
Ai control что это
- 1. Устройство для управления системой или ее элементом в нормальных условиях эксплуатации (ручное или автоматическое). В автоматических системах имеет место высокая чувствительность к изменению давления, температуры и других параметров, которые необходимо регулировать. 2. В промышленности: (в широком смысле) методы и средства управления функционированием аппарата, механизма, системы. Управление осуществляется стартом, остановкой, изменением направления движения, ускорением скорости, замедлением движения тех или иных элементов. Методы управления определяются в процессе конструирования, т.е. выбираются либо ручные, либо автоматические средства, либо совместное их использование. Часто при этом один или более компонентов механизма сознательно переводятся с целью повышения надежности на ручное управление. 3. Выполнение функций регулирования по схеме, описанной выше. 4. В цифровом компьютере: те части, которые в соответствии с инструкцией активизируются и тем самым передают сигналы на арифметическое устройство и другие элементы в соответствии с заданными условиями - см. также thermostat. Сравните с controller.
AI для людей: простыми словами о технологиях
Представляем исчерпывающую шпаргалку, где мы простыми словами рассказываем, из чего «делают» искусственный интеллект и как это все работает.
В чем разница между Artificial Intelligence, Machine Learning и Data Science?

Разграничение понятий в области искусственного интеллекта и анализа данных.
Artificial Intelligence — AI (Искусственный Интеллект)
В глобальном общечеловеческом смысле ИИ — термин максимально широкий. Он включает в себя как научные теории, так и конкретные технологические практики по созданию программ, приближенных к интеллекту человека.
Machine Learning — ML (Машинное обучение)
Раздел AI, активно применяющийся на практике. Сегодня, когда речь заходит об использовании AI в бизнесе или на производстве, чаще всего имеется в виду именно Machine Learning.
ML-алгоритмы, как правило, работают по принципу обучающейся математической модели, которая производит анализ на основе большого объема данных, при этом выводы делаются без следования жестко заданным правилам.
Наиболее частый тип задач в машинном обучении — это обучение с учителем. Для решения такого рода задач используется обучение на массиве данных, по которым ответ заранее известен (см.ниже).
Data Science — DS (Наука о данных)
Наука и практика анализа больших объемов данных с помощью всевозможных математических методов, в том числе машинного обучения, а также решение смежных задач, связанных со сбором, хранением и обработкой массивов данных.
Data Scientists — специалисты по работе с данными, в частности, проводящие анализ при помощи machine learning.

Как работает Machine Learning?
Рассмотрим работу ML на примере задачи банковского скоринга. Банк располагает данными о существующих клиентах. Ему известно, есть ли у кого-то просроченные платежи по кредитам. Задача — определить, будет ли новый потенциальный клиент вовремя вносить платежи. По каждому клиенту банк обладает совокупностью определенных черт/признаков: пол, возраст, ежемесячный доход, профессия, место проживания, образование и пр. В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
Машина видит любого клиента как совокупность признаков: . Где, например, — возраст, — доход, а — количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная — с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).
Совокупность всех данных и — есть Data Set. Используя эти данные, Data Scientist создает модель , подбирая и дорабатывая алгоритм машинного обучения.
В этом случае модель анализа выглядит так:

На практике чаще всего машина обучается лишь на части массива (80 %), применяя остаток (20 %) для проверки правильности выбранного алгоритма. Например, система может обучаться на массиве, из которого исключены данные пары регионов, на которых сверяется точность модели после.
Теперь, когда в банк приходит новый клиент, по которому еще не известен банку, система подскажет надежность плательщика, основываясь на известных о нем данных .
Однако, обучение с учителем — не единственный класс задач, которые способна решать ML.
Другой спектр задач — кластеризация, способная разделять объекты по признакам, например, выявлять разные категории клиентов для составления им индивидуальных предложений.
Также с помощью ML-алгоритмов решаются такие задачи, как моделирование общения специалиста поддержки или создание художественных произведений, неотличимых от сотворенных человеком (например, нейросети рисуют картины).
Новый и популярный класс задач — обучение с подкреплением, которое проходит в ограниченной среде, оценивающей действия агентов (например, с помощью такого алгоритма удалось создать AlphaGo, победившую человека в Го).

Нейронная сеть
Один из методов Machine Learning. Алгоритм, вдохновленный структурой человеческого мозга, в основе которой лежат нейроны и связи между ними. В процессе обучения происходит подстройка связей между нейронами таким образом, чтобы минимизировать ошибки всей сети.
Особенностью нейронных сетей является наличие архитектур, подходящих практически под любой формат данных: сверточные нейросети для анализа картинок, рекуррентные нейросети для анализа текстов и последовательностей, автоэнкодеры для сжатия данных, генеративные нейросети для создания новых объектов и т. д.
В то же время практически все нейросети обладают существенным ограничением — для их обучения нужно большое количество данных (на порядки большее, чем число связей между нейронами в этой сети). Благодаря тому, что в последнее время объемы готовых для анализа данных значительно выросли, растет и сфера применения. С помощью нейросетей сегодня, например, решаются задачи распознавания изображений, такие как определение по видео возраста и пола человека, или наличие каски на рабочем.
Интерпретация результата
Раздел Data Science, позволяющий понять причины выбора ML-моделью того или иного решения.
Существует два основных направления исследований:
- Изучение модели как «черного ящика». Анализируя загруженные в него примеры, алгоритм сравнивает признаки этих примеров и выводы алгоритма, делая выводы о приоритете каких-либо из них. В случае с нейросетями обычно применяют именно черный ящик.
- Изучение свойств самой модели. Изучение признаков, которые использует модель, для определения степени их важности. Чаще всего применяется к алгоритмам, основанным на методе решающих деревьев.
Естественно, производство интересует не только прогноз самого брака, но и интерпретация результата, т. е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
Потому в рамках проекта прогноза брака на производстве должна быть не просто создана ML-модель, но и проделана работа по её интерпретации, т. е. по выявлению факторов, влияющих на брак.

Когда эффективно применение машинного обучения?
Когда есть большой набор статистических данных, но найти в них зависимости экспертными или классическими математическими методами невозможно или очень трудоемко. Так, если на входе есть более тысячи параметров (среди которых как числовые, так и текстовые, а также видео, аудио и картинки), то найти зависимость результата от них без машины невозможно.
Например, на химическую реакцию кроме самих вступающих во взаимодействие веществ влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т. д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
Как связаны Big Data и машинное обучение?
Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные. Для того чтобы эту информацию хранить и анализировать существует целая область технологий — Big Data. Для оптимального накопления данных и их анализа создают «озера данных» (Data Lake) — специальные распределенные хранилища для больших объемов слабоструктированной информации на базе технологий Big Data.
Цифровой двойник как электронный паспорт
Цифровой двойник — виртуальная копия реального материального объекта, процесса или организации, которая позволяет моделировать поведение изучаемого объекта/процесса. Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Модели C2
Хотя имеется множество вариантов реализации C2, архитектура между вредоносным ПО и платформой C2 обычно имеет одну из следующих моделей:
Централизованная модель
Централизованная модель управления и контроля практически аналогична стандартным связям клиент-сервер. «Клиент» вредоносной программы отправляет сигнал на сервер C2 и проверяет инструкции. На практике серверная инфраструктура злоумышленника часто намного сложнее, и может включать в себя редиректоры, балансировщики нагрузки и инструменты обнаружения «следов» охотников за угрозами (threat hunters) и сотрудников правоохранительных органов. Общедоступные облачные сервисы и сети доставки контента (Content Delivery Network, CDN) часто используются для размещения или маскировки активности C2. Также хакеры регулярно взламывают легитимные веб-сайты и используют их для размещения серверов управления и контроля без ведома владельца.
Активность C2 часто обнаруживается довольно быстро; домены и серверы, связанные с проведением атаки, можно удалить в течение нескольких часов после их первого использования. Для противодействия этому в коде современных вредоносных программ часто содержится целый список различных серверов C2, с которыми нужно попытаться связаться. В самых изощренных атаках применяются дополнительные уровни обфускации. Было зафиксировано, что вредоносное ПО получает список серверов C2 по координатам GPS, связанным с фотографиями, а также из комментариев в Instagram.
Одноранговая модель (P2P)
Модель с внешним управлением и случайным выбором каналов
Чего могут достичь хакеры с помощью C2?

Большинство организаций имеет достаточно эффективную защиту периметра, которая затрудняет злоумышленнику инициирование соединения из внешнего мира с сетью организации без обнаружения. Однако исходящие данные часто не подлежат жесткому контролю и ограничениям. За счет этого вредоносное ПО, внедренное через другой канал, например, фишинговое письмо или взломанный веб-сайт, устанавливает исходящий канал связи. Используя его, хакер может выполнять дополнительные действия, например:
«Горизонтальное перемещение» в пределах организации жертвы
Как только злоумышленник получает начальную «точку опоры», он обычно стремится перемещаться «горизонтально» по всей организации, используя свои каналы C2 для получения информации об уязвимых и/или некорректно настроенных хостах. Первая взломанная машина может и не представлять никакой ценности для злоумышленника, но она служит стартовой площадкой для доступа к более важным участкам сети. Этот процесс может повторяться несколько раз, пока злоумышленник не получит доступ к весомой цели, такой как файловый сервер или контроллер домена.
Многоступенчатые атаки
Самые сложные кибератаки являются многоэтапными. Нередко первоначальное заражение представляет собой «дроппер» или загрузчик, который связывается с управляющей инфраструктурой C2 и загружает дополнительные вредоносные данные. Такая модульная архитектура позволяет злоумышленнику проводить атаки с широким охватом и узкой направленностью. Дроппер может заразить тысячи организаций, позволяя злоумышленнику действовать избирательно, и создавать собственные вредоносные программы второго уровня для поражения наиболее привлекательных для него целей. Такая модель также позволяет создать целую децентрализованную индустрию киберпреступности. Группа, осуществившая первоначальное вторжение, может продавать доступ к основной цели (например, банку или больнице) другим киберпреступникам.
Эксфильтрация данных
Каналы C2 часто являются двунаправленными, что означает, что злоумышленник может загружать или извлекать («эксфильтировать») данные из целевой среды. Всё чаще кража данных выступает в качестве дополнительного инструмента для предъявления требований жертве; даже если организация сможет восстановить данные из резервных копий, злоумышленники угрожают раскрыть украденную и потенциально дискредитирующую информацию.
Другие пользователи
Как было отмечено выше, ботнеты часто используются для DDoS-атак на веб-сайты и другие сервисы. Инструкции в отношении того, какие сайты атаковать, доставляются через C2. Через C2 также могут передаваться другие типы инструкций. Например, были идентифицированы масштабные ботнеты для майнинга криптовалют. Кроме того, теоретически возможны даже более экзотические варианты использования команд C2, например, для срыва выборов или манипулирования энергетическими рынками.
Обнаружение и блокировка трафика С2

Трафик C2 чрезвычайно тяжело обнаружить, поскольку злоумышленники прилагают максимум усилий, чтобы их не заметили. Однако на стороне защиты есть огромные возможности, ведь нарушив работу C2, можно предотвратить более серьезные инциденты. Многие масштабные кибератаки были обнаружены, когда исследователи замечали активность C2. Вот несколько общих способов обнаружения и блокировки трафика управления и контроля в вашей сети:
Мониторинг и фильтрация исходящего трафика
Следите за маяками
Маяки могут быть индикатором присутствия управления и контроля в вашей сети, но их часто трудно обнаружить. Большинство решений IDS/IPS идентифицируют маяки, связанные с готовыми фреймворками, такими как Metasploit и Cobalt Strike, но злоумышленники могут легко изменить их настройки, чтобы значительно усложнить их выявление. Для более глубокого анализа сетевого трафика (network traffic analysis, NTA) можно использовать такой инструмент, как RITA. В некоторых случаях группы по поиску угроз заходят настолько далеко, что вручную проверяют дампы пакетов с помощью Wireshark, tcpdump и подобных инструментов.
Ведите журналы и выполняйте проверку

Сопоставляйте данные из разных источников
Общая суть инфраструктуры управления и контроля заключается в выполнении определенных действий, таких как доступ к важным файлам или заражение большого количества хостов. Охота за C&C на основе анализа данных и параметров сети увеличивает вероятность обнаружения хорошо замаскированных кибератак. Именно такой подход применяет Varonis Edge, обеспечивая максимальную прозрачность для выявления внутренних угроз и таргетированных атак.
Что нужно для качественного машинного обучения?
Data Scientiest’ы! Именно они создают алгоритм прогноза: изучают имеющиеся данные, выдвигают гипотезы, строят модели на основе Data Set. Они должны обладать тремя основными группами навыков: IT-грамотностью, математическими и статистическими знаниями и содержательным опытом в конкретной области.
Машинное обучение стоит на трех китах
Получение данных
Могут быть использованы данные из смежных систем: график работ, план продаж. Данные могут быть также обогащены внешними источниками: курсы валют, погода, календарь праздников и т. д. Необходимо разработать методику работы с каждым типом данных и продумать конвейер их преобразования в формат модели машинного обучения (набор чисел).
Построение признаков
Проводится вместе с экспертами из необходимой области. Это помогает вычислить данные, которые хорошо подходят для прогнозирования целей: статистика и изменение количества продаж за последний месяц для прогноза рынка.
Модель машинного обучения
Метод решения поставленной бизнес-задачи выбирает data scientist самостоятельно на основании своего опыта и возможностей различных моделей. Под каждую конкретную задачу необходимо подобрать отдельный алгоритм. От выбранного метода напрямую зависят скорость и точность результата обработки исходных данных.

Процесс создания ML-модели.
От гипотезы до результата
1. Всё начинается с гипотезы
Гипотеза рождается при анализе проблемного процесса, опыта сотрудников или при свежем взгляде на производство. Как правило, гипотеза затрагивает такой процесс, где человек физически не может учесть множество факторов и пользуется округлениями, допущениями или просто делает так, как всегда делал.
В таком процессе применение машинного обучения позволяет использовать существенно больше информации при принятии решений, поэтому, возможно, удается достичь существенно лучших результатов. Плюс ко всему, автоматизация процессов с помощью ML и снижение зависимости от конкретного человека существенно минимизируют человеческий фактор (болезнь, низкая концентрация и т. д.).
2. Оценка гипотезы
На основании сформулированной гипотезы выбираются данные, необходимые для разработки модели машинного обучения. Осуществляется поиск соответствующих данных и оценка их пригодности для встраивания модели в текущие процессы, определяется, кто будет ее пользователями и за счет чего достигается эффект. При необходимости вносятся организационные и любые другие изменения.
3. Расчет экономического эффекта и возврата инвестиций (ROI)
Оценка экономического эффекта внедряемого решения производится специалистами совместно с соответствующими департаментами: эффективности, финансов и т. д. На данном этапе необходимо понять, что именно является метрикой (количество верно выявленных клиентов / увеличение выпуска продукции / экономия расходных материалов и т. п.) и четко сформулировать измеряемую цель.
4. Математическая постановка задачи
После понимания бизнес-результата его необходимо переложить в математическую плоскость — определить метрики измерений и ограничения, которые нельзя нарушать. Данные этапы data
scientist выполняет совместно с бизнес-заказчиком.
5. Сбор и анализ данных
Необходимо собрать данные в одном месте, проанализировать их, рассматривая различные статистики, понять структуру и скрытые взаимосвязи этих данных для формирования признаков.
6. Создание прототипа
Является, по сути, проверкой гипотезы. Это возможность построения модели на текущих данных и первичной проверки результатов ее работы. Обычно прототип делается на имеющихся данных без разработки интеграций и работы с потоком в реальном времени.
Создание прототипа — быстрый и недорогой способ проверить, решаема ли задача. Это весьма полезно в том случае, когда невозможно заранее понять, получится ли достичь нужного экономического эффекта. К тому же процесс создания прототипа позволяет лучше оценить объем и подробности проекта по внедрению решения, подготовить экономическое обоснование такого внедрения.
DevOps и DataOps
В процессе эксплуатации может появится новый тип данных (например, появится ещё один датчик на станке или же на складе появится новый тип товаров) тогда модель нужно дообучить. DevOps и DataOps — методологии, которые помогают настроить совместную работу и сквозные процессы между командами Data Science, инженерами по подготовке данных, службами разработки и эксплуатации ИТ-систем, и помогают сделать такие дополнения частью текущего процесса быстро, без ошибок и без решения каждый раз уникальных проблем.
7. Создание решения
В тот момент, когда результаты работы прототипа демонстрируют уверенное достижение показателей, создается полноценное решение, где модель машинного обучения является лишь составляющей изучаемых процессов. Далее производится интеграция, установка необходимого оборудования, обучение персонала, изменение процессов принятия решений и т. Д.
8. Опытная и промышленная эксплуатация
Во время опытной эксплуатации система работает в режиме советов, в то время как специалист еще повторяет привычные действия, каждый раз давая обратную связь о необходимых улучшениях системы и увеличении точности прогнозов.
Финальная часть — промышленная эксплуатация, когда налаженные процессы переходят на полностью автоматическое обслуживание.
Шпаргалку можно скачать по ссылке.
Завтра на форуме по системам искусственного интеллекта RAIF 2019 в 09:30 — 10:45 состоится панельная дискуссия: «AI для людей: разбираемся простыми словами».
В этой секции в формате дебатов спикеры объяснят простыми словами на жизненных примерах сложные технологии. А также подискутируют на следующие темы:
- В чем разница между Artificial Intelligence, Machine Learning и Data Science?
- Как работает машинное обучение?
- Как работают нейронные сети?
- Что нужно для качественного машинного обучения?
- Что такое разметка, маркировка данных?
- Что такое цифровой двойник и как работать с виртуальными копиями реальных материальных объектов?
- В чем суть гипотезы? Как пройти путь от её постановки до оценки и интерпретации результата?
Николай Марин, директор по технологиям, IBM в России и СНГ
Алексей Натекин, основатель, Open Data Science x Data Souls
Алексей Хахунов, технический директор, Dbrain
Евгений Колесников, директор Центра машинного обучения, Инфосистемы Джет
Павел Доронин, CEO, AI Today
Дискуссия будет доступна на канале YouTube «Инфосистемы Джет» в конце октября.
Надежный (неэкстремальный) разгон процессора и памяти для материнских плат ASUS с процессором i7
Все действия, связанные с разгоном, осуществляются в меню AI Tweaker (UEFI Advanced Mode) установкой параметра AI Overclock Tuner в Manual (рис. 1).
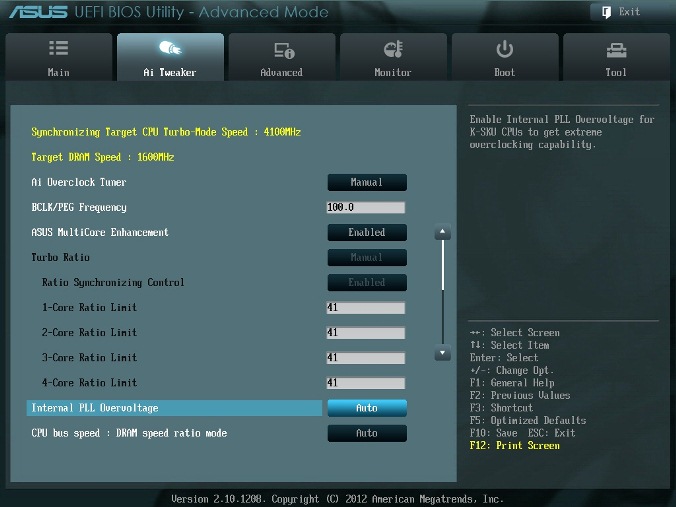
Рис. 1
BCLK/PEG Frequency
Параметр BCLK/PEG Frequency (далее BCLK) на рис. 1 становится доступным, если выбраны Ai Overclock Tuner\XMP или Ai Overclock Tuner\Manual. Частота BCLK, равная 100 МГц, является базовой. Главный параметр разгона – частота ядра процессора, получается путем умножения этой частоты на параметр – множитель процессора. Конечная частота отображается в верхней левой части окна Ai Tweaker (на рис. 1 она равна 4,1 ГГц). Частота BCLK также регулирует частоту работы памяти, скорость шин и т.п.
Возможное увеличение этого параметра при разгоне невелико – большинство процессоров позволяют увеличивать эту частоту только до 105 МГц. Хотя есть отдельные образцы процессоров и материнских плат, для которых эта величина равна 107 МГц и более. При осторожном разгоне, с учетом того, что в будущем в компьютер будут устанавливаться дополнительные устройства, этот параметр рекомендуется оставить равным 100 МГц (рис. 1).
ASUS MultiCore Enhancement
Когда этот параметр включен (Enabled на рис. 1), то принимается политика ASUS для Turbo-режима. Если параметр выключен, то будет применяться политика Intel для Turbo-режима. Для всех конфигураций при разгоне рекомендуется включить этот параметр (Enabled). Выключение параметра может быть использовано, если вы хотите запустить процессор с использованием политики корпорации Intel, без разгона.
Turbo Ratio
В окне рис. 1 устанавливаем для этого параметра режим Manual. Переходя к меню Advanced\. \CPU Power Management Configuration (рис. 2) устанавливаем множитель 41.
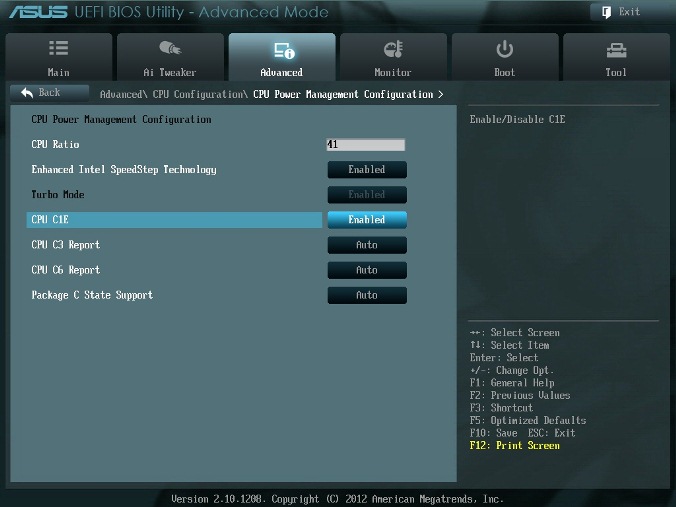
Рис. 2
Возвращаемся к меню AI Tweaker и проверяем значение множителя (рис. 1).
Для очень осторожных пользователей можно порекомендовать начальное значение множителя, равное 40 или даже 39. Максимальное значение множителя для неэкстремального разгона обычно меньше 45.
Internal PLL Overvoltage
Увеличение (разгон) рабочего напряжения для внутренней фазовой автоматической подстройки частоты (ФАПЧ) позволяет повысить рабочую частоту ядра процессора. Выбор Auto будет автоматически включать этот параметр только при увеличении множителя ядра процессора сверх определенного порога.
Для хороших образцов процессоров этот параметр нужно оставить на Auto (рис. 1) при разгоне до множителя 45 (до частоты работы процессора 4,5 ГГц).
Отметим, что стабильность выхода из режима сна может быть затронута, при установке этого параметра в состояние включено (Enabled). Если обнаруживается, что ваш процессор не будет разгоняться до 4,5 ГГц без установки этого параметра в состояние Enabled, но при этом система не в состоянии выходить из режима сна, то единственный выбор – работа на более низкой частоте с множителем меньше 45. При экстремальном разгоне с множителями, равными или превышающими 45, рекомендуется установить Enabled. При осторожном разгоне выбираем Auto. (рис. 1).
CPU bus speed: DRAM speed ratio mode
Этот параметр можно оставить в состоянии Auto (рис. 1), чтобы применять в дальнейшем изменения при разгоне и настройке частоты памяти.
Memory Frequency
Этот параметр виден на рис. 3. С его помощью осуществляется выбор частоты работы памяти.
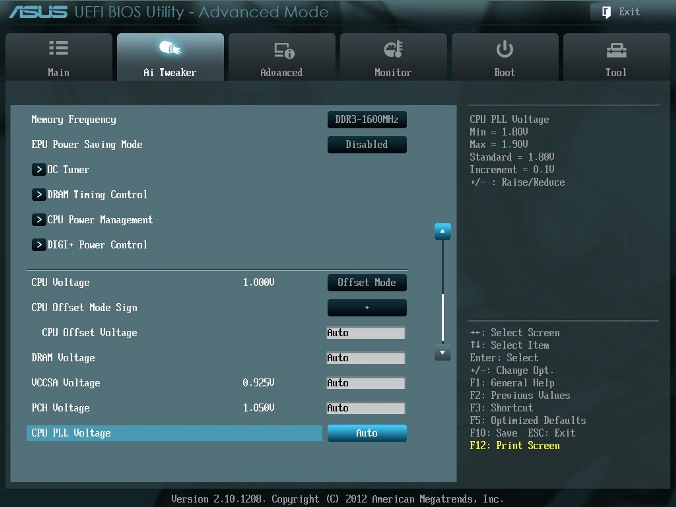
Рис. 3
Параметр Memory Frequency определяется частотой BCLK и параметром CPU bus speed:DRAM speed ratio mode. Частота памяти отображается и выбирается в выпадающем списке. Установленное значение можно проконтролировать в левом верхнем углу меню Ai Tweaker. Например, на рис. 1 видим, что частота работы памяти равна 1600 МГц.
Отметим, что процессоры Ivy Bridge имеют более широкий диапазон настроек частот памяти, чем предыдущее поколение процессоров Sandy Bridge. При разгоне памяти совместно с увеличением частоты BCLK можно осуществить более детальный контроль частоты шины памяти и получить максимально возможные (но возможно ненадежные) результаты при экстремальном разгоне.
Для надежного использования разгона рекомендуется поднимать частоту наборов памяти не более чем на 1 шаг относительно паспортной. Более высокая скорость работы памяти дает незначительный прирост производительности в большинстве программ. Кроме того, устойчивость системы при более высоких рабочих частотах памяти часто не может быть гарантирована для отдельных программ с интенсивным использованием процессора, а также при переходе в режим сна и обратно.
Рекомендуется также сделать выбор в пользу комплектов памяти, которые находятся в списке рекомендованных для выбранного процессора, если вы не хотите тратить время на настройку стабильной работы системы.
Рабочие частоты между 2400 МГц и 2600 МГц, по-видимому, являются оптимальными в сочетании с интенсивным охлаждением, как процессоров, так и модулей памяти. Более высокие скорости возможны также за счет уменьшения вторичных параметров – таймингов памяти.
При осторожном разгоне начинаем с разгона только процессора. Поэтому вначале рекомендуется установить паспортное значение частоты работы памяти, например, для комплекта планок памяти DDR3-1600 МГц устанавливаем 1600 МГц (рис. 3).
После разгона процессора можно попытаться поднять частоту памяти на 1 шаг. Если в стресс-тестах появятся ошибки, то можно увеличить тайминги, напряжение питания (например на 0,05 В), VCCSA на 0,05 В, но лучше вернуться к номинальной частоте.
EPU Power Saving Mode
Автоматическая система EPU разработана фирмой ASUS. Она регулирует частоту и напряжение элементов компьютера в целях экономии электроэнергии. Эта установка может быть включена только на паспортной рабочей частоте процессора. Для разгона этот параметр выключаем (Disabled) (рис. 3).
OC Tuner
Когда выбрано (OK), будет работать серия стресс-тестов во время Boot-процесса с целью автоматического разгона системы. Окончательный разгон будет меняться в зависимости от температуры системы и используемого комплекта памяти. Включать не рекомендуется, даже если вы не хотите вручную разогнать систему. Не трогаем этот пункт или выбираем cancel (рис. 3).
DRAM Timing Control
DRAM Timing Control – это установка таймингов памяти (рис. 4).
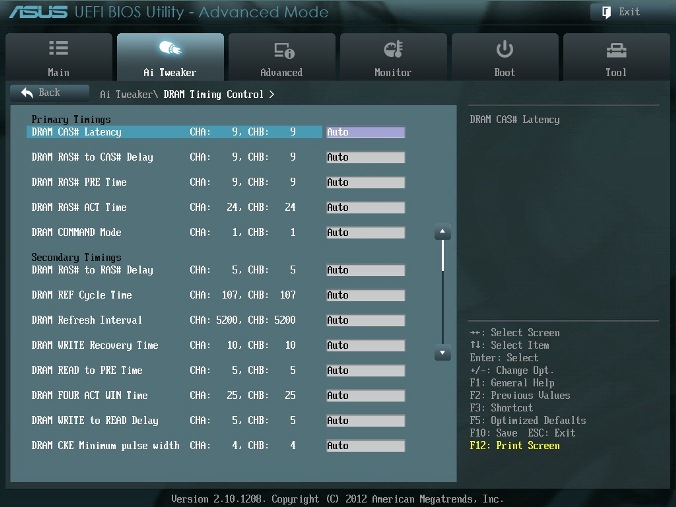
Рис. 4.
Все эти настройки нужно оставить равными паспортным значениям и на Auto, если вы хотите настроить систему для надежной работы. Основные тайминги должны быть установлены в соответствии с SPD модулей памяти.
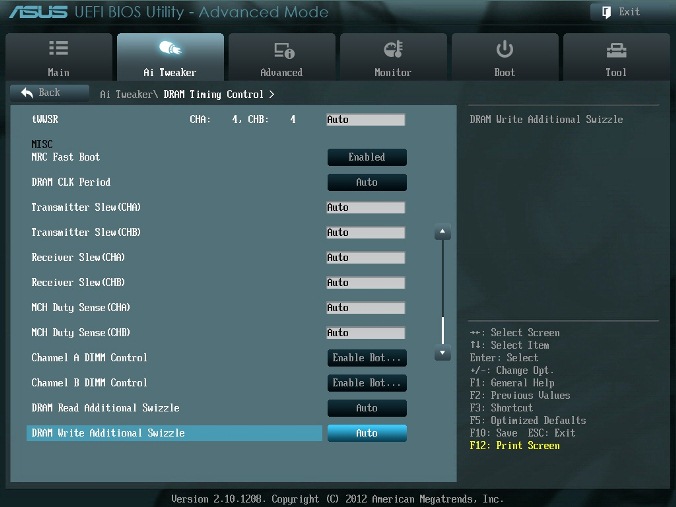
Рис. 5
Большинство параметров на рис. 5 также оставляем в Auto.
MRC Fast Boot
Включите этот параметр (Enabled). При этом пропускается тестирование памяти во время процедуры перезагрузки системы. Время загрузки при этом уменьшается.
Отметим, что при использовании большего количества планок памяти и при высокой частоте модулей (2133 МГц и выше) отключение этой настройки может увеличить стабильность системы во время проведения разгона. Как только получим желаемую стабильность при разгоне, включаем этот параметр (рис. 5).
DRAM CLK Period
Определяет задержку контроллера памяти в сочетании с приложенной частоты памяти. Установка 5 дает лучшую общую производительность, хотя стабильность может ухудшиться. Установите лучше Auto (рис. 5).
CPU Power Management
Окно этого пункта меню приведено на рис. 6. Здесь проверяем множитель процессора (41 на рис. 6), обязательно включаем (Enabled) параметр энергосбережения EIST, а также устанавливаем при необходимости пороговые мощности процессоров (все последние упомянутые параметры установлены в Auto (рис. 6)).
Перейдя к пункту меню Advanced\. \CPU Power Management Configuration (рис. 2) устанавливаем параметр CPU C1E (энергосбережение) в Enabled, а остальные (включая параметры с C3, C6) в Auto.

Рис. 6
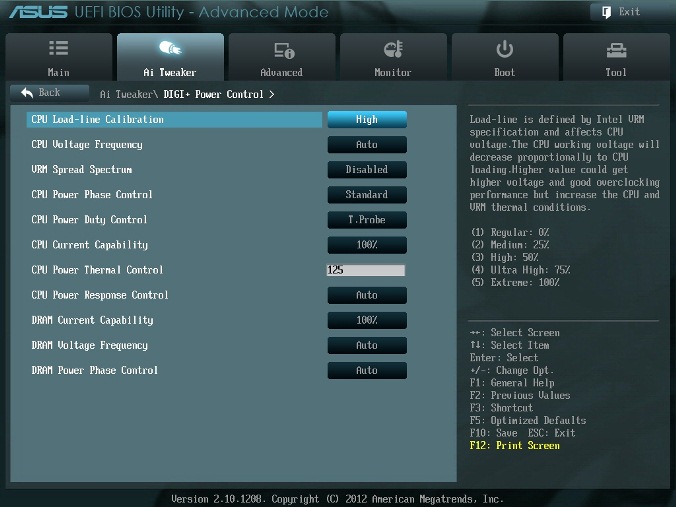
Рис. 7.
DIGI+ Power Control
На рис. 7 показаны рекомендуемые значения параметров. Некоторые параметры рассмотрим отдельно.
CPU Load-Line Calibration
Сокращённое наименование этого параметра – LLC. При быстром переходе процессора в интенсивный режим работы с увеличенной мощностью потребления напряжение на нем скачкообразно уменьшается относительно стационарного состояния. Увеличенные значения LLC обуславливают увеличение напряжения питания процессора и уменьшают просадки напряжения питания процессора при скачкообразном росте потребляемой мощности. Установка параметра равным high (50%) считается оптимальным для режима 24/7, обеспечивая оптимальный баланс между ростом напряжения и просадкой напряжения питания. Некоторые пользователи предпочитают использовать более высокие значения LLC, хотя это будет воздействовать на просадку в меньшей степени. Устанавливаем high (рис. 7).
VRM Spread Spectrum
При включении этого параметра (рис. 7) включается расширенная модуляция сигналов VRM, чтобы уменьшить пик в спектре излучаемого шума и наводки в близлежащих цепях. Включение этого параметра следует использовать только на паспортных частотах, так как модуляция сигналов может ухудшить переходную характеристику блока питания и вызвать нестабильность напряжения питания. Устанавливаем Disabled (рис. 7).
Current Capability
Значение 100% на все эти параметры должны быть достаточно для разгона процессоров с использованием обычных методов охлаждения (рис. 7).
Рис. 8.
CPU Voltage
Есть два способа контролировать напряжения ядра процессора: Offset Mode (рис. 8) и Manual. Ручной режим обеспечивает всегда неизменяемый статический уровень напряжения на процессоре. Такой режим можно использовать кратковременно, при тестировании процессора. Режим Offset Mode позволяет процессору регулировать напряжение в зависимости от нагрузки и рабочей частоты. Режим Offset Mode предпочтителен для 24/7 систем, так как позволяет процессору снизить напряжение питания во время простоя компьютера, снижая потребляемую энергию и нагрев ядер.
Уровень напряжения питания будет увеличиваться при увеличении коэффициента умножения (множителя) для процессора. Поэтому лучше всего начать с низкого коэффициента умножения, равного 41х (или 39х) и подъема его на один шаг с проверкой на устойчивость при каждом подъеме.
Установите Offset Mode Sign в “+”, а CPU Offset Voltage в Auto. Загрузите процессор вычислениями с помощью программы LinX и проверьте с помощью CPU-Z напряжение процессора. Если уровень напряжения очень высок, то вы можете уменьшить напряжение путем применения отрицательного смещения в UEFI. Например, если наше полное напряжение питания при множителе 41х оказалась равным 1,35 В, то мы могли бы снизить его до 1,30 В, применяя отрицательное смещение с величиной 0,05 В.
Имейте в виду, что уменьшение примерно на 0,05 В будет использоваться также для напряжения холостого хода (с малой нагрузкой). Например, если с настройками по умолчанию напряжение холостого хода процессора (при множителе, равном 16x) является 1,05 В, то вычитая 0,05 В получим примерно 1,0 В напряжения холостого хода. Поэтому, если уменьшать напряжение, используя слишком большие значения CPU Offset Voltage, наступит момент, когда напряжение холостого хода будет таким малым, что приведет к сбоям в работе компьютера.
Если для надежности нужно добавить напряжение при полной нагрузке процессора, то используем “+” смещение и увеличение уровня напряжения. Отметим, что введенные как “+” так и “-” смещения не точно отрабатываются системой питания процессора. Шкалы соответствия нелинейные. Это одна из особенностей VID, заключающаяся в том, что она позволяет процессору просить разное напряжение в зависимости от рабочей частоты, тока и температуры. Например, при положительном CPU Offset Voltage 0,05 напряжение 1,35 В при нагрузке может увеличиваться только до 1,375 В.
Из изложенного следует, что для неэкстремального разгона для множителей, примерно равных 41, лучше всего установить Offset Mode Sign в “+” и оставить параметр CPU Offset Voltage в Auto. Для процессоров Ivy Bridge, ожидается, что большинство образцов смогут работать на частотах 4,1 ГГц с воздушным охлаждением.
Больший разгон возможен, хотя при полной загрузке процессора это приведет к повышению температуры процессора. Для контроля температуры запустите программу RealTemp.
DRAM Voltage
Устанавливаем напряжение на модулях памяти в соответствии с паспортными данными. Обычно это примерно 1,5 В. По умолчанию – Auto (рис. 8).
VCCSA Voltage
Параметр устанавливает напряжение для System Agent. Можно оставить на Auto для нашего разгона (рис. 8).
CPU PLL Voltage
Для нашего разгона – Auto (рис. 8). Обычные значения параметра находятся около 1,8 В. При увеличении этого напряжения можно увеличивать множитель процессора и увеличивать частоту работы памяти выше 2200 МГц, т.к. небольшое превышение напряжения относительно номинального может помочь стабильности системы.
PCH Voltage
Можно оставить значения по умолчанию (Auto) для небольшого разгона (рис. 8). На сегодняшний день не выявилось существенной связи между этим напряжением на чипе и другими напряжениями материнской платы.
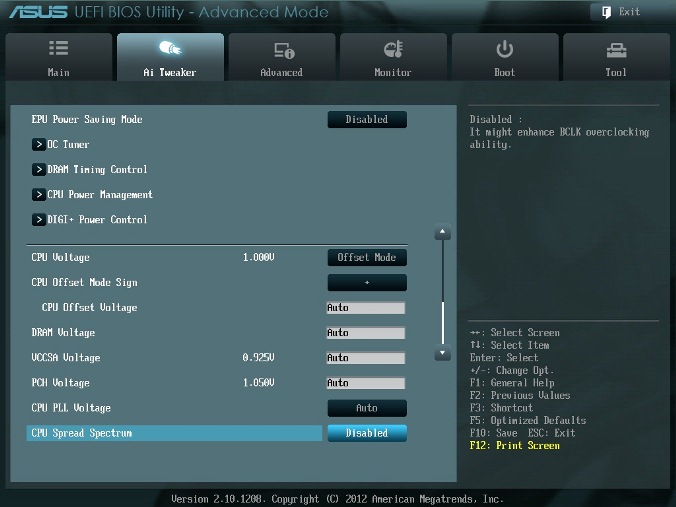
Рис. 9
CPU Spread Spectrum
При включении опции (Enabled) осуществляется модуляция частоты ядра процессора, чтобы уменьшить величину пика в спектре излучаемого шума. Рекомендуется установить параметр в Disabled (рис. 9), т.к. при разгоне модуляция частоты может ухудшить стабильность системы.
Автору таким образом удалось установить множитель 41, что позволило ускорить моделирование с помощью MatLab.
Что такое Command and Control? Описание инфраструктуры управления и контроля

Cегодня мы рассмотрим инфраструктуру управления и контроля (C2), используемую злоумышленниками для управления зараженными устройствами и кражи конфиденциальных данных во время кибератаки.
Успешная кибератака — это не просто вторжение в систему ничего не подозревающей об этом организации. Чтобы получить реальную выгоду, злоумышленник должен поддерживать постоянное функционирование вируса в целевой среде, обмениваться данными с зараженными или скомпрометированными устройствами внутри сети и потенциально извлекать конфиденциальные данные. Для выполнения всех этих задач требуется надежная инфраструктура управления и контроля, или C2. Что такое C2? В этом посте мы ответим на этот вопрос и посмотрим, как злоумышленники используют скрытые каналы связи для проведения изощренных атак. Мы также рассмотрим, как обнаруживать атаки на основе C2 и защищаться от них.
Что такое C2?
Инфраструктура управления и контроля, также известная как C2, или C&C, представляет собой набор инструментов и методов, которые злоумышленники используют для обмена данными со скомпрометированными устройствами после первоначального вторжения. Конкретные механизмы атак сильно отличаются друг от друга, но обычно C2 включает один или несколько скрытых каналов связи между устройствами в атакуемой организации и контролируемой злоумышленником платформой. Эти каналы связи используются для передачи инструкций взломанным устройствам, загрузки дополнительных вредоносных данных и передачи украденных данных злоумышленнику.

Платформы управления и контроля могут быть полностью персонализированными или стандартными. Киберпреступники и пентестеры используют такие популярные платформы, как Cobalt Strike, Covenant, Powershell Empire и Armitage.
В контексте C2 или C&C часто можно услышать ряд других терминов, перечисленных ниже.
«Зомби»
«Зомби» — это компьютер или подключенное устройство другого типа, которое заражено вредоносной программой и может удаленно управляться злоумышленником без ведома или согласия легитимного владельца. Хотя некоторые вирусы, трояны и другие вредоносные программы выполняют определенные действия после заражения устройства, основной целью многих других типов вредоносных программ является прокладка пути к инфраструктуре C2 злоумышленника. Затем системы этих «зомби»-машин могут быть захвачены для выполнения самых разных задач, от рассылки спама по электронной почте до участия в масштабных DDoS-атаках.
Ботнет
Ботнет — это сеть «зомби»-машин, используемых для общей цели. Целью ботнетов может быть что угодно, от майнинга криптовалюты до отключения веб-сайта с помощью DDoS-атаки. Ботнеты обычно объединяются в единой инфраструктуре C2. Также хакеры часто продают доступ к ботнетам другим киберпреступникам в виде «атаки как услуги».
Beaconing
Читайте также: