
Шрифты символы которых хранятся в памяти компьютера в виде поточечного разложения
1. Какой объём памяти займёт приведённый ниже текст, если известно, что в нём используется кодировочная таблица ASCII ?
Happy New Year, dear friends!!
2. C помощью кодировочной таблицы ASCII раскодируйте заданный текст:
98 121 99 107 32 105 115 32 109 121 32 100 111 103 46
3. C помощью кодировочной таблицы ASCII закодируйте заданный текст:
I was born in 1975.
4. Сколько символов содержится в тексте, использующем таблицу ASCII , если известно, что он занимает 24 576 бит памяти?
Выбранный для просмотра документ Задачи группам.docx
Сколько бит памяти компьютера занимает слово МИКРОПРОЦЕССОР?
Что зашифровано последовательностью десятичных кодов: 108 105 110 107, если буква i в таблице кодировки символов имеет десятичный код 105?
С помощью последовательности десятичных кодов: 225 232 242 зашифровано слово бит. Найти последовательность десятичных кодов этого же слова, записанного заглавными буквами.
Свободный объем оперативной памяти компьютера 640 Кбайт. Сколько страниц книги поместится в ней, если на странице 16 строк по 64 символа в строке?
Текст занимает полных 10 секторов на односторонней дискете объемом 180 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
Выбранный для просмотра документ Кодовые таблицы.doc
КОИ-7, КОИ-8 – кодирование русских букв и символов (семи-, восьми -битное кодирование)
ASCII – American Standard Code for Information Interchange (американский стандарт кодов для обмена информацией) – это восьмиразрядная кодовая таблица, в ней закодировано 256 символов (127- стандартные коды символов английского языка, спецсимволы, цифры, а коды от 128 до 255 – национальный стандарт, алфавит языка, символы псевдографики, научные символы, коды от 0 до 32 отведены не символам, а функциональным клавишам).
Международная кодировка ASCII

Символы альтернативной кодировки расширенного кода ASCII

Unicode – стандарт, согласно которому для представления каждого символа используется 2 байта. (можно кодировать математические символы, русские, английские, греческие, и даже китайские). C его помощью можно закодировать не 256, а 65536 различных символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов
СР1251 - наиболее распространенной в настоящее время является кодировка Microsoft Windows, ("CP" означает "Code Page", "кодовая страница").
Кодировка CP 1251

СР866 - кодировка под MS DOS
Мас – кодировка в ПК фирмы Apple, работающих под управлением операционной системы Mac OS .

ISO 8859-5 -Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку.
Кодировка ISO 8859-5
Выбранный для просмотра документ Моя презентация.ppt

для работы онлайн
в проекте «Инфоурок»
Описание презентации по отдельным слайдам:
Представление текстов в памяти компьютера. Кодировочные таблицы.. 2013 – 2014 учебный год
Имея компьютер, можно создавать тексты, не тратя на это много времени и бумагу. Носителем текста становится память ПК. Текст на внешних носителях сохраняется в виде файла.
Самое поразительное отличие компьютерного текста от бумажного – это создание в нем гипертекста. Гипертекст – это способ организации текстовой информации, внутри которой установлены смысловые связи (гиперсвязи) между ее различными фрагментами.
Главное неудобство хранения текстов в файлах состоит в том, что прочитать их можно только с помощью компьютера.
С точки зрения компьютера текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и даже пробелы между словами. Множество символов, с помощью которых записывается текст, называется алфавитом. Число символов в алфавите – это его мощность.
Определение количества информации: где N – мощность алфавита (количество символов), b – количество бит (информационный вес символа). Т.к. в алфавите 256 символов, тогда 256 = 28, т.е. вес 1 символа – 8 бит. Единице измерения 8 бит присвоили название 1 байт: 1 байт = 8 бит. Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти. N = 2b
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Структура таблицы кодировки ASCII Таблица кодов ASCII делится на две части. Порядковый номер Код Символ 0 - 31 00000000 – 00011111 Управляющие символы. Процесс вывода текста на экран или печать, подача звукового сигнала, разметка текста. 32 - 127 00100000 – 01111111 Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. 128 - 255 10000000 – 11111111 Вторая половина может иметь различные варианты. Кодовая страница используется для размещения национальных алфавитов. Для нас в этой это символы русского алфавита.
В таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера. Слова Память file disk 01100110 01101001 01101100 01100101 01100100 01101001 01110011 01101011
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Почему это происходит?
Пример. Сколько бит памяти компьютера занимает выражение жесткий диск? Решение. Жесткий диск – 12 символов, значит занимает 12 байт 12байт х 8= 96 бит
С помощью таблицы ASCII закодировать и декодировать слова Link 01001100 01101001 01101110 01101011 2) Класс 11001010 11101011 11100000 11110001 11110001 3) 01010111 01101001 01101110 01100100 01101111 01110111 01110011 Windows
3. Код (номер) буквы "j" в таблице кодировки символов равен 106. Какая последовательность букв будет соответствовать слову "file"? Алфавит латинских букв: abcdefghijklmn … 1) 110 107 104 111 2) 74 98 120 66 3) 132 112 90 140 4) 102 105 108 101 5) 90 102 114 86 4. Последовательность кодов 105 162 109 таблицы кодировки шифрует некоторые символы. Вставить вместо многоточия верное утверждение. "Среди этих символов …" 1) не может быть букв русского алфавита 2) не может быть букв латинского алфавита 3) могут быть буквы русского и латинского алфавитов 4) не может быть букв русского и латинского алфавитов 5) может быть только одна буква латинского алфавита
5. Для хранения текста требуется 10 Кбайт. Сколько страниц займет этот текст, если на странице размещается 40 строк по 64 символа в строке? 1) 4 2) 40 3) 160 4) 256 5) 320 Кроссворд Кроссвордик.xls
Благодарю за внимание
Цель урока: Изучение способов представления и организации текстов в компьютерной памяти. Задачи: обучающие: изучить способы представления текстов в компьютерной памяти, дать понятия «кодировочная таблица», «гипертекст» ознакомить учащихся с международными стандартами ASCII и Unicode,способствовать овладению техники перевода текста из одной кодировки в другую. - развивающие развивать наблюдательность, память. - воспитательные способствовать воспитанию чувства коллективизма, взаимопомощи.
Тип урока комбинированный Формы работы учащихся индивидуальная, групповая. Необходимое техническое оборудование: персональные компьютеры, мультимедийный проектор, экран.
Выбранный для просмотра документ Памятка.docx
Выбор кодировки при открытии файла
Если текст в открытом файле отображается в искаженном виде, с вопросительными знаками или квадратами, возможно, приложению Word не удалось правильно определить его кодировку. Чтобы устранить эту проблему, можно указать кодировку для отображения (декодирования) текста.
Откройте вкладку Файл .
Выберите команду Параметры .
Выберите пункт Дополнительно .
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии .
Закройте и снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст .
В диалоговом окне Преобразование файла установите переключатель Другая: и выберите нужную кодировку из списка.
В области Образец: можно просмотреть текст и проверить, можно ли его прочитать в выбранной кодировке.
Выбор кодировки при сохранении файла
Если при сохранении файла в приложении Word не указать кодировку, он будет сохранен в Юникоде. Как правило, кодировки Юникод вполне достаточно, поскольку она поддерживает большинство знаков из большинства языков.
Откройте вкладку Файл .
Выберите пункт Сохранить как .
Если требуется сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите новое имя файла.
В поле Тип файла выберите пункт Обычный текст .
Если появится диалоговое окно Microsoft Office Word — проверка совместимости , нажмите кнопку Продолжить .
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать кодировку системы по умолчанию, установите переключатель Windows (по умолчанию) .
Чтобы использовать кодировку MS-DOS, установите переключатель MS-DOS .
Чтобы задать другую кодировку, установите переключатель Другая: и выберите нужный пункт в списке. В области Образец: можно просмотреть текст и проверить, можно ли его прочитать в выбранной кодировке.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).

Выбранный для просмотра документ План-конспект урока.doc
ПЛАН-КОНСПЕКТ УРОКА
Представление текстов в памяти компьютера. Кодировочные таблицы.
ФИО (полностью)
Мурмилова Екатерина Сергеевна
Место работы
МОУ СОШ №3 г. Комсомольск-на-Амуре
Должность
Предмет
Класс
Тема и номер урока в теме
«Представление текстов в памяти компьютера. Кодировочные таблицы» Урок № 9
Базовый учебник
«Информатика и информационные технологии», 8 класс, А. Г. Гейн, А. И. Сенокосов, Н. А. Юнерман, М.: Просвещение, 2008
Цель урока: Изучение способов представления и организации текстов в компьютерной памяти.
Задачи:
- обучающие: изучить способы представления текстов в компьютерной памяти, дать понятия «кодировочная таблица», «гипертекст» ознакомить учащихся с международными стандартами ASCII и Unicode ,способствовать овладению техники перевода текста из одной кодировки в другую.
- развивающие развивать наблюдательность, память .
- воспитательные способствовать воспитанию чувства коллективизма, взаимопомощи.
Тип урока комбинированный
Формы работы учащихся индивидуальная, групповая.
Необходимое техническое оборудование: персональные компьютеры, мультимедийный проектор, экран.
Структура и ход урока
СТРУКТУРА И ХОД УРОКА
Слайд презентации
Деятельность учителя
Деятельность ученика
Приветствие, проверка присутствующих. Объяснение хода урока.
Включаются в деловой ритм урока.
Формулирует вопросы, актуализирующие опорные знания и умения учащихся по теме урока.
- Как должна быть представлена информация, которою обрабатывает компьютер?
- Как принято называть символы 0 и 1?
Отвечают на вопросы:
Включаются в мыслительный процесс по представлению текстовой информации в памяти компьютера.
Изучение нового материала
«Любой из вас согласится с тем, как много сил и времени затрачивается на многочисленные записи, которые приходится делать в различных ситуациях. На уроке вы записываете в тетради объяснения учителя; дома – домашнее задание, пишете письма родственникам или друзьям; кто-то занимается литературным творчеством. Чем отличается обработка и хранение текстов при ручной записи и при создании текстов на компьютере? »
Учитель предлагает самостоятельно ответить на вопрос «Сформулируйте недостатки бумажной технологии и достоинства компьютерной технологии».
Учитель демонстрирует слайд и предлагает ученикам сравнить свою работу со слайдом на экране.
Учитель демонстрирует презентацию с теорией по теме.
Самое поразительное отличие компьютерного текста от бумажного, если информация в нем организована по принципу гипертекста.
Для представления информации в компьютере используется алфавит мощностью 256 символов.
Чему равен информационный вес одного символа такого алфавита?
Вспомним формулу, связывающую информационный вес символа алфавита и мощность алфавита:
Выполняют записи в тетрадях и сравнивают со слайдом:
Преимущества файлового хранения текстов:
экономия бумаги;
компактное размещение;
возможность многократного использования магнитного носителя для хранения разных документов;
возможность быстрого копирования на другие магнитные носители;
возможность передачи текста по линиям компьютерной связи.
Гипертекст – это способ организации текстовой информации, внутри которой установлены смысловые связи (гиперсвязи) между ее различными фрагментами.
Если мощность алфавита равна 256, то i = 8, и, следовательно, один символ несет 8 бит информации.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена). На практике можно встретиться и с другой таблицей – КОИ-8 (Код обмена информацией), которая используется в глобальных компьютерных сетях.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Почему иногда текст, состоящий из букв русского алфавита, полученный с другого компьютера, мы видим на своем компьютере в виде "абракадабры"?
Таблица кодировки - Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера.
Цифровой или компьютерный шрифт — шрифт, записанный в виде последовательности цифровых значений, определяющих форму знаков. С точки зрения описания компьютерные шрифты делят на растровые, векторные, контурные, алгоритмические.
В растровых шрифтах символы хранятся в памяти компьютера в виде поточечного разложения. Растровый шрифт не допускает масштабирования и изменения начертания, в связи с чем этот тип редко используется.
Векторные шрифты характеризуются тем, что изображение символа формируется в виде набора векторов, которые заполняют пространство, занимаемое символом. При масштабировании качество воспроизведения ухудшается, но трансформирование возможно. Векторные шрифты используются для вывода на плоттеры и векторные дисплеи.
Контурные шрифты образуются путем описания контуров символов в виде прямых и кривых линий. Такое описание позволяет легко изменять масштаб изображения без потери качества и занимает немного места в памяти компьютера.
Алгоритмические шрифты обладают наибольшими возможностями при формировании символов. Используются специальные языки описания символов. Они содержат команды управления, описания переменных и массивов, ассортимент расчетных функций обмена с внешней средой, набор геометрических примитивов, поэтому трудоемкость построения шрифтов высока. Реализованы в издательской системе Тех.
В настоящее время в полиграфии используются шрифты трех форматов: PostScript, TrueType, OpenType, отличающихся способом хранения и представления информации о шрифте.
13. Формотирование док-та. Типы форматир.Док-та. Форматир.Абзаца
Форматирование — изменение внешнего вида текста документа, его оформление. Содержание текста при этом не меняется. Цель операции форматирования — создание акцентов с помощью разных приемов, привлечь внимание к документу.
Используются 2 способа форматирования:
прямое, когда установка параметров форматирования осуществляется вручную до набора текста или после его набора;
стилевое, когда фрагментам текста назначаются стили, которые имеют определенный набор параметров форматирования. Для применения этой совокупности параметров форматирования достаточно назначить стиль. При изменении формата стиля все фрагменты, используемые данный стиль, будут автоматически переформатированы.
При выполнении форматирования различают операции по форматированию символов (от одного символа до символов всего текста) и операции по форматированию абзацев, как структурной единицы текста. Все настройки, которые могут пригодиться пользователю в процессе форматирования текста, вынесены в отдельный пункт главного меню ФОРМАТ.
Форматирование абзаца Различают абзацы нескольких типов:
1) С абзацным отступом (в Word — отступ первой строки);
2) с обратным абзацным отступом (в Word — выступ первой строки);
3) втяжка или отступ абзаца — пробел, образующийся слева и/или справа от края набора основного для издания формата, когда часть строк полосы набирают на более узкий формат: со сдвигом влево — правосторонняя втяжка, вправо — левосторонняя, с обеих сторон — двусторонняя [2];
4) выступ абзаца, когда границы абзаца шире основного текста.
К параметрам формата абзаца относятся:
отсутствие/наличие абзацного или обратного абзацного отступа;
выключка — способ выравнивания строк абзаца на странице. Различают выключку на середину формата (в Word — по центру), по левому краю, по правому краю и на формат (в Word — по ширине). При выключке на середину формата, отступы строк от правого и левого края страницы одинаковы, независимо от длины строки. Выключка по левому краю часто используется для придания документу «живого», не «компьютеризированного» вида. Выключку по правому краю можно использовать для создания подписей на документах, адресов и т. п. При включенном режиме выключки строк на формат между словами строки добавляются пробелы для того, чтобы все строки имели одинаковую длину, такое выравнивание придает документу вид официального;
интерлиньяж (в Word — междустрочный интервал);
отступ границ абзаца от границ полей;
интервал между абзацами.
Форматировать абзацы можно с помощью линейки, панели инструментов ФОРМАТИРОВАНИЕ, диалогового окна АБЗАЦ (меню ФОРМАТ–АБЗАЦ).
Вкладка ОТСТУПЫ И ИНТЕРВАЛЫ окна АБЗАЦ используется:
1) для выбора выключки строк (область ОБЩИЕ, раскрывающийся список ВЫРАВНИВАНИЕ);
2) для установки отступа строк абзаца слева и справа (область ОТСТУП, поля СЛЕВА и СПРАВА). Ввод отрицательного значения приводит к вынесению текста на левое или правое поле;
3) для установки абзацного или обратного абзацного отступа (область ОТСТУП, раскрывающийся список ПЕРВАЯ СТРОКА);
4) для установки расстояния до и после абзаца (область ИНТЕРВАЛ, поля ПЕРЕД и ПОСЛЕ). Если интервал от текущего абзаца до соседних строк отличается от интерлиньяжа, то расстояние перед/ после абзаца называется отбивкой сверху/снизу;
5) для установки интерлиньяжа (область ИНТЕРВАЛ, раскрывающийся список МЕЖДУСТРОЧНЫЙ). Возможны следующие варианты::
а) одинарный интерлиньяж выбирается автоматически, для большинства гарнитур он равен 120% наибольшего кегля абзаца;
б) полуторный или двойной интерлиньяж превышает одинарный в 1,5 раза или 2 раза;
в )минимум — это минимальный интерлиньяж, который подбирается автоматически при вставке шрифтов больших размеров или графики, которые никаким другим образом не могли бы уместиться в заданном интерлиньяже;
г ) точно — это фиксированный интерлиньяж, который не меняется в зависимости от кегля шрифта;
д) множитель позволяет задать число, на которое будет умножаться значение одинарного интерлиньяжа.
Вкладка ПОЛОЖЕНИЕ НА СТРАНИЦЕ используется:
для переноса всего абзаца на следующую страницу (устанавливается флажок НЕ РАЗРЫВАТЬ АБЗАЦ);
для контроля висячих строк (устанавливается флажок ЗАПРЕТ ВИСЯЧИХ СТРОК). Висячая строка — концевая строка абзаца, стоящая первой на полосе/в колонке, или начальная строка абзаца, стоящая на полосе/в колонке последней;
для сохранения расположения двух абзацев на одной странице (устанавливается флажок НЕ ОТРЫВАТЬ ОТ СЛЕДУЮЩЕГО);
для выноса в начало страницы заголовка какой-либо части документа, например, главы (устанавливается флажок С НОВОЙ СТРАНИЦЫ);
для отключения переносов только в текущем абзаце (устанавливается флажок ЗАПРЕТИТЬ АВТОМАТИЧЕСКИЙ ПЕРЕНОС СЛОВ).

Главная проблема выбора шрифтов — одновременно слишком много и слишком мало вариантов.
С одной стороны, выбор только из системных шрифтов может привести к плохому решению, потому что среди стандартных шрифтов ничего интересного просто не представлено.
С другой стороны, библиотеки веб-шрифтов с сотнями и тысячами наименований поражают изобилием, что иногда приводит к парадоксальным выборам шрифтов.
Горький привкус меню выбора шрифтов
В среднестатистическом меню шрифты отсортированы по имени, но при этом никак не взаимосвязаны друг с другом: за шрифтом, созданным для жирных заголовков, идёт шрифт, разработанный для маленьких экранных интерфейсов, а за ним следует вычурный рукописный шрифт для свадебных приглашений. И приходится терять время на листание всего списка от начала до конца, либо просто выбирать первый подходящий шрифт из начала списка и закругляться.
Очевидно, что такое интерфейсное решение создано не для систематической работы, а для бесконечных сюрпризов. И хотя многие любят сюрпризы, но все же хочется повлиять на успех поиска хорошего шрифта.

Меню выбора шрифтов из видеоролика “Papyrus”. Ограниченный выбор, всевозможные стили, но далеко не лучшие шрифты из всех возможных.
Систематический подход к поиску шрифтов
Есть разные способы ограничить избыточность выбора. Прежде чем заниматься анализом шрифтовых файлов, глифов и таблиц метаданных, давайте сначала поговорим о классификации, отобранных списках и анатомии.
1. Классификация
Существует сложная система классификации шрифтов. Простейшее деление на категории: шрифты с засечками (serif), гротески (sans-serif), моноширинные (monospaced), рукописные (script) и шрифты для дисплеев (display). Обычно эти категории используются в качестве фильтров на разных шрифтовых сайтах:

Но даже эти простые фильтры всё ещё ставят нас перед слишком богатым выбором шрифтов. Здесь уже возникают более дробные градации, например, шрифты с засечками делятся на переходные, гуманистические и готические.
Иногда эти подкатегории доступны в виде тегов. Но иногда авторы шрифтовых сайтов вообще их игнорируют. Возможно, категорий слишком много? Быть может, пользователи просто не разбираются во всех этих подробностях? Или просто у авторов нет полной и последовательной информации для подробной классификации шрифтов?
2. Отобранные списки
Альтернативный способ наведения порядка заключается в том, чтобы положиться на знания других людей: можно использовать списки шрифтов, кем-то отобранных. Такие списки есть, к примеру, на Fontshop. Вы можете найти здесь коллекции, отсортированные по десятилетиям, по степени схожести или по сфере применения.
Подобные списки есть также на Typekit, TypeWolf и FontsInUse. Это замечательная идея, и можно порекомендовать всем начать составлять собственные списки шрифтов, с которыми вы уже работали или видели. В будущем эти наработки вам очень пригодятся.
3. Анатомия
Самое трудное в поиске хорошего шрифта — ориентироваться на особенности дизайна и понимать, какие свойства делают шрифт хорошим или особенным. К счастью, есть достаточно книг по шрифтовому дизайну, шрифтам и типографике. Эти книги могут научить нас, как создавать шрифты, как их выбирать и использовать.
Например, книга “The Anatomy of Type” Стивена Коулза. В ней собрана информация о 100 хорошо проработанных гарнитурах. Для описания качества шрифтов Стивен использует такие термины, как высота строчных литер (х-height, х-высота), ширина, вес, ball terminal, форма засечек и многие другие.

“The Anatomy of Type“ — графическое руководство Стивена Коулза по 100 гарнитурам. Замечательная книга для изучения истории и особенностей дизайна популярных гарнитур.
Но здесь описаны лишь 100 шрифтов, а как быть с остальными? Что насчёт установленных на ваших компьютерах? А используемых в сети? Какие у них х-высоты, ширины, веса и контрасты? Как это можно узнать?
Внутри шрифтового файла: нехватка метаданных
Прежде чем я начал кодить, я считал, что можно быстро получить нужную информацию о свойствах шрифтов. Теоретически, каждый шрифтовой файл должен содержать разные таблицы метаданных с названием, именем автора, поддерживаемыми языками и визуальными свойствами. Самые очевидные — ширина, вес и класс шрифта. Там же можно найти информацию об х-высоте, высоте заглавных букв, средней ширине символа, верхних и нижних выносных элементах букв. Другой набор метаданных под названием Panose описывает ещё больше свойств: форму засечек, пропорции, контраст и прочее. Для просмотра всей этой информации можно использовать приложения для шрифтового дизайна, например, Glyphs:

Скриншот панели с информацией о шрифте. Здесь указано название семейства, имя дизайнера, ссылка, версия, дата. Также можно посмотреть диапазон Unicode и Panose-данные. 10-значный код описывает многие характеристики, но информация не всегда доступна, так как ее вносит дизайнер или создатель файла. На правом скриншоте вы можете увидеть такие метрики, как верхние и нижние выносные элементы, х-высоту и угол наклона.
Но доступность этой информации зависит от того, насколько ответственно подошел к своей работе создатель шрифта. В каких-то шрифтовых файлах есть много данных, но часто информации не хватает, особенно в бесплатных или open source-шрифтах. И даже если в файле есть информация, она может быть некорректной или неполной.

Сравнение Panose-данных для шрифтов Roboto и Fira Sans, оба доступны на Google Fonts. Для Fira Sans указано много информации, а для Roboto — мало. Эти метаданные не получится использовать для сравнения шрифтов.
DIY: Анализируем шрифты с помощью opentype.js
Давайте проанализируем шрифтовые файлы и придумаем, как автоматически извлекать нужную информацию. Файлы имеют разные форматы, но почти всегда можно найти версии в TTF (TrueType Font).
В файлах формата OTF (OpenType) можно найти информацию о дополнительных свойствах, например, лигатурах. В файлах WOFF (Web Open Font Format) есть дополнительные метаданные, а шрифты хранятся в сжатом виде.
Благодаря opentype.js можно анализировать шрифтовые файлы прямо в браузере с помощью JavaScript. Opentype.js предоставляет доступ к векторной информации всех наборных знаков, входящих в файл, а также к основным метрикам и таблицам метаданных.
База данных характеристик шрифтов
Ниже мы рассмотрим, как можно измерить контраст, х-высоту, ширину и вес всех шрифтов из библиотеки Google Fonts. Те же методы можно применить и к другим шрифтовым библиотекам, например, Typekit или шрифтам на вашем компьютере.
Контраст
Контраст описывает соотношение тонких и толстых штрихов символа. Есть шрифты с низким контрастом, например, брусковые, или многие гротески, созданные для интерфейсов, например, Roboto или San Francisco. А есть шрифты с высоким контрастом, например, Bodoni или Didot. Для измерения контраста мы можем посмотреть на контуры буквы «о» и сравнить самое большое и самое маленькое расстояние между внутренним и внешним контуром.

Контраст шрифта можно измерить в самой толстой и самой тонкой части буквы «о».
Это простая и легко поддающаяся сравнению буква почти всегда состоит из двух частей. Она хороший кандидат на оценку контраста шрифта (примечание: форма у «о» простая лишь на первый взгляд, на самом деле её довольно трудно хорошо нарисовать, потому что штрихи должны плавно менять свою толщину).
С помощью opentype.js удобно получить данные для отрисовки символов в виде SVG-элементов. Например, можно отдельно нарисовать внешний и внутренний контуры. Затем с помощью одного алгоритма можно пройти по каждому контуру, измеряя расстояние между ними. После этого вычисляем соотношение между самым длинным и самым коротким расстоянием, и вуаля — получили значение контраста, по которому можно сравнивать шрифты.
х-высота
х-высота — важная характеристика, которая может быть индикатором удобочитаемости и субъективно воспринимаемого размера шрифта. Обычно этот параметр измеряется как высота строчной буквы «х».

х-высоту можно измерить с помощью информации, предоставленной opentype.js.
opentype.js для каждого символа предоставляет параметр yMax.
Помимо абсолютного измерения х-высоты может понадобиться сравнить х-высоту и с высотой выступающих надстрочных элементов. То есть получить значения вроде «х-высота составляет 60 % прописных букв».
Чтобы полученные значения можно было использовать для сравнения (в одних шрифтах используется 1000 юнитов на Em (типографская единица измерения), в других 2048), необходимо нормализовать их и сопоставить с диапазоном от 0 до 1.
Ширина / Пропорция
С помощью этого значения можно оценить плотность шрифта. Насколько он плотный, сжатый, или напротив, растянутый, свободный? Можно было бы, к примеру, измерять ширину буквы «М» в разных шрифтах, но тогда пришлось бы учитывать и общий размер или х-высоту. К тому же в некоторых шрифтах «М» весьма специфична и не характерна для всего остального набора символов.
Ещё можно вычислять среднюю ширину символа на основе эталонного слова вроде “Hamburgefontsiv”. Это неплохой вариант, но всё равно понадобится делать нормализацию с учётом общего дизайна и высоты шрифта.
Другой подход заключается в определении пропорции буквы «о». Это даёт нам на удивление хорошие значения, по которым можно сравнивать ширины разных гарнитур.

Для измерения веса можно вывести на HTML-странице строчную «о», залить её чёрным, а фон — белым. Затем вычислить отношение чёрных и белых пикселей. У рукописного или очень тонкого шрифта это значение будет совсем маленьким, а у тяжёлого, громоздкого шрифта отношение будет большим. Результаты вполне удовлетворительные, но их можно ещё больше улучшить, измеряя полную ширину символов.

Расстояние
Если у всех символов шрифта одинаковая ширина, такой шрифт называют моноширинным (monospaced). Важно отметить, что для определения ширины нам не обязательно смотреть на сами символы. Даже в моноширинном шрифте символ точки визуально занимает меньше места, чем «м». Поэтому нужно учитывать свойство advanceWidth, описывающее невидимые поля вокруг символа. Удивительно, но Google Fonts использует термин monospaced в качестве определения стиля, а не технического свойства. Шрифты вроде Lekton или Libre Barcode вообще не отнесены к моноширинным, хотя технически они ими являются.
Схожесть
Получив таблицу значений, можем нормализовать их и вычислить расстояния, чтобы оценить схожесть шрифтов. Здесь приведена самая простая версия расчёта, но результат будет лучше, если повысить точность данных. Кроме того, человек может оценивать схожесть шрифтов не так, как алгоритм, для которого все характеристики одинаковы. В этом случае мы должны учитывать некоторые свойства в большей степени, чем другие.
Парсер анализирует каждый шрифт, рисует невидимые SVG и фоновые элементы, проводит измерения и сохраняет данные в JSON-файл.
Для доступа к базе данных написан интерфейс. Шрифты можно просматривать в виде сетки с ячейкой разного размера, чтобы охватить взглядом сразу много шрифтов или подробнее оценить некоторые из них.
Шрифты можно сортировать по весу, х-высоте, контрасту, ширине, названию и количеству стилей. Диаграммы показывают распределение значений и могут использоваться для отфильтровывания определённых значений. Для каждого шрифта есть подробное отображение с несколькими примерами, символами, метриками, Panose-данными и перечислением схожих шрифтов.
Почему-то некоторые шрифты не загружаются в Safari, так что рекомендую использовать Chrome.
Открытия
Вы можете сами исследовать датасет в поисках схожестей и несоответствий. Если задать низкий контраст и наличие засечек, то программа выдаст все брусковые шрифты. Если задать низкую х-высоту, то выдача будет состоять по большей части из рукописных шрифтов. Очень высокие значения обычно характерны для шрифтов, состоящих исключительно из прописных букв.
Изгои
При выборе крайних значений обычно «вылезают» очень странные шрифты. Как правило, они относятся к категории экранных шрифтов.
Неприятные различия
Просмотр в виде сетки выявляет ужасные различия между базовыми линиями и выравниваниями. Некоторые шрифты категорически не вписываются в сетку. И даже если различия невелики, становится очевидно, что простая замена шрифтов в проекте вряд ли возможна, если не считать нескольких популярных шрифтов с очень похожим строением.
Золотая середина
Любопытно, что часто используемые шрифты, считающиеся хорошими, программа помещает в список схожих друг с другом. Если подстроить фильтры, то можно уменьшить список примерно вдвое, но все популярные шрифты останутся. Так что если вам нужно отфильтровать странные и экстремальные шрифты, просто выбирайте средние значения.
«Форкнутые» шрифты
Есть шрифты, которые называются по-разному, но выглядят совершенно одинаково. Некоторые из них являются форками с расширенным набором символов для поддержки разных языков, например, Alegreya & Sahitya.
Количество стилей
Количество стилей шрифта — хороший индикатор его качества. На горизонте уже маячат переменные шрифты, и вполне возможно, что будущее за бесконечной кастомизацией. Но до тех пор рекомендуется работать со шрифтами, относящимися к нескольким стилям. Так что сортировка коллекции по количеству стилей — хороший способ узнать о лучших имеющихся шрифтах.
Итоги
Это довольно сложный подход к поиску шрифтов. В целом результаты поиска зависят от качества шрифтов и сопутствующих данных. Если вы пользуетесь только Google Fonts, то сильно ограничиваете себя, поскольку там представлены не лучшие в своём классе шрифты. При анализе содержимого Typekit выяснилось, что у интерфейса возникают проблемы с производительностью при работе с таким количеством шрифтов. Нужно использовать кэширование и предварительную загрузку, но до этого пока не дошли руки.
Вы можете получить хорошее представление о содержимом шрифтовых файлов и недостающих данных безо всяких нейросетей. Чем больше этим занимаешься, тем явственней осознаёшь масштабы шрифтовой истории и стоящей на её плечах индустрии.
Возможности
Что можно сделать с этим датасетом:
- Найти запасные шрифты аналогичной ширины или стиля.
- На основе х-высоты автоматически настроить размеры шрифтов и высоты строк.
- Найти комбинации шрифтов, опираясь на их сходства или различия.
- Создать собственное меню выбора шрифтов для дизайнера постера фильма Avatar.
- …
Дополнительные материалы
Panose Classification Metrics Guide
Руководство 1991 года, подробно описывающее, как измерять отдельные символы, чтобы получать подходящие для сравнения метрики. К сожалению, эти измерения надо делать вручную, что потребует много времени.
Taking The Robots To Design School, Part 1 by Jon Gold
В мае 2016 Джон Голд (Jon Gold) написал о своём подходе к анализу шрифтов. Он затронул такие темы, как дизайн на основе правил (rule based design), ИИ и соответствие датасетов инструментам дизайнеров.
Google Fonts Tools
Набор open source-инструментов для анализа шрифтов на сайте Google Fonts. Например, для определения угла наклона шрифта.
Font Bakery
Это набор Python-инструментов для проверки TrueType-файлов и файлов метаданных для шрифтов с Google Fonts.
Почему просто не использовать данные из сервисов веб-шрифтов?
Все подобные сервисы — например, Typekit, Google Fonts, Fontstand, Fontshop, MyFonts и так далее — имеют собственные наборы фильтров с разной степенью настройки. API этих сервисов по каждому шрифту предоставляют разный объём информации.
API Typekit предоставляет ещё ширину, х-высоту, вес, классификацию, контраст, заглавные буквы и рекомендации.
Тебе известно, что компьютер работает только с двоичным кодом. \(0\) и \(1\) обозначают два устойчивых состояния: вкл/выкл, есть ток/нет тока и т. д. Оперативная память представляет собой контейнер, который состоит из ячеек. В каждой ячейке хранится одно из возможных состояний: \(0\) или \(1\). Одна ячейка — \(1\) бит информации или представляет собой разряд некоторого числа.
Целые числа в памяти компьютера хранятся в формате с фиксированной запятой . Такие числа могут храниться в \(8\), \(16\), \(32\), \(64\)-разрядном формате.
Для целых неотрицательных чисел в памяти компьютера выделяется \(8\) ячеек (бит) памяти.
Минимальное число для такого формата: \(00000000\). Максимальное: \(11111111\).
Переведём двоичный код в десятичную систему счисления и узнаем самое большое число, которое можно сохранить в восьмибитном формате.
1 × 2 7 + 1 × 2 6 + 1 × 2 5 + 1 × 2 4 + 1 × 2 3 + 1 × 2 2 + 1 × 2 1 + 1 × 2 0 = 255 10 .
Если целое неотрицательное число больше \(255\), то оно будет храниться в \(16\)-разрядном формате и занимать \(2\) байта памяти, то есть \(16\) бит.
Подумай! Какое самое большое число можно записать в \(16\)-разрядном формате?
Чем больше ячеек памяти отводится под хранение числа, тем больше диапазон значений.
В таблице указаны диапазоны значений для \(8\), \(16\) и \(32\)-разрядных форматов.

Для \(n\)-разрядного представления диапазон чисел можно вычислить следующим образом: от \(0\) до 2 n − 1 .
Запишем целое беззнаковое число \(65\) в восьмиразрядном представлении. Достаточно перевести это число в двоичный код.
Это же число можно записать и в \(16\)-разрядном формате.
![]()
Для целых чисел со знаком в памяти отводится \(2\) байта информации (\(16\) бит). Старший разряд отводится под знак: \(0\) — положительное число; \(1\) — отрицательное число. Такое представление числа называется прямым кодом.

Для хранения отрицательных чисел используют дополнительный и обратный коды, которые упрощают работу процессора. Но об этом ты узнаешь в старших классах.
Таблица символов относится к служебным программам Windows, то есть, она бесплатная и входит в состав операционной системы Windows. С ее помощью можно найти символы, которых нет на клавиатуре, скопировать их в память компьютера и затем вставить в какое-либо приложение.
Эта таблица есть во всех версиях Windows: 10, 8, 7, Vista, XP. И работает она везде одинаково. Подробно для Windows 7 описано в этой статье.
Как найти Таблицу символов на своем устройстве
Это можно сделать одним из трех вариантов, предложенных ниже:
2) Либо в главном меню: Пуск — Программы — Стандартные — Служебные — Таблица символов.
3) Третий вариант для того, чтобы найти таблицу символов. Используем горячие клавиши, то есть:
Таблица символов дает возможность посмотреть все символы, которые входят в какой-либо шрифт. Рассмотрим это на конкретном примере.
Таблица символов Windows для шрифта Times New Roman
Для наглядности эта таблица представлена ниже на рисунке:
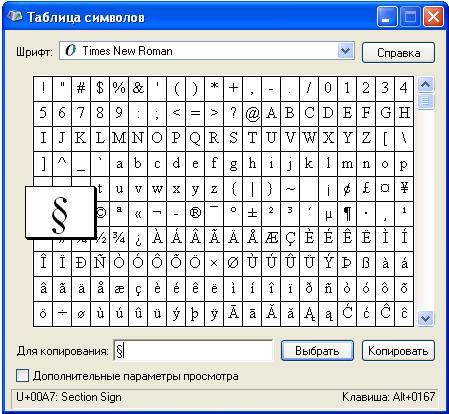
Порядок расположения символов в Таблице символов такой:
- сначала идут знаки препинания,
- затем цифры,
- английские буквы,
- далее языковые.
- И только после всего этого идут символы, которые отсутствуют на клавиатуре, такие как: ⅜, ∆, ™, ₤ и так далее.
Как скопировать символ из Таблицы символов и поместить его туда, где требуется?
Предлагаю для этого два способа:
- Скопировал (в Таблице символов) — Вставил (там, где требуется).
- С помощью сочетания клавиш (то есть, используя горячие клавиши).
Первый способ: Скопировал в Таблице — Вставил там, где нужно.
Мы копируем (не скачиваем, а именно копируем) символ в Таблице символов для того, чтобы временно поместить его в память компьютера (или аналогичного устройства). Такая временная память называется буфер обмена.
Такой буфер нужен для того, чтобы временно туда поместить символ, а потом вставить его из буфера туда, где мы хотим видеть этот символ. Таким образом, символ не скачивается на диск компьютера, а временно помещается в оперативную память компьютера, то есть, в буфер обмена. А из этого буфера пользователь может вставить символ туда, где потребуется.
Разберем на конкретном примере, как можно символ из Таблицы закинуть в буфер обмена, а потом достать его оттуда и разместить туда, где это необходимо.
Чтобы скопировать символ в память компьютера, нам надо его выделить . Для этого достаточно кликнуть по необходимому символу (цифра 1 на рис. 2).
Затем щелкаем по кнопке «Выбрать» (2 на рис. 2):
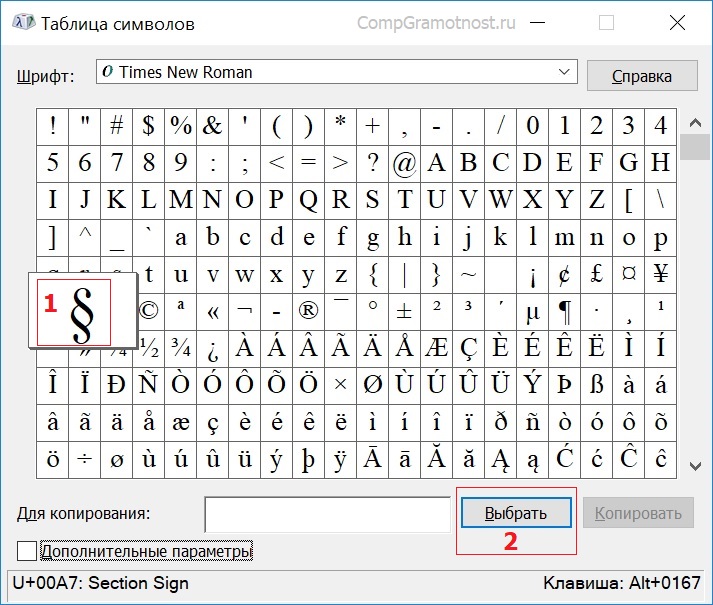
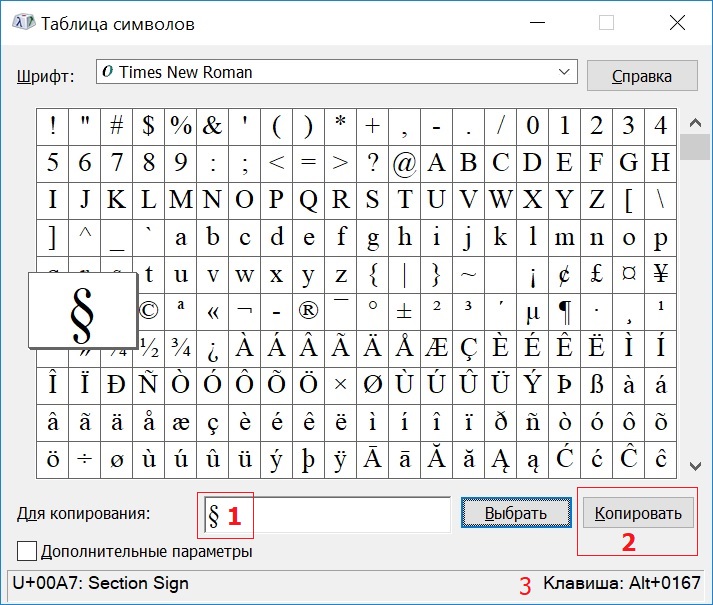
Рис. 3. Копируем символ из Таблицы в буфер обмена
Есть и быстрый вариант:
По символу кликнуть два раза мышкой и он будет скопирован в буфер обмена.
После этого остается перейти в соответствующее приложение (или в текстовый редактор) и вставить скопированный символ из буфера обмена.
Второй способ: копируем символ с помощью сочетания клавиш
Для каждого символа в Таблице имеется строго свое сочетание клавиш.
Справа в таблице символов Windows (3 на рис. 3) Вы можете увидеть, какую комбинацию клавиш нужно нажать, чтобы вставить выбранный символ в нужном Вам приложении.
Например, для знака параграфа § следует нажать сочетание клавиш Alt+0167, при этом можно использовать только цифры с малой цифровой клавиатуры.
Более подробно о том, как на практике проверить кодировку символов, используя малую цифровую клавиатуру, можно узнать ЗДЕСЬ. Такой способ ввода символов, которых нет на клавиатуре, требует определенных навыков и, думаю, что редко используется обычными пользователями.
Упражнение по компьютерной грамотности:
1) Откройте Таблицу символов Windows. Выберите шрифт, которым Вы чаще всего пользуетесь. Найдите два-три символа, которых нет на клавиатуре, выделите и скопируйте их в буфер обмена.
2) Откройте текстовый редактор (например, Блокнот) и вставьте из буфера обмена скопированные туда ранее символы.
Читайте также: