
В csv файле меньше колонок чем ожидается найдено 5 колонок ожидается 9
Я пытаюсь использовать панды для манипулирования .CSV-файл, но я получаю эту ошибку:
панды.синтаксический анализатор.CParserError: ошибка маркирования данных. C ошибка: ожидается 2 поля в строке 3, увидел 12
Я попытался прочитать документы панды, но ничего не нашел.
мой код очень простой:
Как я могу решить это? Я должен использовать csv модуль или другой язык ?
- разделители в
- первая строка, как отметил @TomAugspurger
синтаксический анализатор запутывается в заголовке файла. Он читает первую строку и выводит количество столбцов из этой строки. Но первые две строки не являются репрезентативными для фактических данных в файле.
попробуйте data = pd.read_csv(path, skiprows=2)
CSV-файл может иметь переменное количество столбцов и read_csv выведено количество столбцов из первых нескольких строк. Два способа решить ее в этом случае:
1) измените файл CSV на фиктивную первую строку с максимальным количеством столбцов (и укажите header=[0] )
2) или использовать names = list(range(0,N)) где N-максимальное количество столбцов.
это, безусловно, вопрос разделителя, так как большинство csv CSV получают создать с помощью sep='/t' так попробуй read_csv используя символ табуляции (\t) С помощью разделителя /t . Итак, попробуйте открыть с помощью следующей строки кода.
У меня была эта проблема несколько раз. Почти каждый раз, причина в том, что файл, который я пытался открыть, не был правильно сохранен CSV для начала. И под "правильно" я имею в виду, что каждая строка имела одинаковое количество разделителей или столбцов.
обычно это происходило потому, что я открыл CSV в Excel, а затем неправильно сохранил его. Несмотря на то, что расширение файла все еще было .csv, чистый формат CSV был изменен.
любой файл, сохраненный с pandas to_csv будет правильно отформатирован и не должен иметь этой проблемы. Но если вы откроете его с другой программой, это может изменить структуру.
надеюсь, что это поможет.
я столкнулся с той же проблемой. Используя pd.read_table() на том же исходном файле, казалось, работали. Я не мог проследить причину этого, но это было полезным обходным путем для моего случая. Возможно, кто-то более знающий может пролить свет на то, почему это сработало.
изменить: Я обнаружил, что эта ошибка ползет вверх, когда у вас есть какой-то текст в файле, который не имеет того же формата, что и фактические данные. Обычно это информация верхнего или нижнего колонтитула (больше одной строки, поэтому skip_header не работает) который не будет разделен тем же количеством запятых, что и ваши фактические данные (при использовании read_csv). Использование read_table использует вкладку в качестве разделителя, который может обойти текущую ошибку пользователей, но ввести другие.
обычно я обхожу это, читая дополнительные данные в файл, а затем использую метод read_csv ().
точное решение может отличаться в зависимости от вашего фактического файла, но этот подход работал для меня в нескольких случаях
у меня была аналогичная проблема при попытке прочитать таблицу с разделителями табуляции с пробелами, запятыми и кавычками:
Это говорит, что это имеет какое-то отношение к C parsing engine (который является стандартным). Может быть, переход на python один изменит что-нибудь
теперь это другая ошибка.
Если мы продолжим и попытаемся удалить пробелы из таблицы, ошибка из python-engine снова изменится:и это становится ясно что у панд были проблемы с разбором наших строк. Чтобы разобрать таблицу с движком python, мне нужно было удалить все пробелы и кавычки из таблицы заранее. Тем временем C-engine продолжал рушиться даже с запятыми в строках.
Чтобы избежать создания нового файла с заменами я сделал это, так как мои таблицы малы:
tl; dr
Измените механизм синтаксического анализа, старайтесь избегать любых не разделяющих кавычек / запятых / пробелов в ваших данных.
хотя это не относится к этому вопросу, эта ошибка также может появиться со сжатыми данными. Явно устанавливая значение для kwarg compression решена моя проблема.
альтернатива, которую я нашел полезной при работе с подобными ошибками синтаксического анализа, использует модуль CSV для перенаправления данных в pandas df. Например:
Я считаю, что модуль CSV немного более надежен для плохо отформатированных файлов, разделенных запятыми, и поэтому имел успех с этим маршрутом для решения таких проблем.
У меня был набор данных с предварительными номерами строк, я использовал index_col:
следующая последовательность команд работает (я теряю первую строку данных-нет заголовка=нет настоящего -, но по крайней мере он загружается):
df = pd.read_csv(filename, usecols=range(0, 42)) df.columns = ['YR', 'MO', 'DAY', 'HR', 'MIN', 'SEC', 'HUND', 'ERROR', 'RECTYPE', 'LANE', 'SPEED', 'CLASS', 'LENGTH', 'GVW', 'ESAL', 'W1', 'S1', 'W2', 'S2', 'W3', 'S3', 'W4', 'S4', 'W5', 'S5', 'W6', 'S6', 'W7', 'S7', 'W8', 'S8', 'W9', 'S9', 'W10', 'S10', 'W11', 'S11', 'W12', 'S12', 'W13', 'S13', 'W14']
следующее не работает:
df = pd.read_csv(filename, names=['YR', 'MO', 'DAY', 'HR', 'MIN', 'SEC', 'HUND', 'ERROR', 'RECTYPE', 'LANE', 'SPEED', 'CLASS', 'LENGTH', 'GVW', 'ESAL', 'W1', 'S1', 'W2', 'S2', 'W3', 'S3', 'W4', 'S4', 'W5', 'S5', 'W6', 'S6', 'W7', 'S7', 'W8', 'S8', 'W9', 'S9', 'W10', 'S10', 'W11', 'S11', 'W12', 'S12', 'W13', 'S13', 'W14'], usecols=range(0, 42))
CParserError: ошибка маркирования данных. C ошибка: ожидается 53 поля в строке 1605634, увидел 54 Следующее не работает:
df = pd.read_csv(filename, header=None)
CParserError: ошибка маркирования данных. C ошибка: ожидается 53 поля в строке 1605634, saw 54
следовательно, в вашей проблеме вы должны пройти usecols=range(0, 2)
У меня была аналогичная ошибка, и проблема заключалась в том, что у меня были некоторые экранированные кавычки в моем csv-файле и нужно было установить параметр escapechar соответствующим образом.
Вы можете сделать этот шаг, чтобы избежать проблемы -
просто добавить - header=None
надеюсь, что это помогает!!
CSV является стандартом де-факто для связи между собой разнородных систем, для передачи и обработки объемных данных с «жесткой», табличной структурой. Во многих скриптовых языках программирования есть встроенные средства разбора и генерации, он хорошо понятен как программистам, так и рядовым пользователям, а проблемы с самими данными в нем хорошо обнаруживаются, как говорится, на глаз.
История этого формата насчитывает не менее 30 лет. Но даже сейчас, в эпоху повального использования XML, для выгрузки и загрузки больших объемов данных по-прежнему используют CSV. И, несмотря на то, что сам формат довольно неплохо описан в RFC, каждый его понимает по-своему.
В этой статье я попробую обобщить существующие знания об этом формате, указать на типичные ошибки, а также проиллюстрировать описанные проблемы на примере кривой реализации импорта-экспорта в Microsoft Office 2007. Также покажу, как обходить эти проблемы (в т.ч. автоматическое преобразование типов Excel-ом в DATETIME и NUMBER) при открытии .csv.
Начнем с того, что форматом CSV на самом деле называют три разных текстовых формата, отличающихся символами-разделителями: собственно сам CSV (comma-separated values — значения, разделенные запятыми), TSV (tab-separated values — значения, разделенные табуляциями) и SCSV (semicolon separated values — значения, разделенные точкой с запятой). В жизни все три могут называться одним CSV, символ-разделитель в лучшем случае выбирается при экспорте или импорте, а чаще его просто «зашивают» внутрь кода. Это создает массу проблем в попытке разобраться.
Как иллюстрацию возьмем казалось бы тривиальную задачу: импортировать в Microsoft Outlook данные из таблицы в Microsoft Excel.
В Microsoft Excel есть средства экспорта в CSV, а в Microsoft Outlook — соответствующие средства импорта. Что могло быть проще — сделал файлик, «скормил» почтовой программе и — дело сделано? Как бы не так.
Создадим в Excel тестовую табличку:

… и попробуем экспортировать ее в три текстовых формата:
| «Текст Unicode» | Кодировка — UTF-16, разделители — табуляция, переводы строк — 0×0D, 0×0A, объем файла — 222 байт |
| «CSV (разделители — запятые)» | Кодировка — Windows-1251, разделители — точка с запятой (не запятая!), во второй строке значение телефонов не взято в кавычки, несмотря на запятую, зато взято в кавычки значение «01;02», что правильно. Переводы строк — 0×0D, 0×0A. Объем файла — 110 байт |
| «Текстовые файлы (с разделителями табуляции)» | Кодировка — Windows-1251, разделители — табуляция, переводы строк — 0×0D, 0×0A. Значение «01;02» помещено в кавычки (без особой нужды). Объем файла — 110 байт |
Какой вывод мы делаем из этого. То, что здесь Microsoft называет «CSV (разделители — запятые)», на самом деле является форматом с разделителями «точка с запятой». Формат у Microsoft — строго Windows-1251. Поэтому, если у вас в Excel есть Unicode-символы, они на выходе в CSV отобразятся в вопросительные знаки. Также то, что переводами строк является всегда пара символов, то, что Microsoft тупо берет в кавычки все, где видит точку с запятой. Также то, что если у вас нет Unicode-символов вообще, то можно сэкономить на объеме файла. Также то, что Unicode поддерживается только UTF-16, а не UTF-8, что было бы сильно логичнее.
Теперь посмотрим, как на это смотрит Outlook. Попробуем импортировать эти файлы из него, указав такие же источники данных. Outlook 2007: Файл -> Импорт и экспорт… -> Импорт из другой программы или файла. Далее выбираем формат данных: «Значения, разделенные запятыми (Windows)» и «Значения, разделенные табуляцией (Windows)».
| «Значения, разделенные табуляцией(Windows)» | Скармливаем аутлуку файл tsv, с разделенными табуляцией значениями и. — чтобы вы думали. Outlook склеивает поля и табуляцию не замечает. Заменяем в файле табуляцию на запятые и, как видим, поля уже разбирает, молодец. |
| «Значения, разделенные запятыми (Windows)» | А вот аутлук как раз понимает все верно. Comma — это запятая. Поэтому ожидает в качестве разделителя запятую. А у нас после экселя — точка с запятой. В итоге аутлук распознает все неверно. |
Два майкрософтовских продукта не понимают друг друга, у них напрочь отсутствует возможность передать через текстовый файл структурированные данные. Для того, чтобы все заработало, требуются «пляски с бубном» программиста.
Мы помним, что Microsoft Excel умеет работать с текстовыми файлами, импортировать данные из CSV, но в версии 2007 он делает это очень странно. Например, если просто открыть файл через меню, то он откроется без какого-либо распознавания формата, просто как текстовый файл, целиком помещенный в первую колонку. В случае, если сделать дабл-клик на CSV, Excel получает другую команду и импортирует CSV как надо, не задавая лишних вопросов. Третий вариант — вставка файла на текущий лист. В этом интерфейсе можно настраивать разделители, сразу же смотреть, что получилось. Но одно но: работает это плохо. Например, Excel при этом не понимает закавыченных переводов строк внутри полей.
Более того, одна и та же функция сохранения в CSV, вызванная через интерфейс и через макрос, работает по-разному. Вариант с макросом не смотрит в региональные настройки вообще.
Стандарта CSV как такового, к сожалению, нет, но, между тем, существует т.н. memo. Это RFC 4180 года, в котором описано все довольно толково. За неимением ничего большего, правильно придерживаться хотя бы RFC. Но для совместимости с Excel следует учесть его собенности.
Вот краткая выжимка рекомендаций RFC 4180 и мои комментарии в квадратных скобках:
- между строками — перевод строки CRLF [на мой взгляд, им не стоило ограничивать двумя байтами, т.е. как CRLF (0×0D, 0×0A), так и CR 0×0D]
- разделители — запятые, в конце строки не должно быть запятой,
- в последней строке CRLF не обязателен,
- первая строка может быть строкой заголовка (никак не помечается при этом)
- пробелы, окружающие запятую-разделитель, игнорируются.
- если значение содержит в себе CRLF, CR, LF (символы-разделители строк), двойную кавычку или запятую (символ-разделитель полей), то заключение значения в кавычки обязательно. В противном случае — допустимо.
- т.е. допустимы переводы строк внутри поля. Но такие значения полей должны быть обязательно закавычены,
- если внутри закавыченной части встречаются двойные кавычки, то используется специфический квотинг кавычек в CSV — их дублирование.
Вот в нотации ABNF описание формата:
Также при реализации формата нужно помнить, что поскольку здесь нет указателей на число и тип колонок, поскольку нет требования обязательно размещать заголовок, здесь есть условности, о которых необходимо не забывать:
- строковое значение из цифр, не заключенное в кавычки может быть воспринято программой как числовое, из-за чего может быть потеряна информация, например, лидирующие нули,
- количество значений в каждой строке может отличаться и необходимо правильно обрабатывать эту ситуацию. В одних ситуациях нужно предупредить пользователя, в других — создавать дополнительные колонки и заполнять их пустыми значениями. Можно определиться, что количество колонок задается заголовком, а можно добавлять их динамически, по мере импорта CSV,
- Квотить кавычки через «слэш» не по стандарту, делать так не надо.
- Поскольку типизации полей нет, нет и требования к ним. Разделители целой и дробной частей в разных странах разные, и это приводит к тому, что один и тот же CSV, сгенрированный приложением, в одном экселе «понимается», в другом — нет. Потому что Microsoft Office ориентируется на региональные настройки Windows, а там может быть что угодно. В России там указано, что разделитель — запятая,
- Если CSV открывать не через меню «Данные», а напрямую, то Excel лишних вопросов не задает, и делает как ему кажется правильным. Например, поле со значением 1.24 он понимает по умолчанию как «24 января»
- Эксель убивает ведующие нули и приводит типы даже тогда, когда значение указано в кавычках. Делать так не надо, это ошибка. Но чтобы обойти эту проблему экселя, можно сделать небольшой «хак» — значение начать со знака «равно», после чего поставить в кавычках то, что необходимо передать без изменения формата.
- У экселя есть спецсимвол «равно», который в CSV рассматривается как идентификатор формулы. То есть, если в CSV встретится =2+3, он сложит два и три и результат впишет в ячейку. По стандарту он это делать не должен.
Пример валидного CSV, который можно использовать для тестов:
точно такой же SCSV:
Первый файлик, который реально COMMA-SEPARATED, будучи сохраненным в .csv, Excel-ом не воспринимается вообще.

Второй файлик, который по логике SCSV, экселом воспринимается и выходит вот что:

- Учлись пробелы, окружающие разделители
- Последний столбец вообще толком не распознался, несмотря на то, что данные в кавычках. Исключение составляет строка с «Петровым» — там корректно распозналось 1,24.
- В поле индекс Excel «опустил» ведущие нули.
- в самом правом поле последней строки пробелы перед кавычками перестали указывать на спецсимвол
Если же воспользоваться функционалом импорта (Данные -> Из файла) и обозвать при импорте все поля текстовыми, то будет следующая картина:

С приведением типов сработало, но зато теперь не обрабатываются нормально переводы строк и осталась проблема с ведущими нулями, кавычками и лишними пробелами. Да и пользователям так открывать CSV крайне неудобно.
Есть эффективный способ, как заставить Excel не приводить типы, когда это нам не нужно. Но это будет CSV «специально для Excel». Делается это помещением знака «=» перед кавычками везде, где потенциально может возникнуть проблема с типами. Заодно убираем лишние пробелы.
И вот что случаеся, если мы открываем этот файлик в экселе:
Постановка задачи
Бьюсь об заклад, что у 99% средних и крупных организаций в России инфраструктура построена на использовании Active Directory. Активный каталог замечательная вещь и легко интегрируется в различные сторонние сервисы. Самая частая задача администратора, это получение отчетов или выгрузок по определенным критериям, например:
- Получить список пользователей Active Directory с рядом атрибутов , чтобы в дальнейшем их вывести из эксплуатации
- Получить список всех компьютеров или пользователей, кто не авторизовывался какое-то время. И так до бесконечности
Получить данные вы можете в разном виде, например в виде выдачи на самом экране, или же в сохраненный файл в формате txt или csv. CSV более распространенный, так как позволяет не только выгружать данные, но и еще их импортировать. Вроде бы все удобно, но есть одно но, когда вы захотите красиво перенести такие данные из csv, txt или экрана, у вас не будет форматирования или столбцов, все будет смешано в кучу, а это не удобно. Ниже я вас научу это обходить.
Структура файла CSV
Файл с разделителями-запятыми (CSV) представляет собой простой текстовый файл, который содержит список данных. Эти файлы часто используются для обмена данными между различными приложениями. Например, базы данных и менеджеры контактов часто поддерживают файлы CSV.
Эти файлы иногда могут называться символьно-разделенными значениями или файлами с разделителями-запятыми. В основном они используют запятую для разделения данных, но иногда используют другие символы, такие как точки с запятой. Идея состоит в том, что вы можете экспортировать сложные данные из одного приложения в файл CSV, а затем импортировать данные из этого файла CSV в другое приложение.
Вот пример такого строки с разделителями:
"Name","OperatingSystem","LastLogonDate","Modified","Enabled" ,"Ping","DistinguishedName""DC01","Windows Server 2008 R2 Standard","02.11.2018 6:14:02", "21.12.2018 15:56:16","Torge","False","CN=DC01, OU=ComputerStore,OU=root,DC=pyatilistnik,DC=org"
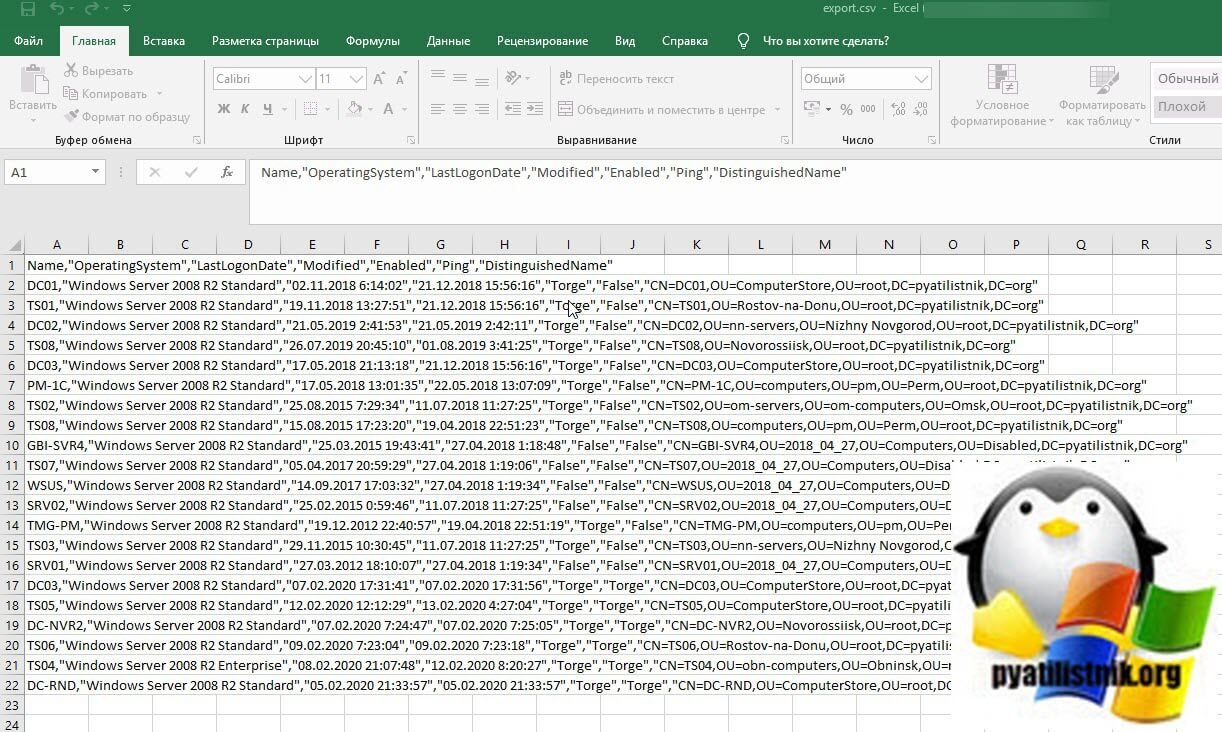
теперь представьте, что таких строк сотни или тысячи, а вы хотите все скопировать в ваш Exсel и по столбцам, вот тут вы и поймете, что одностроковый формат требует преобразования. Благо, это делается очень быстро и просто. Вот пример моего тестового csv файла.
Как csv разделить по столбцам в Excel
Первым инструментом, который позволит из csv получить красивые столбцы и разбиение по ним, будет Excel. Откройте в Excel ваш файл csv.
- Выделите первый столбец и перейдите на вкладку "Данные"
- Найдите пункт "Текст по столбцам"
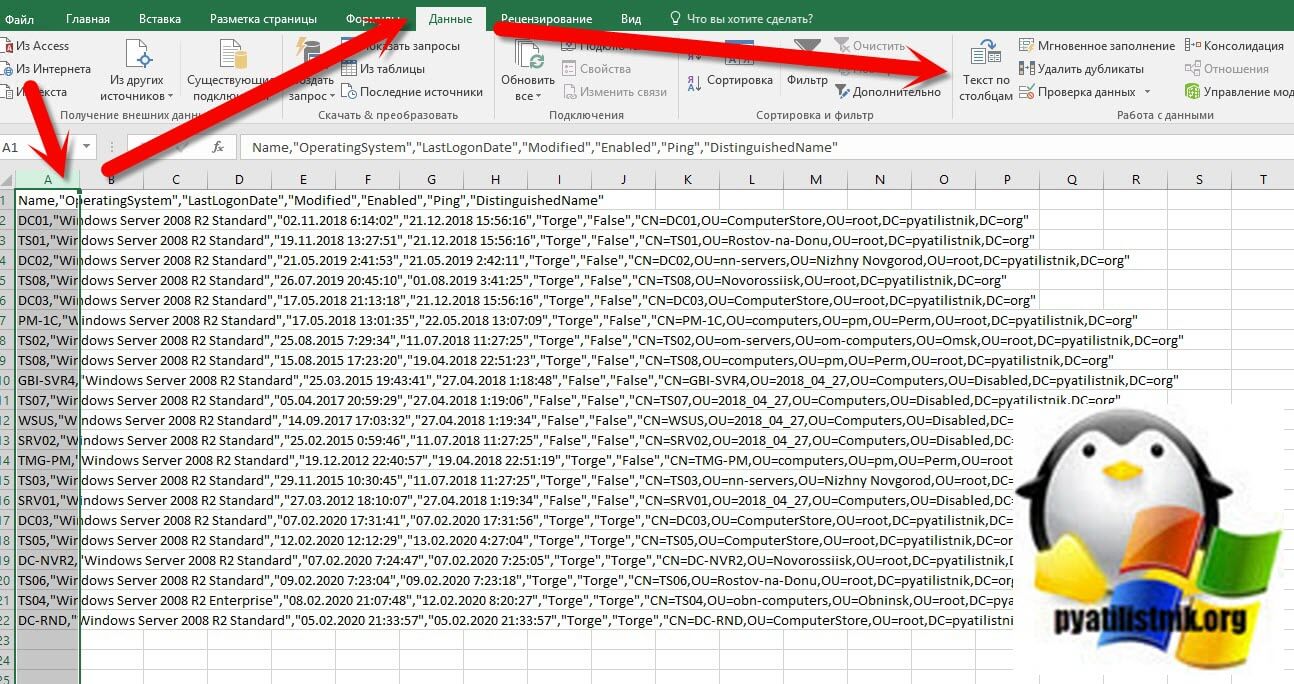
На первом окне мастера распределения текста по столбцам нажмите "Далее".
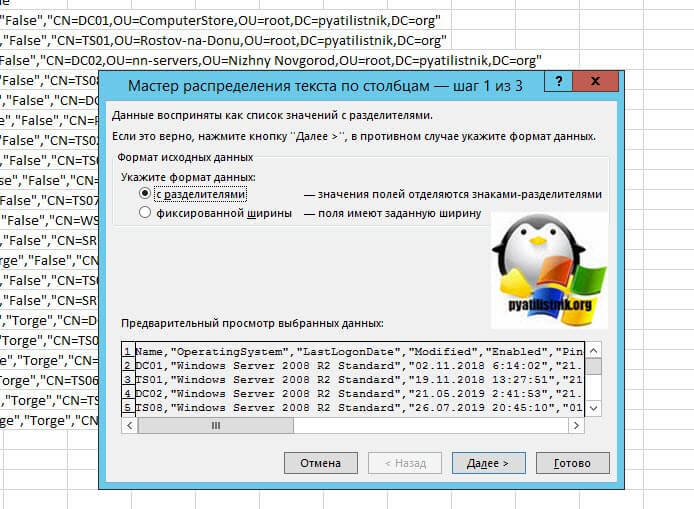
Далее вам необходимо указать по каким критериям производить разбивку по столбцам, на выбор у вас будет:
- Знак табуляции
- Точка с запятой
- Запятая
- Пробел
- Другой вариант
В моем примере CSV разделяет отдельные данные с помощью запятой. Тут же вы сразу видите, как это будет выглядеть в области "Образец разбора данных".
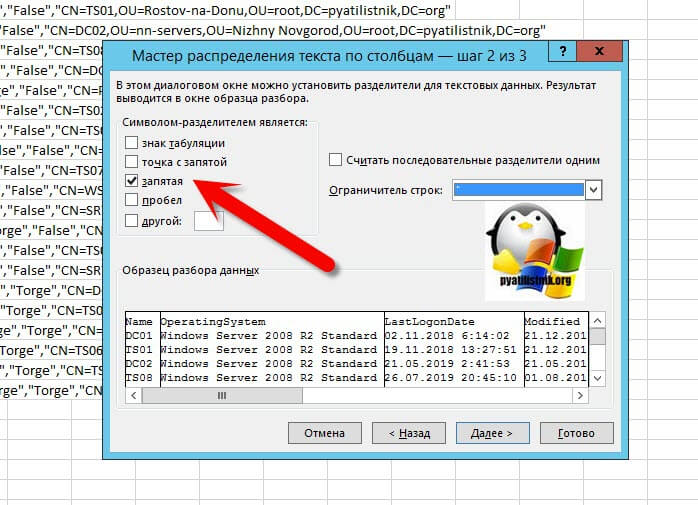
Далее при необходимости вы можете указать формат (Общий, текстовый, дата) и диапазон к которому будет применяться ваше преобразование. Нажимаем "Готово".
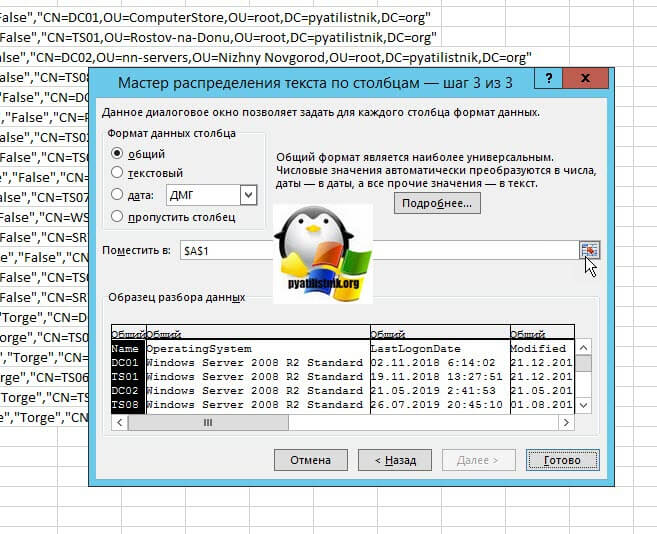
На выходе я получил красивую таблицу, где есть разбивка по столбца. В таком виде мне уже удобнее оперировать данными.
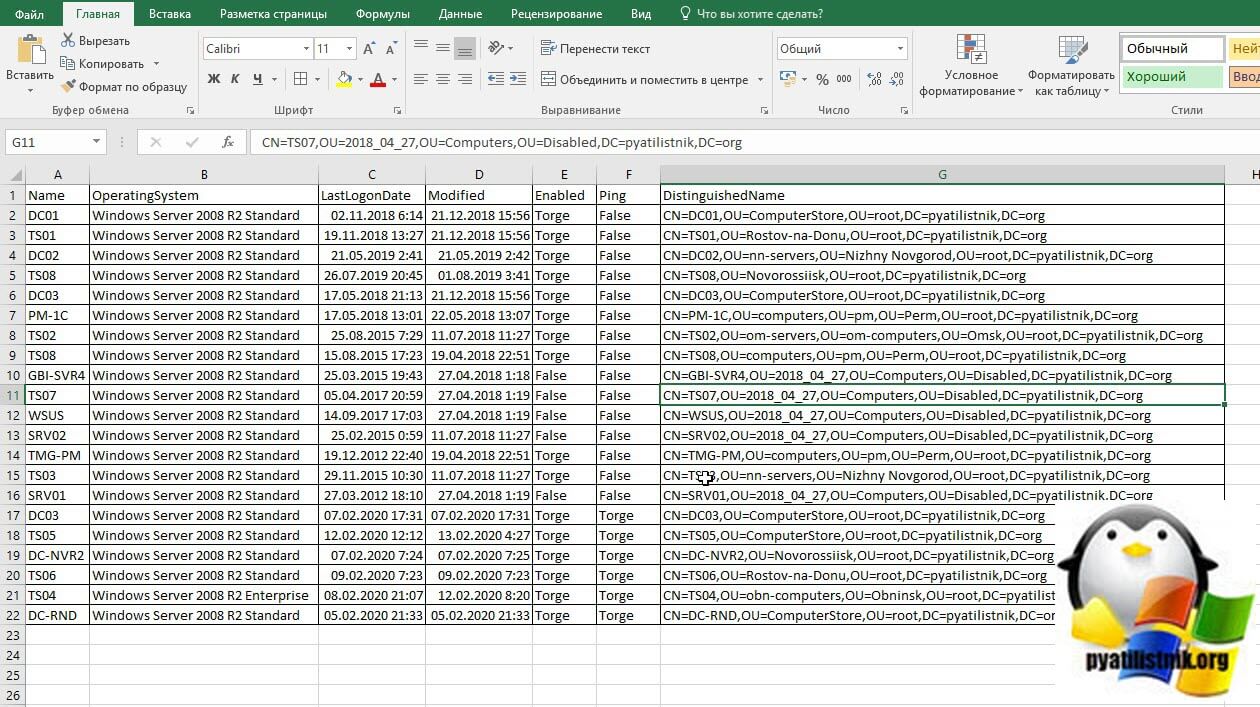
Далее вам остается сохранить файл в формате xlsx и радуемся жизни.
Как csv разделить по столбцам через Google Таблицы
Не так давно я вам рассказывал про установку через групповую политику расширения для Google Chrome под названием "Редактирование файлов Office". Это расширение позволяло работать с файлами Word, Excel и PowerPoint в Google Документах, Google Таблицах и Google Презентациях. Если вы через него откроете ваш файл CSV, то вы буквально в два клика сможете его разбить на столбцы. Для этого выберите меню "Файл - Сохранить в формате Google Таблиц".
Начнется переделывание формата CSV в формат Google Таблиц
На выходе вы получаете разделенный по столбцам документ.
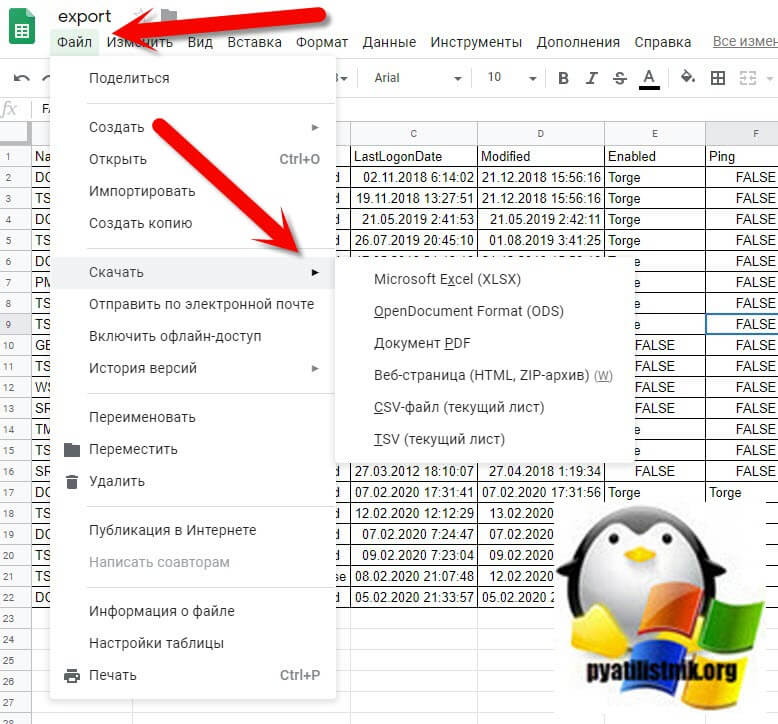
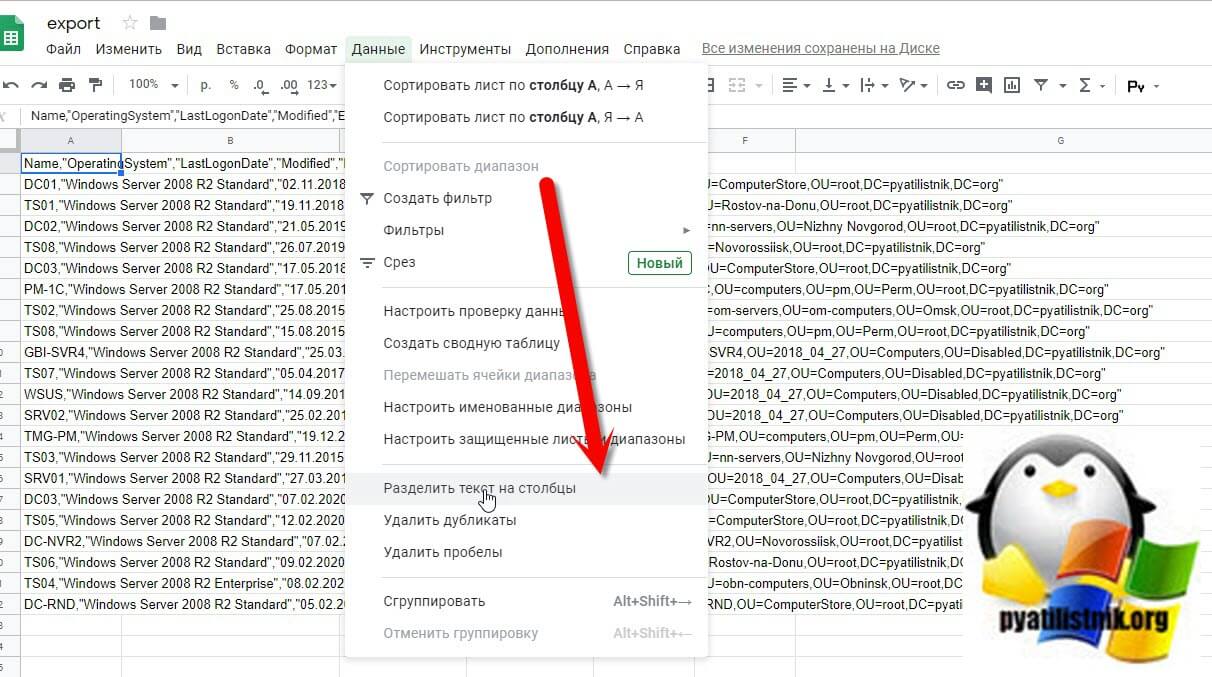
Далее вы уже можете оперировать этими данными или же можете их сохранить в нужный формат. Если у вас изначально документ Google Таблиц содержит данные разделенные запятой в виде одной строки, то вы их можете преобразовать в столбцы вот таким методом. Открываете меню "Данные - Разделить текст на столбцы"
Выбираете тип разделения, в моем случае запятая.
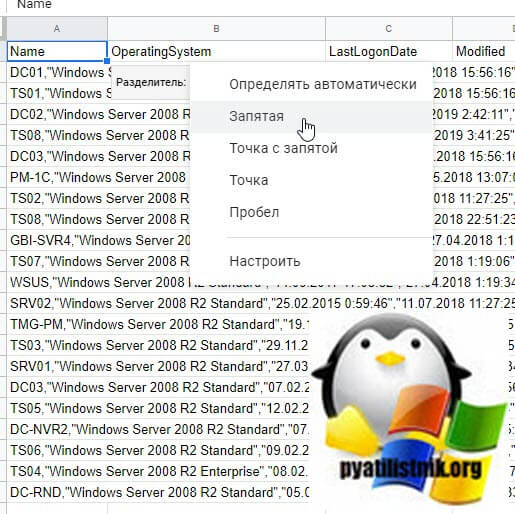
Затем выбираете ваш столбец с данным и еще раз нажмите "Данные - Разделить текст на столбцы"
Читайте также: