
Видеопамять это mem или ram
В процессе работы с CUDA я практически не касался вопросов об использовании памяти видеокарты. Настало время убрать этот пробел.
Так как тема весьма объемная, то я решил разделить её на несколько частей. В этой части я расскажу об основных видах памяти, доступных на видеокарте и приведу пример, как влияет выбор типа памяти на производительность вычислений на GPU.
Видеокарта и типы памяти
При использовании GPU разработчику доступно несколько видов памяти: регистры, локальная, глобальная, разделяемая, константная и текстурная память. Каждая из этих типов памяти имеет определенное назначение, которое обуславливается её техническими параметрами (скорость работы, уровень доступа на чтение и запись). Иерархия типов памяти представлена на рис. 1.
- Регистровая память (register) является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с помощью уже хорошо известной функции cudaGetDeviceProperties. Рассчитать количество регистров, доступных одной нити GPU, так же не составляет труда, для этого необходимо разделить общее число регистров на произведение количества нитей в блоке и количества блоков в гриде. Все регистры GPU 32 разрядные. В CUDA нет явных способов использования регистровой памяти, всю работу по размещению данных в регистрах берет на себя компилятор.
- Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в какой-либо функции. По скоростным характеристикам локальная память значительно медленнее, чем регистровая. В документации от nVidia рекомендуется использовать локальную память только в самых необходимых случаях. Явных средств, позволяющих блокировать использование локальной памяти, не предусмотрено, поэтому при падении производительности стоит тщательно проанализировать код и исключить лишние локальные переменные.
- Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные можно выделить с помощью спецификатора __global__, а так же динамически, с помощью функций из семейства cudMallocXXX. Глобальная память в основном служит для хранения больших объемов данных, поступивших на device с host’а, данное перемещение осуществляется с использованием функций cudaMemcpyXXX. В алгоритмах, требующих высокой производительности, количество операций с глобальной памятью необходимо свести к минимуму.
- Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для минимизации обращение к глобальной памяти, а так же для хранения локальных переменных функций. Адресация разделяемой памяти между нитями потока одинакова в пределах одного блока, что может быть использовано для обмена данными между потоками в пределах одного блока. Для размещения данных в разделяемой памяти используется спецификатор __shared__.
- Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти является возможность записи данных с хоста, но при этом в пределах GPU возможно лишь чтение из этой памяти, что и обуславливает её название. Для размещения данных в константной памяти предусмотрен спецификатор __constant__. Если необходимо использовать массив в константной памяти, то его размер необходимо указать заранее, так как динамическое выделение в отличие от глобальной памяти в константной не поддерживается. Для записи с хоста в константную память используется функция cudaMemcpyToSymbol, и для копирования с device’а на хост cudaMemcpyFromSymbol, как видно этот подход несколько отличается от подхода при работе с глобальной памятью.
- Текстурная память (texture memory), как и следует из названия, предназначена главным образом для работы с текстурами. Текстурная память имеет специфические особенности в адресации, чтении и записи данных. Более подробно о текстурной памяти я расскажу при рассмотрении вопросов обработки изображений на GPU.
Пример использования разделяемой памяти
Чуть выше я вкратце рассказал о различных типах памяти, которые доступны при программировании GPU. Теперь я хочу привести пример использования разделяемой памяти при операции транспонирования матрицы.
Перед тем, как приступить к написанию основного кода, приведу небольшой способ отладки. Как известно, функции из CUDA runtime API могут возвращать различные коды ошибок, но в предыдущий раз я ни как это не учитывал. Чтобы упростить себе жизнь можно использовать следующий макрос для отлова ошибок:
Как видно, в случае, если определена переменная среды CUDA_DEBUG, происходит проверка кода ошибки и выводиться информация о файле и строке, где она произошла. Эту переменную можно включить при компиляции под отладку и отключить при компиляции под релиз.
Приступаем к основной задаче.
Для того чтобы увидеть, как влияет использование разделяемой памяти на скорость вычислений, так же следует написать функцию, которая будет использовать только глобальную память.
Пишем эту функцию:
// Функция транспонирования матрицы без использования разделяемой памяти
//
// inputMatrix - указатель на исходную матрицу
// outputMatrix - указатель на матрицу результат
// width - ширина исходной матрицы (она же высота матрицы-результата)
// height - высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixSlow( float * inputMatrix, float * outputMatrix, int width, int height)
int xIndex = blockDim.x * blockIdx.x + threadIdx.x;
int yIndex = blockDim.y * blockIdx.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
//Линейный индекс элемента строки исходной матрицы
int inputIdx = xIndex + width * yIndex;
//Линейный индекс элемента столбца матрицы-результата
int outputIdx = yIndex + height * xIndex;
outputMatrix[outputIdx] = inputMatrix[inputIdx];
>
>
* This source code was highlighted with Source Code Highlighter .
Данная функция просто копирует строки исходной матрицы в столбцы матрицы-результата. Единственный сложный момент – это определение индексов элементов матриц, здесь необходимо помнить, что при вызове ядра может быть использованы различные размерности блоков и грида, для этого и используются встроенные переменные blockDim, blockIdx.
Пишем функцию транспонирования, которая использует разделяемую память:
// Функция транспонирования матрицы c использования разделяемой памяти
//
// inputMatrix - указатель на исходную матрицу
// outputMatrix - указатель на матрицу результат
// width - ширина исходной матрицы (она же высота матрицы-результата)
// height - высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixFast( float * inputMatrix, float * outputMatrix, int width, int height)
__shared__ float temp[BLOCK_DIM][BLOCK_DIM];
int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * width + xIndex;
//Копируем элементы исходной матрицы
temp[threadIdx.y][threadIdx.x] = inputMatrix[idx];
>
//Синхронизируем все нити в блоке
__syncthreads();
xIndex = blockIdx.y * blockDim.y + threadIdx.x;
yIndex = blockIdx.x * blockDim.x + threadIdx.y;
if ((xIndex < height) && (yIndex < width))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * height + xIndex;
//Копируем элементы исходной матрицы
outputMatrix[idx] = temp[threadIdx.x][threadIdx.y];
>
>
* This source code was highlighted with Source Code Highlighter .
В этой функции я использую разделяемую память в виде двумерного массива.
Как уже было сказано, адресация разделяемой памяти в пределах одного блока одинакова для всех потоков, поэтому, чтобы избежать коллизий при доступе и записи, каждому элементу в массиве соответствует одна нить в блоке.
После копирования элементов исходной матрицы в буфер temp, вызывается функция __syncthreads. Эта функция синхронизирует потоки в пределах блока. Её отличие от других способов синхронизации заключаеться в том, что она выполняеться только на GPU.
В конце происходит копирование сохраненных элементов исходной матрицы в матрицу-результат, в соответствии с правилом транспонирования.
Может показаться, что эта функция должна выполняться медленне, чем её версия без разделяемой памяти, где нет никаких посредников. Но на самом деле копирование из глобальной памяти в глобальную работает значительно медленее, чем связка глобальная память – разделяемая память – глобальная память.
Хочу заметить, что проверять границы массивов матриц стоит вручную, в GPU нет аппаратных средств для слежения за границами массивов.
Ну и напоследок напишем функцию транспонирования, которая исполняется только на CPU:
// Функция транспонирования матрицы, выполняемая на CPU
__host__ void transposeMatrixCPU( float * inputMatrix, float * outputMatrix, int width, int height)
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
outputMatrix[x * height + y] = inputMatrix[y * width + x];
>
>
>
* This source code was highlighted with Source Code Highlighter .
Теперь необходимо сгенерировать данные для расчетов, скопировать их с хоста на девайс, в случае использования GPU, произвести замеры производительности и очистить ресурсы.
Так как эти этапы примерно такие же, что я описывал в предыдущий раз, то привожу этого фрагмента сразу:
__host__ int main()
<
int width = 2048; //Ширина матрицы
int height = 1536; //Высота матрицы
int matrixSize = width * height;
int byteSize = matrixSize * sizeof ( float );
//Выделяем память под матрицы на хосте
float * inputMatrix = new float [matrixSize];
float * outputMatrix = new float [matrixSize];
//Заполняем исходную матрицу данными
for ( int i = 0; i < matrixSize; i++)
inputMatrix[i] = i;
>
//Выбираем способ расчета транспонированной матрицы
printf( "Select compute mode: 1 - Slow GPU, 2 - Fast GPU, 3 - CPU\n" );
int mode;
scanf( "%i" , &mode);
//Записываем исходную матрицу в файл
printMatrixToFile( "before.txt" , inputMatrix, width, height);
if (mode == CPU) //Если используеться только CPU
<
int start = GetTickCount();
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixCPU(inputMatrix, outputMatrix, width, height);
>
//Выводим время выполнения функции на CPU (в миллиекундах)
printf ( "CPU compute time: %i\n" , GetTickCount() - start);
>
else //В случае расчета на GPU
float * devInputMatrix;
float * devOutputMatrix;
//Выделяем глобальную память для храния данных на девайсе
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devInputMatrix, byteSize));
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devOutputMatrix, byteSize));
//Копируем исходную матрицу с хоста на девайс
CUDA_CHECK_ERROR(cudaMemcpy(devInputMatrix, inputMatrix, byteSize, cudaMemcpyHostToDevice));
//Конфигурация запуска ядра
dim3 gridSize = dim3(width / BLOCK_DIM, height / BLOCK_DIM, 1);
dim3 blockSize = dim3(BLOCK_DIM, BLOCK_DIM, 1);
cudaEvent_t start;
cudaEvent_t stop;
//Создаем event'ы для синхронизации и замера времени работы GPU
CUDA_CHECK_ERROR(cudaEventCreate(&start));
CUDA_CHECK_ERROR(cudaEventCreate(&stop));
//Отмечаем старт расчетов на GPU
cudaEventRecord(start, 0);
if (mode == GPU_SLOW) //Используеться функция без разделяемой памяти
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixSlow<<<gridSize, blockSize>>>(devInputMatrix, devOutputMatrix, width, height);
>
>
else if (mode == GPU_FAST) //Используеться функция с разделяемой памятью
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixFast<<<gridSize, blockSize>>>(devInputMatrix, devOutputMatrix, width, height);
>
>
//Отмечаем окончание расчета
cudaEventRecord(stop, 0);
float time = 0;
//Синхронизируемя с моментом окончания расчетов
cudaEventSynchronize(stop);
//Рассчитываем время работы GPU
cudaEventElapsedTime(&time, start, stop);
//Выводим время расчета в консоль
printf( "GPU compute time: %.0f\n" , time);
//Копируем результат с девайса на хост
CUDA_CHECK_ERROR(cudaMemcpy(outputMatrix, devOutputMatrix, byteSize, cudaMemcpyDeviceToHost));
//
//Чистим ресурсы на видеокарте
//
//Записываем матрицу-результат в файл
printMatrixToFile( "after.txt" , outputMatrix, height, width);
//Чистим память на хосте
delete[] inputMatrix;
delete[] outputMatrix;
* This source code was highlighted with Source Code Highlighter .
В случае если расчеты выполняются только на CPU, то для замера времени расчетов используется функция GetTickCount(), которая подключается из windows.h. Для замера времени расчетов на GPU используеться функция cudaEventElapsedTime, прототип которой имеет следующий вид:
- time – указатель на float, для записи времени между event’ами start и end (в миллисекундах),
- start – хендл первого event’а,
- end – хендл второго event’а.
- cudaSuccess – в случае успеха
- cudaErrorInvalidValue – неверное значение
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidResourceHandle – неверный хендл event’а
Так же я записываю исходную матрицу и результат в файлы через функцию printMatrixToFile. Чтобы удостовериться, что результаты верны. Код этой функции следующий:
__host__ void printMatrixToFile( char * fileName, float * matrix, int width, int height)
FILE* file = fopen(fileName, "wt" );
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
fprintf(file, "%.0f\t" , matrix[y * width + x]);
>
fprintf(file, "\n" );
>
fclose(file);
>
* This source code was highlighted with Source Code Highlighter .
Если матрицы очень большие, то вывод данных в файлы может сильно замедлить выполнение программы.
Заключение
В процессе тестирования я использовал матрицы размерностью 2048 * 1536= 3145728 элементов и 20 итераций в нагрузочных циклах. После результатов замеров у меня получились следующие результаты (рис. 2).

Рис. 2. Время расчетов. (меньше –лучше).
Как видно, GPU версия с разделяемой памятью выполняется почти в 20 раз быстрее, чем версия на CPU. Так же стоит отметить, что при использовании разделяемой памяти расчет выполняется примерно в 4 раза быстрее, чем без неё.
В своем примере я не учитываю время копирования данных с хоста на девайс и обратно, но в реальных приложениях их так же необходимо брать в расчет. Количество перемещений данных между CPU и GPU по-возможности необходимо свести к минимуму.
“Моя видеокарта не тянет эту игру”. Думали ли вы иногда так, видя 6 FPS (кадров в секунду) играя в новенькую игру?
Так как это работает? Как набор нулей и едениц на вашем жестком диске превращаются в красивую (или не очень) картинку, которой вы можете управлять? Наваливайте пельмешек, на связи разработчик игр с восьмилетним стажем и мы начинаем!
Архитектура ПК
Всё что я расскажу дальше - сильно упрощенная схема и в реальности всё намного сложнее. Но для первого понимания это подойдет.
Итак, вскрывши крышку своего ПК вы увидите необходимые нам детали:
1. ) Центральный процессор(далее ЦП);
2. ) Оперативная память (далее ОЗУ);
3. )Жесткий диск;
4. ) Видеокарта.
Центральный процессор и жесткий диск
Роль ЦП в работе игр поистине неоценима. Но давайте сейчас отправимся в тот момент, когда игра была только запущенна. Итак, ваша игра лежит на жестком диске. Скорость работы читания с обычного жесткого диска - 100 мегабайт в секунду у нового и почти 50 мегабайт в секунду у старого. Что нам это дает? Как бы быстро это не казалось (1 gb за 10 секунд) это очень моло для игр. Представьте себе ситуацию: вы едите на скорости 150 км/час в новенькой NFS. И тут появляется цель: отрисовать 4 дома (5 мб один), дорогу(30 мб на дорогу со всеми её материалами), 8 деревьев (4 мб одно) и 5 машин (5 мб одна). В среднем, на такой скорости, на вашем экране должно рисоваться на пару секунд разных объектов общим размером на 100-150 мегабайт. Но мы помним, что прежде чем их отрисовать, нужно их вытащить из жесткого диска. И того: ради 2 секунд отрисовки мы потерям секунду на то чтобы их вытащить из памяти и всего лишь 1/60 секунды(при 60 FPS) чтоб их отрисовать. Это нерационально использованное время. Но как иначе?
Жесткий диск и принцип его работы
Как работает жесткий диск?
Он получил своё название не зря. Внутри этой черной коробки и вправду лежит металлический диск. Когда вам нужно что то записать, он раскручивается до скорости 7 200 оборотов в секунду, и маленькая магнитная головка записывает на этом диске данные зарисовывая и очищая клеточки как делали вы на скучных уроках на полях в тетради.
Но как происходит эта запись? При помощи магнитов. Каждая клеточка (правильное её название "бит") может быть либо намагничена либо размагничена. Головка может её намагнить и размагнитить. Так же она может проверить намагничен ли бит. И у нас выходит классическая схема "намагничено = 1, размагничено = 0".
Головка считывает эти нули и единицы и отдает их ЦП. Тот, в свою очередь, расшифровывает их в цифры и буквы. Плюс такой системы в трм, что жесткий диск может хранить информацию годами ведь размагнитить настолько мелкий бит довольно сложно. Минус - 100 мб/сек очень медленно для плавной работы игр.
Оперативная память
Но уже давно для этой проблемы была придумана панацея - оперативная память. Данный вид памяти, в отличии от жесткого диска, работает практически моментально, выдавая ЦП ту информацию, которая ему нужна, не теряя при этом времени. Минус кроется в одном из названий этой памяти - "энергозависимая память". Да, как только к компьютеру перестаёт подходить электроэнергия все данные из оперативной памяти стираются.
ЦП, ОЗУ и Жесткий диск
А теперь рассмотрим как это работает на практике.
Вы кликаете на игру. ЦП говорит Жесткому диску какая информация ему нужна. Многие игры вначале выдают какую-то картинку или экран загрузки. А теперь уйдет от нескольких секунд до нескольких минут на то, чтоб вытащить данные из жесткого диска. Тут же их процессор считывает и записывает в ОЗУ. После появляется главное меню и многие данные напрямую читаются из ОЗУ. Но в играх, на монеру GTA 5 некоторые данные всё равно подгружаются из жесткого диска, так как игра размеров в 60 Gb не поместится в 4 Gb ОЗУ. И работа разработчика в том, чтоб сделать эту подгрузку незаметной. Но чаще игра (или большая её половина) просто перемещается из жесткого диска в оперативную память.
ЦП и Видеокарта
Итак, мы вытащили кучу информации. Но что дальше? Теперь процессор начинает думать по настоящему. Он начинает просчитывать геометрию объектов.
Об этом написано было в другой статье, ссылка будет в конце.
Процессор просчитал геометрию. Но она полностью бесцветная. В этот момент ЦП считывает информацию "какая текстура должна быть у какой геометрии и тут же отправляет эту всю информацию в видеокарту. Тут же видеокарта начинает рендеринг картинки.
Как устроена видеокарта
Мало кто знает, но видеокарта по своей структуре - это еще один маленький компьютер внутри вашего большего ПК. У видеокарты есть свой: 1) процессор и 2) Оперативная память.
Получивши текстуры, материал и геометрию видеокарта записывает их в свою оперативную память и начинает собирать этот "конструктор" на своем процессоре. После этого он выдает его на свой видеовыход и картинка уходит на ваш монитор.
На случай, если вы столь бедны что не имеете возможность купить видеокарту (или она просто сломалась), разработчики материнских плат часто добавляют "встроенную видеокарту".
Этой карты хватает чтоб смотреть видео и играть в старенькие или 2D игры, ведь размер выделенной ей оперативной памяти часто не превышает 64 мегабайт.
Терминология
Давайте в конце поговорим о сухих числах.
Частота работы процессора определяет как часто процессор обрабатывает информацию.
Ядра и потоки процессора определяет сколько информации процессор может обрабатывать паралельно.
Размер ОЗУ говорит сколько мегабайт памяти может содержать ваша оперативная память.
Частота ОЗУ говорит как быстро эта память может записываться\читаться процессором.
Выходит иногда так, что видеокарта на 2 Gb работает лучше чем видеокарта на 4Gb из-за того, что первая имеет большую частоту процессора или оперативной памяти.

Встроенные или интегрированные (iGPU) в современные процессоры видеокарты справляются со многими компьютерными играми. Для AAA-проектов на высоких настройках они не годятся, но кое что все же могут. Рассмотрим особенности работы встроенных графических ускорителей с памятью.
Сколько памяти у встроенной видеокарты
Интегрированные видеокарты не имеют собственной памяти. Ее черпают из оперативной памяти: в зависимости от настроек BIOS/UEFI или операционной системы, Windows резервирует определённый объём оперативной памяти, которая используется встроенным видеоускорителем в качестве видеопамяти (VRAM).
Обычно графика встраивается в центральный процессор, на некоторых ноутбуках распаивается на материнской плате. Во втором случае это самостоятельное, но несъемное устройство – псевдодискретная графика.
Установленный по умолчанию объем VRAM колеблется от 32 до 2048 МБ в зависимости от модели процессора или «материнки».
Как увеличить или уменьшить объем видеопамяти
Размер выделяемой операционной системой встроенной видеокарте памяти изменяется двумя способами:
- Автоматически или динамически – система выделяет такой объём ОЗУ, который на данный момент необходим графическому процессору для выполнения поставленных задач.
- Вручную – фиксированное значение, установленное на заводе или пользователем вручную.
Зачем изменять размер видеопамяти?
Объем видеопамяти увеличивается для повышения производительности интегрированного видеоядра, запуска приложений и игр, которым недостаточно выделенного по умолчанию объёма VRAM. Уменьшается, чтобы освободить приложениям и Windows больше ОЗУ, если текущие задачи задействуют почти всю оперативку. Отображается объем задействованной памяти во вкладке «Производительность» Диспетчера задач.
При изменении размера графической памяти важен баланс. Отданная для видеокарты ОЗУ резервируется операционной системой и не может использоваться ею либо приложениями. Если на компьютере установлено мало ОЗУ – 2-4 ГБ, смысл в выделении большого объема видеопамяти в ущерб оперативной есть не всегда.
Чем шустрее используется «оперативка», тем выше производительность встроенного видеоядра. При одинаковой конфигурации компьютера ПК с DDR4-3200 выдаст больше кадров в секунду, чем с DDR3-2400. Многое зависит и от самих модулей, задач, метода тестирования.
Положительно на быстродействии графики сказывается разгон оперативки, но прирост FPS не превышает нескольких процентов.
Где посмотреть объем
Увидеть, сколько памяти выделено интегрированному графическому ядру, можно несколькими способами.
Параметры Windows 10
Или вместо этого выполните «ms-settings:easeofaccess-display» в окне Win + R.
Диспетчер задач
Первая цифра – занятая память, вторая – выделенная.
Также процент задействования VRAM отображают сторонние утилиты, например, HWiNFO.
Изменить через BIOS
Расширяется и урезается графическая память в настройках BIOS/UEFI.
Посетите BIOS Setup вашего компьютера. Чаще всего после перезагрузки ПК в момент отображения заставки нужно нажать Delete или F2 (смотрите инструкцию по эксплуатации материнской платы или ноутбука). В Windows 10 для этого отключается «Быстрый запуск».
Дальнейшие действия могут отличаются для различных производителей BIOS/UEFI, но в целом они похожи. Рассмотрим на примере материнки от MSI.
В разделе «Mainboard settings» посетите подраздел «Конфигурация встроенной графики».
Откройте окно выбора параметров «Разделение памяти встроенной графики».
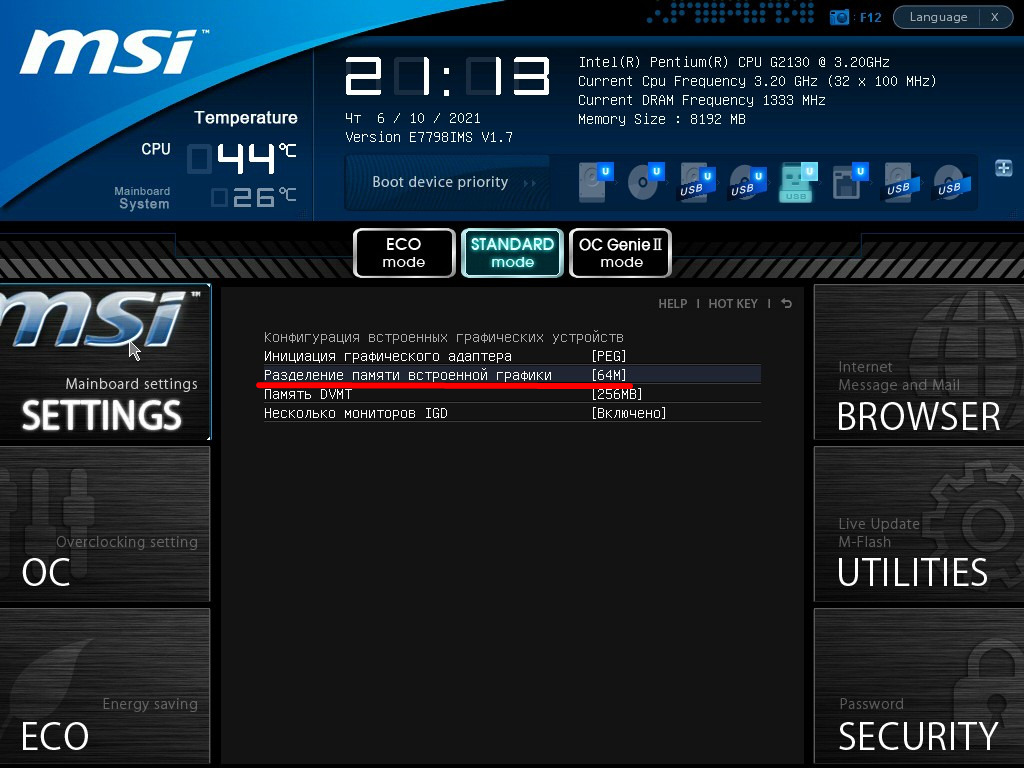
Укажите нужный объём, после чего нажмите F10 для выхода с сохранением настроек.
Также в списке находится параметр «Память DVMT» или Dynamic Video Memory Technology – технология динамического выделения памяти. При включении опции видеокарте выделяется столько видеопамяти, сколько она требует в зависимости от нагрузки, при отключении – весь указанный объем резервируется постоянно.
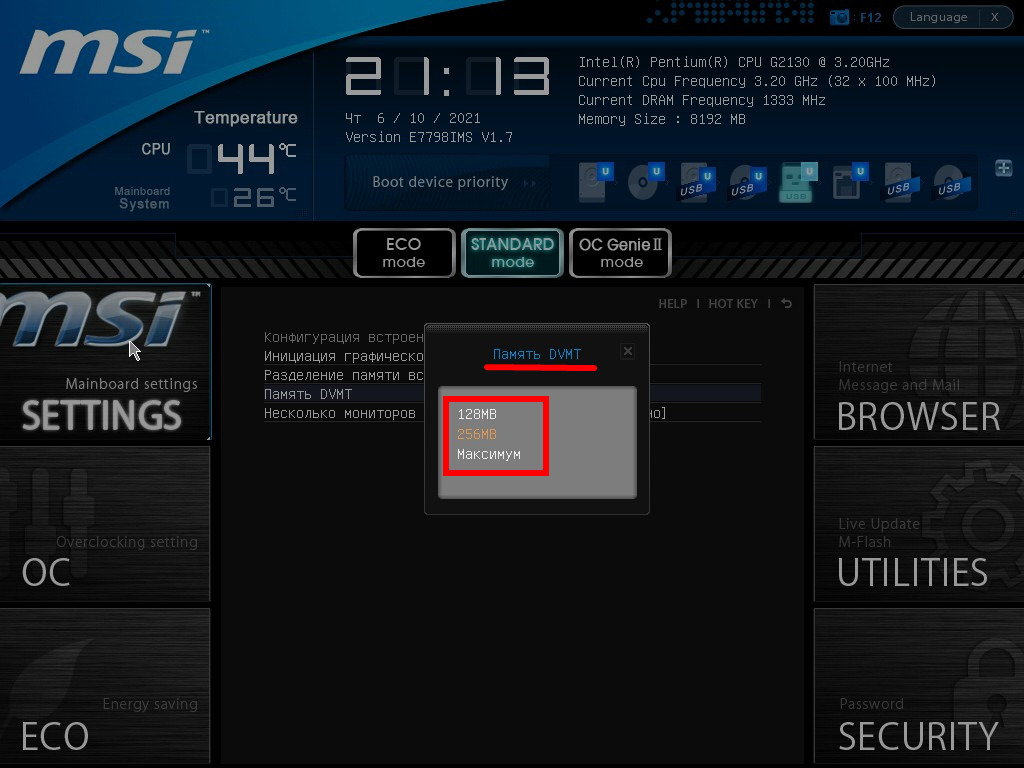
В настройках можно указать максимальный размер ОЗУ, отдаваемый под VRAM.
Параметр может называться «Graphics Adapter Size», «UMA Frame Buffer Size», «Shade Memory», «Video Memory Size» и им подобные, находиться в разделах «Chipset», «Advanced Mode», «Chipset Configuration», «Advanced».
Иногда при включении DVMT память видеокарте выделяется, но приложения её не видят и, соответственно, не запускаются. Выдают ошибку, что объём выделяемой для графики памяти меньше минимальных системных требований игры или программы.
Реестр
Изменяется значение и через реестр. Такой прием удобно использовать если игра не запускается с ошибкой о нехватки видеопамяти.
Вызовите редактор реестра: зажмите Win + R, выполните «regedit».

В ветке «HKLM\Software\Intel» создайте подраздел «GMM».

В него добавьте «Параметр «DWORD (32 бита)».

Назовите его «DedicatedSegmentSize»: через правый клик вызовите «Переименовать» и введите название.
Два раза щелкните по записи левой клавишей, переключите систему счисления на десятичную.

Введите значение, например, «1024» и жмите «ОК», после чего перезагрузите компьютер.
Сколько ставить
Рекомендуется выделять максимально возможный объём памяти для графического ускорителя при условии, что на компьютере достаточно для решения поставленных задач ОЗУ. Если ее мало, стоит активировать опцию DVMT и выставить наибольшее значение. Система автоматически будет выделять оперативку под нужды видеокарты и «забирать» ее, когда потребность во VRAM снижается.
Влияние характеристик оперативной памяти на производительность iGPU
Скорость оперативной памяти оказывает влияние на быстродействие компьютера в играх, частоту кадров. При замене планок с частотой памяти 1866 Гц на 2400 Гц стремительного роста производительности ждать не стоит. Прирост FPS будет незначительным – до нескольких кадров или процентов в секунду. Всё зависит от конфигурации оборудования и самой игры.
Стоит ли заменить оперативку на более быструю, чтобы увеличить FPS в играх?
Как правило такая замена добавляет всего несколько процентов прироста. Если можете достать память задешево можете обновить, иначе я бы не стал заморачиваться.
Читайте также: