
Как по голосу найти человека приложение
Если вам нужно открыть вклад, получить кредит или перевести деньги, необязательно идти в банк. Можно сделать это дистанционно, пройдя удаленную идентификацию с помощью биометрических данных.
С 2019 года биометрическая идентификация по голосу станет обязательной для всех банков. Ожидается, что, сдав биометрию, клиенты смогут обслуживаться удаленно. Вместо визита в банк можно будет просто поднести смартфон к лицу и произнести кодовое слово. Проект DATA4 задумывался как раз, когда в отрасли обсуждалось это решение. Основатели увидели большую перспективу этой технологии на рынке. Например, по данным Ростелекома, для банков прием клиента в онлайн на 60% дешевле, чем в отделении.
При этом не только банки могут воспользоваться технологией. Определить, кто звонил в колцентр или заходил в ваш магазин можно по голосу и видео, даже если человек не представился. О том, как разработчики внедряют искусственный интеллект для бизнеса, рассказал основатель компании DATA4 Кирилл Косолапов.
Предположим, вы звоните в контактный центр банка, чтобы подтвердить операцию по счетам. Вас просят назвать парольное слово, но вы его забываете, ошибаетесь. Возникает заминка. По статистике таких случаев – около 40%. Но если в телефонии организации применяется специальный софт, вам уже не обязательно называть пароль – программа легкого опознает вас, как клиента банка. По вашему уникальному голосу. И обмануть машину практически нереально: точность определения личности – 97%.
Конечно, как личность машина сможет определить вас, если вы заранее дали на это согласие и оставили тестовую запись голоса. Это один из новых продуктов, который мы сейчас запускаем, он называется Robin, биометрическая идентификация человека по голосу.
Вторая инновация – распознавание по лицу. С помощью камеры видеонаблюдения наша программа может с определенной точностью найти профиль человека, попавшего в кадр, в социальных сетях. Эта информация используется для рекламного ретаргентинга. К примеру, вы зашли в автосалон, посмотрели машины и ушли. Ситуация обычная. Для принятия решения о покупке нужно время. Чтобы удержать ваш интерес, автосалон может направлять в ваш адрес дополнительную информацию. Таким образом решается задача возврата клиента, который просто зашел в салон.
Тесты показывают: когда качество изображения хорошее – лицо смотрит прямо в камеру, то вероятность определения личности по соцсетям порядка 60% (вхождение в топ-3 найденных аккаунтов).
Для определения личности по лицу мы используем облачный софт, по голосу – инхаус-решения внутри офиса.
В целом мы занимаемся машинным обучением. Развиваем так называемый «слабый» искусственный интеллект – IT-инструменты для бизнеса. Это и разработки по видеоаналитике, и интеллектуальная компьютерная обработка изображений и текстов. Проект идентификации по голосу мы запустили чуть больше года назад, и сейчас пилотируем с несколькими банками. По видео только начали тестирование с одним автодилером.
Я закончил Магнитогорский Государственный Технический Университет по специальности приборостроения. Потом поступил в магистратуру на мехатронику и робототехнику. Меня всегда интересовали IT технологии, особенно в сфере обработки речи, языков программирования, машинного обучения. Наверно, я в большей степени практик, поэтому после окончания университета захотелось попробовать себя в реальном бизнесе. Так и решил освоить собственный проект.
Сложности вызывает длинный цикл продаж. Особенно с голосом. Рынок не полностью готов к подобным продуктам. Есть 152 ФЗ – о защите персональных данных, который накладывает сильные ограничения обработку и использование полученной информации. Нам пришлось пойти на ухищрения, чтобы узаконить применение продукта.
Например, по закону нужно обрабатывать все данные на территории России – мы выполняем это требование. Еще человек доложен давать свое письменное согласие. В случае с голосом так оно и есть. Но в случае с лицами мы не вторгаемся в закрытую информацию. Мы находим данные только из доступных источников общего пользования – соцсетей. И в случае с ретаргетингом мы даем заказчику не четкое сопоставление «личность–лицо», а формируем пул похожих людей на их потенциального клиента, который прошел перед камерами.
Конечно, перед запуском рекламы мы стараемся максимально точно определить целевую аудиторию и отфильтровать случайные профили. При этом реклама не несет персональных обращений, вроде, «вы посещали такой-то салон». Это просто информация о предложениях на рынке, которая может быть интересна адресатам.
К примеру, человек был в автосалоне и смотрел на Ауди, а через какое-то время в интернете может увидеть окно со сравнением Ауди и Мерседеса. Или ссылку на статью про Ауди. Но «в личку» ему никто не пишет и в салон напрямую не зазывает. Это обычный подогревающий контент.
Конкуренция
По голосу на российском рынке у нас есть лишь пара конкурентов. По идентификации по лицам – значительно больше. Но по ретаргетингу ниша еще не занята. Сейчас здесь работает пара команд, пока с минимальными оборотами. У нас есть хороший шанс отграничиться от конкурентов и занять свое место в этой нише.
Монетизация
Как компания мы зарабатываем на разных разовых заказах, но на новых продуктах пока получаем не много. Суммы – «пилотные». Когда закончатся все «пилоты», надеюсь, монетизация будет хорошая. Сейчас прогнозировать тяжело.
Продвижение
Здесь у нас хорошо работает контент-маркетинг – дает до 70% обращений. Делаем ссылки на тематические статьи о новых технологиях. Не все клиенты знают об этих разработках и готовы применять в бизнесе. Им нужно получить больше информации, созреть.
Кстати, опыт показал: хорошо наладить коммуникации с клиентами помогают и различные акселераторы, конференции, выступления. Например, в акселераторе Российской венчурной компании GenerationS мы наладили контакты с полусотней различных компаний, со многими взаимодействуем по ряду проектов. Также мы выиграли грант от партнеров акселератора на сумму 2 миллиона рублей для проведения НИОКР.
Перспективы
Глобальный рынок биометрии по речи составляет примерно 1,2 млрд долларов. Российский рынок можем смело делить на 60. Итого – около 20 млн долл. Если говорить по биометрии лица, то глобальный рынок – 3,5-6 млрд долл. Российский – порядка 70 млн долл. Рынок рекламы огромен, и какая часть будет задействована под инструмент биометрии, экспертам пока сказать сложно. Но по нашим оценкам здесь можно достичь суммы в 1 млрд рублей. И в наших планах занять доминирующее положение на этом рынке.
Вы тоже можете рассказать о своём проекте, как автор этого материала. Соберите побольше информации — и публикуйте материал в подсайте «Трибуна».Никто в здравом уме в РФ не будет сдавать никуда свои биометрические данные. И пусть банки идут лесом.
1) Приведенные проценты совсем условны и в маркетинге их нельзя учитывать, т.к. рынок не сформирован от слова совсем. То что сегодня 40% может поменяться уже с первым пользовательским опытом. Также пользовательский опыт имеет две плоскости как ваши клиенты, так и клиенты ваших клиентов. Что в свою очередь заставляет измерять обе отдельно "глазами разных групп" и вы удивитесь как эти показатели будут разняться. Потому эти цифры пока только утешить самого себя и фанатично верить в проект
2) Монетизация этого проекта у вас сразу не решена - это глобальная проблема. Надо было такое для кого то уже делать и иметь большую фокус группу и бета тесторов, которые готовы платить за результат.
3) Легко сдуться в вашем случае как деньги закончатся т.к. тут голубого океана нет когда технический вы ничего не придумали, а на стартовой позиции уже китайские проекты, Израиль (два стартапа там - названия не помню) и США (только один видел). интересно как скоро лошадка первым наша придет?
4) Можно дать вам совет чтобы сначала успокоились и немного осознали сможете ли реализовать , т.к. вы больше походи на тех кто получает удовольствие от самого процесса, чем правильно копающего (личное мнение что сложилось от статьи).

Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется нормализация. Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.

Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации.
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.

Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга.
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье

Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье.
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок.
Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью.
m — частота в мелах
f — частота в герцах
Получение вектора признаков

Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2]
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?

Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов.
Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
- Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
- Находим для каждого из них характеристический вектор признаков.
- Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
- В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
- Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.

Как с помощью голоса можно найти вторую половинку! Приложение, в котором нет ботов и мошенников. Здесь можно петь песни и читать стихотворения, набраться вдохновения у других людей.
Знакомится с людьми голосом? Вас удивило? Вот меня удивило и я решил узнать, что это за место такое..
Обычно сейчас на сайте знакомств сидят одни извращенцы, а по поводу женского пола - большинство ботом или мошенников.
Нашел я приложение случайно в какой-то рекламе. Мне нравятся красивые и необычные голоса - сразу понял - это моё место. И навряд ли там будут сидеть под женскими аккаунтами мужики, ведь надо общаться голосовыми)
Вот так выглядит мой профиль в этом приложении:

Где мы сразу видим, что можно поставить себе фотографию (На наличие верификации проверки нет, но я думаю в скором времени введут). Также здесь можно указать ссылки на свои другие соц.сети.
По мимо поиска знакомств (о которых я ниже расскажу), здесь можно вести свою стену со своими воксами (голосовыми). Эти воксы, видят все ваши подписчики и любые другие пользователи в ленте.
Так выглядит окно записи вашего голосового, когда вы хотите записать на своей странице:

Тут вы можете написать название, хэштег вставить. Также есть определенное количество звуков, которые представлен в виде смайликов. Они будут звучать в вашем голосовом.
Изначально вокс можно записать максимум 60 секунд. Но такое ограничение можно расширить:

В графе "Уровни", мы можем увидеть нашу статистику. На данный момент на ограничение голосовых влияют только лайков.
Что по знакомствам здесь?

За всё время мне не попадались извращенцы, возможно потому что я мальчик и искал девушек)
Но если вы слушаете и там происходит какое-то нарушение, то вы можете пожаловаться.

Офигенно, что тут можно ускорить голосовое x1.5 и x2. Думаю многие пользуются этим в других приложениях. Очень спасает, когда мало времени или когда хочешь быстрее прослушать медленное голосовое, где слово раз в 5 секунд говорят.
За всё время пребывания здесь, я услышал только две негативных вещей от девочек:
- Попрошайничество денег
- Предложение о заработке (в основном вступать в команду по сетевому маркетингу)
Мой совет: Запишите интересное голосовое и с бодрым голосом. Мало кому интересно слушать сколько лет и где вы живете и дальше ничего, а еще и с тихим унылом грустным голосом. Это я как парень говорю свое мнение).
Очень много разнообразных девочек, кто-то может шутку сказать или спеть, голоса в основном у всех приятные.
Всего можно свайпнуть "нравится" 50 анкет, а потом придется ждать 12 часов. И после снова есть возможность выбрать 50 анкет, которые понравятся.
А если хотите больше, то покупайте ПРЕМИУМ версию:

"Таймер на начало разговора". По умолчанию, если у тебя взаимная симпатия есть, то дается 24 часа на начало диалога, если не успеешь - не сможешь написать человеку.
Мне она не понадобилась, очень много кто ответил симпатией. Сейчас я скажу как я добился такого)
Перед тем как искать тот самый голос, который тебе понравится, нужно и у себя сделать настройки.

2. Выбрать свой возраст. Многие ставят разные возраста тут, многие маленькие девочки ставят себе 18+, потому что хотят пообщаться с мальчиками от 18. Вы можете и не свой возраст поставить, просто предугадайте какой возраст ставит противоположный возраст и поставьте его. Он нигде не виден, кроме как в этих настройках.
3. Возраст участников. Как вы видите из скриншота я поставил довольно большой диапозон. Изначально ставил вообще от 14, думал что никто не будет лайкать, а так хоть с кем-то пообщаюсь и вообще пойму как что работает. Но после очень много мне приходило голосовых от детей и подростков. Хоть я и сам еще не сильно взрослый, но мне интересно общаться от 18 лет.
А почему я поставил до 48 лет?Всё просто, чтобы больше было разнообразных девушек и больше вероятность что мне ответят взаимностью. И это сработало, правда старше 27 мне не попадались, ну тут понятно, так как я указал свой возраст 21.
4. Цель знакомства. Тут я не понял как работают алгоритмы, но возможно ищут тех кто указал категорию)
5. Согласие на вирт.

Да, здесь есть вирт. И я его поставил)) В анкете, когда ты слушаешь случайное голосовое, то будет еще показан внизу в правом углу "Огонёк". Но уже по практике общения, все забывают про эту категорию. (Опять же говорю со стороны мужчины, но не знаю как обстоят дела у девушек).
Да, бывают попадаются девушки пошлые, но в основном все с юмором и это классно.
Тут нельзя отправлять фотографии, вообще никаких. Хотите обмениваться фотками и чем угодно - списывайтесь и идите в другое место. Здесь только ГОЛОС, ну и текст.
6. Поиск пола. Да, тут есть выбор) То есть даже есть место и людям, у которых нетрадиционная ориентация. Не могу ничего сказать, не пробовал. Но понятное дело, будет меньшее количество людей в знакомстве.
7. Геопозиция. Просто даёте доступ к местоположению и ищет людей сначала из вашего города. Но так как приложения не сильно популярное сейчас, то это будет актуально кто живет в Москве или в Питере. В приложении сейчас около 100 тыс скачиваний.
Есть ещё быстрые знакомства. Эта вещь была добавлена месяц назад, довольно интересная.

Подбор собеседника происходит очень быстро, за 10 секунд находит человека и происходит соединение.

Дальше вам будут даны 30 секунд, чтобы быстро познакомиться. Тут я заметил, что все активные и начинают очень быстро говорить или вкидывать шуточку, чтобы понравится друг другу и продолжить общение.

По истечению 30 секунд нужно оценить или отвергнуть собеседника. Если обе стороны выбрали симпатию, то у вас будет доступен диалог и вы можете уже полноценно общаться.

В приложении есть события, где вы можете увидеть кто на вас подписался, кому понравился ваш голос, кто ответил взаимностью(довольно важная вещь, ибо иногда забываешь и не можешь потом вспомнить кто там тебе ответил взаимностью) Еще здесь можно посмотреть кому ты поставил лайк, но что бы посмотреть профиль - покупай премиум.

Что еще интересного тут есть?
Выше я говорил про воксы на своей странице, они попадают в ленту. Так выглядит лента. Здесь находятся случайные голосовые. Вы можете их прослушать, прокомментировать, пролайкать и даже написать человеку случайному. Можно обновить вкладку и будут постоянно новые голосовые появляться. Так что если скучно и никто не отвечает взаимностью, то можно тут позависать.

Также можно подписаться на человека и слушать его воксы.

Даже можно смотреть воксы и читать комментарии(в виде голосовых),иногда забавляет слушать о чем там рассуждают люди.

НАВИГАЦИЯ. Тут находятся дополнительные штучки.

СООБЩЕСТВА. Тут можно послушать определенного человека или различных людей на определенную тематику.

Категорий здесь достаточно много, так что любой может найти себе что-то по интересам



Пообщавшись в этом месте я увидел очень много талантливых молодых ребят. Очень много людей как мальчиков, так и девочек кто красиво поёт, читает стихи. Не заметил здесь токсичности и оскорблений. Для творческих людей прикольное место, можете тут посидеть.

Меня изначально интересовало только общение на едине, поэтому редко сидел в группах. Но интересна мне тематика философии и инновационных технологий. Было приятно пообщаться.
Тут очень легко найти себе собеседника. Я еще не видел, где так много отзывчивых и приятных людей.
Здесь можно спеть песню, читать стихотворение и многое другое выбрав себе оппонента.


Я ими не пользовался, но как вы видите что здесь предлагают люди.
Было интересно, сделал себе анкету. Нужно было записать голосовое и краткое описание и вставить хэштеги.

Через пару дней было уже много заявок, в основном не ответил, ибо итак много у меня диалогов с девушками, я не успевал им отвечать, а тут еще и заявки.

Вот так выглядят диалоги

В принципе ничего необычного. Сверху показано количество взаимных пар в виде сердечко и количество пар. И справа иконки пользователей, которые последний раз ответили взаимностью: Синим цветом выделяются - если это произошло недавно (когда не прошло 24 часа), серым - когда прошло 24 часа и ты или собеседник не начал диалог. И только с премиум версией можно ответить в любой момент.
Поэтому я сразу, если мне высвечивалась взаимность или в событиях я увидел, что мне ответили взаимностью, я не ждал ответа девушки и сразу писал. А то зная себя, забывая, можно быстро проворонить человека)
А про забывания - тут очень больная тема. У меня было много диалогов, хоть и сижу я не много. но приходилось общаться с 20-30 в день. И все интересные, и все тут хотят общаться. Это и круто, здесь очень редко происходит игнор. Здесь люди как я уже понял сидят за ОБЩЕНИЕМ!
Так выглядят диалоги:
Можно общаться просто голосовыми

А можно в перемешку: как голосовыми, так и обычным текстом.

Мое впечатление об использовании этого приложения:
Скажу сразу это отзыв со стороны парня, я не могу давать вам гарантии, что тут могут сидеть извращенцы, как это бывает во всех приложениях по знакомств. Но тут по крайне мере нельзя фотки присылать, и никто вам не будет присылать "дикпики" и прочие части тела.
Приложение - уникальное в своём роде. Здесь общаются голосом и это завлекает людей сюда общаться. Здесь активные люди, которые будут с вами общаться. Я не заметил тут как такого игнора. Все девушки которые попадались мне были интересные и забавные. Тут можно пообщаться на совершенно любые темы. Я задавал разные вопросы, начинал диалоги на всё то угодно и почти все девушки поддерживали общение. А это круче чем говорить "Привет, как дела".
Да, я спрашивал у девушек как тут общение с мужским полом, и вот популярные ответы:
- Есть веселые ребята, с которыми можно пообщаться.
- Есть скучные, которые не могут поддержать тему.
- Есть парни, которые делают голос сексуальным и пытаются так соблазнить.
Но, пообщавшись, и то что у всех позитивные реакции на общение со мной, я понял, что очень много парней, которые скучные и общаются на банальные темы.
Это не только приложение для знакомства и встреч. Тут можно найти друзей по интересам. Очень много творческих людей, кто поёт и читает стихи. Кто рассуждает на разные темы. Я сам там записывал на общее обозрение разные стыдные голосовые - и не заметил негативной реакции, наоборот люди поддерживают и хотят пообщаться на эту тему.
А моя проблема здесь была в том, что очень много заводил диалогов, развивал разные интересные темы(я общался с девушками очень много и было реально интересно провести ночь общаясь просто голосовыми и всё это без перерыва), а потом пропадал, либо на следующий день из-за обилия общения я забывал часть диалога, которая происходила вчера. Так что не смотря на то, что это не приложение, которое скачивают миллионы, тут очень много людей сидят. У меня не было и минуты времени, с кем бы я не смог пообщаться.
Концепция программного обеспечения для распознавания голоса ни в коем случае не является новой технологией. Вы уже познакомились с ним через Microsoft Cortana, Amazon Alexa и Siri. Это виртуальный ИИ, который позволяет вам использовать голосовые команды для управления вашим компьютером и мобильными телефонами. Но сегодня мы рассмотрим не только основные голосовые команды. Потому что с современными технологиями вы можете делать гораздо больше с помощью голоса. Я говорю о преобразовании аудио в текст.
Раньше было довольно сложно реализовать концепцию голоса в текст из-за большого разрыва, существовавшего между тем, что вы диктовали, и выводом текста. Это означало, что после редактирования документов приходилось тратить долгие часы. Но новые технологии привели к более точному диктату. Мы перечислим 5 лучших программ для распознавания голоса, которые будут для вас неоценимы.
Многие люди хвалят Dragon как программу распознавания речи номер один, и мне придется согласиться с ними по очевидным причинам. Он удивительно точен с первого дня использования и становится еще более точным, когда вы продолжаете его использовать, благодаря технологии глубокого обучения. Это функция, которая позволяет ему адаптироваться к вашему голосу, чем дольше вы его используете, и будет особенно полезна, если у вас иностранный акцент.
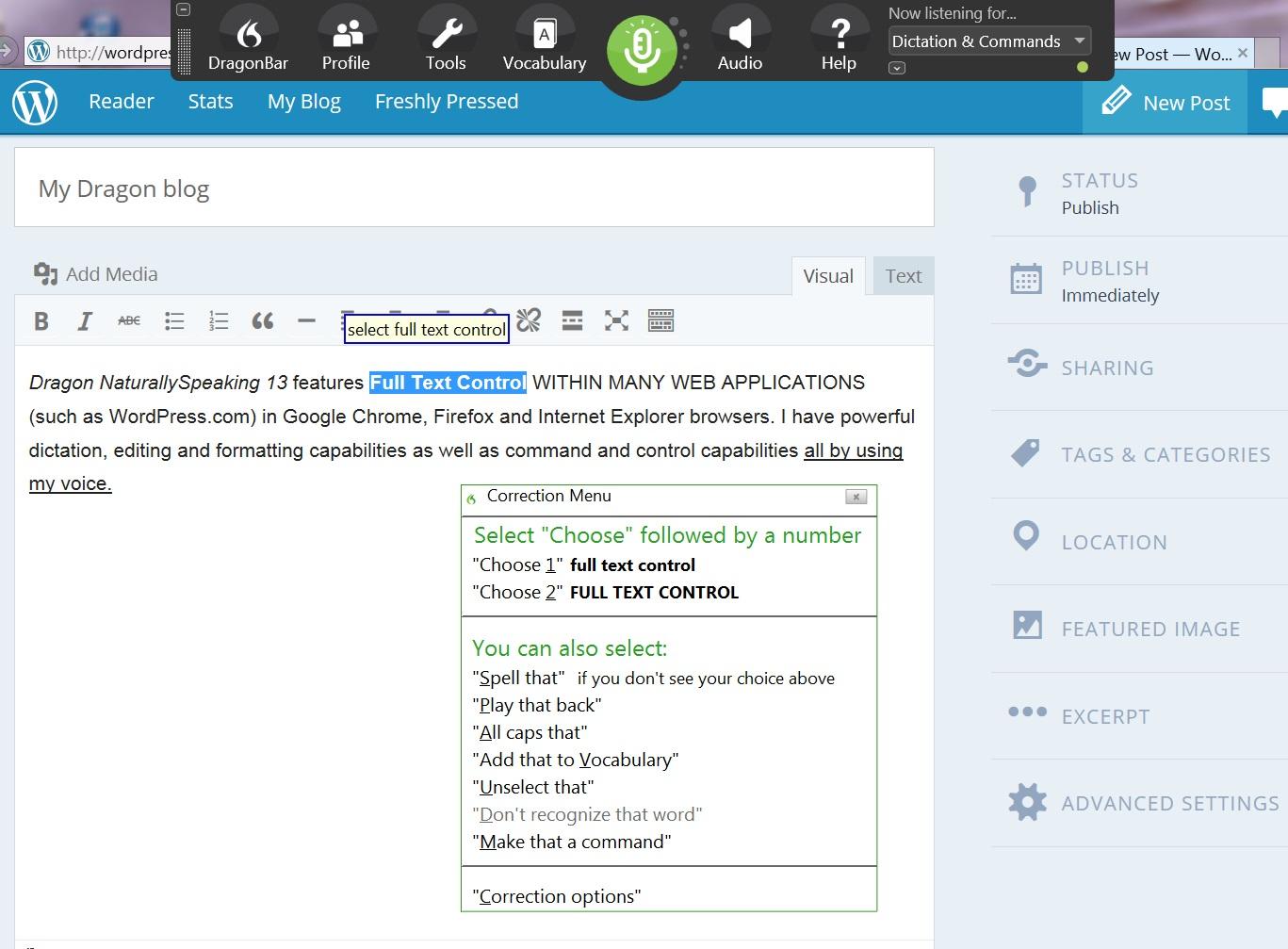
Естественно говорящий дракон
Dragon v15 создан для ОС Windows и позволит вам напрямую диктовать текст практически во всех приложениях Windows с помощью голоса. Это включает Microsoft Office и веб-браузеры. Если вы пользователь Mac, не волнуйтесь, вы можете получить точно такой же пакет с Dragon Professional Individual для Mac.
Дракон Профессиональный Индивидуальный v12
Помимо диктовки, Dragon также можно использовать в качестве виртуального помощника, выполняя ваши голосовые команды, такие как открытие приложений, отправка электронных писем, просмотр сети и планирование встреч. Это программное обеспечение содержит обучающие модули на экране в каждом из своих пакетов, которые дают четкие рекомендации о том, как в полной мере использовать возможности Dragon.
Dragon Professional v12, возможно, не самый дешевый, но я могу гарантировать, что благодаря тому, что он предлагает, вы получите полную отдачу от своих денег.

Braina
Braina позволяет диктовать текст различным приложениям на вашем компьютере и поддерживает более 100 различных языков. Это программное обеспечение также достаточно эффективно для расшифровки акцентов, и, в довершение всего, вы можете настроить его для точного распознавания слов, которые могут отсутствовать в его базе данных. Кстати, у Braina довольно обширная база данных, охватывающая различные профессии, такие как юриспруденция, медицина и наука. Подобно Дракону, Braina позволяет вам озвучивать команды / текст по беспроводной сети с помощью приложения, доступного как для устройств Android, так и для iOS.
Braina доступна как в бесплатной, так и в платной версиях. Если вы используете бесплатную версию, вам, возможно, придется пойти на компромисс с некоторыми функциями. Например, он поддерживает распознавание голоса только для английского языка.
Пользователям Windows, которые ищут быстрый способ преобразовать свою речь в текст, не нужно далеко ходить. В ОС Windows есть собственный инструмент распознавания голоса, который можно легко настроить. Для пользователей Windows 10 все, что вам нужно сделать, это выполнить поиск по распознаванию речи на панели поиска, расположенной в левой части панели задач, и это запустит процесс установки.
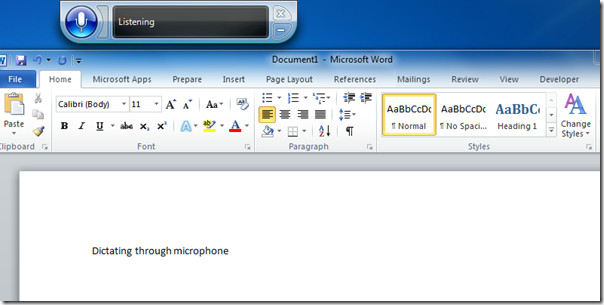
Распознавание речи Windows
Этот инструмент позволяет не только преобразовывать голос в текст, но и управлять вашим компьютером. Это означает, что вы сможете открывать программы и перемещаться по меню, просто используя свой голос. Кроме того, вы сможете управлять каждым приложением из их определенного интерфейса. Будь то электронное письмо или текстовый документ.
Однако для использования распознавания речи Windows вам понадобится специальный микрофон. Он предлагает поддержку микрофона гарнитуры, настольного микрофона и различных других типов, таких как массивные микрофоны. Некоторые пользователи также могут использовать микрофон по умолчанию на своих компьютерах, но в большинстве случаев это может быть проблемой.
Windows Speech Recognition может не иметь возможностей адаптивного обучения Dragon Naturally Speaking, но в нем есть функция обучения распознаванию речи, с помощью которой вы можете научить свой компьютер лучше распознавать вашу речь. Вы также можете предоставить ему доступ к вашим документам, где он определит ваш наиболее часто используемый словарный запас и, следовательно, будет способствовать более точному диктованию. Распознавание Windows доступно на английском, французском, китайском, японском и испанском языках.

Хорошо, в Windows есть встроенный инструмент для диктовки, и поэтому, естественно, Apple должна иметь собственное программное обеспечение для распознавания речи, не так ли? Вы не ошиблись, пользователи iOS и MacOS также имеют доступ к бесплатному программному обеспечению для распознавания голоса под названием Apple Dictation. Если вы используете iOS, вы можете быстро активировать его, нажав микрофон на клавиатуре устройства. Для пользователей MacOS просто перейдите в Системные настройки, нажмите на клавиатуре, а затем на диктовку.
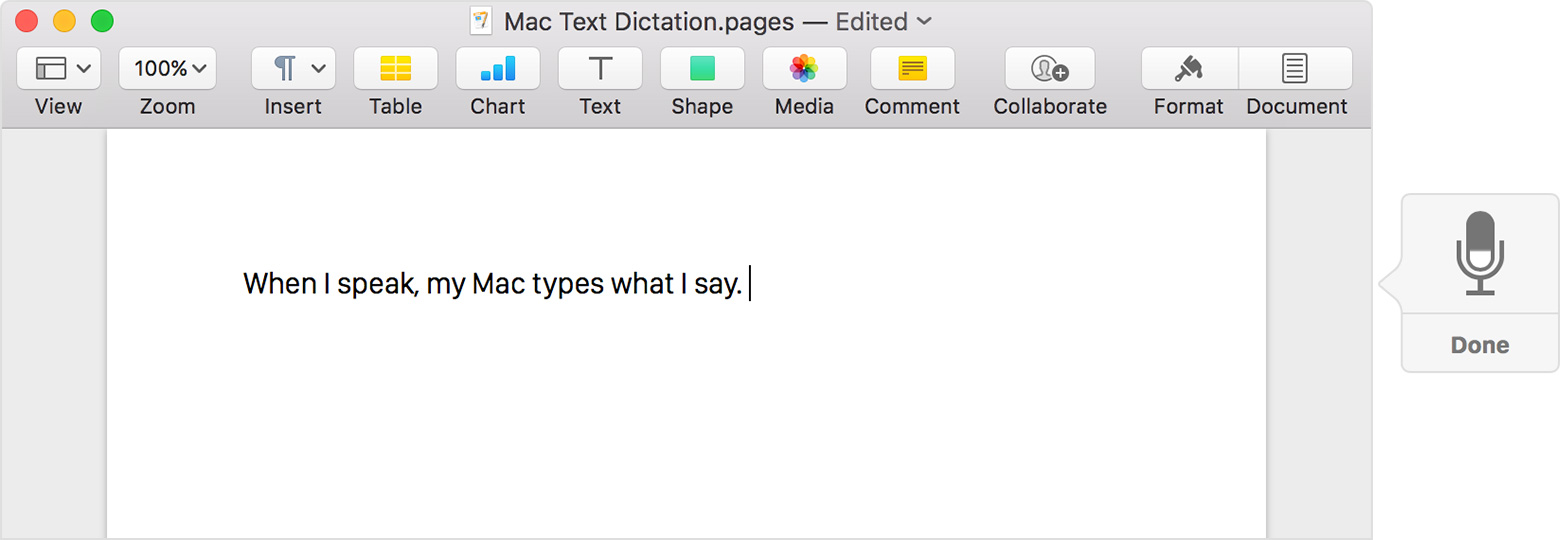
Яблочный диктант
К сожалению, если вы используете любую версию OS X старше 10.9, у вас будет доступ только к стандартной версии этого программного обеспечения, которая имеет свои ограничения. Например, вы не можете использовать его в автономном режиме, и даже тогда вы не можете разговаривать более 40 секунд за один раз. Вероятно, это связано с тем, что ваш звук должен быть сначала отправлен в Apple, прежде чем преобразовываться в текст. Однако с расширенной версией вам не нужно подключаться к Интернету и нет ограничений по времени.
Расширенная версия диктовки также имеет набор из более чем 70 команд, которые облегчают редактирование и форматирование вашего текста. Для простоты использования эти команды видны на небольшом экране дисплея вашего устройства. И что еще лучше, программа Apple Dictation позволяет создавать свои собственные команды. В отличие от распознавания речи Windows, это программное обеспечение поддерживает 20 различных языков.
Если вы часто используете Google Docs и G-Suite в целом, вы будете рады узнать, что в нем есть встроенная функция распознавания голоса, которая позволяет вам легко диктовать текст. И если вы не являетесь пользователем, возможно, вам пора подумать о том, чтобы попробовать его.
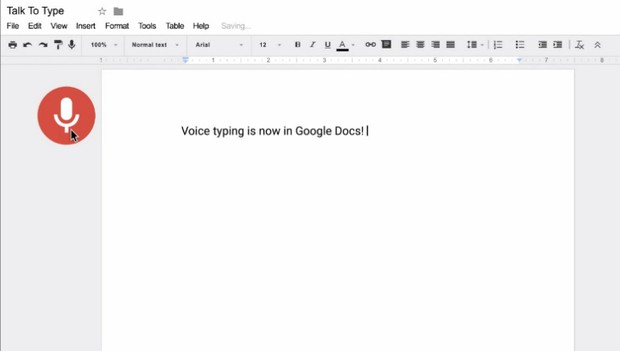
Голосовой ввод Google Документов
Чтобы использовать голосовой набор в Google docs, все, что вам нужно, это учетная запись Google. Как только вы войдете в свою учетную запись, откройте документы Google и перейдите к голосовому вводу. Во время первоначальной настройки вам будет предложено разрешить доступ к микрофону вашего компьютера. Вы также можете подключить внешний микрофон для более точного распознавания голоса. Обратите внимание: для доступа к этой функции вам нужно будет использовать Google Chrome.
Читайте также: