
Ограничение сетевого шторма на ethernet портах
Продолжая просмотр сайта и(или) нажимая X , я соглашаюсь с использованием файлов cookie владельцем сайта в соответствии с Политикой в отношении файлов cookie в том числе на передачу данных, указанных в Политике, третьим лицам (статистическим службам сети Интернет), в соответствии с Пользовательским соглашением >X
Your browser version is too early. Some functions of the website may be unavailable. To obtain better user experience, upgrade the browser to the latest version.
Продукты, решения и услуги для организаций
Чтобы помочь вам лучше понять содержимое этого документа, компания Huawei перевела его на разные языки, используя машинный перевод, отредактированный людьми. Примечание: даже самые передовые программы машинного перевода не могут обеспечить качество на уровне перевода, выполненного профессиональным переводчиком. Компания Huawei не несет ответственность за точность перевода и рекомендует ознакомиться с документом на английском языке (по ссылке, которая была предоставлена ранее).Настройка управления штормом
Поддерживаемые продукты и версии
Этот пример относится к CE12800, CE6800, CE5800 по версии V100R001C00 или более поздней версии.
Этот пример относится к CE7800 по версии V100R003C00 или более поздней версии.
Этот пример относится к CE8800 по версии V100R006C00 или более поздней версии.
Требования к сети
Как показано на Figure 2-41, SwitchA находится между сетью уровня 2 и маршрутизатором уровня 3, чтобы предотвратить штормы, вызванные широковещательными, многоадресными и неизвестными одноадресными пакетами, отправленными пользователями сети уровня 2.
Figure 2-41 Диаграмма для настройки управления штормом
Функции ограничения трафика и управления штормом не могут быть настроены на одном интерфейсе.- Подавление трафика устанавливает пороговое значение для каждого типа пакетов. Когда скорость передачи пакетов превышает пороговое значение, он отбрасывает избыточные пакеты.
- Управление штормом устанавливает пороговое значение для каждого типа пакетов. Когда скорость передачи пакетов превышает пороговое значение, он отключает интерфейс.
Procedure
В V100R002C00 и более ранних версиях, когда средняя скорость широковещательных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом.
В версиях от V100R002C00SPC100 до V100R005C10, когда средняя скорость широковещательных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет контроль бури.
В версиях V100R005C10 и более поздних версиях, когда средняя скорость широковещательных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом; когда средняя скорость широковещательных пакетов в течение периода обнаружения падает ниже 1000 pps, интерфейс останавливает управление штормом.
В V100R002C00 и более ранних версиях, когда средняя скорость многоадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом.
В версиях от V100R002C00SPC100 до V100R005C10, когда средняя скорость многоадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом.
В V100R005C10 и более поздних версиях, когда средняя скорость многоадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом; когда средняя скорость многоадресных пакетов в течение периода обнаружения падает ниже 1000 pps, интерфейс останавливает управление штормом.
В V100R002C00 и более ранних версиях, когда средняя скорость неизвестных одноадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом.
В версиях от V100R002C00SPC100 до V100R005C10, когда средняя скорость неизвестных одноадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом.
В V100R005C10 и более поздних версиях, когда средняя скорость одноадресных пакетов в течение периода обнаружения превышает 2000 pps, интерфейс выполняет управление штормом; когда средняя скорость неизвестных одноадресных пакетов в течение периода обнаружения падает ниже 1000 pps, интерфейс останавливает контроль бури.
По умолчанию интерфейс может быть восстановлен администратором только после его закрытия. Чтобы настроить интерфейс для автоматического восстановления в состояние Up, запустите команду error-down auto-recovery cause storm-control interval interval-value для установки задержку восстановления. После задержки интерфейс автоматически поднимается Up.
V100R002C00 и более ранние версии
V100R002C00SPC100 и более поздние версии
V100R002C00 и более ранние версии
V100R002C00SPC100 и более поздние версии
V100R002C00 и более ранние версии
V100R002C00SPC100 и более поздние версии
Проверка конфигурации
V100R002C00 и более ранние версии
Запустите команду display storm-control interface, чтобы просмотреть конфигурацию управления штормом на 10GE 1/0/1.
От V100R002C00SPC100 до V100R005C10
Запустите команду display storm control interface, чтобы просмотреть конфигурацию управления штормом на 10GE 1/0/1.
V100R001C10 и более поздние версии
Запустите команду display storm control interface, чтобы просмотреть конфигурацию управления штормом на 10GE 1/0/1.

Broadcast storm (широковещательный шторм) – это такой ночной кошмар сетевиков, когда в считанные секунды парализуется передача полезного трафика во всей сети ЦОД. Как это происходит и о чем надо было раньше думать – в нашем сегодняшнем посте.
Откуда есть пошла
Вначале была Ethernet, и не было в ней маршрутизации, и сейчас тоже нету, а посему приходится коммутатору отправлять пакеты данных во все порты – ну, чтобы наверняка. От адресата приходит ответ на определенный порт, коммутатор запоминает соответствие [порт — адресат] и следующая “посылка” отправляется уже не абы куда, а по памятным, так сказать, местам.
Если же ответа нет, а в момент отправки unknown unicast пара-тройка коммутаторов оказываются замкнуты в кольцо, посылка возвращается “отправителю”, который, понятно, снова забрасывает ее во все порты, поскольку ну а что ему еще делать. «Бесхозный» пакет данных опять возвращается и опять улетает. Каждый следующий виток “закольцованного” broadcast flood сопровождается экспоненциальным ростом количества пакетов в сегменте сети. Очень скоро эта лавина «забивает» полосу пропускания портов, на заднем плане красиво «вскипают» перегруженные процессоры коммутаторов – и ваша сеть превращается в памятник самой себе.
Причиной шторма может стать как хакерская атака, так и осечка вашего же инженера при настройке оборудования – или вовсе сбой протоколов. Иными словами, никто не застрахован.
Был такой случай
В 2009 году в сети одного из наших клиентов случился бродкастовый шторм, который мгновенно перекинулся к нам, парализовав работу всей сети передачи данных компании. Отвалились почта, телефония и интернет, система мониторинга «сошла с ума» – и стало невозможно даже локализовать «первоисточник». Полная перезагрузка коммутатора не помогла. Нам ничего не оставалось, кроме как последовательно отключать ВСЕ порты, клиентские и свои собственные… Такой вот «черный понедельник».
Как позже выяснилось, один из сотрудников клиента перепутал порты оборудования – и закольцевал свою топологию на уровне бродкастового домена. Бывает.
Понятно, что в группе риска здесь, в первую очередь, коммерческие ЦОДы: резервированное подключение для каждого клиента само по себе уже означает избыточность соединений между коммутаторами. Однако сетевикам корпоративных дата-центров я бы также не рекомендовал расслабляться: замкнуть по рассеянности пару коммутаторов друг на друга можно и в серверной.
Хорошая новость заключается в том, что при грамотной подготовке вы можете отделаться легким испугом там, где в противном случае получили бы простой сервиса.
С чего начать
Начните с сегментирования сети посредством VLAN: когда сеть разбита на мелкие изолированные сегменты (fault domain), шторм, “накрывший” один из участков, этим участком и ограничивается. Ну, в идеале. В действительности мощный шторм, увы, способен “вбрасывать” пакеты и в так называемые независимые виртуальные сети тоже.
По-хорошему здесь нужно отказаться от “закольцованных” VLAN как внутри собственной инфраструктуры, так и при подключении клиентов к сети (если речь о коммерческом ЦОД). Например, использовать протоколы FHRP и U-образную топологию на уровне доступа.

U-образная топология позволяет избежать закольцованности
В ряде случаев, впрочем, от «закольцованности» при всем желании никуда не деться. Скажем, необходимо развернуть отказоустойчивую (2N) инфраструктуру для заказчика с подключением к нашему облаку. Клиентские VLAN’ы здесь приходится «пробрасывать» внутри облачной инфраструктуры между всеми ESXi хостами кластера виртуализации, – то есть само решение подразумевает полное дублирование всех сетевых элементов.
Смотрим в картинку – видим кольцо.

Кольцевая топология возникает при полном резервировании каналов связи и инфраструктуры заказчика
Что делать, если вы – «властелин колец»
Делать можно разное, и у каждого варианта, как водится, — свои преимущества и издержки.
Хорошая в целом штука, но есть нюанс. Под каждый VLAN выделяется один RSTP-процесс, при этом количество процессов, в отличие от VLAN, сильно ограничено, и при резком росте числа VLAN'ов в рамках одной сетки процессов RSTP может банально не хватить. То есть для корпоративного дата-центра пойдет, а для коммерческого – с постоянно растущим числом клиентов (VLAN) – уже не очень.
На этот случай имеется MSTP – улучшенное и дополненное издание RSTP. Умеет объединять несколько VLAN в один STP процесс (instance), что в хорошем смысле слова сказывается на масштабируемости сети: “потолок” здесь составляет 4096 клиентов (максимальное число VLAN). MSTP также позволяет управлять трафиком, распределяя MST процессы между основным линком и резервным, и дает возможность при необходимости разгружать “загнавшиеся” коммутаторы. Однако с MST нужно уметь работать, то есть это плюс как минимум один недешевый умник в штат (что доступно не всем).

Протоколы RSTP и MST «разрывают» петлю, блокируя трафик по одному из каналов
Из проверенных альтернатив MSTP можем посоветовать FlexLinks от Cisco, который мы используем, когда на стороне клиента находится один коммутатор или стек под единым управлением. FlexLinks умеет резервировать линки коммутатора без применения STP, “назначая” в каждой паре портов основной и резервный. Используется на уровне доступа (access) при подключении оборудования разных компаний по принципу Looped Triangle в коммерческом ЦОД. Очень простой в плане настройки инструмент, что и само по себе приятно, и позволяет рассчитывать на бОльшую стабильность сервиса (по сравнению, например, с STP). Вы полюбите FlexLinks за мгновенное переключение на резервные линки и балансировку нагрузки по VLAN – а потом, возможно, разлюбите за возможность применять его исключительно в топологии Looped Triangle.

В топологии Looped Triangle можно добиться мгновенного переключения трафика между каналами в случае сбоя
Теперь отвлечемся от техники. Любите ли вы экономическую эффективность так же, как люблю ее я? Тогда вам будет интересно узнать, что и MST \ RSTP, и FlexLinks, блокируя резервные линки, фактически исключают половину портов из круговорота трафика в природе.
А вот решения, которые так не делают: Cisco VSS (Virtual Switch System), Nexus vPC (virtual port-channel), Juniper virtual router и другие mLAG-подобные (multichassis link aggregation) технологии. Хороши тем, что задействует все доступные линки, объединяя их в один логический канал EtherChannel. Получается своего рода коммутирующий кластер, в котором модуль управления одного из коммутаторов (Control-plane) “рулит” всеми линками кластера (Data-Plane). В случае выхода текущего Control-plane из строя его полномочия автоматически передаются “оставшемуся в живых”. Мы используем Cisco Nexus vPC для балансировки нагрузки между линками клиентов, у которых по одному коммутатору или стеку. Если же на стороне клиента два отдельных коммутатора, связанных общим VLAN, добавляем в схему STP.

Объединение линков в один логический канал решает проблему со штормами и не сказывается на производительности
Если у вас облака
Виртуализация, катастрофоустойчивые облачные сервисы, распределенные между дата-центрами, и прочие кластерные решения – все это требует несколько иного подхода к организации Layer 2 сети. Убираем STP на антресоли – достаем TRILL.
TRILL использует механизм маршрутизации на Ethernet-уровне и сама строит свободный от петель путь для бродкастового трафика, тем самым предотвращая возникновение штормов. Ну не чудо ли?:) Еще TRILL позволяет равномерно распределять нагрузку между линками (до 16 линков), объединять распределенные дата-центры в единую L2-сеть и гибко управлять трафиком. TRILL – общепринятый стандарт, у которого быстро появились вендорские варианты: FabricPath от Cisco (который используем мы) и VCS от Brocade. Juniper разработал собственную технологию Qfabric, позволяющую создавать единую Ethernet фабрику.
Контрольный выстрел
Какой протокол даст вам 100% защиту от шторма? Правильно, никакой. Поэтому, возможно, вас заинтересуют следующие два инструмента:
• Storm-control
Позволяет установить посекундную “квоту” на количество бродкастовых пакетов, проходящих через один порт. Все, что сверх «квоты», – отбрасывается, и таким образом контролируется нагрузка. Некоторый нюанс заключается в том, что Storm-control не отличает полезный трафик от мусора.
• Control—plane policing (CoPP)
Этакий storm-control для процессора коммутатора. При бродкастовом шторме, помимо прочего, резко возрастает количество ARP-запросов. Когда это количество зашкаливает, процессор загружается на 100% – и сеть, понятно, говорит вам “до свиданья”. CoPP умеет “дозировать” количество ARP-запросов и таким образом управлять нагрузкой на процессор. Неплохо справляется и с броадкастовыми штормами со стороны точек обмена трафиком, и с различными DDoS-атаками — проверено.
Как построить death proof сеть
Итак, какие из возможных вариантов мы проверили на себе и используем в зависимости от вводных:
1. U, V и П-образные топологии + RSTP (MST) + storm control + CoPP.
Базовый набор, в первую очередь, для коммерческого ЦОД, в котором приходится подключать к собственной сети большое количество внешних (неконтролируемых) сетей – и потому крайне желательно не допускать возникновения «петель» вообще.
Если U, V и П-образные топологии не ваш случай, «сокращенный» вариант RSTP (MST) + storm control + CoPP тоже подойдет.
2. Если есть задача максимально использовать возможности оборудования и каналов, присмотритесь к варианту mLAG (VSS, vPC) + storm control + CoPP.
3. Если у вас уже имеется оборудование Cisco или Juniper и нет противопоказаний по топологии, попробуйте комбинацию Flex Links/RTG + storm control + CoPP.
4. Если у вас сложносочиненный случай с распределенными площадками и прочими изысками виртуализации и отказоустойчивости, ваш вариант TRILL + storm control + CoPP.
5. Если вы не знаете, какой у вас случай, – мы можем поговорить об этом:).
Главное – начать делать хоть что-то уже сейчас, даже если вам искренне кажется, что бродкастовый шторм это то, что бывает с другими. В реальности штормы «накрывают» сети самых разных масштабов, а нелепые ошибки совершают даже люди, которые, что называется, двадцать лет в искусстве. «И пусть это вдохновит вас на подвиг» (с).
Широковещательный шторм
Если помните, в первой части статьи мы говорили о коллизии в локальной сети. Рассматривали механизм и причины ее возникновения и варианты предотвращения. Теперь - другая история:
Сегодня я хочу разобрать с Вами понятие: широковещательный шторм. И на реальном примере показать что бывает, когда этот самый Broadcast шторм происходит?
На днях, неожиданно (как это всегда и бывает) один из участков нашей локальной сети начал жестко "глючить". Из двух отделов, расположенных в нем, стали звонить и жаловаться, что сеть "тормозит", из Интернета периодически "выбрасывает" и прочее в том же духе.
Стали в отделе не торопясь прикидывать варианты: вспоминать, что куда в последнее время подключалось, какие кабели протягивались? Кабельная структура у нас - достаточно большая, порой такого насмотришься! :)
Пока прикидывали, оказалось, что сеть начала пропадать и у нас! Команда «ping» показывала огромные временные задержки передачи пакетов, а некоторые из них - вообще терялись! Поскольку весь наш IT отдел подключен к центральному коммутатору сети D-Link DES-3550,

к которому и сходятся все основные кабели передачи данных и подключены все серверы, то получалось так, что очень скоро "глюк" распространился дальше и вся сеть пришла в нерабочее состояние! Но это, все же, случилось не сразу и мы успели выяснить кое-какие интересные подробности :)
Казалось, что сеть стала вдруг перегруженной, но - чем, поначалу было не ясно? Поскольку коммутатор - управляемый (мы говорили об этом в предыдущей статье), то мы посмотрели загрузку его отдельных портов и выяснили, что один из них (под номером 19) находится в состоянии перегрузки и на нем, в большом количестве, наблюдаются коллизии и идентифицируется мощный широковещательный трафик, который уже явственно перешел в широковещательный шторм.
Давайте немного отвлечемся и определимся с тем, что это за шторм такой широковещательный? Мы уже знаем, что в сети информация передается пакетами. Каждая программа, файл или любые другие данные могут быть представлены в виде последовательности таких пакетов, каждый из которых содержит в себе, кроме всего прочего, адрес узла отправителя и адрес узла получателя.
На основе этого, мы можем быть уверены, что наши данные попадут строго тому, кому они и предназначены (другие компьютеры "видя", что адрес получателя не совпадает с их собственным - не будут на них претендовать).
Что интересно: выделенный широковещательный адрес присутствует как на канальном уровне (на уровне MAC адресов), так и на более высоком - сетевом. На уровне физической адресации это будет широковещательный MAC адрес FF-FF-FF-FF-FF-FF, а на уровне логической адресации (IP) адрес может иметь вид: 192.168.0.255 (для нашей сети на работе он - 172.16.255.255).
Примечание: я набросал для Вас таблицу с классами сетей. Кто не в теме, - обязательно посмотрите и вникните :)
В локальных сетях (таких как Ethernet) MAC адрес позволяет однозначно идентифицировать каждый узел сети и доставлять данные только ему. Таким образом, подобные физические адреса формируют основу сетей на канальном уровне, которую используют протоколы более высокого уровня (сетевого).
Примечание: что такое MAC адрес мы также рассматривали в статье о сетевой карте компьютера.
Сам по себе, широковещательный трафик - обычное дело в локальных сетях. С его помощью различные сервисы оповещают всю сеть о своем присутствии, цифровые IP адреса прозрачно для пользователя преобразуются в понятые символьные имена узлов, компьютеры "узнают" о доступных сетевых ресурсах и т.д.
Получив широковещательный запрос, сервер отвечает запрашивающему узлу направленным (unicast-овым) пакетом, в котором сообщает свой адрес и описывает предоставляемые им услуги. С другой стороны, когда подобного широковещательного трафика становится слишком много (пропускная способность сети - не резиновая), то общая эффективность ее работы резко снижается.
Что же является нормой? Считается, что приемлемая доля широковещательного трафика должна составлять 10% от трафика всей сети. Значение в 20% и выше должно классифицироваться как нештатная ситуация, носящая название «широковещательный шторм» (broadcast storm).
В первой части статьи мы выяснили, что с широковещательным штормом можно бороться с помощью интеллектуальных управляемых коммутаторов. Что мы, собственно, и попытались сделать у себя в организации! Давайте я сейчас приведу подборку скриншотов с нашего коммутатора и покажу Вам основные его настройки. Их там - реально очень много, но те что я отобрал, помогут Вам лучше понять, что из себя представляют устройства подобного класса и как с их помощью можно диагностировать широковещательный шторм?
Скриншоты ниже будут кликабельны, так что Вы сможете рассмотреть все детально.
Итак, подключаемся к нашему D-Link DES-3550 по сети:
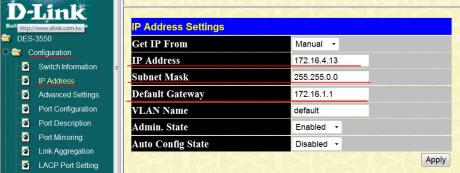
В колонке слева мы видим раскрывающееся "дерево" настроек. Сейчас мы находимся папке "Configuration" подраздел "IP Address".
В правой части окна на скриншоте выше можно видеть сетевые настройки коммутатора. Как видим, в нашей локальной сети он имеет IP адрес 172.16.4.13. Естественно, что адрес можно изменить по своему усмотрению, установить пароль доступа, даже - создать несколько пользователей и делегировать им разные права.
Одна из настроек позволяет нам просмотреть ARP-таблицу коммутатора. ARP (Address Resolution Protocol - протокол определения адреса узла). Подобные таблицы нужны, прежде всего затем, что позволяют четко соотнести IP и MAC адреса узла. Давайте посмотрим на примере.
Посмотрите на фото ниже:

Что мы здесь видим? В самом верху таблицы - уже знакомый нам широковещательный адрес канального уровня: FF-FF-FF-FF-FF-FF. А дальше - список IP адресов компьютеров, посредством сетевого кабеля, подключенных к отдельным портам устройства. Причем, каждому IP адресу в соответствие поставлен уникальный идентификатор сетевой карты этого компьютера (его MAC адрес).
Таким образом, любое устройство в сети может обратиться к конкретному узлу по его логическому имени (IP адресу) или же, - используя аппаратный адрес его сетевого адаптера. В любом случае, коммутатор "поймет" какой из компьютеров является узлом назначения и перешлет данные по нужному порту. Ведь сетевой адрес мы можем легко изменить, а аппаратный (в общем случае) - нет.
Естественно, ARP-таблица динамически обновляется и перестраивается. Нередко бывает, что перенеся устройство в новый сегмент сети, мы должны ждать, когда коммутатор "опросит" все свои порты и выстроит новую таблицу для данного сегмента.
Посмотрите еще на одно фото и его раздел «Port Configuration»:
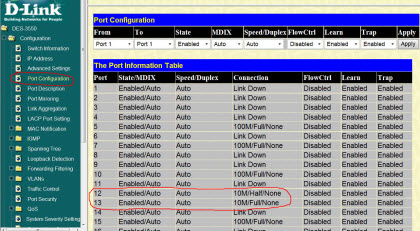
На нем мы видим, в каком режиме и с какой скоростью работают те или иные порты нашего коммутатора. Обратите внимание на два из них (под номерами 12 и 13) обозначенные красным. Как видите, оба они работают на скорости в 10 мегабит в секунду, хотя все остальные имеют скорость в 100 мегабит!
Почему так происходит? Дело в том, что на другом конце кабельной линии, подключенной именно к этим портам, у нас установлены 10-ти мегабитные морально устаревшие концентраторы (хабы). Порты коммутатора "видят", что на другом конце - устройство, работающее на 10Мб/с и автоматически понижают скорость своей работы, чтобы обеспечить одинаковый протокол передачи.
Следующий пункт «Loopback Detection» (обнаружение петли) позволяет нам, не бегая по всем этажам, отследить образование петли в локальной сети:
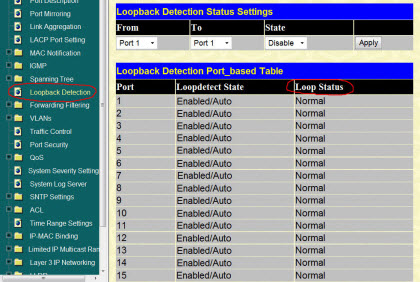
Если «Loop Status» - normal, значит - все в порядке :)
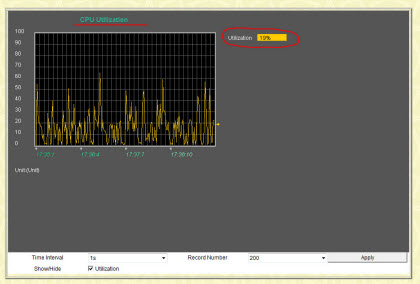
У коммутатора D-Link DES-3550 есть набор различных мониторов, которые в режиме реального времени могут показать нам тот или иной параметр или значение нагрузки. На фото ниже, мы видим график использования (utilization) центрального процессора устройства (в среднем нагрузка составляет 19%).
Есть также очень наглядные счетчики по каждому из 50-ти портов, на которых мы можем увидеть степень загрузки каждого из них, выяснить, трафик какого характера по ним передается (широковещательный, групповая передача, только одному узлу и т.д.)
Вот, к примеру, как выглядит подобный график для порта коммутатора под номером 11:
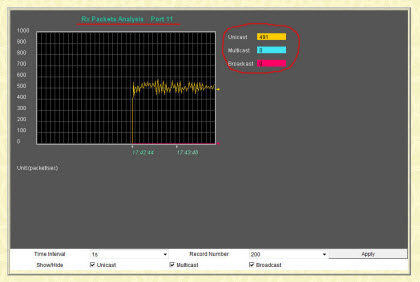
Видим, что порт №11 наполовину загружен Unicast трафиком (адресованным только одному ПК). Почему так происходит? Дело в том, что именно на нем у нас находятся несколько IP камер, ведущих трансляцию, и один сетевой видеорегистратор (DVR), которые и генерируют такой мощный поток данных. Все эти видео потоки затем сводятся на один мощный сервер видеонаблюдения, где и сохраняются на его жесткие диски.
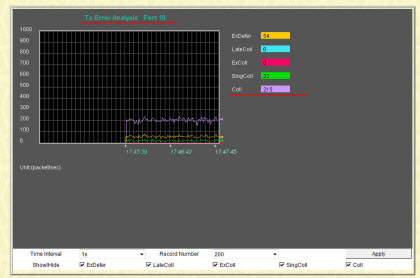
Но это так - к слову :) Возвращаемся к нашему случаю: широковещательные пакеты и широковещательный шторм! Под "прицелом" у нас, если помните, - 19-й порт коммутатора! Именно он находится в состоянии перегрузки и именно на нем мы видим большое количество коллизий.
На скриншоте ниже - наблюдаем однозначное наличие коллизий: параметр coll (фиолетовый график)
Давайте теперь посмотрим на общую загрузку порта №19. Обратите внимание, что просто нажав на графическом изображении коммутатора по соответствующему порту, можно тут же увидеть его график в средней части окна (очень удобно!):
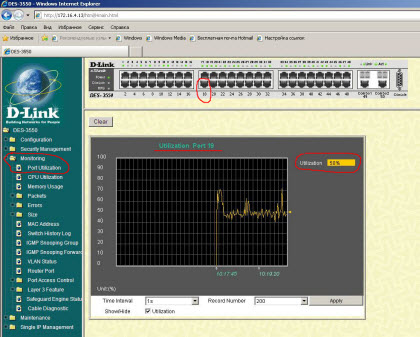
Все это - в секции «Monitoring», подраздел «Port Utilization».
Как видите, порт постоянно загружен на 50% (это - очень много для транка, к которому подключен только один компьютер)!
Вот скриншот, сделанный где-то через минут 15-20 после возникновения широковещательного шторма у нас в сети:
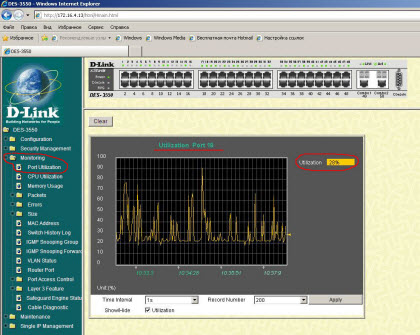
Видим, что "кардиограмма" графика стала более размашистой, загрузка опускается до 20-ти процентов и тут же - "взлетает" до 70-ти и постепенно - растет! Это - явный признак того, что в сети начался широковещательный шторм. Сеть постепенно переполняется широковещательными пакетами, которых становится все больше, и приходит в нерабочее состояние. Почему происходит именно так - читайте в следующей статье!
Эксперимента ради, продолжили ждать. Сеть "легла" полностью еще минут через 10 :)
Также посмотрите на модель broadcast storm, которая поможет Вам лучше представить картину происходящего.
Для борьбы с широковещательным штормом в сетевых устройствах Cisco используется параметр storm-control .
1 Описание
- Параметр storm-control задаёт количество бродкастов в секунду.
- Всё, что свыше этого значения, отбрасывается.
- Порт при этом продолжает работать для пересылки всего остального трафика.
- В случае высокого значения storm-contorol можно получить перегрузку ЦПУ коммутатора, в случае низкого значения можно иметь проблемы с работой DHCP и ARP.
2 Настройка
- Максимальный уровень широковещательного трафика задаётся либо в процентах от полосы пропускания (безразмерные значения), либо в битах в секунду (bps).
- Есть два варианта конфигурирования:
- однопороговое,
- двупороговое.
2.1 Однопороговый вариант
Задаётся максимальный порог и действие по достижении этого порога:
Первая команда устанавливает максимальный уровень широковещательного трафика в 30% от полосы пропускания.
Вторая команда указывает на то, какое действие должно быть совершено, когда лимит будет достигнут. В данном случае мы отключаем порт ( shutdown ).
Если действие не указывать, то свитч будет просто фильтровать трафик, превышающий порог, и не отправлять никаких оповещений.
Чтобы коммутатор автоматически восстанавливал порт через некоторое время после отключения, необходимо в глобальной конфигурации задать:
В данном случае восстановление происходит через 3 минуты (180 секунд).
2.2 Двупороговый вариант
Указывается два порога.
При достижении первого порога порт будет отключаться.
При падении уровня широковещательного трафика до второго порога порт будет включаться:
Здесь первый порог — 30% от полосы пропускания, второй порог — 10% от полосы пропускания.
2.3 Обнаружение петель
Эта опция обычно включена по умолчанию, и в случае срабатывания порт отключается.
Для механизма keepalive можно также настроить автоматическое включение интерфейса:
2.4 Настройка на все порты сразу
Для настройки параметров всех портов сразу используйте диапазон портов:
В рамках данной статьи мы рассмотрим функционал для защиты от петель и различных видов штормов на коммутаторах SNR.
Loopback-detection
Петля коммутации - состояние в сети, при котором коммутатор принимает кадры, отправленные им же. Избежать возникновения петель коммутации поможет функционал Loopback-detection.
Настройка Loopback-detection
Для включения функционала необходимо в режиме конфигурирования порта задать VLAN, для которых будет проверяться наличие петли, а также действие при ее обнаружении:
- block - весь трафик с порта в соответствующем mst-instance будет заблокирован;
- shutdown - порт будет отключен.
В глобальном режиме можно настроить время восстановления после отключения порта по причине петли:
Значение по умолчанию - 0 (порт не будет включен повторно).
По умолчанию коммутатор отправляет 2 LBD-пакета в каждый specified-vlan в промежуток interval-time. Данные значения можно изменить. Значение interval-time меняется также в глобальном режиме. Сначала указывается интервал отправки LBD-пакетов при обнаружении петли, затем, в случае, если петля отсутствует:
Количество отправляемых копий LBD-пакетов можно задать в режиме конфигурирования порта:
При значении по-умолчанию (1) - отправляется 2 LBD-пакета. При 2 - 4 пакета и т.д.
При обнаружении петли за каким-либо портом отправляется SNMP Trap с OID 1.3.6.1.4.1.40418.7.101.112.1.
Storm-control
Для ограничения широковещательного трафика в сети можно воспользоваться функционалом Storm-control, который отбрасывает входящий трафик, превышающий установленный лимит. Функционал полностью аппаратный и выполняется на уровне ASIC без участия CPU, поэтому логирование отсутствует.
Настройка Storm-control
Пороговое значение может быть задано как в kbps, так и в pps. Значение по умолчанию - kbps. Изменить единицу измерения можно в глобальном режиме:
На коммутаторах SNR серий S2995G и S2995G возможно только kbps ограничение.Также можно настроить протоколы, на пакеты которых функционал реагировать не будет. Данная настройка также производится в глобальном режиме:
Пороговое значение для каждого типа трафика настраивается отдельно для каждого порта в режиме его конфигурирования:
Rate-violation
Расширенные возможности для ограничения широковещательного трафика в сети имеет Rate-violation, который также отбрасывает входящий трафик, превышающий установленный лимит. В отличие от Storm-control, данный функционал задействует ресурсы CPU и является софтовым. При превышении порога действие записывается в лог, отправляется соответствующий SNMP Trap.
Настройка Rate-violation
Все настройки Rate-violation применяются в режиме конфигурирования порта.
Пороговое значение задается для выбранного типа трафика и может быть задано только в pps:
В качестве действия при превышении порога широковещательным трафиком может быть выбрано либо отключение порта, либо блокировка всего трафика на порте. При отключении порта также может быть выбрано время восстановления, после которого порт будет включен обратно:
Flood-control
Кроме ограничения входящего широковещательного трафика, на коммутаторах SNR существует возможность ограничить исходящий широковещательный трафик. Для этого используется Flood-control. Механизм, как и Storm-control, является аппаратным и полностью ограничивает передачу определенного типа широковещательного трафика в выбранный порт.
Настройка Flood-control
Настраивается функционал единственной командой в режиме конфигурирования порта. Всё, что нужно - это выбрать тип широковещательного трафика, распространение которого необходимо ограничить:
Читайте также: