
Сканер не распознает текст

Как любая техника, сканер требует умелого обращения. В противном случае проблемы при сканировании гарантированы. К счастью, их несложно решить самостоятельно, если знать как. Давайте рассмотрим основные неполадки и способы их устранения.
Не появляется отсканированное изображение
Как правило, трудности со сканированием возникают из-за неправильной настройки параметров для получения изображения. Если сканер работает впустую, скорее всего, дело в неправильном формате.
Например, в параметрах сканирования установлен формат А5, тогда как вы пытаетесь создать электронную копию для документа формата А4. Решение: установите подходящий формат.
Распознавание идет еле-еле
Многие проблемы при сканировании связаны с неподходящим разрешением. Если оно слишком высокое, процесс распознавания значительно замедлится, при этом его качество заметно не вырастет. Чтобы «разогнать» сканер, уменьшите разрешение до оптимальных значений:
- 300 dpi для печатных текстов с обычным шрифтом;
- 400-600 dpi для текстов с мелким шрифтом.
Плохое качество изображения
Слишком низкое разрешение – тоже плохо. Если вы видите, что качество скана оставляет желать лучшего, попробуйте немного увеличить этот параметр.
Внимание! Для корректного распознавания текста важно, чтобы разрешение изображения было одинаковым по вертикали и по горизонтали.
Изображение слишком светлое/темное
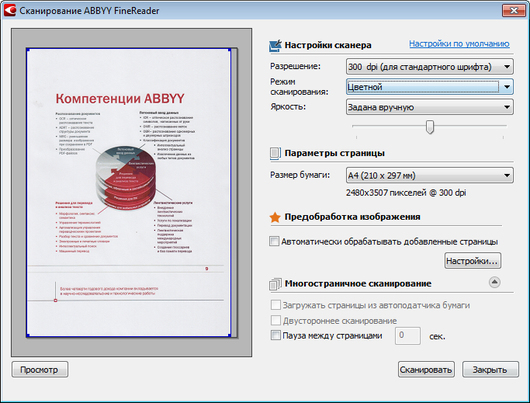
Такие проблемы при сканировании решаются путем регулировки яркости в окне сканера. Для большинства случаев рекомендуется устанавливать среднее значение яркости, но из-за особенностей сканируемого документа правило «золотой середины» может не сработать. Если линии букв слишком светлые и прерывистые, уменьшите значение яркости и снова отсканируйте документ. Если линии настолько толстые, что символы «склеиваются» друг с другом, значение яркости следует увеличить.
Также поэкспериментируйте с настройками контрастности. При увеличении значения этого параметра светлые оттенки становятся светлее, а темные – темнее. При увеличении контрастности обнаруживается больше оттенков в области серого.
Не получается найти отсканированный документ
Зайдите в настройки сканера – там указано место сохранения всех выполненных сканов. Как правило, для этой цели на жестком диске создается отдельная служебная папка. В настройках вы также сможете изменить адрес, по которому система по умолчанию сохраняет готовый результат. Если вы не нашли файл в указанной папке, вероятней всего, скан просто не сохранился. Чтобы не тратить время на поиски, отсканируйте документ заново.
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ. Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст. Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и FB2, что полезно при создании электронных книг и документации для последующей печати.

Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений; для активации.
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
Исправление ошибок
Есть ряд общих советов по исправлению некорректной работы:
Устранение ошибки «Параметр задан неверно»
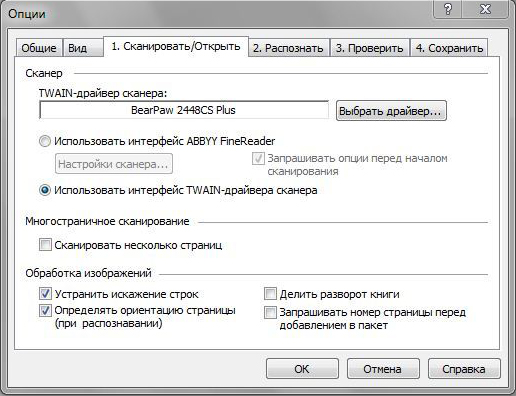
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:
- Перезапустите программу FineReader.
- Зайдите в меню «Инструменты», выберите «OCR-редактор».
- Нажмите «Инструменты», потом «Настройки».
- Включите раздел «Основные».
- Перейдите к «Выбор устройства для получения изображений», затем «Выберите устройство».
- Нажмите на выпадающий список доступных драйверов. Проверьте работоспособность сканирования поочерёдно с каждым из списка. В случае успеха с каким-то из них, используйте его в дальнейшем.
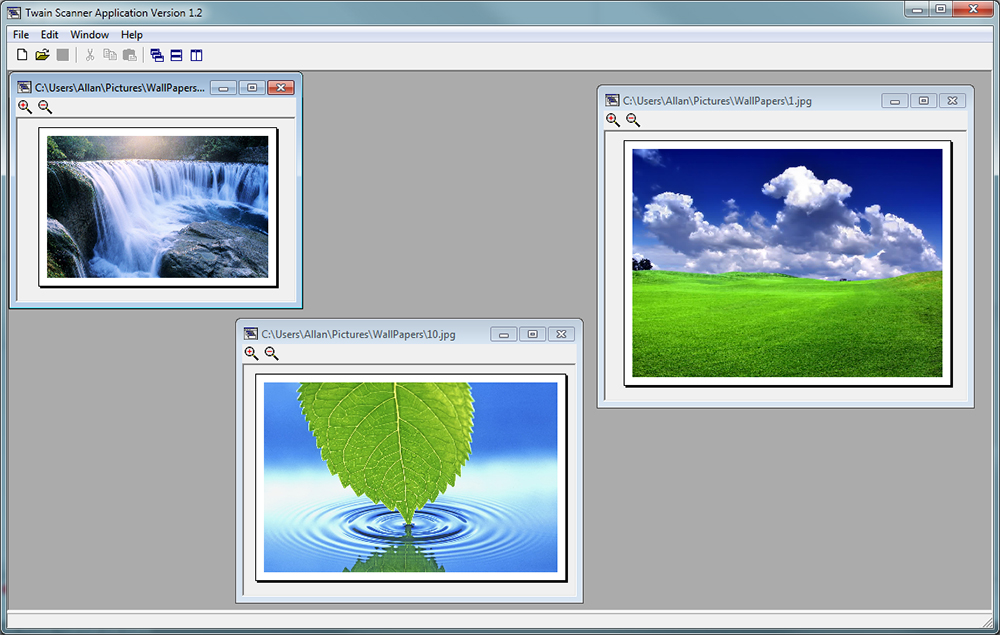
После этого следуйте инструкции:
- Выйдите из Файн Ридер. twack_32.zip в любую папку.
- Дважды щёлкните по Twack_32.exe.
- После запуска программы зайдите в меню «File», затем «Acquire».
- Нажмите «Scan» в открывшемся диалоге.
- Если документ успешно отсканировался, откройте меню «File» и щёлкните «Select Source».
- Синим цветом окажется отображён драйвер, через который утилита успешно выполнила сканирование.
- Выберите этот же файл драйвера в файнридере.
Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Внутренняя программная ошибка
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:
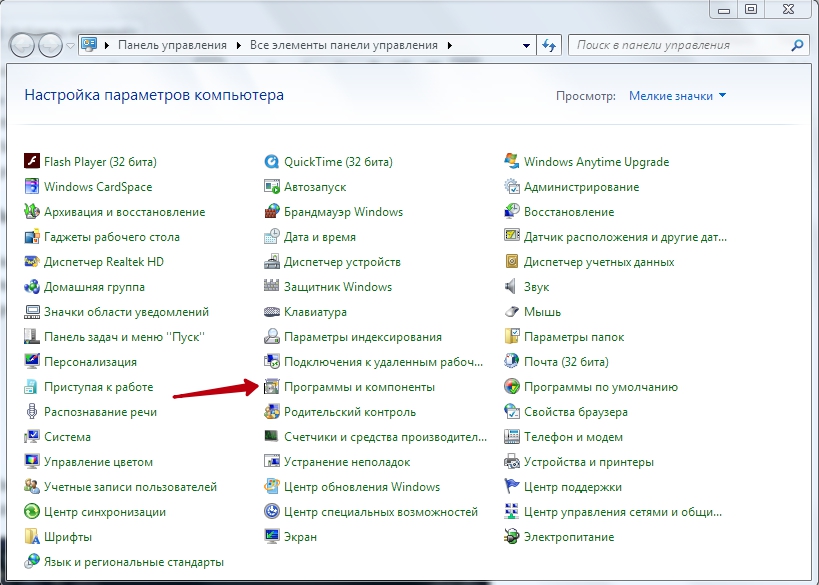
- Добавьте Fine Reader в исключения антивирусного ПО.
- Перейдите в «Панель управления», «Установка и удаление программ».
- Найдите Fine Reader и нажмите «Изменить».
- Теперь выберите «Восстановить».
- Запустите программу и попробуйте отсканировать документ.
Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Таким образом решается проблема подключения программы Fine Reader к сканеру. Иногда причина в конфликте драйверов или несовместимости оборудования. А бывает, сбой сканирования возникает из-за внутренних программных ошибок. Если вы сталкивались с подобными проблемами в файнридере, оставляйте советы и способы решения в комментариях.
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса

Отсканируйте или сфотографируйте текст для распознавания

Загрузите файл

Выберите язык содержимого текста в файле

После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 23M+ запросов
Основные возможности

Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani - Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese - Simplified, Chinese - Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian - Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian - Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek - Cyrillic, Vietnamese

Покажу как это сделать быстро и качественно на примере программы Abbyy FineReader версии 8.0. Принципы, изложенные здесь, можно с успехом применить и в любой другой программе распознавания текста, и в любой другой версии программы FineReader. FineReader на пост-советском пространстве – самая распространённая и успешная программа для этой задачи.
Итак, для того чтобы получить отличный результат нам нужно качественно сосканировать оригинал. Легче всего этого достичь с листов формата А4, распечатанных на принтере, труднее с книг, журналов, газет. Качество сканирования – основа, от которой будет зависеть дальнейший успех работы.
Несколько слов об автоматизации процессов распознавания. Хотя от версии к версии авторы программы FineReader улучшают алгоритмы автоматического распознавания сложных макетов (Scan&Read – когда достаточно запустить программу и нажать одну кнопку, а остальное программа сделает за Вас сама, и Вам остаётся лишь насладиться результатами процесса), эти алгоритмы срабатывают не всегда корректно. Искусственный интеллект ещё не скоро заменит человеческую смекалку и здравый смысл. Причиной чего и послужило написание этой статьи.
Сканирование текста
Запускаем программу Abbyy FineReader, нажимаем кнопочку «Сканировать», ложим наш оригинал в сканер и делаем пробное сканирование. Для оптимальной скорости и качества сканирования в драйвере сканера достаточно выставить режим сканирования «Чёрно-белое» и разрешение 300 точек на дюйм.



Режимы «Оттенки серого» и «Цветное изображение» тоже подходят, но от этого увеличивается время сканирования и возможно, пострадает качество распознавания текста (Серый или цветной фон, особенно если он неоднородный может существенно ухудшить качество распознавания текста). В идеале нам нужно добиться чтобы на белом фоне были чёрные буквы и больше никаких посторонних объектов. Смотрим на результат, если он нас устраивает: буквы видно отчётливо, шума, грязи практически нет, то продолжаем сканирование далее, если шума много (такое бывает, например, если оригинал отпечатан на жёлтой бумаге) – ползунками яркости и контрастности двигаем так, чтобы шум максимально пропал, а буквы стало видно более отчётливо, делаем ещё несколько пробных сканирований пока не добьёмся нужного результата. Как только приемлемый результат получен – приступаем к основному сканированию. Если нам нужно сканировать одновременно участки текста из разных источников (несколько книг, журналов, газетных вырезок), то такую калибровку для достижения приемлемого результата часто приходится делать для каждого источника отдельно.
Поворот страниц.
В программу FineReader встроен механизм автоматического определения ориентации страниц и автоматического же их поворота. В простых случаях этот механизм отлично работает и не требует от нас никакого участия, но если текст видно не очень отчётливо, либо если разные страницы отсканирываны под разными углами, здесь мы получаем сбой и в результате получаем вместо текста абракадабры. Потому имеет смысл осуществлять поворот вручную.

Распознавание текста
Сосканировав все листы документа можно приступать к его распознаванию. Выбираем язык распознаваемого документа. Это важно потому что буквы в разных языках разные и если, например мы будем распознавать украинский текст как русский, то в конечном результате в распознанном тексте будет распознано практически всё более-менее правильно, но украинские буквы «і», «ї» «є» не будут распознаны и FineReader заменит их на что-то более-менее похожее и в конце прийдётся все эти огрехи выправлять вручную. То же самое бывает когда в русском тексте встречаются адреса электронной почты, сайтов, какие-то слова, набранные на иностранном языке, а мы текст распознаём как «русский», то эти символы FineReader заменит на что-то более-менее похожее из русского алфавита. В таком случае перед распознаванием нужно FineReader-у указать, что текст состоит из нескольких языков, отметив нужные галочками. Не стоит также злоупотреблять выбором языков, отметив все возможные какие есть. В этом случае мы тоже можем в результате получить «катавасию» из всех возможных символов вместо искомого результата.
Когда макеты разобраны можно приступать непосредственно к самому процессу распознавания. То есть нам нужно просто нажать на кнопочку «Распознать» и, откинувшись в кресле, дождаться окончания процесса распознавания. А по его окончании, бегло глянув на распознанные страницы, убедиться что тексты, таблицы и прочие объекты распознаны корректно, т.е. процентов на 90-95 (в идеале конечно на все 100) и можно приступать к завершающему этапу работ: постбоработке и сохранению результатов.
Несмотря на все наши предыдущие старания огрехи распознавания будут, и их количество зависит от того, на сколько старательно мы выполняли предыдущие этапы. FineReader помогает нам в этом, подсвечивая участки, в качестве распознавания которых он не уверен, синим цветом. На них мы обращаем внимание в первую очередь и если эти участки распознаны неверно – поправляем их.
Сохранение результатов распознавания можно сделать двумя способами: непосредственно в текстовый редактор (например Microsoft Word) или через буфер обмена. Первый способ нам может пригодиться когда нам нужно максимально сохранить исходное форматирование документа: заголовки, шрифты, взаимное расположение текстовых колонок и графических элементов. Но иногда исходное форматирование нам не нужно и более того, вредно, потому что в текстовом редакторе потом бывает очень сложно потом разобраться что за чем идёт и почему, и как, как сделать по другому, так как нам это будет нужно. При передаче текста через буфер обмена мы избегаем этих моментов и на выходе имеем чистый текстовый массив, который можем уже обрабатывать форматировать на наше усмотрение. И уже в Ворде мы выполняем последний этап работ: убираем лишние детали: множественные пробелы, пробелы перед запятыми, точками, знаки табуляции, исправляем кавычки, знаки тире, исправляем неправильно распознанные участки текста и т.д.
Ну и завершающий этап работ – собственно для чего это всё и затевалось: толи нам нужен был просто распознанный текст, толи нам нужно в него внести изменения для дальнейшей работы.
Читайте также: