
Сайт с информацией о себе на основе запросов в браузере
Остановимся более подробно на методах запроса.
Метод GET
GET — используется для запроса содержимого указанного ресурса. Это с его помощью браузер получает HTML код конкретной страницы и все ее объекты (изображения, CSS и т.п). Тело такого запроса является пустым. Ответ может кэшироваться. GET запрос может передать параметры на сервер для уточнения запрашиваемых данных. Параметры запроса содержаться в адресе запроса, отделяются от URI знаком «?», пары параметр-значение разделяются символом « & ». Подобный адрес запроса может выглядеть так:
Кроме обычных GET запросов, есть еще условные и частичные.
Условный GET
Частичный GET
Частичный GET запрос (partial GET) предназначен для уменьшения ненужной загрузки сети. Позволяет собирать объект из частей без передачи данных уже имеющихся на стороне клиента и потому запрашивает передачу только части объекта. Используется заголовок Range.
Метод POST
Заметка
URI и версия протокола
URI — это последовательность символов (строка), идентифицирующая абстрактный или физический ресурс.
Каждый запрос имеет как минимум свой заголовок, который сообщить серверу информацию о своей конфигурации и данные о форматах документов, которые он может принимать. Заголовок представлен в текстовом виде. Например:
Такой заголовок имеет вес равный 956b.
Только первые две части в особо тяжелых случаях могут весить 0.5 килобайт.
Это все к тому, что твой дополнительный однопиксельный gif на веб странице весом всего лишь 43 байта может вылиться в 130 с лишним мегабайт трафика при всего лишь 100 000 посетителях. Это еще одна причина для чего лучше сокращать число отдельных запросов к серверу.
Заметка
Вес передаваемых данных не влияет на размер заголовка.
Добраться до этих заголовков можно только с помощью настроек сервера и/или серверными скриптами.
Пока не нашел информации по этой части запроса, которая была бы полезной HTML кодеру, поэтому в этой статье рассматривать ее не буду.
5. Узнайте список всех приложений и расширений, которые имеют доступ к вашему аккаунту
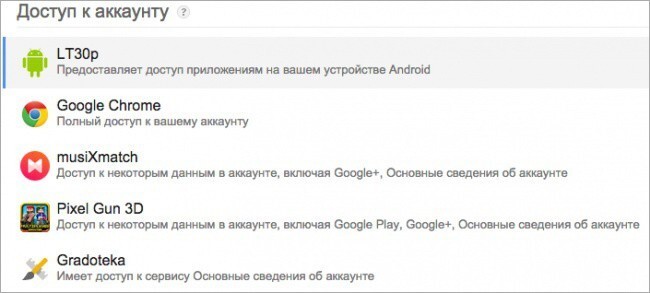
6. Узнайте, как экспортировать все ваши данные
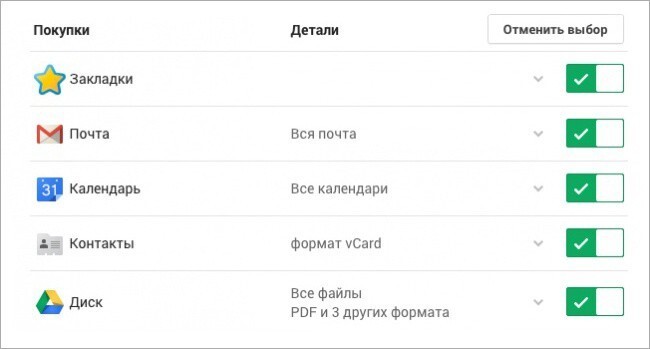
Бонус

а я не пользуюсь гуглом, он обо мне ничего не знает
Если вы не пользуетесь гуглом, это еще не значит, что гугл про вас не собирает информацию)
Элементарный пример - на многих сайтах используется сервис Google Analytics, информация из которого доступна как владельцу сайта, так и гуглу. Для вас как обычного посетителя сайта сбор информации может быть неочевиден, и никак себя не будет проявлять.
скорее всего вы правы. но мне кажется максимум что узнает - это страну и город откуда я. но не мои частые запросы, возраст и тд. во всяком случае я на это надеюсь))
Баян уже в 28и местах порвался. У кого сейчас эти функции включены.

Для сбора информации о вас необязательно что-то включать) Достаточно посещать страницы, на которых установлены счетчики посетителей, скрипты сбора статистики о пользователях, и так далее.
Я не понимаю почему такая шумиха по поводу глобальной слежки. Можно подумать все такие бандиты. У подавляющего большинства дом-работа-дом, ну некоторые налево иногда ездят. И всё. А гонора развели! Джеймс-Бонды, блин.
Вопрос в том, кто имеет доступ к нашей личной информации. Если мусорня, то узнать может любой - через знакомых в мусорне, за взятку. То есть любой может узнать, где я был, что смотрел и так далее - есть повод быть недовольным!
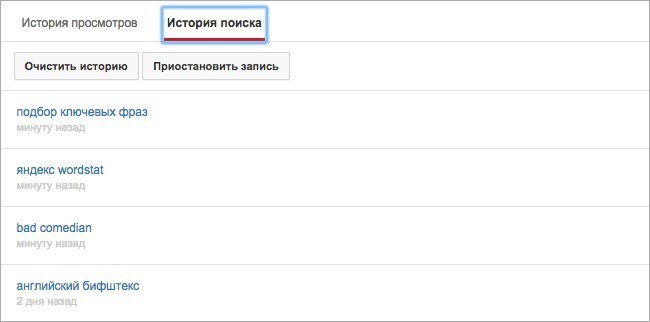
"История местоположений отключена"
"Поисковые запросы и просмотренные страницы (отключено)"
И так далее. В чем проблема-то?
Разве законно собирать информацию обо мне, без моего согласия?
Почему это без согласия? Ты много читаешь условия, когда ставишь галочку "Согласен", при скачивании того или иного приложения. А там всё подробно написано. Не хочешь чтобы следили, не пользуйся.
Те кто париться ,что за ним следить гугл, - начинает скрывать информацию о себе, вот тут то им и интересуются соответствующие органы.
Пусть гугл смотрит ,хочет мне скрывать нечего , по крайней мере пока. )))))

Как выглядело самое долго лунное затмение за 500 лет

Он снялся в “Ворошиловском стрелке”, потому что очень боялся за свою внучку

Делаем модное украшение: кольцо своими руками из бисера




Космические колонии будущего, какими их видели в 1970-е годы


Пассажир с "розочками" набросился на охранника в Шереметьево

"Мстя" была страшна: узнав о гибели любимца, сибирячка не полезла за словом в карман


Машина – огонь! Кубанский изобретатель проверил «Жигули» на прочность огнеметом

«Совпадение? Не думаю!»: странные исторические совпадения, заставляющие верить в судьбу. Часть 1

Медики и спасатели, обвязанные верёвками, на ощупь шли на вызов, но не успели

Сан-Франциско: приёмы шопинга от BLM попали на видео

Беспорядки во Франции: демонстранты нападают на силовиков

Активистам, пытавшимся проверить QR-коды у сотрудников Роспотребнадзора, грозит штраф


Как жестокий отец Маколея Калкина позавидовал сыну и чуть не сломал ему жизнь

Скончался звезда комедии "Ширли-мырли" Валерий Гаркалин

Сравнение размеров звездолетов из известных фантастических фильмов

Полиция в Москве организовала массовый арест мигрантов

Владелец ресторана выгнал всех блогеров и стримеров из своего заведения

Непостоянный Байден и бурление соцсетей и улиц: реакция на оправдательный приговор Кайлу Риттенхаусу
Как отец Маколея Калкина позавидовал сыну и чуть не сломал ему жизнь




15 фотографий редких моментов, которые расширят ваш кругозор

"Новые лапки, новая жизнь": краснодарские зоозащитники спасли собаку, у которой были отрезаны лапы

Мошенник украл у пожилого мужчины шесть миллионов рублей

Взлётную полосу аэропорта Токио закрыли из-за черепах

В Нью-Йорке построят супервысокий "перевернутый" небоскреб

Секс, ложь и алкоголь: как скандалы ставят крест на карьерах знаменитостей

Еще одни: в соцсетях опять всплыло фото оскорбляющее чувства верующих

Потрясающие фотографии рок-звезд, сделанные Миком Роком

Суд в США оправдал подростка, застрелившего во время погромов двух BLM-активистов

Школа в Англии переименовала «дома», названные в честь Черчилля и Роулинг, в стремлении к.

В армии США прекратили чинопроизводство и награждение военных, не привитых от COVID-19

Блогер за рулем BMW устроил страшную аварию на Кутузовском проспекте в Москве
Этичный хакинг и тестирование на проникновение, информационная безопасность
Современные веб-сайты становятся всё сложнее, используют всё больше библиотек и веб технологий. Для целей отладки разработчиками сложных веб-сайтов и веб-приложений потребовались новые инструменты. Ими стали «Инструменты разработчика» интегрированные в сами веб-браузеры:
- Chrome DevTools
- Firefox Developer Tools
Они по умолчанию поставляются с браузерами (Chrome и Firefox) и предоставляют много возможностей по оценке и отладке сайтов для самых разных условий. К примеру, можно открыть сайт или запустить веб-приложение как будто бы оно работает на мобильном устройстве, или симулировать лаги мобильных сетей, или запустить сценарий ухода приложения в офлайн, можно сделать скриншот всего сайта, даже для больших страниц, требующих прокрутки и т.д. На самом деле, Инструменты разработчика требуют глубокого изучения, чтобы по-настоящему понять всю их мощь.
В предыдущих статьях я уже рассматривал несколько практических примеров использования инструментов DevTools в браузере:
Эта небольшая заметка посвящена анализу POST запросов. Мы научимся просматривать отправленные методом POST данные прямо в самом веб-браузере. Научимся получать их в исходном («сыром») виде, а также в виде значений переменных.
По фрагменту исходного кода страницы видно, что данные из формы передаются методом POST, причём используется конструкция onChange="this.form.submit();":

Как увидеть данные, переданные методом POST, в Google Chrome
Итак, открываем (или обновляем, если она уже открыта) страницу, от которой мы хотим узнать передаваемые POST данные. Теперь открываем инструменты разработчика (в предыдущих статьях я писал, как это делать разными способами, например, я просто нажимаю F12):

Теперь отправляем данные с помощью формы.
Переходим во вкладку «Network» (сеть), кликаем на иконку «Filter» (фильтр) и в качестве значения фильтра введите method:POST:

Как видно на предыдущем скриншоте, был сделан один запрос методом POST, кликаем на него:

- Header — заголовки (именно здесь содержаться отправленные данные)
- Preview — просмотр того, что мы получили после рендеренга (это же самое показано на странице сайта)
- Response — ответ (то, что сайт прислал в ответ на наш запрос)
- Cookies — кукиз
- Timing — сколько времени занял запрос и ответ
Поскольку нам нужно увидеть отправленные методом POST данные, то нас интересует столбец Header.
Там есть разные полезные данные, например:
- Request URL — адрес, куда отправлена информация из формы
- Form Data — отправленные значения
Пролистываем до Form Data:

Там мы видим пять отправленных переменных и из значения.
Если нажать «view source», то отправленные данные будут показаны в виде строки:

Вид «view parsed» - это вид по умолчанию, в котором нам в удобном для восприятия человеком виде показаны переданные переменные и их значения.
Как увидеть данные, переданные методом POST, в Firefox
В Firefox всё происходит очень похожим образом.
Открываем или обновляем нужную нам страницу.
Открываем Developer Tools (F12).
Отправляем данные из формы.
Переходим во вкладку «Сеть» и в качестве фильтра вставляем method:POST:

Кликните на интересующий вас запрос и в правой части появится окно с дополнительной информацией о нём:

Переданные в форме значения вы увидите если откроете вкладку «Параметры»:


Другие фильтры инструментов разработчика
Для Chrome кроме уже рассмотренного method:POST доступны следующие фильтры:

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
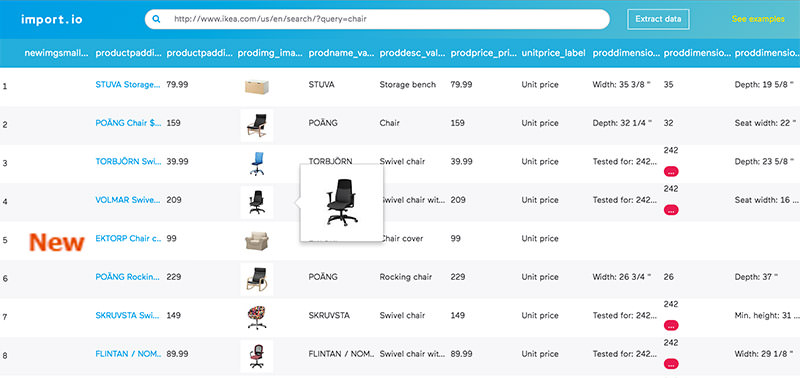
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
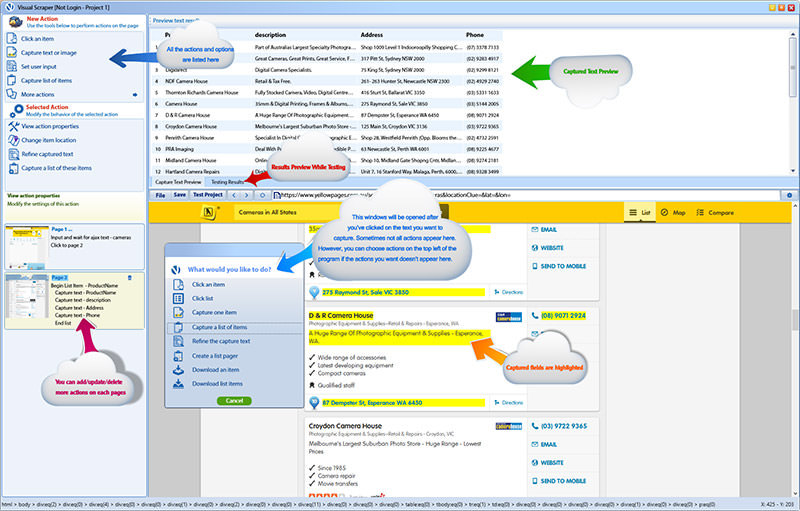
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
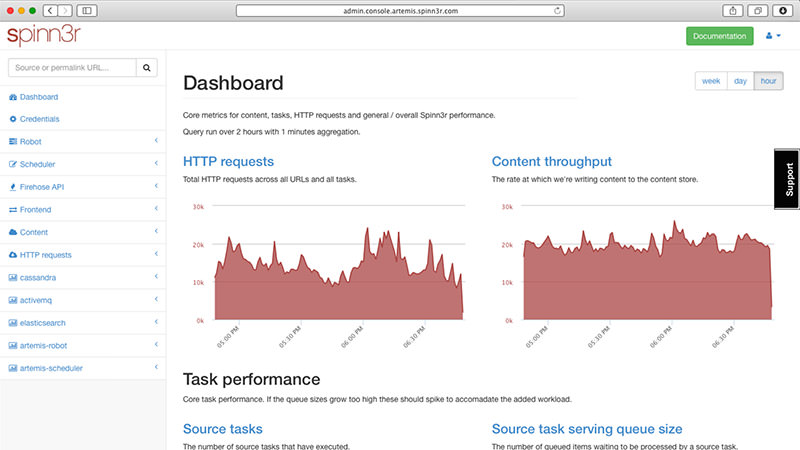
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
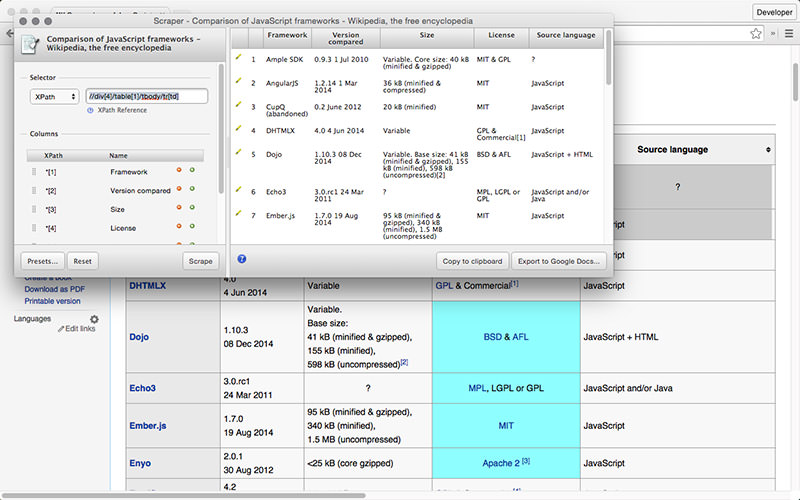
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
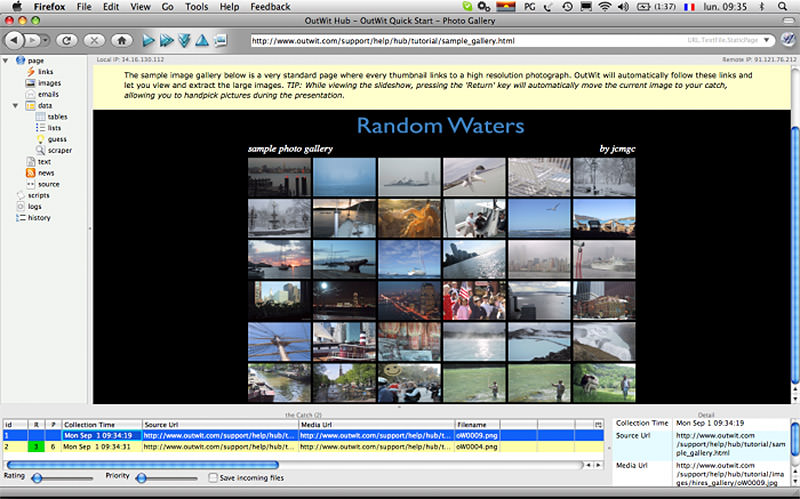
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
Читайте также: