, осуществляющих запросы к сервисам Twitter и возвращающих определённые данные.
![]()
Взаимодействие JavaScript, API и других средств JavaScript
Итак, выше мы поговорили о том, что такое JavaScript API клиентской части и как они связаны с языком JavaScript. Давайте теперь тезисно запишем основные понятия и определим назначение других инструментов JavaScript:
- JavaScript — Язык программирования сценариев высокого уровня, встроенный в браузер, позволяющий создавать функциональность веб-страниц/приложений. Отметим, что JavaScript также доступен на других программных платформах, таких как Node. Но пока не будем останавливаться на этом.
- API браузера (Browser APIs) — конструкции, встроенные в браузер, построенные на основе языка JavaScript, предназначенные для облегчения разработки функциональности.
- Сторонние API (Third party APIs) — конструкции, встроенные в сторонние платформы (такие как Twitter, Facebook) позволяющие вам использовать часть функциональности этих платформ в своих собственных веб-страницах/приложениях (например, показывать последние Твиты на вашей странице).
- Библиотеки JavaScript — Обычно один или несколько файлов, содержащих пользовательские (custom) функции. Такие файлы можно прикрепить к веб-странице, чтобы ускорить или предоставить инструменты для написания общего функциональности. Примеры: jQuery, Mootools и React.
- JavaScript фреймворки (frameworks) — Следующий шаг в развитии разработки после библиотек. Фреймворки JavaScript (такие как Angular и Ember) стремятся к тому, чтобы быть набором HTML, CSS, JavaScript и других технологий, после установки которого можно "писать" веб-приложение с нуля. Главное различие между фреймворками и библиотеками - "Обратное направление управления" ( “Inversion of Control” ). Вызов метода из библиотеки происходит по требованию разработчика. При использовании фреймворка - наоборот, фреймворк производит вызов кода разработчика.
На что способны API?
Широкое разнообразие API в современных браузерах позволяет наделить ваше приложение большими возможностями. Достаточно посмотреть список на странице MDN APIs index page.
Распространённые API браузера
В частности, к наиболее часто используемым категориям API (и которые мы рассмотрим далее в этом модуле) относятся :
Распространённые сторонние API
Существует множество сторонних API; некоторые из наиболее популярных, которые вы рано или поздно будете использовать, включают:
-
для добавления такой функциональности, как показ последних твитов на сайте. для работы с картами на веб-странице (интересно, что Google Maps также использует этот API). Теперь это целый набор API, который может справляться с широким спектром задач, как свидетельствует Google Maps API Picker. позволяет использовать различные части платформы Facebook в вашем приложении, предоставляя, например, возможность входа в систему с логином Facebook, оплаты покупок в приложении, демонстрация целевой рекламы и т.д. , предоставляющий возможность встраивать видео с YouTube на вашем сайте, производить поиск, создавать плейлисты и т.д. - фреймворк для встраивания функциональности голосовой и видео связи в вашем приложении, отправки SMS/MMS из приложения и т.д.
Note: вы можете найти информацию о гораздо большем количестве сторонних API в Каталоге Web API.
Как работает API?
Работа разных JavaScript API немного отличается, но, в основном, у них похожие функции и принцип работы.
Они основаны на объектах
Взаимодействие с API в коде происходит через один или больше объектов JavaScript, которые служат контейнерами для информации, с которой работает API (содержится в свойствах объекта), и реализуют функциональность, которую предоставляет API (содержится в методах объекта).
Note: Если вам ещё не известно как работают объекты, советуем вернуться назад и изучить модуль Основы объектов JavaScript прежде чем продолжать.
Вернёмся к примеру с API Геолокации — очень простой API, состоящий из нескольких простых объектов:
-
, содержит три метода для контроля и получения геоданных. , предоставляет данные о местоположении устройства в заданный момент времени — содержит Coordinates - объект, хранящий координаты и отметку о текущем времени. , содержит много полезной информации о расположении устройства, включая широту и долготу, высоту, скорость и направление движения и т.д.
Так как же эти объекты взаимодействуют? Если вы посмотрите на наш пример maps-example.html (see it live also), вы увидите следующий код:
Note: Когда вы впервые загрузите приведённый выше пример, появится диалоговое окно, запрашивающее разрешение на передачу данных о местонахождении этому приложению (см. раздел У них есть дополнительные средства безопасности там, где это необходимо далее в этой статье). Вам нужно разрешить передачу данных, чтобы иметь возможность отметить своё местоположение на карте. Если вы всё ещё не видите карту, возможно, требуется установить разрешения вручную; это делается разными способами в зависимости от вашего браузера; например, в Firefox перейдите > Tools > Page Info > Permissions, затем измените настройки Share Location; в Chrome перейдите Settings > Privacy > Show advanced settings > Content settings и измените настройки Location.
Во-первых, мы хотим использовать метод Geolocation.getCurrentPosition() , чтобы получить текущее положение нашего устройства. Доступ к объекту браузера Geolocation производится с помощью свойства Navigator.geolocation , так что мы начнём с
Это эквивалентно следующему коду
Но мы можем использовать точки, чтобы связать доступ к свойствам/методам объекта в одно выражение, уменьшая количество строк в программе.
Метод Geolocation.getCurrentPosition() имеет один обязательный параметр - анонимную функцию, которая запустится, когда текущее положение устройства будет успешно считано. Сама эта функция принимает параметр, являющийся объектом Position (en-US) , представляющим данные о текущем местоположении.
Note: Функция, которая передаётся другой функции в качестве параметра, называется колбэк-функцией (callback function).
Такой подход, при котором функция вызывается только тогда, когда операция была завершена, очень распространён в JavaScript API — убедиться, что операция была завершена прежде, чем пытаться использовать данные, которые она возвращает, в другой операции. Такие операции также называют асинхронными операциями (asynchronous operations). Учитывая, что получение данных геолокации производится из внешнего устройства (GPS-устройства или другого устройства геолокации), мы не можем быть уверены, что операция считывания будет завершена вовремя и мы сможем незамедлительно использовать возвращаемые ею данные. Поэтому такой код не будет работать:
Если первая строка ещё не вернула результат, вторая вызовет ошибку из-за того, что данные геолокации ещё не стали доступны. По этой причине, API, использующие асинхронные операции, разрабатываются с использованием callback function, или более современной системы промисов, которая появилась в ECMAScript 6 и широко используются в новых API.
Мы совмещаем API Геолокации со сторонним API - Google Maps API, который используем для того, чтобы отметить расположение, возвращаемое getCurrentPosition() , на Google Map. Чтобы Google Maps API стал доступен на нашей странице, мы включаем его в HTML документ:
Чтобы использовать этот API, во-первых создадим объект LatLng с помощью конструктора google.maps.LatLng() , принимающим данные геолокации Coordinates.latitude (en-US) и Coordinates.longitude (en-US) :
Этот объект сам является значением свойства center объекта настроек (options), который мы назвали myOptions . Затем мы создаём экземпляр объекта, представляющего нашу карту, вызывая конструктор google.maps.Map() и передавая ему два параметра — ссылку на элемент <div> , на котором мы хотим отрисовывать карту (с ID map_canvas ), и объект настроек (options), который мы определили выше.
Когда это сделано, наша карта отрисовывается.
Последний блок кода демонстрирует два распространённых подхода, которые вы увидите во многих API:
- Во-первых, объекты API обычно содержат конструкторы, которые вызываются для создания экземпляров объектов, используемых при написании программы.
- Во-вторых, объекты API зачастую имеют несколько вариантов (options), которые можно настроить и получить именно ту среду для разработки, которую вы хотите. API конструкторы обычно принимают объекты вариантов (options) в качестве параметров, с помощью которых и происходит настройка.
Note: Не отчаивайтесь, если вы что-то не поняли из этого примера сразу. Мы рассмотрим использование сторонних API более подробно в следующих статьях.
У них узнаваемые точки входа
При использовании API убедитесь, что вы знаете где точка входа для API. В API Геолокации это довольно просто — это свойство Navigator.geolocation , возвращающее объект браузера Geolocation , внутри которого доступны все полезные методы геолокации.
Найти точку входа Document Object Model (DOM) API ещё проще — при применении этого API используется объект Document , или экземпляр элемента HTML, с которым вы хотите каким-либо образом взаимодействовать, к примеру:
Точки входа других API немного сложнее, часто подразумевается создание особого контекста, в котором будет написан код API. Например, объект контекста Canvas API создаётся получением ссылки на элемент <canvas> , на котором вы хотите рисовать, а затем необходимо вызвать метод HTMLCanvasElement.getContext() :
Всё, что мы хотим сделать с canvas после этого, достигается вызовом свойств и методов объекта содержимого (content) (который является экземпляром CanvasRenderingContext2D ), например:
Note: вы можете увидеть этот код в действии в нашем bouncing balls demo (see it running live also).
Они используют события для управления состоянием
Мы уже обсуждали события ранее в этом курсе, в нашей статье Introduction to events — в этой статье детально описываются события на стороне клиента и их применение. Если вы ещё не знакомы с тем, как работают события клиентской части, рекомендуем прочитать эту статью прежде, чем продолжить.
Следующий код содержит простой пример использования событий:
Note: вы можете увидеть этот код в действии в примере ajax.html (see it live also).
Затем функция-обработчик onload определяет наши действия по обработке ответа сервера. Нам известно, что ответ успешно возвращён и доступен после наступления события load (и если не произойдёт ошибка), так что мы сохраняем ответ, содержащий возвращённый сервером объект JSON в переменной superHeroes , которую затем передаём двум различным функциям для дальнейшей обработки.
У них есть дополнительные средства безопасности там, где это необходимо
К тому же, некоторые WebAPI запрашивают разрешение от пользователя, как только к ним происходит вызов в коде. В качестве примера, вы, возможно, встречали такое диалоговое окно при загрузке нашего примера Geolocation ранее:
![]()
Notifications API запрашивает разрешение подобным образом:
![]()
Запросы разрешений необходимы для обеспечения безопасности пользователей — не будь их, сайты могли бы скрытно отследить ваше местоположение, не создавая множество надоедливых уведомлений.
Итоги
На данном этапе, у вас должно сформироваться представление о том, что такое API, как они работают и как вы можете применить их в своём JavaScript-коде. Вам наверняка не терпится начать делать по-настоящему интересные вещи с конкретными API, так вперёд! В следующий раз мы рассмотрим работу с документом с помощью Document Object Model (DOM).
Несколько инструментов могут управлять веб-браузером так, как это сделал бы реальный пользователь, например, переходя на разные страницы, взаимодействуя с элементами страницы и захватывая некоторые данные. Этот процесс называется Автоматизация веб-браузера . То, что вы можете сделать с автоматизацией веб-браузера, полностью зависит от вашего воображения и потребностей.
Некоторые из распространенных случаев использования автоматизации веб-браузера могут быть:
- Автоматизация ручных тестов в веб-приложении
- Автоматизация повторяющихся задач, таких как удаление информации с веб-сайтов
- Заполнение HTML-форм, выполнение некоторых административных заданий и т. Д
Что такое Селен?
Selenium IDE-это чисто инструмент для воспроизведения записей, который поставляется в качестве плагина Firefox и расширения Chrome. Selenium RC был устаревшим инструментом, который сейчас обесценился. Selenium WebDriver-это новейший и широко используемый инструмент.
Примечание : Термины Selenium , Selenium WebDriver или просто WebDriver используются взаимозаменяемо для обозначения Selenium WebDriver.
Здесь важно отметить, что Selenium создан только для взаимодействия с веб-компонентами. Поэтому, если вы столкнетесь с какими-либо настольными компонентами, такими как диалоговое окно Windows, Selenium сам по себе не сможет взаимодействовать с ними. Существуют и другие типы инструментов, такие как AutoIt или Automa, которые могут быть интегрированы с Selenium для этих целей.
Зачем использовать Селен?
В этом уроке мы узнаем, как использовать привязки Java Selenium WebDriver . Мы также рассмотрим API WebDriver .
Успех Selenium также можно объяснить тем фактом, что спецификации WebDriver стали рекомендацией W3C для браузеров.
Предпосылки:
- Среда Java и ваша любимая среда разработки Java
WebDriver обеспечивает привязку для всех популярных языков, как описано в предыдущем разделе. Поскольку мы используем среду Java, нам необходимо загрузить и включить привязки Java в путь сборки. Кроме того, почти каждый популярный браузер предоставляет драйвер, который можно использовать с Selenium для управления этим браузером.
В этом уроке мы будем управлять Google Chrome.
Веб-драйвер
Прежде чем двигаться дальше, полезно понять несколько концепций, которые приводят в замешательство новичков. WebDriver не является классом , это интерфейс .
Все зависящие от браузера драйверы, такие как ChromeDriver , FirefoxDriver , InternetExplorerDriver , являются Java классами , которые реализуют интерфейс WebDriver|/. Эта информация важна, потому что, если вы хотите запустить свою программу в другом браузере, вам не нужно менять кучу кода, чтобы он работал, вам просто нужно поменять WebDriver для любого браузера, который вы хотите.
Как мы видим, драйвер содержит ссылку на ChromeDriver и, следовательно, может использоваться для управления браузером. Когда будет выполнено приведенное выше утверждение, вы должны увидеть, как в вашей системе откроется новое окно браузера. Но браузер еще не открыл ни одного веб-сайта. Нам нужно дать указание браузеру сделать это.
Примечание : Для использования другого WebDriver вам необходимо указать путь к драйверу в файловой системе, а затем создать его экземпляр. Например, если вы хотите использовать IE, то вот что вам нужно сделать:
Переход на Веб-сайт
Как упоминалось выше, сначала нам нужно перейти на ваш целевой веб-сайт. Для этого мы просто отправляем запрос GET на URL-адрес веб-сайта:
ВебЭлемент
Первым шагом в автоматизации веб-браузера является поиск элементов на веб-странице, с которыми мы хотим взаимодействовать, таких как кнопка, ввод, выпадающий список и т.д.
Селеновым представлением таких HTML-элементов является Веб-элемент . Как и WebDriver , WebElement также является интерфейсом Java. Как только мы получим WebElement , Мы сможем выполнить с ними любую операцию, которую может выполнить конечный пользователь, например, щелкнуть, ввести, выбрать и т. Д.
Очевидно, что попытка выполнить недопустимые операции, например, ввести текст в элемент кнопки, приведет к исключению.
Мы можем использовать HTML-атрибуты элемента, такие как идентификатор , класс и имя , чтобы найти элемент. Если таких атрибутов нет, мы можем использовать некоторые продвинутые методы определения местоположения, такие как CSS-селекторы и XPath .
Как мы видим, элемент имеет <вход> тег и несколько атрибутов, таких как идентификатор , класс и т.д.
WebDriver поддерживает 8 различных локаторов для поиска элементов:
- идентификатор
- Имя класса
- имя
- тагНаме
- Текст ссылки
- Частичная ссылка на текст
- cssSelector*
- xpath
Давайте рассмотрим их все по очереди, автоматизировав различные элементы на нашем целевом веб-сайте.
Определение местоположения элементов с помощью идентификатора
Если мы проверим поле ввода информационного бюллетеня на нашем целевом веб-сайте, мы сможем обнаружить, что у него есть атрибут id :
Мы можем найти этот элемент с помощью идентификатора локатора:
Поиск элементов по имени класса
Если мы проверим то же поле ввода, мы увидим, что оно также имеет атрибут class .
Мы можем найти этот элемент, используя имя класса локатор:
Определение местоположения элементов по имени
Для этого примера давайте представим выпадающий список, в котором пользователь должен выбрать свой возрастной диапазон. В раскрывающемся списке есть атрибут name , который мы можем найти:
Мы можем найти этот элемент, используя имя локатор:
Определение местоположения элементов с помощью xpath
Однако иногда эти подходы устаревают, так как существует несколько элементов с одним и тем же атрибутом:
В этих случаях мы можем использовать Локаторы XPath . XPath-это очень мощные локаторы, и они сами по себе являются полной темой. Следующий пример может дать вам представление о том, как создать XPath для приведенных выше фрагментов HTML:
Поиск элементов с помощью селектора css
Опять же, давайте представим список флажков, в которых пользователь выбирает предпочитаемый язык программирования:
Технически, для этого фрагмента HTML мы можем легко использовать имя локатор, поскольку они имеют разные значения. Однако в этом примере мы будем использовать селекторы css для поиска этого элемента, который широко используется во интерфейсе с такими библиотеками, как jQuery.
Следующий пример может дать вам представление о том, как создавать селекторы CSS для предыдущего фрагмента HTML:
Очевидно, это очень похоже на подход XPath.
Поиск элементов с помощью linkText
Мы можем найти ссылку по ее тексту:
Поиск элементов с помощью partialLinkText
В этих случаях мы можем использовать partialLinkText локатор:
Определение местоположения элементов с помощью tagName
Мы также можем найти элемент, используя его имя тега, например , , <ввод> , <выбор> и т. Д. Вы должны использовать этот локатор с осторожностью. Поскольку может быть несколько элементов с одинаковым именем тега, и команда всегда возвращает первый соответствующий элемент на странице:
Этот способ поиска элемента обычно более полезен, когда вы вызываете метод findElement для другого элемента, а не для всего HTML-документа. Это сужает ваш поиск и позволяет находить элементы с помощью простых локаторов.
Взаимодействие с элементами
Щелчок по элементам
Мы выполняем операцию щелчка с помощью метода click () . Мы можем использовать это на любом веб-элементе , если он доступен для кликабельности. Если нет, это вызовет исключение.
В этом случае давайте перейдем по ссылке домашняя страница :
Поскольку это фактически выполняет щелчок по странице, ваш веб-браузер затем перейдет по ссылке, которая была нажата программным способом.
Ввод Текста
Давайте введем некоторый текст в поле ввода Электронная почта :
Выбор Переключателей
Поскольку переключатели просто нажимаются, мы используем метод click() для выбора одной из них:
Установка Флажков
То же самое касается выбора флажков, хотя в этом случае мы можем выбрать несколько флажков. Если мы выберем другой переключатель, будет выбран предыдущий:
Выбор элементов из выпадающего списка
Чтобы выбрать элемент из выпадающего списка, нам нужно будет сделать две вещи:
Во-первых, нам нужно создать экземпляр Выбрать и передать ему элемент со страницы:
Git Essentials
Ознакомьтесь с этим практическим руководством по изучению Git, содержащим лучшие практики и принятые в отрасли стандарты. Прекратите гуглить команды Git и на самом деле изучите это!
Затем мы можем выбрать элемент, используя его:
Отображаемый текст :
Значение (атрибут значение ):
Индекс (начинается с 0):
Если приложение поддерживает множественный выбор, мы можем вызвать один или несколько из этих методов несколько раз, чтобы выбрать различные элементы.
Чтобы проверить, позволяет ли приложение выполнять несколько вариантов выбора, мы можем запустить:
Есть много других полезных операций, которые мы можем выполнить в раскрывающемся списке:
Мы также можем сделать это с помощью Select :
Получение Значений Атрибутов
Чтобы получить значение определенного атрибута в элементе:
Установка Значений Атрибутов
Мы также можем задать значение определенного атрибута в элементе. Это может быть полезно там, где мы хотим включить или отключить какой-либо элемент:
Взаимодействие с мышью и клавиатурой
API WebDriver предоставил класс Действия для взаимодействия с мышью и клавиатурой.
Во-первых, нам нужно создать экземпляр Действия и передать ему экземпляр WebDriver :
Перемещение мыши
Иногда нам может потребоваться навести курсор на пункт меню, в котором отображается пункт подменю:
Перетаскивание
Перетаскивание элемента поверх другого элемента:
Перетаскивание элемента на несколько пикселей (например, 200 пикселей по горизонтали и 0 пикселей по вертикали):
Нажатие Клавиш
Удерживайте определенную клавишу при вводе некоторого текста, например, клавиши Shift :
Выполните такие операции, как Ctrl+a , Ctrl+c , Ctrl+v и ВКЛАДКА :
Взаимодействие с браузером
Получение источника страницы
Скорее всего, вы будете использовать это для очистки веб-страниц:
Получение заголовка страницы
Максимизация браузера
Увольнение водителя
Важно выйти из драйвера в конце программы:
Примечание : API WebDriver также предоставляет метод close () , и иногда это сбивает с толку новичков. Метод close() просто закрывает браузер и может быть снова открыт в любое время. Это не уничтожает объект WebDriver . Метод quit() более подходит, когда вам больше не нужен браузер.
Делать Скриншоты
Во-первых, нам нужно привести WebDriver к TakesScreenshot типу, который является интерфейсом . Далее мы можем вызвать getScreenshotAs() и передать OutputType.ФАЙЛ .
Наконец, мы можем скопировать файл в локальную файловую систему с соответствующими расширениями, такими как *.jpg,*. png и т.д.
Выполнение JavaScript
Мы также можем ввести или выполнить любой допустимый фрагмент JavaScript через Selenium WebDriver. Это очень полезно, так как позволяет вам делать многие вещи, которые не встроены непосредственно в Селен.
Во-первых, нам нужно привести WebDriver к типу JavascriptExecutor :
Может быть несколько вариантов использования, связанных с JavascriptExecutor :
Мы также можем сначала найти элемент с помощью локаторов WebDriver и передать этот элемент в execute Script() в качестве второго аргумента. Это более естественный способ использования JavascriptExecutor :
Чтобы задать значение поля ввода:
- Прокрутка элемента, чтобы перенести его в окно просмотра :
- Изменение страницы (добавление или удаление некоторых атрибутов элемента):
Доступ к файлам Cookie
Поскольку многие веб-сайты используют файлы cookie для хранения состояния пользователя или других данных, вам может быть полезно получить к ним программный доступ с помощью Selenium. Некоторые распространенные операции с файлами cookie описаны ниже.
Получить все файлы cookie:
Получите конкретный файл cookie:
Добавьте файл cookie:
Удалите файл cookie:
Вывод
Мы рассмотрели все основные функции Selenium WebDriver, которые могут потребоваться при автоматизации веб-браузера. Selenium WebDriver имеет очень обширный API и охватывает все, что выходит за рамки этого руководства.
Читайте также: