
Как узнать размер кэш линии
N>Хотелось бы получить универсальный код для любого процессора и для любой ОС Windows, начиная с Win2000.
Ядро Windows 2000 не поддерживает запросы для данного класса информации.
Здравствуйте, neokoder, Вы писали:
N>Хотелось бы получить универсальный код для любого процессора и для любой ОС Windows, начиная с Win2000.
Для x86 начиная с P6: инструкция cpuid с eax = 2.
Обязательно бахнем! И не раз. Весь мир в труху! Но потом. (ДМБ)Здравствуйте, ДимДимыч, Вы писали:
ДД>Для x86 начиная с P6: инструкция cpuid с eax = 2.
А можно код полностью, а то я не силён в ассемблере. Мне нужно просто сохранить значение размера кеш-линии в переменной, чобы ею пользоваться.
Могли бы вы функцию на асме написать, которая бы возвращала размер кеш-линии?
Здравствуйте, neokoder, Вы писали:
N>А можно код полностью, а то я не силён в ассемблере. Мне нужно просто сохранить значение размера кеш-линии в переменной, чобы ею пользоваться.
N>Могли бы вы функцию на асме написать, которая бы возвращала размер кеш-линии?
Ассемблер там нужен только для того, чтобы вызвать cpuid, остальное можно сделать на C.
К сожалению, я не настолько помню ассемблер для виндовс, чтобы без компилятора под рукой написать рабочий код, а для gcc он может быть примерно таким:
Более подробный список дескрипторов кешей см. Application note 485, 5.1.3 Cache Descriptors.
Обязательно бахнем! И не раз. Весь мир в труху! Но потом. (ДМБ)Здравствуйте, ДимДимыч, Вы писали:
Спасибо, сейчас буду пробоваать.
Работает не на всех процессорах этот пример.
Или не во всех ОС аналогично GetLogicalProcessorInformation. В общем у меня на одном компе не заработало, там же где и GetLogicalProcessorInformation не показал размер кеш-линии.N>Или не во всех ОС аналогично GetLogicalProcessorInformation. В общем у меня на одном компе не заработало, там же где и GetLogicalProcessorInformation не показал размер кеш-линии.
__cpuid(. ) это intrinsic-функция и к программной платформе не имеет отношения. Компилятор просто вставит вызов инструкции cpuid с указанными параметрами. А если такую информацию не возвращает процессор, то тут ничего не поделаешь.
P.S. в реализацию примера не вчитывался, в MSDN неточности и ошибки в примерах не редкость.
Но думаю, что дело именно в процессоре целевой машины.
Здравствуйте, EreTIk, Вы писали:
А если такую информацию не возвращает процессор, то тут ничего не поделаешь.
Но думаю, что дело именно в процессоре целевой машины.
Очень часто со стороны программистов можно заметить утверждение
"Вот эти данные скорее всего попадут в кеш линию процессора" - на чем основываются программисты, когда делают подобные выводы?
Еще интересует то, что если данные которые претендуют на попадание в кеш превышают размер одной линейки кеша, могут ли они сохраниться сразу в двух линейках последовательно?
Например есть массив
L1 ---60% от последовательных данных---
L2 ---40% от последовательных данных(а остаток свободного места занят другими данными)---
Кеш процессора
Задание Написать программу, многократно выполняющую чтение элементов массива заданного размера.
Не обновляется кеш для потоков
сделал такую штуку: vector<short> done(hard_concur, 1); void task_for_thread(size_t idThread)

Производительность CPU, КЕШ, многопоточность
Доброго времени суток! Суть проблемы - есть курсовой по системному программированию но я не знаю.
Как поместить переменную в кеш процессора
мы знаем, что некоторая переменная будет использоваться очень часто, как поместить ее в кеш.
Решение
Кэш лайн - это сплошной кусок памяти размером в 32 байта, выровненный на такой же размер. Этот размер может быть 64 или 128 байт (или . ) - зависит от конкретного устройства процессора. Для простоты буду называть его словами "32 байта".
При обработке запроса в память со стороны процессорв, реальное обращение в память происходит кусками по 32 байта. Т.е. если мы читаем из памяти 1 байт, то в реальности прочтётся кусок размером 32 байта с адреса, выровненного на 32. И весь этот кусок попадёт в кэш в виде кэш-лайна. Допустим, мы читаем байт по адресу 65, в реальности из памяти прочтётся 32 байта из диапазона адресов 64-95 и весь этот кусок памяти осядет в кэше, а до исполнительного устройства дойдёт только один нужный байт. Если после этого мы захотим прочесть один байт по адресу 66, то он уже прочтётся из кэша
"Вот эти данные скорее всего попадут в кеш линию процессора" - на чем основываются программисты, когда делают подобные выводы?Например, у нас горячим является массив размером 1024 байта. Если мы его разместим в памяти по адресу, выровненному на 32, то мы будем уверены в том, что 32-й, 33-й, . 63-й байты этого массива попадут в один кэшлайн
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.
Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
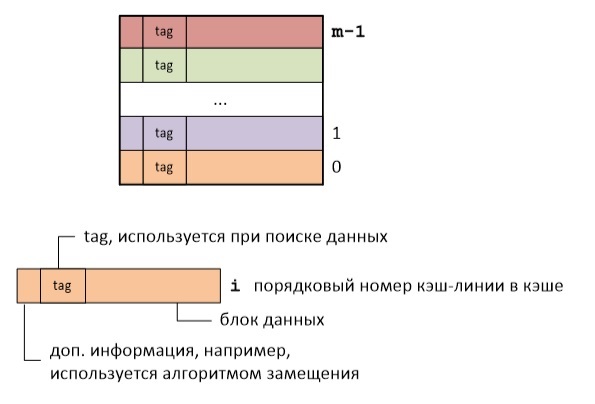
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.

Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
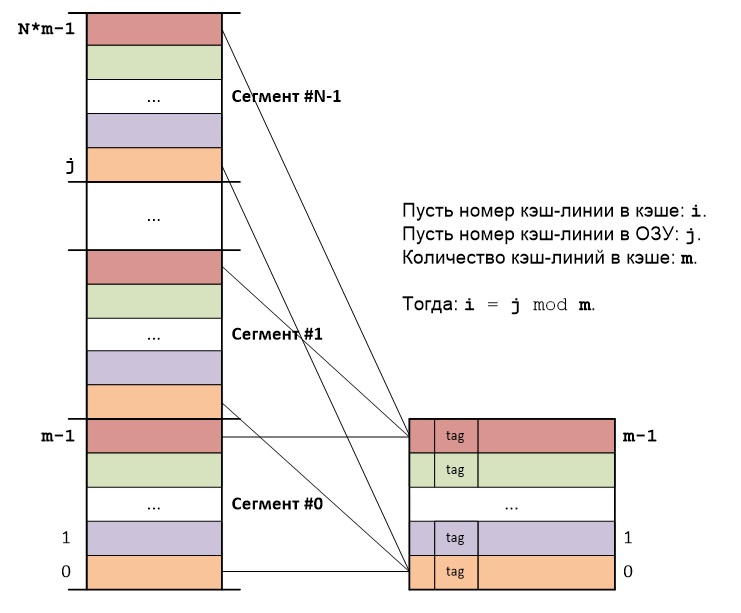
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
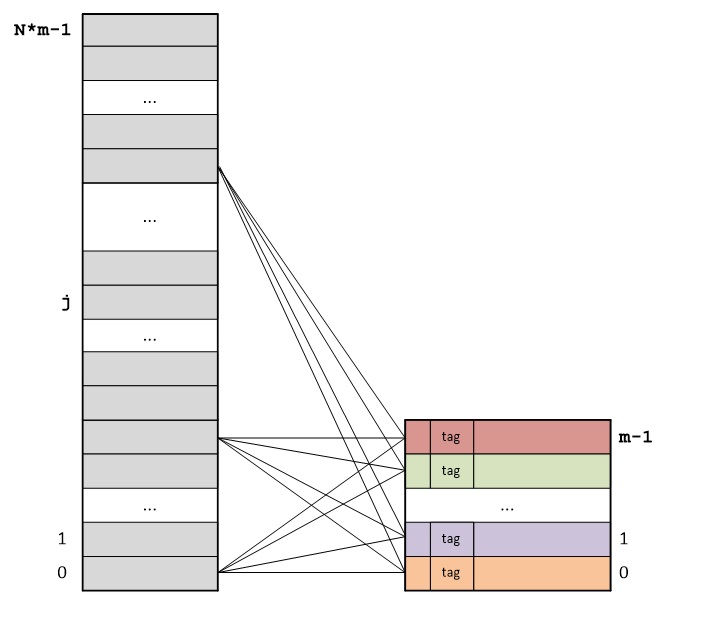
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.
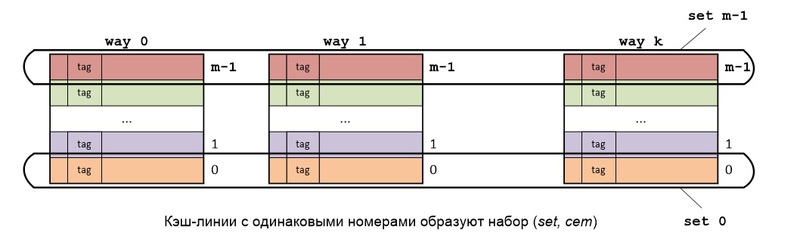
Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
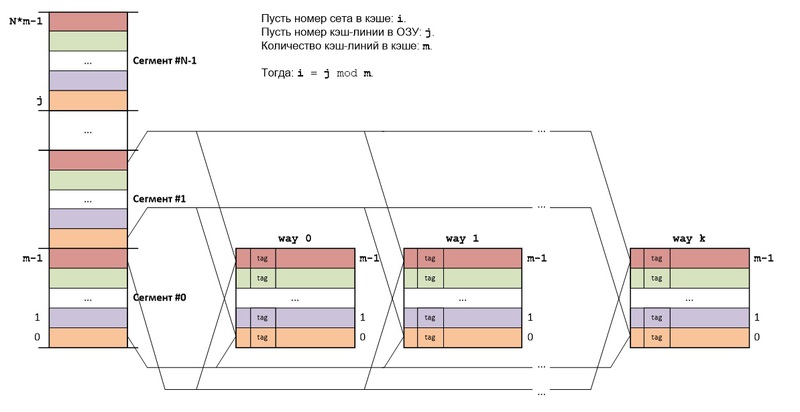
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.
В качестве школьного задания мне нужно найти способ получить размер строки кэша данных L1 без чтения файлов конфигурации или использования вызовов api. Предполагается использовать тайминги чтения / записи доступа к памяти для анализа и получения этой информации. Так как я могу это сделать?
В неполной попытке выполнить другую часть задания, чтобы найти уровни и размер кеша, у меня есть:
Я подумал, может, мне просто нужно изменить строку 2, часть (i * 4) ? Итак, как только я превысил размер строки кеша, мне может потребоваться заменить ее, что займет некоторое время? Но так ли все просто? Требуемый блок может уже быть где-то в памяти? Или, может быть, я все еще могу рассчитывать на то, что если у меня будет достаточно большой steps , он все равно будет работать довольно точно?
ОБНОВЛЕНИЕ
Попытка на GitHub . основная часть ниже
Проблема в том, что, похоже, нет большой разницы во времени. К вашему сведению. так как это для кеша L1. У меня РАЗМЕР = 32 К (размер массива)
Выделите БОЛЬШОЙ массив char (убедитесь, что он слишком большой, чтобы поместиться в кэш L1 или L2). Заполните его случайными данными.
Начните обходить массив с шагом в n байт. Сделайте что-нибудь с полученными байтами, например суммируйте их.
Оцените и вычислите, сколько байтов в секунду вы можете обработать с разными значениями n , начиная с 1 и считая до 1000 или около того. Убедитесь, что ваш тест выводит вычисленную сумму, чтобы компилятор не смог оптимизировать тестируемый код.
Когда n == размер вашей строки кэша, каждый доступ потребует чтения новой строки в кэш L1. Так что на этом этапе результаты тестов должны резко замедлиться.
Если массив достаточно велик, к тому времени, когда вы дойдете до конца, данные в начале массива снова будут вне кеша, а это то, что вам нужно. Таким образом, после увеличения n и повторного запуска на результаты не повлияет наличие необходимых данных в кэше.
Размер строки кэша является переменным в некоторых семействах ARM Cortex и может изменяться во время выполнения без каких-либо уведомлений для текущей программы.
Я думаю, этого должно хватить, чтобы рассчитать время для операции, которая использует некоторый объем памяти. Затем постепенно увеличивайте память (например, операнды), используемую операцией. Когда производительность операции резко падает, вы нашли предел.
Я бы просто прочитал кучу байтов, не печатая их (печать так сильно снизила бы производительность, что стала бы узким местом). При чтении время должно быть прямо пропорционально количеству прочитанных байтов до тех пор, пока данные не перестанут соответствовать L1, тогда вы получите удар производительности.
Вы также должны выделить память один раз в начале программы и перед началом отсчета времени.
Посмотрите, как реализован memtest86. Они каким-то образом измеряют и анализируют скорость передачи данных. Точки изменения скорости соответствуют размеру L1, L2 и возможному размеру кэша L3.
Вы можете использовать функцию CPUID в ассемблере, хотя она и не является переносимой, но она даст вам то, что вы хотите.
Для микропроцессоров Intel размер строки кэша можно рассчитать, умножив bh на 8 после вызова функции cpuid 0x1.
Для микропроцессоров AMD размер строки кэша данных находится в cl, а размер строки кэша инструкции - в dl после вызова функции cpuid 0x80000005.
Взгляните на Calibrator, вся работа защищена авторским правом, но исходный код находится в свободном доступе. Из его документа идея расчета размеров строк кэша звучит гораздо более обоснованно, чем то, что уже было сказано здесь.
Идея, лежащая в основе нашего калибратора, состоит в том, чтобы создать микротест, производительность которого зависит только от от частоты промахов в кэше. Наш калибратор - это простая программа на C, в основном небольшая петля. который выполняет миллион чтений из памяти. Путем изменения шага (т. Е. Смещения между двумя последующими доступ к памяти) и размер области памяти, мы принудительно изменяем частоту промахов кэша.
В принципе, количество промахов в кэше определяется размером массива. Размеры массивов, которые подходят кэш L1 не генерирует никаких промахов кеша после загрузки данных в кеш. Аналогично, массивы, которые превышают размер кэша L1, но все же помещаются в L2, будут вызывать промахи L1, но не промахи L2. Наконец, массивы больше L2 вызывают пропуски L1 и L2.
Частота промахов кеша зависит от шага доступа и размера строки кеша. Шагами равный или больший, чем размер строки кэша, пропуск кэша происходит при каждой итерации. Шагами меньше размера строки кэша, пропуск кэша происходит только каждые n итераций (в среднем), где n равно кэш отношения линия размер / шаг.
Таким образом, мы можем рассчитать задержку для промаха кеша, сравнив время выполнения без пропуски времени выполнения ровно с одним промахом на итерацию. Этот подход работает, только если доступ к памяти выполняется чисто последовательно, т. е. мы должны убедиться, что ни два, ни более загруженных ни инструкции, ни доступ к памяти и чистая работа ЦП не могут перекрываться. Используем простую погоню за указателем механизм для достижения этого: область памяти, к которой мы обращаемся, инициализируется таким образом, что каждая загрузка возвращает адрес для последующей загрузки в следующей итерации. Таким образом, суперскалярные процессоры не могут получить выгоду от их способность скрывать задержку доступа к памяти с помощью спекулятивного исполнения.
Чтобы измерить характеристики кеша, мы запускаем наш эксперимент несколько раз, варьируя шаг и размер массива. Мы следим за тем, чтобы шаг варьировался как минимум от 4 байтов до двукратного максимального значения. ожидаемый размер строки кэша, и что размер массива варьируется от половины минимального ожидаемого размера кеша до как минимум в десять раз больше максимального ожидаемого размера кэша.
Если вы застряли в грязи и не можете выбраться, посмотрите здесь.
Есть руководства и код, объясняющий, как делать то, о чем вы просите. Код тоже довольно качественный. Посмотрите "Библиотеку подпрограмм".
чтобы предотвратить ложное совместное использование, Я хочу выровнять каждый элемент массива по строке кэша. Поэтому сначала мне нужно знать размер строки кэша, поэтому я назначаю каждому элементу такое количество байтов. Во-вторых, я хочу, чтобы начало массива было выровнено по строке кэша.
таким образом, структура будет следовать для пример, предполагающий размер строки кэша 64.
и так далее, предполагая, конечно, что 0-63 выровнен по строке кэша.
чтобы узнать размеры, вам нужно посмотреть его с помощью документации для процессора, afaik нет программного способа сделать это. С другой стороны, большинство строк кэша имеют стандартный размер, основанный на стандартах intels. На x86 строки кэша составляют 64 байта, однако, чтобы предотвратить ложное совместное использование, вам нужно следовать рекомендациям процессора, на который вы нацелены (intel имеет некоторые специальные заметки о своих процессорах на основе netburst), как правило, вам нужно выровнять до 64 байт для этого (intel состояния что вы также должны избегать пересечения границ 16 байт).
для этого в C или C++ требуется использовать стандарт aligned_alloc функция или один из специфических спецификаторов компилятора, таких как __attribute__((align(64))) или __declspec(align(64)) . Чтобы проложить между членами в структуре, чтобы разделить их на разные строки кэша, вам нужно вставить член, достаточно большой, чтобы выровнять его со следующим 64-байтовым boundery
передать значение в качестве определения макроса компилятор.
во время sysconf(_SC_LEVEL1_DCACHE_LINESIZE) можно использовать для получения размера кэша L1.
нет полностью портативного способа получить размер cacheline. Но если вы находитесь на x86 / 64, вы можете вызвать cpuid обучение, чтобы получить все, что нужно знать о кэше, включая размер, размер строки кэша, сколько уровней и т. д.
(прокрутите немного вниз, страница о SIMD, но у нее есть раздел, получающий cacheline.)
что касается выравнивания данных структуры, также нет полностью портативного способа сделать это. GCC и VS10 имеют разные способы указать выравнивание структуры. Один из способов "взломать" - заполнить вашу структуру неиспользуемыми переменными, пока она не будет соответствовать нужному выравниванию.
чтобы выровнять mallocs (), все основные компиляторы также имеют выровненные функции malloc для этой цели.
еще один простой способ-просто cat /proc / cpuinfo:
cat/proc | cpuinfo / grep cache_alignment
posix_memalign или valloc может использоваться для выравнивания выделенной памяти к строке кэша.
если кому-то интересно, как это сделать легко в C++, я построил библиотеку с CacheAligned<T> класс, который обрабатывает определение размера строки кэша, а также выравнивание для вашего T "объект", на который ссылается вызов .Ref() на
Читайте также: