
Когда хранение базы данных и доступ к ней осуществляются на одном компьютере
Система управления базами данных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Основные функции СУБД¶
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша;
- журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификации СУБД¶
По модели данных¶
Иерархические¶
Используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Примеры: Caché, Google App Engine Datastore API.
Сетевые¶
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Реляционные¶
Практически все разработчики современных приложений, предусматривающих связь с системами баз данных, ориентируются на реляционные СУБД. По оценке Gartner в 2013 году рынок реляционных СУБД составлял 26 млрд долларов с годовым приростом около 9%, а к 2018 году рынок реляционных СУБД достигнет 40 млрд долларов. В настоящее время абсолютными лидерами рынка СУБД являются компании Oracle, IBM и Microsoft, с общей совокупной долей рынка около 90%, поставляя такие системы как Oracle Database, IBM DB2 и Microsoft SQL Server.
Объектно-ориентированные¶
Управляют базами данных, в которых данные моделируются в виде объектов, их атрибутов, методов и классов.
Этот вид СУБД позволяет работать с объектами баз данных так же, как с объектами в программировании в объектно-ориентированных языках программирования. ООСУБД расширяет языки программирования, прозрачно вводя долговременные данные, управление параллелизмом, восстановление данных, ассоциированные запросы и другие возможности.
Объектно-реляционные¶
Этот тип СУБД позволяет через расширенные структуры баз данных и язык запросов использовать возможности объектно-ориентированного подхода: бъекты, классы и наследование.
Зачастую все те СУБД, которые называются реляционными, являются, по факту, объектно-реляционными.
В данном курсе мы будем, в первую очередь, гооврить об этом виде СУБД.
Примеры: PostgreSQL, DB2, Oracle, Microsoft SQL Server.
По степени распределённости¶
- Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа к БД¶
Файл-серверные¶
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверные¶
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемые¶
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы (API).
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Стратегии работы с внешней памятью¶
СУБД с непосредственной записью — это СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
СУБД с отложенной записью — это СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
- контрольной точки;
- конец пространства во внешней памяти, отведенное под журнал. СУБД выполняет контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию;
- останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно;
- при нехватке оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
При разработке баз данных принято выделять определённые этапы.
Первый этап — постановка задачи. На этом этапе происходит следующее:
• определяется цель, для которой создаётся база данных;
• уточняется предметная область, при этом привлекаются специалисты этой предметной области для получения более качественного результата разработки;
• определяются предполагаемые виды работ: это может быть выборка данных, изменение данных, печать отчёта и др.;
• определяются потенциальные пользователи базы данных.
На втором этапе происходит проектирование базы данных. Этот этап включает в себя определение самих информационных объектов, из которых будет формироваться база данных, а также перечня атрибутов, характеризующих каждый информационный объект.
После чего определяется структура реляционных таблиц, свойства полей, связи между таблицами, а именно:
1. Формируется общий список полей для описания атрибутов таблиц БД.
2. Все поля распределяются по базовым таблицам.
3. Свойства каждого поля определяются в соответствии со свойствами данных.
4. Ключевые поля определяются для каждой таблицы.
5. Определяются связи между таблицами.
Третий этап — это собственно создание базы данных.
Возможны два варианта:
1. Если нужна уникальная база данных, то она пишется на одном из языков программирования, и в этом случае требуются высококвалифицированные программисты.
2. Существует и второй вариант, для которого достаточно базовых пользовательских навыков и понимания принципов работы базы данных (БД) — это использование специального программного обеспечения — систем управления баз данных (СУБД). В дальнейшем мы будем рассматривать только этот способ.
При создании БД происходит следующее:
— запуск СУБД и создание нового файла БД;
— создание таблиц и связей между ними;
— тестирование БД и коррекция;
— разработка требуемых элементов управления данными: это формы, запросы и отчёты;
— заполнение таблиц данными (это может выполнить пользователь БД).
Четвёртый этап — это эксплуатация БД, которая состоит из сортировки, фильтрации и поиска записей, отбора данных по соответствующим критериям, обработку данных и подготовку отчётов.
В общем виде этапы разработки базы данных представлены на схеме.
Программное обеспечение для создания БД, хранения и поиска в них необходимой информации называется СУБД (системой управления базами данных).
Существует настолько большое количество СУБД, что их можно классифицировать по моделям данных, по размещению или по способу доступа к БД.
В зависимости от модели данных СУБД бывают иерархические, сетевые, реляционные и другие.
Если все составляющие СУБД размещаются на одном компьютере, то она считается локальной. Когда данные могут храниться и обрабатываться на разных компьютерах локальной или глобальной сети, то речь идет о распределённых СУБД.
В файл-серверных СУБД файлы с данными размещаются на сервере и доступ с клиентского компьютера к данным осуществляется через локальную сеть. Частным случаем таких СУБД являются размещение как самих данных, так и СУБД на одном клиентском компьютере. Примерами являются Microsoft Access, OpenOffice Base, LibreOffice Base.
Встраиваемые входят в состав таких программных продуктов, как словари, поисковые системы, электронные энциклопедии и др. Примером может служить компактная встраиваемая СУБД SQLite.
Наиболее популярными являются клиент-серверные СУБД. В этом случае на сервере устанавливается полная версия СУБД и БД, где происходят все операции с данными. На клиентском компьютере устанавливается небольшая по объему клиентская версия СУБД для осуществления запросов и вывода результатов обработки, полученных от сервера. Известными клиент-серверными СУБД являются Oracle, MySQL, PostgreSQL.
Рассмотрим начало работы в программной среде СУБД на примере LibreOffice Base.
Для этого нужно открыть приложение.
Далее мастер БД предложит создать новую базу данных и нажать на кнопку «Дальше».
Следующее диалоговое окно предлагает зарегистрировать БД и открыть её для редактирования.
Оставляем предложенный выбор и нажимаем кнопку «Готово».
Далее в диалоговом окне указываем место сохранения БД и указываем имя.
После этого открывается для редактирования окно базы данных.
Одним из главных элементов интерфейса СУБД является окно базы данных.
В нём отражаются все объекты базы данных: таблицы, запросы, формы, отчёты.
Активный объект выделяется курсором. В нашем случае выделены таблицы.
Вся база данных состоит из таблиц и связей между ними.
Теперь перед заполнением необходимых таблиц нужно определиться с их количеством и структурой, типами связей при использовании нескольких таблиц, а также видами и количеством форм, запросов и отчётов.
Структура таблицы определяется набором и свойствами полей.
Вы уже знаете, что записью является строка таблицы, в ней содержится набор данных об одном объекте. А столбец — это поле, в нём содержатся однородные данные, относящиеся ко всем объектам. Основными свойствами полей являются:
- Имя поля — оно уникально в рамках таблицы, определяет, как нужно обращаться к данным этого поля.
- Тип поля — определяет тип допустимых данных поля.
- Размер поля — определяет допустимую длину данных поля.
- Формат поля — определяет способ форматирования данных.
- Подпись — определяет заголовок столбца таблицы данного поля, при его отсутствии указывается Имя поля.
- Значение по умолчанию — вводится автоматически при формировании очередной записи таблицы.
- Условие на значение — проверка правильности ввода данных.
После создания таблиц нужно установить связи между ними.
СУБД обеспечивает автоматический контроль взаимосвязанных данных из разных таблиц. Это гарантия целостности данных — одного из важнейших свойств БД.
Редактирование таблиц допустимо на любом этапе, т. е. возможны следующие действия:
• изменение типов и свойств полей;
При работе с таблицами пользователь видит все поля и записи в ней. Это не всегда удобно. Более комфортным для пользователя является работа с данными, представленными в формах.
Формы — это вспомогательные объекты БД, обеспечивающие удобный для пользователя интерфейс при вводе, просмотре или редактировании данных в БД.
Формы содержат не все поля таблицы, а только необходимые пользователю. Дизайн формы можно выбрать в соответствии с назначением и по своему усмотрению, включая в форму рисунки, тестовые надписи, диаграммы, а также используя элементы управления (кнопки, флажки, переключатели и т. п.). Для создания форм в СУБД имеются специальные инструменты.
В LibreOffice Base возможен вариант создания формы по шагам с помощью мастера или создания формы в режиме дизайна. В этом случае открывается окно с инструментами рисования, в котором создаётся форма.
Над данными, хранящимися в БД, можно выполнять различные действия, среди которых:
• обновление, удаление и добавление данных;
Действия, выполняемые над данными, хранящимися в БД, называются манипулированием данных.
Для этого существуют инструменты сортировки, фильтров и запросов.
Возможна сортировка по возрастанию или убыванию значений выбранного поля. Для осуществления сортировки в LibreOffice Base достаточно выделить значение одного из полей записи и нажать на кнопку сортировка по возрастанию или сортировка по убыванию. Всегда можно отказаться от сортировки, нажав на соответствующую кнопку.
Поиск данных происходит стандартным образом. Вызвать диалоговое окно поиска данных можно через пиктограмму меню или с помощью комбинации клавиш Ctrl + F.
Если нужно произвести отбор данных, соответствующих определённым условиям, то в этом случае удобно использовать фильтрацию данных.
Фильтр — это условие, по которому производится поиск и отбор записей.
В СУБД LibreOffice Base можно выбрать быстрый фильтр, с помощью которого можно выбрать все записи, у которых значение поля полностью совпадает с выделенным. Если таких записей нет, то фильтр отбирает только текущую запись. Когда необходимо более сложное условие для отбора записей, то можно использовать стандартный фильтр. В этом случае в диалоговом окне нужно указать условия для различных полей и выбрать необходимые логические операторы И, ИЛИ.
Одним из основных инструментов обработки данных являются запросы. Запросы, как и фильтры, осуществляют поиск записей в БД, но запрос — это самостоятельный объект БД, а фильтр привязан к конкретной таблице. Возможны различные способы создания запросов. Для LibreOffice Base — это самостоятельно в режиме дизайна, с помощью мастера или непосредственно указав инструкции в SQL.
Для красивого вывода на печать результатов обработки данных используют отчеты. В отчётах предусмотрены возможности оформления, используемые при печати документов. Кроме того, отчёты позволяют обобщать, сортировать, группировать данные и т. п.
В примере с базой данных «Процессоры» при формировании отчета данные сгруппированы по количеству ядер, расположенных по убыванию, а внутри групп произведена сортировка по цене.

В статье будет три части:
- Как защищать подключения.
- Что такое аудит действий и как фиксировать, что происходит со стороны базы данных и подключения к ней.
- Как защищать данные в самой базе данных и какие для этого есть технологии.
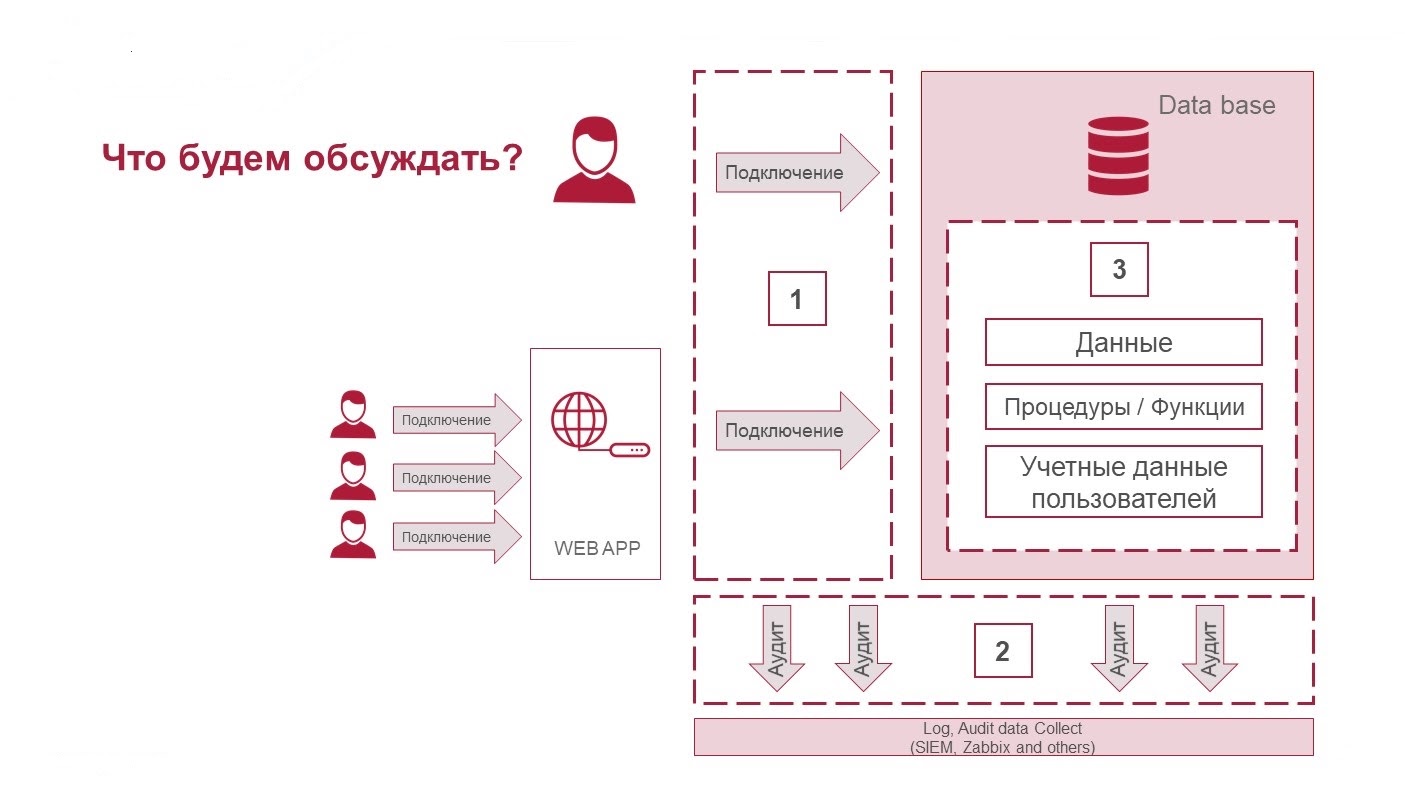
Три составляющих безопасности СУБД: защита подключений, аудит действий и защита данных
Защита подключений
Подключаться к базе данных можно как напрямую, так и опосредованно через веб-приложения. Как правило, пользователь со стороны бизнеса, то есть человек, который работает с СУБД, взаимодействует с ней не напрямую.
Перед тем как говорить о защите соединений, нужно ответить на важные вопросы, от которых зависит, как будут выстраиваться мероприятия безопасности:
- эквивалентен ли один бизнес-пользователь одному пользователю СУБД;
- обеспечивается ли доступ к данным СУБД только через API, который вы контролируете, либо есть доступ к таблицам напрямую;
- выделена ли СУБД в отдельный защищенный сегмент, кто и как с ним взаимодействует;
- используется ли pooling/proxy и промежуточные слои, которые могут изменять информацию о том, как выстроено подключение и кто использует базу данных.
- Используйте решения класса database firewall. Дополнительный слой защиты, как минимум, повысит прозрачность того, что происходит в СУБД, как максимум — вы сможете обеспечить дополнительную защиту данных.
- Используйте парольные политики. Их применение зависит от того, как выстроена ваша архитектура. В любом случае — одного пароля в конфигурационном файле веб-приложения, которое подключается к СУБД, мало для защиты. Есть ряд инструментов СУБД, позволяющих контролировать, что пользователь и пароль требуют актуализации.
Как это повлияет на производительность СУБД?
Посмотрим на примере PostgreSQL, как SSL влияет на нагрузку CPU, увеличение таймингов и уменьшение TPS, не уйдет ли слишком много ресурсов, если его включить.
Нагружаем PostgreSQL, используя pgbench — это простая программа для запуска тестов производительности. Она многократно выполняет одну последовательность команд, возможно в параллельных сеансах базы данных, а затем вычисляет среднюю скорость транзакций.
Тест 1 без SSL и с использованием SSL — соединение устанавливается при каждой транзакции:
vs
Тест 2 без SSL и с использованием SSL — все транзакции выполняются в одно соединение:
vs
Остальные настройки:
Результаты тестирования:
| NO SSL | SSL | |
| Устанавливается соединение при каждой транзакции | ||
| latency average | 171.915 ms | 187.695 ms |
| tps including connections establishing | 58.168112 | 53.278062 |
| tps excluding connections establishing | 64.084546 | 58.725846 |
| CPU | 24% | 28% |
| Все транзакции выполняются в одно соединение | ||
| latency average | 6.722 ms | 6.342 ms |
| tps including connections establishing | 1587.657278 | 1576.792883 |
| tps excluding connections establishing | 1588.380574 | 1577.694766 |
| CPU | 17% | 21% |
При небольших нагрузках влияние SSL сопоставимо с погрешностью измерения. Если объем передаваемых данных очень большой, ситуация может быть другая. Если мы устанавливаем одно соединение на каждую транзакцию (это бывает редко, обычно соединение делят между пользователями), у вас большое количество подключений/отключений, влияние может быть чуть больше. То есть риски снижения производительности могут быть, однако, разница не настолько большая, чтобы не использовать защиту.
Обратите внимание — сильное различие есть, если сравнивать режимы работы: в рамках одной сессии вы работаете или разных. Это понятно: на создание каждого соединения тратятся ресурсы.
У нас был кейс, когда мы подключали Zabbix в режиме trust, то есть md5 не проверяли, в аутентификации не было необходимости. Потом заказчик попросил включить режим md5-аутентификации. Это дало большую нагрузку на CPU, производительность просела. Стали искать пути оптимизации. Одно из возможных решений проблемы — реализовать сетевое ограничение, сделать для СУБД отдельные VLAN, добавить настройки, чтобы было понятно, кто и откуда подключается и убрать аутентификацию.Также можно оптимизировать настройки аутентификации, чтобы снизить издержки при включении аутентификации, но в целом применение различных методов аутентификации влияет на производительность и требует учитывать эти факторы при проектировании вычислительных мощностей серверов (железа) для СУБД.
Вывод: в ряде решений даже небольшие нюансы на аутентификации могут сильно сказаться на проекте и плохо, когда это становится понятно только при внедрении в продуктив.
Аудит действий
Аудит может быть не только СУБД. Аудит — это получение информации о том, что происходит на разных сегментах. Это может быть и database firewall, и операционная система, на которой строится СУБД.
В коммерческих СУБД уровня Enterprise с аудитом все хорошо, в open source — не всегда. Вот, что есть в PostgreSQL:
- default log — встроенное логирование;
- extensions: pgaudit — если вам не хватает дефолтного логирования, можно воспользоваться отдельными настройками, которые решают часть задач.
«Базовая регистрация операторов может быть обеспечена стандартным средством ведения журнала с log_statement = all.
Это приемлемо для мониторинга и других видов использования, но не обеспечивает уровень детализации, обычно необходимый для аудита.
Недостаточно иметь список всех операций, выполняемых с базой данных.
Также должна быть возможность найти конкретные утверждения, которые представляют интерес для аудитора.
Стандартное средство ведения журнала показывает то, что запросил пользователь, в то время как pgAudit фокусируется на деталях того, что произошло, когда база данных выполняла запрос.
Например, аудитор может захотеть убедиться, что конкретная таблица была создана в задокументированном окне обслуживания.
Это может показаться простой задачей для базового аудита и grep, но что, если вам представится что-то вроде этого (намеренно запутанного) примера:
DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Стандартное ведение журнала даст вам это:
LOG: statement: DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Похоже, что для поиска интересующей таблицы может потребоваться некоторое знание кода в тех случаях, когда таблицы создаются динамически.
Это не идеально, так как было бы предпочтительнее просто искать по имени таблицы.
Вот где будет полезен pgAudit.
Для того же самого ввода он выдаст этот вывод в журнале:
AUDIT: SESSION,33,1,FUNCTION,DO. «DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;"
AUDIT: SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Регистрируется не только блок DO, но и полный текст CREATE TABLE с типом оператора, типом объекта и полным именем, что облегчает поиск.
При ведении журнала операторов SELECT и DML pgAudit можно настроить для регистрации отдельной записи для каждого отношения, на которое есть ссылка в операторе.
Не требуется синтаксический анализ, чтобы найти все операторы, которые касаются конкретной таблицы(*)».
Как это повлияет на производительность СУБД?
Давайте проведем тесты с включением полного аудита и посмотрим, что будет с производительностью PostgreSQL. Включим максимальное логирование БД по всем параметрам.
В конфигурационном файле почти ничего не меняем, из важного — включаем режим debug5, чтобы получить максимум информации.
| log_destination = 'stderr' logging_collector = on log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 10MB log_min_messages = debug5 log_min_error_statement = debug5 log_min_duration_statement = 0 debug_print_parse = on | debug_print_rewritten = on debug_print_plan = on debug_pretty_print = on log_checkpoints = on log_connections = on log_disconnections = on log_duration = on log_hostname = on log_lock_waits = on log_replication_commands = on log_temp_files = 0 log_timezone = 'Europe/Moscow' |
На СУБД PostgreSQL с параметрами 1 CPU, 2,8 ГГц, 2 Гб ОЗУ, 40 Гб HDD проводим три нагрузочных теста, используя команды:
Результаты тестирования:
| Без логирования | С логированием | |
| Итоговое время наполнения БД | 43,74 сек | 53,23 сек |
| ОЗУ | 24% | 40% |
| CPU | 72% | 91% |
| Тест 1 (50 коннектов) | ||
| Кол-во транзакций за 10 мин | 74169 | 32445 |
| Транзакций/сек | 123 | 54 |
| Средняя задержка | 405 мс | 925 мс |
| Тест 2 (150 коннектов при 100 возможных) | ||
| Кол-во транзакций за 10 мин | 81727 | 31429 |
| Транзакций/сек | 136 | 52 |
| Средняя задержка | 550 мс | 1432 мс |
| Про размеры | ||
| Размер БД | 2251 МБ | 2262 МБ |
| Размер логов БД | 0 Мб | 4587 Мб |
В итоге: полный аудит — это не очень хорошо. Данных от аудита получится по объему, как данных в самой базе данных, а то и больше. Такой объем журналирования, который генерится при работе с СУБД, — обычная проблема на продуктиве.
Смотрим другие параметры:
- Скорость сильно не меняется: без логирования — 43,74 сек, с логированием — 53,23 сек.
- Производительность по ОЗУ и CPU будет проседать, так как нужно сформировать файл с аудитом. Это также заметно на продуктиве.
В корпорациях с аудитом еще сложнее:
- данных много;
- аудит нужен не только через syslog в SIEM, но и в файлы: вдруг с syslog что-то произойдет, должен быть близко к базе файл, в котором сохранятся данные;
- для аудита нужна отдельная полка, чтобы не просесть по I/O дисков, так как он занимает много места;
- бывает, что сотрудникам ИБ нужны везде ГОСТы, они требуют гостовую идентификацию.
Ограничение доступа к данным
Посмотрим на технологии, которые используют для защиты данных и доступа к ним в коммерческих СУБД и open source.
Что в целом можно использовать:
- Шифрование и обфускация процедур и функций (Wrapping) — то есть отдельные инструменты и утилиты, которые из читаемого кода делают нечитаемый. Правда, потом его нельзя ни поменять, ни зарефакторить обратно. Такой подход иногда требуется как минимум на стороне СУБД — логика лицензионных ограничений или логика авторизации шифруется именно на уровне процедуры и функции.
- Ограничение видимости данных по строкам (RLS) — это когда разные пользователи видят одну таблицу, но разный состав строк в ней, то есть кому-то что-то нельзя показывать на уровне строк.
- Редактирование отображаемых данных (Masking) — это когда пользователи в одной колонке таблицы видят или данные, или только звездочки, то есть для каких-то пользователей информация будет закрыта. Технология определяет, какому пользователю что показывать с учетом уровня доступа.
- Разграничение доступа Security DBA/Application DBA/DBA — это, скорее, про ограничение доступа к самой СУБД, то есть сотрудников ИБ можно отделить от database-администраторов и application-администраторов. В open source таких технологий немного, в коммерческих СУБД их хватает. Они нужны, когда много пользователей с доступом к самим серверам.
- Ограничение доступа к файлам на уровне файловой системы. Можно выдавать права, привилегии доступа к каталогам, чтобы каждый администратор получал доступ только к нужным данным.
- Мандатный доступ и очистка памяти — эти технологии применяют редко.
- End-to-end encryption непосредственно СУБД — это client-side шифрование с управлением ключами на серверной стороне.
- Шифрование данных. Например, колоночное шифрование — когда вы используете механизм, который шифрует отдельную колонку базы.
Как это влияет на производительность СУБД?
Посмотрим на примере колоночного шифрования в PostgreSQL. Там есть модуль pgcrypto, он позволяет в зашифрованном виде хранить избранные поля. Это полезно, когда ценность представляют только некоторые данные. Чтобы прочитать зашифрованные поля, клиент передает дешифрующий ключ, сервер расшифровывает данные и выдает их клиенту. Без ключа с вашими данными никто ничего не сможет сделать.
Проведем тест c pgcrypto. Создадим таблицу с зашифрованными данными и с обычными данными. Ниже команды для создания таблиц, в самой первой строке полезная команда — создание самого extension с регистрацией СУБД:
Дальше попробуем сделать из каждой таблицы выборку данных и посмотрим на тайминги выполнения.
Выборка из таблицы без функции шифрования:
id | text1 | text2
------+-------+-------
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
…
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 строк)
Выборка из таблицы с функцией шифрования:
id | decrypt | decrypt
-----+--------------+------------
1 | \x31 | \x31
2 | \x32 | \x32
3 | \x33 | \x33
…
999 | \x393939 | \x393939
1000 | \x31303030 | \x31303030
(1000 строк)
Результаты тестирования:
| Без шифрования | Pgcrypto (decrypt) | |
| Выборка 1000 строк | 1,386 мс | 50,203 мс |
| CPU | 15% | 35% |
| ОЗУ | +5% |
Шифрование сильно влияет на производительность. Видно, что вырос тайминг, так как операции дешифрации зашифрованных данных (а дешифрация обычно еще обернута в вашу логику) требуют значительных ресурсов. То есть идея зашифровать все колонки, содержащие какие-то данные, чревата снижением производительности.
При этом шифрование не серебряная пуля, решающая все вопросы. Расшифрованные данные и ключ дешифрования в процессе расшифровывания и передачи данных находятся на сервере. Поэтому ключи могут быть перехвачены тем, кто имеет полный доступ к серверу баз данных, например системным администратором.
Когда на всю колонку для всех пользователей один ключ (даже если не для всех, а для клиентов ограниченного набора), — это не всегда хорошо и правильно. Именно поэтому начали делать end-to-end шифрование, в СУБД стали рассматривать варианты шифрования данных со стороны клиента и сервера, появились те самые key-vault хранилища — отдельные продукты, которые обеспечивают управление ключами на стороне СУБД.

Средства безопасности в коммерческих и open source СУБД
| Функции | Тип | Password Policy | Audit | Защита исходного кода процедур и функций | RLS | Encryption |
| Oracle | Коммерческая | + | + | + | + | + |
| MsSql | Коммерческая | + | + | + | + | + |
| Jatoba | Коммерческая | + | + | + | + | extensions |
| PostgreSQL | Free | extensions | extensions | - | + | extensions |
| MongoDb | Free | - | + | - | - | Available in MongoDB Enterprise only |
Таблица далеко не полная, но ситуация такая: в коммерческих продуктах задачи безопасности решаются давно, в open source, как правило, для безопасности используют какие-то надстройки, многих функций не хватает, иногда приходится что-то дописывать. Например, парольные политики — в PostgreSQL много разных расширений (1, 2, 3, 4, 5), которые реализуют парольные политики, но все потребности отечественного корпоративного сегмента, на мой взгляд, ни одно не покрывает.
Что делать, если нигде нет того, что нужно? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
Тогда можно использовать сторонние решения, которые работают с разными СУБД, например, «Крипто БД» или «Гарда БД». Если речь о решениях из отечественного сегмента, то там про ГОСТы знают лучше, чем в open source.
Второй вариант — самостоятельно написать, что нужно, реализовать на уровне процедур доступ к данным и шифрование в приложении. Правда, с ГОСТом будет сложнее. Но в целом — вы можете скрыть данные, как нужно, сложить в СУБД, потом достать и расшифровать как надо, прямо на уровне application. При этом сразу думайте, как вы будете эти алгоритмы на application защищать. На наш взгляд, это нужно делать на уровне СУБД, потому что так будет работать быстрее.
В 4:26 поступил вопрос в раздел Базы данных, который вызвал затруднения у обучающегося.
Вопрос вызвавший трудности
Когда хранение базы данных и доступ к ней осуществляются на одном компьютере?Для того чтобы дать полноценный ответ, был привлечен специалист, который хорошо разбирается требуемой тематике "Базы данных". Ваш вопрос звучал следующим образом: Когда хранение базы данных и доступ к ней осуществляются на одном компьютере?
После проведенного совещания с другими специалистами нашего сервиса, мы склонны полагать, что правильный ответ на заданный вами вопрос будет звучать следующим образом:
-
Ответ: в случае локальной базы данных
НЕСКОЛЬКО СЛОВ ОБ АВТОРЕ ЭТОГО ОТВЕТА:

Работы, которые я готовлю для студентов, преподаватели всегда оценивают на отлично. Я занимаюсь написанием студенческих работ уже более 4-х лет. За это время, мне еще ни разу не возвращали выполненную работу на доработку! Если вы желаете заказать у меня помощь оставьте заявку на этом сайте. Ознакомиться с отзывами моих клиентов можно на этой странице.
Некрасова Карина Германовна - автор студенческих работ, заработанная сумма за прошлый месяц 61 777 рублей. Её работа началась с того, что она просто откликнулась на эту вакансию
ПОМОГАЕМ УЧИТЬСЯ НА ОТЛИЧНО!
Выполняем ученические работы любой сложности на заказ. Гарантируем низкие цены и высокое качество.
Деятельность компании в цифрах:
Зачтено оказывает услуги помощи студентам с 1999 года. За все время деятельности мы выполнили более 400 тысяч работ. Написанные нами работы все были успешно защищены и сданы. К настоящему моменту наши офисы работают в 40 городах.
Ответы на вопросы - в этот раздел попадают вопросы, которые задают нам посетители нашего сайта. Рубрику ведут эксперты различных научных отраслей.
Полезные статьи - раздел наполняется студенческой информацией, которая может помочь в сдаче экзаменов и сессий, а так же при написании различных учебных работ.
Красивые высказывания - цитаты, афоризмы, статусы для социальных сетей. Мы собрали полный сборник высказываний всех народов мира и отсортировали его по соответствующим рубрикам. Вы можете свободно поделиться любой цитатой с нашего сайта в социальных сетях без предварительного уведомления администрации.
Читайте также: