
Поиск по регулярным выражениям в браузере
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
25–27 ноября, Онлайн, Беcплатно
Однако уже здесь следует быть аккуратным — как и любой язык, регекспы имеют спецсимволы, которые нужно экранировать. Вот их список: . ^ $ * + ? < >[ ] \ | ( ) . Экранирование осуществляется обычным способом — добавлением \ перед спецсимволом.
Набор символов
Предопределённые классы символов
Если необходимо описать вообще любой символ, для этого используется точка — . . Если указанные классы написать с заглавной буквы ( \S , \D , \W ) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.

Диапазоны
Квантификаторы

Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
Очевидное решение <.*> здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
Это происходит из-за того, что по умолчанию квантификатор работают по т.н. жадному алгоритму — старается вернуть как можно более длинную строку, соответствующую условию. Решить проблему можно двумя способами. Первый — использовать выражение <[^>]*> , которое запретит считать содержимым тега правую угловую скобку. Второй — объявить квантификатор не жадным, а ленивым. Делается это с помощью добавления справа к квантификатору символа ? . Т.е. для поиска всех тегов выражение обратится в <.*?> .
Ревнивая квантификация
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение <(.*?)> .
Если выражение берётся в скобки только для применения к ней квантификатора (не планируется запоминать результат поиска по этой группе), то сразу после первой скобки стоит добавить ?: , например (?:[abcd]+\w) .
С использованием этого механизма мы можем переписать наше выражение к виду [Хх]([аоие])х?(?:\1х?)* .

Перечисление
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Java[^script]
Найдет ли регулярка Java[^script] что-нибудь в строке Java? А в строке JavaScript?
Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного: -?\d+(\.\d+)? .
Оператор – это [+*/\-] . Заметим, что дефис мы экранируем. Нам нужно число, затем оператор, затем число, и необязательные пробелы между ними. Чтобы получить результат в требуемом формате, добавим ?: к группам, поиск по которым нам не интересен (отдельно дробные части), а операнды наоборот заключим в скобки. В итоге:
Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
33 самые полезные регулярки с примерами использования для быстрого решения наиболее распространенных задач веб-разработки.

Пользовательские данные
1. Юзернейм
Стандартный формат юзернейма – цифры, строчные буквы, символы - и _ . Разумная длина – от 3 до 16 знаков. В зависимости от ваших конкретных потребностей вы можете изменять набор символов (например, разрешить символ * ) и длину строки.
JS:
Что используем:
Символы ^ и $ указывают на начало и конец строки, так что введенный юзернейм будет проверен на совпадение полностью от первого до последнего символа.
2. Валидация email
Проверка адреса электронной почты на корректность – одна из самых частых задач веб-разработчика. Без этого не обходятся ни разнообразные формы подписки, ни авторизация.
Для валидации email существует множество различных регулярок. Вот одна из них – не самая большая и не самая сложная, но достаточно точная для быстрой проверки адреса:
JS:
Что используем:
Флаг i в регулярных выражений обеспечивает регистронезависимость сравнения.
3. Номер телефона
Проверяя номер телефона, обязательно учитывайте общепринятые форматы, так как в разных странах их принято записывать по-разному. Например, для американского стиля подойдет вот такая регулярка:
JS:
Что используем:
Квантификатор ? соответствует одному предыдущему символу или его отсутствию.
4. Надёжность пароля
Часто встречаете на различных сервисах требование придумать сложный пароль? Кто и как определяет требуемую степень сложности? На самом деле, для этого есть некоторые стандарты: минимальная длина, разный регистр символов, наличие букв, цифр и специальных знаков.
Чтобы обеспечить ваших пользователей надежными паролями, можете воспользоваться вот таким выражением (или составить собственные регулярки со специфическими требованиями):
JS:
Что используем:
Оператор ?= внутри скобочной группы позволяет искать совпадения "просматривая вперед" переданную строку и не включать найденный фрагмент в результирующий массив.
Подробнее о надежности паролей вы можете узнать из этого руководства.
5. Почтовый индекс (zip-code)
Формат почтового индекса, как и телефона, зависит от конкретного государства.
В России все просто: шесть цифр подряд без разделителей.
Американский zip-code может состоять из 5 символов или в расширенном формате ZIP+4 – из 9.
JS:
Что используем:
Последовательность ?: внутри скобочной группы исключает ее из запоминания.
6. Номер кредитной карты
Разумеется, при проверке номера платежной карты не стоит полагаться на регулярные выражения. Однако с их помощью вы можете сразу же отсеять очевидно неподходящие последовательности и не нагружать сервер лишним запросом.
С помощью вот такой длинной регулярки вы можете поддерживать сразу несколько платежных систем:
Подробнее разобраться, откуда что взялось, вы можете здесь.
Что используем:
Вертикальная черта | в регулярных выражениях обозначает альтернацию, то есть выбор одного варианта из нескольких.
Распространенные форматы
7. Начальные и конечные пробелы
Пробелы в начале и конце строки обычно не несут никакой смысловой нагрузки, но могут повлиять на анализ и обработку данных, поэтому от них следует сразу же избавляться.
JS:
Что используем:
Квантификатор + соответствует инструкции – один и более символов.
8. Дата
С датами приходится работать очень часто, а форматов записи у них великое множество. Прежде чем начинать обработку, имеет смысл проверить, соответствует ли вид переданной строки требуемому.
Вот такое регулярное выражение поддерживает несколько форматов дат – с полными и краткими числами (5-1-91 и 05-01-1991) и разными разделителями (точка, прямой или обратный слеш).
Здесь учитываются даже високосные годы!
JS:
Что используем:
Последовательности вида \1 , \2 и так далее – это обратные ссылки на скобочные группы, определяющие вид разделителя. Благодаря им можно отсеять даты с разными разделителями:
9. IPv4
Адрес IP используется для идентификации конкретного компьютера в интернете Он состоит из четырех групп цифр (байтов), разделенных точками (192.0.2.235).
Что используем:
Класс \b означает "границу слова" и имеет нулевую ширину (то есть это не отдельный символ).
10. IPv6
IPv6 – это новый, более сложный синтаксис IP-протокола. Выражение для проверки на этот формат выглядит куда страшнее, хотя на самом деле разница заключается только в поддержке шестнадцатеричных чисел:
11. Base64
Base64 – достаточно распространенный формат кодирования бинарных данных, который часто используется, например, в email-рассылках.
Для валидации строки в этом формате можно использовать следующее регулярное выражение:
12. ISBN
ISBN – международная номенклатура для печатных книг. Номер может состоять из 10 (ISBN-10) или 13 цифр (ISBN-13). На самих книгах ISBN обычно разделен дефисами на несколько групп (код страны, издательства и самой книги), но для проверки и использования их следует удалять.
Это регулярное выражение позволяет проверить оба формата сразу:
JS:
Числа
13. Проверка на число
Очень простая проверка строки на число с помощью регулярок:
JS:
14. Разделитель разрядов
Задача разбить большое число на разряды по три цифры встречается в разработке довольно часто. Оказывается это очень легко сделать с помощью регулярок.
JS:
Что используем:
Комбинация $& в строке замены позволяет подставить найденную комбинацию.
15. Цена
Цены могут быть представлены во множестве различных форматов. Универсального регулярного выражения для них, скорее всего, не существует, но цену в долларах из строки извлечь очень просто.
Эта регулярка предполагает, что для разделения разрядов числа используются запятые, а дробная часть отделена точкой:
JS:
Что используем:
Комбинация означает, что символ из диапазона 7 должен быть повторен ровно 2 раза (дробная часть цены).
Файлы и URL
16. Сопоставить строку URL
Если вам необходимо проверить, является ли полученная строка URL-адресом, вы можете воспользоваться вот такой регуляркой:
JS:
17. Извлечение домена
В URL-адресе много частей: протокол, домен, поддомены, путь к странице и строка запроса. С помощью регулярок можно отбросить все лишнее и получить только домен:
JS:
Что используем:
Метод match возвращает объект с данными совпадения. Под индексом 1 в нем хранится совпадение, соответствующее первой скобочной группе.
18. Расширения
Одна строчка регулярного выражения позволяет быстро и просто получить расширение файла, с которым вам предстоит работать:
JS:
Разумеется, при необходимости сюда можно добавлять другие расширения.
19. Протокол
Иногда требуется извлечь протокол полученной ссылки. Регулярные выражения и тут облегчают жизнь:
JS:
Социальные сети
20. Twitter
Имя пользователя Twitter:
21. Facebook
URL аккаунта на Facebook:
22. YouTube
Получение ID видео на YouTube:
JS:
Что используем:
Метод exec объекта регулярного выражения работает почти так же, как метод match строки.
HTML и CSS
23. HEX-цвета
Веб-разработчику часто приходится иметь дело с цветами, заданными в шестнадцатеричном формате. Регулярки позволяют легко извлекать такие цвета из строки:
24. Адрес изображения
Для получения адреса изображения обычно используется DOM-метод img.getAttribute('src') . Регулярки для этого применяются редко, но полезно все же знать их возможности:
JS:
25. CSS-свойства
Еще одна нетривиальная ситуация – получение свойств CSS с помощью регулярных выражений:
JS:
Что используем:
Флаг m в регулярных выражениях включает многострочный режим.
26. HTML комментарии
А это очень полезная регулярка для удаления комментариев из HTML-кода:
Что используем?
Символ ? , стоящий в регулярном выражении после другого квантификатора, переводит его в ленивый режим.
27. Title
Получить заголовок веб-страницы можно с помощью такого регулярного выражения:
28. rel=«nofollow»
Важная SEO-задача, которую очень не хочется делать вручную, – добавление внешним ссылкам атрибута rel="nofollow" . Обратимся к регулярным выражениям:
PHP:
29. Медиа запросы
Если требуется проанализировать медиа-запросы CSS, воспользуйтесь этой регуляркой:
Что используем:
Класс \s обозначает пробельный символ (а также таб и перевод строки), а класс \S – наоборот, любой символ кроме пробельного.
30. Подсветка слов
Полезное выражение для поиска и выделения слов в тексте:
JS:
PHP:
Разумеется, слово ipsum можно заменить на любое другое слово или словосочетание
Другие задачи веб-разработчика
31. Проверка версии Internet Explorer
К счастью, старый добрый IE постепенно уходит в прошлое, но он все же еще играет некоторую роль в современном вебе. Этот фрагмент кода позволяет определить версию всеми любимого браузера:
32. Удалить повторы
Регулярки дают возможность автоматически удалить случайные повторы слов без проглядывания всего текста:
JS:
33. Количество слов
Порой веб-разработчику необходимо определить количество слов в строке, например, для организации ключевых слов в инструментах аналитики. Сделать это можно с помощью следующих регулярок:
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.
| Описание | |
|---|---|
| g | глобальный поиск (обрабатываются все совпадения с шаблоном поиска) |
| i | игнорировать регистр |
| m | многострочный поиск. Поясню: по умолчанию текст это одна строка, с модификатором есть отдельные строки, а значит ^ - начало строки в тексте, $ - конец строки в тексте. |
| s | текст воспринимается как одна строка, спец символ «точка» (.) будет вкючать и перевод строки |
| u | используется кодировка UTF-8 |
| U | инвертировать жадность |
| x | игнорировать все неэкранированные пробельные и перечисленные в классе символы |
Спецсимволы
| Аналог | Описание | |
|---|---|---|
| () | подмаска, вложенное выражение | |
| [] | групповой символ | |
| количество вхождений от «a» до «b» | ||
| | | логическое «или», в случае с односимвольными альтернативами используйте [] | |
| \ | экранирование спец символа | |
| . | любой сивол, кроме перевода строки | |
| \d | 3 | десятичная цифра |
| \D | [^\d] | любой символ, кроме десятичной цифры |
| \f | конец (разрыв) страницы | |
| \n | перевод строки | |
| \pL | буква в кодировке UTF-8 при использовании модификатора u | |
| \r | возврат каретки | |
| \s | [ \t\v\r\n\f] | пробельный символ |
| \S | [^\s] | любой символ, кроме промельного |
| \t | табуляция | |
| \w | [0-9a-z_] | любая цифра, буква или знак подчеркивания |
| \W | [^\w] | любой символ, кроме цифры, буквы или знака подчеркивания |
| \v | вертикальная табуляция |
Спецсимволы внутри символьного класса
| Пример | Описание | |
|---|---|---|
| ^ | [^da] | отрицание, любой символ кроме «d» или «a» |
| - | [a-z] | интервал, любой симво от «a» до «z» |
Позиция внутри строки
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
Здесь символ ^ обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \d соответствует любой цифре от 0 до 9 включительно, \w соответствует буквам и цифрам, а \W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”».
Приведенный выше код начинается с поиска любых символов, кроме пробела ( [^\s]* ), за которыми следует q . Затем парсер достигает «смотрящего вперед» утверждения. Это автоматически делает предшествующий элемент (символ, группу или символьный класс) условным — он будет соответствовать шаблону, только если утверждение верно. В нашем случае, утверждение является отрицательным ( ?! ), т. е. оно будет верным, если то, что в нем ищется, не будет найдено.
Итак, парсер проверяет несколько следующих символов по предложенному шаблону ( werty ). Если они найдены, то утверждение ложно, а значит символ q будет «проигнорирован», т. е. не будет соответствовать шаблону. Если же werty не найдено, то утверждение верно, и с q все в порядке. Затем продолжается поиск любых символов, кроме пробела ( [^\s]* ).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
По умолчанию кванторы — «жадные». Поэтому квантор + , означающий «один или больше раз», будет соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ? ) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности:
Экранирование в регулярных выражениях
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать « . » в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования.
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.<>?[\]^ <|>в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк.
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать \n , где вместо n подставить номер нужной группы. Вам может понадобиться шаблон, соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется с помощью групп:
Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более цифр ( 4+ ), и наконец \1 . Последняя часть шаблона ссылается на первую группу и ищет то же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1 будет искать «aaa» после числа.
Одним из наиболее полезных инструментов в регулярных выражениях является подстановка строк. При замене текста можно сослаться на найденную группу, используя $n . Скажем, вы хотите выделить в тексте все слова «wish» жирным начертанием. Для этого вам следует использовать функцию замены по регулярному выражению, которая может выглядеть так:
Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции):
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1 . Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ( $3 ). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или <strong> ), выделив им вторую группу, найденную по шаблону ( $2 ).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
Модификаторы добавляются в конец этой строки, вот так:
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
Многие сайты, стремясь получить как можно больше информации о своих посетителях, предлагают пройти авторизацию. Как правило, от пользователя в таких случаях необходим e-mail и личный пароль. Что же происходит с этими данными дальше?
Информация поступает на сервер, где обрабатывается при помощи специального кода. Однако часто при некорректно введенных пользовательских данных, код не может обработать информацию и выдает ошибку. Поэтому для проверки адресов электронной почты и другой текстовой информации используются регулярные выражения.
Регулярные выражения представляют собой способ поиска совпадений шаблона с текстом. Такой шаблон поиска может состоять как из отдельного символа, так и более сложных символьных комбинаций и выражений, необходимых для сопоставления с оригинальным текстом. Для поиска используется строка-образец (шаблон/pattern), которая состоит из метасимволов, задающих правило поиска.
Например:
- /example/i — регулярное выражение;
- example — шаблон для поиска;
- i — модификатор, не учитывающий при поиске регистр. Могут использоваться также модификаторы g — глобальное сопоставление (находит все совпадения, не останавливаясь после первого) и m — многострочное сопоставление.
Для работы с регулярными выражениями в Java импортируется пакет java.util.regex с классами, которые помогают сопоставлять последовательности символов с шаблонами. Внутри — три основных класса:
- Pattern — скомпилированное представление регулярного выражения.
- Matcher — выполняет операции сопоставления с последовательностью символов путем интерпретации файла Pattern.
- PatternSyntaxException — является исключением, не выполняет проверку, но указывает на синтаксическую ошибку в шаблоне регулярного выражения.
Регулярные выражения имеют довольно широкую область применения. Они могут использоваться при поиске и замене текста, редактировании и управлении данными, распознавании номеров телефонов, e-mail адресов, имен пользователей (на кириллице и латинице), сопоставлении текста с рисунком, проверке ввода веб-форм, фильтровании информации и многом другом.
Как создать регулярное выражение
Существует два способа создания регулярного выражения:
- При помощи литерала (фиксированного значения). При анализе скрипта литералы вызывают регулярное выражение. Способ используется при постоянном регулярном выражении и позволяет увеличить производительность.
Например:
- Используя конструктор объектаRegExp. Компиляция регулярного выражения происходит во время выполнения скрипта. Способ стоит использовать при изменяемом регулярном выражении.
Например:
Как создать шаблон регулярного выражения
Чтобы быстро освоить регулярные выражения, можно воспользоваться генератором регулярных выражений , например, regex101.
Чтобы создать самое простое регулярное выражение, необходимо выбрать JavaScript в левой колонке Flavor и отключить флаги multi line и global.
Например: введите в поле регулярного выражения слово map, а в тестовую строку map, cap, maps, dap, sap, MAP, lap, map, rap, tap, zap.
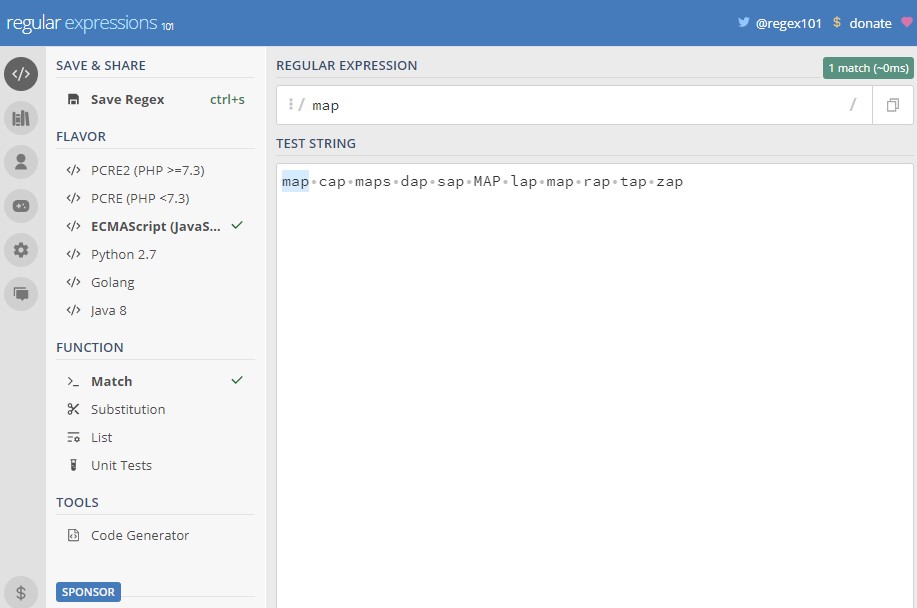
Как видим, некоторые строки в тестовой строке не совпадают. Это происходит потому, что регулярное выражение по умолчанию возвращает только первое найденное совпадение. Чтобы нашлись все совпадения, необходимо включить флаг global (g). Стоит обратить внимание, что шаблоны регулярных выражений учитывают регистр, потому следует также выбрать флаг insensitive (i).
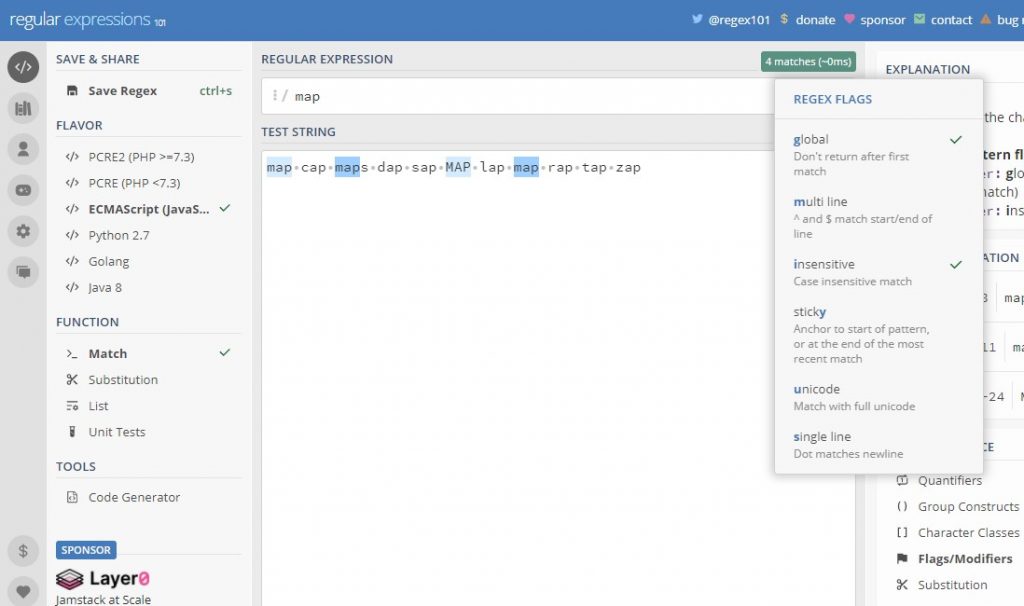
Регулярное выражение теперь имеет вид /map/gi
Регулярное выражение теперь имеет вид /map/gi, а в тестовой строке найдены все совпадения, в том числе в верхнем регистре.
Чтобы сопоставить слова map, cap, rap, необходимо расширить написание регулярного выражения и использовать наборы символов, поместив их в квадратные скобки []. Так, [mcr]ap будет соответствовать строкам:
![[mcr]ap будет соответствовать этим строкам](https://highload.today/wp-content/uploads/2021/06/image3.jpg)
[mcr]ap будет соответствовать этим строкам
Чтобы сопоставить все слова, которые заканчиваются на «-ap», есть возможность использовать диапазон [a-z]ap.![Использование диапазона [a-z]ap](https://highload.today/wp-content/uploads/2021/06/image1.jpg)
Использование диапазона [a-z]ap
Можно использовать следующие диапазоны:Использование специальных символов
Специальные символы используются для написания более сложных регулярных выражений. Они необходимы в тех случаях, когда стоит задача найти пробелы, повторяющиеся символы. Ниже предоставлен полный список таких символов.
Специальные символы регулярных выражений
● /\bbloo/ соответствует bloo в слове blood;
Работа с регулярными выражениями
В JavaScript регулярные выражения используются в методах: exec, test, match, search, replace, split.
Методы, которые используют регулярные выражения
| exec | При совпадении в строке возвращает массив и обновляет regexp. |
| test | Производит тестирование совпадений в строке. Может быть true или false. |
| match | Выполняет поиск совпадений. Возвращает массив, содержащий результаты этого поиска. |
| search | Производит тестирование совпадений в строке. Возвращает позицию первого символа в найденной строке. Если соответствие не найдено, вернет значение -1. |
| replace | Выполняет поиск совпадений в строке. Ищет строку для регулярного выражения и возвращает новую с измененными указанными значениями. |
| split | Выполняет разбиение строки с регулярным выражением в массив по указанному разделителю. |
Методы test и search позволяют узнать, есть ли в строке соответствия шаблону регулярного выражения. Для получения более полной информации используют методы exec и match.
Приведем в пример поиск совпадения в строке с использованием метода exec. Скрипт выглядит так:
Какими могут быть результаты выполнения регулярных выражений — рассмотрим в таблице ниже.
Результаты выполнения регулярного выражения
Флаги регулярных выражений
В регулярных выражениях могут применяться специальные флаги. Они влияют на поиск.
| Флаг | Описание |
| i | Осуществляется поиск без привязки к регистру. Найдет соответствия в верхнем и нижнем регистрах (D и d). |
| g | Глобальный поиск. Осуществляется поиск всех совпадений, а не только первого. |
| m | Многострочный поиск. Влияет на символы ^ (поиск совпадений в начале строки) и $ (поиск совпадений в конце строки). |
| y | Поиск по заданной позиции в исходной строке. |
| u | Поддержка Unicode. |
| s | Поиск любого символа, включая перенос строки \n. |
Флаги в шаблонах регулярных выражений используются с помощью синтаксисов:
Флаги указываются после шаблона/паттерна.
Примеры использования регулярных выражений
Проверка e-mail
Как проверить, действителен ли адрес электронной почты, введенный пользователем в соответствующее поле на сайте?
Регулярное выражение, которое соответствует любому e-mail адресу:
Проверка телефонных номеров
Этот пример может применяться для проверки любого телефонного номера:
Проверка телефонного номера с кодом конкретной страны (например, Украины):
Проверка строки с адресом видео на YouTube
Подходит для всех URL-адресов на YouTube:
Проверка формата URL
Проверка текста на повторяющиеся слова
Поиск соответствий на повторяющиеся слова:
\b — это граница слова, а \1 — ссылка на зафиксированное совпадение (первое слово).
Синтаксис поисковых запросов Google
Проверка имени пользователя
Проверка надежности паролей
Чтобы создать надежный пароль, необходимо придерживаться некоторых стандартов — использовать помимо букв и цифр другие символы в разных регистрах, а также спецзнаки. Это регулярное выражение уже содержит необходимые требования для проверки надежности паролей:
Проверка номера кредитной карты
С помощью регулярных выражений можно исключить номера платежных карт, в которых содержатся умышленные или случайные ошибки, неправильные последовательности введенных цифр:
Проверка цен
Цены имеют множество представлений и форматов. Единого регулярного выражения для них не существует. Приведем пример выражения для извлечения из текста цен в долларовом эквиваленте:
где — комбинация, которая указывает на то, что символ из 4 должен повториться дважды (дробная часть цены).
Внимание! Регулярные выражения имеют в своем арсенале специальные символы, которые в обязательном порядке необходимо экранировать. В этот список входят: . ^ $ * + ? < >[ ] \ | ( ). Перед каждым таким символом необходимо добавлять обратный слэш \.
Сервисы и приложения для проверки регулярных выражений
Чтобы не писать код с нуля, существуют специальные онлайн-инструменты, которые позволяют протестировать уже написанные регулярные выражения или используются для тренировки.
Один из лучших сервисов по созданию регулярных выражений. Позволяет сгенерировать и получить ссылку на код для JavaScript, PHP, Python. Содержит огромную библиотеку уже готовых шаблонов регулярных выражений.
Удобный онлайн-тестер для выполнения простых задач. Не генерирует код, но поддерживает замену по шаблону.
Десктопная программа с рядом преимуществ. Содержит большую библиотеку шаблонов, может генерировать код. Для удобства работа осуществляется в визуальном редакторе.
Плагин для IDE. Поддерживает замены и разделения по шаблону, включает в себя подсказки и описания используемых элементов. Не сохраняет регулярные выражения, но прекрасно подходит для их проверки перед тем, как добавить в код.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Простой метод измерения реальной скорости загрузки страниц у посетителей сайта
Как можно закэшировать данные и выиграть в производительности
Как работает Server-Sent API с примерами
Примеры применения Javascript в Nginx'e
Как просто сделать удобный дебаг и не лазить в код или как бородатые хакеры перехватывают ajax-запросы, нарушая вашу безопасность.
В своем блоге индийский разработчик Шашват Верма (Shashwat Verma) рассказал, как преобразовать веб-сайт или веб-страницу в прогрессивное веб-приложение (PWA).
Приведенные ниже примеры показывают, как использовать и составлять простые регулярные выражения. Каждый пример содержит искомый текст, одно или несколько соответствующих ему регулярных выражений, а также примечания, поясняющие использование специальных символов и форматов.
Чтобы получить дополнительную информацию, ознакомьтесь с советами по созданию фильтров содержания с использованием регулярных выражений и посетите страницу на сайте GitHub, посвященную синтаксису RE2. Также прочитайте статью о том, как настроить правила соответствия содержания.Важно! Поддерживается только синтаксис RE2, который немного отличается от PCRE. Обратите внимание, что регулярные выражения по умолчанию вводятся с учетом регистра.
Примечание. На основе примеров, приведенных ниже, можно составлять более сложные регулярные выражения. Однако для поиска отдельных слов мы рекомендуем использовать параметры Соответствие содержания и Нежелательное содержание.Пример 2: (\W|^)сборник\sзаконов(\W|$)
- \W соответствует любому символу, кроме букв, цифр и знака подчеркивания. Этот элемент исключает из поиска символы в начале или конце фразы.
- В примере 2 элемент \s соответствует пробелу, а указывает на то, что между словами сборник и законов может быть от 0 до 3 пробелов.
- ^ соответствует началу новой строки. Этот элемент позволяет искать с помощью регулярного выражения фразы, которые находятся в начале строки и перед которыми отсутствуют символы.
- $ соответствует окончанию строки. Этот элемент позволяет искать с помощью регулярного выражения фразы, которые находятся в конце строки и после которых отсутствуют символы.
- В примере 3 (s) соответствует букве и, а указывает на то, что эта буква может встречаться 0 или 1 раз в конце слова "сборник". Таким образом, регулярное выражение ищет словосочетание сборник законов и сборники законов. Другой вариант: вместо можно использовать символ "?".
- туфта
- проклятие
- убирайся
- бред
- черт возьми
- зараза
Элемент (. ) объединяет все слова, а класс символов \W применяется ко всем словам в круглых скобках.
(?i) делает выражение нечувствительным к регистру.
\W соответствует любому символу, кроме букв, цифр и знака подчеркивания. Этот элемент исключает из поиска символы в начале или конце слова или фразы из списка.
^ соответствует началу новой строки. Этот элемент позволяет искать с помощью регулярного выражения слова, которые находятся в начале строки и перед которыми отсутствуют символы.
$ соответствует окончанию строки. Этот элемент позволяет искать с помощью регулярного выражения слова, которые находятся в конце строки и после которых отсутствуют символы.
Знак | соответствует оператору "или"; таким образом, регулярное выражение будет искать каждое слово из списка по отдельности.
\s соответствует пробелу. Этот символ используется для разделения слов в фразе.
- ви@гра
- веагра
- ве@гра
- в№@гр@
- Элемент \W не используется, так как до и после любых вариантов написания слова виагра могут быть расположены другие символы. Например, регулярное выражение будет искать слово виагра в следующем тексте:
виагра!! или ***виагра***
- \W соответствует любому символу, кроме букв, цифр и знака подчеркивания. Этот элемент исключает из поиска символы в начале или конце адреса электронной почты.
- ^ соответствует началу новой строки. Этот элемент позволяет искать с помощью регулярного выражения адреса, которые находятся в начале строки и перед которыми отсутствуют символы.
- $ соответствует окончанию строки. Этот элемент позволяет искать с помощью регулярного выражения адреса, которые находятся в конце строки и после которых отсутствуют символы.
- Элемент [\w.\-] соответствует любому словообразующему символу (a-z, A-Z, 0-9 и знаку подчеркивания), точке или дефису. Эти символы используются чаще всего в первой части адреса электронной почты. Обратите внимание, что элемент \-, обозначающий дефис, должен находиться в конце списка символов, заключенных в квадратные скобки.
- Знак \ перед дефисом и точкой исключает эти символы из поиска, т. е. указывает, что тире и точка не являются специальными символами регулярного выражения. Обратите внимание, что экранировать точку, которая находится в квадратных скобках, не нужно.
- указывает на то, что перед символом @ может находиться набор символов, состоящий из 0–25 знаков. Настройки соответствия содержания в электронной почте поддерживают в регулярных выражениях наборы символов длиной до 25 знаков.
- Элемент (…) объединяет домены, а разделяющий их символ | соответствует оператору "или".
- Знак \ перед каждой точкой исключает ее из поиска, т. е. указывает, что точка не является специальным символом регулярного выражения.
- В примере 1 отсутствуют символы после последней точки, поэтому регулярное выражение будет искать все IP-адреса, которые начинаются с цифр 192.168.1., вне зависимости от последующих цифр.
- В примере 2 элемент \d соответствует любой цифре от 0 до 9 после последней точки, а указывает, что за последней точкой может следовать от 1 до 3 цифр. В этом случае регулярное выражение будет искать все полные IP-адреса, которые начинаются с цифр 192.168.1. Обратите внимание, что такое регулярное выражение также будет находить недопустимые IP-адреса, например 192.168.1.999.
Неиспользуемые символы в регулярных выражениях
Регулярные выражения со следующими символами не поддерживаются, так как могут привести к задержкам при обработке вашего письма:
Читайте также: