
Application vnd openxmlformats чем открыть
Internet Media Types [1] — типы данных, которые могут быть переданы посредством сети интернет с применением стандарта MIME. Ниже приведён список MIME-заголовков и расширений файлов.
Содержание
Согласно RFC 2045, RFC 2046, RFC 4288, RFC 4289 и RFC 4855 [2] выделяются следующие базовые типы передаваемых данных:
Внутренний формат прикладной программы
- application/atom+xml : Atom
- application/EDI-X12 : EDIX12 (RFC 1767)
- application/EDIFACT : EDIEDIFACT (RFC 1767)
- application/json : JavaScript Object Notation JSON (RFC 4627)
- application/javascript : JavaScript (RFC 4329)
- application/octet-stream : двоичный файл без указания формата (RFC 2046) [3]
- application/ogg : Ogg (RFC 5334)
- application/pdf : Portable Document Format, PDF (RFC 3778)
- application/postscript : PostScript (RFC 2046)
- application/soap+xml : SOAP (RFC 3902)
- application/font-woff : Web Open Font Format[4]
- application/xhtml+xml : XHTML (RFC 3236)
- application/xml-dtd : DTD (RFC 3023)
- application/xop+xml :XOP
- application/zip : ZIP[5]
- application/gzip : Gzip
- application/x-bittorrent : BitTorrent
- application/x-tex : TeX
- application/xml : XML
- application/msword : DOC
- model/example : (RFC 4735)
- model/iges : IGS файлы, IGES файлы (RFC 2077)
- model/mesh : MSH файлы, MESH файлы (RFC 2077), SILO файлы
- model/vrml : WRL файлы, VRML файлы (RFC 2077)
- model/x3d+binary : X3DISO стандарт для 3D компьютерной графики, X3DB файлы
- model/x3d+vrml : X3DISO стандарт для 3D компьютерной графики, X3DV VRML файлы
- model/x3d+xml : X3DISO стандарт для 3D компьютерной графики, X3D XML файлы
- multipart/mixed : MIMEE-mail (RFC 2045 и RFC 2046)
- multipart/alternative : MIMEE-mail (RFC 2045 и RFC 2046)
- multipart/related : MIMEE-mail (RFC 2387 и используемое MHTML (HTML mail))
- multipart/form-data : MIMEWebform (RFC 2388)
- multipart/signed : (RFC 1847)
- multipart/encrypted : (RFC 1847)
- text/cmd : команды
- text/css : Cascading Style Sheets (RFC 2318)
- text/csv : CSV (RFC 4180)
- text/html : HTML (RFC 2854)
- text/javascript (Obsolete): JavaScript (RFC 4329)
- text/plain : текстовые данные (RFC 2046 и RFC 3676)
- text/php : Скрипт языка PHP
- text/xml : Extensible Markup Language (RFC 3023)
- text/markdown : файл языка разметки Markdown (RFC 7763)
- text/cache-manifest : файл манифеста(RFC 2046)
- application/vnd.oasis.opendocument.text : OpenDocument[14]
- application/vnd.oasis.opendocument.spreadsheet : OpenDocument[15]
- application/vnd.oasis.opendocument.presentation : OpenDocument[16]
- application/vnd.oasis.opendocument.graphics : OpenDocument[17]
- application/vnd.ms-excel : Microsoft Excel файлы
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet : Microsoft Excel 2007 файлы
- application/vnd.ms-powerpoint : Microsoft Powerpoint файлы
- application/vnd.openxmlformats-officedocument.presentationml.presentation : Microsoft Powerpoint 2007 файлы
- application/msword : Microsoft Word файлы
- application/vnd.openxmlformats-officedocument.wordprocessingml.document : Microsoft Word 2007 файлы
- application/vnd.mozilla.xul+xml : MozillaXUL файлы
- application/vnd.google-earth.kml+xml : KML файлы (например, для Google Earth)
- application/x-pkcs12 : p12 файлы
- application/x-pkcs12 : pfx файлы
- application/x-pkcs7-certificates : p7b файлы
- application/x-pkcs7-certificates : spc файлы
- application/x-pkcs7-certreqresp : p7r файлы
- application/x-pkcs7-mime : p7c файлы
- application/x-pkcs7-mime : p7m файлы
- application/x-pkcs7-signature : p7s файлы
Структура документа SpreadsheetML включает элемент , содержащий элементы и , которые ссылаются на листы в книге. The document structure of a SpreadsheetML document consists of the element that contains and elements that reference the worksheets in the workbook. Для каждого листа создается отдельный XML-файл. A separate XML file is created for each worksheet. Эти элементы необходимы для создания действительной электронной таблицы. These elements are the minimum elements required for a valid spreadsheet document. Кроме того, электронная таблица может содержать элементы , , или другие элементы, относящиеся к электронным таблицам. In addition, a spreadsheet document might contain , , , or other spreadsheet related elements.
В этом разделе: In This Section
Важные части электронных таблиц Important Spreadsheet Parts
С помощью Пакет Open XML SDK 2.5 для Office можно создать структуру и содержимое документа, использующие строго типизированные классы, соответствующие элементам SpreadsheetML. Эти классы можно найти в пространстве имен DocumentFormat.OpenXML.Spreadsheet. В следующей таблице перечислены имена классов, соответствующие некоторым важным элементам электронной таблицы. Using the Open XML SDK 2.5 for Office, you can create document structure and content that uses strongly-typed classes that correspond to SpreadsheetML elements. You can find these classes in the DocumentFormat.OpenXML.Spreadsheet namespace. The following table lists the class names of the classes that correspond to some of the important spreadsheet elements.
| Часть пакета Package Part | Элемент SpreadsheetML верхнего уровня Top Level SpreadsheetML Element | Класс Пакет SDK 2.5 Open XML Open XML SDK 2.5 Class | Описание Description |
|---|---|---|---|
| Книга Workbook | книга workbook | Workbook Workbook | Корневой элемент основной части документа. The root element for the main document part. |
| Лист Worksheet | лист worksheet | Worksheet Worksheet | Тип листа, представляющий таблицу ячеек, которая содержит текст, числа, даты и формулы. Дополнительные сведения см. в статье Работа с листами (Open XML SDK). A type of sheet that represent a grid of cells that contains text, numbers, dates or formulas. For more information, see Working with sheets (Open XML SDK). |
| Лист диаграммы Chart Sheet | chartsheet chartsheet | Chartsheet Chartsheet | Лист, представляющий диаграмму, которая хранится в отдельном листе. Дополнительные сведения см. в разделе Работа с листами (Open XML SDK). A sheet that represents a chart that is stored as its own sheet. For more information, see Working with sheets (Open XML SDK). |
| Таблица Table | table table | Table Table | Логическая конструкция, которая определяет диапазон данных, принадлежащий одному набору данных. Дополнительные сведения см. в статье Работа с таблицами SpreadsheetML (Open XML SDK). A logical construct that specifies that a range of data belongs to a single dataset. For more information, see Working with SpreadsheetML tables (Open XML SDK). |
| Сводная таблица Pivot Table | pivotTableDefinition pivotTableDefinition | PivotTableDefinition PivotTableDefinition | Логическая конструкция, отображающая объединенное представление данных в понятном формате. Дополнительные сведения см. в статье Работа со сводными таблицами (Open XML SDK). A logical construct that displays aggregated view of data in an understandable layout. For more information, see Working with PivotTables (Open XML SDK). |
| Сводный кэш Pivot Cache | pivotCacheDefinition pivotCacheDefinition | PivotCacheDefinition PivotCacheDefinition | Конструкция, определяющая источник данных в сводной таблице. Дополнительные сведения см. в статье Работа со сводными таблицами (Open XML SDK). A construct that defines the source of the data in the PivotTable. For more information, see Working with PivotTables (Open XML SDK). |
| Записи сводного кэша Pivot Cache Records | pivotCacheRecords pivotCacheRecords | PivotCacheRecords PivotCacheRecords | Кэш исходных данных сводной таблицы. Дополнительные сведения см. в разделе Работа со сводными таблицами (Open XML SDK). A cache of the source data of the PivotTable. For more information, see Working with PivotTables (Open XML SDK). |
| Цепочка вычислений Calculation Chain | calcChain calcChain | CalculationChain CalculationChain | Конструкция, указывающая порядок вычислений ячеек в книге в последний раз. Дополнительные сведения см. в статье Работа с цепочкой вычислений (Open XML SDK). A construct that specifies the order in which cells in the workbook were last calculated. For more information, see Working with the calculation chain (Open XML SDK). |
| Общая строковая таблица Shared String Table | sst sst | SharedStringTable SharedStringTable | Конструкция, которая содержит один экземпляр каждой уникальной строки во всех листах книги. Дополнительные сведения см. в разделе Работа с таблицей общих строк (Open XML SDK). A construct that contains one occurrence of each unique string that occurs on all worksheets in a workbook. For more information, see Working with the shared string table (Open XML SDK). |
| Условное форматирование Conditional Formatting | conditionalFormatting conditionalFormatting | ConditionalFormatting ConditionalFormatting | Конструкция, определяющая формат, который применяется к ячейке или последовательности ячеек. Дополнительные сведения см. в разделе Работа с условным форматированием (Open XML SDK). A construct that defines a format applied to a cell or series of cells. For more information, see Working with conditional formatting (Open XML SDK). |
| Формулы Formulas | f f | CellFormula CellFormula | Конструкция, определяющая текст формулы для ячейки с формулой. Дополнительные сведения см. в разделе Работа с формулами (Open XML SDK). A construct that defines the formula text for a cell that contains a formula. For more information, see Working with formulas (Open XML SDK). |
Простейший случай книги Minimum Workbook Scenario
В приведенном ниже тексте из стандарта ECMA-376 представлен простейший случай книги. The following text from the Standard ECMA-376 introduces the minimum workbook scenario.
Самая маленькая (пустая) книга должна содержать следующие элементы: The smallest possible (blank) workbook must contain the following:
один лист; A single sheet
идентификатор листа; A sheet ID
идентификатор связи, указывающий на расположение определения листа. A relationship Id that points to the location of the sheet definition
© Ecma International: декабрь 2006 г. © Ecma International: December 2006.
Пример кода Open XML SDK Open XML SDK Code Example
В этом примере кода классы Пакет SDK 2.5 Open XML используются для создания минимальной пустой книги. This code example uses the classes in the Open XML SDK 2.5 to create a minimum, blank workbook.
Созданный документ SpreadsheetML Generated SpreadsheetML
После выполнения кода Пакет SDK 2.5 Open XML для создания книги с минимальной структурой можно изучить XML-код SpreadsheetML в ZIP-пакете. Для этого переименуйте расширение электронной таблицы минимальной структурой с .xlsx на .zip. ZIP-пакет содержит несколько частей, из которых состоит книга с минимальной структурой. After you run the Open XML SDK 2.5 code to generate a minimum workbook, you can explore the contents of the .zip package to view the SpreadsheetML XML code. To view the .zip package, rename the extension on the minimum spreadsheet from .xlsx to .zip. Inside the .zip package, there are several parts that make up the minimum workbook.
На приведенном ниже рисунке показана структура папки xl из ZIP-пакета простейшей книги. The following figure shows the structure under the xl folder of the .zip package for a minimum workbook.
Рис. 1. Структура папок в ZIP-файле Figure 1. .zip folder structure
Файл workbook.xml содержит элементы , ссылающиеся на листы книги. The workbook.xml file contains elements that reference the worksheets in the workbook. Каждый лист связан с книгой по идентификаторам листа и отношения. Each worksheet is associated to the workbook via a Sheet ID and a relationship ID. sheetID — это ИД, используемый в пакете для идентификации листа. Он должен быть уникальным в рамках книги. The sheetID is the ID used within the package to identify a sheet and must be unique within the workbook. id — это ИД отношения, который указывает определение части листа, связанное с листом. The id is the relationship ID that identifies the sheet part definition associated with a sheet.
Следующий XML-код код документа SpreadsheetML, представляющий часть книги в электронной таблице. Этот код формируется при выполнении кода Пакет SDK 2.5 Open XML для создания книги с самой простой структурой. The following XML code is the spreadsheetML that represents the workbook part of the spreadsheet document. This code is generated when you run the Open XML SDK 2.5 code to create a minimum workbook.
Файл workbook.xml.rels содержит элементы , определяющие отношения между книгой и листами в ней. The workbook.xml.rels file contains the elements that define the relationships between the workbook and the worksheets it contains.
Следующий XML-код код документа SpreadsheetML, представляющий часть связей в электронной таблице. Этот код формируется при выполнении кода Пакет SDK 2.5 Open XML для создания книги с минимальной структурой. The following XML code is the spreadsheetML that represents the relationship part of the spreadsheet document. This code is generated when you run the Open XML SDK 2.5 to create a minimum workbook.
Файл sheet.xml содержит элемент , представляющий таблицу ячеек. The sheet.xml file contains the element that represents the cell table. В этом примере книга пуста, поэтому элемент тоже пуст. In this example, the workbook is blank, so the element is empty. Дополнительные сведения о листах см. в статье Работа с листами (Open XML SDK)**. For more information about sheets, see Working with sheets (Open XML SDK)**.
Следующий XML-код код документа SpreadsheetML, представляющий часть книги в электронной таблице. Этот код формируется при выполнении кода Пакет SDK 2.5 Open XML для создания книги с самой простой структурой. The following XML code is the spreadsheetML that represents the worksheet part of the spreadsheet document. This code is generated when you run the Open XML SDK 2.5 to create a minimum workbook.
Типичный случай книги Typical Workbook Scenario
Типичная книга отличается от пустой книги с минимальной структурой. Она может содержать числа, текст, диаграммы, таблицы и сводные таблицы. Каждая из дополнительных частей размещена в ZIP-пакете электронной таблицы. A typical workbook will not be a blank, minimum workbook. A typical workbook might contain numbers, text, charts, tables, and pivot tables. Each of these additional parts is contained within the .zip package of the spreadsheet document.
На следующем рисунке показаны основные элементы типичной электронной таблицы. The following figure shows most of the elements that you would find in a typical spreadsheet.
Рис. 2. Элементы типичной электронной таблицы Figure 2. Typical spreadsheet elements
Сегодняшним постом я хочу начать серию материалов. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …

Сегодняшним постом я хочу начать еще одну серию. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
Прежде чем перейти к содержательной части некоторый предваряющий disclaimer (традиционно ):
● Я в основном буду касаться современных офисных форматов, тех что появились в редакции Office 2007. Их еще называют XML-based форматами, в противовес старым бинарным (и это закрепилось в расширении файлов: docx, pptx, xlsx, … – в противовес doc, ppt, xls, …), ну или просто Open XML
● Некоторая часть статей (по крайней мере в самом начале) будет основана на материалах Open XML Developer Workshop (контент и видео), который вел Doug Mahugh. Если вам не хочется ждать моих статей рекомендую обратиться к этим материалам
● Еще одним хорошим подспорьем для изучающих Open XML будет книга Воутер Ван Вугт. OpenXML. Кратко и доступно. Ранее она в электронном виде была доступна в блоге евангелиста Microsoft Владимира Габриеля, но теперь – увы. Так что, если вам интересно и не хочется тратить время на поиск, можете взять здесь.
Вроде бы все. Можно приступать.
Что такое Open Packaging Conventions?
В двух словах, это формат контейнеров, поддерживающих хранение как структурированных (XML), так и неструктурированных компонентов (картинки, видео, бинарные компоненты, …) в одном файле.
Краткая но довольно информативная статья об OPC есть на wikipedia.
Что можно сказать в общем об этом стандарте/формате? Я бы выделил такие моменты:
● Формальное описание является частью ECMA-376. Office Open XML File Formats, более конкретно – второй частью Part 2 — Open Packaging Conventions.
● Сам стандарт описывает только структуру хранения и самые общие метаданные (типа автора, даты,…) поэтому потенциально в таком контейнере можно хранить практически что угодно.
Например, вот несколько форматов, основанных на OPC от самого Microsoft:
o .docx, pptx, xlsx, .vsdx – форматы Word, Power Point, Excel и Visio
o .xps (.oxps) – формат “электронной бумаги” или формат c фиксированной разметкой, предназначенный для передачи документов без искажения форматирования (в чем-то аналог PDF).
o .vsix – формат расширений Visual Studio, начиная с версии 2010
o .cspkg – формат пакетов для Windows Azure Cloud Services
o .appx – формат пакетов приложений Windows Store (для Windows 8)
Что представляют собой контейнеры в OPC?
Тут нужно сделать одну существенную оговорку: сам стандарт разбивает описание контейнеров на 2 части: абстрактную модель (которая описывает из каких элементов состоят контейнеры, но ни слова не говорит о том как это должно храниться физически) и физический формат пакета, т.е. конкретную реализацию.
Т.е. в чистой теории, контейнер в OPC может храниться единый файл, а может, например, как набор отдельных ресурсов на Web-сервере. Но (!) на текущий момент определена только 1 реализация – в виде единого файла ZIP-архива.
Структура контейнеров в OPC
Вообще говоря, концептуальная схема пакетов в Open Packaging Conventions очень проста, она включает в себя всего два элемента:
● компоненты (parts), которые собственно и содержат хранящийся контент (любой: xml, image, video, …)
● отношения (relationships), которые определяют
o предназначение (смысл/семантику) каждой части
o отношения между частями, а также между частями и пакетом целиком
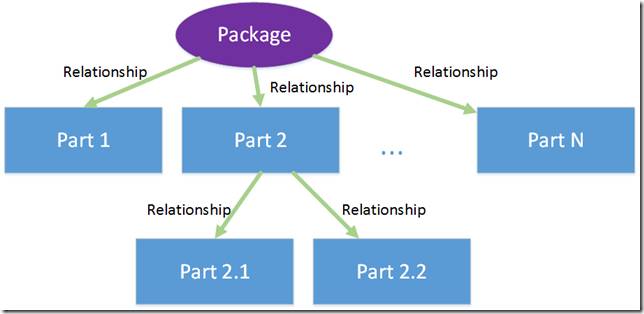
Как уже было сказано выше компонент в OPC это и есть основная единица хранения контента. Каждый компонент характеризуется 2-я составляющими: именем и типом содержимого.
Имя компонента состоит из набора сегментов, начинающихся с прямого слэша (“/”), вот несколько примеров:
В спецификации приведены более формальные правила построения имен, из которых я укажу только основные (на мой взгляд):
● все имена должны начинаться с прямого слэша (“/”) и не должны им заканчиваться
● имя недолжно содержать пустых сегментов (т.е. /images//image1.jpg – неправильное имя)
● сегменты могут состоять из букв, цифр и знаков «!«, «$«, «&«, «‘«, «(«, «)«, «*«, «+«, «,«, «;«, «=«, «-«, «.«, «_«, «
● ни одно имя компонента не должно строиться как имя уже существующего компонента + новый сегмент. Т.е. если есть компонент с именем /abc/abc, то компонент с именем /abc/abc/a существовать не может, зато вполне может существовать компонент с именем /abc/abcde
● имена могут записываться Unicode-символами или использовать кодирование в виде /a/%D1%86.xml
Тип содержимого компонента задается в соответствии с RFC 2616 (раздел Media Types) т.е. в виде <type>/<subtype>:
Связи
Любой компонент в пакете (а также сам пакет) может ссылаться на другие компоненты или некоторые ресурсы за пределами пакета. Для представления этих ссылок введен специальный механизм связей. По большому счету, связи позволяют решить 2 задачи:
● получить список связанных с компонентом ресурсов, без необходимости анализировать его содержимое (которое может быть очень большим, иметь разную структуру, быть зашифрованным или вообще не поддерживать хранение ссылок)
● поменять набор связей компонента, не меняя его содержимого (которое может быть, например, зашифровано или защищено цифровой подписью)
Создавая свой пакет вы, конечно же, можете не использовать связи. Вместо этого везде в коде использовать фиксированные имена компонент, а где нужны списки связанных ресурсов, ссылаться на них прямо из самих компонент. Однако, рекомендации “лучших собаководов” все же советуют использовать связи везде, где это возможно.
Информация о связях для каждого компонента (а также самого пакета), хранится в специальных компонентах связей (relationships parts) тип содержимого которых application/vnd.openxmlformats-package.relationships+xml
Имена компонентов связи строятся из имени исходных компонент, к которым:
● добавляется предпоследний сегмент с именем _rels
● дописывается “расширение” .rels
Связи самого пакета хранятся в специальном компоненте с именем /_rels/.rels
Например, если в пакете у нас есть компонент с именем /document/mainPart.xml и два связанных компонента с картинками (пусть их мена будут /images/image1.jpg и /images/image2.jpg), то пакет для них будет иметь следующую структуру:
Содержимое компонента связи представляет собой XML следующего формата:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles"
Target="styles.xml" />
<Relationship
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme"
Target="theme/theme1.xml" />
<Relationship
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable"
Target="fontTable.xml" />
<Relationship
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="file:///C:\Users\Public\Pictures\Sample%20Pictures\Desert.jpg"
TargetMode="External" />
</Relationships>
Как уже наверняка понятно из приведенного фрагмента, каждый тэг <Relationship> определяет одну связь. Его атрибуты:
Идентификатор связи. На него ссылаются из содержимого компонент, когда необходимо использовать конкретную связь.
Тип связи. По сути дела тип указывает семантику связи. Например, две разных связи могут указывать на 2 компонента типа image/jpeg, но одно изображение будет картинкой в тексте документа, а второе – миниатюрой (thumbnail) всей страницы целиком.
В качестве типа может использоваться любой валидный URI
(Необязательный) Принимает одно из возможных значений:
· Internal (значение по умолчанию) – указывает, что связь ссылается на компонент пакета
· External – связь указывает на ресурс за пределами пакета
Адрес ресурса или компонента на который ссылается связь
Важный момент: для обращения к компонентам и внешним ресурсам можно использовать как абсолютные адреса (для компонент это будет их полное имя), так и относительные. В последнем случае полное имя компоненты рассматривается как путь в файловой системе, каждый сегмент, кроме последнего – имя “папки”, а последний – имя “файла”. Вот несколько примеров такой адресации:
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Loading
Copy raw contents
Copy raw contents
Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
docx - самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы - использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически - 3 вида элементов:
- Типы (Content Types) - список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) - отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого - PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Простейший docx после распаковки выглядит следующим образом
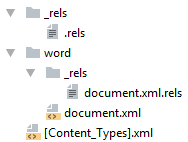
Давайте посмотрим из чего он состоит.
Находится в корне документа и перечисляет MIME типы содержимого документа:
Главный список связей документа. В данном случае определена всего одна связь - сопоставление с идентификатором rId1 и файлом word/document.xml - основным телом документа.
- <w:document> - сам документ
- <w:body> - тело документа
- <w:p> - параграф
- <w:r> - run (фрагмент) текста
- <w:t> - сам текст
- <w:sectPr> - описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
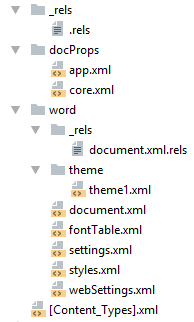
Вот что в них содержится:
- docProps/core.xml - основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml - общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml - настройки относящиеся к текущему документу.
- word/styles.xml - стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml - настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml - список шрифтов используемых в документе.
- word/theme1.xml - тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Итак, первоначальная задача - узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML. Использование под Windows:
- unpack file dir - распаковывает документ file в папку dir и форматирует xml
- pack dir file - запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack .
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
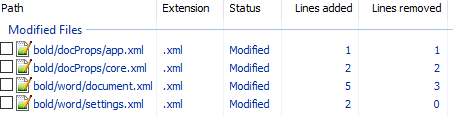
Рассмотрим его подробно:
Изменение времени нам не нужно.
Изменение версии документа и даты модификации нас также не интересует.
Изменения в w:rsidR не интересны - это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/> ) и проверяем что документ открывается и показывает то, что ожидалось. 8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее - добавление нижнего колонтитула. Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
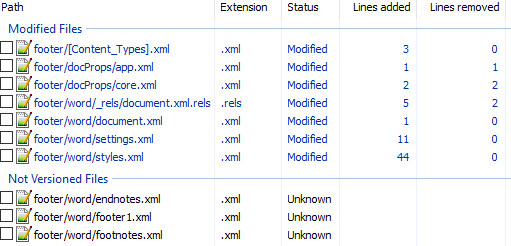
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml - там тоже самое, что и в первом примере.
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
Изначально diff выглядит вот так:
```diff @@ -1,8 +1,11 @@ + + - - + + + ``` Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их: ```diff @@ -3,6 +3,9 @@ + + + ``` Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ. ```diff @@ -480,6 +480,50 @@ + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + ``` Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег <w:sectPr> надо добавить <w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его. Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование - замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы не знаете - не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм выглядит следующим образом:
- Распаковываем документ
- Добавляем наш нижний колонтитул
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels
- В word/document.xml в тег <w:sectPr> добавляем тег <w:footerReference> или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл - footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует. Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
- in.docx - исходный документ
- out.docx - выходящий документ
- TEST - текст, который добавляется в нижний колонтитул
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Одной из новинок Microsoft Office 2007 станет поддержка нового формата хранения документов на базе языка XML. Этот формат будет поддерживаться в программных продуктах Microsoft Word 2007, Microsoft Excel 2007 и Microsoft PowerPoint 2007. В данном обзоре мы рассмотрим основные характеристики Office 2007 Open XML Format, обсудим формат файлов, а также программные интерфейсы для работы с офисными файлами в новом формате.
Поддержка языка XML не является эксклюзивом пакета Microsoft Office — первые варианты такой поддержки появились в 1999 году в Office 2000, когда были представлены XML-форматы для Word (WordprocessingML) и Excel (SpreadSheetML). В версии Office 2007 появился формат PresentationML для PowerPoint, а форматом сохранения документов по умолчанию стал ZIP-контейнер, соответствующий спецификации Open Packaging Conventions (подмножество Office 2007 Open XML Format) и пришедшей на смену бинарным форматам хранения документов, электронных таблиц и презентаций, использовавшихся в предыдущих версиях Office.
В таблице приведен список используемых в Microsoft Office 2007 расширений файлов, в которых хранятся документы в формате Office 2007 Open XML Format.
Microsoft планирует выпуск соответствующих обновлений для предыдущих версий Office, начиная с Office 2000 — для того, чтобы эти продукты могли полноценно работать с новым форматом хранения документов, создаваемых в Word, Excel и PowerPoint.
Общий обзор формата Office 2007 Open XML Format
Начнем обсуждение Office 2007 Open XML Format с рассмотрения общих характеристик этого формата. Затем в следующем разделе мы обратимся к более подробному рассмотрению деталей сохранения документов, создаваемых такими приложениями Microsoft Office 2007, как Word 2007, Excel 2007 и PowerPoint 2007.
Контейнер
XML-формат, используемый в Microsoft Office 2007, представляет собой ZIP-архив — контейнер, который называется package и в котором помещаются различные компоненты документа, называемые частями (part) и элементами (item). Части являются фрагментами документа и отвечают за его содержимое, элементы представляют собой метаданные, описывающие то, каким образом части должны быть собраны вместе и отображены. Элементы можно разделить на два типа: реляционные (relationship items), описывающие взаимоотношения между частями и типизованные (content-type items), задача которых — дать описание содержимого каждой части документа. Реляционные элементы, в свою очередь, подразделяются на элементы, описывающие взаимоотношения контейнеров, и элементы, задающие взаимоотношения между частями документа.
Части документа
Каждый документ содержит так называемую главную часть — все остальные элементы либо располагаются внутри этой главной части, либо так или иначе привязаны к ней. В зависимости от типа файла (текстовый документ, электронная таблица, презентация) главная часть может называться по-разному. Например:
Не все части документа сохраняются в XML-формате. Например, графические изображения (*.jpg, *.jpg, *.tiff) хранятся в оригинальном формате, что делает более удобным доступ к ним и выполнение соответствующих манипуляций. Помимо этого в бинарном виде хранятся VBA-проекты и внедренные в документы OLE-объекты. Части документа, сохраняемые в XML-формате, соответствуют схемам, определенным для того или иного фрагмента документа.
Реляционные элементы
<Relationship Type=”relationshipType”, Target = “target Part” />
- Id — строковый идентификатор взаимоотношения, который должен иметь уникальное в рамках файла имя;
- Type — описывает тип взаимоотношения, указывает на схему, которая определяет тип для данного формата. Существует ряд предопределенных типов, часть из которых показана ниже:
- Target — указывает на папку и файл, в которых располагается описываемый фрагмент документа.
Папка _rels имеет ключевое значение для всего процесса сохранения офисных документов в формате XML. Взаимоотношения между частями документа всегда задаются именно в этой папке. Упомянутое выше взаимоотношение officeDocument является взаимоотношением на уровне контейнера — другими словами, оно описывает весь контейнер и потому хранится в папке _rels в корне контейнера. Если же требуется найти описание взаимоотношений между частями документа, то в случае Microsoft Word 2007 его следует искать в файле document.xml — он будет находиться в подкаталоге word каталога _rels. Итеративный просмотр содержимого этого файла позволит вам обнаружить все части документа и взаимоотношения между ними.
Типизованные элементы
Как мы уже отмечали, типизованные элементы содержат метаданные, описывающие файловый тип каждой части документа. К частям документа могут относиться простой текст (text/plain), графическое изображение (image/jpeg) или более абстрактные понятия, например XML-документ (application/xml). Реляционные элементы также имеют соответствующие типизованные элементы, служащие для описания взаимоотношений. Множество типизованных элементов позволяет потребителям XML-файлов получить представление не только о его содержимом, но и о том, как интерпретировать и отрисовывать отдельные части документа.
Типизованные элементы хранятся вместе, в одном элементе с именем [Content_Types].xml в корневой папке контейнера. Типизованный элемент по умолчанию обычно ассоциируется с расширением имени файла, например *.xml или *.jpg. Типизованный элемент override может указывать на то, что данный фрагмент имеет указанный тип независимо от расширения имени файла.
Встроенные объекты
Формат Office Open XML может включать любое число встроенных объектов, которые могут принадлежать к любому типу. Эта возможность, пришедшая на смену неэффективному кодированию Base64, которое использовалось в предыдущих версиях продукта, сделала файлы более гибкими и удобными для обработки.
Например, вставка графического изображения в документ Word 2007 приведет к появлению в контейнере следующих элементов:
- в файл [Content_Types).xml будет добавлено описание типа, связывающего расширение файла *.jpg с to image/jpeg;
- папка media, созданная в папке word, будет содержать копию вставленного в документ графического изображения;
- в файле document.xml, который находится в папке word, будет вставлена ссылка на новое взаимоотношение;
- в файле document.xml.rels (находящийся в папке word) будет добавлено новое взаимоотношение, которое будет ссылаться на соответствующий элемент в файле document.xml.
После рассмотрения основных характеристик контейнеров и входящих в них элементов хотелось бы более подробно обсудить, как выглядит содержимое файлов, создаваемых в Word 2007, Excel 2007 и PowerPoint 2007.
Детали реализации
В данном разделе мы рассмотрим, как описанный выше XML-формат используется при сохранении документов, создаваемых такими приложениями Microsoft Office 2007, как Word 2007, Excel 2007 и PowerPoint 2007.
Начнем с простого текстового документа, созданного с помощью Word 2007. На рис. 1 показано, как этот документ выглядит в редакторе.
Рис. 1. Документ, созданный средствами Word 2007
Сохраненный документ имеет расширение *.docx и представляет собой ZIP-контейнер, который мы можем исследовать с помощью любой программы, позволяющей работать с ZIP-архивами. В качестве примера будем использовать программу WinZip. Ниже показана структура docx-файла, открытого в WinZip (рис. 2).
Рис. 2. Структура docx-файла
В файле [Content_Types).xml описаны все типизованные элементы, связанные с данным документом. Все типизованные элементы, уникальные для Word 2007, имеют префикс application/vnd.ms-word. Если типизованный элемент соответствует XML-файлу, то в конец URI добавляется «+xml». Типичными для Word 2007 типизованными элементами являются:
Поскольку имеется возможность изменения имени любого фрагмента документа, в файле [Content_Types).xml описаны и ссылки на такие фрагменты. Например, вот как указывается местоположение таблицы шрифтов:
<Override PartName=”/word/fontTable.xml”
<ContentType=”application/vnd.openxmlformats-officedocument.wordprocessingml.fontTable+xml” />
Здесь задается связь между схемой, описывающей нижний колонтитул документа, и файлом footer1.xml, в котором содержится сам колонтитул.
Более подробно прочитать о структуре XML-файла Word 2007 можно в документе «Walkthrough: Office 12 Word Open XML File Format», доступном на сайте MSDN.
Теперь создадим простую электронную таблицу — для этого воспользуемся Excel 2007. На рис. 3 показано, как эта таблица выглядит в Excel 2007.
Рис. 3. Таблица, созданная средствами Excel 2007
Откроем файл sample.xlsx в WinZip и посмотрим на его структуру.
Как видно на рис. 4, структура xlsx-файла напоминает структуру docx-файла, но части документа имеют другие имена, отражающие назначение частей электронной таблицы, а не текстового документа. Типичными типизованными элементами для Excel 2007 будут:
Рис. 4. Структура xlsx-файла
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet.main+xml;
- application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml.
В папке xl располагаются основные части электронной таблицы — workbook.xml, styles.xml, папка worksheets, папка drawings, папка charts и т.п. Взаимоотношения между частями документа описаны в файле workbook.xml.rels.
Более подробно прочитать о структуре XML-файла Excel 2007 можно в документе «Walkthrough: Office 12 Excel Open XML File Format», доступном на сайте MSDN.
Завершить рассмотрение примеров использования Office 2007 Open XML Format мы хотим простой презентацией, созданной в PowerPoint 2007. Ниже показано, как эта презентация выглядит в PowerPoint 2007 (рис. 5).
Рис. 5. Презентация, созданная средствами PowerPoint 2007
Откроем файл sample.pptx в программе WinZip и посмотрим на его структуру (рис. 6).
Рис. 6. Структура pptx-файла
Несмотря на то что в pptx-файле содержится значительно больше (по сравнению с docx- и xlsx-файлами) фрагментов, его структура легко узнаваема. Файл presentation.xml описывает всю презентацию, файл presentation.xml.rels — взаимоотношения между частями презентации. Типичными типизованными элементами для PowerPoint 2007 будут:
- application/vnd.openxmlformats-officedocument.presentationml.slideLayout+xml;
- application/vnd.openxmlformats-officedocument.presentationml.slideMaster+ xml;
- application/vnd.openxmlformats-officedocument.presentationml.slide+xml;
- application/vnd.openxmlformats-officedocument.presentationml.presentation. main+xml;
- application/vnd.openxmlformats-officedocument.presentationml.tableStyles+xml.
Каждый слайд описан документом slide.xml, расположенным в каталоге slides. В каталогах theme и slideLayouts находятся xml-документы, описывающие различные шаблоны, применимые к слайдам.
Программные интерфейсы
После того как мы научились извлекать главную часть документа, давайте выясним, каким образом можно найти любую часть документа — для этого необходимо выполнить итерацию по описанию взаимоотношений частей. Ниже показано, как это сделать, на примере поиска комментариев в документе Word.
В приведенном примере мы использовали URI для нахождения адреса определенного фрагмента документа — это необходимо для того, чтобы не зависеть от имени фрагмента, которое может меняться по мере работы с документом. Последний пример, который мы рассмотрим, относится к удалению определенного фрагмента документа. Предположим, что мы хотим удалить из файла VBA-проект.
Сценарии использования документов в XML-формате
Возможность манипуляции частями офисных документов либо посредством редакторов XML-файлов, либо через вышеупомянутые программные интерфейсы открывает перед разработчиками ряд новых сценариев, которые мы хотим кратко описать. К новым сценариям можно отнести следующие:
Читайте также: