
Oracle сколько записей обновил update
На рынке есть несколько генераторов приложений, поддерживающих базовый подход к разработке "чем проще, тем лучше". Простой код легче генерировать и проще сопровождать, даже если он кажется несколько менее эффективным. Но если генератор форм всегда генерирует код для обновления каждого столбца в таблице, даже если пользователь меняет всего лишь одно поле в форме, насколько при этом растет нагрузка на сервер базы данных?
Краткая история генераторов форм
Было время, когда в SQL*Forms (так его тогда называли) было принято использовать единственный SQL-оператор обновления для блока. Этот оператор update обновлял (по значению rowid ) каждый столбец таблицы, упоминающийся в блоке. Это казалось неплохой идеей, поскольку упрощало код и делало его более эффективным на клиенте: не нужно было решать вычислительно сложную задачу определения действиетльно измененных полей и динамически формировать SQL-оператор для обновления только соответствующих столбцов в базе данных.
Потом, в районе версии Forms 4.5 (я могу ошибаться с версией - жду поправок), корпорация Oracle добавила флаг, который можно устанавливать для выбора либо одного оператора, "обновляющего все", либо динамически генерируемого оператора "обновлять только минимальный набор столбцов". Какая из этих опций лучше?
Сколько стоит обновить столбец?
В частности, нас будет интересовать, сколько стоит обновление столбца, если его значение не меняется. Если бы сервер мог выявить, что при обновлении реально ничего не меняется, то дополнительные расходы ресурсов на лишнее обновление были бы минимальны. К сожалению, сервер и не пытается выявлять "лишние" обновления. В конечном итоге, логично предполагать, что при обновлении данные должны меняться. Было бы контрпродуктивно добавлять проверку условия, которое почти всегда будет истинным, просто чтобы немного сэкономить в тем "весьма редких и странных" случаях, когда при обновлении изменения не происходят.
Итак, что же может произойти при обновлении одного столбца в таблице в отдельной транзакции? Понятно, что строку надо заблокировать и данные изменить, а для этого - получить запись списка заинтересованных транзакций (Interested Transaction List - ITL) в блоке. Необходимо захватить слот таблицы транзакций (transaction table slot) в заголовке сегмента отмены ( undo segment header ) для использования в качестве глобально видимой "ссылки" на транзакцию, а также внести запись отмены в блок отмены, описывающую, как отменить изменения, только что выполненные в блоке данных. Изменения во всех трех блоках необходимо записать в журнал повторного выполнения (первоначально - в буфер журнала), и в этом простом случае потребуется только одна запись повторного выполнения (redo record).
Затем, при фиксации транзакции в слоте таблицы транзакций записывается соответствующее значение номера системного изменения ( commit SCN ) и он помечается как свободный, а адрес использованного блока отмены тоже можно записать в пул свободных блоков в блоке заголовка сегмента отмены. Эти изменения в блоке заголовка сегмента отмены записываются в журнал повторного выполнения (в буфер), а для сброса буфера журнала на диск вызывается процесс записи журнала (log writer process - lgwr ), после чего пользовательский процесс уведомляют, что транзакция успешно зафиксирована. (Oracle может, а в этом случае, скорее всего, и будет также очищать измененный блок данных, но не будет записывать выполненные при очистке изменения в журнал повторного выполнения).
Предположим, пользователь изменил на экране всего одно поле - представленное выше описание дает понять, какой объем работы придется выполнить серверу, чтобы реализовать это изменение. Но что, если генератор форм обновил всю строку - какие дополнительные расходы ресурсов при этом возникают?
Затраты на получение записи ITL, блокирование и обновление строки, вероятно, не сильно изменятся, а затраты на получение блока заголовка сегмента отмены вообще не изменятся.
Но вот объем данных в записи отмены, вероятно, возрастет существенно - вместо дополнительных примерно 100 байт плюс старая версия одного столбца мы получим дополнительные байты плюс старая версия всех столбцов. Вероятно, это не так уж важно, - в конечном итоге, сервер Oracle пишет блоки, а не записи, - но если записи отмены в результате выросли по размеру в четыре раза, придется записывать в четыре раза больше блоков отмены.
Аналогично, существенно изменится и запись повторного выполнения. В идеале, запись повторного выполнения будет для этого изменения длиной около 200 байтов (плюс еще 200, связанных с с блоком заголовка сегмента и вектором аудита транзакции). Эта запись, вероятно, будет дополнена до 512 байтов (типичный минимальный размер блока ОС) всяким мусором при фиксации транзакции. Но основная запись повторного выполнения состоит, по сути, из двух векторов изменений - вектора для блока таблицы и вектора для записи отмены, - и оба они увеличатся в размере, потому что запись отмены будет включать старую версию всех столбцов, а запись повторного выполнения для таблицы - новую версию всех столбцов. Поэтому объем генерируемых данных повторного выполнения увеличивается в два-четыре раза, а во многих интенсивно загруженных системах скорость сброса данных повторного выполнения на диск часто является критической проблемой производительности.
Но это еще не все
Дополнительный объем данных отмены и повторного выполнения - это еще не обязательно самая большая проблема - в конечном итоге, дополнительно генерируемые и буферизуемые данные зачастую не так уж велики по сравнению с базовыми накладными расходами. Более того, поскольку архитектура сервера Oracle такова, что записи на диск, по возможности, выполняются фоновыми "асинхронными" процессами, конечный пользователь не часто ощущает замедление из-за записи на диск. Но есть еще ряд нюансов, непосредственно влияющих на производительность системы с точки зрения конечных пользователей.
Как вы думаете, что делает сервер при обновлении столбца без реального изменения со следующими объектами:
Срабатывают ли строчные триггеры типа ' update of < список_столбцов >'? before row
after row
instead of Изменяются ли индексы, включающие такой столбец? Что, если это индексы на основе B*-дерева?
А как насчет индексов на основе битовых карт?
Что будет с индексами по функции (function-based indexes)? Как сервер будет обеспечивать целостность ссылок? Если этот столбец - подчиненный?
Если этот столбец - главный?
Триггеры
Создадим простую таблицу с триггером и выполним действия, представленные ниже в листинге 1:
Триггер срабатывает. То же самое происходит и с триггером after-row update . Подтверждение моего предположения, что сработает и триггер instead of оставляю читателю в качестве упражнения.
Фактически, строчный триггер before генерирует одну дополнительную запись отмены и одну дополнительную запись повторного выполнения, даже если ничего при этом не делает из-за добавления достаточно сложной конструкции when , которая в примере закомментирована. Так что, если есть выбор, немного эффективнее будет использовать строчные триггеры after .
Индексы
Некоторые эксперименты с индексами должны быть более продуманными, поскольку для оценки всех затрат может иметь смысл учитывать логический ввод/вывод, а для этого - построить достаточно большую таблицу, чтобы индекс по ней был многоуровневым. Однако для некоторых тестов достаточно будет проверять объем данных отмены и повторного выполнения, и учитывать блокировки, оставляя в стороне такой тонкий момент, как объем логического ввода/вывода.
Итак, что же происходит при выполнении обновления без фактического изменения значения для столбца, входящего в простой индекс на основе B-дерева? Ничего . Сервер Oracle определяет, что проиндексированное значение не изменилось, и даже не обращается к индексу, не говоря уже про блокирование записи. Это верно и для простых индексов на основе битовых карт.
Вы можете усомниться, а не произойдет ли что-то ужасное при переходе на индексы по функции - не будет ли вызываться функция "на всякий случай", правильно ли отслеживает сервер Oracle зависимости между функциями и используемыми в них столбцами? Ответ : все работает правильно, никаких лишних вычислений функции или проходов по индексу не будет. В качестве теста можно создать такую же таблицу, как в листинге 1, а затем выполнить следующие SQL-операторы:
Вы увидите, что функция вызывается один раз (поскольку в таблице только одна строка), при создании индекса, но она не вызывается при обновлении без изменения значения. Кстати, при выполнении второго оператора update функция будет вызываться дважды - один раз для поиска исходного местонахождения в индексе, а второй - для вычисления нового. Вы можете обнаружить, что функция вызывается еще два раза при выполнении отката - я уверен, что сталкивался с этим в прежних версиях, когда индексы по функции только появились, но сейчас это больше не происходит.
Целостность ссылок
Вот тут, вероятно, и наступает решающий момент для систем оперативной обработки транзакций (ООТ - OLTP). Их ждет двойной удар - сначала в подчиненной таблице, а потом и в главной.
Возьмите таблицу из листинга 1 и вставьте в нее еще 9 одинаковых строк, чтобы всего их стало 10. Затем выполните следующие тесты и проверьте объем логического ввода/вывода и т.п.:
Вы обнаружите, что количество прочитанных блоков db block gets ( current mode gets ) увеличится на 10 после добавления ограничения целостности. Почему? Потому что при каждом обновлении сервер Oracle проверяет ограничение внешнего ключа, и делает это путем просмотра индекса по первичному ключу в главной таблице с помощью current mode gets . Если главная таблица будет достаточно большой, может потребоваться три current mode gets для каждого избыточного обновления столбца в подчиненной таблице.
Компромисс будет всегда
Вы могли уже решить, что пора переписывать массу кода. Но, написание кода, генерирующего идеальный SQL-оператор каждый раз, повышает вероятность ошибок. Компромисс между повышенным риском ошибки (а также временем на кодирование, тестирование и отладку) и производительностью всегда будет, так что, если сервер далек до полной загрузки, вполне допустимо и обоснованно будет игнорировать все описанные выше проблемы. По крайней мере, в краткосрочной перспективе.
Есть и еще один, более тонкий компромисс. Если приложение генерирует идеальный SQL-оператор для каждого обновления, которое оно потенциально может сгенерировать конечное приложение, то существенно возрастает количество различных SQL-операторов в системе.
Теоретически, если в таблице есть N столбцов, тогда разных операторов update может быть power(2,N) - 1 , и это если ограничиться только однострочными обновлениями по rowid . Если не увеличить соответственно разделяемый пул и не настроить несколько параметров, вроде session_cached_cursors , может оказаться, что экономия в одном месте оборачивается дополнительными проблемами (такими как конфликты доступа к библиотечному кэшу) в другом.
Заключение
Если разрешить инструментальным средствам создания конечных приложений использовать простой способ обновления данных (путем генерации одного SQL-оператора для всех возможных обновлений), нагрузка на систему может существенно возрасти. При работе в среде клиент-сервер или в многоуровневой архитектуре может иметь смысл использовать дополнительные вычислительные ресрсы на клиенте или сервере приложений для построения специфических SQL-операторов, минимизирующих затраты ресурсов на сервере. Решение при этом, однако, - не очевидное. Убедитесь, что преимущества окупят затраты.
Иногда у программиста, который разрабатывает SQL инструкцию или какую-нибудь процедуру, возникает необходимость узнать количество строк, например, которые он обновил инструкцией UPDATE или удалил с помощью инструкции DELETE, Microsoft SQL Server позволяет это сделать с помощью системной функции @@ROWCOUNT. Сегодня мы поговорим об этой функции, а также рассмотрим несколько примеров ее использования.

Функция @@ROWCOUNT в языке T-SQL
@@ROWCOUNT – это системная функция в Microsoft SQL Server, которая возвращает количество затронутых строк при выполнении последней инструкции.
Возвращает значение с типом данных INT. В случае если Вы подразумеваете, что число измененных строк будет больше 2 миллиардов, то лучше использовать аналогичную функцию ROWCOUNT_BIG(), в этом случае тип возвращающего значения будет BIGINT.
Важные моменты при использовании @@ROWCOUNT:
- Функцию ROWCOUNT необходимо использовать сразу же после выполнения той инструкции, результат которой, в части количества затронутых (измененных) строк, Вы хотите узнать. В случае если этот результат, т.е. число задействованных строк, Вам необходимо использовать дальше по коду, то это число нужно сразу сохранить в переменную;
- Если ROWCOUNT использовать после инструкции SELECT, то функция будет возвращать число строк, которые возвращает инструкция SELECT;
- После инструкций INSERT, UPDATE или DELETE функция ROWCOUNT будет возвращать количество задействованных строк в результате соответствующих изменений. Но при этом стоит понимать, что ROWCOUNT будет учитывать и те строки, в которых по факту изменений не произошло, но они были затронуты, например, Вы обновили поле со значением 1 на такое же значение, т.е. на 1;
- Если @@ROWCOUNT вызвать после инструкции MERGE, то будет возвращаться общее число вставленных, обновленных и удаленных строк;
- После выполнения инструкций присваивания функция ROWCOUNT будет возвращать значение 1, например, это относится к таким операциям как SET @TestVariable = 1 или SELECT @TestVariable = 1. Также будет возвращаться значение 1 после инструкций DECLARE CURSOR и FETCH;
- В случаях, если ROWCOUNT используется после инструкций, которые не возвращают, не изменяют и не присваивают не одной строки, функция возвращает значение 0. К таким инструкциям можно отнести USE, IF, DEALLOCATE CURSOR, CLOSE CURSOR, BEGIN TRANSACTION или COMMIT TRANSACTION.
Создаем тестовые данные для примеров
Для того чтобы посмотреть, как работает функция @@ROWCOUNT, давайте создадим таблицу. К этой таблице мы и будем обращаться в наших тестовых запросах.
Примечание! Все примеры мы будем рассматривать в СУБД Microsoft SQL Server 2016 Express.
Примеры использования функции ROWCOUNT
Теперь можно переходить к рассмотрению примеров. Так как в нашей тестовой таблице еще нет данных, давайте добавим в нее строки и посмотрим, что нам вернет @@ROWCOUNT.
Пример 1. Использование ROWCOUNT после инструкции INSERT
Для примера давайте добавим 5 строк, а после сразу вызовем функцию @@ROWCOUNT.
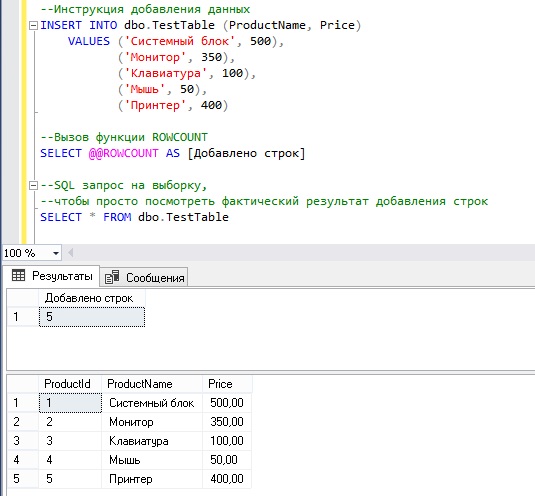
Как видим, функция вернула нам правильное значение.
Пример 2. Использование ROWCOUNT после инструкции UPDATE
Теперь давайте обновим наши данные инструкцией UPDATE и посмотрим, что нам вернет функция ROWCOUNT. Для примера мы будем обновлять поле Price, но только те строки, у которых значение данного поля больше 200. Также в предыдущем примере мы сразу смотрели на результат того, что нам вернет ROWCOUNT, но иногда требуется сохранить это значение, поэтому давайте в этом примере сохраним число, которое нам вернет ROWCOUNT в переменную.
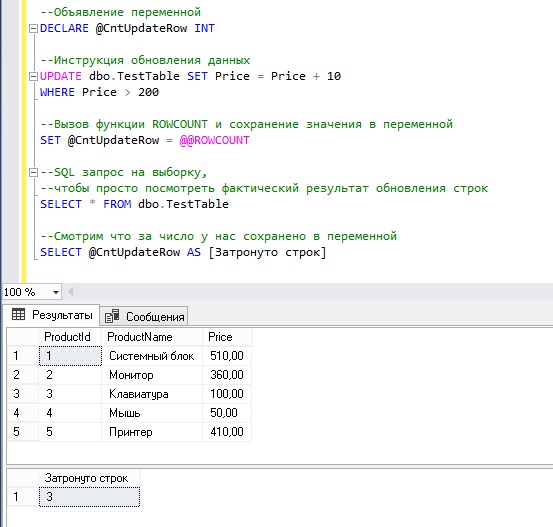
В данном случае мы можем узнать количество измененных строк именно этой инструкцией UPDATE в любой части инструкции, т.е. не только сразу после непосредственного UPDATE (за счет сохранения значения в переменной).
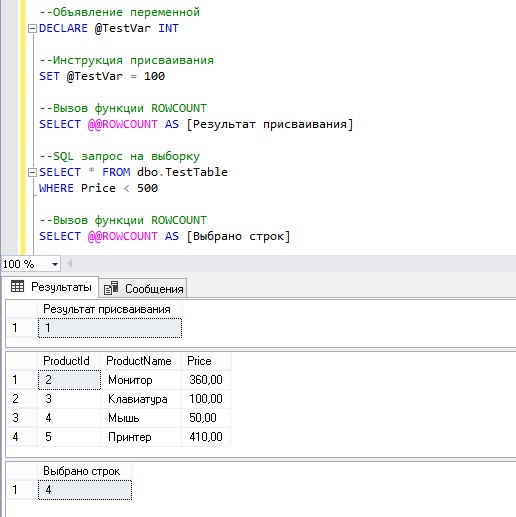
Пример 3. Использование ROWCOUNT после инструкции SELECT и операций присваивания
Сейчас давайте посмотрим, как работает функция в случаях с выборкой данных, а также после операций присваивания.
Пример 4. Использование ROWCOUNT после инструкции DELETE
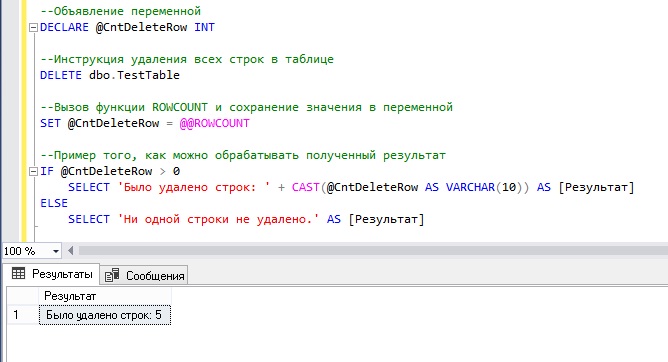
Если мы запустим этот SQL запрос второй раз, то у нас уже результат будет другим, так как ни одной строки, в этом случае, мы не удалим.
обновление данных oracle, псевдоколонка данных, обработка транзакций
1. Обновление данных
Если вы хотите изменить данные перед таблицей, вы можете использовать следующий синтаксис для завершения:
Обновить имя таблицы set field = value, field = value, . [где обновить условие (я)];
Если вы не записываете никаких условий обновления при написании оператора обновления, вы можете иметь в виду обновить все данные в таблице.
Пример: требуется изменить зарплату Смита на 5500 и комиссию до 5000;
Update myemp set sal = 5500,comm=5000 where ename=’smith’;
Пример: единообразно изменить заработную плату всего торгового персонала до 2000;
Update myemp set sal =2000 where job = ‘salesman’;
Фактически, когда все данные обновлены, будет возвращено количество обновленных данных. Если оно увеличено, будет отображаться количество затронутых данных. При написании программы в будущем вы можете судить, успешна ли определенная операция обновления, по наличию строк обновления.
Пример: повысить зарплату первого нанятого сотрудника на 10%;
Update myemp set sal=sal*1.1
Where hiredate=(select min(hiredate) from myemp);
Пример: изменить зарплату компании с самой низкой зарплатой на среднюю зарплату компании;
1. Знайте среднюю зарплату компании
Select avg(sal) from myemp;
Update myemp set sal=(select avg(sal) from myemp where sal=(select min(sal) from myemp));
Когда строки данных в таблице больше не нужны, их можно удалить напрямую, используя следующий синтаксис:
Удалить из имени таблицы [где удалить условие (я)];
Пример: удалить самого высокооплачиваемого сотрудника компании
Delete from myemp
Where sal=(select max(sal) from myemp);
Пример: удалить сотрудников, у которых нет лидера
Delete from emp where mgr is null;
Пример: удалить всех сотрудников
Delete from myemp;
Как и в случае с модификацией и удалением, немногие люди делают такие вещи, и еще одно напоминание: в реальной работе мало кто выполняет такое физическое удаление.
Описание: Об удалении данных:
· В реальной работе полезные реальные данные по-прежнему необходимо сохранять, поэтому их будет нелегко удалить;
· Если есть функция для удаления данных, часто есть два способа:
| - Физическое удаление данных: непосредственно выполнить оператор удаления для удаления всех данных;
| - Логическое удаление данных: добавьте столбец, чтобы пометить столбец, который необходимо удалить для удаления. Поле is_delete обычно используется для указания того, удалена ли запись строки. Логическое удаление данных удаляется, но данные удаляются. Он существует сам по себе.
2. Псевдостолбец данных
Два псевдостолбца данных относятся к столбцам, которые не существуют, но могут использоваться напрямую.Помимо sysdate, в Oracle есть два псевдостолбца, связанные с записями строк, ROWNUM и ROWID.
Номер строки: rownum
При отображении данных пользователь может динамически генерировать номера строк через псевдостолбец rownum.
Пример: соблюдайте rownum
Select rownum ,empno,ename,job,hiredate from emp;
Пример: запросить первую строку данных
Select rownum,empno,ename,job,hiredate from emp
Where deptno =10 and rownum = 1;
Пример: запросить первые n строк записей
Select rownum ,empno,ename,job,hiredate from emp
Where rownum <10;
За исключением первых N строк строк и столбцов, все операции недоступны, но поскольку он уже может получить первые N строк записей, rownum можно использовать для реализации операций разбиения на страницы данных.
Пример: формат отображения страницы данных
Выберите столбец [псевдоним], столбец [псевдоним] . rownum rn
Из имени таблицы [псевдоним]
Where rownum<=currentPage* lineSize temp
Пример: получить 1-5 строк записей в таблице emp (currentPage = 1, linesize = 5)
Select empno,ename,job,rownum rn
Where rownum<=5) temp
ID строки: rowid
Теперь каждая строка записей находит свой собственный столбец данных, и в дополнение к этим столбцам данных существует также уникальный физический адрес каждой строки данных, полученных с помощью rowid.
Затем данные каждого идентификатора строки содержат сохраненные данные, например "AAAR3qAAEAAAACHAAC":
AAAR3q: номер объекта данных
AAE: номер относительного файла, в котором сохранены данные.
AAAACH: номер блока, в котором сохраняются данные.
AAC: номер строки сохраненных данных
Все данные в базе хранятся на диске. Поэтому разные места распределяются по разным данным. И rowid предназначен для записи этой пространственной информации.
Вопрос для собеседования: Теперь есть таблица данных. Из-за отсутствия некоторых ограничений в дизайне большое количество повторяющихся данных было удалено в процессе дальнейшего использования, и остались только самые оригинальные увеличенные данные.
- Чтобы облегчить наблюдение за проблемой, сначала скопируйте таблицу dept в таблицу mydept;
- Обратите внимание на данные и rowid в текущей таблице mydept (на этот раз это самые важные данные для сохранения)
Create table mydetp as select * from dept;
Select rowid,deptno,dname,loc from mydept;
Insert into mydept(deptno,dname,job) values(10,’accounting’,’new york’);
Insert into mydept(deptno,dname,job) values(10,’accounting’,’new york’);
Insert into mydept(deptno,dname,job) values(30,’sales’,’chicago’);
Insert into mydept(deptno,dname,job) values(30,’sales’,’chicago’);
Insert into mydept(deptno,dname,job) values(30,’sales’,’chicago’);
Delete form mydept where rowid not in(
Group by deptno,dname,loc
В будущем анализе rowid по-прежнему будет отображаться, просто помните, что rowid подобен идентификационной карте, которая отображается как ряд определенных меток данных.
3. Обработка транзакций
Первый шаг: сократите счет студента A на 100;
Шаг 2. Добавьте 100 в аккаунт класса B;
Третий шаг: оплатить сервисный сбор 50, необходимый для этой операции.
Однако, если студент А откажется выполнить третий шаг этой операции, банк сочтет, что все предыдущие операции следует вернуть в исходное состояние. Эти три операции завершаются успешно или завершаются неудачно одновременно, и такое поведение управления становится транзакцией в базе данных.
Транзакция обязательно будет работать, когда пользователь выполняет операции обновления данных. Защитите целостность и непротиворечивость данных.
Зафиксируйте транзакцию: commit - действительно хотите выдать команду обновления в базе данных;
· Откат транзакции: откат-откат к исходному состоянию;

После того, как пользователь выдает инструкцию операции для подтверждения транзакции, все данные будут обновлены достоверно.
В Oracle каждый пользователь, подключенный к базе данных, представлен концепцией сеанса, и работа каждого пользователя показывает изоляцию данных.
Update myemp set sal=9999 where empno=7499;
Когда первый сеанс выполняет этот оператор, он может быть завершен нормально, и в то же время в это время транзакция не фиксируется.
Во втором сеансе выполняется следующий оператор:
Update myemp set sal=9999 where empn7499;
Можно обнаружить, что интерфейс в это время перешел в состояние ожидания, которое является изоляцией данных. Означает: до завершения первой сеансовой транзакции ее транзакция перешла в заблокированное состояние.
Команда UPDATE редактирует записи в базе данных.
Какие записи для редактирования задаются с помощью команды WHERE.
Команда WHERE не является обязательной, если ее не указать - будут обновлены все записи в таблице. Будьте внимательны - так случайно можно уничтожить все данные.
См. также команды SELECT, INSERT, DELETE, которые отвечают за получение, вставку и удаление записей.
Синтаксис
Примеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 24 | 500 |
| 3 | Вася | 25 | 600 |
Пример
В данном примере работнику с id, равным 1 (то есть Диме), устанавливается возраст 30 и зарплата 1000:
Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 30 | 1000 |
| 2 | Петя | 24 | 500 |
| 3 | Вася | 25 | 600 |
Пример
В данном примере работнику с id, равным 1 (то есть Диме), устанавливается возраст 30:
Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 30 | 400 |
| 2 | Петя | 24 | 500 |
| 3 | Вася | 25 | 600 |
Пример
В данном примере работнику Пете устанавливается новое имя Коля:
Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Коля | 24 | 500 |
| 3 | Вася | 25 | 600 |
Пример
В данном примере всем работникам устанавливается зарплата 1000 (так как не задано WHERE - наш запрос обновит все записи):
Читайте также: