
Как посмотреть локатор в браузере
Будущих студентов курса "Java QA Automation Engineer" и всех интересующихся приглашаем посмотреть подарочное демо-занятие в формате открытого вебинара.
А также делимся переводом полезной статьи.
В данной статье рассматриваются примеры использования функций XPath для идентификации элементов.
Автоматизация взаимодействия с любым сайтом начинается с корректной идентификации объекта, над которым будет выполняться какая-либо операция. Как нам известно, легче всего идентифицировать элемент по таким атрибутам, как ID, Name, Link, Class, или любому другому уникальному атрибуту, доступному в теге, в котором находится элемент.
Но правильно идентифицировать объект можно только в том случае, если такие атрибуты присутствуют и (или) являются уникальными.
Чему вы научитесь: [показать]
Обзор функций XPath
Обсудим сценарий, при котором атрибуты недоступны напрямую.
Постановка задачи
Как идентифицировать элемент, если такие локаторы, как ID, Name, Class и Link, недоступны в теге элемента?
Суть проблемы демонстрирует следующий пример:
Как видно из скриншота выше, заголовок «Log in to Twitter» не имеет дополнительных атрибутов. Поэтому мы не можем использовать ни один из локаторов, таких как ID , Class , Link или Name , для идентификации этого элемента.
Плагин Firepath для Firefox сгенерировал следующий путь XPath:
Мы бы не рекомендовали использовать указанный выше путь XPath, поскольку структура страницы или id могут меняться динамически. Если все же использовать этот нестабильный XPath, вероятно, потребуется чаще его обновлять, что подразумевает лишнюю трату времени на поддержку. Это один из случаев, когда мы не можем использовать общее выражение XPath с такими локаторами, как ID, Class, Link или Name.
Решение
Идентификация элемента с помощью функций XPath по тексту
Поскольку у нас есть видимый текст «Log in to Twitter», мы могли бы использовать следующие функции XPath для идентификации уникального элемента.
contains() [по тексту]
starts-with() [по тексту]
Функции XPath , такие как contains() , starts-with() и text() , при использовании с текстом «Log in to Twitter» помогут нам корректно идентифицировать элемент, после чего мы сможем произвести над ним дальнейшие операции.
1. Метод Contains()
Синтаксис. Чтобы найти на веб-странице элемент «Log in to Twitter», воспользуйтесь одним из следующих выражений XPath на основе метода contains() .
Поиск по тексту:
//h1[contains(text(),’ Log in to’)]
//h1[contains(text(),’ in to Twitter’)]
Примечание. Наличие одного совпадающего узла свидетельствует об успешной идентификации веб-элемента.
Из примера выше видно, что методу contains() не требуется весь текст для правильной идентификации элемента. Достаточно даже части текста, но эта часть текста должна быть уникальной. Используя метод contains() , пользователь может легко идентифицировать элемент, даже после смены ориентации страницы.
Обратите внимание, что при указании всего текста «Log in to Twitter» с методом contains() элемент будет также идентифицирован корректно.
2. Метод starts-with()
Синтаксис. Чтобы найти на веб-странице элемент «Log in to Twitter», используйте следующие выражения XPath на основе метода starts-with().
Поиск по тексту:
//h1[starts-with(text(),’Log in to’)]
Из приведенного выше примера видно, что XPath-функции starts-with() требуется по крайней мере первое слово («Log») видимого текста для однозначной идентификации элемента. Функция работает даже с неполным текстом, но он должен как минимум включать первое слово частично видимого текста.
Обратите внимание, что при использовании всего текста «Log in to Twitter» с методом starts-with() элемент будет также идентифицирован корректно.
Недействительный XPath для starts-with() : //h1[starts-with(text(),’in to Twitter’)]
Примечание. Отсутствие совпадающих узлов свидетельствует о том, что элемент на веб-странице не был идентифицирован.
3. Метод text()
Синтаксис. Чтобы найти на веб-странице элемент «Log in to Twitter», воспользуйтесь следующим выражением XPath на основе метода text() .
В этом выражении мы указываем весь текст, содержащийся между открывающим тегом <h1> и закрывающим тегом </h1> . Если использовать функцию text() с частью текста, как в случае с методами contains() и starts-with() , то мы не сможем найти данный элемент.
Недействительное выражение Xpath для text() :
Идентификация элемента с помощью функций XPath по атрибуту
Мы используем функции XPath ( contains или starts-with ) с атрибутом в тех случаях, когда в теге содержатся уникальные значения атрибутов. Доступ к атрибутам производится с помощью символа « @ ».
Для лучшего понимания рассмотрим следующий пример:
1. Метод Contains()
Синтаксис. Чтобы точно идентифицировать кнопку «I’m Feeling Lucky» («Мне повезет») с помощью XPath-функции contains() , можно указать следующие атрибуты.
Вариант А — поиск по значению атрибута Value
На скриншотах выше видно, что поиск по атрибуту Value слов «Feeling» или «Lucky» с помощью функции contains() позволяет однозначно идентифицировать данный элемент. Стоит отметить, что, даже если мы используем полное содержимое атрибута Value , мы сможем корректно идентифицировать элемент.
Вариант Б — поиск по содержимому атрибута Name
Неправильное использование функции XPath с атрибутом:
Нужно быть крайне внимательным при выборе атрибута для поиска с помощью методов contains() и starts-with() . Если значение атрибута не уникальное, мы не сможем однозначно идентифицировать элемент.
Если мы воспользуемся атрибутом type при идентификации кнопки «I'm Feeling Lucky», то XPath не сработает.
Наличие двух совпадающих узлов свидетельствует о том, что нам не удалось корректно идентифицировать элемент. В данном случае значение атрибута type не является уникальным.
2. Метод starts-with()
Метод starts-with() в сочетании с атрибутом может пригодиться для поиска элементов, у которых начало атрибута постоянное, а окончание изменяется. Такой метод позволяет работать с объектами, динамически изменяющими значения своих атрибутов. Его также можно использовать для поиска однотипных элементов.
Изучите первое текстовое поле First Name (Имя) и второе текстовое поле Surname (Фамилия) формы авторизации.
Первое текстовое поле First Name идентифицировано.
Второе текстовое поле Surname идентифицировано.
В случае обоих текстовых полей, из которых состоит форма авторизации Facebook, первая часть атрибута id всегда остается неизменной.
First Name id
Surname id
Это тот случай, когда мы можем использовать атрибут вместе с функцией starts-with() , чтобы получить все элементы такого типа с атрибутом id . Обратите внимание, что мы рассматриваем эти два поля только для примера. На экране может быть больше полей с id , которые начинаются с «u0».
Starts-with() [по атрибуту id]
Важное примечание. Здесь мы использовали двойные кавычки вместо одинарных. Но одиночные кавычки тоже будут работать с методом starts-with .
11 найденных узлов указывают на то, что данное выражение XPath позволило идентифицировать все элементы, id которых начинается с «u0». Вторая часть id («2» для имени, «4» для фамилии и т. д.) позволяет однозначно идентифицировать элемент.
Мы можем использовать атрибут с функцией starts-with там, где нам нужно собрать элементы похожего типа в список и динамически выбрать один из них, передавая аргумент в обобщенный метод, чтобы однозначно идентифицировать элемент.
На примере ниже показано использование функции starts-with .
public void xpathLoc(String identifier)
//The below step identifies the element “First Name” uniquely when the argument is “2”
E1.sendKeys(“Test1”); / This step enters the value of First Name as “Test 1” /
public static void main(String[] args)
xpathLoc(“2”); --- This step calls the xpathLoc() method to identify the first name.
Примечание. Eclipse может не допускать использование двойных кавычек. Возможно, вам придется прибегнуть к другому коду, чтобы сформировать динамический XPath.
Приведенный код является лишь примером. Вы можете усовершенствовать его, чтобы он работал со всеми элементами, выполняемыми операциями и вводимыми значениями (в случае текстовых полей), сделав код более универсальным.
Заключение
В этой статье мы рассмотрели, как можно использовать функции XPath contains() , starts-with() и text() с атрибутом и текстом для однозначной идентификации элементов в структуре HTML DOM.
Ниже приведены некоторые замечания касательно функций XPath:
Используйте метод contains() в XPath, если известна часть постоянно видимого текста или атрибута.
Используйте метод starts-with() в XPath, если известна первая часть постоянно видимого текста или атрибута.
Вы также можете использовать методы contains() и starts-with() со всем текстом или полным атрибутом.
Используйте метод text() в XPath, если вам известен весь видимый текст.
Нельзя использовать метод text() с частичным текстом.
Нельзя использовать метод starts-with() , если начальный текст не используется в XPath или если начальный текст постоянно изменяется.
В следующем уроке мы узнаем, как использовать оси XPath с функциями XPath для более точного определения расположения элементов на веб-странице.
Все знают как написать хороший тест, а может быть даже несколько. Но вот что делать, когда этих тестов у вас больше 100 или возможно даже несколько тысяч?
Об этом расскажем на открытом вебинаре. Регистрируйтесь
Узнать подробнее о курсе "Java QA Automation Engineer" можно здесь.






Что пишут в блогах

Онлайн-тренинги
Что пишут в блогах (EN)
- Agile Testing Days 2021 - My Heart Is Full
- Balancing the Speaker Circuit
- Agile Testing Days 2021 – Part 1
- Automate for yourself first
- I’m now a Developer Advocate!
- Keeping the Customer Satisfied
- Lessons Learned in Finding Bugs
- Workshop on Built-in Quality at the Agile Testing Days
- Increasing Understanding of Modern (Exploratory) Testing
- The George Foreman Heuristic for Quality
Разделы портала
Про инструменты
Автор: Энди Найт (Andy Knight)
Оригинал статьи
Перевод: Ольга Алифанова
Если вы занимаетесь тест-автоматизацией через веб-интерфейс (например, при помощи Selenium WebDriver), то, возможно, тратите много рабочего времени на поиск элементов на странице – к примеру, кнопок, полей ввода и блоков. Поиск нужных элементов может быть сложным делом, особенно в тех случаях, когда у них нет уникальных идентификаторов или имен классов. Это руководство поможет вам профессионально находить любые веб-элементы.
Что такое веб-элементы?
Веб-элемент – это индивидуальная сущность, генерирующаяся на веб-странице. Элементы – это все то, что пользователь видит (а иногда и не видит) на странице – заголовки, кнопки "ОК", поля ввода, текстовые блоки… Элементы в HTML определяются через имя тэга, атрибуты и содержание. У них также могут быть дочерние элементы – например, таблицы. CSS может применяться к элементам и менять их цвета, размеры и расположение. Языки программирования обычно получают доступ к веб-элементам как к нодам в объектной модели документа (DOM).
Что такое локаторы веб-элементов?
Веб-элементы и локаторы – это разные вещи. Локатор веб-элемента – это объект, который находит и возвращает веб-элементы на странице по заданному запросу. Короче говоря, локаторы находят элементы.
Зачем нужны локаторы? Как пользователи, мы взаимодействуем с веб-страницами визуально. Мы смотрим, скроллим, кликаем и печатаем посредством браузера. Тест-автоматизация, однако, взаимодействует со страницами программно: ей нужен закодированный способ поиска и манипулирования теми же самыми элементами. Традиционная автоматизация не будет "смотреть" на страницу, как человек – вместо этого она будет искать через DOM.
(Более современные технологии автоматизации позволяют визуальное тестирование – об этом будет сказано чуть позже).
Selenium WebDriver разделяет вопросы поиска элементов и взаимодействия с ними. Вызовы WebDriver для этих двух целей часто идут подряд.
WebDriver предоставляет следующие типы запросов для локаторов через "By":
provides the following locator query types using “By”:
-
(Имя класса) (текст ссылки) (имя) (частичный текст ссылки) (название тэга)
Какой из них лучше? Обсудим далее.
Локаторы могут возвращать несколько элементов, или вообще их не вернуть! Вот пример:
Большие тест-фреймворки часто используют шаблоны дизайна для структурирования локаторов и взаимодействий. Модель Page Object организует локаторы и методы действий в классы – по странице или по компоненту. Однако я крайне рекомендую шаблон Screenplay, а не Page Object, потому что части Screenplay лучше подаются повторному использованию и масштабированию. Вне зависимости от модели локаторы необходимы.
Как найти элементы?
Элементы могут с трудом поддаваться поиску, когда вы пишете локаторы для тест-автоматизации. Для упрощения работы я использую инструменты разработчика Chrome вместе с моей IDE. Почему Chrome?
- Все так делают (посмотрите на информацию о долях рынка у браузеров).
- Инструменты Chrome легко использовать, и они дают много полезной информации.
Чтобы исследовать любую страницу в Chrome, просто кликните правой кнопкой на любом месте страницы:
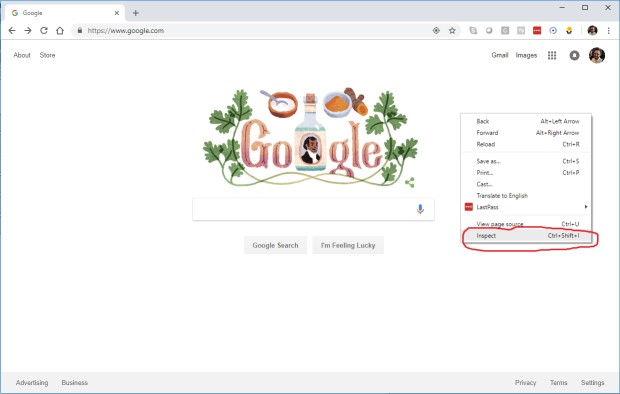
Вуаля! Инструменты разработчика откроются. Для поиска веб-элементов мы воспользуемся вкладкой Elements.
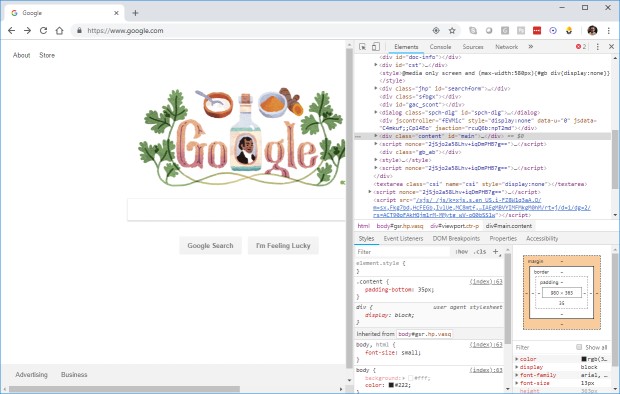
В Chrome легко выделить элемент визуально. Выберите инструмент "Select" в верхнем левом углу панели инструментов разработчика (она выглядит как квадрат с курсором). Иконка должна поменять цвет на синий.
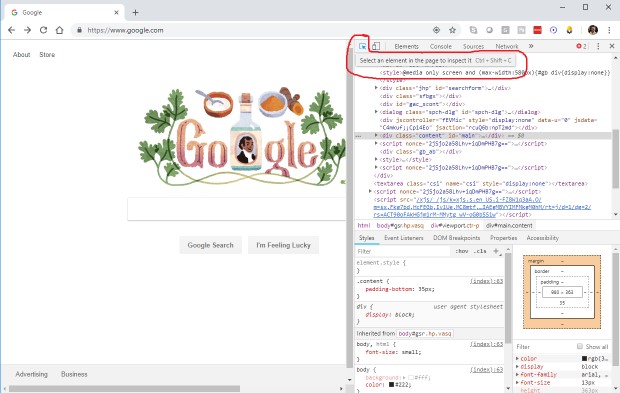
Затем переместите курсор к нужному элементу на странице. Вы увидите, как каждый элемент подсвечивается, когда вы наводите на него мышь. Соответствующий исходный HTML-код на вкладке Elements также будет подсвечен. Чудненько! Кликните на нужном элементе, чтобы подсветка сохранилась после смещения курсора.
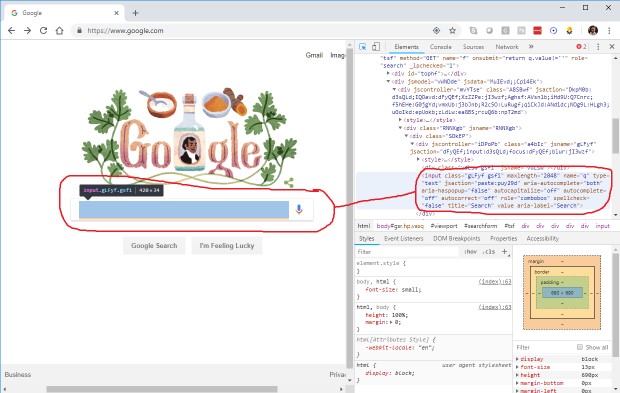
Теперь вы можете изучить тег элемента, классы, атрибуты, содержание, родительские и дочерние элементы.
Как писать хорошие локаторы?
Поиск элемента – это полдела. Создание уникального запроса для локатора – вот вторая половина. Если локатор чересчур широк, он будет возвращать ложноположительные значения. При слишком узком подходе он начнет ломаться при любом изменении DOM, и его будет сложно читать другим людям. Лучший подход здесь такой – пишите наиболее простой запрос, который уникально идентифицирует целевой элемент или элементы.
Мой список предпочтения типов запросов в порядке убывания:
- ID (если уникален)
- Имя (если уникально)
- Имя класса
- CSS-селектор
- XPath без текста или индексирования
- Текст ссылки/частичный текст ссылки.
- XPath с текстом и/или индексированием.
Уникальные ID, имена и имена классов крайне упрощают создание локаторов: запросы будут краткими и не требуют дополнительных якорей. Всегда ратуйте, чтобы ваши разработчики использовали уникальные идентификаторы (например, имена классов) для всех элементов. Однако у многих элементов таких идентификаторов нет, и локаторам приходится полагаться на более сложные CSS-селекторы и (содрогнувшись) XPath. Если это случилось с вами, вот мои рекомендации:
Всегда тестируйте локаторы, в них часто встречаются ошибки синтаксиса и ложноположительные значения. Chrome DevTools упрощает их тестирование – нажмите Ctrl+F на вкладке элементов и вставьте запрос локатора в поле поиска. DevTools подсветит все соответствующие элементы по порядку. Шик-блеск-красота!
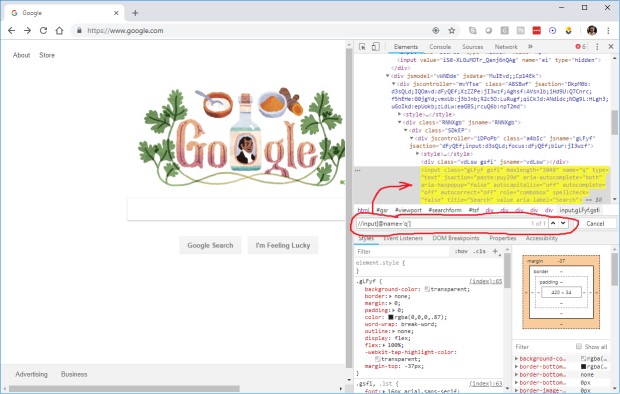
Если я не могу разобраться, почему локатор в тесте не срабатывает, я делаю следующее:
- Запускаю тест без дебага со своей IDE.
- Устанавливаю на локаторе брейкпойнт.
- Жду, пока тест остановится.
- Захожу в DevTools в активном окне Chrome.
- Проверяю DOM и тестирую локатор на живой странице.
Что делать, если тесты нестабильны?
Лучший способ избежать гоночных условий таков – всегда ожидайте существования элемента, прежде чем взаимодействовать с ним. Это кажется элементарным, но про это легко забыть. Пакеты Selenium WebDriver всегда предлагают какую-то разновидность объекта WebDriverWait, заставляющего драйвер ожидать истинности определенного условия перед дальнейшими действиями. Простейший способ проверить, существует ли элемент – это проверить список элементов, возвращаемый вызовом FindElements (для списка элементов) и убедиться, что он непустой. Добавление дополнительного вызова для каждого взаимодействия может показаться затратным, однако дизайн-шаблоны хорошо спроектированных фреймворков (например, Screenplay) могут автоматически осуществлять подобные проверки.
Еще одна хорошая практика – всегда получать "свежие" элементы. Иногда автоматизация вначале получит ряд элементов, а затем через второй запрос получит следующую часть. Или же, в случае с Page Object Factory (никогда ей не пользуйтесь – если в трех словах, она отвратительна), элементы получаются один раз при конструировании Page Object, а затем на них ссылаются. Вне зависимости от способа – чем дольше существует объект на веб-странице, тем более он подвержен тому, чтобы устареть и вызвать исключения. Я видел элементы, необъяснимо устаревающие, даже если они еще присутствовали на странице. Всегда запрашивайте элемент тогда, когда он нужен – в этом случае он не успеет устареть!
Как искусственный интеллект может помочь в тестировании Web UI?
Ряд новых основанных на ИИ проектов и продуктов направлен на улучшение автоматизированного тестирования Web UI по сравнению с традиционными методами:
-
расширяет автоматизацию Selenium WebDriver, добавляя проверки на необычные визуальные различия. может автоматически исправлять сломанные локаторы, что позволяет избежать нестабильности тестов, связанной с изменениями фронтэнда. – это помощник, который выучит и запустит тесты, которому его научили разработчики, без создания какого-либо кода. прогоняет распространенные пользовательские тесты вроде авторизации, поиска и покупок в мобильных приложениях, основываясь на знаниях ИИ о ряде других приложений. использует краудсорсинг и ИИ для прогона ручных тестов, конкретизированных командой, так, что они получаются почти как автоматизированные.
Множество инструментов тестирования, основанных на ИИ, очень полезны, но держите в уме, что под капотом они все-таки пользуются локаторами.

Selenium 4 принес нам относительные локаторы — Relative Locators (первоначально называвшиеся Friendly Locators). Этот функционал был добавлен, чтобы помочь вам найти элементы, которые находятся рядом с другими элементами.
- above(): искомый элемент находится над указанным элементом
- below(): искомый элемент находится ниже указанного элемента
- toLeftOf(): искомый элемент находится слева от указанного элемента
- toRightOf(): искомый элемент находится справа от указанного элемента
- near(): искомый элемент находится на расстоянии не более 50 пикселей от указанного элемента. Существует также перегруженный метод, позволяющий указать расстояние.
Использование относительных локаторов
На примере этого приложения книжного магазина, мы хотим проверить, что книга слева от «Advanced Selenium in Java» — это «Java For Testers». Относительные локаторы позволяют нам это сделать.

Вот DOM фрагмент для книг

«Advanced Selenium in Java» представлен в DOM идентификатором pid6, а «Java For Testers» — pid5.
Метод WebDriver::findElement может принимать метод withTagName() , который возвращает объект RelativeLocator.RelativeBy (потомок By).
Здесь я уже могу указать относительные локаторы. Я знаю, что «Java For Testers» находится слева от «Advanced Selenium in Java» (pid6) и находится ниже «Test Automation in the Real World» (pid1). Итак, я могу указать из обоих:
И получу «Java For Testers» (pid5).
Мы можем использовать методы above() и toRightOf() , чтобы найти «Experiences of Test Automation» (pid2):
Как это работает?
Я не смогла обнаружить «Java For Testers» только с помощью вызова toLeftOf(By.id(“pid6”)). Один он вернет «Test Automation in the Real World» (pid1). Это потому, что driver.findElement() выполняет поиск от корня DOM, а первый элемент < li> слева от «Advanced Selenium в Java» — «Test Automation in the Real World».
Selenium использует функцию JavaScript getBoundingClientRect() для поиска относительных элементов. Эта функция возвращает свойства элемента, такие как right, left, bottom и top.
Рассматривая свойства этих трех книг, мы видим, что и «Test Automation in the Real World» (pid1), и «Java For Testers» (pid5) обе имеют одинаковую позицию по оси x.

Таким образом, они обе слева от «Java For Testers», причем «Test Automation in the Real World» (pid1) является первой найденной.
Еще один момент, которую следует учитывать, — это изменения во вьюпортах приложений. Если бы я запустила тесты, указанные выше, на своем приложении в мобильном представлении, то, естественно, они потерпели бы неудачу, так как книги больше не находятся слева/справа от других книг:

Я также столкнулся с проблемой с дружественными локаторами, когда попытался использовать их в этом приложении ToDo.

Я попытался использовать метод toLeftOf() , чтобы найти переключатель ввода рядом с элементом «goodbye world». Визуально этот переключатель ввода находится слева от ярлыка «goodbye world». Вот этот div в DOM:
Вот код, который я использовала, чтобы найти элемент ввода слева от метки:
Однако я наткнулась на исключение:
org.openqa.selenium.NoSuchElementException: Cannot locate an element using [unknown locator]
Кажется, что хотя этот < input> находится слева от < label> визуально, на самом деле это не так. Я вызвала функцию getBoundingClientRect() для обоих этих элементов, и они фактически перекрываются. Обратите внимание, что они оба имеют позицию x 838, так что технически < input> не слева от < label> .

И когда я выделяю элемент < label> , я теперь вижу, что он действительно перекрывает элемент < input> .

Поиск оптимальных локаторов для начинающих
Что такое локаторы (краткий ликбез)
Оптимальный локатор
Во-первых, он должен однозначно определять наш элемент, т.е. должен быть уникальным в пределах страницы (экрана). Конечно, иногда нам нужно найти группу однотипных элементов (например, разные элементы списка), но даже в этом случае мы ищем локатор, позволяющий найти только эти элементы и никакие больше.
Во-вторых, в нем должно упоминаться как можно меньше соседних элементов. Таким образом, мы и обеспечиваем стабильность: соседние элементы могут часто меняться, а значит, чем их меньше в локаторе, тем реже нам придется что-то в локаторе менять.
В-третьих, хороший локатор помогает ориентироваться в автотесте, т.е. нужно использовать такие атрибуты, которые что-то говорят об элементе. Чтобы мы только взглянули на локатор и сразу поняли, что это за элемент. Конечно, это условие выполняется реже всего, но будем к этому стремиться.
И тут я сразу хочу предостеречь желающих использовать в локаторе видимый текст элемента. Вроде бы, что может лучше говорить о назначении элемента, чем его текст? Это конечно да, только вот все то, что видит конечный пользователь, меняется гораздо чаще, например, потому что так красивее, понятнее и сильнее привлекает внимание. Конечно, если совсем не за что зацепиться при составлении локатора, можно использовать текст.
Как подбирать локатор
Первым делом нужно открыть инструменты разработчика в браузере и посмотреть на верстку страницы (в браузере Chrome горячая клавиша F12). Выбираем на странице элемент, для которого будем строить локатор, и приступаем к анализу.
Алгоритм поиска локатора будет следующим:
1. Сначала ищем у элемента атрибут id или name и убеждаемся, что он уникален и не меняется. Эти атрибуты наиболее точно подходят под описание оптимального локатора, но иногда их делают динамическими, т.е. при обновлении страницы значение этих атрибутов не меняется.
3. Элемент совсем ничем не примечателен? Переходим к элементу на уровень выше (родителю) и повторяем пункты 1 и 2. Тут уже простым локатором точно не обойтись, придется составлять сложный.
А теперь посмотрим, как этот div выглядит в интерфейсе: он определяет весь блок поиска на странице.
5. Так и не нашли локатор, начинаем шерстить по соседям (элементам, расположенным рядом с искомым на одном уровне) и потомкам (элементам внутри искомого), опять повторяя шаги 1 и 2. Здесь стараемся не уходить далеко от искомого элемента, т.к. такой локатор может быть самым нестабильным.
Например, у элемента чекбокса, на который можно кликнуть (span), нет никаких уникальных атрибутов. Зато у его соседа (input) есть уникальный атрибут data-show-special-first.
Дополнительно
Читайте также: