
Что такое репликация файлов
В статье мы расскажем, что такое репликация и где она применяется. Также на примере двух виртуальных серверов настроим репликацию данных в PostgreSQL и проверим, что она работает.
Что такое репликация
Репликация — это дублирование данных, когда данные с одного сервера полностью повторяются на других. Приложения пишут данные в одну базу данных PostgreSQL, а изменения автоматически синхронизируются на другие базы.
Репликация используется для достижения двух целей:
- Повышение отказоустойчивости. Если один из серверов выйдет из строя, то остальные продолжат работу.
- Повышение производительности. Распределение данных по серверам в разных частях страны или мира повышает скорость доступа к данным для местных пользователей.
Виды репликации в PostgreSQL
Существует несколько видов репликаций, у каждого из них свои особенности. Но прежде чем рассказывать о видах, нужно хотя бы поверхностно познакомиться с WAL — журналом предзаписи транзакций.
Когда PostgreSQL получает команду на изменение данных, она не сразу изменяет их на диске. Сначала она записывает изменения в WAL. Этот журнал нужен для того, чтобы в случае сбоя сервера можно было восстановить незафиксированные данные. Также WAL используется и для репликации данных.
Итак, в PostgreSQL есть несколько видов репликации:
Потоковая репликация (Streaming Replication). Это репликация, при которой от основного сервера PostgreSQL на реплики передается WAL. И каждая реплика затем по этому журналу изменяет свои данные. Для настройки такой репликации все серверы должны быть одной версии, работать на одной ОС и архитектуре. Потоковая репликация в Postgres бывает двух видов — асинхронная и синхронная.
- Асинхронная репликация. В этом случае PostgreSQL сначала применит изменения на основном узле и только потом отправит записи из WAL на реплики. Преимущество такого способа — быстрое подтверждение транзакции, т.к. не нужно ждать пока все реплики применят изменения. Недостаток в том, что при падении основного сервера часть данных на репликах может потеряться, так как изменения не успели продублироваться.
- Синхронная репликация. В этом случае изменения сначала записываются в WAL хотя бы одной реплики и только после этого фиксируются на основном сервере. Преимущество — более надежный способ, при котором сложнее потерять данные. Недостаток — операции выполняются медленнее, потому что прежде чем подтвердить транзакцию, нужно сначала продублировать ее на реплике.
Логическая репликация (Logical Replication). Логическая репликация оперирует записями в таблицах PostgreSQL. Этим она отличается от потоковой репликации, которая оперирует физическим уровнем данных: биты, байты, и адреса блоков на диске. Возможность настройки логической репликации появилась в PostgreSQL 10.
Этот вид репликации построен на механизме публикации/подписки: один сервер публикует изменения, другой подписывается на них. При этом подписываться можно не на все изменения, а выборочно. Например, на основном сервере 50 таблиц: 25 из них могут копироваться на одну реплику, а 25 — на другую.
Также есть несколько ограничений, главное из которых — нельзя реплицировать изменения структуры БД. То есть если на основном сервере добавится новая таблица или столбец — эти изменения не попадут в реплики автоматически, их нужно применять отдельно.
В отличие от потоковой репликации, логическая может работать между разными версиями PostgreSQL, ОС и архитектурами.
Облачные базы данных
Готовые к работе управляемые базы данных MySQL с встроенной репликацией.Установить PostgreSQL
Перейдем к практике: настроим потоковую асинхронную репликацию в режиме Master-Replica: один сервер — основной, в него можно писать данные, другой — реплика, из него можно только читать.
На примере платформы Selectel создадим два отдельных сервера PostgreSQL, один из которых будет основным (Master), а второй — репликой (Replica).
В панели управления платформой заходим в раздел «Облачная платформа» — «Серверы», нажимаем кнопку «Создать сервер».

Укажем имя сервера — Master. Так нам будет проще ориентироваться в серверах. Выберем ОС — Ubuntu 20.04, конфигурацию — 2 vCPU, 8 ГБ оперативной памяти и 10 ГБ диска.
В разделе «Сеть» нужно выбрать подсеть с публичным адресом, чтобы к виртуальной машине можно было подключаться из интернета. В разделе «Доступ» нужно проверить, что вы либо записали пароль root-пользователя, либо указали правильный SSH-ключ для подключения к машине.

По такому же принципу создаем второй сервер, только укажем другое имя — Replica. Остальные параметры оставим такими же.
В итоге у нас получилось два сервера. Обратите внимание, что у них есть публичные и приватные IP-адреса.
Публичные адреса мы будем использовать для подключения к машинам, а приватные — для настройки репликации.

Теперь нужно подключиться к каждому серверу по SSH. Рекомендуем открыть 2 окна терминала и держать их открытыми, потому что мы будем часто переключаться между серверами.
Итак, подключаемся к серверам и устанавливаем PostgreSQL на каждом из них:
Все, сервера готовы к настройке репликации. Сейчас они ничем не отличаются друг от друга, кроме названия. Перейдем к настройке каждого из них.
Настроить Master-сервер
Репликацию будем выполнять под пользователем postgres, который автоматически создается после установки PostgreSQL. Установим ему пароль, он нам понадобится позже:
Далее нужно разрешить этому пользователю подключаться из Replica-сервера в Master. Для этого мы отредактируем файл /etc/postgresql/12/main/pg_hba.conf.
Обратите внимание, что мы показываем настройку репликации на примере PostgreSQL 12, поэтому в пути к файлу есть номер — 12. Если у вас другая версия PostgreSQL, то вам нужно поменять путь к файлу.
Итак, откроем файл:
Найдем в нем строчку «If you want to allow non-local connections, you need to add more» и впишем после нее такую строчку:
Так мы разрешаем пользователю postgres подключаться к этому серверу из Replica.
Обратите внимание, что мы используем приватные адреса, потому что виртуальные машины находятся в одной сети. При этом нам не нужно открывать порты, настраивать Firewall и так далее. Если ваши машины будут находиться в разных сетях или вы хотите, чтобы они общались друг с другом по публичным адресам — скорее всего вам придется настроить Firewall.
Далее нужно указать настройки репликации. Открываем конфигурационный файл PostgreSQL:
Находим в нем эти параметры, раскомментируем их и подставляем указанные значения.
Все, Master настроен. Чтобы применить настройки, перезапускаем сервер:
Настроить Replica-сервер
Переключаемся в окно терминала Replica-сервера. Перед началом настройки нужно остановить PostgreSQL-сервер:
Аналогично Master-серверу отредактируем файл pg_hba.conf. В то же самое место вставим ту же самую строчку, но только теперь укажем IP-адрес мастера.
Добавляем в него строчку:
Затем правим файл postgresql.conf. Настройки те же самые, как и у Master, только нужно поменять IP-адрес. Открываем файл на редактирование:
Находим в нем эти параметры, раскомментируем их и подставляем указанные значения:
Сейчас настройки обоих серверов одинаковые, отличаются только IP-адреса. Это потому, что при необходимости реплики могут становиться мастером, а вся разница будет в наличии одного лишь файла. О нем расскажем далее.
Прежде чем Replica-сервер сможет начать реплицировать данные, нужно создать новую БД, идентичную Master-серверу. Для этого воспользуемся утилитой pg_basebackup. Она создаст бэкап с Master-сервера и скачает его на Replica-сервер. Эту операцию нужно выполнять от имени пользователя postgres, поэтому логинимся от него:
Далее переходим в каталог с базой данных:
Удалим каталог с дефолтной БД и снова его создадим, но уже пустой:
Теперь выгрузим БД с мастера. Для выполнения этой команды нужно будет ввести пароль от пользователя postgres, который мы задавали в самом начале настройки Master-сервера.
В этой команде есть важный параметр -R. Он означает, что PostgreSQL-сервер также создаст пустой файл standby.signal. Несмотря на то, что файл пустой, само наличие этого файла означает, что этот сервер — реплика.
Файл standby.signal появился только в PostgreSQL версии 12. Раньше вместо него создавался файл recovery.conf, в котором хранились настройки для подключения к Master-серверу. Имейте это ввиду, если вы используете более ранние версии PostgreSQL.
Возвращаемся в root-пользователя и запускаем PostgreSQL-сервер:
Проверить репликацию
Теперь нужно протестировать репликацию и убедиться, что мы все правильно настроили. На Master-сервере создадим таблицу и вставим в нее одну строчку:
Переключимся в терминал Replica-сервера и проверим, что таблица с данными появилась:
Еще одна проверка — попробуем создать новую таблицу на сервере Replica. Если мы все сделали правильно, то сервер не должен позволить нам этого сделать, потому что он настроен только на репликацию с основной БД.
На Replica-сервере выполняем команду:
Значит репликация настроена правильно.
Теперь покажем, как можно из Replica-сервера сделать Master. Сымитируем ситуацию, что основной сервер вышел из строя. Для этого в консоли управления платформой Selectel просто выключим сервер Master.

Чтобы перевести Replica-сервер в режим записи, выполните команду:
Проверяем, снова пробуем создать новую таблицу:
На этот раз таблица создастся. Значит, мы перевели сервер из режима чтения в режим записи.
Но нужно понимать, что запросы от приложений не начнут автоматически направляться на этот сервер. Если сервисы и приложения подключались к «старому» Master-серверу напрямую, они так и будут пытаться подключаться к нему.
Обычно в такой ситуации используется балансировщик нагрузки. Он сам следит за состоянием серверов и распределяет нагрузку между всеми рабочими инстансами. При этом приложения отправляют запросы не напрямую в СУБД, а в балансировщик нагрузки.
Заключение
Что такое репликация? Это средство организации работы одного или нескольких пользователей с одним и тем же документом, базой данных или другими-файлами на разных компьютерах независимо, без одновременного доступа к файлам, но когда требуется поддерживать некоторую общую версию изменяемых файлов, содержащую в себе все последние исправления, сделанные независимо. Более конкретно, репликация — это процесс создания копий файлов, между которыми может осуществляться обмен обновляемыми данными или объектами. Такие копии называются репликами, а такой обмен — синхронизацией .
Когда нужна репликация? Microsoft приводит два примера необходимости в такой организации работы.
- Вы — агент по продажам и совершаете поездки для посещения клиентов. Перед поездкой вам нужно просмотреть последние заказы и маркетинговые тенденции клиентов, которых вы собираетесь посетить. Эта информация хранится в базах данных о клиентах и заказах вашей компании. Вы загружаете данные о клиентах на свой переносной компьютер. Во время посещения клиента вы обновляете загруженную информацию о клиенте, например: номера телефонов, адреса E-mail и прочую персональную информацию о клиенте на вашем переносном компьютере, а также вносите туда информацию о новых заказах. Однако вам необходимо закончить работу с заказами как можно быстрее. В конце дня вы подключаетесь по Интернету к сети вашей компании через защищенное удаленное соединение и обновляете базы данных о клиентах и заказах. Конфликты данных автоматически разрешаются благодаря имеющимся бизнес-процедурам. После этого вы печатаете и отправляете клиенту по факсу отчет о принятии заказа или отправляете снимок отчета по E-mail, который клиент может просмотреть с помощью программы Просмотр снимков (Snapshot Viewer).
- Вы — разработчик программного обеспечения и хотите закончить работу с приложением вашей компании, отслеживающим статистику об обнаружении и исправлении ошибок в проекте, дома, где нет необходимого или защищенного доступа к корпоративной сети. Вы забираете данные только о ваших ошибках, помещая их на свой переносной компьютер, и отключаете его от корпоративной сети. Затем приходите домой и работаете с имеющимися данными, изменяя поля статуса ошибки и прочие поля с информацией об ошибке. На следующий день* вы подключаете свой переносной компьютер к корпоративной сети и легко син-* хронизируете свои изменения с приложением вашей компании, отслеживающим; статистику ошибок в проекте.
Существует несколько средств репликации баз данных, проектов Access и других файлов.
- Портфельная репликация— средство операционной системы Microsoft Windows. Оно позволяет осуществлять репликацию файлов многих типов, в том числе баз данных Access (файлов MDB), исключая проекты Access (файлы ADP).
- Репликация баз данных и проектов средствами Access — встроенные средства Microsoft Access. Они предназначены для репликации баз данных и проектов Access.
- Репликация с помощью Диспетчера репликации Microsoft— полнофункциональное средство управления репликами, планирования синхронизации и просмотра элементов набора реплик. Диспетчер репликации входит в комплект средств разработчика Microsoft Office 2002 Developer Edition. Описание Диспетчера репликации (Replication Manager) можно найти в документации этого комплекта.
- Репликация файлов на сервере Web — средство сервера Web фирмы Microsoft. Оно позволяет работать с файлами, сохраненными на узле Web, в автономном режиме — без подключения к серверу.
- Программная репликация с помощью интерфейсов DАО и JRO. Создание и управление репликами баз данных Access может осуществляться программно — в процедурах на VBA. Разработчики приложений Access могут обеспечить автоматическую синхронизацию реплик и прочие действия, связанные с репликацией, используя специальные свойства и методы объектов из библиотек VBA: Объекты репликации и Jet (JRO) для репликации баз данных Access 2000 и выше и Объекты доступа к данным (DАО) для репликации баз данных более ранних версий — Access 95 и 97.
Репликация включает следующие действия:
- выбор средства репликации;
- создание реплик;
- синхронизация реплик;
- управление репликами.
Способ выполнения перечисленных действий зависит от выбранного средства репликации. Мы рассмотрим основные вопросы, касающиеся использования перечисленных средств репликации, но не будем касаться темы программирования. Дополнительную информацию о репликации можно найти в справочной системе Access 2002.
Репликация DFS представляет собой службу роли в Windows Server, которая позволяет эффективно реплицировать папки (включая те, ссылка на которые указывается по пути пространства имен DFS) между разными серверами и сайтами. Репликация DFS предоставляет эффективный механизм репликации между несколькими источниками, который поддерживает синхронизацию папок между серверами, соединенными сетевыми подключениями с ограниченной пропускной способностью. Она заменяет собой службу репликации файлов (FRS) в роли подсистемы репликации для пространств имен DFS, а также для репликации папки SYSVOL доменных служб Active Directory (AD DS) в доменах с Windows Server 2008 или более поздним функциональным уровнем.
Репликация DFS использует алгоритм сжатия, называемый удаленным разностным сжатием (remote differential compression — RDC). Алгоритм удаленного разностного сжатия определяет изменение данных в файле, что позволяет репликации DFS реплицировать только измененные блоки файла, а не весь файл.
Дополнительные сведения о переходе с репликации SYSVOL на репликацию DFS см. в этой статье.
Чтобы использовать репликацию DFS, следует создать группы репликации и добавить в них реплицируемые папки. На следующем рисунке представлены группы репликации, реплицируемые папки и элементы.
На этом рисунке видно, что группа репликации представляет собой набор серверов (элементов), между которыми выполняется репликация одной или нескольких папок. Реплицируемая папка — это папка, содержимое которой постоянно синхронизируется между всеми элементами. На рисунке есть две реплицируемые папки: Projects и Proposals. При любом изменении данных в каждой реплицируемой папке все такие изменения реплицируются между элементами группы репликации по установленным подключениям. Подключения между всеми элементами формируют топологию репликации. Создание нескольких реплицируемых папок в одной группе репликации упрощает процесс развертывания реплицируемых папок, так как топология, расписание и регулирование пропускной способности для группы репликации автоматически применяются к каждой реплицируемой папке. Чтобы развернуть дополнительные реплицируемые папки, нужно с помощью программы Dfsradmin.exe или по инструкциям мастера определить локальный путь и разрешения для новой реплицируемой папки.
Каждая реплицируемая папка имеет уникальные параметры, в том числе фильтры файлов и вложенных папок, что позволяет исключать разные файлы и вложенные папки для каждой реплицируемой папки.
Реплицируемые папки, которые хранятся в каждом элементе, могут находиться на разных томах, и их не обязательно делать общими папками или включать в пространства имен. Но оснастка управления DFS позволяет легко предоставить общий доступ к реплицируемым папкам, а при желании — опубликовать их в существующем пространстве имен.
Для управления репликацией DFS можно использовать оснастку управления DFS, команды DfsrAdmin и Dfsrdiag, а также скрипты с вызовом WMI.
Требования
До начала развертывания репликации распределенной файловой системы (DFS) необходимо настроить серверы следующим образом.
- Обновите схему доменных служб Active Directory (AD DS), чтобы включить в нее дополнения для Windows Server 2003 R2 или более поздней версии. Нельзя использовать реплицируемые папки, доступные только для чтения, с дополнениями схемы для Windows Server 2003 R2 или более ранних версий.
- Убедитесь, что все серверы в группе репликации находятся в одном и том же лесу. Репликация на серверах, находящихся в разных лесах, недоступна.
- Установите репликацию DFS на все серверы, которые будут членами группы репликации.
- Чтобы проверить совместимость антивирусного программного обеспечения с репликацией распределенной файловой системы (DFS), свяжитесь с поставщиком антивирусного программного обеспечения.
- Найдите все папки, которые требуется реплицировать, на томах, форматированных в файловой системе NTFS. Репликация DFS не поддерживает файловые системы ReFS (Resilient File System) и FAT. Также репликация DFS не поддерживает репликацию содержимого общих томов кластера.
Взаимодействие с виртуальными машинами Azure
Использование репликации DFS на виртуальной машине в Azure протестировано для Windows Server. Однако существуют некоторые ограничения и требования, которые необходимо соблюдать.
- Использование снимков или сохраненных состояний для восстановления сервера, выполняющего репликацию DFS с целью реплицирования любых данных, кроме папки SYSVOL, приводит к отказу репликации DFS, что требует особых действий по восстановлению базы данных. Точно так же нельзя экспортировать, клонировать или копировать виртуальные машины. Дополнительные сведения см. в статье 2517913 базы знаний Майкрософт и в разделе Безопасная виртуализация DFSR.
- При резервном копировании данных в реплицированной папке, размещенной на виртуальной машине, необходимо использовать программы резервного копирования из гостевой виртуальной машины.
- Службе репликации DFS требуется доступ к физическим или виртуализованным контроллерам домена, так как она не может взаимодействовать непосредственно с AAD.
- Для репликации DFS требуется VPN-подключение между локальными членами группы репликации и другими элементами, размещенными на виртуальных машинах Azure. Необходимо также настроить локальный маршрутизатор (например, Forefront Threat Management Gateway), чтобы разрешить сопоставителю конечных точек RPC (порт 135) и случайным образом назначенному порту в диапазоне между 49152 и 65535 передачу через VPN-подключение. Лучше использовать статический, а не случайный порт, указав его с помощью командлета Set-DfsrMachineConfiguration или средства командной строки Dfsrdiag. Дополнительные сведения о способах указания статического порта для репликации DFS см. в разделе Set-DfsrMachineConfiguration. Сведения о связанных портах, используемых для управления Windows Server, см. в статье 832017 в базе знаний Майкрософт.
Дополнительные сведения о начале работы с виртуальными машинами Azure см. на веб-сайте Microsoft Azure.
Установка репликации DFS
Репликация DFS входит в роль "Файловые службы и службы хранилища". Средства управления для DFS ("Управление DFS", модуль репликации DFS для Windows PowerShell, а также средства командной строки) устанавливаются отдельно в составе средств администрирования удаленного сервера.
Репликацию DFS можно установить с помощью Windows Admin Center, диспетчера сервера или PowerShell, как описано в следующих разделах.
Чтобы установить DFS с помощью диспетчера серверов
Откройте диспетчер серверов, щелкните Управление, а затем нажмите кнопку Добавить роли и компоненты. Откроется мастер добавления ролей и компонентов.
На странице Выбор сервера выберите сервер или виртуальный жесткий диск автономной виртуальной машины, на который требуется установить DFS.
Выберите службы ролей и компоненты, которые следует установить.
Чтобы установить службу репликации DFS", на странице Роли сервера выберите Репликация DFS.
Чтобы установить только средства управления DFS, на странице Компоненты разверните узлы Средства администрирования удаленного сервера, Средства администрирования ролей, Средства файловых служб, а затем выберите Средства управления DFS.
Компонент Средства управления DFS устанавливает оснастку "Управление DFS", модули "Пространства имен DFS" и "Репликация DFS" для Windows PowerShell, а также средства командной строки, но не устанавливает на сервер никаких служб DFS.
Установка репликации DFS с помощью Windows PowerShell
Откройте сеанс Windows PowerShell с правами привилегированного пользователя, после чего введите указанную ниже команду, где <name> обозначает службу роли или компонент, которые требуется установить (см. следующую таблицу со списком соответствующих имен служб ролей или компонентов).
| Служба роли или компонент | Название |
|---|---|
| Репликация DFS | FS-DFS-Replication |
| Средства управления DFS | RSAT-DFS-Mgmt-Con |
Например, для установки средств распределенной файловой системы, включенных в компонент средств удаленного администрирования сервера, введите:
Для установки таких частей компонента средств удаленного администрирования сервера, как "Репликация DFS" и "Средства распределенной файловой системы", введите:



Распределенная файловая система DFS ( Distributed File System) – это технология, обеспечивающая возможности упрощения доступа к общим файловым ресурсам и глобальной репликации данных. Благодаря DFS распределённые по различным серверам общие ресурсы (каталоги и файлы) можно объединить в единую логическую UNC структуру, которая для пользователя выглядит, как единый сетевой ресурс. Даже при изменении физического местоположения целевой папки, это не влияет на доступ пользователя к ней.
Установка служб DFS в Windows Server 2012
Установить службы DFS можно с помощью консоли Server Manager или же при помощи Windows PowerShell.
Как мы уже говорили, службы DFS являются элементами роли Files and Storage Services:
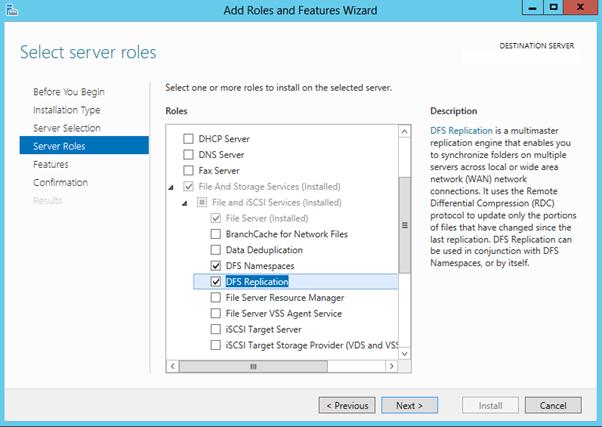
Но проще и быстрее установить все DFS службы и консоль управления DFS с помощью PowerShell:

, где FS-DFS-Namespace – служба DFS Namespaces
FS-DFS-Replication – служба репликации DFS Replication
Настройка пространства имен DFS в Windows Server 2012
Перейдем к описанию процедуры настройки пространство имен DFS, для чего необходимо открыть панель управления DFS Management tool.
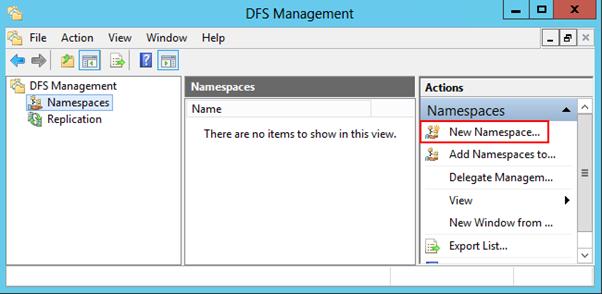
Создадим новое пространство имен (New Namespace).
Необходимо указать имя сервера, который будет содержать пространство имен (это может быть как контроллер домена, так и рядовой сервер).
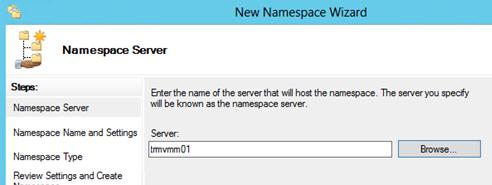
Затем следует указать имя создаваемого пространства имен DFS и перейти в расширенные настройки (Edit Settings).
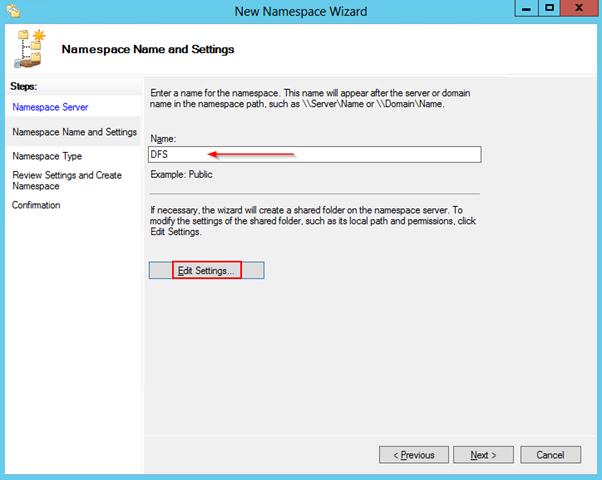
Здесь следует указать имя пространства имен DFS и права доступа к данному каталогу. Обычно рекомендуется указать, что доступ к сетевой папке разрешен Всем (Everyone), в этом случае права доступа проверяются на уровне файловой системы NTFS.
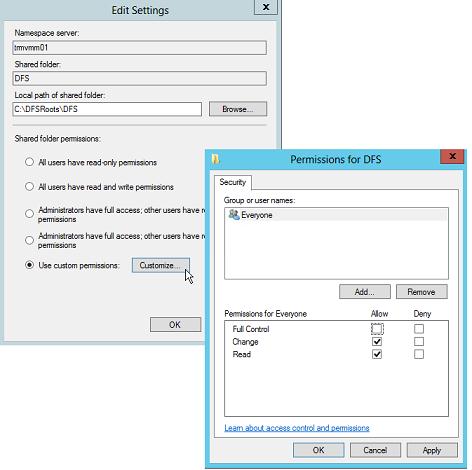
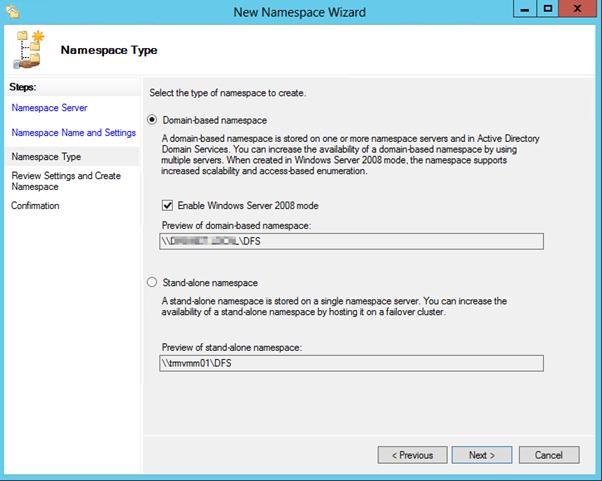
Далее мастер предложит указать тип создаваемого пространства имен. Это может быть Domain-based namespace (доменное пространство имен) или Stand-alone namespace (отдельное пространство имен). Domain-based namespace обладает ряд преимуществ, но для его работы нужен, собственно домен Active Directory и права администратора домена (либо наличие делегированных прав на создание доменных пространств имен DFS).
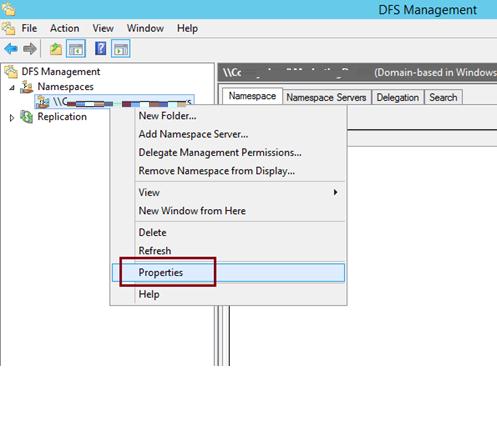
После окончания работы мастера в ветке Namespaces консоли управления DFS появится созданное нами новое пространство имен DFS. Чтобы пользователи при доступе к DFS каталогам видели только те каталоги, к которым у них имеется доступ, включим для данного пространства DFS Access-Based Enumeration (подробнее о данной технологии в статье Access-Based Enumeration в Windows). Для этого откройте окно свойств созданного пространства имен.
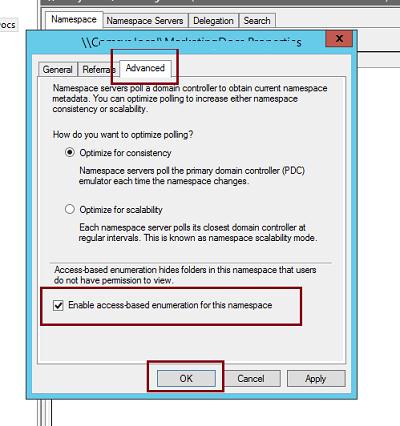
И на вкладке Advanced включите опцию Enable access-based enumeration for this namespace.
Чтобы посмотреть содержимое нового пространства DFS, просто наберите в окне проводника UNC путь: \\имя_домена_или_сервера\DFS
Добавление дополнительного DFS сервера
В доменное пространство имен DFS можно добавить дополнительный сервер (пункт меню Add Namespace Server), который его будет поддерживать. Делается это для увеличения доступности пространства имен DFS и позволяет разместить сервер пространства имен в том же сайте, в котором находится пользователи.
Примечание. Отдельно стоящие пространства имен DFS поддерживают только один сервер.Добавление нового каталога в существующее пространство имен DFS
Укажите наименование каталога в DFS пространстве и его реальное местоположение на существующем файловом сервере (Folder targets).
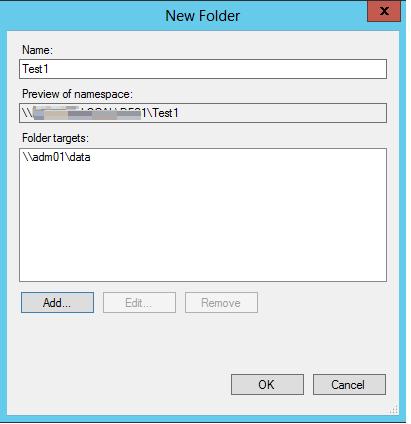
Настройка DFS-репликации на Windows Server 2012
Технология репликации DFS-R предназначена для организации отказоустойчивости пространства имен DFS и балансировки нагрузки между серверами. DFS-R автоматически балансирует трафик между репликами в зависимости от их загрузки и в случае недоступности одного из серверов перенаправляет клиентов на другой сервер-реплику. Но прежде, чем говорить о DFS репликации и ее настройке в Windows Server 2012перечислим основные системные требования и ограничения:
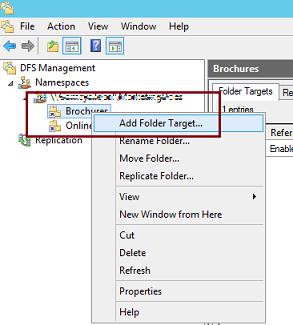
В консоли DFS Managment выберите нужный вам DFS Namespace и щелкните ПКМ по каталогу, для которого необходимо создать реплику и выберите пункт Add Folder Target.
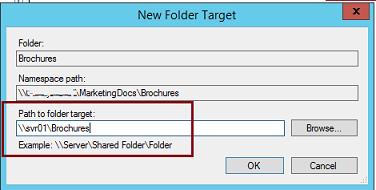
И укажите полный (UNC) путь к сетевому каталогу другого сервера, в котором и будет храниться реплика.
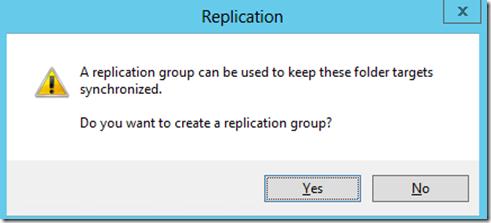
На вопрос хотите ли вы создать группу репликации отвечаем Yes.
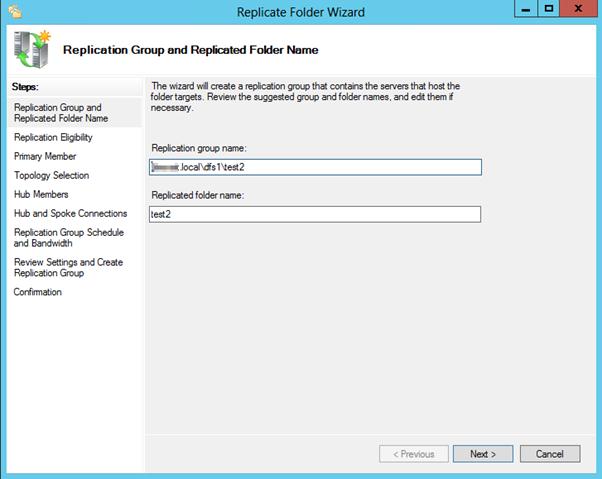
Запускается мастер настройки репликации. Проверяем имя группы репликации и каталог.
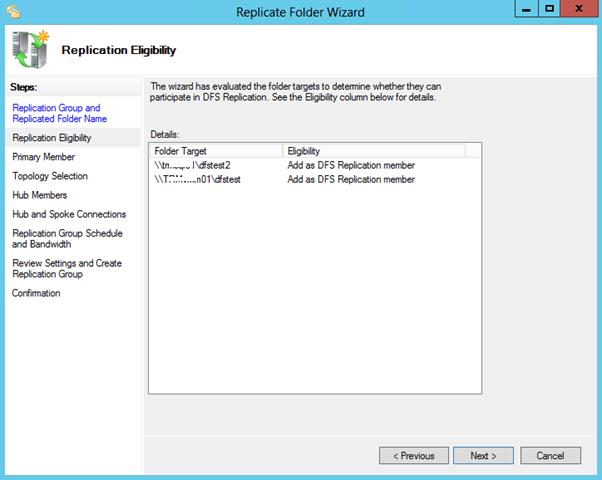
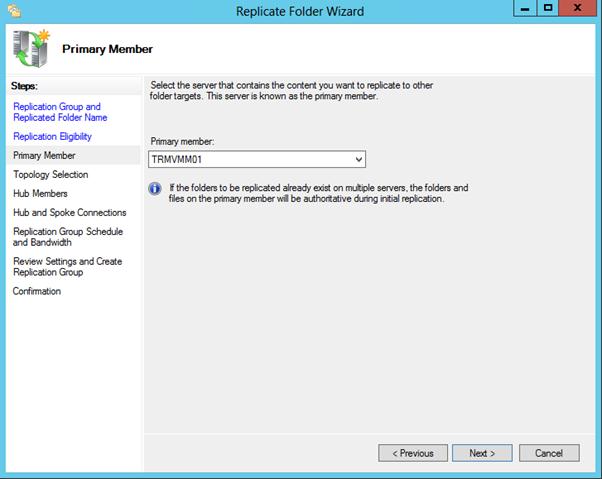
Указываем первичный (Primary) сервер. Именно этот сервер будет источником данных при инициальной (первичной) репликации.
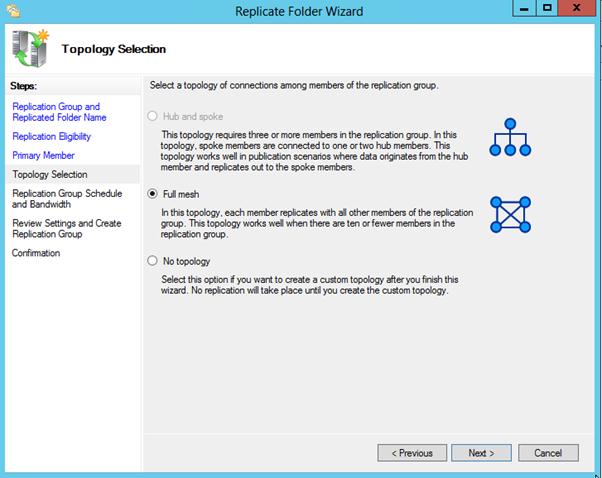
Затем выбираем тип топологии (соединения) между членами группы репликации. В нашем примере выбираем Full Mesh (все со всеми).
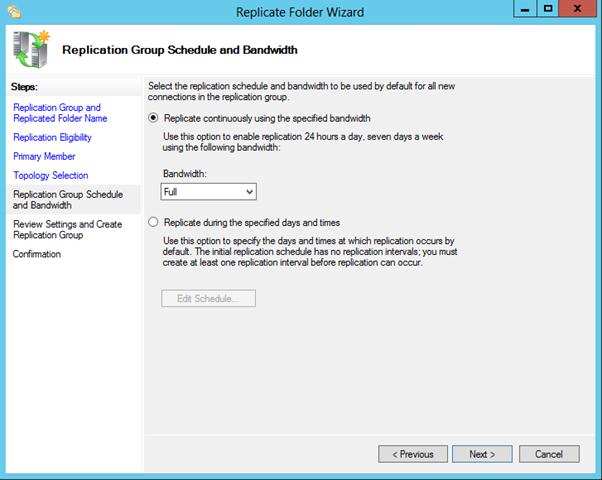
И, наконец, указываем расписание репликации и параметры bandwidth throttling – ограничение доступной для репликации полосы пропускания.
После окончания работы мастера, запуститься первоначальная синхронизация.
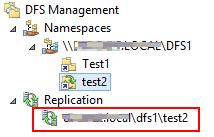
В случае необходимости, настройки расширенных параметры расписания репликации и максимальную полосу пропускания под данный трафик, можно задать в ветке Replication.
Еще материалы по теме

На заметку разработчику Spark-приложений: 3 ошибки PySpark и тонкости Outer…

Комбо Apache Airflow и NiFi для запланированного запуска ETL-конвейеров: практическая…

Графовая аналитика путешествий цифровых кочевников с Neo4j и Cypher

Новое на сайте
Отзывы на Google

Курсы от инженеров и для инженеров. Всё чётко, по делу. Тренеры глубоко знают продукты, о которых читают лекции. read more
Принимал участие в обучении по курсу "KAFKA: Администрирование кластера Kafka". В целом понравилось, но хотелось бы более качественной организации работы с лабгайдами. Когда лектор выполняет лабораторную работу, не совсем удобно выполнять её параллельно - где-то отстаешь, где-то убегаешь вперед. Может будет лучше разделить на более мелкие модули. read more
Прошел Курс Администрирование кластера Hadoop. Подача материала хорошая, размеренная. Преподаватель отвечает на все вопросы, и пытается как можно прозрачней приподнести материал. read more
Обучался на программе HADM. Подача материала доступная. Порадовало соотношение теории и практики 50/50. Отзывчивый преподаватель. Однозначно рекомендую. read more
Заканчиваю прохождения курса "ADH: Администрирование кластера Arenadata Hadoop". Хочу сказать, что выстроен грамотный план обучения, где отслеживается отличное соотношение практики и теории. Преподаватель, Комисаренко Николай, обладает отличным чувством юмора, что позволило не скучать на серьезных темах, и обладает отличным навыком объяснять сложные вещи простыми словами. На курс приходил с большим числом вопросов, на все из которых получил грамотные ответы, после чего все разложилось по полочкам. read more
В декабре 2020 прошел курс "Администрирование кластера Kafka". Курс проводился удаленно. В части организации обучения придраться не к чему. Необходимую информацию прислали заранее, лабораторный стенд и портал обучения работали стабильно. Немного разочаровали лабораторные работы. На месте BigDataSchool я бы их переделал. В документах с лабами нужно сделать нормальное форматирование и нумерацию пунктов. Все пункты, необходимые для выполнения, нужно сделать в виде текста. В лабах много работ по созданию «обвязки» kafka (создание самоподписных сертификатов, развертывание MIT и т.п), которые можно сделать заранее. Это позволит студентам уделять больше времени изучению самой kafka. BigDataSchool идет навстречу и позволяет пользоваться лабораторным стендом гораздо дольше установленных часов обучения. Это очень к стати, если в течении дня Вы вынуждены отвлекаться от обучения. В целом, курс дает хорошую базу по kafka. Преподаватель хорошо подает материал, делает акценты в нужных местах, подробно отвечает на вопросы. read more
С 30 ноября по 4 декабря прошел курс "Администрирование кластера Hadoop". Учитывая, что я обладал довольно поверхностной информацией в данной теме (я CIO) - ушел с курсов просветленным. Многое стало понятным, в процессе обучения наложил знания на существующую инфраструктуру компании, в которой работаю. Рекомендую коллегам руководителям в ИТ - прокачаться на данном курсе, вы поймете куда двигаться в ближайшие 2-3 года. Админам, работающим или стремящимся в BigData- обязательно! Рекомендация - настойчиво, для тех кто "думает, что знает": перед курсом уделите время работе с командной строкой Linux! Total recall - обязательное условие. Много практической работы, и если есть затык в Linux - будете безнадежно отставать при выполнении лабораторных работ. read more
В октябре прошел курс Анализ данных с Apache Spark, это был второй раз, когда я обучался в этом месте. В целом, все хорошо, думаю что не последний. Не могу не подчеркнуть профессионализм преподавателя Королева Михаила, отвечал на поставленные вопросы, делился своим опытом. В общем, рекомендую! read more
Прошел тут курс "NIFI: Кластер Apache NiFi", вёл Комисаренко Николай. Живое и понятное обучение. Преподаватель отвечал на все вопросы от самых глупых, до самых умных и это было приятно. Так же порадовало, что преподаватель не идёт по заранее проложенным рельсам, а проходит весь путь вместе с вами, стараясь привнести, что-то новое. read more
Спасибо за обучение!
Очень крутое место, много практики, понятное объяснение заданной темы. Еще вернусь :) read more
Обучался на курсе HADM администрирование кластера Arenadata Hadoop. Интересный курс, хорошая подача. read more
Обучался на курсе по администрированию Apache Kafka. Хорошая подача материала, интересные практические задачи. Возникающие вопросы доходчиво и ясно объясняют. Остался очень доволен. read more
Был на курсе "Администрирование кластера Hadoop". Отличная подача материала. Очень много практики и технических подробностей. Подробный обзор стека технологий, платформы и инструментов. Рекомендую! read more
Учился на курсе Администрирование Hadoop. Курс вёл Николай Комиссаренко. Отлично подготовленная, продуманная, системная программа курса. Практические занятия организованы так, что у студентов есть возможность познакомиться с реальными особенностями изучаемого продукта. Отключил голову и прощёлкал лабы по книжке - здесь не работает. Преподаватель легко и развёрнуто отвечает на возникающие вопросы не только по теме предмета, но и по смежным. read more
Прошёл курс по администрированию Apache Kafka. Очень понравилась как подача материала, так и структура курса. Только вот времени маловато оказалось. не всё успел доделать, но это уже не к курсу претензии :). Практики было довольно много, и это хорошо read more
Прошёл курс "Hadoop для инженеров данных" у Николая Комиссаренко. Информация очень актуальна и полезна, заставляет задуматься о текущих методах работы с большими данными в нашей компании и, возможно, что-то поменять. Занятия с большим количеством практики, поэтому материал хорошо усваивается. Отдельное спасибо Николаю за то, что некоторые вещи объяснял простым языком, понятным даже для "чайников" в области Hadoop. read more
I did not find any disadvantages in the course. Pluses: + A lot of practice (50% of the time). + The teacher can explain difficult topics easy way. + Announced topics were considered. Besides additional materials were studied. read more
Посетил курс администрирование Hadoop. На курсе устанавливали кластер с нуля на виртуалках в облаке Amazon. Настраивали Kerberos, тестировали выполнение задач на кластере, управление ресурсами кластера. Т.к. кластер развернут в облаке, после завершения занятий можно самостоятельно работать с кластером из дома. Лекции вел Николай Комиссаренко, после обучения предоставил все материалы. На занятиях отвечал на дополнительные вопросы, рассмотрели как решить пару живых задач от студентов. Хороший курс для начала изучения BigData. Update Дополнительно прошел обучения по Airflow и NiFi. Курсы двух дневные упор на занятиях делался на использовании продуктов, администрированию уделялось меньше времени. Т.к. курсы короткие, то перед занятиями желательно почитать обзорные статьи по продуктам, чтобы не терять время на базовое погружение и задавать более предметные вопросы. Перед началом занятий желательно связаться с школой и запросить что больше интересуется на обучении. Может быть предложить свои кейсы, чтобы на лабораторных отработать не только общий функционал. read more
Был на основах хадупа, все материалы описаны доступным языком. В частности хочу отметить преподавателя Николая Комисаренко, как очень квалифицированного преподавателя и специалиста. read more
Отличные курсы по "Администрированию Hadoop" и отличная организация проведения занятий, все по делу и понятно. Очень понравилось, знания получены основательные. Материал подаётся основательно. Постараюсь ещё попасть на другие курсы. read more
Курс по Isilon у Николая Комиссаренко мне тоже понравился. Грамотный и отзывчивый. Возникали вопросы по курсу он отвечал на все вопросы. Спасибо. Успехов ему read more
Посетил курс администрирование Hadoop. На курсе устанавливали кластер с нуля на виртуалках в облаке Amazon. Настраивали Kerberos, тестировали выполнение задач на кластере, управление ресурсами кластера. Т.к. кластер развернут в облаке, после завершения занятий можно самостоятельно работать с кластером из дома. Лекции вел Николай Комиссаренко, после обучения предоставил все материалы. На занятиях отвечал на дополнительные вопросы, рассмотрели как решить пару живых задач от студентов. Хороший курс для начала изучения BigData. read more
Эффективный практический курс. Прошел курс Администрирование Hadoop в октябре 2018. Хорошо наполненный материал, оптимальная длительность курса и все делалось своими руками. Местами было непросто, но преодолимо. Оправдал все ожидания, после курса появилось целостное понимание создания и работы кластера. Николай, большое спасибо read more
Прошёл курс по администрированию Hadoop Cloudera. Отличная "живая" подача материала на "простом" языке. Как плюс работа с кластером построена на платформе AWS. На курсах не скучно, рекомендую! read more
Я узнал много нового посетив курс уважаемого Николая Комиссаренко по айзелону. Очень грамотный специалист обучение было очень полезным и грамотным. Спасибо вам большое read more
Читайте также: