
1с типы данных sql
Материал сегодня будет посвящен рассмотрению типов данных языка T-SQL – это язык программирования, которой используется в СУБД Microsoft SQL Server. Мы поговорим о том, какие существуют типы данных, какие у них особенности, а также в каких случаях использовать тот или иной тип данных.
Если Вы только начинаете изучать T-SQL, то на нашем сайте Вы можете найти полезные материалы для новичков на данную тему, например статьи «Справочник Transact-SQL» и «Основы программирования на T-SQL», где мы рассматривали основные моменты данного языка.
В перечисленных выше материалах мы затрагивали типы данных, но подробно о них не разговаривали, поэтому сегодня мы рассмотрим данную тему более подробно, так как понимание типов данных поможет Вам правильно спроектировать БД или написать процедуру. Например, выбор оптимального (корректного) типа данных для столбца в таблице может в будущем отразиться на размере базы (если таблица будет интенсивно расти), а именно она будет значительно меньше, чем, если бы Вы выбрали какой-то некорректный тип данных, причем это разница может достигать несколько сотен мегабайт, а то и нескольких гигабайт!
Итак, давайте начинать.

Что такое тип данных в SQL Server?
Тип данных – это характеристика, определяющая, какого рода данные будут храниться в объекте. Например: целые числа, числовые данные с плавающей запятой, данные денежного типа, дата, время, текст, двоичные данные и так далее. У каждого столбца, выражения, переменной или параметра есть определенный тип данных. В Microsoft SQL Server существует набор системных типов данных, который и определяет все доступные по умолчанию типы данных для использования. У разработчиков также существует возможность создавать псевдонимы типов данных основанные на системных типах, а также собственные пользовательские типы данных, о том, как реализовать псевдоним типа данных, мы разговаривали в материале – «Создание псевдонима типа данных в Microsoft SQL Server на T-SQL».
Типы данных в MS SQL Server делятся на следующие категории:
- Точные числа;
- Приблизительные числа;
- Символьные строки;
- Символьные строки в Юникоде;
- Дата и время;
- Двоичные данные;
- Прочие типы данных.
Описание типов данных в T-SQL
Сейчас давайте рассмотрим типы данных по категориям.
Точные числа
Приблизительные числа
Не рекомендуется использовать столбцы с типами float и real в предложении WHERE, так как данные типы не хранят точных значений. Также не рекомендуется использовать float и real в финансовых приложениях, в операциях, связанных с округлением. Для этого лучше использовать decimal, money или smallmoney.
Символьные строки
| Наименование типа | Хранилище | Описание |
| char (n) | n байт | Строка с фиксированной длиной не в Юникоде, где n длина строки (от 1 до 8000). По умолчанию n = 1, если значение n не указано при использовании функций CAST и CONVERT, длина по умолчанию равна 30. |
| varchar ( n | max ) | Размер занимаемой памяти в байтах = количество введенных символов + 2 байта. Если указать MAX, то максимально возможный размер = 2^31-1 байт (2 ГБ). | Строковые данные переменной длины не в Юникоде, где n длина строки (от 1 до 8000). По умолчанию n = 1, если значение n не указано при использовании функций CAST и CONVERT, длина по умолчанию равна 30. |
| text | Размер занимаемой памяти в байтах = количество введенных символов. Максимальный размер 2^31-1 (2 147 483 647 байт, 2 ГБ). | Строка переменной длины не в Юникоде. Является устаревшим типом данных, рекомендуется использовать varchar(max). |
Символьные строки в Юникоде
Дата и время
| Наименование типа | Хранилище | Диапазон | Точность | Описание |
| date | 3 байта | От 01.01.0001 до 31.12.9999 | 1 день | Используется для хранения даты. |
| datetime | 8 байт | От 01.01.1753 00:00:00 до 31.12.9999 23:59:59,997 | 0,00333 секунды | Используется для хранения даты, включая время с точностью до одной трехсотой секунды. |
| datetime2 | От 6 до 8 байт (в зависимости от точности: менее 3 цифр = 6 байт, 3-4 цифры = 7 байт, более 4 цифр = 8 байт) | От 01.01.0001 00:00:00.0000000 до 31.12.9999 23:59:59.9999999 | 100 наносекунд | Расширенный вариант типа данных datetime, имеет более широкий диапазон дат и большую точность в долях секунды (до 7 цифр). |
| smalldatetime | 4 байта | От 01.01.1900 00:00:00 до 06.06.2079 23:59:00 | 1 минута | Сокращенный вариант типа данных datetime, имеет меньший диапазон дат и не имеет долей секунд. |
| time [Точность] | От 3 до 5 байт | От 00:00:00.0000000 до 23:59:59.9999999 | 100 наносекунд | Используется для хранения времени дня. Точность может быть целым числом от 0 до 7, по умолчанию 7 (100 наносекунд, 5 байт). Если указать 0, то точность будет до секунды (3 байта). |
| datetimeoffset [Точность] | От 8 до 10 байт | От 01.01.0001 00:00:00.0000000 до 9999-12-31 23:59:59.9999999 | 100 наносекунд | Используется для хранения даты и времени, включая смещение часовой зоны относительно универсального глобального времени. Точность определяет количество знаков в дробной части секунды, данное значение может быть от 0 до 7, по умолчанию 7 (100 наносекунд, 10 байт). |
Двоичные данные
Прочие типы данных
Приоритеты типов данных в T-SQL
В Microsoft SQL Server в случаях, когда оператор объединяет два выражения с разными типами данных, происходит неявное преобразование типов, если такое преобразование не поддерживается, SQL сервер будет выдавать ошибку. Чтобы определять какой тип данных из выражений преобразовывать, SQL Server применяет правила приоритета типов данных. Тип данных, который имеет меньший приоритет, будет преобразован в тип данных с большим приоритетом. Если оба выражения имеют одинаковый тип данных, результат операции будет иметь такой же тип данных.
В MS SQL Server существует следующий приоритет типов данных:
- Определяемые пользователем типы данных (высший приоритет);
- sql_variant
- xml
- datetimeoffset
- datetime2
- datetime
- smalldatetime
- date
- time
- float
- real
- decimal
- money
- smallmoney
- bigint
- int
- smallint
- tinyint
- bit
- ntext
- text
- image
- timestamp
- uniqueidentifier
- nvarchar (включая nvarchar(max));
- nchar
- varchar (включая varchar(max));
- char;
- varbinary (включая varbinary(max));
- binary (низший приоритет).
Синонимы типов данных в Microsoft SQL Server
В MS SQL Server для совместимости со стандартом ISO существуют синонимы системных типов данных. Эти синонимы можно использовать в инструкциях языка Transact-SQL точно также как и соответствующие системные типы данных, единственный момент, что после создания объекта (таблицы, процедуры) синониму назначается базовый тип данных, связанный с этим синонимом, иными словами, каких-либо признаков, что в инструкции использовался синоним, нет.
Синонимы и соответствующие им системные типы данных представлены в таблице ниже:
Распространенные ошибки при выборе типа данных в T-SQL
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
Таблица 2 (с использованием BIT столбцов)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
В шапке отчета подключение к базе SQL выполняется по параметрам:
- Сервер SQL
- База данных SQL
- Пользователь SQL
- Пароль пользователя SQL
Проверялось на 1С:ERP Управление предприятием 2 (2.4.7.141) платформе 1С:Предприятие 8.3 (8.3.13.1690). Подходит для всех типовых конфигураций 1С, содержащих справочник Идентификаторов объектов метаданных (УТ, ЗУП, БП, УНФ и т.д.).
- Отчет подключается как дополнительный к базе данных либо открывается через меню Файл-Открыть.
- Отчет полностью универсален для всех типовых конфигураций 1С на базе Библиотеки стандартных подсистем.
- Используется система компоновки данных, со всеми возможностями: Произвольной настройки вида отчета, Сохранение различных вариантов отчета, Сохранение параметров подключений к разным базам.

По типам объектов 1С формируется отчет, в нём указаны:
- Совокупности таблиц SQL для хранения объекта 1С и их предназначение;
- Число объектов данного типа;
- Размеры хранения данных и индексов в MB (мегабайтах).
Рис 1. Свёрнутый вид отчета

Рис. Справочник

Рис. Документ

Рис. Регистр накопления

Рис. Регистр бухгалтерии

Рис. Диаграммы (все документы, список документов)




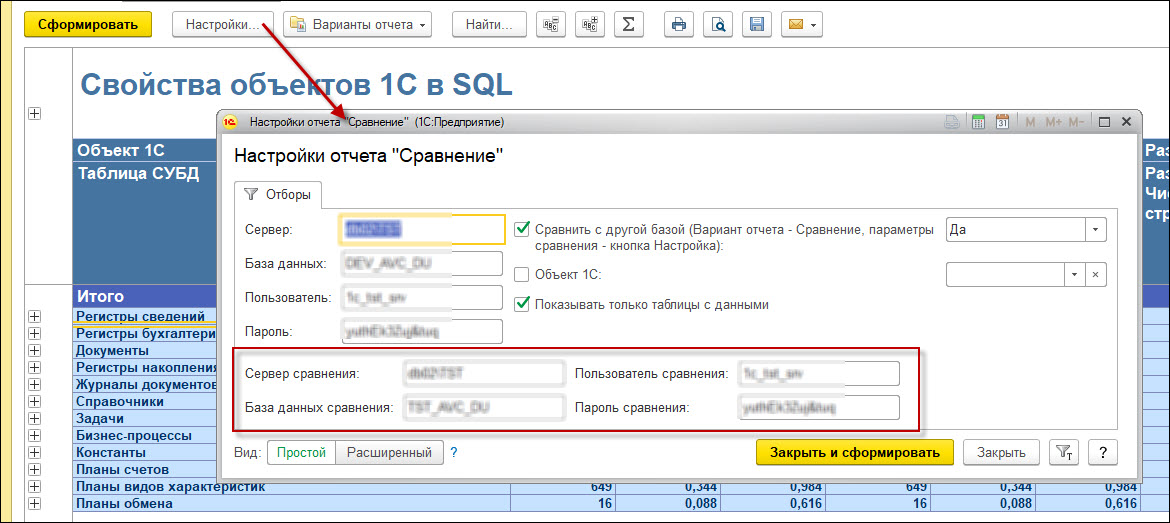
Рис.2 Вариант отчета со сравнением данных двух баз между собой (дополнительно указываем параметры второй базы)

Внимание:
- В небольшой части продуктов 1С при открытии отчета через Главное меню - Файл - Открыть в отчете некорректно подключается общая форма из конфигурации и в результате появляется ошибка вида: "Не установлена схема компоновки данных"
Решение: Для её обхода подключите отчет в разделе НСИ и администрирование - Дополнительные отчеты.

- В некоторых была проблема, что СУБД съедал префикс dboи поэтому не устанавливается связь по равенству ТабСУБД.name = ""[dbo].[_"" + Таб1С.ИмяТаблицыХранения + ""]"", но работал вариант решения добавлен ТабСУБД.name = ""_"" + Таб1С.ИмяТаблицыХранения.Решение: В версиях отчетов для скачивания от 13.05.2020 эти варианты совмещены.
- Если у кого-то возникнет проблема вида "Время ожидания запроса истекло". Тогда о ткройте отчет в конфигураторе 1С, откройте модуль объекта и добавьте строки
Функция ДанныеСУБД(ПараметрыСУБД) Connection = Новый COMОбъект("ADODB.Connection"); RecordSet = Новый COMОбъект("ADODB.RecordSet"); Connection.ConnectionTimeout = 100;//По умолчанию 15; Connection.CommandTimeout = 500;//По умолчанию 30; Попытка Connection.Open("Provider=SQLOLEDB.1;Persist Security Info=False;User ID inf-message-wrap seen" data-id="10135817">
в указанной процедуре, добавьте код увеличения интервала- С расширениями появился следующий момент, стали в SQL появляться таблицы с постфиксом X1, например:
Таблица обычного регистра сведений базы данных [dbo].[_InfoRg80251]
Таблица регистра сведений добавленного в расширении [dbo].[_InfoRg80607X1]

Типовой метод ПолучитьСтруктуруХраненияБазыДанных() использующийся показывал имена таблиц без постфикса X1, поэтому они не отображались в отчете. Поправил данный момент в версиях отчетов от 23.07.2020
Обработка выгрузки и загрузки данных через XML между идентичными конфигурациями с возможностью установки произвольных отборов на выгружаемые объекты.
Подключаемый отчет на системе компоновки данных по типам объектов 1С показывает: 1) Совокупности таблиц SQL для хранения объекта 1С и их предназначение; 2) Число объектов данного типа; 3) Размеры хранения данных и индексов в MB (мегабайтах); 4) Сравнение данных двух баз
Предназначается для запуска сеанса другого пользователя из своего сеанса 1С (если пароль вам неизвестен).
Если пользователю не хватает прав на объект, то на практике в 90 % случаев, недостающую роль можно найти через типовой регистр сведений Права ролей. Также с помощью дополнительного отчета или небольшого расширения можно ускорить описанный процесс.
Онлайн диаграмма доступных лицензий 1С и показателей ресурсов сервера 1С в различных измерениях и отборах.
Обработка ищет все объекты базы, в которых одновременно присутствуют перечисленные элементы. Построена на базе типовой обработки Все функции - Стандартные - Поиск ссылок на объект, но позволяет накладывать отбор не по одному объекту, а по нескольким, что позволяет настраивать поиск по комбинациям условий
Часто не хватает визуализации хронологии документов в структуре подчиненности и кнопок проведения. Это расширение конфигурации, с функционалом структуры подчиненности документов, отображающее хронологическую последовательность документов во времени и дающее доступ к проведению, отмене проведения, пометке на удаление документов непосредственно в форме подчиненности.
Обработка для массовой проверки доработок конфигурации: Открытие форм, Печать, Формирование отчетов, Проведение документов, Запись справочников, ПВХ, ПВР. Выдает список обнаруженных ошибок. Рекомендуется применять для тестирования обновленной конфигурации, перед установкой пользователям. В коде используются универсальные методы поэтому подходит для большинства конфигураций, построенных на базе библиотеки стандартных подсистем.
Групповая обработка ссылок вида Объект не найден (502:37855254002e11eb11e73b8f36150d9e) заполняется максимально просто копированием и вставкой из буфера: 1) Выделяет уникальные идентификаторы (далее УИ); 2) Ищет ссылки на объекты базы по УИ; 3) Создаёт пустые объекты с указанным УИ; 4) Регистрирует найденные ссылки для обмена данными. Работает на любых продуктах 8.3
Обработка на управляемых формах для работы с календарями google, событиями календарей и контактами.
Обработка проверяет наличие и решает проблему с ошибкой развернутого сальдо в Оборотно-сальдовой ведомости (регистр бухгалтерии Хозрасчетный) из-за ошибки Универсального редактора реквизитов или кода программиста, устанавливающего пустые ссылки в значениях Валюты, Подразделения, Направления деятельности не равными NULL. И пересчёт итогов тут точно не поможет.
Выполнил 3 разных теста для проверки серверного оборудования (тест 1С, тесты gilev) на возможное число 1С онлайн-пользователей одновременно работающих на нем и интерпретировал результаты тестов через легких, средних и тяжелых пользователей с помощью таблицы с профилями реальных пользователей.
Перед началом проекта требуется определить параметры серверного и клиентского оборудования, необходимые для работы внедряемой программы 1С:Предприятие, и учесть будущую нагрузку, которая ляжет на систему в реальной рабочей обстановке. Мощность оборудования должна быть достаточной для нормальной работы пользователей. Но как подобрать сервер простым способом?
На время сеанса отключаем контроль остатков и проверку документов в ERP, КА, УТ типовыми средствами и простым расширением.
Часто при моделировании примеров бизнес-процессов, на запуске в эксплуатацию или закрытии требуется несколько раз прогнать ситуацию с разными настройками, а для этого изменить, удалить ранее введенную цепочку документов. Дается все это с трудом. Ты уверен, что не навредишь своими действиями системе, но документы цепляют друг друга и ругаются контролями остатков, не разрешая тебе менять их в произвольном порядке.
Есть несколько удобных опций для облегчения внесения изменений.
Для уведомления пользователей программных продуктов 1С о разных событиях, в них включена подсистема «Новостной центр». Это довольно удобная штука, т.к. новостные ленты сообщают о выходе обновлений, о новостях и событиях в сфере учёта. Но можно увеличить пользу от новостной подсистемы используя её локально в рамках 1С базы. Например, внутренняя служба техподдержки или внедряющая компания может через новостную ленту оповещать пользователей информационной базы об изменениях в программе, совещаниях, проведении тестирований, заполнения нужных документов или сдача отчетов к определенной дате и т.п.
Пример технического задания для практического понимания основных разделов.
Кратко описаны основополагающие моменты при старте групповой разработки конфигурации несколькими программистами. Полезно для проектной документации как требование к разработчикам или сопровождающей компании
Ссылка на компетенции по 1С:ERP - команда со знаниями, умениями и успешными проектами.
В одной из компаний где я когда-то работал, имелась собственная разработка на 1С 8.2 платформе.
Однажды мы пришли к понимаю что наша система работает не очень быстро. Оставалось понять в каком направлении двигаться, что бы оптимизировать работу системы. После долгих исследований и экспериментов, мы решили в серьез взяться за перенос некоторых операций на плечи СУБД, а именно на плечи MS SQL с помощью выполнения прямых запросов на стороне SQL Server, в обход сервера приложений 1С.
Тот случай был единственным где подобное решение было рациональным. Но те навыки что я получил в тот момент, с легкостью можно использовать для интеграций системы 1С с другими информационными системами.
Cтруктура базы данных 1С на уровне СУБД выглядит не совсем внятно.
Постараюсь описать что же из себя представляет эта структура. Описание будет не полное. Постараюсь описать лишь самое интересное и важное, из того что нужно понимать спускаясь на уровень СУБД.
Рассматриваем структуру хранения данных.
Каждый объект метаданных имеет определенный вид наименования таблиц. Например РегистрСведений начинается с "_InfoRg. ", далее идет номер (идентификатор/индекс) регистра. А вот таблички начинающиеся с _InfoRgChng это таблицы содержащие в себе регистрацию изменений в регистре. Перечислять в данной статье все префиксы я не буду. Это можно сделать с помощью средсв 1С. По мере необходимости.
Ещё интереснее у нас хранятся данные составных полей. Точнее те поля, которые могут примнимать разнотипные значения.
Допустим у нас есть поле. И оно может хранить в себе Строку, Дату, Число, ссылку на справочник клиентов, и ссылку на справочник сотрудников. В 1С мы видим одно единственное поле. На деле же такое поле в базе данных будет иметь ряд полей. Давайте рассмотрим этот пример. Предположим что индекс нашего поля - 8818.
| Наименование поля | Описание |
| _Fld8818_TYPE(binary(1)) | В данном поле хранится тип значения, который хранится в текущей записи. Тип представляет из себя индекс. Целое число. |
| _Fld8818_N(Numeric(x)) | Здесь будет храниться значение числа. Тип числа (разрядность и длинна равная x) будет зависеть от настроек в самом конфигураторе 1С |
| _Fld8818_T(datetime) | В данном поле будет храниться значение типа Дата и Время |
| _Fld8818_S(nvarchar(1024)) | В этом поле значение в виде строки. Причем длина строки зависит от настроек. |
| _Fld8818_RTRef(binary(4)) | В данном поле, при условии что в записи хранится ссылка, будет указан тип ссылки. То есть, на какую таблицу ссылается ссылка, справочник это или документ, что за документ или справочник. |
| _Fld8818_RRRef(binary(16)) | А это уже будет сама ссылка на конкретную запись, в конкретной таблице |
Если с простыми типами данных все ясно, то тип ссылки не так прост.
Наверняка вы зададите вопрос: Как можно определить тип ссылки? То есть, что означает индекс хранящийся в поле _Fld8818_RTRef?
Если мы переведем этот индекс из шестнадцатеричной системы счисления в десятичную, и затем посмотрим на список таблиц базы данных, то обязательно найдем таблицу, в имени которой содержится данный индекс. То есть мы можем по этому индексу получить таблицу, в которой содержится элемент, на который ссылается ссылка в нашем поле.
Зная индекс, мы можем найти необходимую таблицу простым запросом:
Где 1950 — искомый индекс.
Получаем структуру хранения средствами платформы 1С.
Остается вопрос, как нам определить, как некоторая таблица в конфигурации 1С, именуется на уровне СУБД, а так же, соответствие полей на уровне СУБД и конфигурации?
В этом нам поможет встроенная функция поставляемая вместе с платформой:
Данная функция возвращает структуру в которой мы можем по имени объекта в МетаДанных, получить имя объекта в базе данных. Точно так же в структуре содержаться и все поля объектов, и их наименования в базе данных. Но здесь уже начинаются подводные грабли. Которых вроде как и нет, и в тоже время они есть.
Важный момент. При вызове метода, обязательно нужно передать во второй параметр значение «Истина». Что это означает? Этот параметр означает будет ли структура отображать данные в формате 1С: Предприятие, либо в формате СУБД. В чем же разница?
Допустим мы отображаем данные в формате 1С: Предприятие.
Например, если мы попытаемся с помощью этой структуры узнать как называется в базе данных поле «Клиент», то получим к примеру такое имя «Fld1234». Вроде бы все хорошо. Но если мы попытаемся написать запрос к MS SQL:
Мы в 80% случаев — получим ошибку. Почему? А потому что это лишь общий вид наименования поля. Но стоит знать о том что во первых любое имя поля начинается с нижнего подчеркивания. Казалось бы прибавим к наименованию поля символ "_" и делов то! Но нет. Далее ещё интересней. В зависимости от содержимого поля и его типа, поле имеет определенный постфикс в наименовании. Например RRef — это значит что в поле содержится ссылка. А если просто значение то этого постфикса нет. А помните составные типы данных? Там вообще может быть куча различных постфиксов, при этом полей начинающихся на "_Fld1234" будет гораздо больше чем одно. И как же нам обойти это?
Легко. Те кто знает MS SQL, сразу догадались что на помощь придет системное представление INFORMATION_SCHEMA.COLUMNS
С помощью этого представления мы можем отобрать информацию по наименованию таблицы, и по тому ключевому наименованию поля.
Пример запроса:
Данный запрос выдаст нам ряд полей, имена которых начинаются на "_Fld1234". Нам же останется эти данные обработать в нашей программе для использования в запросах к базе.
Но какие минусы у этого метода? Во первых для того что бы обратиться к базе, нам необходимо настроенное подключение к БД, через 1С. То есть дополнительные настройки. Но они нам в любом случае пригодятся, но представьте, у вас большой запрос. Нужно получить имена 20 полей. И каждый раз при этом обращаться к базе и искать там имена полей? Получать и использовать подключение? Это не очень оптимально. Плюс к тому полученные из базы данные, придется ещё как-то обрабатывать. Дополнительные действия. Да и словом - изобретение велосипеда.
Вот тут то нам и приходит на помощь функция
Когда значение параметра ИменаБазыДанных = Истина, то функция в результирующую структуру сразу передает всю необходимую информацию по объектам. Включая все физические поля Базы данных. Если поле составное, то в структуре будут видны все физические поля составного поля. Это значительно облегчает нашу работу.
Использование прямых запросов. Отборы. Соединения и обращения через точку.
Как же нам использовать отбор в прямых запросах? Как отобрать данные по конкретному документу? Или по конкретному значению?
Все довольно просто, но снова есть нюансы.
Поля формата Дата. По умолчанию при использовании MS SQL сервера, дата 1С в базу помещается с прибавлением к году 2000. То есть дата в системе 1С «01.01.2013» будет выглядеть как «01.01.4013». Но и это ещё не все. Для того что бы в запросе произвести сравнение даты и оно прошло корректно, нам необходимо дату конвертировать в определенный формат.
По умолчанию в базе данных MSSQL используется формат ymd. Это означает что в дате сперва указан год, месяц и затем число. А выглядит дата следующим образом: 4013-01-01. Для использования в условиях сравнения или для прочих манипуляций нам эту дату нужно обрамлять в опострофы, так же как и строки.
Для преобразования даты в формат SQL я написал для себя такую простенькую функцию:
Данная функция возвращает готовую дату, в нужном формате в виде строки, остается только подставить в текст запроса. Если у вас в MS SQL по каким то причинам установлен иной формат даты, можно на момент исполнения запроса его поменять. Делается это так:
Либо надо будет переделать представление даты в своем запросе.
Теперь нам нужно отобрать записи по определенному элементу справочника. Как это сделать?
Изначально, когда я не знал о существовании функции ЗначениеВСтрокуВнутр(), для своих нужно я написал пару функций, для получения ссылок на справочники и на документы. Выглядят они так:
Как видно в коде, мы строим простой запрос, и получаем из базы значение ID, которое храниться в базе данных. Объект — это у нас наименование справочника либо документа, а код — код элемента справочника или документа.
Функция master.dbo.fn_varbintohexstr() — позволяет преобразовать значение формата binary в строку.
Но использовать эту функцию — не обазательно.
Полученный ID имеет примерно такой вид: 0xa8ed00221591466911e17da9fd549878
В запросе мы его можем сравнивать как строку
Но в таком случае запрос будет отрабатывать дольше. Так как на преобразование в строку тоже нужно время.
Поэтому лучше сравнение делать таким образом:
Предыдущий вариант использовать можно, но на самом деле, имеется более универсальный и оптимальный способ получить ссылку. Он приведен в функции что показана ниже:
А давайте представим что нам нужно в запросе сделать внутреннее соединение. И сравнение должно происходить с полем через точку?
То есть, для сравнения нам необходимо проверять одно условие, что дата в основной таблице, равна дате, которая содержится в документе, ссылка на который содержится в присоединяемой таблице.
В 1С это будет выглядеть примерно так
Как же описать это с помощью MS SQL? В том месте запроса, где описываются соединения, компилятор запросов ещё не знает о том что в таблице регистра есть ссылка на регистратор, и что это в свою очередь есть документ, а у этого документа есть дата. Описать ещё одно соединение? Не поможет. Словом я пытался это сделать всяко. Но в итоге решение свелось к вложенному запросу. (если кто-то найдет реальную альтернативу, буду рад узнать ваш способ).
Выше приведенный фрагмент на чистом SQL будет выглядить так:
В запросе мы видим, что во вложенном запросе делаем выборку из таблицы документа, где ID документа равен ID который записан в поле нашей таблицы «Источник», и далее полученное значение _Date_Time сравниваем с датой из нашей таблицы. Все логично и просто. Думаю теперь мы понимаем, во что превращаются наши обращения к полям и объектам через точку, в запросах 1С, когда они транслируются на SQL запрос. И теперь становится понятно почему такие обращения затормаживают работу запросов.
Очень рекомендую вам поэксперементировать с различными запросами, используя инструмент SQL Server Profiler. С его помощью вы сможете увидеть, во что превращаются ваши запросы написанные на языке запросов 1С, пройдя трансляцию на сервере приложений 1С. Особенно интересно вам будет посмотреть что из себя представляют такие виртуальные таблицы как "СрезПоследних".
Тот пример который я описал выше, с внутренним соединеним, 1С сервер скорее всего реализует немного по другому. Но у него свои методы, с использованием переменных, значения которых заполняются серверов приложений перед выполнением запроса.
Ниже я приведу один пример.
Допустим у нас есть запрос в формате 1С:
Как мы видим, ситуация аналогичная, как я приводил выше, только соединение не внутреннее, а левое. Как же 1С Сервер приложений траслирует такой запрос?

С помощью SQL Server Profiler мы сможем это увидеть. На картинке выше, показан запрос сервера приложений. Как я и писал выше, мы видим что сервер приложений использует переменные, в которые заранее пишет соответствующие ID. Но нам при использовании прямых запросов, проще было использовать именно вложенный запрос, для нас это универсальное решение, так как не придется подставлять значения переменным.
Будет замечательно если вы самостоятельно изучите различные запросы в таком виде. Возможно это поможет вам оптимизировать ваши запросы.
Для решения каких задач нам могут понадобиться прямые запросы к базе данных?
Думаю данная возможность понадобиться при активной разработки своих собственных решений, либо при реструктуризации готовых решений. В тех случаях, когда в отладочных целях, либо ещё по каким-то причинам, нам придётся переносить большие объемы данных с одной таблицы в другую, либо разбивать данные на несколько таблиц.
Для интеграции 1С с другими, сторонними разработками. Например вывод данных из 1С в какую-нибудь стороннюю программу анализа продаж или что-то похожее.
Оптимизация массивных обработок данных. Когда нам необходимо обработать большое количество данных, при этом внося какие-то изменения, корректировки и т.п. Например копирование записей регистра сведений с изменением какого-либо поля средствами 1С, займет куда больше времени, чем выполнение операции T-SQL Update
Учимся получать доступ к СУБД из 1С.
Для работы с СУБД на прямую, в обход сервера приложений 1С, нам потребуется использовать COM объекты - ADO.
Первым делом нам понадобится строка подключения к базе данных. У нас даже есть возможность формировать эту строку через стандартный интерфейс Windows. Это значительно облегчает процесс подключения к БД.

Интерфейс настройки подключения к базе данных.
Давайте рассмотрим пример работы с ADO.
В данном фрагменте кода, мы создаем объект подключения к базе данных. А так же с помощью объекта DataLinks, получаем строку подключения к базе данных используя пользовательский интерфейс настройки этого самого подключения.
После того как мы получим строку подключения, нам скорее всего захочется отдельные её части разместить на форме, для того что бы пользователь мог исправлять отдельно взятые опции подключения. Следовательно строку необходимо распарсить. Я пока (на момент написания статьи) нашел лишь один способ это сделать, и привожу его ниже. Если кто-то подскажет более элегантный способ парсинга строк, будет здорово.
Теперь мы сохранили параметры подключения базы данных на форме, при желании можем их сохранить в базу данных.
Далее надо предусмотреть вариант, когда пользователь (чаще всего мы сами), изменит наименование базы данных или тайм аут прямо в форме обработки, минуя форму редактирования строки подключения. На такой случай создадим такую функцию, которая будет формировать строку подключения собирая данные из визуальных контролов формы. Выглядит она примерно так:
После выполнения данной функции нам станет ясно, можно ли работать дальше, или соединение с базой установить не удалось, и следовательно дальше что-либо делать с подключением — бесполезно. Кстати, для оптимизации функцию получения объекта ADODB.Connection можно разместить в общем модуле, в настройках которого выставлено «Повторное использование». Это позволит не создавать каждый раз новый объект подключения, а будет использоваться уже созданный объект. В теории это позволит сократить время вызова соединения, а так же совсем чуть-чуть сэкономит ресурсы системы.
Причем заметьте, что свойству ActiveConnection мы присваиваем ранее созданное подключение к базе. Теперь когда объект у нас создан, нам остается лишь воспользоваться им. Если нам необходимо просто выполнить запрос, который не вернет никаких результатов, то будет достаточно одной простой команды, которая показана ниже.
Типы данных MySQL
Типы данных MySQL разделяются на следующие типы:
Типы данных Oracle
Типы данных Oracle разделяются на следующие группы:
ANSI SQL стандарт распознает только текст и число, в то время как большинство коммерческих программ используют другие специальные типы, такие как DATЕ и TIME — фактически почти стандартные типы. Некоторые пакеты также поддерживают такие типы, как, например, MONEY и BINARY. Типы данных, распознаваемые с помощью ANSI, состоят из строк символов и различных типов чисел, которые могут классифицироваться как точные числа и приблизительные числа.
CHARACTER(length) определяет спецификацию строк символов, где length задает длину строк заданного типа. Значения этого типа должны быть заключены в одиночные кавычки. Большинство реализаций поддерживают строки переменной длины для типов данных VARCHAR и LONG VARCHAR (или просто LONG).
В то время, как поле типа CHAR всегда может распределить память для максимального числа символов, которое может сохраняться в поле, поле VARCHAR при любом количестве символов может распределить только определенное количество памяти, чтобы сохранить фактическое содержание поля, хотя SQL может установить некоторое дополнительное пространство памяти, чтобы следить за текущей длиной поля. Поле VARCHAR может быть любой длины, включая реализационно-определяемый максимум. Этот максимум может меняться от 254 до 2048 символов для VARCHAR и до 16000 символов для LONG. LONG обычно используется для текста пояснительного характера или для данных, которые не могут легко сжиматься в простые значения полей; VARCHAR может использоваться для любой текстовой строки, чья длина может меняться.
Извлечение и модифицирование полей VARCHAR — более сложный, и, следовательно, более медленный процесс, чем извлечение и модифицирование полей CHAR. Кроме того, некоторое количество памяти VARCHAR, остается всегда неиспользованной для гарантии вмещения всей длины строки. При использовании таких типов следует предусматривать возможность полей к объединению с другими полями.
Точные числовые типы — это числа, с десятичной точкой или без десятичной точки, которые могут представляться в виде [+|-]<целое без знака>[.<целое без знака>] и специфицироваться как:
DECIMAL(precision [, scale]) — аргумент размера имеет две части: точность и масштаб. Масштаб не может превышать точность. Точность указывает сколько значащих цифр имеет число. Масштаб указывает максимальное число цифр справа от десятичной точки. Масштаб = нулю делает поле эквивалентом целого числа.
NUMERIC(precision [, scale]) — такое же как DECIMAL за исключением того, что максимальное десятичное не может превышать аргумента точности
INTEGER — число без десятичной точки. Эквивалентно DECIMAL, но без цифр справа от десятичной точки, т.е. с масштабом равным 0. Аргумент размера не используется (он автоматически устанавливается в реализационно-зависимое значение).
SMALLINT — такое же как INTEGER, за исключением того, что, в зависимости от реализации, размер по умолчанию может ( или не может ) быть меньше чем INTEGER.
Приблизительные числовые типы — это числа в показательной (экспоненциальной по основанию 10) записи, представляемые как <литеральное значение точного числа>Е<целое со знаком> и специфицирущиеся следующим образом:
FLOAT[(precision)] — число с плавающей запятой. Аргумент размера состоит из одного числа, определяющего минимальную точность.
REAL — такое же как FLOAT, за исключением того, что никакого аргумента размера не используется. Точность устанавливается реализационно-зависимой по умолчанию.
DOUBLE PRECISION — такое же как REAL, за исключением того, что реализационно-определяемая точность для DOUBLE PRECISION должна превышать реализационно-определяемую точность REAL.
Типы данных Access
Типы данных Access разделяются на следующие группы:
Типы данных SQL Server
Microsoft SQL Server поддерживает большинство типов данных SQL 2003. Также SQL Server поддерживает дополнительные типы данных, используемые для однозначной идентификации строк данных в таблице и на многих серверах, например UNIQUEIDENTIFIER , что соответствует аппаратной философии «роста в ширину», исповедуемой Microsoft (т. е. внедрение базы на множестве серверов на платформах Intel), вместо «роста в высоту» (т. е. внедрение на одном огромном мощном UNIX-сервере или Windows Data Center Server).
Типы данных, используемые в SQL Server:
Типы данных PostgreSQL
База данных PostgreSQL поддерживает большинство типов данных SQL2003 плюс огромный набор типов для хранения пространственных и геометрических данных. PostgreSQL может похвастаться богатым набором операторов и функций, специально предназначенных для геометрических типов данных. Сюда входят такие средства, как поворот, поиск пересечений и масштабирование. В PostgreSQL также есть поддержка дополнительных версий существующих типов данных, которые характерны тем, что занимают меньше места на диске, чем соответствующие исходные версии. Например, в PostgreSQL предлагается несколько вариантов типа INTEGER для хранения больших и небольших чисел, соответственно занимающих больше или меньше места.
Читайте также: