
Что значит все есть файл
Перед тем как перейти к чтению следующих глав, вы должны понять философию ОС Inferno, которая базируется на идее "Всё есть файл". Любой ресурс, предоставляемый операционной системой любому приложению является файлом. Мышь - это файл, экран - файл, видеодаптер - опять файл, сетевое соединение - снова файл. Inferno построена из кирпичиков под названием файл и это особенность дает ей ряд приемуществ, включая сетевую прозрачность, цельность, компактность и просту.
В следующих разделах мы рассмотрим три ключевые компонента модели "Всё есть файл".
Протокол Styx [ ]
Коммуникационный протокол Styx (P9 в Plan9) - центральная часть операционной системы Inferno. Все без исключения приложения операционной системы получают доступ к файлам (как локальным, так и удаленным) с его помощью.
Протокол Styx является той самой средой, по которой передаются запросы на открытие, чтение и запись файлов. Тот факт, что приложение, пославшее запрос на открытие файла, передает этот запрос в дальнейшем протоколу Styx, и делает возможным перенаправлять приходящие запросы как внутри локальной системы, так и обращаться к удаленным машинам. При этом, для приложения удаленные ресурсы выглядят в точности аналогично локальным.
Файловые серверы [ ]
Файловые серверы представляют собой специальные программы, экспортирующие собственные ресурсы (в виде файлов) по протоколу Styx. Любая другая программа или пользователь может обратиться к этим файлам для получения управления над файловым сервером или использования его возможностей. В Inferno файловые серверы везде: это и драйвера, и файловые системы, и оконный интерфейс, и все что угодно. В идеале, любая программа для ОС Inferno, не носящая утилитарный характер, должна быть файловым сервером.
Хороший пример файлового сервера - сервер соединений cs(8) , экспортирующий всего один файл - /net/cs. Его задача - преобразовывать символьные имена удаленных машин и сервисов в инструкции для подключения к этим машинам и сервисам. Сервер соединений должен быть запущен в любой копии Inferno, предназначенной для сетевого взаимодействия. Выполните команду ndb/cs, а затем просмотрите список файлов каталога /net:
Вы должны увидеть файл /net/cs в выводе:
Теперь выполните команду ndb/csquery и укажите ей какой-либо адрес:
Последняя строка - это и есть инструкция на подключение к серверу $signer (которую мы разберем в следующем подразделе).
Драйвера [ ]
Драйвера устройств в Inferno также представляют собой файловые серверы, единственное отличие которых в том, что они работают в режиме ядра. Обычно драйвера экспортируют ресурсы низлежащего оборудования в виде файлов каталога /dev, но это скорее закономерность, чем требование. Например, драйвер сетевого стека ip(3) экспортирует ресурсы в виде файлов каталога /net, обращаясь к которым можно создать или завершить соединение или получать данные от удаленного узла. Поэтому строка:
из предыдущего раздела, это ничто иное как инструкция о том, что нужно сделать с файлами каталога /net для создания нового подключения к серверу 200.1.1.67 ($signer) и порту 6673 (inflogin), а именно: открыть файл /net/tcp/clone и записать в него строку 200.1.1.67!6673.
Пространство имен [ ]
В отличие от других ОС, Inferno следует идее обособленных пространств имен для каждого процесса и пользователя. Это значит, что структура видной приложениям (а следовательно и пользователям) файловой системы никогда не бывает статической и может изменяться во времени, причем изменения, произведенные одним приложением/пользователем не отражаются на пространстве имен другого приложения/пользователя.
По самой своей сути пространство имен есть ни что иное, как растущее из корня файловое дерево, к каждой ветви (каталогу) которого в любое время можно подключить новый набор каталогов и файлов, экпортируемых (по протоколу Styx) драйверами, файловыми серверами или удаленными машинами.
Важно понимать, что это файловое дерево и есть единственный путь взаимодействия пользователя/приложения с операционной системой Inferno. Оно может (и должно) хранить необходимые пользователю приложения, личные данные пользователей, файлы, предоставлющие доступ к ресурсам ОС, ПК и приложений.
Являясь деревом, пространство имен полностью подчиняется идее постоянного роста. Сразу после старта ОС пространство имен системного пользователя eve имеет лишь корень (так называемый корневой каталог /). Чтобы пользователь смог работать с ОС, ядро (на последнем этапе инициализации) создает так называемое начальное пространство имен.
// TODO: вставить этот пример:
Приведенная последовательность может быть несколько иной в завивсимости от типа низлежащей ОС или факта запуска ОС на голом железе. В любом случае, последовательность команд, нужная для формирования этого пространства имен будет выглядеть так:
Обычно команда bind используется для подключения содержимого уже существующего в текущем пространстве имен каталога к другому каталогу (например, вы можете создать каталог /dev2 и выполнить команду "bind /dev /dev2", которая создаст копию (а точнее зеркальное отражение) файлов каталога /dev в каталоге /dev2). Но bind также применяется для подключения файлов, экспортируемых драйверами устройств.
bind source target
bind -a source target
bind -b source target
-c additionally permits creation of files in the union directory. A new file name is entered into the first directory within a union where creation is possible.
// TODO Mount introduces an external file tree into the namespace, just as it does on unix systems. The file tree is accessed by talking the styx protocol over a file descriptor. The kernel takes care of the styx-part by translating open/read/write/stat/etc system calls into styx messages (the messages are described in section 5 of the manual pages), and the response messages into return values. The mount system call expects a file descriptor to talk styx over. The mount program has convenient syntax for mounting three types of styx servers:
mount /path/to/styx/file target, gets file descriptor by opening /path/to/styx/file
mount target, starts program and uses its stdin as file descriptor
Причина использования команды bind для подключения файлов, экспортируемых драйверами устройств, кроется в том, что согласно внутренним механизмам работы Inferno, эти файлы уже существуют в пространстве имен (они появляются во время инициализации драйвера), но до фактического вызова bind к ним невозможно получить доступ. Именно для этого были придуманы инексы. Вы можете убедится в этом просмотрев листинг файлов, экпортируемых любым из описанных выше драйверов устройств: // TODO: разобрать это все
Вы можете увидеть последовательность команд, которые были выполнены для создания текущего пространства имен, запустив следующую команду:
Настройка сетевой карты [ ]
Для наглядной демонстрации того, как используются пространства имен и файловые серверы в повседневной работе с Inferno, рассмотрим пример настройки сетевой карты (если вы используете гостевой вариант Inferno, этого делать не потребуется, так Inferno будет использовать сетевой стек низлежащей ОС):
2. Получаем новый сетевой интерфейс:
3. Устанавливаем связь между сетевой картой и интерфейсом:
4. Задаем интерфейсу IP адрес и маску сети:
5. Добавляем запись в таблицу маршрутизации и прописываем маршрут по-умолчанию
Все эти команды необязательно выполнять при каждом запуске ОС, в разделе Настройка будет приведен пример перманентной настройки сети, которая будет осуществляться в автоматическом режиме при каждом запуске ОС.
Сетвое взаимодействие [ ]
An existing namespace can be exported with styxlisten. Use it as in the following example:
styxlisten 'tcp!*!styx' export / This will listen for tcp connections on the port "styx" (which is defined in /lib/ndb/common to be 6666). All connections will be served by a single invocation of export / (styxlisten expects the program to serve the styx protocol on its file descriptor 0). The program "export" simply exports the namespace starting at the parameter it is passed, the root of the file system in this case. These simple programs (they are just over 300 lines combined!) give a lot of power. Just as with mount, option -A disables authentication on the connection.

В Unix-подобных системах, куда входит и Linux, существует концепция «Всё есть файл». Согласно ей, работа с системой сводится к работе с файлами. Однако файлы в системе «Линукс» бывают разные. Об этом — наша статья.
К файлам в системе Linux относят и объекты, куда мы записываем наши данные, и исполняемые файлы, и файлы специального назначения (устройств, туннелей, сокетов и пр.). Но всё это неважно, ведь мы в любом случае работаем именно с файлами, которые используются и для обычных данных, и для устройств.
Преимущество такой концепции заключается в том, что отпадает необходимость в реализации отдельного набора API для каждого устройства, в результате чего с ним способны работать все стандартные программы системы «Линукс» и API-интерфейсы.
Основные типы файлов Linux
В системе Linux файлы делят на 3 главных типа: 1) обыкновенные (для хранения информации); 2) специальные (для туннелей и устройств); 3) директории.
Теперь рассмотрим каждый из этих типов подробнее.
Обыкновенные файлы
С обычными файлами мы работаем ежедневно. Они содержат текст, изображения, инструкции для работы софта и прочие данные. Это наиболее распространённый файловый тип в системе Linux. Сюда входят: 1) текстовые файлы; 2) файлы изображений, архивов, библиотек; 3) исполняемые и другие файлы.
Для определения файлового типа в режиме списка используется утилита ls. Обычные файлы будут обозначаться чертой:

Говоря об обычных файлах в системе, обязательно упомянем форматы. Чтобы система понимала, какой утилитой открывать файлы, необходимо, чтобы они были сохранены в конкретном формате. Форматы тоже можно посмотреть, но уже с помощью команды file:

В примере выше система сообщила, что файл является исполняемым. А вот как обстоит дело в случе, если он текстовый:

Так вы можете посмореть все файловые форматы:
Специальные файлы
Файлы этого типа обеспечивают обмен информацией с ядром, работу с устройствами либо общение между утилитами. С учётом своего назначения они делятся на несколько видов: 1.Блочные. Файлы устройств, обеспечивающие буферный доступ к аппаратным компонентам. В процессе записи информации на жёсткий диск либо съёмный носитель данные не записываются сразу — это нерационально с точки зрения расходования ресурсов. Поэтому данные сначала собираются в буфере, для чего и используются блочные файлы. Они способны передавать большие блоки информации за один раз, и с их помощью файловая система и прочие утилиты получают возможность взаимодействовать с драйверами аппаратных устройств.
Если вернутся к уже упомянутой программе ls, то блочные файлы обозначаются буквой b. Давайте выведем их из /dev:

Файловые типы также умеет определять и утилита file:

2.Символьные. С их помощью обеспечивается небуферизованный доступ к ядру и аппаратным компонентам. Это значит, что они могут передавать за раз лишь один символ. В остальном, это те же файлы устройств.
Как и в случае с блочными, вы можете отсортировать их посредством ls. Для символьных файлов предусмотрена буква c (character):

3.Символические ссылки. Они указывают на другие файлы по их имени, способны указывать и на обыкновенные файлы, и на каталоги, и на другие файловые типы. Можно сказать, что они аналогичны ярлыкам в системе Windows. Обозначаются буквой l (link):

Создать символические ссылки можно посредством утилиты ln:
4.Туннели/именованные туннели. Обеспечивают настройку связи между 2-мя процессами в системе, перенаправляя вывод одного на вход другого. Туннели именованного типа тоже применяются для связи между 2-мя процессами и функционируют, как и обыкновенные туннели.
Для их обозначения существует буква p (pipe):

Для создания именованного туннеля воспользуйтесь утилитой mkfifo:
В примере выше мы создали туннель и передали в него информацию, а оболочка стала неинтерактивной. Прочитать данные можно на другом конце туннеля:
5.Файлы сокетов. Создают прямую связь между процессами в системе. Передают данные между процессами, которые запущены в различных средах либо даже на различных машинах. Означает это следующее: посредством сокетов программы могут осуществлять обмен информацией даже по сети. Работа сокета похожа на работу туннеля, но в обе стороны.
Для обозначения предусмотрена буква s:

Создадим Unix-сокет с помощью утилиты nc:

И теперь подключимся к этому сокету из другой консоли:
Связь функционирует в обоих направлениях, поэтому после нажатия Enter вся информация, которую вы будете вводить в одной из консолей, станет отправляться в другую.
Каталоги
Каталог может содержать и обычные, и специальные файлы, то есть любые файловые типы в системе Linux. Они объединяют файлы (а также другие каталоги) в группы, чтобы упростить навигацию и поиск. В системе Linux файлы организовываются в папки, начиная от корня (/).
Каталоги обозначаются буквой d (directory):

Для создания каталога используют команду mkdir :
Вывод
В статье мы рассмотрели довольно простые вещи, которые касались типов файлов в Linux. Но если вы хотите освоить администрирование операционной системы Linux на продвинутом уровне, имеет смысл ознакомиться со специализированным курсом от практикующих администраторов. Не пропустите:
Стартовое Руководство Пользователя описывает концепцию прав доступа к файлам, а также понятия владельца файла, но в действительности для файловых систем UNIX (это относится и к GNU/Linux' ext2fs) требуется, чтобы мы ввели определение файла.
Различные Типы Файлов
Если вы помните, при вводе команды ls -l, символ перед правами доступа идентифицирует тип файла. Мы уже видели два типа файлов: обычный файл (-) и каталог (d). Блуждая по диску, вы также можете встретить и другие типы файлов:
Символьные файлы: это любые специальные системные файлы (типа /dev/null, который мы уже обсуждали), или периферийные устройства (последовательные или параллельные порты), которые разрешают совместное использование своего содержания без буферизации (их значение не сохраняется в памяти). Такие файлы идентифицированы символом c.
Файлы блочного доступа: Эти файлы - являются периферийными устройствами, и, в отличие от символьных файлов, их содержание - буферизируется . В эту категорию входят такие файлы, как например: жесткие диски, разделы на жестком диске, дисководы для гибких дискет, CD-ROM, и так далее. Примерами файлов блочного доступа могут служить файлы /dev/hda, /dev/sda5. В результате выполнения команды ls -l, они идентифицированы символомb.
Сокеты (socket: розетка, разъем): Этот тип файла для всех сетевых подключений. Только некоторые из них имеют названия. Нужно заметить, что сокеты бывают нескольких типов, но эта тема выходит за рамки данной книги. Такие файлы идентифицированы символом 's'.
Вот примеры каждого типа файлов:
Inode
Иначе говоря UNIX не идентифицирует файл по его имени . Вместо этого используется номер [18] из таблицы inode. Причина для этого заключается в том, что файл может иметь несколько названий, или вообще не иметь никакого названия. Имя файла в UNIX, является только указателем на inode. Такой указатель называется link (линк или ссылка). Давайте рассмотрим ссылки более подробно.
[18] Важно: обратите внимание, что номер inode уникален в пределах файловой системы , что означает, что inode с тем же самым номером может существовать на другой файловой системе. Это приводит к различию между дисковым inode и inode в оперативной памяти. Два дисковых inode могут иметь один и тот же номер, если они находятся на двух различных файловых системах. В оперативной памяти inode имеет уникальный номер на всю систему.
В статье показано, как в Linux/FFmpeg организована кодовая база на C с учётом расширяемости, которая работает так, будто в C есть полиморфизм. Вы увидите, как концепция Linux «всё — файл» работает на уровне исходного кода, а также как FFmpeg позволяет быстро и легко добавлять поддержку новых форматов и кодеков.
Качественный дизайн ПО — введение
В процессе работы над кодом программисты регулярно сталкиваются с тем, что качественный дизайн кода окупается впоследствии при усложнении продукта. Для создания полезного и легко поддерживаемого в долгосрочной перспективе ПО разработчики подбирают определённые шаблоны и объединяют их в абстракции, и похоже, что разработчики Linux и FFmpeg поступили именно так.
При разработке программ создаются структуры данных и определяются их зависимости и поведение. То, как они построены и связаны между собой, можно рассматривать как дизайн/архитектуру ПО.
Предположим, что мы разрабатываем фреймворк для обработки видео- и аудиофайлов. Кодеки AV1, H264, HEVC и AAC производят некоторые идентичные операции с данными, и если мы разработаем некоторую обобщённую абстракцию, включающую эти операции, мы сможем использовать эту абстракцию вместо того, чтобы реализовывать конкретную идею, заложенную в каждом отдельном кодеке.
Ещё один хороший приём — использовать слабо связанные компоненты, чётко определив их функции.
Возможно, эти концепции проще понять на практике. Сделаем примерный набросок фреймворка для обработки потоковых медиаданных, использующего несколько разных кодеков.
Этот код на Ruby отражает одну из описанных выше концепций. Без конкретизации в коде предполагается, что каждый кодек реализует функции encode и decode. Поскольку Ruby — язык с динамической типизацией, любой класс может иметь реализацию этих двух операций и работать как кодек.
Такой дизайн кода можно назвать хорошим, поскольку если нам потребуется добавить новый кодек, нужно только включить его реализацию в список. Разумеется, список можно сделать и динамическим. Смысл примера в том, что такой код легко расширять и поддерживать, поскольку компоненты слабо связаны между собой и каждый из них делает только то, что должен.
Фреймворк Ruby on Rails подталкивает к определённым способам организации кода, реализуя архитектуру «Модель-Представление-Контроллер» (MVC).
Обращаясь к языкам со статической типизацией, таким как Go, нам придётся быть более формальными, описывая требуемые типы, но мы всё равно можем создать код, аналогичный приведённому выше.
Тип interface в Go намного мощнее аналогичной конструкции в Java, так как его определение никак не связано с реализацией, и наоборот. Можно даже присвоить каждому кодеку тип ReadWriter и использовать в таком виде.
На C тоже можно создать код с аналогичным поведением, но будут некоторые отличия.
Сначала в обобщённой структуре мы определяем абстрактные операции (в данном случае функции). Затем мы наполняем их конкретным кодом, например кодером и декодером кодека av1.
Множество других языков поддерживают сходные механизмы распределения методов или функций, как если бы они придерживались некой конвенции. В результате ПО на уровне ОС достаточно уметь работать только с показанными высокоуровневыми абстракциями.
Linux kernel и концепция «всё — файл»
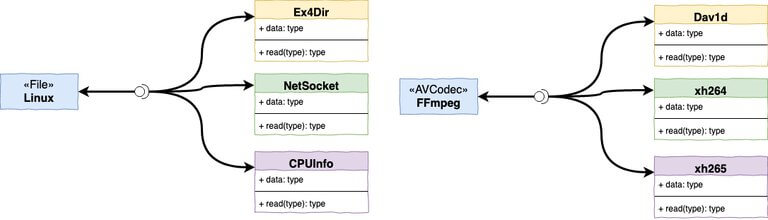
Концепция «всё — файл» ОС Linux позволяет использовать один интерфейс для работы с любыми ресурсами системы. Например, Linux обрабатывает сетевые сокеты, особые файлы (такие как /proc/cpuinfo) и даже USB-устройства как файлы.
Этот подход облегчает разработку программ для ОС, поскольку мы можем использовать хорошо изученный набор операций для абстракции, названной «файлом». Вот как это работает:
Это возможно только потому, что концепция файла (структуры данных и операции) была разработана как один из главных способов взаимодействия подсистем. Вот участок API-структуры file_operations :
Эта структура чётко определяет то, что мы подразумеваем под концепцией файла, и какое поведение мы от него ожидаем:
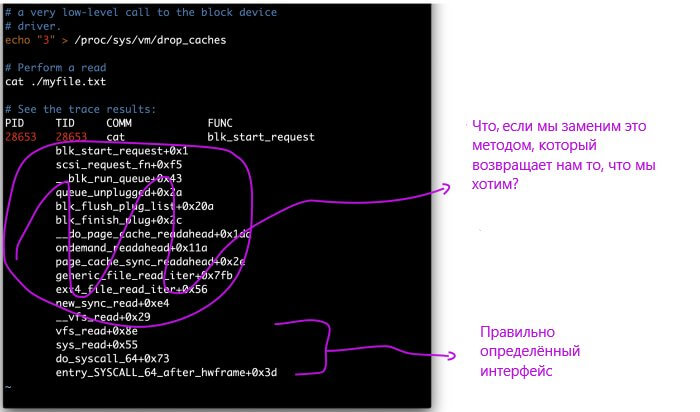
Здесь можно увидеть набор функций, реализующих это поведение, в файловой системе ext4.
Даже файлы cpuinfo proc реализованы через эту абстракцию. Фактически, работая с файлами под Linux, вы используете виртуальную файловую систему (VFS), которая в свою очередь обращается к функциям абстракции.
FFmpeg — форматы
Вот общая схема архитектуры процессов FFmpeg, демонстрирующая, что внутренние компоненты связаны в основном через такие абстрактные концепции, как AVCodec, а не напрямую через конкретные кодеки.

Для входящих файлов в FFmpeg создаётся структура AVInputFormat, реализуемая любым форматом (видеоконтейнером), который требуется использовать. Файлы MKV также заполняют эту структуру своей реализацией, как и формат MP4 — своей.
Такой дизайн позволяет легко интегрировать новые кодеки, форматы и протоколы. В мае 2019 года в FFmpeg был включён кодек DAV1d (аналог av1 с открытым исходным кодом), и, изучив изменения в коде, вы увидите, насколько безболезненно прошло внедрение. В итоге ему только требуется зарегистрироваться в качестве доступного кодека и придерживаться списка общих операций.
Безотносительно используемого нами языка мы всегда можем как минимум попытаться создать код со слабой зависимостью и высокой согласованностью. Именно эти два основных свойства позволят вам писать ПО, которое легко расширять и поддерживать.
Читайте также: