
Как построить граф классификации на компьютере
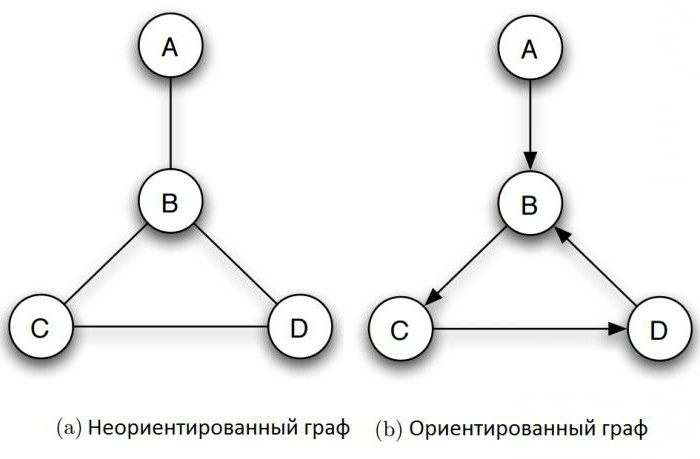
Из чего состоит граф в информатике? Он включает множество объектов, называемых вершинами или узлами, некоторые пары которых связаны т. н. ребрами. Например, граф на рисунке (а) состоит из четырех узлов, обозначенных А, В, С, и D, из которых B соединен с каждой из трех других вершин ребрами, а C и D также соединены. Два узла являются соседними, если они соединены ребром. На рисунке показан типичный способ того, как строить графы по информатике. Круги представляют вершины, а линии, соединяющие каждую их пару, являются ребрами.
Какой граф называется неориентированным в информатике? У него отношения между двумя концами ребра являются симметричными. Ребро просто соединяет их друг с другом. Во многих случаях, однако, необходимо выразить асимметричные отношения – например, то, что A указывает на B, но не наоборот. Этой цели служит определение графа в информатике, по-прежнему состоящего из набора узлов вместе с набором ориентированных ребер. Каждое ориентированное ребро представляет собой связь между вершинами, направление которой имеет значение. Направленные графы изображают так, как показано на рисунке (b), ребра их представлены стрелками. Когда требуется подчеркнуть, что граф ненаправленный, его называют неориентированным.
Модели сетей
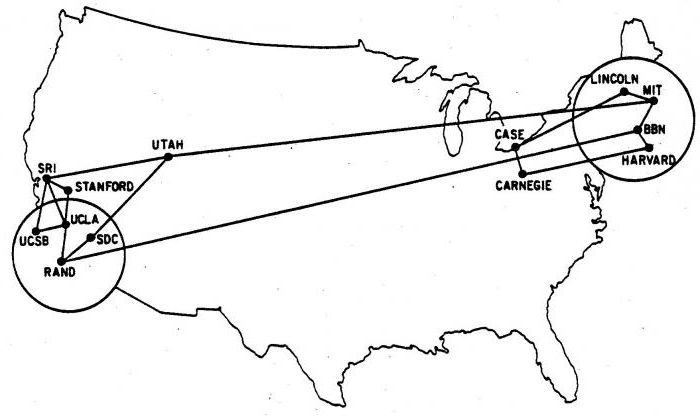
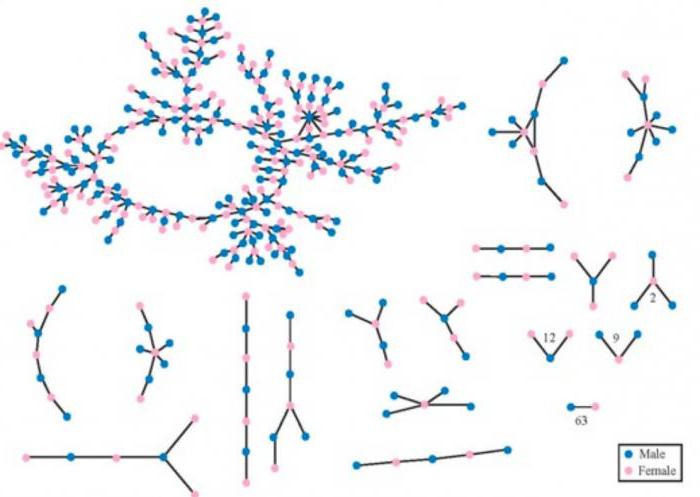
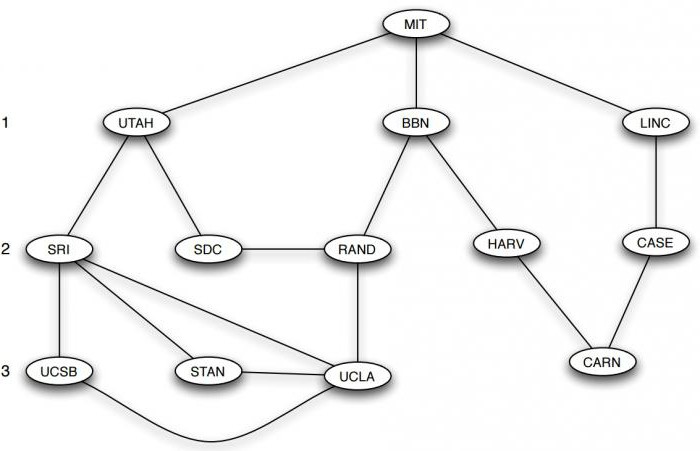
Графы в информатике служат математической моделью сетевых структур. На следующем рисунке представлена структура интернета, тогда носившего название ARPANET, в декабре 1970 года, когда она имела лишь 13 точек. Узлы представляют собой вычислительные центры, а ребра соединяют две вершины с прямой связью между ними. Если не обращать внимания на наложенную карту США, остальная часть изображения является 13-узловым графом, подобным предыдущим. При этом действительное расположение вершин несущественно. Важно, какие узлы соединены друг с другом.
Маршруты
Хотя графы применяются во многих различных областях, они обладают общими чертами. Теория графов (информатика) включает, возможно, важнейшую из них – идею о том, что вещи часто перемещаются по ребрам, последовательно переходя от узла к узлу, будь то пассажир нескольких авиарейсов или информация, передаваемая от человека к человеку в социальной сети, либо пользователь компьютера, последовательно посещающий ряд веб-страниц, следуя по ссылкам.
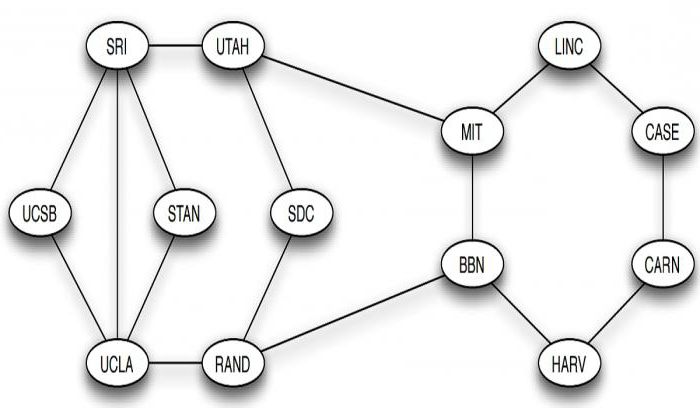
Эта идея мотивирует определение маршрута как последовательности вершин, связанных между собой ребрами. Иногда возникает необходимость рассматривать маршрут, содержащий не только узлы, но и последовательность ребер, их соединяющих. Например, последовательность вершин MIT, BBN, RAND, UCLA является маршрутом в графе интернета ARPANET. Прохождение узлов и ребер может быть повторным. Например, SRI, STAN, UCLA, SRI, UTAH, MIT также является маршрутом. Путь, в котором ребра не повторяются, называется цепью. Если же не повторяются узлы, то он носит название простой цепи.
Циклы
Особенно важные виды графов в информатике – это циклы, которые представляют собой кольцевую структуру, такую как последовательность узлов LINC, CASE, CARN, HARV, BBN, MIT, LINC. Маршруты с, по крайней мере, тремя ребрами, у которых первый и последний узел одинаковы, а остальные различны, представляют собой циклические графы в информатике.
Примеры: цикл SRI, STAN, UCLA, SRI является самым коротким, а SRI, STAN, UCLA, RAND, BBN, UTAH, SRI значительно больше.
Фактически каждое ребро графа ARPANET принадлежит к циклу. Это было сделано намеренно: если какое-либо из них выйдет из строя, останется возможность перехода из одного узла в другой. Циклы в системах коммуникации и транспорта присутствуют для обеспечения избыточности – они предусматривают альтернативные маршруты по другому пути цикла. В социальной сети тоже часто заметны циклы. Когда вы обнаружите, например, что близкий школьный друг кузена вашей жены на самом деле работает с вашим братом, то это является циклом, который состоит из вас, вашей жены, ее двоюродного брата, его школьного друга, его сотрудника (т. е. вашего брата) и, наконец, снова вас.
Связный граф: определение (информатика)
Естественно задаться вопросом, можно ли из каждого узла попасть в любой другой узел. Граф связный, если между каждой парой вершин существует маршрут. Например, сеть ARPANET – связный граф. То же можно сказать и о большинстве коммуникационных и транспортных сетей, так как их цель состоит в том, чтобы направлять трафик от одного узла к другому.
С другой стороны, нет никаких априорных оснований ожидать того, что данные виды графов в информатике широко распространены. Например, в социальной сети несложно представить двух людей, не связанных между собой.
Компоненты
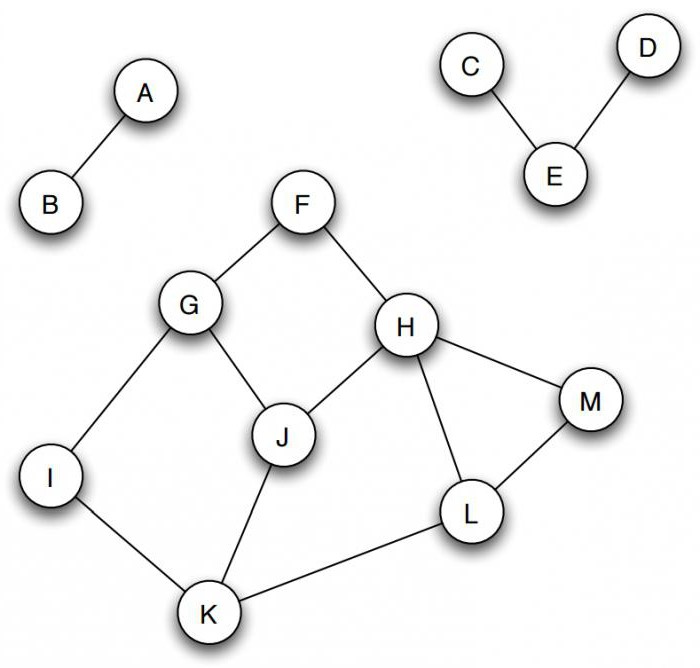
Если графы в информатике не связаны, то они естественным образом распадаются на набор связанных фрагментов, групп узлов, которые являются изолированными и не пересекающимися. Например, на рисунке изображены три таких части: первая – А и В, вторая – C, D и Е, и третья состоит из оставшихся вершин.
Компоненты связности графа представляют собой подмножество узлов, у которых:
- каждая вершина подгруппы имеет маршрут к любой другой;
- подмножество не является частью некоторого большего набора, в котором каждый узел имеет маршрут к любому другому.
Когда графы в информатике разделяются на их компоненты, то это является лишь начальным способом описания их структуры. В рамках данного компонента может быть богатая внутренняя структура, важная для интерпретации сети. Например, формальным методом определения важности узла является определение того, на сколько частей разделится граф, если узел будет убран.

Максимальная компонента
Существует метод качественной оценки компонентов связности. Например, есть всемирная социальная сеть со связями между двумя людьми, если они являются друзьями.
Связная ли она? Вероятно, нет. Связность – довольно хрупкое свойство, и поведение одного узла (или небольшого их набора) может свести ее на нет. Например, один человек без каких-либо живых друзей будет компонентом, состоящим из единственной вершины, и, следовательно, граф не будет связным. Или отдаленный тропический остров, состоящий из людей, которые не имеют никакого контакта с внешним миром, также будет небольшой компонентой сети, что подтверждает ее несвязность.
Глобальная сеть друзей
Но есть еще кое-что. Например, читатель популярной книги имеет друзей, выросших в других странах, и составляет с ними одну компоненту. Если принять во внимание родителей этих друзей и их друзей, то все эти люди также находятся в той же компоненте, хотя они никогда не слышали о читателе, говорят на другом языке и рядом с ним никогда не были. Таким образом, хотя глобальная сеть дружбы - не связная, читатель будет входить в компонент очень большого размера, проникающий во все части мира, включающий в себя людей из самых разных слоев и, фактически, содержащий значительную часть населения земного шара.
То же имеет место и в сетевых наборах данных – большие, сложные сети часто имеют максимальную компоненту, которая включает значительную часть всех узлов. Более того, когда сеть содержит максимальную компоненту, она почти всегда только одна. Чтобы понять, почему, следует вернуться к примеру с глобальной сетью дружбы и попробовать вообразить наличие двух максимальных компонент, каждая из которых включает миллионы людей. Потребуется наличие единственного ребра от кого-то из первой компоненты ко второй, чтобы две максимальные компоненты слились в одну. Так как ребро единственное, то в большинстве случаев невероятно, чтобы оно не образовалось, и, следовательно, две максимальные компоненты в реальных сетях никогда не наблюдаются.
В некоторых редких случаях, когда две максимальные компоненты сосуществовали в течение длительного время в реальной сети, их объединение было неожиданным, драматическим, и, в конечном итоге, имело катастрофические последствия.
Катастрофа слияния компонент
Например, после прибытия европейских исследователей в цивилизации Западного полушария примерно полтысячелетия назад произошел глобальный катаклизм. С точки зрения сети это выглядело так: пять тысяч лет глобальная социальная сеть, вероятно, состояла из двух гигантских компонент - одной в Северной и Южной Америке, а другой - в Евразии. По этой причине технологии развивалась независимо в двух компонентах, и, что еще хуже, так же развивались и болезни человека и т. д. Когда две компоненты, наконец, вошли в контакт, технологии и заболевания одной быстро и катастрофически переполнили вторую.
Американская средняя школа
Расстояние и поиск в ширину
В дополнение к сведениям о том, связаны ли два узла маршрутом, теория графов в информатике позволяет узнать и о его длине – в транспорте, связи или при распространении новостей и заболеваний, а также о том, проходит ли он через несколько вершин или множество.
Для этого следует определить длину маршрута, равную числу шагов, которые он содержит от начала до конца, т. е. число ребер в последовательности, которая его составляет. Например, маршрут MIT, BBN, RAND, UCLA имеет длину 3, а MIT, UTAH – 1. Используя длину пути, можно говорить о том, расположены ли два узла в графе близко друг к другу или далеко: расстояние между двумя вершинами определяется как длина самого короткого пути между ними. Например, расстояние между LINC и SRI равно 3, хотя, чтобы убедиться в этом, следует удостовериться в отсутствии длины, равной 1 или 2, между ними.
Алгоритм поиска в ширину
Для небольших графов расстояние между двумя узлами подсчитать легко. Но для сложных появляется необходимость в систематическом методе определения расстояний.
Самым естественным способом это сделать и, следовательно, наиболее эффективным, является следующий (на примере глобальной сети друзей):
- Все друзья объявляются находящимися на расстоянии 1.
- Все друзья друзей (не считая уже отмеченных) объявляются находящимися на расстоянии 2.
- Все их друзья (опять же, не считая помеченных людей) объявляются удаленными на расстояние 3.
Продолжая таким образом, поиск проводят в последующих слоях, каждый из которых - на единицу дальше предыдущего. Каждый новый слой составляется из узлов, которые еще не участвовали в предыдущих, и которые входят в ребро с вершиной предыдущего слоя.
Эта техника называется поиском в ширину, так как она выполняет поиск по графу наружу от начального узла, в первую очередь охватывая ближайшие. В дополнение к предоставлению способа определения расстояния, она может служить полезной концептуальной основой для организации структуры графа, а также того, как построить граф по информатике, располагая вершины на основании их расстояния от фиксированной начальной точки.
Поиск в ширину может быть применен не только к сети друзей, но и к любому графу.
Мир тесен
Если вернуться к глобальной сети друзей, можно увидеть, что аргумент, объясняющий принадлежность к максимальной компоненте, на самом деле утверждает нечто большее: не только у читателя есть маршруты к друзьям, связывающие его со значительной долей населения земного шара, но эти маршруты на удивление коротки.
Эта идея получила название «феномена тесного мира»: мир кажется маленьким, если думать о том, какой короткий маршрут связывает любых двух людей.
Теория «шести рукопожатий» впервые экспериментально исследовалась Стенли Милгрэмом и его коллегами в 1960-е годы. Не имея какого-либо набора данных социальных сетей и с бюджетом в 680 долларов он решил проверить популярную идею. С этой целью он попросил 296 случайно отобранных инициаторов попробовать отослать письмо биржевому брокеру, который жил в пригороде Бостона. Инициаторам были даны некоторые личные данные о цели (включая адрес и профессию), и они должны были переслать письмо лицу, которого они знали по имени, с теми же инструкциями, чтобы оно достигло цели как можно быстрее. Каждое письмо прошло через руки ряда друзей и образовало цепочку, замыкавшуюся на биржевом брокере за пределами Бостона.
Среди 64 цепочек, достигших цели, средняя длина равнялась шести, что подтвердило число, названное два десятилетия ранее в названии пьесы Джона Гэра.
Несмотря на все недочеты этого исследования, эксперимент продемонстрировал один из важнейших аспектов нашего понимания социальных сетей. В последующие годы из него был сделан более широкий вывод: социальные сети, как правило, имеют очень короткие маршруты между произвольными парами людей. И даже если такие опосредованные связи с руководителями предприятий и политическими лидерами не окупаются на ежедневной основе, существование таких коротких маршрутов играет большую роль в скорости распространения информации, болезней и других видов заражения в обществе, а также в возможностях доступа, которые социальная сеть предоставляет людям с совершенно противоположными качествами.
Ранее мы публиковали пост, где с помощью графов проводили анализ сообществ в Точках кипения из разных городов России. Теперь хотим рассказать, как строить такие графы и проводить их анализ.

Под катом — пошаговая инструкция для тех, кто давно хотел разобраться с визуализацией графов и ждал подходящего случая.
1. Выбор гипотезы
Если попытаться визуализировать хотя бы что-то, бездумно загрузив данные в программу построения графов, результат вас не порадует. Поэтому сначала сформулируйте для себя, что хотите узнать с помощью графов, и придумайте жизнеспособную гипотезу.
Для этого разберитесь, какие данные у вас уже есть, что из них можно представить «объектами», а что – «связями» между ними. Обычно объектов значительно меньше, чем связей — можно таким образом проверять себя.
Наш тестовый пример мы готовили совместно с командой Точки кипения из Томска. Соответственно, все данные для анализа по мероприятиям и их участникам у нас будут именно оттуда. Нам стало интересно, сформировалось ли из участников этих мероприятий сообщество и как оно выглядит с точки зрения принадлежности участников к бизнесу, университетам и власти.
Мы предположили, что люди, которые посетили одно и то же мероприятие, связаны друг с другом. Причем чем чаще они присутствовали на мероприятиях совместно, тем сильнее связь.
Во втором случае мы решили узнать, как соотносится принадлежность участников к одному из «нетов» (наших ключевых направлений) с интересующими их сквозными технологиями. Равномерно ли распределение, есть ли «горячие темы»? Для этого анализа мы взяли данные по участникам мероприятий из 200 томских технологических компаний.
В принципе, даже таких первичных формулировок гипотез достаточно, чтобы перейти ко второму шагу.
2. Подготовка данных
Теперь, когда вы определились с тем, что хотите узнать, возьмите весь массив данных, посмотрите, какая информация об «объектах» хранится, выкиньте все лишнее и добавьте недостающее. Если данные распределены по нескольким источникам, предварительно соберите все в одну кучу, убрав дубли.
Поясню на примере. У нас были данные об участниках 650 мероприятий. Это, условно говоря, 650 эксель-таблиц с
23000 записей в них, содержащих поля «Leader ID», «Должность», «Организация». Для постройки графа достаточно одного уникального идентификатора (тут, к счастью, такой есть – это Leader ID) и признака, привязывающего каждого участника к одной из трех рассматриваемых сфер: власти, бизнесу или университетам. И этой информации у нас еще нет.
Чтобы получить ее, можно пойти напролом: в каждом из 650 файлов убрать лишние столбцы и добавить новое поле, заполнить его значениями для каждой строки, например: «1» для власти, «2» для бизнеса и «3» для образования и науки. А можно сначала объединить все 650 файлов в один большой список, убрать дубли и только после этого добавлять новые значения. В первом случае такая работа займет 1-2 месяца. Во втором — 1-2 недели.
Вообще при добавлении новых атрибутов старайтесь предварительно группировать данные. Например, можно отсортировать участников по компаниям/организациям и скопом выставлять признак.
Готовим данные дальше. Для их загрузки в большинство программ визуализации потребуется создать два файла: один — с перечнем вершин, второй — со списком ребер.


Файл вершин в нашем случае содержал два столбца: Id — номер вершины и Label — тип. Файл ребер содержал также два столбца: Source — id начальной вершины, Target — id конечной вершины.
Как превратить данные о том, что участники 1, 2, 5 и 23 посетили одно мероприятие, в ребра? Необходимо создать шесть строк и отметить связь каждого участника с каждым: 1 и 2, 1 и 5, 1 и 23, 2 и 5, 2 и 23, 5 и 23.
Во втором нашем примере таблицы выглядели так:


В качестве вершин перечислены как рынки, так и сквозные технологии. Если, скажем, представитель компании, относящейся к рынку «Технет» (ID=4), посетил мероприятие по теме «Большие данные и ИИ» (ID=17), в таблицу ребер заносим ребро (строку), соединяющее эти вершины (Source=4, Target=17).
Этап подготовки данных – это самая трудоемкая часть процесса, но наберитесь терпения.
3. Визуализация графа
Скриншоты я буду делать со второго проекта, в котором было небольшое число вершин и связей, чтобы все было максимально понятно.
Первым делом нам надо загрузить таблицы с вершинами и ребрами. Для этого выбираем пункт «Импортировать из CSV» из меню раздела «Лаборатория данных».

Сначала грузим файл с вершинами. На первом экране формы указываем, что импортируем именно вершины, и проверяем, чтобы программа правильно определила кодировку подписей.

На третьей форме «Отчет об импорте» важно указать тип графа. У нас он не ориентирован.

Похожим образом грузим ребра. В первом окне указываем, что это файл с ребрами, и также проверяем кодировку.

Важный момент ждет нас в третьем окне «Отчет об импорте». Тут важно указать не только то, что граф не ориентирован, но и подгрузить ребра в то же рабочее пространство, что и вершины. Поэтому выбираем пункт «Append to existing workplace».

В результате перед нами предстанет граф примерно вот в таком виде (закладка «Обработка»):

Итак, ребра имеют разную толщину в зависимости от количества связей между вершинами. Посмотреть, какой вес стал у каждого ребра, можно на закладке «Лаборатория данных» в свойствах ребер в столбце Weight.
Что здесь плохо: все вершины имеют один размер и расположены абсолютно произвольно. На закладке «Обработка» мы это исправим. Сначала в верхнем левом окне выбираем Nodes и жмем на пиктограммку с кругами («Размер»). Далее выбираем пункт Ranking — он позволяет задать размер вершины в зависимости от какого-либо параметра. У нас есть возможность выбрать только один параметр — Degree (степень), который показывает, сколько ребер выходят из вершины. Выбираем минимальный и максимальный размер кружочка и жмем кнопку «Применить». Здесь же, если выбрать другие пиктограммки, можно настроить цвет маркера вершины и цвет ребер. Теперь граф уже более нагляден.

Следующее, что нужно сделать, — распутать граф. Это можно сделать вручную, двигая вершины, а можно использовать алгоритмы укладки, которые реализованы в Gephi.
Чего мы добиваемся правильной укладкой? Максимальной наглядности. Чем меньше на графе наложений вершин и ребер, чем меньше пересечений ребер, тем лучше. Также неплохо было бы, чтобы смежные вершины были расположены поближе друг к другу, а несмежные —подальше друг от друга. Ну и все было распределено по видимой области, а не сжато в одну кучу.
Как это сделать в Gephi? Левое нижнее окно «Укладка» содержит самые популярные алгоритмы укладки, построенные на силовых аналогиях. Представьте, что вершины — это заряженные шарики, который отталкиваются друг от друга, но при этом некоторые скреплены чем-то, похожим на пружинки. Если задать соответствующие силы и «отпустить» граф, вершины разбегутся на максимально допустимые пружинками расстояния.

Можно помочь алгоритму и, не останавливая его, поперетаскивать некоторые вершины, стараясь распутать граф. Но помните, что здесь нет кнопки «Отменить», вернуться к прежнему расположению вершин уже не удастся. Поэтому сохраняйте новые версии проекта перед каждым рискованным изменением.
Еще один полезный алгоритм — Force Atlas 2. Он представляет граф в виде металлических колец, связанных между собой пружинами. Деформированные пружины приводят систему в движение, она колеблется и в конце концов принимает устойчивое положение. Этот алгоритм хорош для визуализаций, подчеркивающих структуру группы и выделяющих подмножества с высокой степенью взаимодействия.
Этот алгоритм имеет большое количество настроек. Рассмотрим наиболее важные. «Запрет перекрытия» запрещает вершинам перекрывать друг друга. Разреженность увеличивает расстояние между вершинами, делая граф более читаемым. Также более воздушным граф делает уменьшение влияния весов ребер на взаимное расположение вершин.
Поигравшись с настройками, получим такой граф:

Получив граф в том виде, который вас устраивает, переходите к финальной обработке. Это закладка «Просмотр». Здесь мы можем задать, например, отрисовку графа кривыми ребрами, которая минимизирует наложение вершин на чужие ребра. Можем включить подписи вершин, задав размер и цвет шрифта. Наконец, поменять фон подложки. Например, так:

Для того чтобы сохранить получившийся рисунок, нажмите на надпись «Экспорт SVG/PDF/PNG в левом нижнем углу окна. Также отдельно не забудьте сохранить сам проект через верхнее меню «Файл» — «Сохранить проект».
В нашем случае принципиально было выделить взаимосвязь сквозных технологий с рынками НТИ, для чего мы вручную выстроили все рынки в одну линию в центре и разместили все остальное сверху и снизу. Получился вот такой граф. Все-таки для решения конкретных задач без ручной расстановки вершин обойтись не удалось.

Вы, наверное, думаете, как нам удалось раскрасить вершины в разный цвет? Есть одна хитрость. Можно перейти в закладку «Лаборатория данных», создать там новый столбец в вершинах, назвав его «Market». И заполнить для каждой вершины значениями: 1 если это рынок НТИ, 0 — если сквозная технология. Затем достаточно перейти в «Обработку», выбрать пиктограммку в виде палитры, Nodes — Partition, а в качестве разделителя — наш новый атрибут Market.

Для более сложных построений, когда требуется выделить кластеры и закрасить их разными цветами, в Gephi используется богатый арсенал статистических расчетов, результаты которых можно использовать для раздельной окраски. Находятся эти расчеты в правом столбце вкладки «Обработка».

Например, нажав кнопку «Запуск» возле расчета «Модулярность», вы узнаете оценку уровня кластеризации вашего графа. Если после этого выставить цвет вершин в зависимости от Modularity Class, появится симпатичная картинка наподобие такой:

4. Анализ результата
Итак, вы получили итоговую визуализацию графа. Что она вам дает? Во-первых, это красиво, ее можно вставить в презентацию, показать знакомым или сделать заставкой на рабочем столе. Во-вторых, по ней вы можете понять, насколько сложной и многокластерной структурой является рассматриваемая вами предметная область. В-третьих, обратите внимание на самые крупные вершины и на самые жирные связи. Это особенные элементы, на которых все держится.
Так, построив граф экспертного сообщества, посещающего мероприятия в Точке кипения, мы сразу обнаружили участников, которые с наибольшей вероятностью выполняют роль суперконнекторов. Они являлись «вершинами», через которые кластеры объединялись в единое целое. А во втором случае мы увидели, как выглядит концентрация специалистов из томских компаний с точки зрения их принадлежности к рынку и сквозной цифровой технологии, на которую они делают ставку. Это косвенно говорит об уровне технологических компетенций и экспертизы региона.
Помощь графов в понимании окружающей действительности реально велика, так что не поленитесь и попробуйте создать собственную визуализацию данных. Это совсем не сложно, но порой трудозатратно.
Граф – совокупность точек, соединенных линиями. Точки называются вершинами , или узлами , а линии – ребрами , или дугами .
Степень входа вершины – количество входящих в нее ребер, степень выхода – количество исходящих ребер.
Граф, содержащий ребра между всеми парами вершин, является полным .
Встречаются такие графы, ребрам которых поставлено в соответствие конкретное числовое значение, они называются взвешенными графами , а это значение – весом ребра .
Когда у ребра оба конца совпадают, т.е. оно выходит из вершины и входит в нее, то такое ребро называется петлей .

Классификация графов
Графы делятся на
В связном графе между любой парой вершин существует как минимум один путь.
В несвязном графе существует хотя бы одна вершина, не связанная с другими.
Графы также подразделяются на
В ориентированном графе ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
В неориентированном графе по каждому из ребер можно осуществлять переход в обоих направлениях.
Частный случай двух этих видов – смешанный граф. Он характерен наличием как ориентированных, так и неориентированных ребер.
Способы представления графа
Граф может быть представлен (сохранен) несколькими способами:
- матрица смежности;
- матрица инцидентности;
- список смежности (инцидентности);
- список ребер.
Использование двух первых методов предполагает хранение графа в виде двумерного массива (матрицы). Размер массива зависит от количества вершин и/или ребер в конкретном графе.
Матрица смежности графа — это квадратная матрица, в которой каждый элемент принимает одно из двух значений: 0 или 1.
Число строк матрицы смежности равно числу столбцов и соответствует количеству вершин графа.
- 0 – соответствует отсутствию ребра,
- 1 – соответствует наличию ребра.

Когда из одной вершины в другую проход свободен (имеется ребро), в ячейку заносится 1, иначе – 0. Все элементы на главной диагонали равны 0 если граф не имеет петель.
Матрица инцидентности (инциденции) графа — это матрица, количество строк в которой соответствует числу вершин, а количество столбцов – числу рёбер. В ней указываются связи между инцидентными элементами графа (ребро(дуга) и вершина).
В неориентированном графе если вершина инцидентна ребру то соответствующий элемент равен 1, в противном случае элемент равен 0.
В ориентированном графе если ребро выходит из вершины, то соответствующий элемент равен 1, если ребро входит в вершину, то соответствующий элемент равен -1, если ребро отсутствует, то элемент равен 0.

Матрица инцидентности для своего представления требует нумерации рёбер, что не всегда удобно.
Список смежности (инцидентности)
Если количество ребер графа по сравнению с количеством вершин невелико, то значения большинства элементов матрицы смежности будут равны 0. При этом использование данного метода нецелесообразно. Для подобных графов имеются более оптимальные способы их представления.
Преимущества списка смежности:
- Рациональное использование памяти.
- Позволяет быстро перебирать соседей вершины.
- Позволяет проверять наличие ребра и удалять его.
Недостатки списка смежности:
- При работе с насыщенными графами (с большим количеством рёбер) скорости может не хватать.
- Нет быстрого способа проверить, существует ли ребро между двумя вершинами.
- Количество вершин графа должно быть известно заранее.
- Для взвешенных графов приходится хранить список, элементы которого должны содержать два значащих поля, что усложняет код:
- номер вершины, с которой соединяется текущая;
- вес ребра.
Алгоритмы обхода графов
Основными алгоритмами обхода графов являются
Поиск в ширину подразумевает поуровневое исследование графа:- вначале посещается корень – произвольно выбранный узел,
- затем – все потомки данного узла,
- после этого посещаются потомки потомков и т.д.
Вершины просматриваются в порядке возрастания их расстояния от корня.
Алгоритм прекращает свою работу после обхода всех вершин графа, либо в случае выполнения требуемого условия (например, найти кратчайший путь из вершины 1 в вершину 6).
Каждая вершина может находиться в одном из 3 состояний:Фиолетовый – рассматриваемая вершина.
Применения алгоритма поиска в ширину
- Поиск кратчайшего пути в невзвешенном графе (ориентированном или неориентированном).
- Поиск компонент связности.
- Нахождения решения какой-либо задачи (игры) с наименьшим числом ходов.
- Найти все рёбра, лежащие на каком-либо кратчайшем пути между заданной парой вершин.
- Найти все вершины, лежащие на каком-либо кратчайшем пути между заданной парой вершин.
Алгоритм поиска в ширину работает как на ориентированных, так и на неориентированных графах.
Для реализации алгоритма удобно использовать очередь.
1
Реализация на C++ (с использованием очереди STL)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35![Результат обхода графа в ширину]()
Результат выполнения
Задача поиска кратчайшего пути
1
Реализация на С++
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
Результат выполнения
Поиск в глубину – это алгоритм обхода вершин графа.Поиск в ширину производится симметрично (вершины графа просматривались по уровням). Поиск в глубину предполагает продвижение вглубь до тех пор, пока это возможно. Невозможность продвижения означает, что следующим шагом будет переход на последний, имеющий несколько вариантов движения (один из которых исследован полностью), ранее посещенный узел (вершина).
Отсутствие последнего свидетельствует об одной из двух возможных ситуаций:
- все вершины графа уже просмотрены,
- просмотрены вершины доступные из вершины, взятой в качестве начальной, но не все (несвязные и ориентированные графы допускают последний вариант).
Каждая вершина может находиться в одном из 3 состояний:
- 0 - оранжевый – необнаруженная вершина;
- 1 - зеленый – обнаруженная, но не посещенная вершина;
- 2 - серый – обработанная вершина;
Фиолетовый – рассматриваемая вершина.
Применения алгоритма поиска в глубину
- Поиск любого пути в графе.
- Поиск лексикографически первого пути в графе.
- Проверка, является ли одна вершина дерева предком другой.
- Поиск наименьшего общего предка.
- Топологическая сортировка.
- Поиск компонент связности.
Алгоритм поиска в глубину работает как на ориентированных, так и на неориентированных графах. Применимость алгоритма зависит от конкретной задачи.
Для реализации алгоритма удобно использовать стек или рекурсию.
1
Реализация на C++ (с использованием стека STL)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36![Результат обхода графа в глубину]()
Результат выполнения
1
Задача поиска лексикографически первого пути на графе.
Реализация на C++
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64Результат выполнения
Поиск в глубину также может быть реализован с использованием рекурсивного алгоритма.
Реализация обхода графа в глубину на C++ (с использованием рекурсии)
Наглядным средством представления состава и структуры системы является граф .
Слово «граф» в математике означает картинку, где нарисовано несколько точек, некоторые из которых соединены линиями. В процессе решения задач математики заметили, что удобно изображать объекты точками, а отношения между ними — отрезками или дугами.
Основы теории графов как математической науки заложил в \(1736\) г. Леонард Эйлер , рассматривая задачу о Кёнигсбергских мостах. Сегодня эта задача стала классической.
![21 28.jpg]()
Графом называется конечное множество точек, некоторые из которых соединены линиями.
Точки называются вершинами графа, а соединяющие линии — рёбрами.
![22.jpg]()
Количество рёбер, выходящих из вершины графа, называется степенью вершины .
Вершина графа, имеющая нечётную степень, называется нечётной, а чётную степень — чётной.
![23.jpg]()
Изолированная вершина — вершина, степень которой равна \(0\).
Конечная вершина графа — вершина, степень которой равна \(1\).
Линия ненаправленная (без стрелки) называется ребром .
Линия, выходящая из некоторой вершины и входящая в неё же, называется петлёй .
![24.jpg]()
Рассмотрим отношение «дети переписываются» (пишут письма друг другу). Отношение является двусторонним, поэтому вершины соединены линиями без стрелок.
Взвешенный граф — граф, каждому ребру которого поставлено в соответствие некое значение (вес ребра).
Граф, в котором все вершины соединены рёбрами, называется неориентированным .
Цепь — путь по вершинам и рёбрам, включающий любое ребро графа не более одного раза.
Цикл — цепь, начальная и конечная вершины которой совпадают.
Ориентированный граф — граф, рёбрам которого присвоено направление.
С помощью таких графов могут быть представлены схемы односторонних отношений.
![26.jpg]()
Если все вершины графа чётные, то можно одним росчерком пера начертить граф. При этом начать движение можно с любой вершины и закончить в той же вершине.
Граф с двумя нечётными вершинами также можно начертить одним росчерком. Начинать движение надо с одной нечётной вершины, а заканчивать в другой.Граф с большим количеством нечётных вершин невозможно начертить таким образом.
Читайте также:






