
Как парсить данные с сайта в excel google
У агентства IT-Agency есть план обучения для сотрудников — он открыт и опубликован на их сайте.
Я хочу пройти этот план, для этого решил сделать себе список материалов и ссылок, где я мог бы отмечать прогресс.
Три способа собрать данные в таблицу:
- Ручной. Можно скопировать всё руками: текст сюда, достать ссылку, поставить рядом, указать номер.
- Автоматический. Написать парсер на Питоне (как я делал с блогом Бирмана). Но потом придется всё равно как-то копировать данные в гугл-таблицы, где надо будет отмечать прогресс.
- Полуавтоматический. Как-то сразу получить данные с сайта в таблицы. Видел в гугл-таблицах формулы для импорта HTML.
Выбираю третий вариант — будут парсить сразу в гугл-таблицы.
Парсинг
Через внутреннюю справку ищу подходящую формулу для парсинга. Нахожу IMPORTHTML:
Imports data from a table or list within an HTML page.
Синтаксис формулы: IMPORTHTML(url, query, index). Здесь query это либо список, либо таблица. Удобно для узкой задачи, но у нас текст и заголовки — не подходит.
Смотрю похожие формулы, нахожу IMPORTXML:
Imports data from any of various structured data types including XML, HTML, CSV, TSV, and RSS and ATOM XML feeds.
Синтакс IMPORTXML(url, xpath_query), где
- url — ссылка,
- xpath_query — запрос на языке XPath.
Вроде похоже. Для теста запускаю формулу с ссылкой на веб-страницу IT-Agency с параметром по умолчанию:
Получаю такой результат. Формула работает, остаётся отладить детали.

Иду на веб-страничку с планом и изучаю как выглядят нужные мне элементы через хром девтулс:
Значит, мне нужны тэги h2, h3, p и атрибут href у тэгов a (адреса ссылок). Лезу в мануал изучать синтаксис языка XPath.
Чтобы убрать из выдачи технические элементы, добавил условие, что элементы должны быть дочерними от div с любым атрибутом. В результате получаю такую формулу:
И весь текст с сайта, разбитый на колонки в таблице.

Обработка
С парсингом разобрался, теперь есть данные. Пока что выглядит не очень — здесь сложно отслеживать прогресс и изучать материалы. Оформим всё как надо.
Некоторые тэги p разбиты на несколько ячеек — соберём текст в одну ячейку через формулу JOIN.
Но список большой, хочу взять формулу и скопировать на всю длину. Но тогда она заджойнит и ссылки. Разделю на этом этапе текст и ссылки в разные колонки, чтобы потом получить удобный список.
Делаю ячейку True / False с детектором ссылок через простое регулярное выражение:
Добавляю в формулу join проверку на условие True / False из ячейки с детектором ссылки:
В соседнюю колонку собираю отдельно ссылки по тому же условию только инвертированному
Получаю две колонки: отдельно весь текст и все ссылки

Эти две колонки удобно взять и скопировать на новый лист, чтобы оформить.
Оформление
Копирую колонки с текстом и ссылками на новый лист. Использую копирование, а не автоматические ссылки, чтобы зафиксировать ячейки. Дальше будет оформление и не хочу, чтобы оно потом «поползло». На этом этапе теряется автоматизация — если страница на сайте агентства поменяется, то контент в таблице останется прежним.
Заменил дефолтный шрифт Arial на приятный Proxima Nova, который чем-то похож на шрифт Gerbera на сайте агентства.
Добавим условное форматирование цвета заголовков через регекс:

Оформить заголовок, добавить туда ссылку на оригинал.
Сделаем ссылки great again — добавим каждой название. Для этого спарсим название страницы по каждоый ссылке:
Из ссылки и спарсенного названия составляем красивую ссылку через формулу HYPERLINK
В таблицах есть какое-то системное ограничение на парсинг, поэтому только часть из 290 формул смогли спарсить название страницы. Для этого в формулу HYPERLINK добавил проверку на ошибку парсинга — если есть ошибка, то название ссылки будет самой ссылкой.
У каждой ссылки ставим чекбокс, чтобы не забыть, что уже прочитал. Чтобы разделить ссылки на открытые и внутренние, я ставил чекбоксы в два разных столбца для каждого типа.
Группируем строки по темам, чтобы было легче перемещаться по всей длине документа.
Скрываем рабочие поля, получаем опрятную страницу.

Дешборд с прогрессом
Теперь eсть список материалов по теме с чекбоксами у каждой ссылки. Хочу видеть общую информацию о прогрессе по каждой области на отдельной странице. Такие страницы со сводкой называют дешбордами (dashboard).
Чтобы понять прогресс по каждому разделу, нужно знать, сколько чекбоксов отмечено — считаем по формуле:
Рядом так же считаем столбец с чекбоксами внутренних ссылок. И считаем общее количество ссылок в разделе.
Здесь на каждый раздел пришлось руками ставить границы формулы. Не придумал, как можно автоматизировать.
Делаю новый лист. С помощью SQL-подобного запроса соберём с листа названиями разделов. Повезло, что они пронумерованы римскими цифрами — это упрощает дело. Есть всего три знака, с которых может начинаться искомые строки: ’I’, ’V’ или ’X’.
Через VLOOKUP собираем счётчики по каждому разделу
Получается 4 числа:
- сколько пройдено открытых материалов,
- сколько пройдено закрытых,
- сколько всего материалов,
- и ещё сколько из них открытых.
Чтобы понимать прогресс из этих цифр собираем строку вида «25 / 63» формулой
Т.к. это первый пост про гугл таблички, то кроме разбора конкретной функции расскажу в целом чем же они так хороши.
Гугл таблички (далее ГТ) просчитываются на бекенде, т.е. на серверах гугла и продолжают работать даже если они закрыты физически у вас в браузере. Это значит, что сложные вычисления, справочники, доки со скриптами и т.д. продолжают работать в фоне. Это позволяет из ГТ делать настоящую информационную экосистему в компании. Если добавить сюда бесчисленные интеграции - то ГТ могут собрать всё инфо в вашем бизнесе и в автоматическом режиме с ней работать.
Что касается персонального использования - то тут плюсом будут в основном интеграции и скрипты, которые оч просто использовать и обращаться к ним с телефона или вообще из телеграмма.
С прелюдией всё, переходим к мясу.
У ГТ есть замечательнейшая функция =importxml(), которая позволяет забирать данные с сайтов, т.е. парсить эти самые сайты. Функционал её ограничен и полноценного парсера в ГТ не сделать по двум причинам:
1. Оно не может парсить данные с сайтов, где необходима авторизация.
2. Оно имеет техническое ограничение на кол-во попыток парсинга, т.к. вход на сайт парсер осуществляет с одного и того же IP. Если на сайте установлено ограничение на кол-во заходов в минуту (а его специально ставят против парсеров), то работать он будет, но будет это крайне медленно.
Итак, к самой функции.
Покажу на двух примерах - КиноПоиск и Авито.
Я очень люблю ужастики, поэтому работать будем с ними :3
Заходим на кинопоиск и исследуем конкретный элемент:



На сайтах похожие элементы чаще всего имеют одинаковый класс внутри тега div, span или a. Технически грузить не буду, достаточно навести мышкой на кусок когда и нужный элемент будет подсвечен. Нам нужен тег и его класс. Т.е. div и 'info'.
Дальше заходим в ГТ и пишем следующее:
Первый аргумент функции - ссылка на сайт. Второй - запрос на языке Xpath, который ведет к заветному div с классом 'info'. На выходе получаем:

Аналогично для авито:




Вот и все на сегодня) Пост первый, так что жду критики и советов, чтобы следующий контент материал был более читабельным и полезным)
xPath это такой язык запросов, который позволяет среди множества элементов веб-страницы найти нужный, — и обратиться к нему, чтобы достать необходимые данные:
xPath поддерживают платные инструменты для парсинга (например, Screaming Frog Seo Spider), его выражения можно использовать в программировании на JavaScript, PHP и Python, и даже сделать простой бесплатный парсер прямо в Google Таблицах. Разбираемся, как именно — на трех практических примерах.
Когда начинаешь изучать большинство видео/статей по теме, начинает взрываться мозг — кажется, что все это очень сложно и подвластно только крутым технарям/хакерам. На самом деле все 200 встроенных функций xPath (как сообщает туториал W3C) знать совсем не обязательно, и на практике освоить язык получается гораздо проще. Процесс напоминает привычное ориентирование в папках и файлах в компьютере, а сами выражения xPath — адреса вроде «C:\Program Files (x86)\R-Studio».
1. Сбор и проверка заголовков и метатегов
Подготовка таблицы и разбор синтаксиса IMPORTXML
Начать можно с дизайна самой таблицы. Допустим, в первой колонке (A) будут ссылки на страницы, а правее уже результаты, извлеченные данные: H1, тайтл, дескрипшн, ключевые слова.
Тогда стоит первую строку отдать под заголовки (если планируются десятки ссылок, не помешает «Вид → Закрепить → 1 строку»), в A2 указать URL (можно пока любой — для проверки работоспособности) и приступить к написанию первой функции. (А так как текстовые фрагменты довольно длинные, можно заодно выделить все ячейки, нажать «Формат → Перенос текста → Переносить по словам».)

Начало работы с парсер-таблицей. В качестве примера разберем заголовки и метатеги главной страницы Webartex — это такая платформа для работы с блогерами и сайтами.
Для импорта данных с сайтов (в форматах HTML, XML, CSV) в Google Таблицах есть функция IMPORTXML. Она принимает такие аргументы:
Составление функций для импорта XML с разными запросами xPath
Для парсинга H1 получится довольно просто: =IMPORTXML(A2;"//h1").
"//" это оператор для выбора так называемого корневого узла — откуда нужно будет сразу взять данные или же «плясать» дальше (к дочернему элементу, соседнему или др.). В данном случае не нужно прописывать длинный путь, указывать дополнительные параметры — тег <h1> такой один единственный (как правило, но может быть и несколько заголовков первого уровня, тогда запрос "//h1" выгрузит их в несколько строк).
Правда, есть нюанс — часть заголовка первого уровня оказывается в ячейке D2, а там нужны совсем другие данные. Все из-за тега <br>, который внутри <h1> используется для перевода строки. Решение — функция самого xPath "normalize-space()", в которую нужно упаковать текст из H1. Дополненная функция получается такой: =IMPORTXML(A2;"normalize-space(//h1)")

xPath-локатор работает корректно, можно идти дальше
В ячейке C2 — по тому же принципу, только выражение xPath, соответственно, будет "//title".
А вот для загрузки дескрипшна в соседнюю ячейку D2 нельзя указать просто "//description", потому что такого отдельного тега нет. Эти данные лежат в теге <meta>, у которого есть дополнительный параметр (атрибут) — "name" со значением "description".
Если в запросе xPath нужно указать не просто элементы веб-страницы, а элементы с конкретным атрибутом, то соответствующие условия указываются в квадратных скобках. Название атрибута пишется с собакой "@", а его значение передается через одинарные кавычки. Если нужно проверить эквивалентность, то условие записывается просто как «атрибут = значение».

Шпаргалка: из чего состоят HTML-элементы, из которых уже состоят веб-страницы (иллюстрация из курса Hexlet по основам HTML, CSS и веб-дизайна).
Это хорошо видно, если открыть исходный код страницы (например, через сочетание клавиш Ctrl + U в Google Chrome). У <meta> нет закрывающего тега </meta>, как это бывает у многих других, получается, нет и внутреннего содержания. Нужные данные лежат в другом атрибуте — @content.

Исходный код страницы Webartex, на которых хорошо видно устройство тегов <meta>
Если нужно указать не корневой элемент (узел), а его параметр или вложенный тег, тогда уже используется одинарный слеш, а не двойной. По аналогии с URL страниц сайтов или адресами файлов и папок операционной системы.

Результаты после запуска всех функций. Все формулы написаны верно, данные собираются корректно, все работает нормально.
Если нужно, аналогичным образом можно извлекать и другие данные: подзаголовки H2—H6, метатеги для разметки OpenGraph и Viewport, robots и др.
Бонус: оценка полученных метатегов и заголовков
Допустим, нужно проверить, находится ли длина title и description в пределах нормы. Для этого можно воспользоваться функцией гугл-таблиц ДЛСТР (LEN). Она работает довольно просто: на входе текстовая строка, на выходе — число символов.
Согласно рекомендациям из блога Promopult, отображаемая длина тайтла в Google — до 50-55, а в Яндексе — до 45-55. Поэтому желательно не писать его слишком длинным, по крайней мере в первых 45–55 символах должна быть законченная мысль, самое главное о странице.
Чтобы не создавать дополнительных ячеек с цифрами по количеству символов, можно прописать формулу LEN в условном форматировании. Выделить третий столбец C, кликнуть в меню на «Формат → Условное форматирование», выбрать в списке «Правила форматирования» вариант «Ваша формула». И туда уже прописать, допустим, =LEN($C$2:$C)>55. А цвет, например, желтый, который как бы будет сигнализировать: «Тут надо посмотреть!».
В данном примере строка C2 пожелтеет, так как длина title составляет 59 знаков, а не 55. Но в принципе вся ключевая мысль, призыв к действию, умещается в лимит, так что все нормально.

Настройка условного форматирования Google Таблиц для подсвечивания тайтлов, длина которых больше рекомендуемой
А еще там есть рекомендация не указывать в метатеге keywords больше 10 ключевых слов. Но чтобы проверить это, нужен не подсчет длины, а количества самих слов, разделенных запятыми.
В гугл-таблицах нет специальной функции, которая считает количество вхождений определенных символов в текстовую строку, но эту задачу можно решить через условное форматирование с помощью такой формулы: =COUNTA(SPLIT($E$2:$E;","))>10. Небольшой ликбез:
- SPLIT — разделяет текст по определенным символам и выводит в разные ячейки. Два обязательных параметра: 1) собственно, текст, который нужно разделить, или ссылку на ячейку с таковым 2) один или несколько символов в кавычках, по которым как раз и нужно разделять текст.
- СЧЁТЗ (COUNTA) подсчитывает количество значений в наборе данных: принимает неограниченное число аргументов (значений и диапазонов). В данном случае забирает на вход результаты SPLIT, выдающей массив текстовых значений, и подсчитывает их общее число.
«Поисковое продвижение» — бесплатный видеокурс по SEO в обучающем центре CyberMarketing. В программе структура поисковой выдачи, санкции поисковых систем, инструменты для сбора семантического ядра и другие важные темы. Преподаватель — Евгений Костин, руководитель департамента продаж системы Promopult.
2. Парсинг ссылок из топ-10 поисковика
Допустим, нужно регулярно мониторить топ Яндекса по определенному запросу, чтобы узнать, попал ли туда конкретный сайт и на какую позицию. Можно с помощью xPath извлечь все ссылки с органической выдачи, а благодаря текстовым функциям Google Таблиц уже искать совпадения с названием нужного сайта.
Поиск и анализ нужных элементов через DevTools
В качестве примера — запрос «отложенный постинг». Для начала нужно в браузере Chrome перейти на соответствующую страницу, кликнуть правой кнопкой на один из элементов, который нужно будет извлечь (пусть это будет ссылка ниже заголовка), и нажать на «Просмотреть код» (горячие клавиши — Ctrl + Shift +I). Тогда откроются «Инструменты разработчика» (Chrome DevTools) с кодом этого элемента.
В коде документа сразу можно заметить древовидную структуру. На самом верху — корневой тег <html>, внутри на одном уровне <head> и <body>, затем <body> раскрывается на десятки <div> и <script>, а в некоторых <div> еще другие <div> с <ul>, <li>, <h2> и т. п. Написание xPath-запроса напоминает квест: нужно правильно описать искомый элемент и путь к нему.

Так выглядит просмотр кода нужного элемента в Chrome DevTools. (И было бы удобно кликнуть еще раз правой кнопкой, потом выбрать Copy и Copy XPath, затем вставить этот код в соответствующую функцию Таблиц, но, увы, как правило, так не работает. Приходится разбираться.)
Напоминаем: страница состоит из элементов, а каждый элемент включает тег и содержание (что между открывающим и закрывающим тегом), а еще в открывающем теге может быть дополнительная информация: атрибуты и их значения. В данном случае необходимые данные — ссылка на страницу, которая попала в топ Яндекса — находятся в значении атрибута "href" тега <a>, у которого еще есть атрибут "class" со значением "Link Link_theme_outer Path-Item link path__item i-bem link_js_inited"
(А этот тег <a> находится внутри тега <div> с атрибутом "class" и значением "Path Organic-Path path organic__path"… но весь путь писать нет смысла, если сам <a> достаточно уникальный и правильно находится.)
Фрагмент кода (на скриншоте он не помещается целиком):
Но прежде чем писать запрос xPath, стоит проверить — действительно ли все нужные элементы имеют соответствующие атрибуты и значения. "href", понятно, будет везде разный, а вот что насчет "class" со значением "Link Link_theme_outer Path-Item link path__item i-bem link_js_inited"?
Для этого в окне «Инструменты разработчика» нужно нажать «Ctrl + F» и внизу появится поле «Find by string, selector, or xPath». Если вставить эту большую и страшную строку, видно, что подсвечивается с десяток элементов.

В процессе поиска нужного значения в коде через Chrome DevTools. Вроде все хорошо, и подсвечиваются нужные элементы с необходимыми ссылками…
Написание xPath-локатора с учетом изученных элементов и их параметров
Вспоминаем: "//" — это оператор, который выбирает так называемый корневой узел — элемент для непосредственного извлечения данных или тот, от которого нужно будет дальше «плясать». Значит, нужно начать с «//a». Но если оставить так, то загрузятся все <a> со страницы, а для решения задачи нужны конкретные. То есть нужно указать, что нужен элемент <a> с атрибутом @class, у которого есть конкретное значение.
Ах, да — как и в случае с description и keywords, искомые данные лежат в другом атрибуте. То есть нужно продолжить путь с помощью "/@href". Но функция снова не может импортировать данные.

Вроде все написано правильно, но импорт данных не работает…

Вставили в IMPORTXML такой запрос xPath — все заработало.

Выражение работает корректно: в списке URL’s органической выдачи, без рекламных ссылок и колдунщиков
3. Выгрузка статистики по популярным статьям в блоге
Допустим, автору (редактору, маркетологу или блогеру) хочется следить за популярными материалами в других медиа, чтобы черпать идеи по новым темам уже для своего ресурса. Можно делать это вручную — заходить на каждый сайт, скроллить, тратить время на поиск соответствующего блока — или собирать такие данные в таблицу. Рассмотрим, как это можно делать, на примере сайта Yagla (не самый посещаемый тематический ресурс, но интересный вариант с точки зрения освоения языка xPath).
Изучение сайта и подходящих элементов
Для начала: кликнуть правой кнопкой мыши на один из нужных заголовков в вышеперечисленных блоках, выбрать «Просмотреть код». Chrome DevTools подсвечивают тег <p> с атрибутом @class равным "small-post__title". Но если ввести это значение в поле «Find by string, selector, or xPath» видно, что оно есть и у материалов другого блока «Примеры роста конверсий, заказов и прибыли», который не нужно импортировать.

Начинаем изучать элементы главной страницы сайта в «Инструменты разработчика» Google Chrome
Но ведь можно прописать путь к элементу не только по значению атрибута, но и его содержанию, тексту.
Составление запроса xPath

Проверка первой части запроса xPath в DevTools показывает, что все ищется верно
Базовая настройка и оформление таблицы

Такая вот таблица с популярными материалами получается в итоге
Внутри искомого <p> есть еще <span> с указанием формата, поэтому IMPORTXML требуется дополнительный столбец справа. (Так как эта информация излишняя, можно просто выделить все ячейки B, кликнуть правой кнопкой и выбрать «Скрыть столбец».)
Бонус: прокачка мини-парсера в Google Spreadsheets
Допустим, названия статей мало, нужны еще и просмотры, которых нет на главной странице. Тогда придется немного усовершенствовать гугл-таблицу. Разберем на примере блока «Обсуждаемое» — с другим все будет так же.

Все работает — в таблице появились ссылки на статьи.
Правда, ссылки не полные, а относительные — нужно превратить их в URL’s с названием домена. Решить задачу можно с помощью текстовой функции гугл-таблиц — СЦЕПИТЬ (CONCATENATE). Она работает просто: принимает на вход несколько строк, а возвращает объединенный текст.

Пока что получился такой некрасивый результат
Остается только протянуть ее ниже — для всех строк с выгруженными URL статей.
Подытожим
xPath в гугл-таблицах — мощная штука, однако подходит только для решения относительно простых задач.
Так, при наличии большого количества формул типа IMPORTHTML, IMPORTDATA, IMPORTFEED и IMPORTXML результаты могут грузиться очень долго — а польза парсинга как раз в том, что можно быстро добывать свежие данные. К тому же, например, статистику Яндекс.Вордстат не получится извлечь через xPath — для работы нужна авторизация, да и даже при ручном сборе сервис может замучать капчей.
Поэтому для более серьезных задач по продвижению/оптимизации нужны профессиональные инструменты, например, Promopult. Там большой выбор решений для SEO- и PPC-специалистов: парсинг Wordstat и метатегов, сбор поисковых подсказок и кластеризация запросов, поиск и генерация объявлений и др. Один запрос стоит от 0.01 руб.

К слову, в таблицах Excel также имеется инструмент, который позволяет выполнять подобный парсинг и мы с ним ранее уже сталкивались. Только в таблицах Google он реализован и работает намного лучше, поэтому мое предпочтение однозначно за этим инструментом.
Так или иначе, заходим на Google-диск и нажимаем кнопку " Создать ", а затем из выпадающего меню выбираем " Google таблицы ".
Подробности дальнейшей работы по импорту данных с сайтов в таблицы Google рассматриваются на нашем YouTube-канале " Учите компьютер вместе с нами ". Также вы можете воспользоваться рекомендациями ниже.
Пробежавшись по основному меню Google-таблиц мы увидим, что пункта, который был отвечал за импорт данных со сторонних сайтов здесь нет. А все потому, что данный функционал реализован с помощью встроенных функций рабочего листа.
Итак, выделяем ячейку, начиная с которой мы хотим получить результирующую таблицу, например ячейку "А1". Ввод любой формулы или встроенной функции, как в Excel так и в Google-таблицах, начинается со знака равенства. А дальше вводим функцию:
=IMPORTHTML(ссылка; запрос; индекс)
Данная функция умеет импортировать со сторонних сайтов содержимое таблиц или списков. Всплывающая подсказка помогает нам настроить ее параметры:
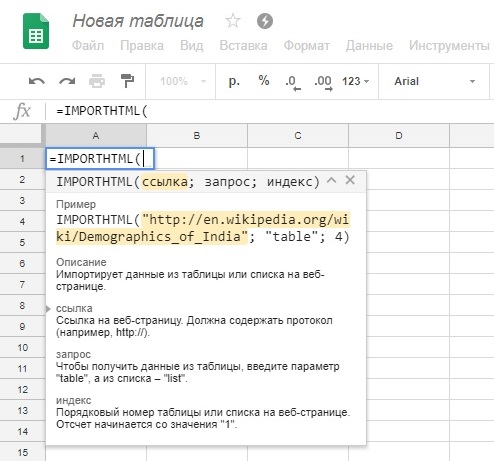
Параметр " Ссылка " содержит полный URL-адрес сайта, с которого вы хотите импортировать данные. Ссылка должна заключаться в кавычки.
Параметр "Запрос" может принимать значение "table" или "list". В первом случае данные будут импортироваться из таблицы на выбранном сайте, а во втором - со списка.
Поскольку таблиц или списков на обозначенной странице сайта может быть несколько, в параметре "Индекс" нам необходимо указать ее порядковый номер, например "1", "2" и так далее.
После ввода формулы, нажимаем клавишу "Enter" и ждем пару секунд. Google-таблицы соединяются с указанным сайтом и импортируют из него выбранный блок информации.
Если необходимо отредактировать введенную формулу или удалить ее, тогда все необходимые правки делаем с той ячейкой, куда эта формула была введена. В нашем случае это ячейка "А1". Также, если необходимо обновить данные импортированной таблицы, входим в режим редактирования этой ячейки и повторно нажимаем клавишу "Enter".
Как сообщалось на нашем сайте ранее, вы без проблем можете выполнять экспорт Google документов в другие форматы данных.
Читайте также: