
Браузер и сервер что это
Эта статья — короткий и простой перевод статьи « What happens when… », опубликованной на Гитхабе. В ней автор подробно рассказывает, что именно происходит внутри компьютера, когда мы вводим в браузере адрес сайта и нажимаем энтер. Мы убрали излишние технические подробности вроде IRQ-прерываний и ARP-запросов и добавили картинки, чтобы было проще понять суть.
Начало
Мы ввели адрес сайта — thecode.media — и нажали энтер. Что происходит дальше?
Поиск сервера в интернете
Каждый сайт в сети физически хранится на каком-то сервере. Как только браузер от нас получил адрес сайта, он должен понять, к какому серверу обратиться за данными. Но то, что мы называем адресом, на самом деле не адрес, а доменное имя.
👉 Проще говоря, когда вы садитесь в такси и говорите «Мне в „Мегу“», вы назвали водителю не адрес, а доменное имя. Водитель уже сам должен знать, где в вашем городе «Мега».
Так вот: теперь задача браузера — определить по доменному имени адрес, на который отправлять запрос. В мире интернета этот адрес называется IP-адресом. Он есть у каждого сервера и выглядит, например, так:
- Сначала смотрит, посещали мы этот сайт раньше или нет. Если посещали — возьмёт IP-адрес из истории. Так же, как водитель, который тысячу раз ездил в «Мегу».
- Если не посещали — посмотрит в конфигурационных файлах операционной системы. Иногда для ускорения работы некоторые IP-адреса можно прописать в конфигурации компьютера, чтобы он сразу знал, куда обращаться.
- Если в настройках такого нет, браузер смотрит недавние адреса в роутере, через который компьютер подключается к интернету.
- Если и там нет, то браузер отправляет запрос на DNS-сервер. Там точно всё есть, но результат получится медленнее, чем в остальных способах.
DNS-сервер — это такая служба в интернете, которая отвечает всем желающим на вопрос «Какой IP у такого-то домена?». Таких серверов в интернете много, и каждый из них знает про свою часть сети. Если у ближайшего сервера нет записей о нашем домене, то он отвечает «Я не знаю, спроси у DNS-сервера покрупнее, вот его адрес». В итоге браузер найдёт DNS-сервер, который знает то, что нам нужно, и получит IP-адрес сервера с сайтом.
В предыдущем материале мы рассмотрели, как работает Интернет на базовом уровне, включая взаимодействие между клиентом (вашим компьютером) и сервером (другим компьютером, который отвечает на запросы клиента о веб-сайтах).
В этой же части рассмотрим, как устроены клиент, сервер и веб-приложение, что мы можем удобно серфить в Интернете.
Модель клиент-сервер
На самом деле, модель клиент-сервер - это ни что иное, как способ описать отношения между клиентом и сервером в веб-приложении. Это детали того, как информация переходит от одного конца к другому, где картина усложняется.
Базовая конфигурация веб-приложения
Существует сотни способов настройки веб-приложения. При этом большинство из них следуют одной и той же базовой структуре: клиент , сервер , база данных .
Клиент
Клиент - это то, с чем взаимодействует пользователь. Так что «клиентский» код отвечает за большую часть того, что на самом деле видит пользователь. Это включает в себя:
- Определение структуры веб-страницы
- Настройка внешнего вида веб-страницы
- Реализация механизма пользовательского взаимодействия (нажатие кнопок, ввод текста и т.д.)
Структура : Макет и содержимое веб-страницы определяются с помощью HTML (обычно HTML 5, если речь идет о современных веб-приложениях, но это другая история.)
HTML означает язык гипертекстовой разметки (Hypertext Markup Language). Он позволяет описать основную физическую структуру документа с помощью HTML-тэгов. Каждый HTML-тэг описывает определенный элемент документа.
- Содержимое тега «<h1>» описывает заголовок.
- Содержимое тега «<p>» описывает абзац.
- Содержимое тега «<button>» описывает кнопку.
- И так далее.
Веб-браузер использует эти HTML-тэги для определения способа отображения документа.
Look and Feel : Чтобы определить внешний вид веб-страницы, веб-разработчики используют CSS , который расшифровывается как каскадные таблицы стилей (Cascading Style Sheets). CSS - это язык, который позволяет описать стиль элементов, определенных в HTML, позволяя изменять шрифт, цвет, макет, простые анимации и другие поверхностные элементы.
Стили для указанной выше HTML-страницы можно задать следующим образом:
Взаимодействие с пользователем : Наконец, для реализации механизма взаимодействия с пользователем, на сцену выходит JavaScript .
Например, если вы хотите что-то сделать, когда пользователь нажимает кнопку, вы можете сделать что-то подобное:
Иногда взаимодействие с пользователем, может быть реализовано без необходимости обращения к вашему серверу - отсюда и термин "JavaScript на стороне клиента". Другие типы взаимодействия требуют отправки запросов на сервер для обработки.
Например, если пользователь публикует комментарий в потоке, может потребоваться сохранить этот комментарий в базе данных, чтобы весь материал был структурирован и собран в одном месте. Таким образом, вы отправляете запрос на сервер с новым комментарием и идентификатором пользователя, а сервер прослушивает эти запросы и обрабатывает их соответствующим образом.
Сервер
База данных
Базы данных – это подвалы веб-архитектуры - большинство из нас боятся туда спускаться, но они критически важны для прочного фундамента. База данных - это место для хранения информации, чтобы к ней можно было легко обращаться, управлять и обновлять.
Например, при создании сайта в социальных сетях можно использовать базу данных для хранения сведений о пользователях, публикациях и комментариях. Когда посетитель запрашивает страницу, данные, вставленные на страницу, поступают из базы данных сайта, что позволяет нам воспринимать взаимодействие пользователей в реальном времени как должное на таких сайтах, как Facebook или в таких приложениях, как Gmail.
Как масштабировать простое веб-приложение
Вышеописанная конфигурация отлично подходит для простых приложений. Но по мере роста приложения один сервер не сможет обрабатывать тысячи - если не миллионы - одновременных запросов от посетителей.
Чтобы выполнить масштабирование в соответствии с этими большими объемами, можно распределить входящий трафик между группой внутренних серверов.
Ответ очевиден - никак. Управление всеми этими отдельными экземплярами приложения происходит через средство балансировки нагрузки.
Подсистема балансировки нагрузки действует как гаишник, который маршрутизирует клиентские запросы по серверам как можно быстрее и эффективнее, насколько это возможно.
Поскольку вы не можете транслировать IP-адреса всех экземпляров сервера, вы создаете виртуальный IP-адрес, который транслируется клиентам. Этот виртуальный IP-адрес указывает на подсистему балансировки нагрузки. Таким образом, когда DNS ищет ваш сайт, он указывает на балансировщик нагрузки. Затем подсистема балансировки нагрузки перескакивает для распределения трафика на различные внутренние серверы в реальном времени.
Возможно, вам интересно, как подсистема балансировки нагрузки узнаёт, на какой сервер следует отправлять трафик. Ответ: алгоритмы.
Один популярный алгоритм, Round Robin , включает равномерное распределение входящих запросов по ферме серверов (все доступные серверы). Вы обычно выбираете такой подход, если все ваши серверы имеют одинаковую скорость обработки и память.
С помощью другого алгоритма, Least Connections , следующий запрос отправляется на сервер с наименьшим количеством активных соединений.
Существует гораздо больше алгоритмов, которые вы можете реализовать, в зависимости от ваших потребностей.
Например, для получения итоговой страницы, которую пользователь будет просматривать в браузере, сервер приложений может заполнить HTML-шаблон данными из базы данных. По этому принципу работают такие сайты, как MDN или Википедия, которые состоят из тысяч веб-страниц, являющихся не реальными HTML документами, а несколькими HTML-шаблонами и объемными базами данных. Эта структура упрощает и ускоряет сопровождение веб-приложений и доставку контента.
Для чего нужен веб-сервер
Также к задачам веб-серверов относятся создание журналов ошибок и обращений к файлам (логов), аутентификация и авторизация пользователей, использование настроек для обработки файлов.
Типы веб-серверов
На сегодняшний день среди веб-серверов выделяют несколько ведущих систем:
Рейтинг-2021 для веб-серверов
Наибольшее количество пользователей по всему миру в 2021 году имеют веб-серверы:
- Apache - 40,86%;
- Nginx - 27,66%;
- IIS - 11,01;
- LiteSpeed - 2,4%;
- Apache Traffic Server - 0,53%;
- OpenGSE - 0,44%;
- Phusion Passenger - 0,36%;
- Apache Tomcat - 0,16%.
Как настроить веб-сервер
Создание такого стека можно рассмотреть на примере системы управления ВМ libvirt в Linux/Ubuntu, которая используется во многих высокоуровневых облачных платформах. Для этого формируется инфраструктура, с помощью которой сможем быстро и легко подготовить ферму виртуальных серверов требуемой конфигурации. Данный процесс включает три этапа:
- установка виртуального сетевого моста, который будет использоваться для коммуникации ВМ друг с другом и доступа реверс-прокси во внешнюю среду;
- установка и настройка libvirt;
- подготовка набора шаблонов ВМ.
Настройка сетевого моста происходит следующим образом: устанавливаются инструменты управления мостом, выбирается основной сетевой интерфейс и редактируются настройки. В качестве IP-адреса и маски подсети здесь следует использовать физические адреса. Предполагается, что сервер находится в локальной сети, а доступ во внешнюю среду организован с помощью шлюза. После этого проводятся подъем и проверка работоспособности бриджа, установка и отладка libvirt и создание виртуальной машины под шаблон ВМ.
Готовый шаблон ВМ используется для создания всех необходимых серверов из связки LAMP. Вначале проводятся настройки Apache/PHP. Чтобы создать новую ВМ на базе уже существующей, используется команда virt-clone: sudo virt-clone -o web_devel -n database_devel -f /path/to/database_devel.img \--connect=qemu:///system
- o: оригинальная виртуальная машина;
- n: имя новой виртуальной машины;
- f: путь к файлу, локальному тому или разделу для использования новой виртуальной машиной;
- connect: определяет к какому супервизору подключаться.
Таким образом создается новая ВМ, аналогичная уже существующей. Теперь необходимо запустить эту машину, зайти на нее с помощью все того же virt-viewer, а дальше - установить и запустить на ней связку Apache/PHP и остальные серверы. Чтобы проверить, что машина действительно запустилась, используется команду virsh: virsh -c qemu:///system start web_devel
Вторую команду следует выполнять опять же с удаленной машины, имеющей графический интерфейс. В первую очередь потребуется изменить ее IP-адрес, который достался в наследство от шаблонной ВМ. Затем - установить и настроить MySQL, добавив в в файл необходимые строки конфигурации и перезапустив сервер. После этого вводятся пользователи и создается база данных. На завершающем этапе iptables конфигурируется так, чтобы он пропускал только пакеты для MySQL. Чтобы настройки вступили в силу после перезагрузки, эти строки следует добавить в /etc/rc.local (без sudo).
Теперь следует создать и настроить сервер memcached. Для этого, как и в случае с сервером MySQL, требуется создать клон заранее подготовленного шаблона, запустить виртуальный сервер и подключиться к нему, добавить правило iptables, закрывающее все порты, кроме порта memcached и установить аналогичные строки в /etc/rc.local.
Установка и настройка Apache/PHP проводится на одной виртуальной машине. Это связано с особенностями архитектуры PHP, выполненного в виде Apache-модуля. Процесс установки Apache/PHP будет выглядеть так:
- создание и запуск клона;
- правка сетевых конфигураций и постановка необходимых модулей;
- размещение сайта в каталоге /var/www/html и перезапуск Apache;
- добавление правила iptables для пропуска трафика на 80-й порт.
Заключительный шаг - настройка веб-сервера nginx в режиме реверс-прокси. Nginx позволит создать задел для будущего расширения созданной конфигурации, выступая в роли балансировщика нагрузки на несколько серверов, а также защитит от ряда угроз, работая а качестве брандмауэра прикладного уровня.
Чтобы защититься от возможных проблем с конфигурацией и прочих сбоев, сразу после настройки окончательной конфигурации следует сделать клоны всех серверов. В этом случае вышедший из строя сервер можно будет быстро восстановить из работоспособной копии. Но Apache и MySQL таким образом, восстановить не удастся, так как они содержат динамически генерируемые данные; однако эту информацию можно заранее расположить на втором виртуальном диске, который достаточно будет подключить после восстановления рабочей копии.
Подбираем оборудование
Основное требование, которое предъявляется к аппаратной платформе для веб-сервера - высокая скорость работы, которая показывает минимальное время отклика у накопителя, хранящего запрашиваемые данные. Поэтому для создания оперативно действующего веб-сервера рекомендуется использовать оборудования с твердотельными накопители, которые быстрее и надежнее традиционных жестких дисков.
Чаще всего аппаратная платформа веб-серверов представляет собой компактные одноюнитовые решения с поддержкой одного-двух процессоров. К наиболее популярным из них относятся:
- HP ProLiant DL360 Gen9 - сервер высокой плотности с одним или двумя процессорами (на выбор). Использование флагманских твердотельных накопителей NVMe PCIe в форм-факторе 2,5˝ объемом до 2 Тбайт позволяет снизить время задержки и повысить эффективность работы с данными.
- HPE ProLiant DL360 Gen10. Высокопроизводительный двухпроцессорный сервер с возможностью установки процессоров Intel Xeon Scalable серий 3100, 4100, 5100, 6100 и 8100. Оснащается оперативной памятью DDR4 частотой 2666. Позволяет установить 10 SFF жестких дисков, или SSD-дисков, или NVMe.;
- Dell R630 - двухпроцессорный стоечный сервер с большой плотностью установки. Поддерживает до 24 флэш-накопителей форм-фактора 1,8ʺ или до 10 дисков форм-фактора 2,5ʺ.
Компания ServerGate предлагает всем, кто ищет веб-сервер для частного использования в корпоративных целях или размещения внешних сайтов, б/у оборудование от перечисленных вендоров. Мы поможем вам сэкономить, подобрав оптимальное по скорости доступа к данным и производительности решение.

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
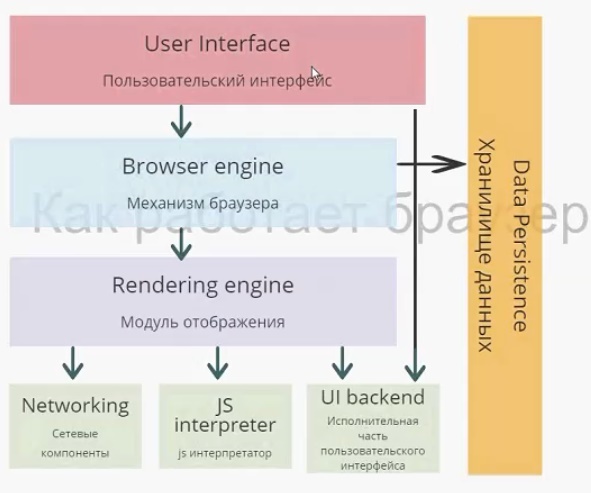
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения
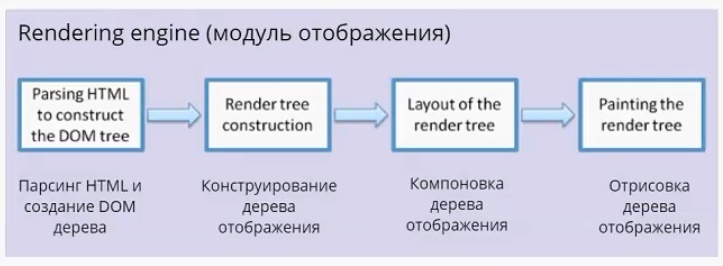
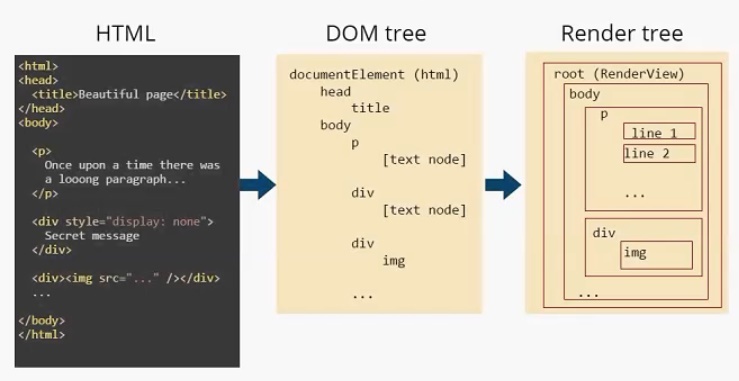
Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
- Дерево отображения не содержит скрытых элементов. Если у нас есть html-элемент, у которого прописан display:none , в дереве отображения он присутствовать не будет. При этом, если visibility:hidden , то в дереве отображения он будет. Некоторые DOM-узлы, которые в DOM-дереве представлены как единый узел, в дереве отображения могут быть представлены в виде нескольких. Яркий пример — составной тэг select. Если в DOM-дереве это один узел, в дереве отображение он преобразовывается в минимум три узла. Первый узел отвечает за отображение выбранного элемента. Второй — за выпадающий список с возможными пунктами. И, наконец, третий блок отвечает за стрелочку.
- Текст в DOM-дереве представлен как простая node. DOM-дереву нет никакого дела до того, что там написано, сколько строк этот текст занимает. В то время, как для дерева отображения — это важно, и текст трансформируется в несколько узлов, в зависимости от того сколько строк он занимает. Это нагляднее рассмотрим чуть позже.
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.

Предлагаю рассмотреть два браузерных движка: Webkit и Gecko.
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).
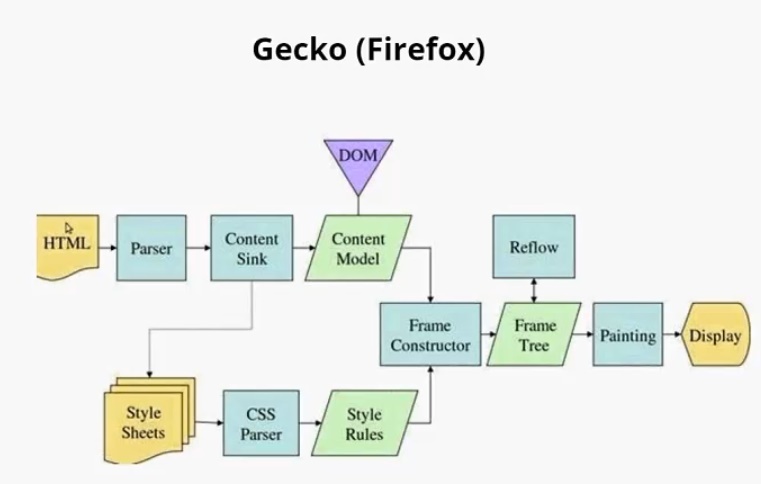
Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
- Attachment = Frame constructor = Совмещение
- Render Tree = Frame Tree = Дерево отображения
- Layout= Reflow = Компоновка
Пример

Здесь у нас есть теги:

Модуль отображения строит DOM-дерево. В данном случае оно будет выглядеть следующим образом. Есть корневой элемент (он всегда присутствует), называется он documentElement и соответствует тегу html . В этом дереве присутствуют все теги. И заметим, что текст представлен, как [text node] . И DOM-дереву больше ничего о тексте знать не нужно. На основе этого DOM-дерева строится Render Tree.
Пример
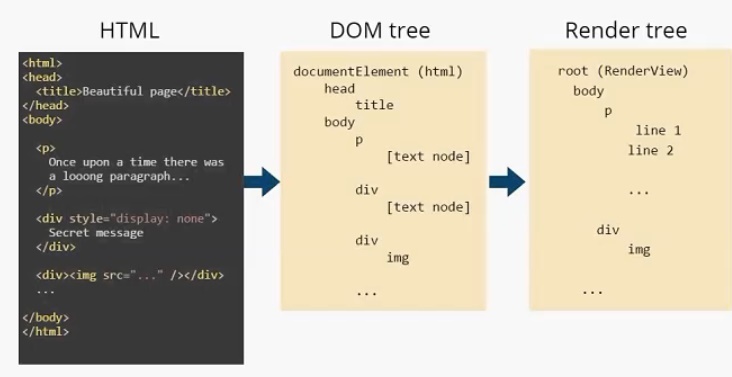
Дерево отображения. У него также есть корневой элемент (RenderView), но уже можно увидеть отличия между DOM-деревом и деревом отображения. Во-первых, нет тега head , т. к. он не отображается на экране. Нет <div style =” display: none”> , есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример
Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
При этом скрипт 3 все равно не будет выполняться, пока не выполнится скрипт 1. К моменту, когда скрипт 1 уже выполнится, скрипт 3 уже может быть полностью загружен. Скрипты можно вставлять в теги head и body . Разница в том, что в скрипте 2, в отличии от скрипта 1, практически весь документ уже будет проанализирован.
У скрипта могут быть атрибуты, такие как defer и async . Они похожи, но у них есть отличия:
- Атрибут defer сообщает браузеру, чтобы тот не ждал окончания выполнения скрипта, а продолжал парсинг html-страницы. При этом скрипт 4 выполнится только после того, как весь html-документ будет проанализирован и построено DOM-дерево.
- Атрибут async тоже говорит браузеру, что дальнейший html-документ может быть проанализирован, пока скрипт выполняется. При этом он загружается в параллельном потоке и выполняется сразу после загрузки. Это означает, что он может быть выполнен раньше, чем скрипт1, если последний тоже имеет атрибут async. Т. е. порядок подключения в этом случае не соблюдается.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
- Тип окна (свойство display).
- Схема позиционирования (свойства position и float).
- Размеры окна.
- Внешняя информация (размеры изображения, размер экрана).
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Читайте также: