
Разбить архив на части 1с
В прошлых статьях мы уже говорили о подходах к разработке и обслуживанию базы данных, которые позволяют использовать индексы произвольной структуры и даже секционирование для баз 1С. Казалось бы, тема исчерпана и для высоконагруженных баз может наступить светлое будущее, не смотря на то, что платформа 1С пока так и не поддерживает эти возможности из "коробки".
Однако, хотелось бы остановиться подробнее на такой теме как разбиение базы данных на отдельные файлы с помощью файловых групп. В статье про секционирование файловые группы уже использовались для секций, но там про них был сказано вскользь.
Сегодня мы более детально рассмотрим их использование, а также нюансы, с которыми нужно считаться при обслуживании базы данных, реструктуризациях и других моментах.
Для чего вообще может понадобиться разбивать базу данных на отдельные файлы? Самые распространенные кейсы:
- Есть регистр сведений, в котором хранятся двоичные данные файлов. Необходимо вынести хранение файлов на отдельный диск / хранилище, чтобы освободить место на быстрых дисках.
- Есть старые архивные таблицы, которые уже редко используются, но удалять данные нельзя. Почему бы такие таблицы также не перенести на отдельные диски, которые для этого и предназначены. Тем более такие файловые группы можно сделать только для чтения.
- Ускорить бэкапирование базы, т.к. архивные файловые группы можно не бэкапировать каждый раз. Они ведь не меняются!
- Улучшение производительности, за счет распределения файлов базы данных на отдельные носители.
Тему ускорения бэкапирования и производительности сейчас мы рассматривать не будем, но Вы можете прочитать об этом в публикации про секционирование. Сосредоточимся на описании настроек для файловых групп и их сопровождении. Все примеры ниже будут сделаны для SQL Server, но и для PostgreSQL это будет работать с некоторыми модификациями.
Стандартный подход
Любая база, будь то для 1С или любого другого приложения, поддерживает разбиение базы на несколько файлов (конечно, если это поддерживает СУБД). В контексте SQL Server это реализуется с помощью файловых групп.
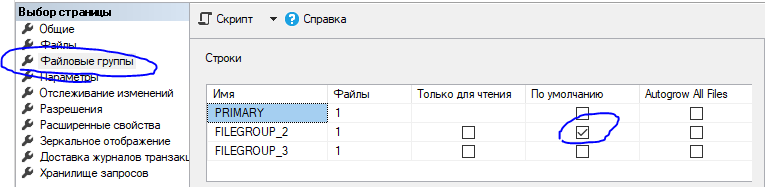
По умолчанию база содержит лишь одну файловую группу "PRIMARY", которую 1С и использует для своих целей. Кроме таблиц и индексов в этой предопределенной группе хранится служебная информация о базе, различные заголовки и др., поэтому полностью заменить эту группу на другую нельзя, она всегда будет присутствовать.
Однако, мы можем добавить собственные файловые группы и использовать их для 1С'ных таблиц, причем сама платформа об этом не узнает.
Возьмем для примеров демобазу БСП и создадим в ней две новых файловых группы.
Но просто добавить файловые группы недостаточно. Еще нужно добавить файлы данных, для которых эти файловые группы будут задействованы.
Отлично, у нас есть две файловые группы "FILEGROUP_2" и "FILEGROUP_3", осталось их задействовать. Есть несколько основных вариантов:
- Мы можем вручную изменить основную файловую группу базы и сделать реструктуризацию средствами 1С.
- Мы можем пересоздать кластерный или другие индексы средствами T-SQL, указав для использования нужную файловую группу.
- Ничего не делать.
По третьему варианту написано довольно много примеров в сети, поэтому рассмотрим только первые два пункта. Все примеры будем делать на регистре сведений "История адресных объектов", который на стороне базы представлен таблицей "_InfoRg4683" с несколькими индексами.
И так, для начала установим основную файловой группой - одну из тех, что добавили выше.
То же самое можно сделать через T-SQL.
Кому как больше нравится.
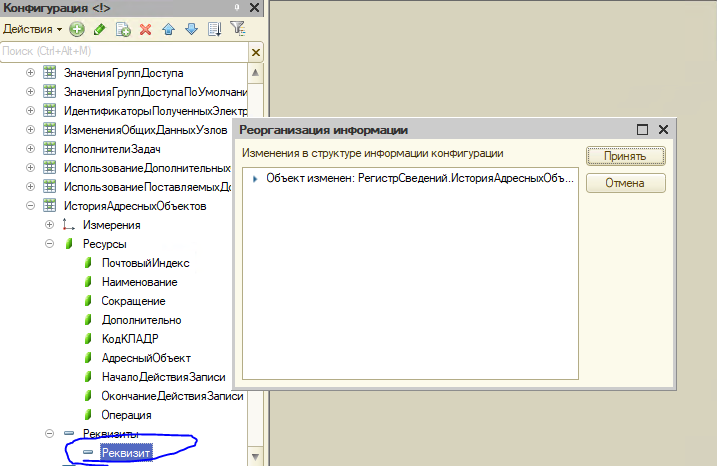
Теперь нужно сделать реструктуризацию средствами платформы. Нормального способа вызвать ее для нашего случая нет, но мы можем:
- Добавить временно реквизит в таблицу, а потом запустить реструктуризацию.
- Полностью реструктуризировать базу через "Тестирование и исправление".
Оба варианта выглядят "не очень", и Вам повезет, если необходимость реструктуризации появится как-раз в этот момент для других задач. При использовании инструмента "Тестирование и исправление" Вы вообще переведете все таблицы и индексы в установленную файловую группу, поэтому этот случай мы вообще рассматривать не будем. А вот пример с добавлением временного реквизита - пожалуйста.
С помощью этих скриптов можно узнать как изменилась структура базы в части использования файловых групп. Вот какие изменения мы получили.
| Таблица | Индекс | Файловая группа | Файл |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4705_SNNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4706_SNNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByMainFilter_NNNNNNNNNNNB | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
Таким образом, мы перевели таблицу регистра сведений "История адресных объектов" и все ее индексы в файловую группу "FILEGROUP_2".
Подведем итог по данному способу.
Плюсы:
Минусы:
- Нужен вызов платформенной реструктуризации, что не всегда оптимально.
- После реструктуризации надо обратно настраивать основную файловую группу.
- Необходимость проводить реструктуризацию таблиц в разных файловых группах отдельно друг от друга, что не всегда возможно.
Вообщем, способ неэффективный, но требует минимальных действий на стороне СУБД.
Скриптуем
Более эффективный и гибкий подход - это перенос таблиц и индексов в другую файловую группу с помощью скриптов. Вот так будет выглядеть скрипт для переноса всех индексов регистра сведений "История адресных объектов" в третью файловую группу.
Перенос всех индексов таблицы в другую файловую группуФактически, нам нужно пересоздать индексы с указанием новой файловой группы. При этом, когда мы пересоздаем кластерный индекс таблицы, то все данные в ней переносятся в новую файловую группу.
Для того, чтобы сгенерировать скрипты создания индексов, можно воспользоваться стандартными возможностями SQL Managment Studio по созданию скриптов для базы данных.
Все, теперь мы счастливые обладатели регистра сведений, который находится в дополнительной файловой группе. Смотрим итог с помощью этих скриптов.
| Таблица | Индекс | Файловая группа | Файл |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4705_SNNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4706_SNNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByMainFilter_NNNNNNNNNNNB | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
Как итог, определим плюсы и минусы.

Плюсы:
- Быстрый и эффективный способ работы с файловыми группами.
- Нет необходимости каких-либо действий на стороне 1С.
- Нет связи с платформой 1С, даже призрачной как в прошлом примере.
Конечно, предпочтительнее использовать этот способ, если Вы бережете время, нервы и деньги.
Сложности для 1С
Все выглядит просто, но есть нюансы.
Во-первых, лицензионное соглашение 1С запрещает так работать с СУБД, т.к. эти возможности недокументированы. Начиная использовать файловые группы, Вы должны осознавать риски нарушения этого соглашения. Минимальные последствия - это отказ в технической поддержке решений на платформе 1С.
В пункте 65 лицензионного соглашения сказано следующее:
Лицензионное соглашение не позволяет использовать недокументированные фирмой "1С" средства для построения решений на платформе "1С:Предприятие". Это означает, что средства СУБД (или любые другие внесистемные средства) можно использовать только в том случае, если документация по продуктам линейки "1С:Предприятие" (включая 1С:ИТС) содержит явную рекомендацию использовать данное средство для решения данной задачи.
Во всех остальных случаях лицензионное соглашение позволяет использовать для построения решений только штатные средства платформы. В частности, можно обращаться к данным информационной базы только при помощи объектов "1С:Предприятия", специально предназначенных для работы с данными (запросы, справочники, документы и т. д.). Нельзя обращаться к данным информационной базы напрямую, минуя уровень объектов работы с данными "1С:Предприятия", например при помощи средств СУБД или при помощи внешних компонент, которые реализуют прямой доступ к СУБД. Это ограничение распространяется на любые действия с данными, в том числе на изменение их структуры, а так же на чтение или изменение самих данных информационной базы или служебных данных "1С:Предприятия".
Данное ограничение необходимо для обеспечения стабильности работы механизмов системы, осуществления поддержки и возможности перехода на новые версии "1С:Предприятия".
Вы должны четко понимать плюсы и минусы данного шага. Все, что Вы сделаете будет на Вашей совести!
Во-вторых, это усложнение сопровождения, т.к. при обновлении базы данных необходимо учитывать тот факт, что некоторые таблицы находятся в других файловых группах или дисковых носителях.
Зачем это учитывать? Например, у Вас в базе есть регистр сведений "Присоединенные файлы" (в базе представлен таблицей "_InfoRg2133"), в котором хранятся двоичные данные разнотипных документов. Для экономии места в основном хранилище данных был выполнен перенос этих документов в отдельную файловую группу. Файл данных для нее находится на отдельном диске.
Перенос данных документов в отдельную файловую группуПлатформа 1С хранит двоичные данные документов в LOB-типах данных (image или varbinary(max) в зависимости от версии платформы). Для переноса LOB-данных в отдельную файловую группу не обязательно переносить всю таблицу и индексы. Достаточно перенести только сами LOB-данные, указав основную файловую группу для таких типов. Именно так мы и сделаем в примере ниже.
Теперь все LOB-данные перенесены в файловую группу "FILEGROUP_3". При необходимости основной файл данных, где ранее хранились перемещенные документы, можно уменьшить операцией Shrink. В нашем случае мы это рассматривать не будем.
P.S. Не забудьте сделать бэкап перед такими операциями.
P.P.S. Этот скрипт не является готовым решением. Его можно улучшить за счет различных проверок, транзакций и т.д.
Все отлично сработало, мы освободили 1 ТБ данных в основном хранилище. НО! В один прекрасный день разработчики 1С внесли изменения в систему, добавив новый ресурс к регистру сведений "Присоединенные файлы". В тестовых базах все проверено, ведь там никто не держит полную копию рабочей базы. Изменение ушло в релиз, но при развертывании возникли следующие проблемы:
В итоге, если такая ситуация произойдет и добрые администраторы не смогут выделить дополнительное место да дисках, то может произойти остановка работы системы. Но это не точно и полностью зависит от Вашей инфраструктуры!
Но есть ли способ избавиться от такой проблемы? Да, есть! Вот несколько рекомендаций:
- Проверять перечень таблиц для реструктуризации перед каждым релизом.
- В случае, если изменения затронули тяжелые таблицы, для которых применены нестандартные файловые группы, то один из вариантов:
- Отказаться от изменения на этой таблице. Вместо этого использовать внешние таблицы. Например, вместо добавления реквизита в справочник можно добавить его как доп. свойство или в дополнительный регистр сведений. Включите воображение!
- Если изменения все же очень нужны, то необходимо делать реструктуризацию в "ручном режиме". Подробнее останавливаться на этом сейчас не будем, но на ИС уже об этом писали. Причем, чем больше изменений, тем и сложнее будет сделать это вручную.
- Максимально автоматизировать настройку файловых групп для таблиц и индексов базы, а также сделать заглушки для тех таблиц, где реструктуризация автоматически проходить не должна. Об этом будет ниже.
В этом и кроются основные причины усложнения сопровождения. Поэтому стоит 7 раз подумать, прежде чем начать такое у себя использовать.
Автоматизируй это!
Выше мы упомянули про автоматизацию настроек файловых групп для таблиц и индексов. На самом деле здесь ничего нового нет и используется тот же самый подход по созданию произвольных индексов и применению настроек сжатия, что был в статье "Создаем свои индексы для баз 1С. Со своей структурой и настройками!". Он заключается в создании глобальных триггеров, в которых мы отлавливаем события создания таблицы или индекса и встраиваем свою логику для настройки базы данных.
Как пересоздать индекс с учетом новой файловой группы? Например, у нас есть таблица "_InfoRg4683" и индекс "_InfoRg4683_ByDims_NNNNNNNNNNBN" (это из примера с регистром сведений "История адресных объектов"), при этом основная файловая группа в базе это "PRIMARY". Имея уже такие данные мы можем написать такой скрипт.
Универсальный (почти) скрипт пересоздания индекса с новой файловой группойСкрипт генерирует команду "CREATE INDEX" для уже существующего индекса, а в ней мы просто подменяем имя файловой группы.
Параметр "DROP_EXISTING = ON" позволяет избежать ошибки, что такой индекс уже существует. В этом случае СУБД удалит старый индекс и создаст новый.
Также есть несколько нюансов при пересоздании индексов с новыми файловыми группами:
- При пересоздании кластерного индекса с новой файловой группой, все остальные индексы таблицы будут также созданы с этой файловой группой.
- Для большей универсальности имя новой и старой файловой группы можно получать динамически, вместо явного указания в скрипте.
- Пользователь СУБД, от имени которого выполняется реструктуризация, должен иметь необходимые привилегии для выполнения запросов.
А что на счет остановки реструктуризации, если она начинается на таблице, где этого происходить не должно?
В триггере проверяем имя таблицы и/или индекса и если он попадает под запрет, то выполняем:
При попытке запуска обновления информационной базы получим ошибку.

Вот такой страшный запрет!

Можно пойти дальше и не ограничиваться отдельными скриптами, а вынести все подобные ограничения и настройки в отдельный инструмент, как это было сделано здесь.
Послесловие
На первый, второй и третий взгляд все это может показаться настоящим монстром, особенно для сопровождения. Что ж, так оно и есть! Остается надеяться, что наступят светлые времена, когда платформа 1С позволит использовать возможности СУБД без таких костылей. А пока на этом все!
Дата публикации 29.09.2017
В программах "1С:Предприятие" реализованы возможности, позволяющие решать проблему накапливающейся электронной корреспонденции в 1С-Отчетности.
Дело в том, что входящая и исходящая корреспонденция (письма, технологические документы и др.) при их отправке и получении сохраняются в информационной базе, тем самым увеличивая ее объем.
Если проблема увеличившегося объема информационной базы мешает вашей работе, то возможны следующие варианты ее решения:
1. Можно выполнить настройку, позволяющую сразу сохранять файлы 1С-Отчетности в отдельную папку на диске (или на сервере). В этом случае файлы не будут сохраняться в информационной базе изначально, но в последующем будут доступны из программы так же, как если бы они хранились в базе.
2. Можно выгрузить сохраненную в информационной базе корреспонденцию 1С-Отчетности с помощью специальной обработки в архив на диске. При этом файлы архива будут удалены из информационной базы (с возможностью восстановления, если это потребуется) и станут недоступны из программы.
Рассмотрим эти оба варианта в нашей статье.
Хранение данных в томах на диске
Рассмотрим вариант 1: можно выполнить настройку, позволяющую сразу сохранять файлы корреспонденции 1С-Отчетности в отдельную папку на диске (или на сервере). В этом случае корреспонденция 1С-Отчетности не будет загружаться в информационную базу изначально, но в последующем будут доступны из программы так же, как если бы они хранились в базе, то есть изменение не повлияет на работу пользователя.
Важная особенность этого варианта заключается в том, что данная настройка может быть задана только для информационной базы в целом. Это означает, что в заданных томах на диске будут храниться не только файлы 1С-Отчетности, но и файлы других механизмов.
Для перехода к настройке перейдите по гиперссылке "Настройки работы с файлами" в разделе "Администрирование" (рис. 1).

В форме "Настройка работы с файлами" установите флажок "Хранить файлы в томах на диске" (рис. 2). При этом появится предупреждение, что нужно настроить тома (папки), нажмите "ОК".

Щелкните по гиперссылке "Тома хранения файлов" (рис. 3).


Укажите наименование тома и путь для хранения файлов (рис. 5).

Для запуска регламентного задания перейдите из раздела "Администрирования" по гиперссылке "Обслуживание".

Затем перейдите по гиперссылке "Регламентные и фоновые задания" (рис. 7).


За один запуск задание переносит только 10 файлов. Вы можете настроить удобное для себя расписание запусков регламентного задания.
После переноса файлов в тома необходимо выполнить реструктуризацию (сжатие) таблиц информационной базы для уменьшения ее физического размера.
Для этого откройте программу в режиме режиме "Конфигуратор" выберите пункт меню "Администрирование" - "Тестирование и исправление".
При работе с клиент-серверным вариантом базы установите флажок "Реструктуризация таблиц информационной базы" (рис. 9).
При работе с файловой базой - флажок "Сжатие таблиц информационной базы" (рис. 10).


Архивация данных
Второй вариант решения проблемы предполагает разовую выгрузку файлов 1С-Отчетности в архив на диске с помощью специальной обработки.
Перед выполнением архивирования настоятельно рекомендуется выполнить резервное копирование данных информационной базы. Также убедитесь, что на диске достаточно места для размещения архива.
В поле "Каталог архива" укажите путь для хранения архива (рис. 11).

Чтобы установить отбор (по организации, по периоду, по видам объектов и контролирующим органам) воспользуйтесь соответствующими вариантами отбора (рис. 12).
Если снять флажок "Не удалять файлы из базы", то после окончания архивации файлы 1С-Отчетности будут удалены из информационной базы и после проведения реструктуризации таблиц (см. ниже) объем базы будет уменьшен.
Для архивации нажмите кнопку "Архивировать".


После переноса файлов в тома необходимо выполнить реструктуризацию (сжатие) таблиц информационной базы для уменьшения ее физического размера.
Для этого откройте программу в режиме режиме "Конфигуратор" выберите пункт меню "Администрирование" - "Тестирование и исправление".
При работе с клиент-серверным вариантом базы установите флажок "Реструктуризация таблиц информационной базы" (рис. 14).
При работе с файловой базой - флажок "Сжатие таблиц информационной базы" (рис. 15).


Восстановление данных из архива
Если при архивации данных файлы 1С-Отчетности были удалены (был снят флажок "Не удалять файлы из базы"), а затем понадобилось их снова загрузить в информационную базу, то можно выполнить восстановление.
Восстановление выполняется с помощью той же обработки, что и архивация.
Восстановить данные можно только в ту информационную базу, из которой была выполнена архивация.
Укажите каталог архива, в котором хранятся заархивированные файлы 1С-Отчетности и нажмите кнопку "Восстановить".

В окне "Настройка восстановления объектов" укажите какие данные за какой период необходимо восстановить (рис. 17) и нажмите "ОК".

Мы реализовали ряд низкоуровневых инструментов для работы с двоичными данными. Теперь вы можете решать такие задачи как:
- Взаимодействие со специализированными устройствами по двоичному протоколу;
- Разбор файлов и манипуляция файлами различных форматов;
- Конвертация текстовых данных напрямую в двоичные данные, например, для отправки отчетов;
- Работа с двоичными данными в памяти.
Ранее в платформе существовал ряд методов для работы с файлами и тип ДвоичныеДанные. Но они не позволяли каким-либо простым способом проанализировать внутреннее содержимое или модифицировать его. Все действия выполнялись над всеми данными целиком. Единственная операция, которая была возможна над частью данных это разделение файла на части и склейка обратно.
Теперь платформа предоставляет инструменты как для последовательной работы с большими объёмами двоичных данных, так и для произвольного доступа к относительно небольшим двоичным данным целиком в оперативной памяти.
Основные типы для последовательной работы с данными
Назначение и взаимную связь новых объектов удобнее всего посмотреть на конкретном примере. Пример разбивает wav файл на одинаковые части размером 1000 байт.
На схеме показана последовательность использования объектов встроенного языка, соответствующая листингу.

Пример: Разбить WAV-файл на части
Основу для работы с двоичными данными составляет группа новых типов, которую можно обозначить словом «потоки». Таких типов три: Поток, ФайловыйПоток и ПотокВПамяти. В примере используется один из них, ФайловыйПоток, но остальные работают, по большому счёту, аналогично.
Потоки предназначены для последовательного чтения/записи больших объемов двоичных данных. Их преимущество заключается в том, что они позволяют работать с потоками данных произвольного объёма. Но вместе с этим они предоставляют лишь базовые возможности работы, такие как чтение из потока, запись в поток и изменение текущей позиции.
Потоки можно сконструировать по имени файла или из объекта ДвоичныеДанные. В примере поток конструируется по имени файла (ФайловыеПотоки.ОткрытьДляЧтения(ИмяФайла)) одним из методов объекта МенеджерФайловыхПотоков. Это новый способ конструирования, дальше мы расскажем о нём.
Затем в примере, для того, чтобы иметь более широкие возможности работы, из файлового потока конструируется объект ЧтениеДанных (Новый ЧтениеДанных(ПотокИсходный)). Этот объект позволяет уже читать отдельные байты, символы, числа. С его помощью можно прочитать строку с учётом кодировки, или прочитать данные до некоторого известного заранее маркера. Этот объект имеет своего «антипода», ЗаписьДанных, который конструируется аналогичным образом, но занимается не чтением, а записью данных. Поскольку эти объекты читают/пишут данные из/в потоки, то они также делают это последовательно, что позволяет работать с потоками произвольного объёма.
В примере ЧтениеДанных используется с двумя целями. Во-первых, для того, чтобы прочитать и изменить заголовок файла, а во-вторых, для того, чтобы разделить файл на несколько частей.
Заголовок файла получается в виде объекта БуферДвоичныхДанных. Это важный объект, но о нём мы скажем чуть позже. А тело файла делится на части равного размера (ЧтениеДанных.РазделитьНаЧастиПо(1000)), которые получаются в виде объектов РезультатЧтенияДанных. Этот тип никаких особенных возможностей не предоставляет, а в основном просто хранит прочитанные данные.
Далее в примере для каждой такой части файла создаётся ФайловыйПоток для записи, и на его основе конструируется ЗаписьДанных. Запись данных записывает в поток новый заголовок, новое тело, и закрывает его. В результате, по окончании цикла, получается набор из нескольких файлов.
Побайтовые операции
В примере заголовок файла читается в объект БуферДвоичныхДанных (ПрочитатьВБуферДвоичныхДанных(44)). Главное отличие этого объекта от рассмотренных выше заключается в том, что он предоставляет не последовательный, а произвольный доступ к данным, и позволяет изменять их по месту.
Все данные этого объекта полностью находятся в оперативной памяти. Поэтому, с одной стороны, он предназначен для анализа и редактирования не очень больших объёмов двоичных данных. Но с другой стороны даёт удобные возможности для произвольного чтения и записи байтов, представленных числами, для разделения буфера на несколько частей и объединения нескольких буферов в один, а также для получения части буфера указанного размера.
В качестве иллюстрации возможностей буфера двоичных данных можно привести пример поворота картинки на 90 градусов.
Пример: поворот изображения
Синхронная и асинхронная работа
Потоки (Поток, ФайловыйПоток, ПотокВПамяти), ЧтениеДанных, ЗаписьДанных, РезультатЧтенияДанных имеют пары синхронных и асинхронных методов. Например, Записать() – НачатьЗапись(), Закрыть() – НачатьЗакрытие().
Асинхронные методы нужны для того, чтобы иметь возможность одинаковой работы и в тонком клиенте, и в веб-клиенте. Потому что браузеры используют асинхронную модель работы.
Синхронные методы необходимы для работы в контексте сервера. Потому что на сервере используется только синхронная модель работы.
Менеджеры и асинхронные конструкторы
В дополнение к перечисленным объектам мы реализовали ещё два менеджера, которые существуют в единственном экземпляре, и доступны через свойства глобального контекста БуферыДвоичныхДанных и ФайловыеПотоки.
МенеджерБуферовДвоичныхДанных позволяет выполнять какие-либо операции с буферами без привязки к контексту конкретных экземпляров этих объектов. Например, сейчас с его помощью можно соединить несколько буферов в один.
Конечно, одноимённый метод Соединить() есть и у самого объекта БуферДвоичныхДанных. С его помощью можно соединить данный буфер с другим. Но для этого нужно использовать контекст данного буфера, что бывает не всегда удобно.
МенеджерФайловыхПотоков мы создали для других целей. Для потоков, как мы уже говорили, необходима возможность как синхронной, так и асинхронной работы. И если для синхронных методов мы сделали их асинхронные аналоги, то для конструкторов такой способ не подходит. Конструкторы объектов могут работать только синхронно. Поэтому для того, чтобы была возможность асинхронного конструирования, мы реализовали менеджер с асинхронными методами, которые, по сути, разными способами конструируют объект ФайловыйПоток.
А для красоты и симметричности мы добавили ему аналогичные синхронные методы. Чтобы была возможность упростить запись, и вместо конструктора с четыремя параметрами:
использовать подходящий метод с одним параметром:
В качестве иллюстрации новых возможностей работы с двоичными данными хочется привести ещё два листинга. Они показывают реализацию актуальной задачи, о которой нас часто спрашивали.
Бывает необходимо разделить текстовый файл большого размера на несколько маленьких файлов. Ниже представлены функции при помощи которых можно разделить файл:
РазделитьФайл(<ИмяФайла>, <РазмерЧасти>, <Путь>)
// для разделения файла на части, размером каждой равной одному мегабайту Код 1C v 8.хРазделяет указанный файл на несколько частей (файлов) заданного размера. Имя каждой части образуется из имени исходного файла с прибавлением ему расширения в виде порядкового номера, включая лидирующие нули.
В результате получим несколько файлов:
А для объединения файлов в один используйте:
При объединении файлов по маске необходимо задать маску поиска файлов и имя файла, который требуется создать.
Выполнение кода вида:
приведет к объединению вышеперечисленных файлов в файл с заданным именем.
Внимание! Файлы объединяются в порядке возрастания имен.Разместил: E_Migachev Версии: | 8.x | 8.3 | Дата: 23.02.2015 Прочитано: 11795

Похожие FAQ
Еще в этой же категории
Загрузить данные в 1с из текстового файла с разделителями 6В этой статье я расскажу, как загружать данные в 1с 8 из простейших текстовых файлов с разделителями. Обычно они имеют расширение csv (Comma-Separated Values). Т. е. название подразумевает, что в каждой строке такого текстового файла значения разделе Пример выгрузки данных в Текстовый файл, документ 0
Режим = РежимДиалогаВыбораФайла.Сохранение; ДиалогСохраненияФайла = Новый ДиалогВыбораФайла(Режим); ДиалогСохраненияФайла.ПолноеИмяФайла = " Выгрузка_" +Формат(ПериодРегистрации," ДФ=M_yy" ); Фильтр = " Текст(*.txt)|*.txt" ; Пример загрузки данных из Текстового файла, документа 0
Файл для загрузки содержит данные вида(КодФизЛица, ФизЛицо, Сумма): 000000513
Петров Юрий Викторович
Иванов Александр Юрьевич
50 //Выбор файла Режим = РежимДиалогаВыбораФайла.Открытие; ДиалогОткрытияФайла = Новый ДиалогВыбораФайла Посмотреть все в категории Текстовый документ
Задание к занятию "Двоичные данные"
Задача 1 Создать в справочнике Номенклатура возможность загрузки и хранения картинки.
Добавить возможность загрузки и хранения картинки в справочнике Номенклатура.
Требования к результату
Выгрузка информационной базы (.dt) с конфигурацией из предыдущих заданий, в которой реализована возможность загружать и просматривать из формы элемента номенклатуры.
Можно выбрать каталог и картинку для загрузки.
Добавим реквизит "ФайлКартинки" с типом Хранилище значений в справочнике Номенклатура.
Добавим реквизит "ПутьКартинки" на форму элемента, укажем тип "Строка". В нем будет адрес картинки во временном хранилище.
Добавим на событие Нажатие процедуру "ПутьКартинкиНажатие".
Внутри процедуры добавим выбор файла с логичными для этого фильтрами отбора формата файла.
Используем асинхронный способ.
Сохраним картинку во временное хранилище.
Перед записью на сервере запишем в хранилище значений картинку.
При чтении на сервере получим картинку из хранилища значений.
Пример получения через временное хранилище и записи в реквизит объекта через Хранилище значений.
Задача 2 (со звездочкой) Разбить файл на части и склеить после этого.
Изучить системные глобальные методы "РазделитьФайл" и "ОбъединитьФайлы". Реализовать аналогичную пару методов самостоятельно во внешней обработке (при реализации не использовать "РазделитьФайл" и "ОбъединитьФайлы", необходимо реализовать их аналоги, пользуясь работой с файлами и потоками). Внешняя обработка должна содержать 2 закладки:
На первой закладке расположено поле "Имя файла", в которой пользователь с помощью стандартного диалога выберет произвольный файл на диске. Так же на закладке расположено числовое поле "Размер части" и текстовое поле "Путь", в котором пользователь с помощью стандартного диалога выбора каталога выберет путь, в котором нужно разместить полученные части файла.
На второй закладке должен быть размещен элемент управления ТаблицаФормы, в котором пользователь сможет указать в нужном ему порядке перечень имен файлов. Так же на закладке должен быть размещен элемент "Результат", в котором пользователь с помощью стандартного диалога сохранения укажет место, в которое нужно сохранить результат склейки.
Читайте также: