
Некорректный формат url файла sitemap
User-agent: *
Sitemap : /sitemap.xml
Disallow: /address_book_process.php
Disallow: /ajax_shopping_cart.php
Disallow: /account.php
Disallow: /account_edit.php
Disallow: /account_edit_process.php
Disallow: /account_history.php
Disallow: /account_history_info.php
Disallow: /address_book.php
Disallow: /advanced_search_result.php?
Disallow: /affiliate_affiliate.php
Disallow: /ask_a_question.php
Disallow: /checkout_alternative.php
Disallow: /checkout_process.php
Disallow: /advanced_search.php
Disallow: /advanced_search_result.php
Disallow: /cache/
Disallow: /admin/
Disallow: /checkout_address.php
Disallow: /checkout_confirmation.php
Disallow: /checkout_payment.php
Disallow: /checkout_success.php
Disallow: /checkout_shipping.php
Disallow: /contact_us.php
Disallow: /create_account.php
Disallow: /create_account_guest.php
Disallow: /create_account_process.php
Disallow: /create_account_success.php
Disallow: /featured.php
Disallow: /index.php/manufacturers_id/
Disallow: /info_shopping_cart.php
Disallow: /shopping_cart.php
Disallow: /login.php
Disallow: /logoff.php
Disallow: /newsletter.php
Disallow: /products_new.php
Disallow: /password_double_opt.php
Disallow: /popup_image.php
Disallow: /popup_search_help.php
Disallow: /product_notifications.php
Disallow: /product_reviews.php
Disallow: /product_reviews_info.php
Disallow: /shipping.php
Disallow: /media/export/
Disallow: /media/download/
Disallow: /includes/
Disallow: /media/pub/
Disallow: /media/
Disallow: /index.php/action/
Disallow: /articles.php
Disallow: /articles_new.php
Disallow: /article_info.php/action/
Disallow: /product_info.php/action/
Disallow: /manu/
Disallow: /index.php/manu
Disallow: /index.html?products_id
Disallow: /cookie_usage.php
Disallow: /index.php/products_id
Disallow: /index.php?action=buy_now
Disallow: /specials.php/action/buy_now
Disallow: /market.php
Disallow: /*action=buy_now
Предупреждения
Доступ к URL заблокирован в файле robots.txt.
Файл Sitemap содержит URL, доступ к которым заблокирован в файле robots.txt.

хотя он сам проверил robots нечего не понимаю :-[
При скормление robots.txt в Яндексе ошибка

Но сайт в Яндексе еще не начал индексирование может из за этого
Проверял sitemap ошибок не найдено
В Disallow: /*action=buy_now убери звездочку.
Яндекс достаточно медлительный при начальном индексировании, минимум одна-две недели.
Если по прошествии времени сдвигов не будет, дай Яндексу полный доступ, типа:
И по мере индексирования вводи требуемые ограничения на индексацию.
И по мере индексирования вводи требуемые ограничения на индексацию.ограничения?зачем?и как? :-\
Спасибо звездочку убрал будем тогда ждать!
Ограничения это запрет индексации роботом поисковых систем определенных страниц на Вашем сайте. Файл robots.txt на ShopOS написан не зря, хотя нужно и его корректировать под свои нужды. Пробуй, бери по очереди каждую стоку и вставляй в свой браузер, смотри, дальше решение за тобой, открывать её для робота или нет. Не забудь указать полный путь, как в Sitemap.
Парень. В корне сайта лежит файл .htaccass в нём сделай правку.
Найди строку
Перед ней, ПЕРЕД НЕЙ пропиши правило
RewriteRule sitemap.xml index.php?page=xml_sitemap
И будэ тоби щастя.))
спасибо но счастье не наступило((((((
это 151 заблокировано у меня. ппц :-\
при проверки Sitemap
Ребят посмотрите мой robots.txt все ли верно.
Яша начал индексировать и уже 16 страниц полетели черт знает куда.
А Гугл это нормально.
Раз уж прописали в htaccess правило для карты сайта, то и в файле robots.txt нужно указать /sitemap.xml
Ну и в ПС толкать ваш-сайт.ру/sitemap.xml
Или я чего не понял?
спасибо!Всем вроде как помогло. а там посмотрим.
Вы мне не подскажете, где я могу найти больше информации по этому вопросу?
Перечень ошибок, возникающих при обработке файла Sitemap .
Загрузка файла Sitemap закончилась неудачно. Возможно URL файла задан неверно.
Размер файла Sitemap больше 50 МБ.
Указан невалидный URL файла Sitemap .
В процессе загрузки файла Sitemap сервер прервал соединение.
Не удалось загрузить файл из-за ошибки DNS. Возможно указан неправильный URL файла.
Файл Sitemap не удалось загрузить, так как не удалось соединиться с сервером.
URL файла Sitemap запрещен в файле robots.txt и поэтому не был загружен. Проверьте правильность файла robots.txt и адрес файла Sitemap .
При загрузке файла Sitemap сервер вернул пустой документ.
Произошла ошибка при распаковке файла Sitemap , сжатого с помощью gzip.
Указанный тег должен встречаться в данном контексте только один раз.
Указанный тег не должен встречаться в данном контексте.
Пропущен обязательный тег.
URL не соответствует стандарту.
Местоположение файла Sitemap определяет набор URL, которые можно включить в этот файл. Файл, расположенный в некотором каталоге, должен содержать URL, который размещен в этом же каталоге, либо в его подкаталогах. Подробнее см. Местоположение файла Sitemap.
Длина URL превышает установленный предел (1024 символа).
Указанный тег не должен быть пустым.
Указанный тег не должен содержать дочерние теги.
Указанный тег содержит слишком много данных.
Указанный тег не содержит необходимых данных.
Файл Sitemap не начинается с корректного префикса UTF-8 (0xEF 0xBB 0xBF). Он должен начинаться со строки <?xml version=\"1.0\" encoding=\"UTF-8\"?>
Файл Sitemap не является правильно построенным (well-formed) XML-документом, то есть не соответствует правилам синтаксиса XML.
В файле Sitemap обнаружено более 100 ошибок. Дальнейшая обработка файла прекращена.
Файл Sitemap может содержать не более 50000 URL. Если необходимо перечислить более 50000 URL, следует создать несколько файлов Sitemap и включить их в файл индекса Sitemap (см. Использование файлов индекса Sitemap).
Файл индекса Sitemap может содержать не более 50 000 URL файлов Sitemap .
Файл Sitemap начинается с идущих подряд некорректных URL. Дальнейшая обработка файла прекращена, так как скорее всего файл имеет неверный формат.
Файл индекса Sitemap может содержать ссылки только на файлы Sitemap , но не на другие файлы индекса Sitemap .
Robots.txt - это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы или разделы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие - нет.
Почему robots.txt важен для продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Ниже приведены ссылки на инструкции по использованию файла robots.txt:
Содержание отчета

- Кнопка «обновить» - при нажатии на неё данные о наличии ошибок в файле robots.txt обновятся.
- Содержимое строк файла robots.txt.
- При наличии в какой-либо директиве ошибки Labrika дает её описание.
Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом ":".
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent. Это основная директива, которая указывает, для какого поискового робота прописаны дальнейшие правила индексации.
Не указан пользовательский агент.
Каждое правило должно содержать не менее одной директивы «Allow» или «Disallow». Disallow закрывает раздел или страницу от индексации, Allow открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге). Эти директивы задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: / , то есть "не запрещать ничего".
Пример ошибки в директиве Sitemap:
Не указан путь к карте сайта.
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Найдено несколько правил вида "User-agent: *"
Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
запрещает всем поисковым роботам индексирование всего сайта.
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущены ошибки синтаксиса, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле - 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки. Например:
запрещает индексировать любые php файлы.
- Звездочка «*» обозначает любую последовательность и любое количество символов.
- Знак доллара «$» означает конец адреса и ограничивает действие знака «*».
Например, если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак "$" можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Правило начинается не с символа "/" и не с символа "*".
Правило может начинаться только с символов «/» и «*».
Значение пути указывается относительно корневого каталога сайта, на котором находится файл robots.txt, и должно начинаться с символа слэш «/», обозначающего корневой каталог.
Правильным вариантом будет:
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
Sitemap - это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо обходить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы «Crawl-delay»
Директива Crawl-delay задает роботу минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей.
Использовать директиву Crawl-delay следует в тех случаях, когда сервер сильно загружен и не успевает обрабатывать запросы поискового робота. Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии.
При указании интервала можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды:
К ошибкам относят:
- несколько директив Crawl-delay;
- некорректный формат директивы Crawl-delay.
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере.
Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Некорректный формат директивы «Clean-param»
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд "&" подряд:
Правило должно соответствовать виду "p0[&p1&p2&..&pn] [path]". В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: ".", "-", "/", "*", "_".
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark - маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
При создании и редактировании файла с помощью стандартных программ редакторы могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
При использовании маркера последовательности байтов в файлах .html сбиваются настройки дизайна, сдвигаются блоки, могут появляться нечитаемые наборы символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Как избавиться от BOM меток?
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать - открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».


В этой статье вы узнаете, как работает карта сайта, в каком формате она должна быть, и о нескольких различных способах решения этой проблемы.
Что такое карта сайта?
Вы знаете, как поисковые системы находят ваш вебсайт? С помощью небольшого удобного бота, называемого веб-сканером – автоматизированного инструмента, рассылаемого поисковыми системами для индексации страниц вашего сайта.
С миллионами страниц в сети сбор информации о каждом сайте был бы невозможен. Поэтому в Интернете работают поисковые роботы, кэшируя информацию на каждой странице и на всех носителях.
Это кажется достаточно простым, но Google не знает, когда вы добавляете новую страницу на свой вебсайт, например, когда вы публикуете пост в блоге или выпускаете новый продукт в своем магазине. Они периодически отправляют поискового робота посетить ваш сайт и посмотреть, не изменилось ли что-нибудь, но этот процесс не происходит мгновенно.
Когда у вас огромный веб-сайт, поисковому роботу легко пропустить ключевые страницы даже после нескольких посещений. В первую очередь вызывает беспокойство то, что на такие страницы нечасто ссылаются.
Вот где на помощь сканерам приходят карты сайта. Эти XML-файлы отличаются от обычных страниц; они обычно не читаются людьми и не предназначены для просмотра посетителями. Но поисковые роботы могут использовать их, чтобы все проиндексировать.
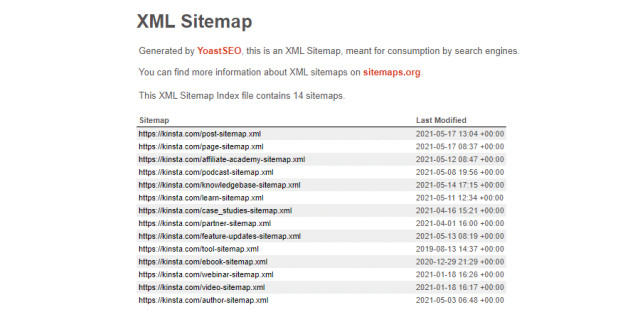
Они работают, просто перечисляя все страницы вашего сайта вместе с их иерархией ссылок, а также другие файлы на вашем сайте, такие как изображения и видео. Это гарантирует, что Google видит все на вашем проекте и соответственно улучшит SEO.
Если вы использовали такой инструмент, как Google Analytics или Google Search Console, возможно, видели возможность ссылки на свою карту сайта. Google будет ссылаться на это в первую очередь, когда отправит поисковые роботы на вебсайт.

Различия между файлами Sitemap в формате HTML и XML
Итак, ваша карта сайта – это HTML-страница, но в чем именно проблема? Почему Google хочет, чтобы вы его изменили?
Файлы Sitemap должны быть написаны в определенном формате, чтобы поисковые роботы поняли их. В большинстве случаев это должен быть файл XML. Они также могут читать RSS, Atom, KML или текстовый файл, но XML – наиболее распространенный выбор.

XML означает «расширяемый язык разметки». Это веб-язык, очень похожий на HTML. Разница заключается в его использовании: хотя он удобочитаем, его основная функция – помогать машинам кодировать документы и читать данные.
В этом случае это помогает поисковому роботу понять, где находятся страницы и другие носители на вашем сайте и как они взаимодействуют друг с другом.
Но вы, возможно, видели термин «карта сайта», который раньше использовался в совершенно другом контексте. Карты сайта в формате HTML существуют, но разница в том, что они созданы для людей, а не для поисковых роботов.
Если вы когда-либо щелкали ссылку на навигацию сайта и находили удобочитаемый и приятно оформленный список страниц на сайте, это карта сайта. Она может быть полезна вашим посетителям, но это не то, что ищет Google.
Карта сайта XML для большинства пользователей будет выглядеть как беспорядок из нечитаемого кода или огромная стена ссылок. Поэтому, если вы хотите добавить полезную страницу навигации на свой сайт, то можете создавать карту сайта HTML, но вы должны создать XML карту сайта также.
Другие типы файлов Sitemap
Когда вы думаете о карте сайта, на ум приходит простой список страниц вашего сайта. Но Google использует несколько различных типов карт сайта для каталогизации различной информации:
Обычно часть этой информации содержится в вашей основной карте сайта. Для других – должна быть специальная карта сайта. И, в конце концов, все они должны соответствующим образом быть отформатированы в XML или в другом поддерживаемом формате, а не в HTML.
Смотрите также:
Плагин Rank Math SEO – поисковая оптимизация для WordPress, аналог Yoast SEO
Как создать XML-карту сайта
Если вы намеренно отправили ссылку на карту сайта в формате HTML, вам необходимо заменить ее XML-файлом. Если вы не знаете, как его создать, есть несколько разных способов создать его с помощью плагинов и генераторов WordPress.
Даже если у вас есть карта сайта XML, которая просто не работает, восстановление или отправка другой карты сайта сможет решить проблему.
Есть два простых способа получить карту сайта: использовать плагин или создать его с помощью карты сайта.
Создайте карту сайта с помощью плагина
С WordPress самый простой способ получить динамически обновляемую карту сайта на вашем сайте – это загрузить плагин. Таким образом, не нужно загружать файлы на сервер вручную.
Есть довольно много плагинов, которые генерируют карту сайта:
- Yoast SEO : самый популярный плагин для SEO в репозитории, который также поддерживает создание карты сайта. Вы можете найти настройки в разделе SEO > Общие > Функции и XML-файлы Sitemap.
- RankMath : помимо обычной карты сайта, этот плагин SEO может создавать карту сайта WooCommerce и карту сайта геоданных KML. Перейдите в RankMath > Настройки карты сайта.
- XML-файлы Sitemap : как следует из названия, плагин создает карту сайта. Он бесплатный и с открытым исходным кодом, поэтому скрытых комиссий нет.
- XML Sitemap и Google News : этот плагин генерирует XML-карту сайта и карту сайта Google News. Его легко установить и настроить.
- Companion Sitemap Generator – HTML & XML : если вы хотите сгенерировать карту сайта в формате HTML вместе с картой сайта в формате XML, этот плагин для вас. Оба обновляются автоматически, поэтому вам не нужно выполнять какую-либо ручную работу.
Сайты-генераторы файлов Sitemap
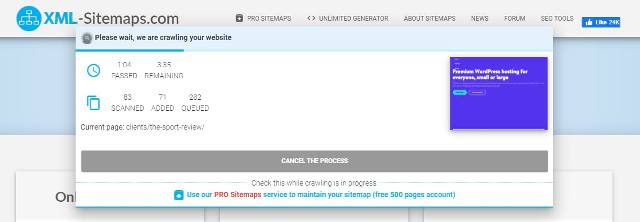
Вместо плагина можно использовать генератор карты сайта, такой как XML-Sitemaps или XML Sitemap Generator . Затем вы можете загрузить его на свой сайт.
Шаг 1. Создайте карту сайта, используя один из указанных выше сайтов или любой генератор по вашему выбору. Загрузите XML-документ.
Шаг 2: Загрузите FileZilla или используйте свой веб-хостинг для подключения к вашему сайту через FTP.
Шаг 3: Поместите XML-файл в корневую папку вашего сайта. Корневой каталог – это самый верхний каталог вашего сайта – тот же каталог, с которого вы начинаете при первом подключении.
В отличие от карт сайта на основе плагинов, карты сайта, созданные с помощью веб-сайта, не являются динамическими. Статические карты сайта не будут обновляться по мере публикации новых записей и страниц на сайте. Вам нужно каждый раз создавать новый файл. Так что для блогов и других сайтов, которые часто обновляются, это не идеально.
Ошибка карты сайта часто вызвана случайной отправкой HTML-страницы, а не правильно отформатированного XML-файла. Но если ваша XML-карта сайта по-прежнему претендует на роль HTML-страницы, у вас может быть более серьезная проблема.
Проблема обычно заключается в легко решаемом конфликте в ваших плагинах WordPress. Вот несколько советов, как заставить вашу карту сайта снова работать правильно.
Проверить на ошибки и перенаправления
Намного проще диагностировать проблему, если у вас есть явный код ошибки для поиска. Первое, что вам нужно сделать, это посетить страницу карты сайта и посмотреть, нет ли там каких-либо странных кодов ошибок.
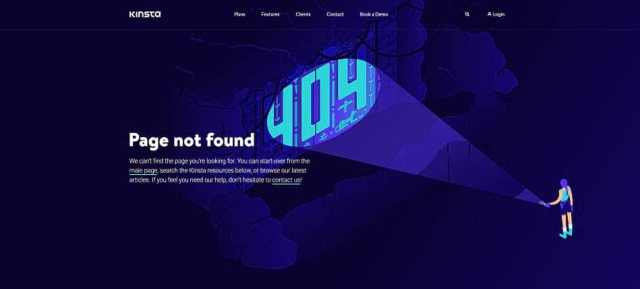
Если вы заметили ошибку при посещении карты сайта, это заставит Google подумать, что он видит HTML-страницу.
Что делать, если вы периодически замечаете ошибку карты сайта – иногда она есть, а иногда нет? Это может произойти, если вы динамически создаете карту сайта.
Еще одна вещь, на которую следует обратить внимание, – это перенаправления. Если вы посетите свою страницу карты сайта и внезапно окажетесь на главной странице или в бесконечном цикле перенаправления, это также приведет к ошибке.
Если вы обнаружите какие-либо ошибки или перенаправления, которые не исчезают, проблема обычно заключается в конфликте плагинов. Плагины, которые генерируют карты сайта, такие как Yoast, могут вызывать конфликт, или источником проблемы может стать плагин кеширования.
Но иногда даже кажущиеся случайными плагины могут вызывать конфликты. Используйте плагин проверки работоспособности и устранения неполадок (Health Check & Troubleshooting) чтобы идентифицировать их.
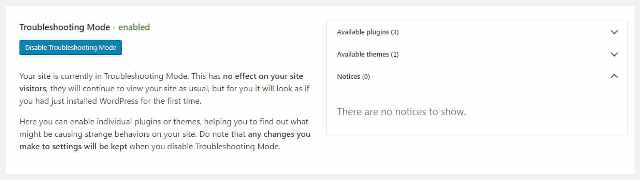
Установите плагин, если его еще нет, затем перейдите в Инструменты > Работоспособность сайта > Режим устранения неполадок. Он временно отключит все плагины, не затронув ваших посетителей.
Посмотрите, исчезла ли ошибка или перенаправление на вашем сайте. Если это так, повторно активируйте плагины один за другим, пока сайт снова не сломается. Ищите конфликты между несколькими плагинами.
Теперь вы можете связаться с авторами плагинов, чтобы сообщить об ошибке и попросить о помощи.
Отключить кеширование
Одна из основных причин конфликтов – это плагины кеширования. Когда карта сайта кэшируется, это может иногда вызывать проблемы с тем, что Google читает ее как HTML-страницу, так как вам не следует кэшировать XML-файлы таким образом. Из-за этого большинство плагинов кэширования избегают кеширования страницы карты сайта, но они все равно могут делать это ошибочно, особенно если вы используете уникальный URL-адрес для своей карты сайта.
К счастью, вам не нужно отключать весь плагин кеширования. Вы можете добавить исключение, и проблема должна исчезнуть автоматически.
Это должно быть описано в документации вашего плагина. Пример, как это можно сделать в WP Super Cache и W3 Total Cache , читайте ниже.
Для WP Super Cache перейдите в Настройки > WP Super Cache. На вкладке «Дополнительно» прокрутите до пункта «Добавить сюда строки (не имя файла)», что заставляет страницу не кэшироваться.
Для W3 Total Cache перейдите в «Производительность» > «Кэш страниц», затем найдите «Дополнительно»> «Никогда не кэшировать следующие страницы». Как и в случае с WP Super Cache, введите URL-адрес карты сайта.
Проверьте URL вашего файла Sitemap
Хотя это небольшое предположение, всегда стоит перепроверить: вы отправили правильную ссылку? Это элементарная ошибка, и даже один неверный символ укажет не на то место.
Проверьте ссылку, которую вы отправили, как через Google, так и в любых плагинах SEO или Sitemap.
Снова включите режим устранения неполадок в плагине проверки работоспособности и попытайтесь найти, какой плагин вызывает эту проблему.
Удалить лишние файлы Sitemap
Хотя обычно это не вызывает проблем, пока вы ссылаетесь на правильную страницу, наличие дополнительных активных карт сайта может иногда вызывать проблемы или путаницу для вас. Кроме того, ваш сервер тратит дополнительные ресурсы на обновление нескольких ненужных карт сайта.
Плагины могут добавлять разные карты сайта, и вы даже не догадываетесь, что WordPress создает для вас свои собственные. Поэтому нужно проверить и удалить все, кроме того, который хотите использовать. Вот несколько URL-адресов, которые можете проверить на своем сайте:
- /sitemap.xml – стандартный выбор для сгенерированных карт сайта в большинстве плагинов для карт сайта.
- /wp-sitemap.xml – это карта сайта по умолчанию, созданная WordPress начиная с версии 5.5.
- /sitemap_index.xml – URL-адрес карты сайта, созданной Yoast.
А если вы загрузили другие плагины для SEO или карты сайта, они могут использовать совершенно другие URL. Проверьте документацию и убедитесь, что вы отключили все функции карты сайта, которые не нужны.
Вам действительно нужен файл Sitemap?
Иногда карты сайта могут необъяснимо быть источником постоянного потока проблем. И простого исправления может быть недостаточно, чтобы они исчезли. Если вы постоянно сталкиваетесь с трудно решаемыми проблемами, то начнете сомневаться в том, важна ли для вас карта сайта.
Обычно рекомендуется создавать карту сайта, но Google заявляет, что никогда не будет наказывать ваше SEO за отсутствие карты сайта. Карта сайта может только помочь улучшить ваше SEO и ускорить индексацию вашего сайта.
Но не обязательно, чтобы он был у вас в определенных ситуациях, и сам Google предлагает не использовать их на некоторых сайтах.
Предположим, на вашем сайте меньше 500 страниц, и вряд ли когда-либо будет больше. В этом случае, если сайт имеет внутренние ссылки (что вам все равно следует делать) и не имеет большого количества мультимедийных файлов, которые вы хотите отображать в Google Images и Google Video, вам может вообще не понадобиться карта сайта.
С другой стороны, наличие карты сайта действительно поможет вашему оптимизатору поисковых систем, и в ее наличии нет ничего плохого, поэтому продвижение и устранение проблемы не принесет ничего, кроме пользы. Ваш сайт сейчас может быть небольшим, но, вероятно, так будет не всегда.
Ошибка «Карта сайта выглядит как HTML-страница» может раздражать, но обычно это просто результат неправильно отформатированной страницы или легко решаемого конфликта кеширования. После того, как вы выяснили проблему, ее решение – это всего лишь несколько дополнительных шагов.
Читайте также: