
Метод хаффмана в excel
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и насколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Шенон предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0,6 – 1,3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение .
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
- Сжатие без потерь (полностью обратимое) – это метод сжатия данных, при котором ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. Для каждого типа данных, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
- Сжатие с потерями – это метод сжатия данных, при котором для обеспечения максимальной степени сжатия исходного массива данных часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемыми. В основном такие алгоритмы применяются для сжатия аудио- и видеоданных, статических изображений.
Алгоритм сжатия данных (алгоритм архивации) – это алгоритм , который устраняет избыточность записи данных.
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовый символ – наименьшая единица данных, подлежащая сжатию. Обычно символ – это 1 байт , но он может быть битом, тритом , или чем-либо еще.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.

Значение 0,6 означает, что данные занимают 60% от первоначального объема. Значения больше 1 означают, что выходной поток больше входного (отрицательное сжатие, или расширение).
Коэффициент сжатия – величина, обратная отношению сжатия.

Значения больше 1 обозначают сжатие, а значения меньше 1 – расширение.
Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
где – вероятности кодовых слов;
Существуют два основных способа проведения сжатия.
Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
Словарное сжатие – это методы сжатия, хранящие фрагменты данных в "словаре" (некоторая структура данных ). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
Метод Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Хаффмановское кодирование (сжатие) – это широко используемый метод сжатия, присваивающий символам алфавита коды переменной длины, основываясь на вероятностях появления этих символов.
Идея алгоритма состоит в следующем: зная вероятности вхождения символов в исходный текст, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Таким образом, в этом методе при сжатии данных каждому символу присваивается оптимальный префиксный код , основанный на вероятности его появления в тексте.
Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового слова. Эти коды имеют переменную длину.
Оптимальный префиксный код – это префиксный код , имеющий минимальную среднюю длину.
Алгоритм Хаффмана можно разделить на два этапа.
- Определение вероятности появления символов в исходном тексте.
Первоначально необходимо прочитать исходный текст полностью и подсчитать вероятности появления символов в нем (иногда подсчитывают, сколько раз встречается каждый символ). Если при этом учитываются все 256 символов, то не будет разницы в сжатии текстового или файла иного формата.
Далее находятся два символа a и b с наименьшими вероятностями появления и заменяются одним фиктивным символом x , который имеет вероятность появления, равную сумме вероятностей появления символов a и b . Затем, используя эту процедуру рекурсивно, находится оптимальный префиксный код для меньшего множества символов (где символы a и b заменены одним символом x ). Код для исходного множества символов получается из кодов замещающих символов путем добавления 0 или 1 перед кодом замещающего символа, и эти два новых кода принимаются как коды заменяемых символов. Например, код символа a будет соответствовать коду x с добавленным нулем перед этим кодом, а для символа b перед кодом символа x будет добавлена единица.
Коды Хаффмана имеют уникальный префикс , что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Пример 1. Программная реализация метода Хаффмана.
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранения словаря). В настоящее время данный метод практически не применяется в чистом виде, обычно используется как один из этапов сжатия в более сложных схемах. Это единственный алгоритм , который не увеличивает размер исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
В данной статье я расскажу вам о широко известном алгоритме Хаффмана, и вы наконец разберетесь, как все там устроено изнутри. После прочтения вы сможете своими руками(а главное, головой) написать архиватор, сжимающий реальные, черт подери, данные! Кто знает, быть может именно вам светит стать следующим Ричардом Хендриксом!
Да-да, об этом уже была статья на Хабре, но без практической реализации. Здесь же мы сфокусируемся как на теоретической части, так и на программерской. Итак, все под кат!
Немного размышлений
В обычном текстовом файле один символ кодируется 8 битами(кодировка ASCII) или 16(кодировка Unicode). Далее будем рассматривать кодировку ASCII. Для примера возьмем строку s1 = «SUSIE SAYS IT IS EASY\n». Всего в строке 22 символа, естественно, включая пробелы и символ перехода на новую строку — '\n'. Файл, содержащий данную строку будет весить 22*8 = 176 бит. Сразу же встает вопрос: рационально ли использовать все 8 бит для кодировки 1 символа? Мы ведь используем не все символы кодировки ASCII. Даже если бы и использовали, рациональней было бы самой частой букве — S — дать самый короткий возможный код, а для самой редкой букве — T (или U, или '\n') — дать код подлиннее. В этом и заключается алгоритм Хаффмана: необходимо найти оптимальный вариант кодировки, при котором файл будет минимального веса. Вполне нормально, что у разных символов длины кода будут отличаться — на этом и основан алгоритм.
Кодирование
Ни один код не должен быть префиксом другого
Это правило является ключевым в алгоритме. Поэтому создание кода начинается с частотной таблицы, в которой указана частота (количество вхождений) каждого символа:

Символы с наибольшим количеством вхождений должны кодироваться наименьшим возможным количеством битов. Приведу пример одной из возможных таблиц кодов:

Код каждого символа я разделил пробелом. По-настоящему в сжатом файле такого не будет!
Вытекает вопрос: как этот салага придумал код как создать таблицу кодов? Об этом пойдет речь ниже.
Построение дерева Хаффмана
Здесь приходят на выручку бинарные деревья поиска. Не волнуйтесь, здесь методы поиска, вставки и удаления не потребуются. Вот структура дерева на java:
Это не полный код, полный код будет ниже.
Вот сам алгоритм построения дерева:
- Извлечь два дерева из приоритетной очереди и сделать их потомками нового узла (только что созданного узла без буквы). Частота нового узла равна сумме частот двух деревьев-потомков.
- Для этого узла создать дерево с корнем в данном узле. Вставить это дерево обратно в приоритетную очередь. (Так как у дерева новая частота, то скорее всего она встанет на новое место в очереди)
- Продолжать выполнение шагов 1 и 2, пока в очереди не останется одно дерево — дерево Хаффмана

Здесь символ «lf»(linefeed) обозначает переход на новую строку, «sp» (space) — это пробел.
А что дальше?
Мы получили дерево Хаффмана. Ну окей. И что с ним делать? Его и за бесплатно не возьмут А далее, нужно отследить все возможные пути от корня до листов дерева. Условимся обозначить ребро 0, если оно ведет к левому потомку и 1 — если к правому. Строго говоря, в данных обозначениях, код символа — это путь от корня дерева до листа, содержащего этот самый символ.

Таким макаром и получилась таблица кодов. Заметим, что если рассмотреть эту таблицу, то можно сделать вывод о «весе» каждого символа — это длина его кода. Тогда в сжатом виде исходный файл будет весить: 2 * 3 + 2*4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 бит. Вначале он весил 176 бит. Следовательно, мы уменьшили его аж в 176/65 = 2.7 раза! Но это утопия. Такой коэффициент вряд ли будет получен. Почему? Об этом пойдет речь чуть позже.
Декодирование
Ну, пожалуй, осталось самое простое — декодирование. Я думаю, многие из вас догадались, что просто создать сжатый файл без каких-либо намеков на то, как он был закодирован, нельзя — мы не сможем его декодировать! Да-да, мне было тяжело это осознать, но придется создать текстовый файл table.txt с таблицей сжатия:
Запись таблицы в виде 'символ'«код символа». Почему 01110 без символа? На самом деле он с символом, просто средства java, используемые мной при выводе в файл, символ перехода на новую строку — '\n' -конвертируют в переход на новую строку(как бы это глупо не звучало). Поэтому пустая строка сверху и есть символ для кода 01110. Для кода 00 символом является пробел в начале строки. Сразу скажу, что нашему коэффициенту ханаэтот способ хранения таблицы может претендовать на самый нерациональный. Но он прост для понимания и реализации. С удовольствием выслушаю Ваши рекомендации в комментариях по поводу оптимизации.
Имея эту таблицу, очень просто декодировать. Вспомним, каким правилом мы руководствовались, при создании кодировки:
Ни один код не должен являться префиксом другого
Реализация
Пришло время унижать мой код писать архиватор. Назовем его Compressor.
Начнем с начала. Первым делом пишем класс Node:
Класс, создающий дерево Хаффмана:
Класс, облегчающий чтение из файла:
Ну, и главный класс:
Файл с инструкциями readme.txt предстоит вам написать самим :-)
Заключение
Наверное, это все что я хотел сказать. Если у вас есть что сказать по поводу моей некомпетентности улучшений в коде, алгоритме, вообще любой оптимизации, то смело пишите. Если я что-то недообъяснил, тоже пишите. Буду рад услышать вас в комментариях!
Да-да, я все еще здесь, ведь я не забыл про коэффициент. Для строки s1 кодировочная таблица весит 48 байт — намного больше исходного файла, да и про добавочные нули не забыли(количество добавленных нулей равно 7)=> коэффициент сжатия будет меньше единицы: 176/(65 + 48*8 + 7)=0.38. Если вы тоже это заметили, то только не по лицу вы молодец. Да, эта реализация будет крайне неэффективной для малых файлов. Но что же происходит с большими файлами? Размеры файла намного превышают размер кодировочной таблицы. Вот здесь-то алгоритм работает как-надо! Например, для монолога Фауста архиватор выдает реальный (не идеализированный) коэффициент, равный 1.46 — почти в полтора раза! И да, предполагалось, что файл будет на английском языке.
Выпустил upgrade: добавил GUI + изменил алгоритм обработки исходного текста так, чтобы не читать весь файл в память. Короче, кидаю ссылку на git для любознательных: сами всё увидите.
Благодарности
Как и автор каждой хорошей книги, я созидал эту статью не без помощи других людей. Имхо, очень мало людей сделало что-то крутое в одиночку.
Огромное спасибо Исаеву Виталию Вячеславовичу за небходимую теоретическую поддержку.
Также, часть материала этой статьи взята из книги Роберта Лафоре «Data Structures and Algorithms in Java». Если сомневаетесь как или окуда начать свой путь в теории алгоритмов и структур данных — берите, не прогадаете.

Кодирование Хаффмана – это алгоритм сжатия данных, который формулирует основную идею сжатия файлов. В этой статье мы будем говорить о кодировании фиксированной и переменной длины, уникально декодируемых кодах, префиксных правилах и построении дерева Хаффмана.
Мы знаем, что каждый символ хранится в виде последовательности из 0 и 1 и занимает 8 бит. Это называется кодированием фиксированной длины, поскольку каждый символ использует одинаковое фиксированное количество битов для хранения.
Допустим, дан текст. Каким образом мы можем сократить количество места, требуемого для хранения одного символа?
Основная идея заключается в кодировании переменной длины. Мы можем использовать тот факт, что некоторые символы в тексте встречаются чаще, чем другие (см. здесь), чтобы разработать алгоритм, который будет представлять ту же последовательность символов меньшим количеством битов. При кодировании переменной длины мы присваиваем символам переменное количество битов в зависимости от частоты их появления в данном тексте. В конечном итоге некоторые символы могут занимать всего 1 бит, а другие 2 бита, 3 или больше. Проблема с кодированием переменной длины заключается лишь в последующем декодировании последовательности.
Как, зная последовательность битов, декодировать ее однозначно?
Рассмотрим строку «aabacdab». В ней 8 символов, и при кодировании фиксированной длины для ее хранения понадобится 64 бита. Заметим, что частота символов «a», «b», «c» и «d» равняется 4, 2, 1, 1 соответственно. Давайте попробуем представить «aabacdab» меньшим количеством битов, используя тот факт, что «a» встречается чаще, чем «b», а «b» встречается чаще, чем «c» и «d». Начнем мы с того, что закодируем «a» с помощью одного бита, равного 0, «b» мы присвоим двухбитный код 11, а с помощью трех битов 100 и 011 закодируем «c» и «d».
В итоге у нас получится:
Таким образом строку «aabacdab» мы закодируем как 00110100011011 (0|0|11|0|100|011|0|11), используя коды, представленные выше. Однако основная проблема будет в декодировании. Когда мы попробуем декодировать строку 00110100011011, у нас получится неоднозначный результат, поскольку ее можно представить как:
Чтобы избежать этой неоднозначности, мы должны гарантировать, что наше кодирование удовлетворяет такому понятию, как префиксное правило, которое в свою очередь подразумевает, что коды можно декодировать всего одним уникальным способом. Префиксное правило гарантирует, что ни один код не будет префиксом другого. Под кодом мы подразумеваем биты, используемые для представления конкретного символа. В приведенном выше примере 0 – это префикс 011, что нарушает префиксное правило. Итак, если наши коды удовлетворяют префиксному правилу, то можно однозначно провести декодирование (и наоборот).
Давайте пересмотрим пример выше. На этот раз мы назначим для символов «a», «b», «c» и «d» коды, удовлетворяющие префиксному правилу.
С использованием такого кодирования, строка «aabacdab» будет закодирована как 00100100011010 (0|0|10|0|100|011|0|10). А вот 00100100011010 мы уже сможем однозначно декодировать и вернуться к нашей исходной строке «aabacdab».
Кодирование Хаффмана
Теперь, когда мы разобрались с кодированием переменной длины и префиксным правилом, давайте поговорим о кодировании Хаффмана.
Метод основывается на создании бинарных деревьев. В нем узел может быть либо конечным, либо внутренним. Изначально все узлы считаются листьями (конечными), которые представляют сам символ и его вес (то есть частоту появления). Внутренние узлы содержат вес символа и ссылаются на два узла-наследника. По общему соглашению, бит «0» представляет следование по левой ветви, а «1» — по правой. В полном дереве N листьев и N-1 внутренних узлов. Рекомендуется, чтобы при построении дерева Хаффмана отбрасывались неиспользуемые символы для получения кодов оптимальной длины.
Мы будем использовать очередь с приоритетами для построения дерева Хаффмана, где узлу с наименьшей частотой будет присвоен высший приоритет. Ниже описаны шаги построения:
- Создайте узел-лист для каждого символа и добавьте их в очередь с приоритетами.
- Пока в очереди больше одного листа делаем следующее:
- Удалите два узла с наивысшим приоритетом (с самой низкой частотой) из очереди;
- Создайте новый внутренний узел, где эти два узла будут наследниками, а частота появления будет равна сумме частот этих двух узлов.
- Добавьте новый узел в очередь приоритетов.
- Единственный оставшийся узел будет корневым, на этом построение дерева закончится.





Путь от корня до любого конечного узла будет хранить оптимальный префиксный код (также известный, как код Хаффмана), соответствующий символу, связанному с этим конечным узлом.

Дерево Хаффмана
Ниже вы найдете реализацию алгоритма сжатия Хаффмана на языках C++ и Java:
Примечание: память, используемая входной строкой, составляет 47 * 8 = 376 бит, а закодированная строка занимает всего 194 бита, т.е. данные сжимаются примерно на 48%. В программе на С++ выше мы используем класс string для хранения закодированной строки, чтобы сделать программу читаемой.
Поскольку эффективные структуры данных очереди приоритетов требуют на вставку O(log(N)) времени, а в полном бинарном дереве с N листьями присутствует 2N-1 узлов, и дерево Хаффмана – это полное бинарное дерево, то алгоритм работает за O(Nlog(N)) времени, где N – количество символов.
Вы вероятно слышали о Дэвиде Хаффмане и его популярном алгоритме сжатия. Если нет, то поищите информацию в интернете — в этой статье я не буду вас грузить историей или математикой. Сегодня я хочу просто попытаться показать вам практический пример применения алгоритма к символьной строке.
Примечание переводчика: под символом автор подразумевает некий повторяющийся элемент исходной строки — это может быть как печатный знак (character), так и любая битовая последовательность. Под кодом подразумевается не ASCII или UTF-8 код символа, а кодирующая последовательность битов.
К статье прикреплён исходный код, который наглядно демонстрирует, как работает алгоритм Хаффмана — он предназначен для людей, которые плохо понимают математику процесса. В будущем (я надеюсь) я напишу статью, в которой мы поговорим о применении алгоритма к любым файлам для их сжатия (то есть, сделаем простой архиватор типа WinRAR или WinZIP).
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие — побольше (но так как они редкие, это не имеет значения). Для нашей программы я решил, что символ будет иметь длину 8 бит, то есть, будет соответствовать печатному знаку.
Мы могли бы с той же простотой взять символ длиной в 16 бит (то есть, состоящий из двух печатных знаков), равно как и 10 бит, 20 и так далее. Размер символа выбирается, исходя из строки ввода, которую мы ожидаем встретить. Например, если бы я собрался кодировать сырые видеофайлы, я бы приравнял размер символа к размеру пикселя. Помните, что при уменьшении или увеличении размера символа меняется и размер кода для каждого символа, потому что чем больше размер, тем больше символов можно закодировать этим размером кода. Комбинаций нулей и единичек, подходящих для восьми бит, меньше, чем для шестнадцати. Поэтому вы должны подобрать размер символа, исходя из того по какому принципу данные повторяются в вашей последовательности.
Для этого алгоритма вам потребуется минимальное понимание устройства бинарного дерева и очереди с приоритетами. В исходном коде я использовал код очереди с приоритетами из моей предыдущей статьи.
Предположим, у нас есть строка «beep boop beer!», для которой, в её текущем виде, на каждый знак тратится по одному байту. Это означает, что вся строка целиком занимает 15*8 = 120 бит памяти. После кодирования строка займёт 40 бит (на практике, в нашей программе мы выведем на консоль последовательность из 40 нулей и единиц, представляющих собой биты кодированного текста. Чтобы получить из них настоящую строку размером 40 бит, нужно применять битовую арифметику, поэтому мы сегодня не будем этого делать).
Чтобы лучше понять пример, мы для начала сделаем всё вручную. Строка «beep boop beer!» для этого очень хорошо подойдёт. Чтобы получить код для каждого символа на основе его частотности, нам надо построить бинарное дерево, такое, что каждый лист этого дерева будет содержать символ (печатный знак из строки). Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей. Скоро вы увидите, для чего это нужно.
Чтобы построить дерево, мы воспользуемся слегка модифицированной очередью с приоритетами — первыми из неё будут извлекаться элементы с наименьшим приоритетом, а не наибольшим. Это нужно, чтобы строить дерево от листьев к корню.
Для начала посчитаем частоты всех символов:
| Символ | Частота |
|---|---|
| 'b' | 3 |
| 'e' | 4 |
| 'p' | 2 |
| ' ' | 2 |
| 'o' | 2 |
| 'r' | 1 |
| '!' | 1 |

После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:
Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
Повторим те же шаги и получим последовательно:

Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:

Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
Если мы так сделаем, то получим следующие коды для символов:
| Символ | Код |
|---|---|
| 'b' | 00 |
| 'e' | 11 |
| 'p' | 101 |
| ' ' | 011 |
| 'o' | 010 |
| 'r' | 1000 |
| '!' | 1001 |
Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа. Например, если есть строка «101 11 101 11» и наше дерево, то мы получим строку «pepe».
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для 'b', то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на 'b'.
На практике, при реализации данного алгоритма сразу после построения дерева строится таблица Хаффмана. Данная таблица — это по сути связный список или массив, который содержит каждый символ и его код, потому что это делает кодирование более эффективным. Довольно затратно каждый раз искать символ и одновременно вычислять его код, так как мы не знаем, где он находится, и придётся обходить всё дерево целиком. Как правило, для кодирования используется таблица Хаффмана, а для декодирования — дерево Хаффмана.
Приложенный исходный код работает по тому же принципу, что и описан выше. В коде можно найти больше деталей и комментариев.
Все исходники были откомпилированы и проверены с использованием стандарта C99. Удачного программирования!
Алгоритм Хаффмана (англ. Huffman's algorithm) — алгоритм оптимального префиксного кодирования алфавита. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. Используется во многих программах сжатия данных, например, PKZIP 2, LZH и др.
Содержание
- [math]c_[/math] не является префиксом для [math]c_[/math] , при [math]i \ne j[/math] ,
- cумма [math]\sum\limits_ w_\cdot |c_|[/math] минимальна ( [math]|c_|[/math] — длина кода [math]c_[/math] ),
Построение кода Хаффмана сводится к построению соответствующего бинарного дерева по следующему алгоритму:
- Составим список кодируемых символов, при этом будем рассматривать один символ как дерево, состоящее из одного элемента c весом, равным частоте появления символа в строке.
- Из списка выберем два узла с наименьшим весом.
- Сформируем новый узел с весом, равным сумме весов выбранных узлов, и присоединим к нему два выбранных узла в качестве детей.
- Добавим к списку только что сформированный узел вместо двух объединенных узлов.
- Если в списке больше одного узла, то повторим пункты со второго по пятый.
Если сортировать элементы после каждого суммирования или использовать приоритетную очередь, то алгоритм будет работать за время [math]O(N \log N)[/math] .Такую асимптотику можно улучшить до [math]O(N)[/math] , используя обычные массивы.
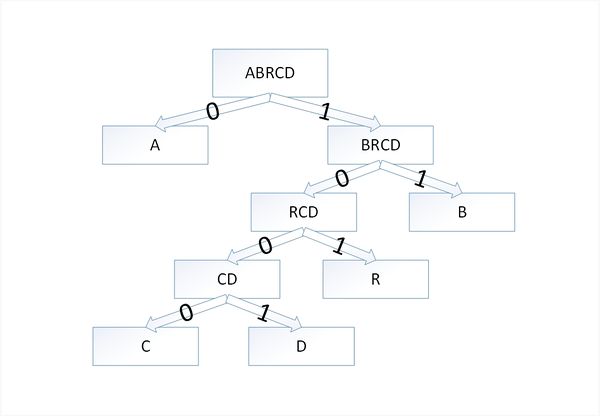
Закодируем слово [math]abracadabra[/math] . Тогда алфавит будет [math]A= \ [/math] , а набор весов (частота появления символов алфавита в кодируемом слове) [math]W=\[/math] :
В дереве Хаффмана будет [math]5[/math] узлов:
| Узел | a | b | r | с | d |
|---|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 1 | 1 |
По алгоритму возьмем два символа с наименьшей частотой — это [math]c[/math] и [math]d[/math] . Сформируем из них новый узел [math]cd[/math] весом [math]2[/math] и добавим его к списку узлов:
| Узел | a | b | r | cd |
|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 2 |
Затем опять объединим в один узел два минимальных по весу узла — [math]r[/math] и [math]cd[/math] :
| Узел | a | rcd | b |
|---|---|---|---|
| Вес | 5 | 4 | 2 |
Еще раз повторим эту же операцию, но для узлов [math]rcd[/math] и [math]b[/math] :
| Узел | brcd | a |
|---|---|---|
| Вес | 6 | 5 |
На последнем шаге объединим два узла — [math]brcd[/math] и [math]a[/math] :
| Узел | abrcd |
|---|---|
| Вес | 11 |
Остался один узел, значит, мы пришли к корню дерева Хаффмана (смотри рисунок). Теперь для каждого символа выберем кодовое слово (бинарная последовательность, обозначающая путь по дереву к этому символу от корня):
| Символ | a | b | r | с | d |
|---|---|---|---|---|---|
| Код | 0 | 11 | 101 | 1000 | 1001 |
Таким образом, закодированное слово [math]abracadabra[/math] будет выглядеть как [math]01110101000010010111010[/math] . Длина закодированного слова — [math]23[/math] бита. Стоит заметить, что если бы мы использовали алгоритм кодирования с одинаковой длиной всех кодовых слов, то закодированное слово заняло бы [math]33[/math] бита, что существенно больше.
Чтобы доказать корректность алгоритма Хаффмана, покажем, что в задаче о построении оптимального префиксного кода проявляются свойства жадного выбора и оптимальной подструктуры. В сформулированной ниже лемме показано соблюдение свойства жадного выбора.
Пусть [math]C[/math] — алфавит, каждый символ [math]c \in C[/math] которого встречается с частотой [math]f[c][/math] . Пусть [math]x[/math] и [math]y[/math] — два символа алфавита [math]C[/math] с самыми низкими частотами. Тогда для алфавита [math]C[/math] существует оптимальный префиксный код, кодовые слова символов [math]x[/math] и [math]y[/math] в котором имеют одинаковую максимальную длину и отличаются лишь последним битом.Возьмем дерево [math]T[/math] , представляющее произвольный оптимальный префиксный код для алфавита [math]C[/math] . Преобразуем его в дерево, представляющее другой оптимальный префиксный код, в котором символы [math]x[/math] и [math]y[/math] — листья с общим родительским узлом, находящиеся на максимальной глубине.
Пусть символы [math]a[/math] и [math]b[/math] имеют общий родительский узел и находятся на максимальной глубине дерева [math]T[/math] . Предположим, что [math]f[a] \leqslant f[b][/math] и [math]f[x] \leqslant f[y][/math] . Так как [math]f[x][/math] и [math]f[y][/math] — две наименьшие частоты, а [math]f[a][/math] и [math]f[b][/math] — две произвольные частоты, то выполняются отношения [math]f[x] \leqslant f[a][/math] и [math]f[y] \leqslant f[b][/math] . Пусть дерево [math]T'[/math] — дерево, полученное из [math]T[/math] путем перестановки листьев [math]a[/math] и [math]x[/math] , а дерево [math]T''[/math] — дерево полученное из [math]T'[/math] перестановкой листьев [math]b[/math] и [math]y[/math] . Разность стоимостей деревьев [math]T[/math] и [math]T'[/math] равна:
[math]B(T) - B(T') = \sum\limits_ f(c)d_T(c) - \sum\limits_ f(c)d_(c) = (f[a] - f[x])(d_T(a) - d_T(x)),[/math]
что больше либо равно [math]0[/math] , так как величины [math]f[a] - f[x][/math] и [math]d_T(a) - d_T(x)[/math] неотрицательны. Величина [math]f[a] - f[x][/math] неотрицательна, потому что [math]x[/math] — лист с минимальной частотой, а величина [math]d_T(a) - d_T(x)[/math] является неотрицательной, так как лист [math]a[/math] находится на максимальной глубине в дереве [math]T[/math] . Точно так же перестановка листьев [math]y[/math] и [math]b[/math] не будет приводить к увеличению стоимости. Таким образом, разность [math]B(T') - B(T'')[/math] тоже будет неотрицательной.
Пусть дан алфавит [math]C[/math] , в котором для каждого символа [math]c \in C[/math] определены частоты [math]f[c][/math] . Пусть [math]x[/math] и [math]y[/math] — два символа из алфавита [math]C[/math] с минимальными частотами. Пусть [math]C'[/math] — алфавит, полученный из алфавита [math]C[/math] путем удаления символов [math]x[/math] и [math]y[/math] и добавления нового символа [math]z[/math] , так что [math]C' = C \backslash \ < x, y \>\cupСначала покажем, что стоимость [math]B(T)[/math] дерева [math]T[/math] может быть выражена через стоимость [math]B(T')[/math] дерева [math]T'[/math] . Для каждого символа [math]c \in C \backslash \[/math] верно [math]d_T(C) = d_[/math] , значит, [math]f[c]d_T(c) = f[c]d_(c)[/math] . Так как [math]d_T(x) = d_T(y) = d_ (z) + 1[/math] , то
[math]f[x]d_T(x) + f[y]d_T(y) = (f[x] + f[y])(d_(z) + 1) = f[z]d_(z) + (f[x] + f[y])[/math]
из чего следует, что
[math] B(T) = B(T') + f[x] + f[y] [/math]
[math] B(T') = B(T) - f[x] - f[y] [/math]
Докажем лемму от противного. Предположим, что дерево [math]T[/math] не представляет оптимальный префиксный код для алфавита [math]C[/math] . Тогда существует дерево [math]T''[/math] такое, что [math]B(T'') \lt B(T)[/math] . Согласно лемме (1), элементы [math]x[/math] и [math]y[/math] можно считать дочерними элементами одного узла. Пусть дерево [math]T'''[/math] получено из дерева [math]T''[/math] заменой элементов [math]x[/math] и [math]y[/math] листом [math]z[/math] с частотой [math]f[z] = f[x] + f[y][/math] . Тогда
[math]B(T''') = B(T'') - f[x] - f[y] \lt B(T) - f[x] - f[y] = B(T')[/math] ,
Читайте также: