
Отпечаток памяти драйвера что это
Будущих учащихся на курсе «Экосистема Hadoop, Spark, Hive» приглашаем на открытый вебинар по теме «Spark Streaming». На вебинаре участники вместе с экспертом познакомятся со Spark Streaming и Structured Streaming, изучат их особенности и напишут простое приложение обработки потоков.
А сейчас делимся с вами традиционным переводом полезного материала.
Spark приложения легко писать и легко понять, когда все идет по плану. Однако, это становится очень сложно, когда приложения Spark начинают медленно запускаться или выходить из строя. Порой хорошо настроенное приложение может выйти из строя из-за изменения данных или изменения компоновки данных. Иногда приложение, которое до сих пор работало хорошо, начинает вести себя плохо из-за нехватки ресурсов. Список можно продолжать и продолжать.
Важно понимать не только приложение Spark, но также и его базовые компоненты среды выполнения, такие как использование диска, сети, конфликт доступа и т.д., чтобы мы могли принимать обоснованные решения, когда дела идут плохо.
В этой серии статей я хочу рассказать о некоторых наиболее распространенных причинах, по которым приложение Spark выходит из строя или замедляется. Первая и наиболее распространенная — это управление памятью.
Если бы мы заставили всех разработчиков Spark проголосовать, то условия отсутствия памяти (OOM) наверняка стали бы проблемой номер один, с которой все столкнулись. Это неудивительно, так как архитектура Spark ориентирована на память. Некоторые из наиболее распространенных причин OOM:
неправильное использование Spark
высокая степень многопоточности (high concurrency)
Чтобы избежать этих проблем, нам необходимо базовое понимание Spark и наших данных. Есть определенные вещи, которые могут быть сделаны, чтобы либо предотвратить OOM, либо настроить приложение, которое вышло из строя из-за OOM. Стандартная конфигурация Spark может быть достаточной или не подходящей для ваших приложений. Иногда даже хорошо настроенное приложение может выйти из строя по причине OOM, когда происходят изменения базовых данных.
Переполнение памяти может быть в узлах драйвера, исполнителя и управления. Рассмотрим каждый случай.
НЕДОСТАТОЧНО ПАМЯТИ ПРИ РАБОТЕ ДРАЙВЕРА
Драйвер в Spark — это JVM (Java Virtual Machine) процесс, в котором работает основной поток управления приложения. Чаще всего драйвер выходит из строя с ошибкой OutOfMemory — OOM (недостаточно памяти из-за неправильного использования Spark. Spark — это механизм распределения нагрузки между рабочим оборудованием. Драйвер должен рассматриваться только как дирижер. В типовых установках драйверу предоставляется меньше памяти, чем исполнителям. Поэтому мы должны быть осторожны с тем, что мы делаем с драйвером.
Обычными причинами, приводящими к OutOfMemory OOM (недостаточно памяти) драйвера, являются:
Низкий уровень памяти драйвера, настроенный в соответствии с требованиями приложения
Неправильная настройка Spark.sql.autoBroadcastJoinThreshold .
Spark использует этот лимит для распределения связей ко всем узлам в случае операции соединения. При самом первом использовании, все связи реализуются на узле драйвера. Иногда многочисленные таблицы также транслируются как часть осуществления запроса.
Попробуйте написать свое приложение таким образом, чтобы в драйвере можно было избежать полного сбора всех результатов. Вы вполне можете делегировать эту задачу одной из управляющих программ. Например, если вы хотите сохранить результаты в определенном файле, вы можете либо собрать их в драйвере, или назначить программу, которая сделает это за вас.
Если вы используете SQL (Structured Query Language) от Spark, а драйвер находится в состоянии OOM из-за распределения связей, то вы можете либо увеличить память драйвера, если это возможно; либо уменьшить значение " spark.sql.autoBroadcastJoinThreshold " (неправильная настройка порога подключения) так, чтобы ваши операции по объединению использовали более удобные для памяти операции слияния соединений.
Недостаточно памяти при работе управляющей программы
Это очень распространенная проблема с приложениями Spark, которая может быть вызвана различными причинами. Некоторые из наиболее распространенных причин — высокая степень многопоточности, неэффективные запросы и неправильная конфигурация. Рассмотрим каждую по очереди.
Высокая степень многопоточности
Прежде чем понять, почему высокая степень многопоточности может быть причиной OOM, давайте попробуем понять, как Spark выполняет запрос или задание и какие компоненты способствуют потреблению памяти.
Spark задания или запросы разбиваются на несколько этапов, и каждый этап далее делится на задачи. Количество задач зависит от различных факторов, например, на какой стадии выполняется, какой источник данных читается и т.д. Если это этап map-stage (фаза сканирования в SQL), то, как правило, соблюдаются базовые разделы источника данных.
Например, если реестр таблицы ORC (Optimized Row Columnar) имеет 2000 разделов, то для этапа map-stage создается 2000 заданий для чтения таблицы, предполагая, что обработка разделов ещё не началась. Если это этап reduce-stage (стадия Shuffle), то для определения количества задач Spark будет использовать либо настройку " spark.default.parallelism " для RDD (Resilient Distributed Dataset), либо " spark.sql.shuffle.partitions " для DataSet (набор данных). Сколько задач будет выполняться параллельно каждой управляющей программе, будет зависеть от свойства " spark.executor.cores ". Если это значение установить больше без учета памяти, то программы могут отказать и привести к ситуации OOM (недостаточно памяти). Теперь посмотрим на то, что происходит, как говорится, за кадром, при выполнении задачи и на некоторые вероятные причины OOM.
Допустим, мы реализуем задачу создания схемы (map) или этап сканирования SQL из файла HDFS (распределенная файловая система Hadoop distributed file system) или таблицы Parquet/ORC. Для файлов HDFS каждая задача Spark будет считывать блок данных размером 128 МБ. Таким образом, если выполняется 10 параллельных задач, то потребность в памяти составляет не менее 128*10 только для хранения разбитых на разделы данных. При этом опять же игнорируется любое сжатие данных, которое может привести к резкому скачку данных в зависимости от алгоритмов сжатия.
Spark читает Parquet (формат файлов с открытым исходным кодом) в векторном формате. Проще говоря, каждая задача Spark считывает данные из файла Parquet пакет за пакетом. Так как Parquet является столбцом, то эти пакеты строятся для каждого из столбцов. Она накапливает определенный объем данных по столбцам в памяти перед выполнением любой операции над этим столбцом. Это означает, что для хранения такого количества данных Spark необходимы некоторые структуры данных и учет. Кроме того, такие методы кодирования, как словарное кодирование, имеют некоторое состояние, сохраненное в памяти. Все они требуют памяти.
Spark задачи и компоненты памяти во время сканирования таблицы
Так что, при большем количестве параллелей, потребление ресурсов увеличивается. Кроме того, если речь идет о широковещательное соединении (broadcast join), то широковещательные переменные (broadcast variables) также займут некоторое количество памяти. На приведенной выше диаграмме показан простой случай, когда каждый исполнитель выполняет две задачи параллельно.
Неэффективные запросы
Хотя программа Spark's Catalyst пытается максимально оптимизировать запрос, она не может помочь, если сам запрос плохо написан. Например, выбор всех столбцов таблицы Parquet/ORC. Как видно из предыдущего раздела, каждый столбец нуждается в некотором пакетном состоянии в памяти. Если выбрано больше столбцов, то больше будет потребляться ресурсов.
Постарайтесь считывать как можно меньше столбцов. Попробуйте использовать фильтры везде, где это возможно, чтобы меньше данных попадало к управляющим программам. Некоторые источники данных поддерживают обрезку разделов. Если ваш запрос может быть преобразован в столбец(ы) раздела, то это в значительной степени уменьшит перемещение данных.
Неправильная конфигурация
Неправильная конфигурация памяти и кэширования также может привести к сбоям и замедлению работы приложений Spark. Рассмотрим некоторые примеры.
ПАМЯТЬ ИСПОЛНИТЕЛЯ И ДРАЙВЕРА
Требования к памяти каждого приложения разные. В зависимости от требований, каждое приложение должно быть настроено по-разному. Вы должны обеспечить правильные значения памяти spark.executor.memory или spark.driver.memory в зависимости от загруженности. Как бы очевидно это ни казалось, это одна из самых трудных задач. Нам нужна помощь средств для мониторинга фактического использования памяти приложения. Unravel (Unravel Data Operations Platform) делает это довольно хорошо.
YARN запускает каждый компонент Spark, как управляющие программы и драйвера внутри модулей. Переполненная память — это off-heap память, используемая для JVM в режиме перегрузки, интернированных строк и других метаданных JVM. В этом случае необходимо настроить spark.yarn.executor.memoryOverhead на нужное значение. Обычно 10% общей памяти управляющей программы должно быть выделено под неизбежное потребление ресурсов.
Если ваше приложение использует кэширование Spark для хранения некоторых наборов данных, то стоит обратить внимание на настройки менеджера памяти Spark. Менеджер памяти Spark разработан в очень общем стиле, чтобы удовлетворить основные рабочие нагрузки. Следовательно, есть несколько настроек, чтобы установить его правильно для определенной внеплановой нагрузки.
Spark определила требования к памяти как два типа: исполнение и хранение. Память хранения используется для кэширования, а память исполнения выделяется для временных структур, таких как хэш-таблицы для агрегирования, объединения и т. д.
Как память исполнения, так и память хранения можно получить из настраиваемой части (общий объем памяти — 300МБ). Эта настройка называется " spark.memory.fraction ". По умолчанию — 60%. Из них по умолчанию 50% (настраивается параметром " spark.memory.storageFraction ") выделяется на хранение и остаток выделяется на исполнение.
Бывают ситуации, когда каждый из вышеперечисленных резервов памяти, а именно исполнение и хранение, могут занимать друг у друга, если другой свободен. Кроме того, память в хранилище может быть уменьшена до предела, если она заимствовала память из исполнения. Однако, не вдаваясь в эти сложности, мы можем настроить нашу программу таким образом, чтобы наши кэшированные данные, которые помещаются в память хранилища, не создавали проблем для выполнения.
Если мы не хотим, чтобы все наши кэшированные данные оставались в памяти, то мы можем настроить " spark.memory.storageFraction " на меньшее значение, чтобы лишние данные были исключены и выполнение не столкнулось бы с нехваткой памяти.
Перегрузка памяти в менеджере узла
Spark приложения, которые осуществляют перетасовку данных в рамках групповых операций или присоединяются к подобным операциям, испытывают значительные перегрузки. Обычно процесс перетасовки выполняется управляющей программой. Если управляющая программа (исполнитель) занята или завалена большим количеством (мусора) GC (Garbage Collector), то она не может обслуживать перетасовки запросов. Эта проблема в некоторой степени решается за счет использования внешнего сервиса обмена.
Внешний сервис обмена работает на каждом рабочем узле и обрабатывает поступающие от исполнителей запросы на переключение. Исполнители могут читать перемешанные файлы с этого сервиса, вместо того, чтобы не считывать файлы между собой. Это помогает запрашивающим исполнителям читать перемешанные файлы, даже если производящие их исполнители не работают или работают медленно. Также, когда включено динамическое распределение, его обязательным условием является включение внешнего сортировочного сервиса.
Когда внешний сервис обмена данными Spark настроен с помощью YARN, NodeManager (управляющий узел) запускает вспомогательный сервис, который действует как внешний провайдер обмена данными. По умолчанию память NodeManager составляет около 1 ГБ. Однако приложения, выполняющие значительную перестановку данных, могут выйти из строя из-за того, что память NodeManager исчерпана. Крайне важно правильно настроить NodeManager, если ваши приложения попадают в вышеуказанную категорию.
Конец части №1, спасибо за внимание
Процессинг внутренней памяти Spark — ключевая часть ее мощности. Поэтому эффективное управление памятью является критически важным фактором для получения наилучшей производительности, расширяемости и стабильности ваших приложений Spark и каналов передачи данных. Однако настройки по умолчанию в Spark часто бывают недостаточными. В зависимости от приложения и среды, некоторые ключевые параметры конфигурации должны быть установлены правильно для достижения ваших целей производительности. Если иметь базовое представление о них и о том, как они могут повлиять на общее приложение, то это поможет в работе.
Я поделился некоторыми соображениями о том, на что следует обратить внимание при рассмотрении вопроса об управлении памятью Spark. Это область, которую платформа Unravel понимает и оптимизирует очень хорошо, с небольшим количеством, если таковое вообще потребуется, человеческого вмешательства. Я рекомендую вам заказать демо-версию, чтобы увидеть Unravel в действии. Мы видим довольно значительное ускорение работы приложений Spark.
Во второй части этой серии статьи напишу о том, почему ваши приложения Spark медленно работают или не работают: Во второй части цикла, посвященной искажению данных и сбору мусора, я расскажу о том, как структура данных, искажение данных и сбор мусора влияют на производительность Spark.
цель ускорить ноутбук. сначала информация.
Тип ЦП Mobile Intel Celeron M 370, 1500 MHz (15 x 100)
Видеоадаптер Mobile Intel(R) 915GM/GMS,910GML Express Chipset Family(64 Мб)
3D-акселератор Intel GMA 900 Описание устройства Mobile Intel(R) 915GM/GMS,910GML Express Chipset Family Строка адаптера Intel(R) Строка BIOS Intel Video BIOS Тип видеопроцессора Intel(R) 915GM/GMS,910GML Express Chipset
Тип DAC Внутренний Объем видеоОЗУ 64 Мб
Видеоадаптер Intel 82910GML Graphics Controller 0
Кодовое название ГП Alviso-GM
PCI-устройство 8086-2592 / 103C-099C
Тип шины Встроено
Частота RAMDAC 400 МГц
Пиксельные конвейеры 4
TMU на конвейер 1
Vertex-шейдеры 1 (v2.0)
Пиксельные шейдеры 4 (v2.0)
Аппаратная поддержка DirectX DirectX v9.0
теперь что непонятно. все настройки идут из драйвера видео,я так понял что это всё OpenGL.
ЗНАЧЕНИЕ-ДОСТУПНЫЕ НАСТРОЙКИ
Асинхронный переход-вкл,выкл
Тройная буферизация-по умолчанию,вкл,выкл
Режим перехода-переход,блит
Число битов буфера глубины-по умолчанию,16 битный буфер глубины.24 битный буфер глубины
Текстурное сжатие S3TC-вкл,откл
Текстурное сжатие FXT1-вкл,откл
отпечаток памяти драйвера-нормальный вид,меньше,больше
Глубина цветовой текстуры-глубина цветности рабочего стола,16 битов на элемент текстуры,32 битов на элемент текстуры
Азинторпная фильтрация-управление приложением,откл,вкл
Ещё раз напоминаю что почти все что я написал непонятно какие НАСТРОЙКИ ставить.
идем дальше . так как памяти всего лишь 256 то захотел поставить еще памяти. но по всей видимости тут память другая нежели у меня на компе. может кто еще знает чтото интересное про карты памяти которые вставляются в видео камеры,сотовые телефоны,итд,итп. у меня разьем есть. интересно их как дополнительную память можно использоать или они только для хранения. пока писал пришла мысль может есть в сети владелец ноутбука HP NX6110. было бы интересно по говорить. вобщем если кто что знает пишите.
там за винтиком должен быть еще слот памяти, плата памяти там чуть шире и в два раза короче. Все что тебе надо сходить и купить у хп новыую память и там в центре (если сам не справишься) ее вставить. А еще удали нахрен кучу ненужных прог что с компом грузятся, а заодно и службы в винде поодключай лишниие, что не юзаешь.

Приветствую всех!
В этой небольшой статье речь пойдет об одном способе создания разделяемой памяти, к которой можно будет обращаться как из режима ядра, так и из пользовательского режима. Приведу примеры функций выделения и освобождения памяти, а также будут ссылки на исходники, чтобы можно было попробовать любому желающему.
Драйвер собирался под 32-битную ОС Windows XP (так же проверял его работу и
в 32-битной Windows 7).
Полностью описывать разработку драйвера, начиная с установки WDK(DDK), выбора инструментов разработки, написания стандартных функций драйвера и т.д., я не буду (при желании можно почитать вот и вот, хотя там тоже не много информации). Чтобы статья не получилась слишком раздутой, опишу только способ реализации разделяемой памяти.
Немного теории
Драйвер не создает специального программного потока для выполнения своего кода, а выполняется в контексте потока, активного на данный момент. Поэтому считается, что драйвер выполняется в контексте произвольного потока (Переключение контекста). Очень важно, чтобы при отображении выделенной памяти в пользовательское адресное пространство, мы находились в контексте потока приложения, которое будет управлять нашим драйвером. В данном случае это правило соблюдается, т.к. драйвер является одноуровневым и обращаемся мы к нему с помощью запроса IRP_MJ_DEVICE_CONTROL, следовательно контекст потока не будет переключаться и мы будем иметь доступ к адресному пространству нашего приложения.
Выделение памяти
разбор функции по частям:
Сохраняем указатель, с помощью которого передадим указатель на выделенную память нашему приложению:
Следующий шаг — выделение неперемещаемой физической памяти размером memory_size и построение на ее основе структуру MDL (Memory Descriptor List), указатель на которую сохраняем в переменной pdx->mdl:
Как видно из изображения, структура MDL нам нужна для описания зафиксированных физических страниц.
Затем получаем диапазон виртуальных адресов для MDL в системном адресном пространстве и сохраняем указатель на эти адреса в переменной pdx->kernel_va:
Эта функция возвратит указатель, по которому мы сможем обращаться к выделенной памяти в драйвере (причем независимо от текущего контекста потока, т.к. адреса получены из системного адресного пространства).
В цикле запишем первые 10 ячеек памяти числами от 10 до 1, чтобы можно было проверить доступность выделенной памяти из пользовательского режима:
Теперь необходимо отобразить выделенную память в адресное пространство приложения, которое обратилось к драйверу:
Переменная pdx->vaReturned является указателем на указатель и объявляется в структуре pdx (см. driver.h в папке source_driver). С помощью нее передадим указатель pdx->user_va в приложение:
Освобождение памяти
Здесь происходит освобождение адресного пространства приложения:
ситемного адресного пространства:
затем освобождаются физические страницы:
Обращаемся к драйверу из пользовательского режима
(Весь код приложения смотрите в прилагаемых материалах)
Первое, что необходимо сделать, это получить манипулятор устройства (handle) с помощью функции CreateFile():
Вызов функции преобразуется в IRP пакет, который будет обрабатываться в диспетчерской функции драйвера (см. DispatchControl() в файле control.cpp драйвера). Т.е. при вызове DeviceIoControl() управление передастся функции драйвера, код которой выше был описан. Так же, при вызове функции DeviceIoControl() в программе DebugView (надо галочку поставить, чтобы она отлавливала события режима ядра) увидим следующее:

По возвращению управления приложению переменная vaReturned будет указывать на разделяемую память (точнее будет указывать на указатель, который уже будет указывать на память). Сделаем небольшое упрощение, чтобы получить обычный указатель на память:

Теперь по указателю data мы имеем доступ к разделяемой памяти из приложения:
При нажатии на кнопку «Allocate memory» приложение передает управление драйверу, который выполняет все действия, описанные выше, и возвращает указатель на выделенную память, доступ к которой из приложения будет осуществляться через указатель data. Кнопкой «Fill TextEdit» выводим содержимое первых 10-и элементов, которые были заполнены в драйвере, в QTextEdit и видим успешное обращение к разделяемой памяти.
При нажатии на кнопку «Release memory» происходит освобождение памяти и удаление созданной структуры MDL.
Исходники
За основу драйвера (source_driver) я взял один из примеров у Уолтера Они (примеры прилагаются к его книге «Использование Microsoft Windows Driver Model»). Так же необходимо скачать библиотеку ядра Generic, т.к. эта библиотека нужна как при сборке, так и при работе драйвера.
Тем, кто хочет попробовать сам
Создаем директорию (н-р, C:\Drivers) и распаковываем туда исходники (source_driver, source_generic_oney и source_app). Если не будете пересобирать драйвер, то достаточно установить новое оборудование вручную (указав inf-файл: sharedmemory.inf) через Панель управления-установка нового оборудования (для Windows XP). Затем надо запустить habr_app.exe (source_app/release).
Если решите пересобирать, то:
1. Необходимо установить WDK.
2. Сначала нужно будет пересобрать библиотеку Generic, т.к. в зависимости от версии ОС папки с выходными файлами могут по разному называться (н-р, для XP — objchk_wxp_x86, для Win7 — objchk_win7_x86).
3. После 1 и 2 пункта можно пробовать собрать драйвер командой «build» с помощью x86 Checked Build Environment, входящую в WDK.
Этим постом я хотел бы открыть небольшую серию статей, посвященных продуктам Intel Optane на базе технологии 3D XPoint. Мой беглый обзор русскоязычных источников показал, что хороших материалов по этому вопросу нет; кроме того, из комментариев к нашим анонсам я убедился, что существует глубокое непонимание того, зачем все это вообще нужно и почему реализовано именно таким образом.

Технология 3D XPoint
Начнем с краткой информации по самой технологии 3D XPoint (читается как «три-ди кросс-поинт»). Сразу прошу извинений — детальную информацию о технологии мы на данный момент не раскрываем. Кроме того, фокус обзоров будет именно на конечных продуктах, нежели чем на самой технологии.
Во-первых, хотя технология является совместной разработкой компаний Intel и Micron, реализация технологии в виде продуктов находится в раздельном ведении каждого из вендоров. Таким образом, всё, что я буду рассказывать о продуктах на базе 3D XPoint, имеет отношение только к продуктам Intel.
Во-вторых, 3D XPoint – это не NAND, это не NOR, это не DRAM, а совершенно другой зверь. Не раскрывая деталей физической реализации памяти, опишу ключевые характеристики, а также отличия 3D XPoint от NAND и от DRAM.
-
В отличие от NAND, нет привязки операций записи к страницам и привязки операций стирания к блокам. C 3D XPoint обращаться к данным на физическом уровне мы можем на уровне отдельной ячейки. Кроме того, нам не нужно удалять данные перед операцией записи – мы можем перезаписывать данные, что позволяет избавиться от операций read-modify-write и сильно упростить сборку мусора. Это приводит к уменьшению задержкек доступа (latency) и росту количества выполняемых операций ввода-вывода за секунду (IOPS); в дополнение к этому, операции записи выполняются почти так же быстро, как и операции чтения. Наконец, износостойкость (endurance) памяти 3D XPoint сильно выше по сравнению с NAND (такой эффект, как утечка электронов из ячеек, здесь не существует). Подводя итог, 3D XPoint быстрее и обладает большей износостойкостью по сравнению с NAND. Однако, было бы несправедливо не отметить недостаток 3D XPoint – это стоимость производства, которая на данный момент ощутимо выше по сравнению со стоимостью производства 3D NAND.
Intel Optane
На данный момент, официально анонсировано и выпущено на рынок 2 принципиально разных продукта: Intel Optane Memory – для клиентских моделей использования — и Intel® Optane SSD DC P4800X – для серверного использования. В данной статье мы подробнее разберем клиентский продукт, серверный же будет темой следующего обзора.
Итак, Intel Optane Memory. Первое, что стоит понять об этом продукте – несмотря на название, это не DRAM, а NVMe SSD в форм-факторе M.2 2280-S3-B-M.
Вид сверху – под наклейкой 1 чип 3D XPoint (это версия 16ГБ, на 32ГБ расположены 2 чипа 3D XPoint – площадки под второй чип видны):

Модуль односторонний, так что обратная сторона пустая:

Устройство соответствует спецификации NVM Express 1.1. На данный момент на рынок выпущены емкости 16ГБ (используется один чип памяти 3D XPoint емкостью 16ГБ) и 32ГБ (используются два чипа памяти 3D XPoint емкостью 16ГБ каждый). Из интересных деталей дизайна:
- контроллер явлется внутренней разработкой Intel
- в дизайне не используется DRAM
- используются только 2 линии PCIe gen3, а не 4 линии, как многие могли бы ожидать
- заявленная износостойкость – 100ГБ записанных данных каждый день в течение 5 лет
Тест производительности
Теперь о производительности

(производительность версии 32ГБ выше из-за того, что используются 2 чипа памяти 3D XPoint против одного чипа у версии 16ГБ)
Казалось бы, производительность в плане пропускной способности и IOPS не впечатляет – однако, собака зарыта совсем не тут. Вся штука в том, что эти данные производительности замерялись при глубине очереди (queue depth) равной 4 – в отличие от прочих SSD, которые обычно замеряются с глубиной очереди 32 и выше. Именно на неглубоких очередях более всего заметно превосходство Optane. Для наглядности, вот график производительности разных типов устройств на разной глубине очереди*:

При этом, как показывают наши внутренние тесты, подавляющее большинство задач, с которыми сталкивается обычный пользователь дома или в офисе, имеют глубину очереди от 1 до 4 (более подробно – см. ниже), а спецификации SSD пишутся с использованием нагрузок с глубиной очереди 32 (для SATA) и более (для NVMe). Разница весьма наглядна.
Однако, Intel не позиционирует использование Optane Memory в качестве обычного SSD по понятным причинам – емкости устройств не хватит для пользовательских задач (за исключением некоторых интересных вариантов, как, например, небольшой, но быстрый и надежный загрузочный накопитель для Linux, или scratch disk для Adobe Photoshop, или небольшой, но быстрый кэш вместе с Intel Cache Acceleration Software, или интересное решение, описанное вот тут). Вся сила маркетингового аппарата Intel направлена на продвижение новой технологии ускорения (грубо говоря – кэширования, но это не совсем точное определение) медленного SATA-накопителя (будь то жесткий диск, твердотельный накопитель или даже некоторые гибридные модели) быстрым модулем Optane Memory.
Эта модель использования накладывает ограничения на поддерживаемые железо и ОС:
- Процессор Intel Core 7-го поколения или новее
- Чипсет Intel 200 Series или новее (полный список тут)
- BIOS, в который интегрирован UEFI-драйвер RST версии 15.5 или новее (15.7 для серии чипсетов X299). Да, legacy-режим БИОСа не поддерживается – для Optane Memory обязательна загрузка в режиме UEFI
- Windows 10 64-bit
- Драйвер Intel Rapid Storage Technology 15.5 или новее
- Загрузочный SATA-накопитель (именно его будет ускорять Optane Memory). Поддерживается только разметка GPT.
- 5МБ свободного пространства в конце SATA-накопителя – это нужно для метаданных RST
-
Убеждаемся, что BIOS материнской платы поддерживает Optane (см. выше; сейчас все “Optane Memory Ready” платы на 200 сериях чипсетов отгружаются с БИОСом, который поддерживает Optane Memory, однако на рынке еще можно найти платы из предыдущих партий – на них потребуется обновить БИОС).
И да, Intel провел громадную работу с производителями плат – все платы, которые поддерживают Optane Memory, имеют на коробке вот такой шильдик:
- Более быстрая загрузка операционной системы;
- Ускорение большинства операций ввода-вывода (по сути – кэширование, однако достаточно умными алгоритмами).
Принцип работы
Также немного поговорим о том, как это все работает.
Во-первых, в момент активации Optane Memory, RST драйвер перенесет файлы, необходимые для загрузки ОС, а также файловую таблицу на быстрый Optane Memory накопитель. Ключевое здесь – именно перенесет, а не скопирует. Механика работы RST драйвера такова, что не все данные, лежащие в кэше на быстром устройстве, будут в обязательном порядке скопированы на медленное устройство. Это увеличивает общее быстродействие системы и, кроме того, решает проблему синхронизации данных. Однако, как можно понять, физический сбой Optane Memory с большой вероятностью приведет к потере доступа к данным на SATA-диске. Из-за того, что перенос данных происходит сразу в момент активации Optane Memory, уже первая же загрузка системы будет быстрее, чем до Optane Memory (особенно это заметно, если ускорялся жесткий диск, нежели чем SATA SSD – однако, и в последнем случае стоит ожидать увеличения производительности системы хранения).
Во-вторых, во время работы системы RST драйвер будет непрерывно производить кэширование. И здесь существует одно важное различие между модулями Optane Memory разной емкости – на устройстве емкостью 16ГБ поддерживается только кэширование на уровне блоков, на устройстве емкостью 32ГБ – кэширование на уровне блоков и кжширование на уровне файлов (оба работают одновременно). В случае блочного кэширования, решение о кэшировании того или иного блока происходит мгновенно в момент запроса на ввод-вывод. В случае файлового кэширования, драйвер мониторит частоту доступа к файлам и кладет все это в специальную таблицу, которую затем (в момент простоя системы или по расписанию пользователя) использует для определения того, какие файлы остаются в кэше, какие удаляются, а какие добавляются.
Оба вида кэширования используют довольно умные, на мой взгляд, алгоритмы принятия решения о кэшировании – глубоко описывать я их здесь не могу, но для общего понимания отмечу, что, например, не кэшируются видеофайлы (да, драйвер смотрит на расширение файла), в расчет принимается размер файла, определяется вид нагрузки – предпочтение в кэшировании отдается случайному доступу нежели чем последовательному, что имеет смысл в силу крайне медленной работы жестких дисков на операциях случайного доступа, и т.п. В интернетах я встречал некоторые негативные комментарии на тему того, что «кэш моментально забьется данными», «емкости 16ГБ ни на что не хватит» и тому подобное – как правило, это отзывы от людей, которые никогда не тестировали Optane Memory. Я еще не слышал негативных отзывов о производительности такого решения ни от кого из наших партнеров, с которыми работаю.
Несколько очень важных моментов.
-
Если при включенном ускорении системы с помощью RST драйвера и Optane Memory необходимо подключить SATA-накопитель к другой системе, то нужно либо переносить всю конфигурацию (SATA-устройство + Optane Memory, при этом надо убедиться, что новая система поддерживает Optane Memory), либо предварительно выключить ускорение (это делается нажатием одной кнопки в утилите – при этом в момент выключения данные из кэша перенесутся на SATA-устройство, метаданные RST будут удалены, устройство Optane Memory будет очищено).
Зачем это нужно
Теперь пришло время подробнее поговорить про то, зачем все это вообще нужно. Начнем с более детального анализа нагрузок, которые испытывают системы обычных пользователей ПК. Еще до окончания разработки продукта Optane Memory, в рамках Intel Product Improvement Program мои коллеги провели исследование на предмет того, что обычные пользователи делают с компьютером дома и на работе. Результаты – количество действий разных типов, производимых пользователями (усредненные данные на 1 день пользования ПК):

Все эти события тесно связаны с производительностью системного диска, причем, как правило, они требуют случайного доступа к данным, с чем жесткие диски справляются крайне плохо. Таким образом, использование Optane Memory может значительно ускорить исполнение каждого из указанных выше действий.
Однако, имейте в виду, что с Optane Memory никакого ручного переноса данных не требуется – как только вы перестаете пользоваться одним приложением и начинаете активнее пользоваться другим, необходимые данные буду довольно быстро добавлены в кэш. С другой стороны, вспомним график, который я привел выше – производительность в зависимости от глубины очереди. На небольших очередях задержки доступа к данным на Optane Memory гораздо ниже по сравнению с SATA SSD. Внутри Intel мы замерили, какая глубина очереди используется различными приложениями – вот результаты:
Глубина очереди при использовании приложений:


Глубина очереди при запуске приложений:
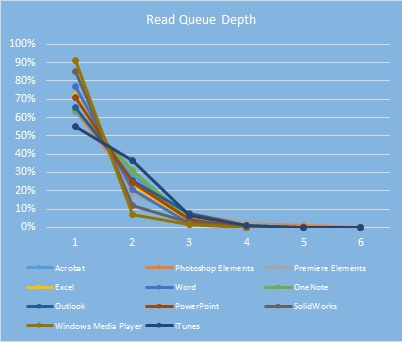

Распределение глубины очереди в течение типичного рабочего дня корпоративного пользователя (замерено на сотрудниках Intel, занимающих разные должности в компании):

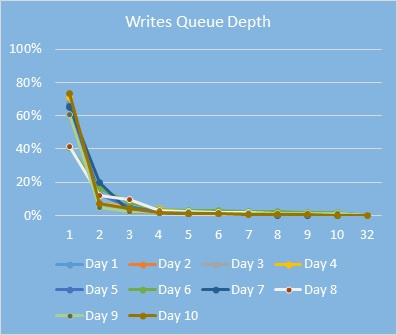
Таким образом, распределение глубины очереди разных пользовательских нагрузок:
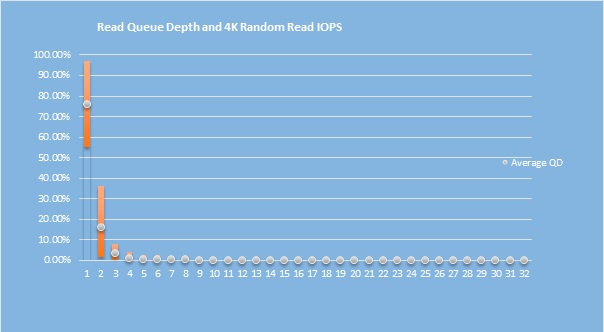
И мы уже видели, насколько лучше Optane Memory справляется в работой на неглубоких очередях.
Сравнение производительности системы с HDD против такой же системы с HDD + Optane Memory:
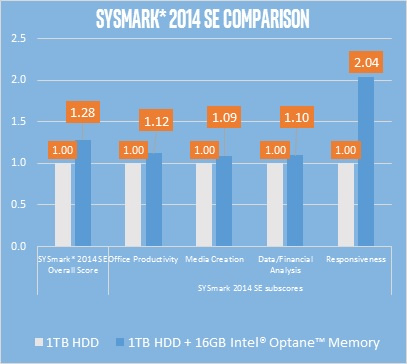
Еще одно интересное сравнение – тот же тест, но в системе без Optane Memory в 2 раза больше оперативной памяти:
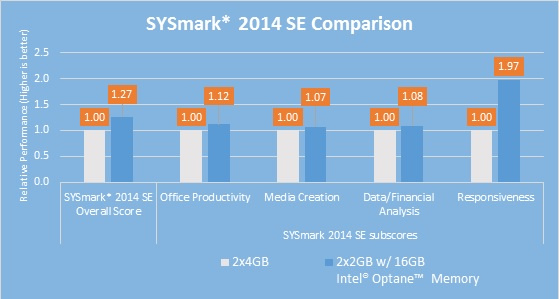
И, на самом деле, это весьма валидное сравнение. Хотя некоторые виды нагрузок требуют большого количества оперативной памяти, львиная их доля требований к большим объемам памяти не имеет. Таким образом, для многих пользователей может иметь смысл поставить 4 ГБ памяти вместо 8 ГБ, а сэкономленные деньги вложить в ускорение системы хранения.
Заключение
Подводя итог, напомню, что Optane Memory может использоваться как самостоятельный SSD, но это не основная модель использования. Вся магия происходит при его использовании как ускорителя для медленного жесткого диска (или даже SATA SSD) – сравнительно небольшое вложение денег может ускорить быстродействие системы в несколько раз на большинстве пользовательских нагрузок. Это достигается за счет как аппаратной части (Optane Memory имеет ощутимо меньшие задержки доступа по сравнению с другими SSD на рынке, быстродействие на небольших очередях значительно выше альтернативных решений), так и программной – драйвер RST использует достаточно продвинутую логику для осуществления операций кэширования (и в этом отличие от предыдущей технологии – Intel Smart Response Technology). Это делает текущую реализацию отличной от всех тех решений по кэшированию/ускорению жестких дисков, что выспукались на рынок ранее, в том числе нами же.
Я очень заинтересован узнать мнение о продукте и решении в целом из комментариев – однако, хотелось бы избежать негатива во мнениях из-за непонимания работы решения или отсутствия опыта его использования. Если есть сомнения – лучше спросите, прежде чем пускаться в критику.
P.S. в следующей статье мы разберем серверный продукт на базе технологии 3D XPoint — Intel Optane SSD DC P4800X Series – вкупе с программным решением Intel Memory Drive Technology.
* Все тесты, указанные в этой статье, были проведены внутри Intel. Все тесты с Optane Memory были проведены на процессорах Intel Core 7-го поколения, тесты на глубину очереди с использованием процессора Intel Core 6-го поколения. Конфигурация системы, использованной для тестов:
Читайте также: