
Re search python 3 что возвращает
Модуль re предоставляет операции сопоставления шаблонов регулярных выражений, аналогичные тем, которые встречаются в языке Perl .
Важно отметить, что большинство операций с регулярными выражениями доступны как функции и методы уровня модуля для скомпилированных регулярных выражений. Функции модуля re не требуют, чтобы вы сначала компилировали объект регулярного выражения, но не допускают некоторые параметры тонкой настройки шаблона для поиска регулярного выражения.
Синтаксис регулярных выражений в Python.
Функция compile() модуля re в Python.
Функция `compile()` модуля `re` компилирует шаблон регулярного выражения `pattern` в объект регулярного выражения, который может быть использован для поиска совпадений
Флаги, используемые для компиляции регулярного выражения.
Функция search() модуля re в Python.
Функция `search()` модуля `re` сканирует строку `string` в поисках первого совпадения с шаблоном `pattern` регулярного выражения и возвращает соответствующий объект соответствия
Функция match() модуля re в Python.
Функция match() модуля re вернуть соответствующий объект сопоставления, если ноль или более символов в начале строки string соответствуют шаблону регулярного выражения pattern.
Функция fullmatch() модуля re в Python.
Функция `fullmatch()` модуля `re` вернет объект сопоставления, если вся строка `string` соответствует шаблону регулярного выражения `pattern`.
Функция finditer() модуля re в Python.
Функция `finditer()` модуля `re` возвращает итератор объектов сопоставления по всем неперекрывающимся совпадениям для шаблона регулярного выражения в строке.
Функция split() модуля re в Python.
Функция `split()` модуля `re` делит строку по появлению шаблона регулярного выражения `pattern` и возвращает список получившихся подстрок.
Функция findall() модуля re в Python.
Функция `findall()` модуля `re` возвращает все неперекрывающиеся совпадения шаблона `pattern` в строке `string` в виде списка строк. Строка сканируется слева направо, и совпадения возвращаются в найденном порядке.
Функция sub() модуля re в Python.
Функция `sub()` модуля `re` возвращает строку, полученную путем замены крайнего левого неперекрывающегося вхождения шаблона регулярного выражения `pattern` в строке `string` на строку замены `repl`. Если шаблон регулярного выражения не найден, строка возвращается без изменений.
Функция subn() модуля re в Python.
Функция subn() модуля re выполняет ту же операцию, что и функция sub(), но возвращает кортеж (new_string, number_of_subs_made)
Функция escape() модуля re в Python.
Функция `escape()` модуля `re` выполняет экранирование специальных символов в шаблоне. Это полезно, если требуется сопоставить произвольную строку литерала, которая может содержать метасимволы регулярных выражений
Функция purge() модуля re в Python.
Функция `purge()` модуля `re` очищает кэш от регулярных выражений.
Исключение error() модуля re в Python.
Исключение `error()` модуля `re` возникает, когда строка, переданная одной из функций модуля, не является допустимым регулярным выражением, например шаблон может содержать несоответствующие скобки или когда возникает какая-либо другая ошибка во время компиляции шаблона или сопоставления со строкой.
Объект регулярного выражения Pattern модуля re в Python.
Объект регулярного выражения Pattern получается в результате компиляции шаблона регулярного выражения. Скомпилированные объекты регулярных выражений поддерживают рассмотренные ниже методы и атрибуты.
Объект сопоставления с шаблоном Match модуля re в Python.
Объект сопоставления регулярного выражения со строкой всегда имеет логическое значение True. Можно проверить, было ли совпадение, с помощью простого утверждения if. else. Объекты сопоставления поддерживают методы и атрибуты.
Ответы
\b находится слева от ‘B’, значит слово должно начинаться на ‘B’.
Добавьте flags=re.IGNORECASE , что бы шаблон был не чувствительным к регистру.
Надеемся, информация была вам полезна. Стояла цель — познакомить вас с примерами регулярных выражений легким и доступным для запоминания способом.
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон 3+ указывает на соответствие всем числам от 0 до 9. Добавление символа + в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть 5 .
Для кода курса, как вы могли догадаться, [А-ЯЁ] будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).
Для названий курса, [а-яА-ЯёЁ] будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.
Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().
Обратите внимание на шаблон номера курса: 8+ , код: [А-ЯЁ] и название: [а-яА-ЯёЁ] они все помещены в круглую скобку (), для формирования группы.
Примеры регулярных выражений
Любой символ кроме новой строки
Точки в строке
Любая цифра
Все, кроме цифры
Любая буква или цифра
Все, кроме букв и цифр
Только буквы
Соответствие заданное количество раз
1 и более вхождений
Любое количество вхождений (0 или более раз)
0 или 1 вхождение
Граница слова
Границы слов \b обычно используются для обнаружения и сопоставления началу или концу слова. То есть, одна сторона является символом слова, а другая сторона является пробелом и наоборот.
Функции модуля Re
Модуль re предлагает набор функций, которые позволяют нам искать строку на предмет соответствия:
| Функции | Значение |
|---|---|
| findall | Возвращает список со всеми совпадениями |
| search | Возвращает объект Match, если в строке есть совпадение |
| split | Возвращает список, из строки, которую разделили по шаблону |
| sub | Заменяет совпадение по шаблону, на заданную строку |
Метод Sub
Одним из наиболее важных методов модуля re, которые используют регулярные выражения, является re.sub .
Пример синтаксиса sub:
Этот метод заменяет все вхождения pattern в string на repl , если не указано на max . Он возвращает измененную строку.
Пример
Запускаем скрипт и получаем вывод:
Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
В приведенном выше коде специальный символ \ d является регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах.
Добавление к нему символа + означает наличие по крайней мере 1 числа.
Подобно + , есть символ * , для которого требуется 0 или более чисел. Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.
В итоге, метод findall извлекает все вхождения 1 или более номеров из текста и возвращает их в список.
re.search() против re.match()
Как понятно из названия, regex.search() ищет шаблоны в заданном тексте.
Но, в отличие от findall , который возвращает согласованные части текста в виде списка, regex.search() возвращает конкретный объект соответствия. Он содержит первый и последний индекс первого соответствия шаблону.
Аналогично, regex.match() также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.
В качестве альтернативы вы можете получить тот же результат, используя метод group() для объекта соответствия.
Комбинации
Комбинации — это набор символов внутри пары квадратных скобок [] со специальным значением:
| Комбинации | Значение |
|---|---|
| [arn] | Возвращает совпадение, в котором присутствует один из указанных символов (a, r или n) |
| [a-n] | Возвращает совпадение для с символом нижнего регистра в алфавитном порядке между a и n, включая их |
| [^arn] | Возвращает совпадение для любого символа, КРОМЕ а, r и n |
| [0123] | Возвращает совпадение, в котором присутствует любая из указанных цифр (0, 1, 2 или 3) |
| 3 | Возвращает совпадение с любой цифрой от 0 до 9 |
| 23 | Возвращает совпадение с любыми двузначными числами от 0 до 59 |
| [a-zA-Z] | Возвращает совпадение с любым символом английского алфавита между a и z, включая строчные буквы и прописные |
| [а-яА-ЯёЁ] | Возвращает совпадение с любым символом русского алфавита между а и я, включая строчные буквы и прописные |
| [+] | В комбинациях символы +, *, ., |, (), $,<> не имеют особенного значения, поэтому [+]: будет искать любой + в строке |
Функция findall()
Функция findall() возвращает список, содержащий все совпадения.
Список содержит совпадения в порядке их поиска. Если совпадений не найдено, возвращается пустой список.
Модуль Re для регулярных выражений в Python
Регулярные выражения — специальная последовательность символов, которая помогает сопоставлять или находить строки python с использованием специализированного синтаксиса, содержащегося в шаблоне. Регулярные выражения распространены в мире UNIX.
Модуль re предоставляет полную поддержку выражениям, подобным Perl в Python. Модуль re поднимает исключение re.error , если возникает ошибка при компиляции или использовании регулярного выражения.
Давайте рассмотрим две функции, которые будут использоваться для обработки регулярных выражений. Важно так же заметить, что существуют символы, которые меняют свое значение, когда используются в регулярном выражении.Чтобы избежать путаницы при работе с регулярными выражениями, записывайте строку как r'expression' .
Функция search
Эта функция выполняет поиск первого вхождения pattern внутри string с дополнительным flags .
Пример синтаксиса для этой функции:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения |
| 2 | string — строка, в которой мы будем искать первое соответствие с шаблоном |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.search возвращает объект match если совпадение найдено, и None , когда нет совпадений. Используйте функцию group(num) или groups() объекта match для получения результата функции.
| № | Способы совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — метод, который возвращает полное совпадение (или же совпадение конкретной подгруппы) |
| 2 | groups() — метод возвращает все сопоставимые подгруппы в tuple |
Пример функции re.search
Запускаем скрипт и получаем следующий результат:
Как разбить строку, разделенную регулярным выражением?
Рассмотрим следующий фрагмент текста.
У меня есть три курса в формате “[Номер курса] [Код курса] [Название курса]”. Интервал между словами разный.
Передо мной стоит задача разбить эти три предмета курса на отдельные единицы чисел и слов. Как это сделать?
Их можно разбить двумя способами:
- Используя метод re.split .
- Вызвав метод split для объекта regex .
Оба эти метода работают. Но какой же следует использовать на практике?
Если вы намерены использовать определенный шаблон несколько раз, вам лучше скомпилировать регулярное выражение, а не использовать re.split множество раз.
Специальные пары символов
Специальная пара символов представляет собой \ , за которым следует один из символов в списке ниже, и имеет специальное значение:
Функция match
Эта функция ищет pattern в string и поддерживает настройки с помощью дополнительного flags .
Ниже можно увидеть синтаксис данной функции:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения ( r'g.le' ) |
| 2 | string — строка, в которой мы будем искать соответствие с шаблоном в начале строки ( 'google' ) |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.match возвращает объект match при успешном завершении, или None при ошибке. Мы используем функцию group(num) или groups() объекта match для получения результатов поиска.
| № | Метод совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — этот метод возвращает полное совпадение (или совпадение конкретной подгруппы) |
| 2 | groups() — этот метод возвращает все найденные подгруппы в tuple |
Пример функции re.match
Когда вышеуказанный код выполняется, он производит следующий результат:
Практические упражнения
1. Извлеките никнейм пользователя, имя домена и суффикс из данных email адресов.
2. Извлеките все слова, начинающиеся с ‘b’ или ‘B’ из данного текста.
3. Уберите все символы пунктуации из предложения
Примеры применения регулярных выражений в Python
Регулярные выражения, также называемые regex, синтаксис или, скорее, язык для поиска, извлечения и работы с определенными текстовыми шаблонами большего текста. Он широко используется в проектах, которые включают проверку текста, NLP (Обработка естественного языка) и интеллектуальную обработку текста.
Как заменить один текст на другой, используя регулярные выражения?
Для изменения текста, используйте regex.sub() .
Рассмотрим следующую измененную версию текста курсов. Здесь добавлена табуляция после каждого кода курса.
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Для этого нужно просто использовать regex.sub для замены шаблона \s+ на один пробел .
Предположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Это можно сделать, используя отрицательное соответствие (?!\n) . Шаблон проверяет наличие символа новой строки, в python это \n , и пропускает его.
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
| . | Один символ кроме новой строки |
| \. | Просто точка . , обратный слеш \ убирает магию всех специальных символов. |
| \d | Одна цифра |
| \D | Один символ кроме цифры |
| \w | Один буквенный символ, включая цифры |
| \W | Один символ кроме буквы и цифры |
| \s | Один пробельный (включая таб и перенос строки) |
| \S | Один не пробельный символ |
| \b | Границы слова |
| \n | Новая строка |
| \t | Табуляция |
Модификаторы
| $ | Конец строки |
| ^ | Начало строки |
| ab|cd | Соответствует ab или de. |
| [ab-d] | Один символ: a, b, c, d |
| [^ab-d] | Любой символ, кроме: a, b, c, d |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| [ab] | 2 непрерывных появления a или b |
| [ab] | от 2 до 5 непрерывных появления a или b |
| [ab] | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
Объект Match
Объект Match — это объект, содержащий информацию о поиске и результат.
Примечание: Если совпадений нет, будет возвращено None вместо объекта Match.
Выполним поиск, который вернет объект Match.
У объекта Match есть свойства и методы, используемые для получения информации о поиске и результате:
.span() возвращает кортеж, содержащий начальную и конечную позиции совпадения.
.string возвращает строку, переданную в функцию.
.group() возвращает часть строки, где было совпадение
Выведем позицию (начальную и конечную) первого совпадения.
Выведем строку, переданную в функцию.
Выведем часть строки, где было совпадение.
Примечание: Если совпадений нет, будет возвращено None вместо объекта Match.
Углубиться в тему регулярных выражений можно помощью наше подборки документаций и примеров: Регулярные выражения
Метасимволы
Метасимволы — это символы с особым значением:
| Символ | Значение | Пример |
|---|---|---|
| [] | Содержит символы для поиска вхождений | [a-m] |
| \ | Сигнализирует о специальном символе (также может использоваться для экранирования специальных символов) | \d |
| . | Любой символ, кроме новой строки (\n) | “he…o” |
| ^ | Строка начинается с | “^hello” |
| $ | Строка заканчивается | “world$” |
| * | 0 и более вхождений | “aix*” |
| + | 1 и более вхождений | “aix+” |
| <> | Указанное количество вхождений | “al” |
| | | Или | “falls|stays” |
| () | Группирует шаблон |
Что такое шаблон регулярного выражения и как его скомпилировать?
Шаблон регулярного выражения представляет собой специальный язык, используемый для представления общего текста, цифр или символов, извлечения текстов, соответствующих этому шаблону.
Основным примером является \s+ .
Здесь \ s соответствует любому символу пробела. Добавив в конце оператор + , шаблон будет иметь не менее 1 или более пробелов. Этот шаблон будет соответствовать даже символам tab \t .
В конце этой статьи вы найдете больший список шаблонов регулярных выражений. Но прежде чем дойти до этого, давайте посмотрим, как компилировать и работать с регулярными выражениями.
Вышеупомянутый код импортирует модуль re и компилирует шаблон регулярного выражения, который соответствует хотя бы одному или нескольким символам пробела.
Шаблоны регулярных выражений
За исключением символов (+?. * ^ $ () [] <> | ), все остальные соответствуют самим себе. Вы можете избежать экранировать специальный символ с помощью бэкслеша ( / ).
В таблицах ниже описаны все символы и комбинации символов для регулярных выражений, которые доступны в Python:
Match и Search
Python предлагает две разные примитивные операции, основанные на регулярных выражениях: match выполняет поиск паттерна в начале строки, тогда как search выполняет поиск по всей строке.
Пример разницы re.match и re.search
Когда этот код выполняется, он производит следующий результат:
№24 Регулярные выражения в Python / Уроки по Python для начинающих
RegEx, или регулярное выражение, представляет собой последовательность символов, которая формирует шаблон поиска.
Регулярные выражения используют, чтобы проверить, содержит ли строка указанный шаблон поиска.
Модуль Re
В Python есть встроенный модуль re , который можно использовать для работы с регулярными выражениями.
Введение в регулярные выражения
Регулярные выражения, также называемые regex, используются практически во всех языках программирования. В python они реализованы в стандартном модуле re .
Он широко используется в естественной обработке языка, веб-приложениях, требующих проверки ввода текста (например, адреса электронной почты) и почти во всех проектах в области анализа данных, которые включают в себя интеллектуальную обработку текста.
Эта статья разделена на 2 части.
Прежде чем перейти к синтаксису регулярных выражений, для начала вам лучше понять, как работает модуль re .
Итак, сначала вы познакомитесь с 5 основными функциями модуля re , а затем посмотрите, как создавать регулярные выражения в python.
Узнаете, как построить практически любой текстовый шаблон, который вам, скорее всего, понадобится при работе над проектами, связанными с поиском текста.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя . )
Для того, чтобы в конечный результат не попал пробел, используем вместо . \w .
Теперь попробуем достать каждое слово (используя * или + )
И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем + :
Теперь вытащим первое слово, используя ^ :
Если мы используем $ вместо ^ , то мы получим последнее слово, а не первое:
Вернуть первые два символа каждого слова
Вариант 1: используя \w , вытащить два последовательных символа, кроме пробельных, из каждого слова:
Вариант 2: вытащить два последовательных символа, используя символ границы слова ( \b ):
Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ) :
Извлечь дату из строки
Используем \d для извлечения цифр.
Для извлечения только года нам опять помогут скобки:
Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
А теперь — только те, которые начинаются на определенные буквы (используя [] ):
Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем \b для обозначения границы слова:
Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
Разбить строку по нескольким разделителям
Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
Извлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между <td> и </td> , кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.
Пример содержимого html-файла:
С помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str ):
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Python RegEx: практическое применение регулярок
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
RegEx в Python
Найдем строку, чтобы увидеть, начинается ли она с «The» и заканчивается «Spain»:
Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
С другой стороны, ленивое соответствие “берет как можно меньше”. Это можно задать добавлением ? в конец шаблона.
Если вы хотите получить только первое совпадение, используйте вместо этого метод поиска search .
Основы регулярных выражений
Регулярками называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
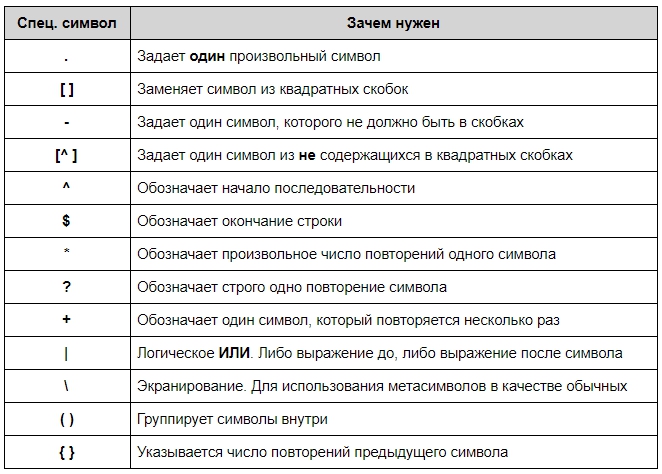
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
- \d — соответствует любой одной цифре и заменяет собой выражение 2;
- \D — исключает все цифры и заменяет [^0-9];
- \w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- \W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- \s — соответствует любому пробельному символу;
- \S — описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
15 октября в 17:00, Онлайн, Беcплатно
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
Регулярные выражения в Python
В Python для работы с регулярками есть модуль re . Его нужно просто импортировать:
А вот наиболее популярные методы, которые предоставляет модуль:
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
Теперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None :
Также есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match() , но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
Метод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall() , так как он может работать и как re.search() , и как re.match() .
re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки \n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра 7 (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
| [..] | Один из символов в скобках ([^..] — любой символ, кроме тех, что в скобках) |
| \ | Экранирование специальных символов (\. означает точку или \+ — знак «плюс») |
| ^ и $ | Начало и конец строки соответственно |
| От n до m вхождений ( — от 0 до m) | |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Функция sub()
Функция sub() заменяет совпадение указанным текстом.
Заменим каждый символ пробела цифрой 9.
Вы можете контролировать количество замен, указав параметр count .
Функция split()
Функция split() возвращает список, в котором строка разбита по шаблону.
Вы можете контролировать количество разбитий, указав параметр maxsplit .
Модификаторы регулярных выражений: flags
Функции регулярных выражений включают необязательный модификатор для управления изменения условий поиска. Модификаторы задают в необязательном параметре flags . Несколько модификаторов задают с помощью побитового ИЛИ ( | ), как показано в примерах выше.
Функция search()
Функция search() ищет в строке совпадение и возвращает обьект Match, если оно найдено. Если найдено более одного совпадения, будет возвращено только первое совпадение.
Найдем первый символ пробела в строке:
Если совпадений не найдено, возвращается None .
Читайте также: