
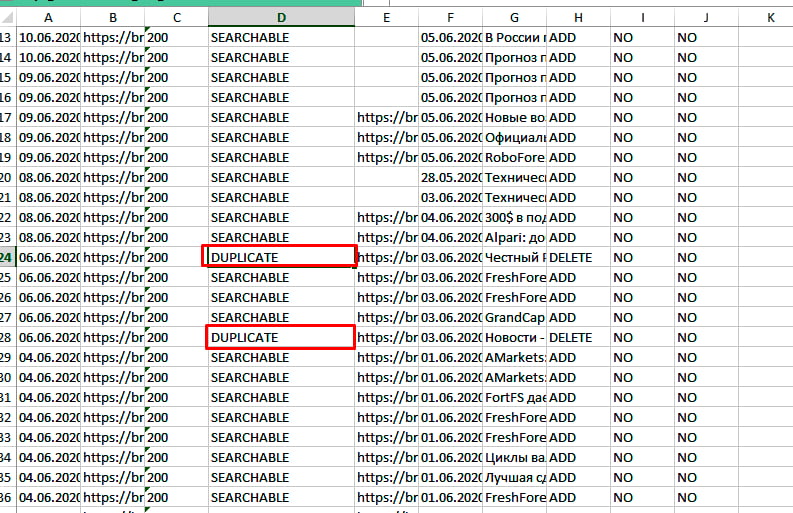
Как склеить дубли страниц на сайте
Дубли страниц это две или более страниц одного сайта, которые содержат идентичный или схожий контент. Довольно часто дубли — одна и та же страница сайта, доступная по разным url
Проблемы к которым приводят дубли страниц
- Постоянная смена релевантной страницы
- Обход роботом дублирующего контента
- Затруднение сбора статистики
- Неправильно распределяется внутренний ссылочный вес
- Потеря внешнего ссылочного веса
Виды дублей
Явные дубли - полностью идентичный контент
7. Если вы крутите рекламу то обязательно используете UTM-метки, обычно такие страницы тоже попадают в индекс.
8. Админки сайта выводят некоторые страницы используя GET-параметры
10. Не правильно настроенная страница с выводом ошибки 404. Если вы в адресной строке после домена добавляете любое значение он становится ссылкой.
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению

Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.

SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →
Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.
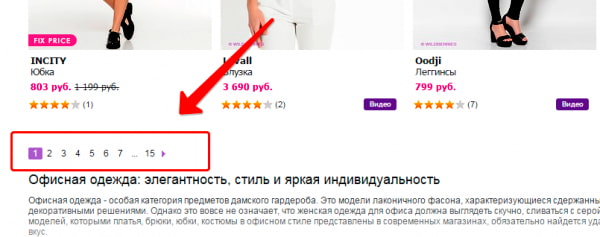
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
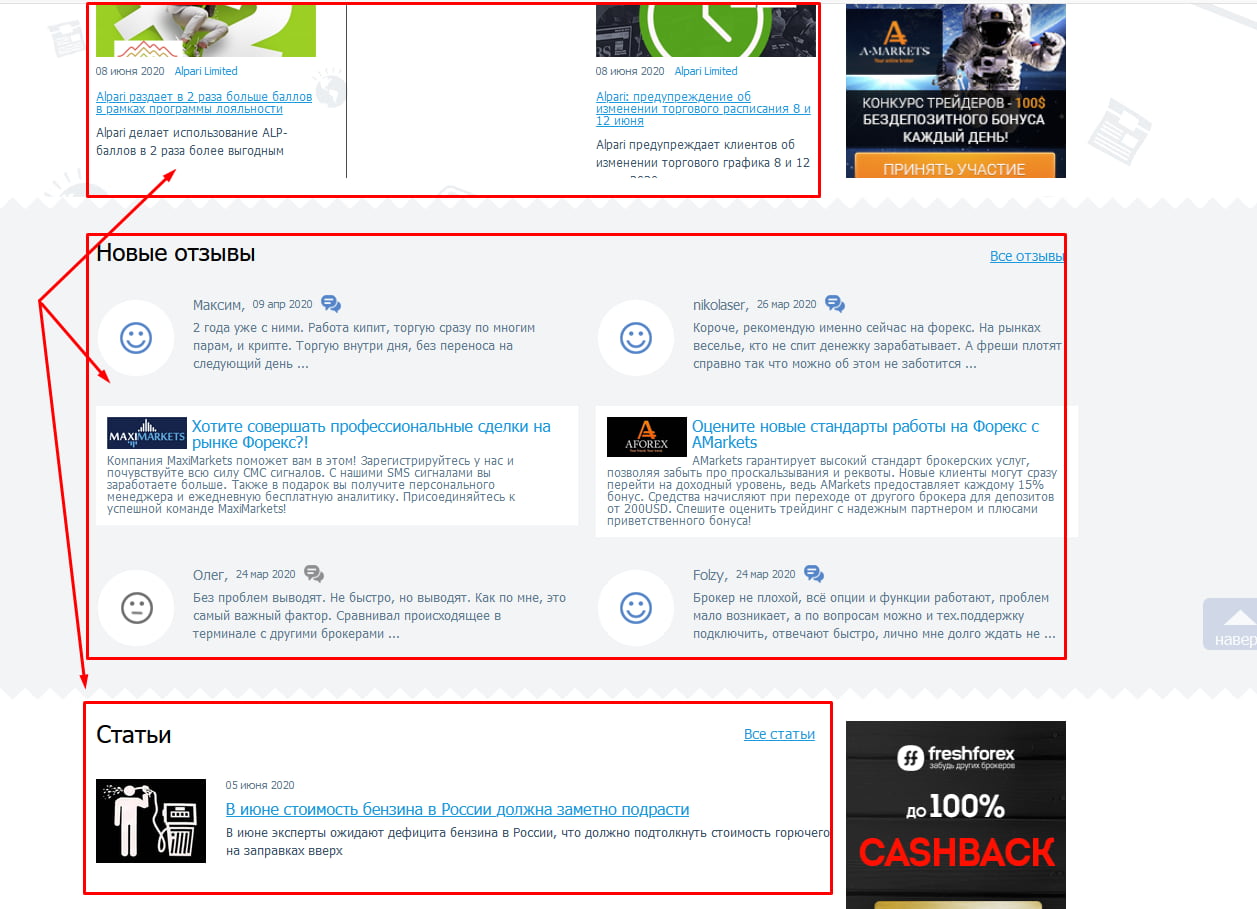
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
С применением команды site
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
-
– бесплатная; – от $15 в месяц, но есть 14-дневный trial; – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
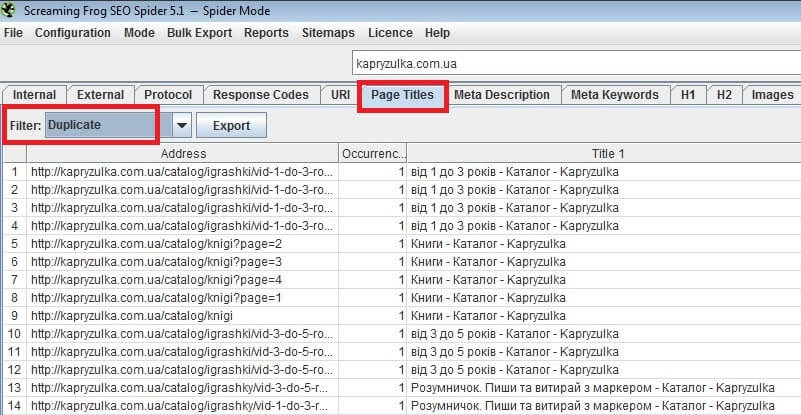
Вот пример того, как ищет дубликаты программа Screaming Frog:
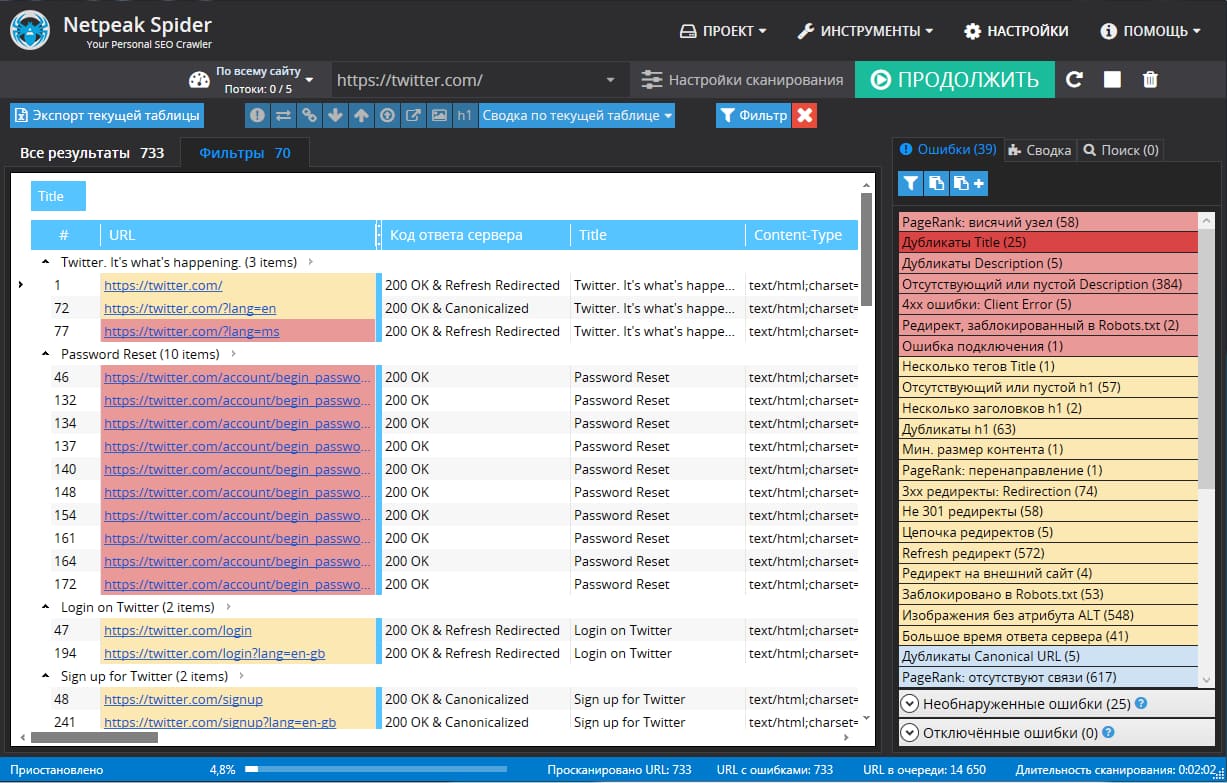
А вот как можно проверить дубли страниц в NetPeak:
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег , который помещают в шапку между открывающим тегом и закрывающим . Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:

Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом и закрывающим , и выглядит он так:
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
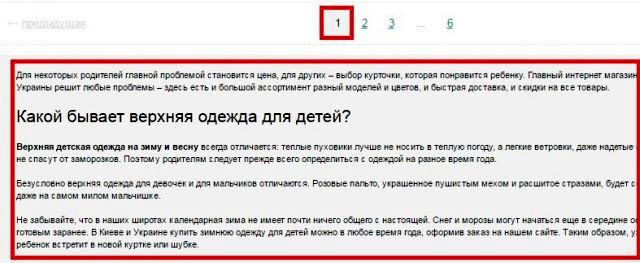
Выше на скрине 1-я страница каталога, а вот вторая:
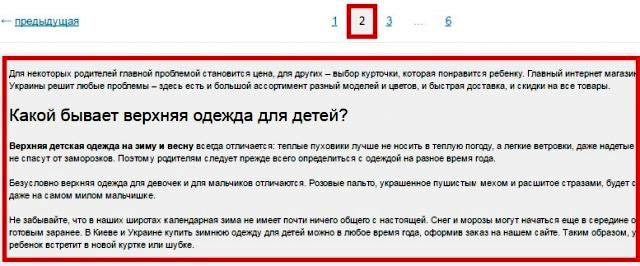
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.
5 способов избавится от дубликатов страниц на вашем сайте
Как возникают дубликаты страниц
Основные причины появления дублей — несовершенство CMS сайта, практически все современные коммерческие и некоммерческие CMS генерируют дубли страниц. Другой причиной может быть низкий профессиональный уровень разработчика сайтов, который допустил появление дублей.
Какие бывают дубли страниц
Какую опасность несут в себе дубли страниц
Представьте себе что вы читаете книгу где на страничках одинаковый текст, или очень похожий. Насколько полезна для вас такая информация? В таком же положении оказываются и поисковые машины, ища среди дубликатов вашего сайта то полезное содержимое которое необходимо пользователю.
Поисковые машины не любят такие сайты, следовательно ваш сайт не займет высокие позиции в поиске, и это несет для него прямую угрозу.
Как обнаружить дубликаты на сайте
1. С помощью команды site:site.ua можете проверить какие именно дубли попали в индекс поисковой машины.
2. Введите отрывки фраз с вашего сайте в поиск, таким образом обнаружите страницы на которых она присутствует
3. Инструменты для веб-мастеров Google, в разделе Вид в поиске → Оптимизация HTML, можете увидеть страницы, на которых есть повторяющееся метаописание или заголовки.
5 способов удалить дубликаты страниц
Таким образом, дадим знать поисковой машине, что странички, которые содержат параметры ?, index.php?, не должны индексироваться.
.htaccess — это файл конфигурации сервера Apache, находится в корне сайта. Позволяет настраивать конфигурацию сервера для отдельно взятого сайта.
Функция Параметры URL позволяют запретить Google сканировать странички сайта с определенными параметрами
4. Мета тег noindex — это самый действенный способ удаления дубликатов. Удаляет навсегда и бесповоротно.
Важно. Для того что бы робот смог удалить страничку, он должен ее проиндексировать, то есть она не должна быть закрыта от индексации в файле robots.txt.
Подведем итог. При разработке сайта учитывайте возможности появления дублей и заранее определяйте способы борьбы с ними. Создавайте правильную структуру сайта (подробнее здесь).
Проверяйте периодически количество страниц в индексе, и используйте возможности панели Инструментов для веб-мастеров.
Теперь разберемся, откуда на сайте появились страницы с одинаковыми заголовками. Вариантов тут немного: либо вы сами создали пачку дублей, либо же они сгенерировались автоматом.
90% дублей страниц я нахожу в следующих местах:
Я тегирую дубли страниц по характеру их образования и сразу прикидываю, что с ними делать: удалять и склеивать, менять заголовок H1, или же закрывать от индексации.
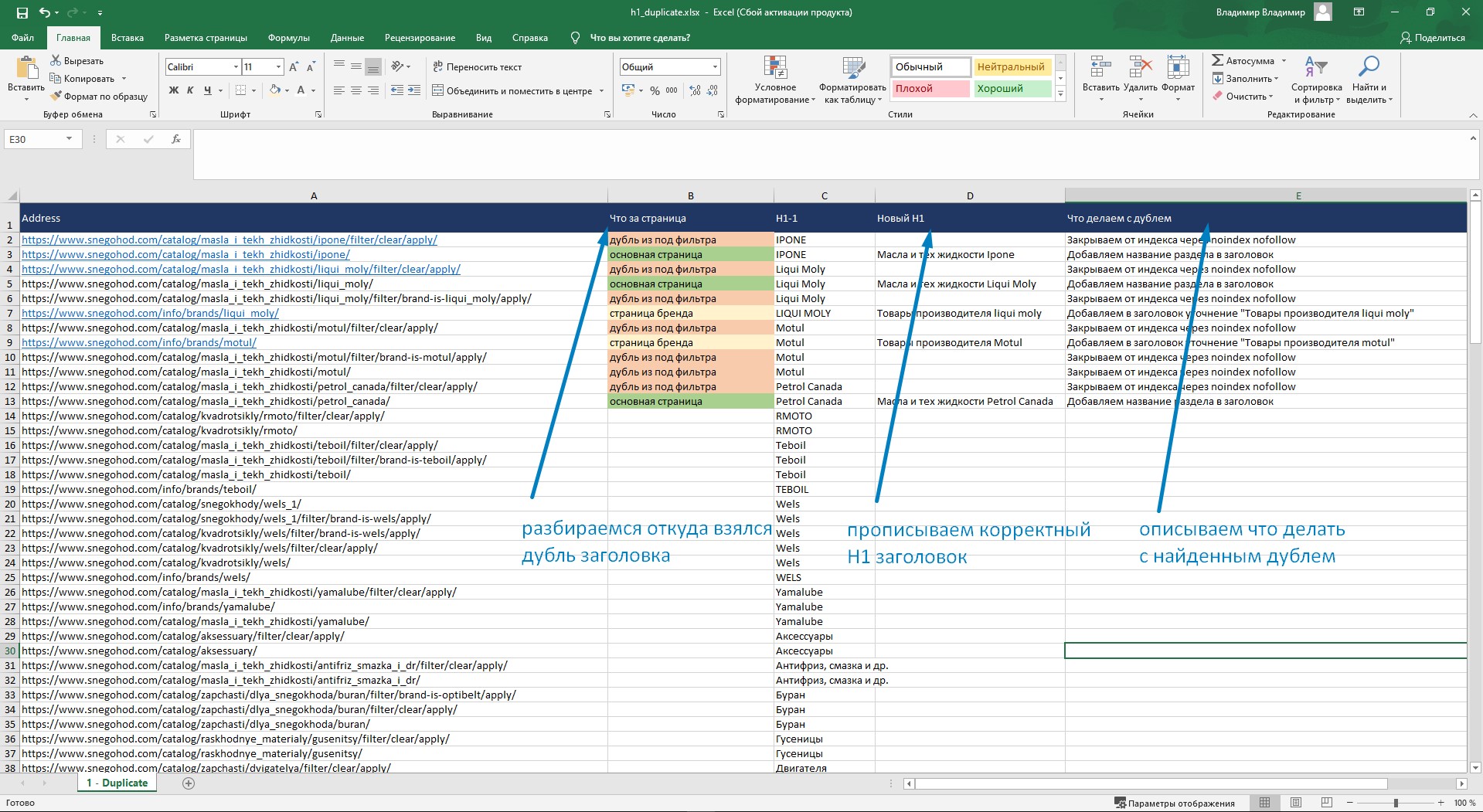
Удаление явных дублей страниц
После склейки страниц проверьте, не осталось ли битых ссылок.
Добавляем директивы в robots.txt
В дополнение нужно закрыть дубли в robots.txt
Для того чтобы закрыть от индексации URL, в которых есть знак "?", добавьте в robots.txt следующую строку:
Вместо знака вопроса можно добавить любой фрагмент дубликата страниц. Например:
Дубли из-под фильтра:
У дублей в примере есть кое-что схожее, в них встречается " apply " и " filter ".
Для того чтобы закрыть все возможные дубли страниц в моем случае, нужно добавить сл. директивы в robots.txt:
Виды дублей страниц
Я разделяю дубли на 2 типа:
- Явные – полный дубль страницы. Их генерируют движки сайтов (Битрикс, Wordpress, OpenCart, и др.). Как их искать и удалять мы разобрали выше.
- Неявные – похожая по смыслу страница, воспринимаемая поисковиком как дубль. Такие дубли создают сами пользователи по глупости. Как с ними работать — тема для отдельной статьи.

Пишу про SEO и маркетинг, опираясь на 10 летний опыт работы! Более 300 проектов толкнул в ТОП.

Дублирование контента — довольно распространённая проблема не только сайтов электронной коммерции, но и других типов веб-ресурсов. И хотя из-за одних лишь дублей сайт не будет наказан поисковыми системами, их основная угроза для оптимизатора в том, что они препятствуют продвижению отдельных страниц.
В рамках этого поста я расскажу, что такое дубли, и какой ещё вред они могут нанести, как их найти и устранить.
1. Что такое дубликаты, и в чём их опасность
Дубли — это страницы с одинаковым или частично одинаковым содержимым. Когда по разным адресам доступны страницы с идентичным контентом, поисковые системы попросту не могут отличить одну страницу от другой и считают их равноценными. Поэтому в результатах выдачи может оказаться URL, который там быть не должен.
Для больших сайтов наличие дубликатов может представлять ещё одну опасность — из-за ограничений краулингового бюджета поисковые роботы могут не просканировать приоритетные URL, потратив основные ресурсы на обход дублей страниц.
2. Причины возникновения дубликатов
К самым распространённым причинам появления дублей страниц можно отнести следующие:
Причиной появления дубликатов title, description и H1 чаще всего является неправильная оптимизация (или её отсутствие) страниц, на которых содержание этих элементов генерируется автоматически по неверно настроенным шаблонам.
3. Типы дубликатов и способы их устранения
В пределах одного сайта могут встречаться следующие типы дубликатов:
- дубликаты страниц;
- дубликаты текста;
- дубликаты тегов title;
- дубликаты meta description;
- дубликаты заголовков H1.
Ниже я рассмотрю все типы дубликатов и расскажу, чем они грозят.
2.1. Дубликаты страниц
Дубли страниц — это идентичное содержимое всего HTML-кода на разных страницах. В незначительном количестве дубликаты страниц не станут причиной санкций со стороны поисковых систем, но если их на сайте много, это чревато растратой краулингового бюджета.
Как устранить дубликаты страниц: настройте 301 редирект с дубликатов на основной адрес страницы. Если страницу нужно удалить, настройте корректный 404 код ответа сервера и удалите все ссылки, которые вели на эту страницу.
2.2. Дубликаты текста
Как устранить дубли текста: заменить дублированный текст на уникальный. С не приоритетных для продвижения страниц можно настроить 301 редирект на основной URL страницы или же просто их удалить, выставив 404 код ответа сервера.
2.3. Дубликаты title
Тег title играет значительную роль в продвижении сайта, так как служит заголовком сниппета в поисковой выдаче. Его дублирование может привести к появлению в выдаче страниц, названия которых не соответствуют содержимому. В таких случаях поисковая система может сама составить заголовок сниппета, который с большой вероятностью будет совсем не кликабельным с точки зрения пользователей. Итог — потеря трафика из выдачи.
Как устранить дублированные title: для каждой страницы сайта необходимо прописать уникальный тег title, который будет сообщать пользователям и поисковым системам о содержимом страницы и содержать релевантный поисковой запрос. Рекомендованная поисковиками длина тега title составляет от 40 до 140 символов.
2.4. Дубликаты description
Метаописание влияет на формирование сниппета и непосредственно на CTR.
Потому важно, чтобы метаописание каждой отдельной страницы соответствовало её содержимому и побуждало пользователей перейти на сайт.
Как устранить дублированные description: оформить уникальные метаописания с содержанием релевантных ключевых слов для каждой целевой страницы. Рекомендуемая длина — от 100 до 260 символов.
2.5. Дубликаты H1
Если на страницах с разным контентом содержатся идентичные заголовки H1, поисковые роботы и посетители могут посчитать сайт некачественным.
Как устранить дубликаты заголовков H1: составить для каждой страницы уникальный, краткий и информативный заголовок длиной от трёх до семи слов.
3. Как найти дубли на сайте
Мы уже выяснили, в чём опасность дубликатов, и каких типов они бывают. Пора разобраться с главной задачей — найти их на своём сайте.
Сделать это можно в панелях вебмастеров Google и Яндекс.
Существует также ручной способ поиска дублей с помощью оператора site:.
В поисковую строку введите фрагмент текста, затем добавьте поисковый оператор и домен сайта.

Чтобы не искать дубликаты вручную, советуем провести быстрый поиск каждого из типов дублей на сайте в Netpeak Spider.

Мы подготовили короткое и наглядное видео о том, как проверить дубликаты страниц и контента на сайте:
Находить дубликты и другие SEO-ошибки, а также работать со многими базовыми функциями вы можете в бесплатной версии Netpeak Spider без ограничений по времени использования!
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
Подводим итоги
Дубликаты вредят продвижению страниц в органической выдаче — из-за них ваше время и ресурсы, вложенные в оптимизацию, тратятся впустую. Опасность заключается также в том, что дубликаты могут появляться и не по вашей вине. Регулярный анализ сайта на наличие дублей и своевременное их устранение — лучший способ не дать им шанса негативно повлиять на продвижение.
Искать дубли можно в панели вебмастеров, с помощью поискового оператора и краулера Netpeak Spider.
Самые действенные способы избавления от дублей страниц:
Для устранения дубликатов title, description и H1 необходимо на каждой странице заполнить эти элементы контента уникальным текстом и желательно оформить согласно рекомендациям поисковых систем.
Читайте также: