
Как распарсить csv файл
Разбор файла Comma Separated Value (CSV) поначалу кажется достаточно простым. Однако эта задача весьма быстро становится все более сложной по мере того, как проясняются болевые точки CSV-файлов. Если вы не знакомы с этим форматом, то CSV-файлы хранят данные в виде чистого текста. Каждая строка в файле образует запись. В каждой записи есть поля, обычно отделяемые запятыми, отсюда и произошло название формата — значения, разделенные запятыми.
Сегодня разработчики используют стандартные форматы для обмена данными. Формат CSV восходит к ранним временам программной индустрии еще до появления JSON и XML. Хотя существует документ RFC (Request for Comments) для CSV-файлов (bit.ly/1NsQlvw), он не имеет официального статуса. Кроме того, он был создан в 2005 году, десятилетия спустя после того, как CSV-файлы начали появляться еще в 1970-х. В итоге существует довольно много вариаций CSV-файлов, и правила не совсем внятны. Например, поля CSV-файла могут разделяться табуляторами, точками с запятой или любым символом.
На практике стандартом де-факто стала Excel-реализация импорта и экспорта CSV, и именно она чаще всего встречается в индустрии — даже за пределами экосистемы Microsoft. Соответственно предположения, которые я допускаю в этой статье о «корректном» разборе и форматировании, будут базироваться на том, как Excel импортирует/экспортирует CSV-файлы. Большинство CSV-файлов отвечают реализации в Excel, тем не менее, таковыми являются не все файлы. В связи с этим я предложу стратегию для обработки такой неопределенности.
Возникает вопрос по существу: «Зачем писать средство разбора очень старого псевдоформата на самой новой платформе?». Ответ прост: во многих организациях имеются устаревшие системы, работающие с данными. Благодаря долгому существованию этого файлового формата почти все эти системы умеют экспортировать в CSV. Более того, экспорт данных в CSV требует минимума времени и усилий. А значит, существует множество CSV-файлов в наборах корпоративных и правительственных данных.
Проектирование средства разбора CSV универсального назначения
Несмотря на отсутствие официального стандарта CSV-файлы, как правило, имеют общие черты.
Вообще говоря, CSV-файлы являются чистым текстом, содержат по одной записи на строку, записи в каждой строке отделяются разделителем, имеют разделитель из одного символа и представляют поля в одинаковом порядке.
Эти общие черты обрисовывают универсальный алгоритм, который работал бы в три этапа.
- Разбиваем файл на строки по разделителю строк.
- Разбиваем каждую строку по разделителю полей.
- Присваиваем значение каждого поля какой-то переменной.
Это можно было бы реализовать сравнительно легко. Код на рис. 1 разбирает входную строку CSV в List<Dictionary<string, string>>.
Рис. 1. Разбор входной строки CSV в List<Dictionary<string,string>>
Этот подход отлично работает на примере следующего списка офисов, числа сотрудников и объемов продаж:
Чтобы получить значения из строки (string), вы должны были бы перебирать List и извлекать значения в Dictionary, используя индексацию полей от нуля. Например, получение поля офиса выглядело бы так:
Хотя это работает, код не столь читаем, каким мог бы быть.
Более эффективный словарь
Многие CSV-файлы включают строку заголовка (header row) для имени поля. Разработчикам было бы легче использовать средство разбора, если бы оно использовало имя поля в качестве ключа для словаря. Поскольку в конкретном CSV-файле может не оказаться строки заголовка, следует добавить свойство, сообщающее о наличии этой информации:
Например, образец CSV-файл со строкой заголовка мог бы выглядеть так:
В идеале, средство разбора CSV должно быть способно задействовать преимущества этой части метаданных. Это сделало бы код более читаемым. Получение поля Office Division выглядело бы следующим образом:
Пустые поля
Пустые поля часто встречаются в наборах данных. В CSV-файлах поле без информации представлено пустым полем в записи. При этом наличие разделителя все равно обязательно. Скажем, если для офиса East нет данных Employee, запись принимает такой вид:
Если же нет данных Unit Sales, а также данных Employee, запись выглядит так:
У каждой организации свои стандарты качества данных. Некоторые могут помещать в пустое поле значение по умолчанию, чтобы сделать CSV-файл более понятным человеку. Значения по умолчанию для чисел — это обычно 0 или NULL, а для строк — "" или NULL.
Сохранение гибкости
Учитывая всю неоднозначность файлового формата CSV, код не может делать никаких допущений. Нет никаких гарантий, что разделитель полей будет запятой, а разделитель записей — новой строкой.
Соответственно оба они будут свойствами класса CSVParser:
Чтобы упростить разработчикам использование этого компонента, нужно задать параметры по умолчанию, которые будут применяться в большинстве случаев:
Если кто-то пожелает изменить разделитель по умолчанию на табулятор, то необходимый код весьма прост:
Экранированные символы
Что будет, если само поле содержит символ-разделитель, например запятую? А если вместо объемов продаж по регионам данные содержат информацию о городе и штате? Как правило, в CSV-файлах эту проблему обходят, заключая все поле в кавычки наподобие:
Этот алгоритм превратил бы одно значение поля “New York, NY” в два отдельных поля со значениями, разбитыми по запятой: “New York” и “NY”.
В этом случае разделение названий города и штата может не оказаться не столь важным, но данные по-прежнему загрязняются дополнительными символами-кавычками. Хотя здесь их достаточно легко удалить, выполнить очистку более сложных данных может быть не так просто.
Теперь усложним задачу
Метод экранирования запятых внутри полей вводит необходимость в экранировании другого символа: кавычек. Что будет, если, например, в исходных данных были кавычки, как показано в табл. 1?
Табл. 1. Исходные данные с кавычками
| Office Division | Employees | Unit Sales | Office Motto |
| New York, NY | 73 | 8300 | “We sell great products” |
| Richmond, VA | 42 | 3000 | “Try it and you'll want to buy it” |
| San Jose, CA | 35 | 4250 | “Powering Silicon Valley!” |
| Chicago, IL | 18 | 1200 | “Great products at great value” |
Исходный текст в самом CSV-файле выглядел бы так:
Один символ кавычек (“) после экранирования превращается в три символа кавычек (“””), что добавляет алгоритму интересную особенность. Конечно, сразу же возникает резонный вопрос: почему одна кавычка превращается в три? Как и в поле Office Division, содержимое этого поля заключается в кавычки. Чтобы экранировать символы кавычек, которые являются частью контента, они удваиваются. Поэтому “ становится “”.
Другой пример (табл. 2) более наглядно продемонстрирует этот процесс.
Табл. 2. Данные цитат
| Quote |
| "The only thing we have to fear is fear itself." -President Roosevelt |
| "Logic will get you from A to B. Imagination will take you everywhere." -Albert Einstein |
Данные из табл. 2 были бы представлены в CSV следующим образом:
Теперь должно быть понятнее, что поле заключается в кавычки и что индивидуальные кавычки в содержимом поля удваиваются.
Пограничные случаи
Как уже упоминалось, не все файлы соответствуют Excel-реализации CSV. Отсутствие настоящей спецификации CSV затрудняет написание одного средства разбора для обработки всех существующих CSV-файлов. Пограничные случаи будут встречаться вне всяких сомнений, а значит, код должен оставлять дверь открытой для интерпретации и адаптации.
Инверсия управления спешит на помощь
Учитывая размытость стандарта CSV, не практично писать универсальное средство разбора для всех случаев. Гораздо разумнее писать средство разбора, подходящее для конкретных потребностей какого-либо приложения. Используя инверсию управления (Inversion of Control), вы можете адаптировать механизм разбора под конкретные требования.
С этой целью я создам интерфейс, определяющий две базовые функции синтаксического разбора: для получения записей и извлечения полей. Я решил сделать интерфейс IParserEngine асинхронным. Это гарантирует, что любое приложение, использующее этот компонент, не перестанет отвечать при разборе CSV-файла даже очень большого размера:
После этого я добавляю в класс CSVParser следующее свойство:
И предлагаю разработчикам выбор: использовать средство разбора по умолчанию или встроить собственное. Чтобы упростить эту задачу, я перегрузил конструктор:
Теперь класс CSVParser предоставляет базовую инфраструктуру, а реальная логика синтаксического анализа содержится в интерфейсе IParserEngine. Для удобства разработчиков я создал DefaultParserEngine, который может обрабатывать большинство CSV-файлов.
Задача для читателя
Я принял во внимание большинство вероятных сценариев, с которыми могут столкнуться разработчики при разборе CSV-файлов. Однако неопределенность природы CSV-формата делает непрактичным создание универсального средства разбора. Учет всех вариаций и пограничных случаев добавил бы существенные издержки и сложность наряду с негативным влиянием на производительность.
Уверен, что на практике вы встретите CSV-файлы, которые DefaultParserEngine не сумеет обработать. И здесь очень хорошо подходит шаблон встраивания зависимостей. Если разработчику нужно средство разбора, которое может обрабатывать пограничные случаи, или требуется написать нечто более производительное, это определенно приветствуется. Механизмы разбора можно заменять без изменений в коде-потребителе.
Заключение
CSV-файлы — пережиток прошлого, но, несмотря на наличие более удобных и эффективных форматов XML и JSON, по-прежнему широко используются как формат для обмена данными. CSV-файлам недостает общепринятой спецификации или стандарта, и, хотя у них много общих черт, вы не можете быть уверены, что ожидаемые символы окажутся в конкретном файле. Это делает разбор CSV-файла нетривиальным упражнением.
Будь на то выбор, большинство разработчиков, по-видимому, исключило бы CSV-файлы из своих решений. Однако их широкая распространенность в устаревших корпоративных и правительственных наборах данных препятствует этому в большинстве случаев.
Исходный код можно скачать по ссылке bit.ly/1To1IVI.
Выражаю благодарность за рецензирование статьи эксперту Рэчел Аппель (Rachel Appel).
Сбор данных из различных источников, преобразование с целью унифицирования либо удобства довольно распространенная задача. Конечно, в большинстве случаев можно обойтись собственным решением, но чтобы оно было гибким и легко расширяемым придется потратить немало времени. В таком случае разумным будет воспользоваться готовым решением. Talend Open Studio (TOS) одно из таких решений.
Меня несколько удивило отсутствие статей про работу с TOS на Хабре. Возможно, тому есть причины, мне непонятные. Как бы то ни было, постараюсь восполнить этот пробел.
Вероятно, при написании этой статьи я был излишне подробен в некоторых вопросах, поэтому некоторые инструкции я спрятал под спойлер.
Итак, TOS это Open Source решение для интеграции данных. Основным средством настройки процесса преобразования данных в TOS является специальный визуальный редактор, позволяющий добавлять и настраивать отдельные узлы преобразования данных и связи между ними.
Интересной особенностью и существенным плюсом TOS, на мой взгляд, является тот факт, что TOS преобразует наши компоненты и связи в код Java. По сути мы получаем библиотеку на Java с возможностью генерировать код на основе графа преобразования данных. Плюс мы можем собрать пакет и запустить его на любой машине, где есть Java и где может отсутствовать TOS.
Генерация кода дает нам еще один плюс — можно расширять возможности TOS путем написания собственного кода (для этого даже есть специальные инструменты).
Отдельное целостное преобразование данных в Talend называется задачей(job). Задача состоит из подзадач, которые, в свою очередь, состоят из компонент и связей. Компоненты непосредственно преобразуют данные либо занимаются вводом/выводом. Связи бывают нескольких типов. Основным средством обмена данными между компонентами являются связи типа “поток”(flow). Поток очень похож на таблицу в БД. У потока есть схема(названия, типы и атрибуты полей) и данные(значения полей). Как сами данные так и схема потока могут быть изменены в процессе обработки. Потоки в TOS не синхронизируются между собой. Они работают независимо друг от друга.
Далее, попробую на примере показать, как настраивается процесс обработки данных.
Предположим у есть нас CSV файл вида:
id,event_name,event_datetime,tag
1,"Hello, world!",2017-01-10T18:00:00Z,
2,"Event2",2017-01-10T19:00:00Z,tag1=q
3,Event3,2017-01-10T20:00:00Z,
4,"Hello, world!",2017-01-10T21:00:00Z,tag2=a
5,Event2,2017-01-10T22:00:00Z,
.
И мы хотим разделить данные по разным событиям(поле event).
Перед началом работы с данными нам потребуется создать задачу. Процесс создания не описываю по причине его тривиальности.
Итак, первое что нам надо сделать это прочитать и распарсить CSV. Для начала создадим запись метаданных для нашего входного CSV файла — это упростит дальнейшую работу (Metadata -> File delimited). Создание File delimited происходит более или менее интуитивно, поэтому подробное описание спрятано под спойлером.
Единственное, что заслуживает упоминания, это расстановка кавычек, при подстановке значений в поля форм. Это относится не только к созданию File delimited но и к большинству других полей в формах. Дело в том, что большинство значений во всевозможных полях будут подставлены в Java код “как есть”, т.е. должны являться выражением Java определенного типа. Если мы задаем строковую константу ее придется написать в кавычках. Это дает нам дополнительную гибкость. Получается что везде, где требуется значение, можно подставить значение параметра или выражения.
Далее необходимо задать имя и выбрать файл. Выбираем наш CSV файл с входными данными.
На следующем шаге необходимо настроить парсинг файла.

Разделитель полей — у нас запятая (comma).
В секции “Escape Char Settings” нас интересует поле “Text Enclosure”. Зададим значение “\”” — т.е. “двойная кавычка”. Теперь весь текст внутри двойных кавычек будет интерпретироваться как единое целое, даже если внутри есть разделитель(запятая).
В правой части можно настроить пропуск строк и ограничения. Нас это не интересует.
Поставим галочку “Установить строку заголовка в качестве имен столбцов” т.к. у нас в первой строчке находятся имена столбцов. Эти значения станут именами полей.
Кнопка “Refresh Preview” позволит обновить область предпросмотра. Убеждаемся, что все в порядке и идем дальше.
Далее от нас требуется настроить схему для выходного потока. Схема это набор типизированных полей. Каждому полю также могут быть назначены некоторые атрибуты.
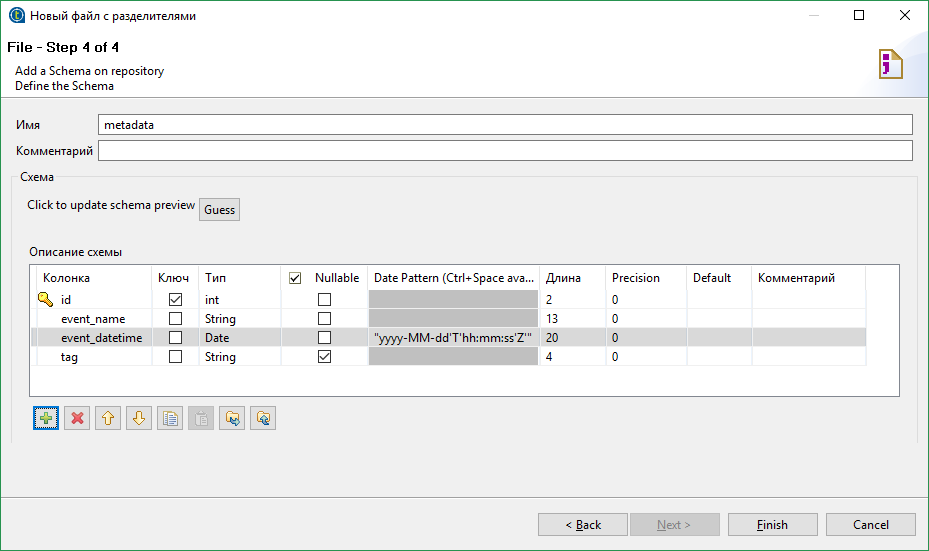
Заголовки из CSV файла стали именами полей. Тип каждого поля определяется автоматически исходя из данных в файле. Здесь нас все устраивает, кроме формата даты. Дата в нашем файле выглядит примерно следующим образом 2017-01-10T22:00:00Z и для ее парсинга нужен шаблон «yyyy-MM-dd'T'HH:mm:ss'Z'». Обратите внимание на кавычки. Дело в том, что большинство значений во всевозможных полях будут подставлены в java код “как есть”, т.е. должны являться выражением Java определенного типа. Если мы задаем строковую константу ее придется написать в кавычках.
Теперь у нас есть шаблон парсера CSV файлов заданного формата.
Далее добавим компонент, который будет заниматься парсингом. Нужный нам компонент называется tFileInputDelimited.
Далее, настроим наш парсер. Для компонента tFileInputDelimited в настройках установим “Property type” в значение “Repository” и выберем ранее созданный шаблон.
Теперь парсер настроен на парсинг файлов нужного нам формата и если запустить работу то в логах мы увидим содержимое нашего исходного CSV файла. Проблема в том, что если парсер связан с шаблоном он жестко настроен на файл в шаблоне. Мы не можем указать другой файл такого же формата, что может быть не очень удобно, когда мы заранее не знаем что за файл собираемся обрабатывать.
Из этой ситуации есть два выхода. Первый — все время подменять файл из шаблона на нужный файл. Второй — развязать компонент парсера и шаблон. В этом случае настройки парсинга можно сохранить, но появляется возможность задать входной файл. Недостатки первого способа очевидны, к недостаткам второго относится отсутствие синхронизации между шаблоном и парсером. Если мы изменим шаблон то синхронизировать настройки парсера нужно будет вручную. Мы пойдем вторым путем и отвяжем парсер от шаблона. Для этого вернем значение “Build-In” в поле “Property type”. Настройки сохранились, но появилась возможность их менять.
Изменим имя входного файла на выражение context.INPUT_CSV. Обратите внимание, имя было в кавычках (строковая константа), а наше выражение без кавычек. Оно является параметром контекста. Также нужно создать этот параметр на вкладке контекста. Для отладки можно задать значение по умолчанию. Параметры контекста можно задавать как параметры командной строки (примерно так --context_param INPUT_CSV=path). Это относится к запуску собранного пакета Java.
Далее. Мы хотим разделить данные по именам событий.
Для этого потребуется компонент tMap и несколько tFilterRow. Давайте пока ограничимся двумя tFilterRow т.е. будем выделять только два разных события. Соединим их как показано на рисунке:
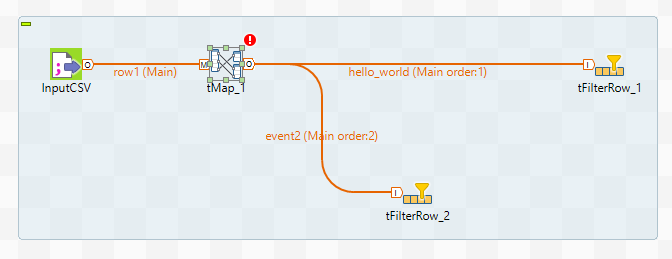
При соединении tMap и tFilterRow потребуется ввести имя для связи. Имя должно быть уникально. Далее нужно настроить компонент tMap. Для этого войдем в меню Map Editor либо дважды кликнув по иконке tMap, либо вызвав редактор из панели свойств компонента.
В нашем случае нам нужно только “скопировать” поток, поэтому просто перетащим все поля входящих данных (слева) в каждый из потоков вывода (справа).
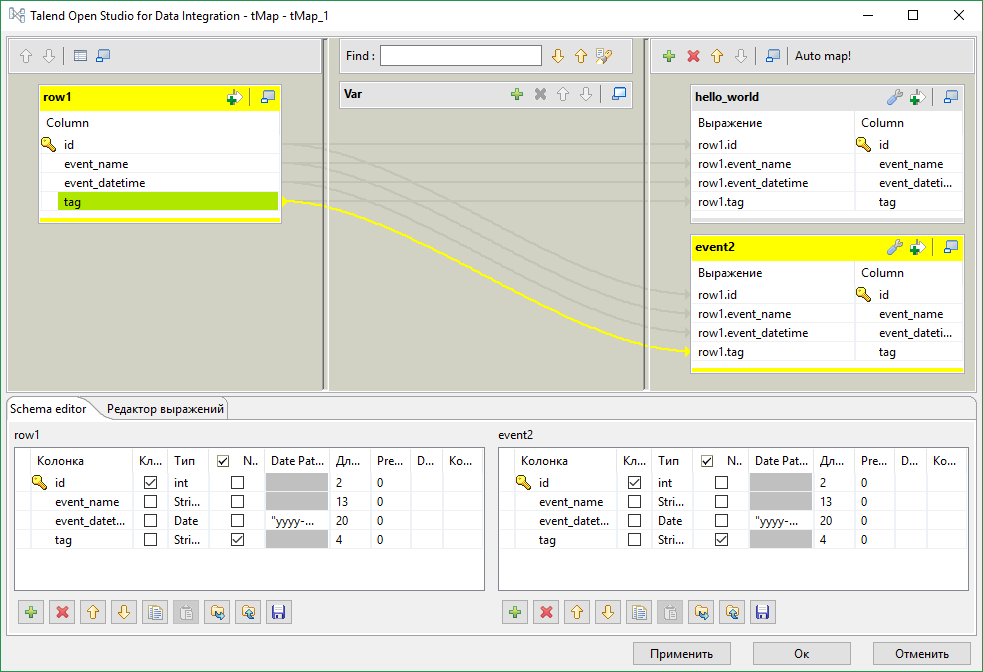
В секции в середине можно задать внутреннюю переменную (можно использовать для генерации новых значений, например номеров строк, или подстановки параметров). В каждой ячейке редактора можно написать выражение. По сути то что мы сделали это и есть подстановка значений. row1 на скриншоте это имя входного потока. Теперь наш маппер будет делить входные данные на два потока.
Настройка фильтров tFilterRow не представляет из себя ничего особенного.
Добавляем входную колонку, выбираем тип условия и вводим значение. Мы установим фильтры на поле event_name. Один фильтр будет проверять на равенство (==) «Hello, world!» (в кавычках), а второй «Event2».
Параметр “Функция” в настройках компонента задает преобразование входных данных и задает функцию преобразования F. Тогда условия отбора будет: F(input_column) value. У нас нет функции F, это равенство, а value это «Hello, world!». Получаем в нашем случае input_column == «Hello, world!».
Добавим после фильтров пару tLogRow, запустим и увидим что данные делятся. Единственно, лучше установить Mode для tLogRow в что-то отличное от “Основной”, иначе данные перемешаются.
Вместо tLogRow можно добавить какой угодно другой компонент вывода данных, например tFileOutputDelimited для записи в CSV файл, или компонент базы данных для записи в таблицу.
Для работы с базой данных есть множество компонент. Многие из них имеют в настройках поля для настройки доступа к базе. Однако если предполагается много обращаться к базе из разных компонент лучше всего использовать следующую схему:
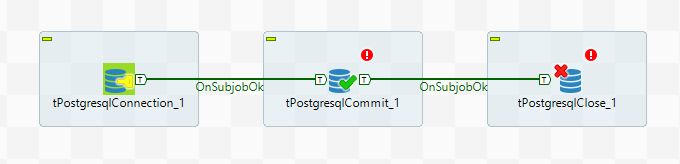
Компонент Connection задает параметры доступа к базе и устанавливает соединение. Компонент Close отключается от базы. В среднем блоке, где на рисунке находится единственный компонент Commit, можно использовать базу данных не устанавливая новых соединений. Для этого в настройках компонентов нужно выбрать опцию “Использовать существующее соединение” и выбрать нужный компонент Connection.
Здесь также используется еще один механизм TOS — подзадачи (subjob). Путем создания подзадач можно добиться, чтобы некоторые части задачи завершались прежде, чем начнутся другие. В данной примере компонент Commit не начнет работу пока не установится соединение. Между подзадачами проводится связь OnSubjobOk (в контекстном меню компонента доступен пункт Trigger, внутри которого есть эта связь). Существуют и другие связи, например, ObSubjobError для обработки ошибок.
Вернемся к нашему примеру с CSV файлом.
Поле tag у нас не очень подходит для записи в базу данных — tag2=a. Наверняка мы захотим разделить пару ключ-значение по разным полям в базе. Это можно сделать разными способами, но мы сделаем это при помощи компонента tJavaFlex. tJavaFlex это компонент, поведение которого можно описать на языке Java. В его настройках присутствуют три секции — первая выполняется до начала обработки данных (инициализация), вторая занимается обработкой данных и третья выполняется после обработки всех данных. Также, как и у остальных компонент есть редактор схемы. Удалим из схемы данных на выходе поле tag и добавить пару новых — tag_name и tag_value (типа String).

Далее, в средней секции компонента напишем
Да, параметры перечисляются два раза одни и те же (возможно я слишком плохо знаю Java). Обратите внимание, что точка с запятой в конце кода на Java не нужна.
После этого нужно сделать тривиальный запрос, чтобы получить id записи в таблице.
Но в случае с Postgres можно пойти более простым путем, и использовать RETURNING id. Однако этот механизм вернет значение только если данные будут добавлены. Но при помощи подзапроса можно обойти это ограничение. Тогда наш запрос преобразуется во что-то подобное:
В случае если запрос должен возвращать значения в компоненте tPostgresqlRow нужно включить опцию “Propagate QUERY’s recordset” (на вкладке “Advanced settings”), а также в исходящем потоке нам потребуется поле типа Object, которое нужно указать как поле для распространения данных. Чтобы извлечь данные из recordset нам потребуется компонент tParseRecordSet. В настройках в поле “Prev. Comp. Column list” нужно выбрать наше поле, через которое распространяются данные. Далее в таблице атрибутов для полей прописать имена полей, возвращенных запросом.
Должно получиться примерно следующее:

Т.е. все наши поля автоматически будут установлены в нужные значения, а новое поле dbtag_id типа int будет взят из результатов запроса по ключу “tag_id”. Сложить все в таблицу event можно при помощи того же tPostgresqlRow или tProstgresqlOutput.
В итоге получится примерно следующая схема:
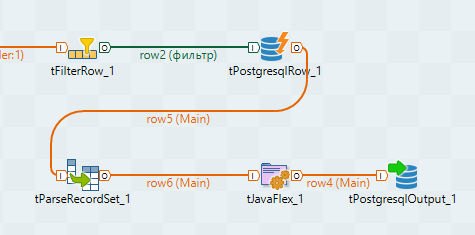
Отдельного рассмотрения заслуживает случай, когда у нас возникает необходимость в создании замкнутой структуры. TOS не позволяет делать замкнутых структур, даже если они не являются циклическими. Дело в том, что потоки данных живут каждый сами по себе, не синхронизируются, и могут нести разное количество записей. Наверняка, почти всегда можно обойтись без образования замкнутых контуров. Для этого придется не делить потоки и делать все в одном. Но если очень хочется, то при желании можно обойти ограничение на создание замкнутых структур. Нам потребуется компоненты tHashInput и tHashOutput.
По умолчанию они не отображаются в панели компонент и их придется сначала добавить туда. Для этого нужно перейти в меню Файл -> Edit project properties -> Дизайнер -> Palette Settings далее в закладке технические найти наши компоненты и добавить в рабочий набор.Эти компоненты позволяют сохранять потоки в памяти и после осуществлять к ним доступ. Можно, конечно, воспользоваться временным файлом, но хэш наверняка быстрее (если у вас хватит оперативной памяти).
Добавляем компонент tHashOutput и входящий поток, который хотим сохранить. Компоненту можно настроить на самостоятельную работу, либо на дописывание данных в другой tHashOutput компонент. В этом случае компонент будет работать подобно union из sql, т.е. данные будут записываться в один общий поток.Придется создать новую подзадачу, в которой будет осуществляться слияние. Не забудьте добавить связь OnSubjobOk.
Для каждого потока, работающего индивидуально, нужно создать компоненту tHashInput. У этой компоненты есть недостаток — даже после указания компоненты tHashOutput, из которой будут браться данные, схема не подгрузится автоматически. Далее все tHashInput нужно объединить при помощи tMap. Только один поток будет помечен как Main, по нему будут синхронизироваться остальные входящие потоки, а также исходящий, остальные входящие потоки будут Lookup. Кроме того нам надо задать связь между потоками, иначе мы получим Cross Join.
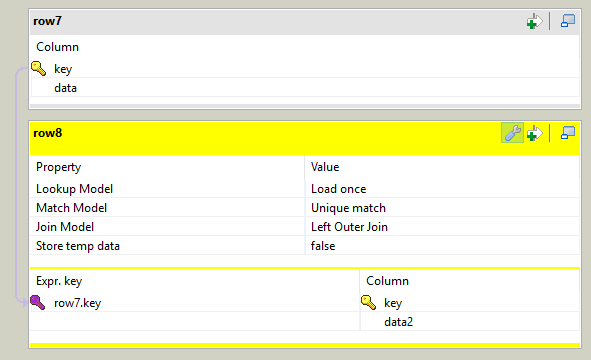
Теперь, несмотря на то что в левой части маппера много потоков, можно считать что у нас один входной поток и использовать для маппинга любые поля любых потоков.
CSV (от англ. Comma-Separated Values — значения, разделённые запятыми) — текстовый формат , предназначенный для представления табличных данных. Каждая строка файла — это одна строка таблицы. Значения отдельных колонок разделяются разделительным символом (delimiter) — запятой ( , ). Однако, большинство программ вольно трактует стандарт CSV и допускают использование иных символов в качестве разделителя.
За основу кода взята типовая функция РазложитьСтрокуВМассивПодстрок .
Это функция дополнена параметром СимволВыделения! Этот параметр решает проблему выделения ячеек, в которых присутствует разделитель.
В разработке использовался код: Работа в 1С с CSV файлами.
Обновление от 30.10.2015
Дописан алгоритм вычленения ячеек, в которых есть и символ разделитель, и символ выделения.
Например, строка: "Ответ на письмо", мой друг" доставлен". Вернятся как: Ответ на письмо", мой друг" доставлен.
В прошлой версии результат был: Ответ на письмо| мой друг" доставлен.
Специальные предложения







Давайте я вам дам файл, а вы мне его корректно вашим парсером разложите? А как быть со строковыми колонками которые в тексте содержат разделитель? По стандарту такие значения заключают в кавычки, и тогда разделитель до закрывающей кавычки не анализируется!
(3) V.Nikonov, после тестирования парсера на большом массиве строк, доработал код. Но пока нет времени обновить файл публикации. Так что в скором времени и этот вопрос будет решен.
Но даже в текущей версии такую строку распарсит корректно, если рядом не будет символа выделения!
Немного статистики. CSV-файл более 2 ГБ обработка не смогла даже прочитала, т.к. просто вылетела платформа. А вот файл менее 1 ГБ обработало, но на 97% не хватило памяти на сервере и тоже вылет (процесс 1С использовал почти 3 гига оперативной памяти).
Файл в 680 МБ с трудом дочитало (процесс 1С использовал почти 2.5 гига оперативной памяти).
Файлы с меньшим объемом без проблем читает.
Все операции выполнялись на 32-битном процессе. Как поведет себя обработка в регламентном задании, пока не могу сказать, но там используется 64-битный процесс, поэтому ограничение на память там больше.
(0) функция РазложитьСтрокуВМассивПодстрокMSExchange работает неверно!Как видно из вложений в Excel csv открывается правильно, а в 1С неправильно.
Из Вашей обработки я взял только одну функцию. (6) BigB, вы настройки для своего конфигурации сделали? На скриншотах этого я не увидел. (7) повторю еще раз: Из Вашей обработки я взял только одну функцию.
Запускал её с параметрами так: (8) BigB, так с такими параметрами, она будет работать по другому. Как типовая. Используйте полный список параметров! (9) приложил настройки из обработки.
Только я не понял, чем они отличаются от моих, что я выложил ранее?
Специально проверил Вашу загрузку. Мало того, что она не отработала нормально даже шапку файла, так и табличная часть была пустой! (10) BigB, у вас шапка есть? Похоже строки шапки либо нет, либо разделитель у вас не тот. Взять только эту функцию будет не достаточно для корректной работы всего алгоритма! Используйте обработку полностью! (11) Вы почему не умеете читать, то, что Вам пишут? Я же Вам только, что написал и картинки приложил. Повторю ещё раз: При использовании Вашей обработки с настройками, которые я уже выкладывал - я получил кривую шапку (только последнюю колонку) и пустую табличную часть. В личку могу выслать csv файл, чтобы Вы сами убедиться, что функция РазложитьСтрокуВМассивПодстрокMSExchange не работает. (12) BigB, скиньте в личку ваш файл. Важным нюансом также является, чтобы названия колонок шапки писались слитно!
Думаю именно из-за этого у вас и не работает все. Поэтому, если вы весь алгоритм работы не разобрали, то такой результат и получили!
Просмотры 23377
Загрузки 39
Рейтинг 10
Создание 22.10.15 11:37
Обновление 22.10.15 11:37
№ Публикации 410803
Конфигурация Конфигурации 1cv8
Операционная система Windows
Вид учета Не имеет значения
Доступ к файлу Абонемент ($m)
Код открыт Не указано

См. также
Модуль обмена с QIWI Промо
Компании, которые используют систему моментальных платежей QIWI, ценят ее за удобство по скорости выплат и для платежей по запросу. Но такие переводы сложны для учета, а при большом объеме проводимых операций отнимают много времени и превращаются в дополнительную головную боль. Мы сотрудничали с компаниями, которые отправляют большое количество платеже на QIWI, и часто слышали боль бухгалтеров о том, как им сложно работать с такими переводами. Поэтому мы автоматизировали выплаты через QIWI в 1С и создали модуль интеграции 1С c API QIWI Wallet и QIWI TopUp.
5 стартмани
25.05.2020 8200 0 Neti 10
Расширение конфигурации для Web-доступа к 1С (1С в роли back-end)
Для реализации того, чтобы 1С формировала и отдавала страницу, которую можно было бы открыть через браузер было написано расширение, которое позволяет публиковать из 1С произвольные ресурсы, будь то API, сайт или изображения / прочие файлы.
1 стартмани
01.04.2021 8833 11 SaschaG 4
Работа с картами в 1С на примере бесплатной библиотеки Leaflet
Разработка функционала отображения и выбора пунктов доставки на карте прямо в 1С с помощью бесплатной библиотеки Leaflet. Тестирование производилось на платформе 8.3.15.1534 на тонком клиенте.
1 стартмани
31.03.2021 10466 31 Parsec1C 11
1 стартмани
24.03.2021 7114 13 ltfriend 12
BIM: взаимодействие с платформой Autodesk Forge Промо
Предлагаемый пример демонстрирует широкие возможности для взаимодействия «1С:Предприятие» с платформой Autodesk Forge и позволяет вам получить базовые представления о применения технологий информационного моделирования в строительстве. Поддерживаются все версии платформы от 8.3.12 и выше до 8.3.18.

Передача информации для обработки в прикладных программах, а также представление конечных результатов их работы возможны не только с использованием клавиатуры и консоли. В большинстве случаев для решения подобных задач организуется обмен информацией с помощью текстовых файлов. Этот способ в настоящее время является самым распространенным способом обмена информацией как между программами, так и между программой и пользователем. Одним из популярных в настоящее время форматов, использующихся для представления табличных данных, является формат CSV.
Отметим, что для того, чтобы использовать CSV при написании своих программ на языке Python, вам не нужно писать свой собственный синтаксический анализатор (парсер). И хотя существует немало хороших библиотек, которые вы можете использовать для работы с CSV, возможностей предоставляемых стандартной библиотекой Python, а точнее модулем csv из ее состава, достаточно для решения большинства возникающих задач. Если же вам необходимо обработать большое количество данных в формате CSV, например осуществить их статистический анализ, то в составе библиотеки pandas также реализованы удобные методы для чтения и записи файлов в этом формате.
Из этой статьи вы узнаете как читать и записывать файлы в формате CSV, а также организовывать обработку полученных данных с помощью средств языка Python. Мы рассмотрим основы работы модуля csv, а затем ознакомимся с работой парсера данных в формате CSV, входящего в состав библиотеки pandas.
Что такое файл в формате CSV
Обратите внимание, что отдельные значения разделяются с помощью запятых. При этом столбцы данных идентифицируется путем перечисления их имен в первой строке файла. Каждая последующая строка после строки с именами содержит непосредственно данные и ограничена только размерами файла. Разделяющий значения символ называют разделителем и, конечно же, символ , (запятая) не является единственным, который может использоваться для этих целей. Другие популярные символы, использующиеся в качестве разделителя: символ табуляции ( \t ), двоеточие ( : ) и точка с запятой ( ; ). Отметим, что для корректного синтаксического анализа (парсинга) файла CSV требуется знание вида разделителя, использующегося в этом файле.
Как появились CSV файлы?
Файлы CSV создаются программами, которые обрабатывают большие объемы табличных данных. Файлы CSV представляют удобный способ для экспорта данных из электронных таблиц и баз данных, с последующим использованием в других программах. Например, вы можете экспортировать результаты работы программы статистического анализа данных в файл CSV, а затем импортировать их в структуру специального вида для дальнейшего анализа, построения графиков для презентации или подготовки отчета для публикации.
Файлы CSV очень просты и удобны для работы с прикладным программным обеспечением. Любой язык, поддерживающий ввод текстовых файлов и обработку строк (например, Python), может напрямую работать с файлами CSV.
Разбор (парсинг) CSV-файлов с помощью встроенной в Python библиотекой для обработки CSV данных
Модуль csv обеспечивает стандартный функционал для чтения и записи данных в файлы CSV. Разработанный для работы с CSV файлами созданными в Excel, он легко настраивается для работы с любыми разновидностями этого формата. csv содержит объекты и методы для чтения файлов CSV, обработки данных в этом формате, а также записи данных в файл CSV.
Чтение CSV файлов с помощью библиотеки csv
Чтение данных из файла CSV выполняется с использованием объекта reader . Файл CSV открывается как обычный текстовый файл стандартной функцией Python open() , которая возвращает объект типа файл. Затем ссылка на этот объект передается объекту reader .
Рассмотрим для примера файл employee_birthday.txt содержащий данные:
С помощью следующего кода откроем его для чтения, прочитаем и обработаем содержимое файла:
Результат его выполнения будет следующим:
Каждая строка, возвращаемая объектом reader , представляет собой список значений типа String , содержащих данные с удаленными разделителями. Кроме того первая строка возвращает имена столбцов, которые должны быть обработаны другим способом.
Чтение CSV файлов в словарь с помощью библиотеки csv
Вместо того, чтобы иметь дело со списком значений типа String , вы можете считывать данные непосредственно в словарь (технически в объект класса Ordered Dictionary).
Например, наш файл employee_birthday.txt имеет следующий вид:
Приведенный ниже код преобразует прочитанные данные в словарь:
Это приведет к тому же результату, что был получен ранее:
Откуда взялись значения ключей для словаря? Изначально предполагается, что первая строка файла CSV содержит ключи для создания словаря. Если их нет в вашем файле CSV, вы должны определить имена для ключей, передав их через необязательный именованный параметр fieldnames в виде списка значений имен.
Необязательные параметры объекта reader библиотеки csv
Объект reader может обрабатывать файлы CSV с различными стилями форматирования, указывая значения необязательных параметров, некоторые из которых представлены ниже, а с остальными вы можете ознакомиться в документации перейдя по ссылке:
Применение этих параметров требует дополнительного пояснения. Предположим, вы работаете с файлом employee_addresses.txt следующего содержания:
Этот CSV файл содержит три столбца данных: имя name , адрес address и дата добавления date joined , разделенных запятыми. Проблема в том, что данные в полях столбца адрес address тоже содержат запятую для того чтобы выделить номер почтового индекса.
- Использовать другой разделитель. Таким образом, запятая может безопасно использоваться в самих данных. Вы используете необязательный именованный параметр delimiter , чтобы указать новый вид разделителя.
- Обернуть поля данных в кавычки. Специальный вид выбранного вами разделителя игнорируется в строках, обернутых в двойные кавычки. Поэтому вы можете указать вид символа, используемый для обертывания значений полей данных через необязательный параметр quotechar . Пока этот символ отсутствует в значениях полей данных, все будет работать корректно.
- Экранирование символа разделителя delimiter в данных поля. Экранирующие символы работают так же, как в форматированных строках, не допуская интерпретацию символа, который экранируется (в данном случае символа разделителя delimiter ). Если вы используете экранирующие символы, вид его необходимо указать с помощью необязательного именованного параметра escapechar .
Запись CSV файлов с помощью библиотеки csv
Запись данных в файл CSV производится с использованием объекта writer и его метода write_row() :
Записанный нами файл будет иметь следующее содержимое:
Использование необязательного именованного параметра quotechar предписывает объекту writer , использовать указанный вид символа для обертывания значений полей данных при записи (например, обернуть значения полей данных в двойные кавычки). Однако, используется ли обертывание или нет, определяется наличием необязательного параметра quoting :
- Если значение параметра quoting задано как csv.QUOTE_MINIMAL , то метод .writerow() при записи будет оборачивать значения полей данных (например, в двойные кавычки) только в том случае, если в содержимом поля данных присутствуют символы delimiter или quotechar . Это поведение метода .writerow() задано по умолчанию.
- Если значение параметра quoting задано как csv.QUOTE_ALL , то метод .writerow() будет оборачивать все поля данных, вне зависимости от их содержимого.
- Если значение параметра quoting задано как csv.QUOTE_NONNUMERIC , то метод .writerow() будет обертывать значения полей данных, содержащих текстовые данные, а поля содержащие численные данные в данные с типом float .
- Если значение параметра quoting задано как csv.QUOTE_NONE , то вместо обертывания полей данных метод .writerow() будет экранировать символы разделителя, присутствующие в содержимом полей. В этом случае вы обязательно должны указать значение для необязательного параметра escapechar .
Запись файла CSV из словаря с помощью библиотеки csv
Поскольку вы можете читать данные из файла CSV непосредственно в словарь, то соответственно, вы также сможете легко записать их из словаря в файл:
Для записи данных в формате CSV из словаря в файл, в отличие от DictReader , объекту DictWriter требуется задать значение для параметра fieldnames . Без списка имен столбцов fieldnames DictWriter не может понять, какие ключи использовать для извлечения соответствующих значений из вашего словаря. Далее он использует имена ключей для записи первой строки в качестве имен столбцов данных.
Приведенный выше код генерирует файл следующего содержания:
Синтаксический анализ (парсинг) CSV файлов с помощью библиотеки pandas
Конечно же модуль из стандартной библиотеки Python csv не единственный в своем роде. Чтение CSV файлов также возможно с использованием библиотеки pandas. Но применять её рекомендуется если у вас есть большое количество данных для последующей обработки и анализа средствами этой же библиотеки.
Установка pandas и его зависимостей в Anaconda выполняется легко:
Тоже с использованием другого установщика пакетов Python pip/pipenv:
В этой статье не рассматриваются особенности работы pandas. Для углубленного изучения вопросов использования pandas для чтения и анализа больших наборов данных ознакомьтесь в превосходной статье Shantnu Tiwari О работе с большими файлами Excel в pandas.
Чтение файлов CSV с помощью pandas
Для демонстрации возможностей библиотеки pandas по чтению файлов в формате CSV, используем файл hrdata.csv . Он содержит информацию о сотрудниках компании и имеет следующую (более сложную чем рассмотренные ранее) структуру данных:
Чтение CSV файла с использованием библиотеки pandas, а точнее ее класса DataFrame , производится достаточно просто:
Это всего лишь три строки кода и только одна из них выполняет фактическую работу. Метод pandas.read_csv() открывает для чтения, анализирует, считает данные из файла CSV, а затем сохраняет их в специальную структуру данных, описываемых классом DataFrame . Вывод в консоли полученного результата покажет следующее:
Исходя из этого приведем несколько соображений:
- Во-первых, pandas распознала, что первая строка файла CSV содержит имена столбцов и автоматически использовала их.
- Также pandas самостоятельно назначила для отдельных строк данных в DataFrame целочисленные индексы, начинающиеся с нуля. Это потому, что мы не определили какими они должны быть и нужны ли они вообще.
- Кроме того, если вы посмотрите на типы данных в наших столбцах, то вы увидите, что pandas правильно преобразовала значения столбцов Salary and Sick Days в числа, но значения в столбце Hire Date по-прежнему остались строкой String . Что легко проверить в консоли:
Последовательно рассмотрим способы решения описанных выше проблем.
Чтобы использовать один из столбцов структуры DataFrame в качестве индекса, необходимо задать значение для необязательного параметра index_col :
Теперь давайте переопределим поведение по умолчанию метода для значений поля Hire Date . В этом случае вы можете обязать pandas считывать значения этого поля как дату, используя необязательный параметр parse_dates , в который передается список имен list соответствующих столбцов:
Обратите внимание на отличие полученных результатов от полученных выше:
Теперь значение даты интерпретируется правильно, что легко проверяется в консоли:
Если ваши данные в файле CSV не имеют первой строки с именами столбцов, то вы можете использовать необязательный параметр names для определения своего списка list имен столбцов. Вы также можете использовать эту возможность, если хотите переопределить имена столбцов, указанных в первой строке файла. В этом случае вы должны указать методу pandas.read_csv() , чтобы тот игнорировал существующие имена столбцов, используя необязательный именованный параметр header=0 :
Обратите внимание, что поскольку имена столбцов изменены, данные в столбцах, измененных с помощью необязательных параметров index_col и parse_dates , также изменятся. Что приведет к следующему результату:
Запись CSV файлов с помощью pandas
Запись данных структуры DataFrame в файл CSV так же проста, как и его чтение. Давайте запишем данные с новыми именами столбцов в новый файл:
Единственное различие между этим кодом и приведенным выше для чтения данных из файла заключается в том, что вызов функции print(df) был заменен на метод df.to_csv() , которому передано имя нового файла. Полученный файл будет выглядеть следующим образом:
Выводы
Если вы поймете из этой статьи основы работы с CSV файлами, то сможете импортировать и экспортировать данные в этом формате для использования в своих программах. Большинство задач чтения, обработки и записи данных в формате CSV могут быть легко решены с использованием модуля стандартной библиотеки csv. Если у вас большой объем данных для чтения и последующей статистической обработки, то библиотека pandas обеспечит более удобную работу с данными в этом формате.
Читайте также: