
В чем отличие индексно прямых файлов от индексно последовательных файлов
Индексирование в базах данных
Индекс в базе данных аналогичен предметному указателю в книге. Это — вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они могут существенным образом повысить ее производительность. Как и в случае с предметным указателем книги, читатель может найти определение интересующего его понятия, просмотрев всю книгу, но это потребует слишком много времени. А предметный указатель, ключевые слова в котором расположены в алфавитном порядке, позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, — индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
Первичный индекс - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи. Индекс кластеризации - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации. Вторичный индекс - это индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей.
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом. Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основу поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
- первичная область хранения;
- отдельный индекс или несколько индексов;
- область переполнения.
Обычно большая часть первичного индекса может храниться в оперативной памяти, что позволяет обрабатывать его намного быстрее. Для ускорения поиска могут применяться специальные методы доступа, например метод бинарного поиска. Основным недостатком использования первичного индекса (как и при работе с любым другим отсортированным файлом) является необходимость соблюдения последовательности сортировки при вставке и удалении записей. Эти проблемы усложняются тем, что требуется поддерживать порядок сортировки как в файле данных, так и в индексном файле. В подобном случае может использоваться метод, заключающийся в применении области переполнения и цепочки связанных указателей, аналогично методу, используемому для разрешения конфликтов в хэшированных файлах.
Вторичные индексы
Вторичный индекс также является упорядоченным файлом, аналогичным первичному индексу. Однако связанный с первичным индексом файл данных всегда отсортирован по ключу этого индекса, тогда как файл данных, связанный со вторичным индексом, не обязательно должен быть отсортирован по ключу индексации. Кроме того, ключ вторичного индекса может содержать повторяющиеся значения, что не допускается для значений ключа первичного индекса. Для работы с такими повторяющимися значениями ключа вторичного индекса обычно используются перечисленные ниже методы.
- Создание плотного вторичного индекса, который соответствует всем записям файла данных, но при этом в нем допускается наличие дубликатов.
- Создание вторичного индекса со значениями для всех уникальных значений ключа. При этом указатели блоков являются многозначными, поскольку каждое его значение соответствует одному из дубликатов ключа в файле данных.
- Создание вторичного индекса со значениями для всех уникальных значений ключа. Но при этом указатели блоков указывают не на файл данных, а на сегмент, который содержит указатели на соответствующие записи файла данных.
Вторичные индексы повышают производительность обработки запросов, в которых для поиска используются атрибуты, отличные от атрибута первичного ключа. Однако такое повышение производительности запросов требует дополнительной обработки, связанной с сопровождением индексов при обновлении информации в базе данных. Эта задача решается на этапе физического проектирования базы данных.
Многоуровневые индексы
При возрастании размера индексного файла и расширении его содержимого на большое количество страниц время поиска нужного индекса также значительно возрастает. Обратившись к многоуровневому индексу, можно попробовать решить эту проблему путем сокращения диапазона поиска. Данная операция выполняется над индексом аналогично тому, как это делается в случае файлов другого типа, т.е. посредством расщепления индекса на несколько субиндексов меньшего размера и создания индекса для этих субиндексов. На каждой странице файла данных могут храниться две записи. Кроме того, в качестве иллюстрации здесь показано, что на каждой странице индекса также хранятся две индексные записи, но на практике на каждой такой странице может храниться намного больше индексных записей. Каждая индексная запись содержит значение ключа доступа и адрес страницы. Хранимое значение ключа доступа является наибольшим на адресуемой странице.
Усовершенствованные сбалансированные древовидные индексы
Дерево - это структура данных, используемая во многих СУБД для хранения данных или индексов. Дерево состоит из иерархии узлов (node), в которой каждый узел, за исключением корня (root), имеет родительский (parent) узел, а также один, несколько или ни одного дочернего (child) узла. Корень не имеет родительского узла. Узел, который не имеет дочерних узлов, называется листом (leaf). Глубина дерева - это максимальное количество уровней между корнем и листом. Глубина дерева может быть различной для разных путей доступа к листам. Сбалансированное дерево, В-дерево, В-Тгее - это дерево, у которого глубина дерева одинакова для всех листов. Степень (degree), порядок (order) дерева - это максимально допустимое количество дочерних узлов для каждого родительского узла. Большие степени обычно используются для создания более широких и менее глубоких деревьев.Поскольку время доступа в древовидной структуре зависит от глубины, а не от ширины, обычно принято использовать более "разветвленные" и менее глубокие деревья.
Бинарное дерево, binary tree - это дерево порядка 2, в котором каждый узел имеет не больше двух дочерних узлов.Усовершенствованные сбалансированные древовидные индексы определяются по следующим правилам.
При этой стратегии файловое пространство не разделяется на области, но для каждой записи добавляется 2 указателя: указатель на предыдущую запись в цепочке синонимов и указатель на следующую запись в цепочке синонимов. Отсутствие соответствующей ссылки обозначается специальным символом, например нулем. Для каждой новой записи вычисляется значение хэш-функции, и если данный адрес свободен, то запись попадает на заданное место и становится первой в цепочке синонимов. Если адрес, соответствующий полученному значению хэш-функции, занят, то по наличию ссылок определяется, является ли запись, расположенная по указанному адресу, первой в цепочке синонимов. Если да, то новая запись располагается на первом свободном месте и для нее устанавливаются соответствующие ссылки: она становится второй в цепочке синонимов, на нее ссылается первая запись, а она ссылается на следующую, если таковая есть.
Если запись, которая занимает требуемое место, не является первой записью в цепочке синонимов, значит, она занимает данное место "незаконно" и при появлении "законного владельца" должна быть "выселена", то есть перемещена на новое место. Механизм перемещения аналогичен занесению новой записи, которая уже имеет синоним, занесенный в файл. Для этой записи ищется первое свободное место и корректируются соответствующие ссылки: в записи, которая является предыдущей в цепочке синонимов для перемещаемой записи, заносится указатель на новое место перемещаемой записи, указатели же в самой перемещаемой записи остаются прежние.
После перемещения "незаконной" записи вновь вносимая запись занимает свое законное место и становится первой записью в новой цепочке синонимов.
Механизмы удаления записей во многом аналогичны механизмам удаления в стратегии с областью переполнения. Однако еще раз кратко опишем их.
Если удаляемая запись является первой записью в цепочке синонимов, то после удаления на ее место перемещается следующая (вторая) запись из цепочки синонимов и проводится соответствующая корректировка указателя третьей записи в цепочке синонимов, если таковая существует.
Если же удаляется запись, которая находится в середине цепочки синонимов, то производится только корректировка указателей: в предшествующей записи указатель на удаляемую запись заменяется указателем на следующую за удаляемой запись, а в записи, следующей за удаляемой, указатель на предыдущую запись заменяется на указатель на запись, предшествующую удаляемой.
Вопросы для самостоятельной работы
- Сравнить обе стратегии и определить, какая из них будет наиболее перспективной и в каких случаях.
- Разработать алгоритмы удаления записей для первой и второй стратегий. Показать, как определяются ссылки.
Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также и файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной
интерпретацией, то сумеете разобраться в сути, несмотря на некоторую путаницу в терминологии. Наверное, это отчасти связано с тем, что область баз данных является достаточно молодой областью знаний, и несмотря на то, что здесь уже выработалась определенная терминология, многие поставщики коммерческих СУБД предпочитают свой упрощенный сленг при описании собственных продуктов. Иногда это связано с тем, что в целях рекламы они не хотят ссылаться на старые, хорошо известные модели и методы организации информации в системе, а изобретают новые названия при описании своих моделей, тем самым пытаясь разрекламировать эффективность своих продуктов. Хорошее знание принципов организации данных поможет вам объективно оценивать решения, предлагаемые поставщиками современных СУБД , и не попадаться на рекламные крючки.
Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл , а основная область образует файл , для которого создается индекс . Но нам удобнее рассматривать эти две части совместно, так как именно взаимодействие этих частей и определяет использование механизма индексации для ускорения доступа к записям.
Мы предполагаем, что сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом.Эти файлы имеют еще дополнительные названия, которые напрямую связаны c методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также индексно-последовательными файлами. Смысл этих названий нам будет ясен после того, как мы более подробно рассмотрим механизмы организации данных файлов.
Файлы с плотным индексом, или индексно-прямые файлы
Рассмотрим файлы с плотным индексом.В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в них имеет следующий вид:
Здесь значение ключа — это значение первичного ключа, а номер записи — это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой
записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
Длина доступа к произвольной записи оценивается не в абсолютных значениях, а в количестве обращений к устройству внешней памяти , которым обычно является диск. Именно обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в оперативной памяти.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является логарифмический, или бинарный, поиск . Очень хорошо изложил этот алгоритм барон Мюнхгаузен, когда он объяснял, как поймать льва в пустыне. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то определяется сначала, не является ли элемент искомым, а если нет, то в какой половине его надо искать. Следующим шагом мы определенную половину также делим пополам и производим аналогичные сравнения, и т. д., пока не обнаружим искомый элемент. Максимальное количество шагов поиска определяется двоичным логарифмом от общего числа элементов в искомом пространстве поиска:
где N — число элементов.
Однако в нашем случае является существенным только число обращений к диску при поиске записи по заданному значению первичного ключа. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а потом путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи.
На диске записи файлов хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и операционной системой. В одном блоке могут размещаться несколько записей. Поэтому нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от заданного числа блоков плюс единица. Зачем нужна единица? После поиска номера записи в индексной области мы должны еще обратиться к основной области файла. Поэтому формула для вычисления максимального времени доступа в количестве обращений к диску выглядит следующим образом:
Давайте рассмотрим конкретный пример и сравним время доступа при последовательном просмотре и при организации плотного индекса.
Допустим, что мы имеем следующие исходные данные:
Длина записи файла ( LZ ) — 128 байт. Длина первичного ключа ( LK ) — 12 байт. Количество записей в файле ( KZ ) — 100000. Размер блока ( LB ) — 1024 байт.
Рассчитаем размер индексной записи. Для представления целого числа в пределах 100000 нам потребуется 3 байта, можем считать, что у нас допустима только четная адресация, поэтому нам надо отвести 4 байта для хранения номера записи, тогда длина индексной записи будет равна сумме размера ключа и ссылки на номер записи, то есть:
LI = LK + 4 = I2 + 4 = 16 байт .
Определим количество индексных блоков, которое требуется для обеспечения ссылок на заданное количество записей. Для этого сначала определим, сколько индексных записей может храниться в одном блоке:
KIZB = LB/LI = 1024/16 = 64 индексных записи в одном блоке .
Теперь определим необходимое количество индексных блоков:
KIB = KZ/KZIB = 100000/64 = 1563 блока .
Мы округлили в большую сторону, потому что пространство выделяется целыми блоками, и последний блок у нас будет заполнен не полностью.
А теперь мы уже можем вычислить максимальное количество обращений к диску при поиске произвольной записи:
Tпоиска = log2KIB + 1 = log21563 + 1 = 11 + 1 = 12 обращений к диску .
Логарифм мы тоже округляем, так как считаем количество обращений, а оно должно быть целым числом.
Следовательно, для поиска произвольной записи по первичному ключу при организации плотного индекса потребуется не более 12 обращений к диску. А теперь оценим, какой выигрыш мы получаем, ведь организация индекса связана с дополнительными накладными расходами на его поддержку, поэтому такая организация может быть оправдана только в том случае, когда она действительно дает значительный выигрыш. Если бы мы не создавали индексное пространство, то при произвольном хранении записей в основной области нам бы в худшем случае было необходимо просмотреть все блоки, в которых хранится файл, временем просмотра записей внутри блока мы пренебрегаем, так как этот процесс происходит в оперативной памяти.
Количество блоков, которое необходимо для хранения всех 100 000 записей, мы определим по следующей формуле:
KBO = KZ/(LB/LZ) = 100000/(1024/128) = 12500 блоков .
И это означает, что максимальное время доступа равно 12500 обращений к диску. Да, действительно, выигрыш существенный.
Рассмотрим, как осуществляются операции добавления и удаления новых записей.
При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 9.7):
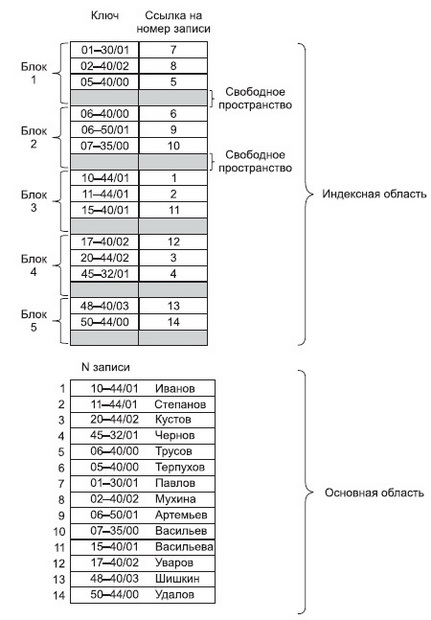
увеличить изображение
Рис. 9.7. Пример организации файла с плотным индексом
После определения блока, в который должен быть занесен индекс, этот блок копируется в оперативную память, там он модифицируется путем вставки в нужное место новой записи (благо в оперативной памяти это делается на несколько порядков быстрее, чем на диске) и, измененный, записывается обратно на диск.
Определим максимальное количество обращений к диску, которое требуется при добавлении записи, — это количество обращений, необходимое для поиска записи плюс одно обращение для занесения измененного индексного блока и плюс одно обращение для занесения записи в основную область.
T добавления = log2N + 1 + 1 + 1 .
Естественно, в процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи. Однако первый способ потребует дополнительного времени на перестройку индексной области, а второй увеличит время на доступ к произвольной записи и потребует организации дополнительных ссылок в блоках на область переполнения.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.
Индексно-последовательный файл организуется по принципу многоуровневого справочника. Индексно-последовательная организация представляет собой компромисс между последовательной и прямой организациями: при обеспечении возможности прямого доступа к записям сохраняется последовательная упорядоченность файла, что бывает крайне полезно для многих приложений. Каждая логическая запись индексно-последовательного файла должна содержать атрибут, являющийся ключом.
Прямой доступ к записям по ключу становится возможным только в том случае, когда устройство ВП обеспечивает необходимый тип доступа. ЗУ на МЛ является устройством с последовательным доступом. Оно непригодно для хранения индексно-последовательных файлов. Чаще всего для этих целей используют НМД, поэтому в дальнейшем предполагается, что файловые структуры размешены именно на этих устройствах.
Индексно-последовательный файл состоит из трех областей: основной, индексной и области переполнения.
Основная область служит для записи при его первоначальном создании. Логические записи записываются последовательно на дорожки цилиндра, начиная с первой в порядке возрастания значений ключа. Формат записей основной области приведен на рис. 8.1. Запись содержит поле ключа и поле данных. В поле ключа размещается ключ записи, в поле данных — сама запись.
Индексная область (область многоуровневого справочника) — вторая большая область индексно-последовательного файла. Она создается автоматически программами управления данными операционной системы. В индексной области размещаются служебные наборы данных — индексы. Обычно их два: индекс дорожек и индекс цилиндров.
Индекс дорожек - это нижний уровень индекса. Формат записей индекса дорожек приведен на рис. 8.2. Записи также состоят из двух полей. В поле данных запись индекса дорожек содержит адрес (номер) дорожки, с которой эта запись связана. В поле ключа содержится значение ключа последней записи на этой дорожке. Этот ключ самый большой на дорожке, так как записи в пределах ее упорядочены по возрастанию значений ключа. Количество записей в индексе дорожек равно числу дорожек цилиндра, занятого записями файла. Индекс дорожек размещается на нулевой дорожке цилиндра.
Рис. 8.1. Формат записи основной области Рис. 8.2.Формат записи индекса дорожек
индексно-последовательного файла индексно-последовательного файла
Индекс цилиндров указывает, как записи размещаются на нескольких цилиндрах. Каждая запись индекса цилиндров (рис. 8.3) в поле ключа содержит значение ключа последней записи цилиндра (это максимальный ключ цилиндра). В поле данных содержится адрес этого цилиндра. Количество записей в индексе цилиндров равно числу цилиндров дискового пакета, занятых хранимым файлом. Индекс цилиндров размещается на отдельном цилиндре.
Рис. 8.3. Формат записи индекса цилиндров индексно-последовательного файла
Пример, иллюстрирующий фрагмент структуры индексно-последовательного файла, размещенного на шестидисковом пакете, приведен на рис. 8.4. Файл занимает цилиндры с 51-го по 66-й. Максимальный ключ файла — 1385. Индекс цилиндра размещен на трех дорожках цилиндра 50. На рисунке приведены фрагменты файла, размещенные на двух цилиндрах, и указаны связи, устанавливаемые индексом цилиндров. Значения ключей отделены от адресов цилиндров и дорожек наклонной чертой.
Для обращения к записи с ключом 721 сначала последовательно просматриваются дорожки индекса цилиндров и находится запись с ключом, большим или равным заданному. Поле данных этой записи содержит номер цилиндра, на котором должна быть помещена запись с ключом 721 (если она вообще содержится в файле). Из рис. 8.4 видно, что соответствующая запись индекса цилиндров отсылает к цилиндру 58. Механизм доступа НМД устанавливается для чтения информации с этого цилиндра и осуществляется последовательный просмотр нулевой дорожки, на которой хранится индекс дорожек. В индексе дорожек находится запись, ключ которой больше или равен заданному ключу. Поле данных этой записи содержит адрес дорожки, на которой должна находиться запись с заданным ключом. Как следует из примера, запись с ключом 721 необходимо искать на восьмой дорожке цилиндра 58. Головки записи - воспроизведения механизма доступа переключаются на эту дорожку, и последовательным просмотром дорожки ищется нужная запись.
Время доступа к записям файла увеличивается с увеличением объема индекса цилиндров. Поэтому для очень больших файлов, занимающих много цилиндров, создается еще один, самый верхний, уровень индекса — главный индекс. В поле ключа записей главного индекса содержится максимальное значение ключа на соответствующей дорожке индекса цилиндров. Записи главного индекса обеспечивают прямой доступ к дорожкам индекса цилиндров. Связи, устанавливаемые главным индексом, указаны на рис. 8.4. Главный индекс, будучи запрошенным, находится в ОП в течение всего времени работы с файлом. Индексно-последовательная организация допускает как последовательный, так и прямой режим обработки файла.
Рис.8.4. Структура индексно-последовательного файла
Последовательная обработка индексно-последовательного файла логически идентична последовательной обработке последовательного файла. Записи обрабатываются в порядке, определяемом значениями ключа. Так как записи файла упорядочены по возрастанию значений ключа, то записи при последовательной обработке фактически читаются в том же порядке, в котором они были записаны в файл.
Несмотря на то, что в представлении пользователя последовательная обработка индексно-последовательного файла ничем не отличается от последовательной обработки последовательного файла, следует помнить, что доступ к записям для этих типов файлов существенно различен. Последовательный режим обработки индексно-последовательного файла имеет и свою особенность. Так, например, последовательно обрабатываться может не весь файл, а лишь его часть, начиная с указанной записи. Предварительный просмотр всех предшествующих записей при этом не нужен, так как к записи, с которой следует начать последовательную обработку, обеспечивается прямой доступ.
При произвольной обработке прикладные программы задают в любой последовательности ключи. Логические записи в заданной последовательности передаются на обработку.
В режиме корректировки решается проблема добавления и удаления записей файла. Проблема добавления записей решается созданием области (или областей) переполнения, как правило, на том же устройстве, на котором располагается файл. Возможны два типа областей переполнения: область переполнения цилиндра и независимая область переполнения.
Область переполнения цилиндра представляет собой несколько специально отведенных дорожек того же цилиндра, на котором содержатся дорожки основной области. Если новая запись в соответствии со значением ее ключа должна быть вставлена между уже существующими записями, то происходит следующее. По ключу новой записи с помощью индекса цилиндров и индекса дорожек ищется дорожка, на которой следует поместить новую запись. Эта запись размещается в нужном месте дорожки основной области, для чего все записи с большими ключами сдвигаются. При этом запись с самым большим значением ключа вытесняется с дорожки основной области и переносится в область переполнения цилиндра. Теперь эта дорожка основной области характеризуется другим значением ключа и в индекс дорожек необходимо внести соответствующие изменения.
Для часто обновляемых файлов индекс дорожек содержит обычно по две записи для каждой. Первая запись для дорожки основной области, вторая — для дорожки области переполнения. После первого создания файла эти записи идентичны. После корректировки файла в поле ключа второй записи заносятся максимальный ключ дорожки переполнения, а в поле данных помещается адрес этой дорожки и номер записи с минимальным значением ключа. Поле ключа первой записи корректируется.
Рис. 8.5. Размещение записей переполнения в индексно-последовательном файле
По мере добавления в индексно-последовательный файл новых записей область переполнения цилиндра исчерпывается, и вновь поступающие записи передаются в независимую область переполнения. Эта область должна описываться при создании файла. Под независимую область отводится свободный цилиндр или группа цилиндров. Записи в независимой области переполнения связываются так же, как и в области переполнения цилиндров.
Использование независимой области переполнения может привести к существенному увеличению времени доступа, поскольку на перемещение механизма доступа между цилиндрами основной и независимой областей переполнения тратится много времени. Поэтому длительно эксплуатируемые файлы периодически реорганизуют. Обычно реорганизацию проводят, как только записи начинают попадать в независимую область переполнения. При этом записи файла последовательно копируются во временный файл, а затем основной файл создается заново. В результате реорганизации все записи переполнения включаются в основной файл.
При удалении записи не исключаются из файла, а только помечаются как удаленные. В качестве метки удаления может использоваться, например, строка битов '11111111'В, размещенная в первом байте записи. Если со временем в файл добавляется новая запись с тем же самым ключом, что и удаленная запись, то ячейка памяти, занятая удаленной записью, используется повторно.
Файл может длительное время существовать без реорганизации, если при его инициализации оставляют свободные блоки на всех дорожках и свободные дорожки на всех цилиндрах. Однако всегда существует опасность необоснованно большого расхода памяти.
Перечисленные методы отличаются друг от друга по двум признакам:
- Эффективность хранения;
- Эффективность доступа.
Как правило, эти два признака находятся в обратной зависимости. При эффективном хранении доступ усложняется. И наоборот - меры ускоряющие доступ к данным, приводят к увеличению объемов требуемой для хранения памяти.
Другие более сложные методы доступа строятся из перечисленных базовых методов. При этом разработчики программного обеспечения стараются найти оптимальное для конкретных задач соотношение эффективности хранения и доступа.
Физический последовательный метод доступа
Логической записью называется совокупность записей взаимосвязанных информационных элементов, которая рассматривается как единое целое.
Физической записью называется фрагмент данных, пересылаемый как единое целое между ПЗУ и оперативной памятью. Физической записью может быть поле данных или файл.
Логическая запись может состоять из нескольких физических записей или быть частью одной физической записи. Физический последовательный метод предполагает хранение физических записей в определенной логической последовательности. При этом требуется, чтобы логическая последовательность была организована даже, если данные поступали в память без какой-либо логической последовательности.
Эффективность физического последовательного доступа очень низка. Для нахождения нужной записи производится последовательный перебор. В среднем требуется перебрать N/2 записей при общем количестве записей N.
А вот эффективность хранения этого метода напротив очень высока, потому что он требует минимального количества памяти. Память расходуется только на сами данные и на организацию логических связей.Особенно эффективен данный метод при хранении на магнитной ленте (например, в современных стриммерах). В этом случае физическая последовательность совпадает с логической, потому дополнительная память не нужна вообще.
Готовые работы на аналогичную тему
Получить выполненную работу или консультацию специалиста по вашему учебному проекту Узнать стоимостьИндексно-последовательный метод доступа
Первичный ключ – это атрибут физической записи с уникальным значением, по которому запись может быть однозначно идентифицирована.
Индексно-последовательный метод требует, чтобы файл данных был упорядочен по первичному ключу. Записи делятся на блоки. Далее создается индексный файл, который содержит ссылки на блоки записей. Обычно в него заносится либо наибольшее, либо наименьшее значение в блоке. Индексный файл также упорядочен, поэтому и для него можно создать другой индексный файл.
При добавлении новой записи выполняется один из двух алгоритмов:
- Запись сохраняется в отдельной области (область переполнения) и связывается с блоком, которому логически принадлежит.
- Если запись невозможно добавить в некоторый блок, то блок делится пополам. В индексный файл записывается новый ключ.
Эффективность доступа может варьировать в зависимости от размера блока и числа индексных файлов. Эффективность хранения зависит от количества свободных физических блоков, отведенных на область переполнения, и размера блока
Индексно-произвольный метод доступа
Индексно-произвольный метод доступа позволяет создавать индексный файл не только на основе первичного ключа, но и на основе ключа, который является произвольным полем. Индексный файл при этом содержит ключ поиска и ссылку на саму запись. При поиске сначала по индексному файлу находится ключ, потом по ссылке определяется сама запись.
Эффективность доступа при этом методе очень высока, так как индекс содержит ссылки на сами записи, а не на блоки. Но индексные файлы по этой же причине имеют очень большой объем.
Инвертированный метод доступа
Этот метод предназначен для поиска по значениям произвольных полей и их комбинаций. Произвольные комбинации часто бывают не уникальными, поэтому на каждое значение ключа формируется список указателей на записи. При поиске сначала выбирается нужный индекс, а уже внутри него каким-то иным способом (например, индексно-произвольным) выбирается статья с этим значением. Далее по статье выбирается весь блок ссылок, связанных с данным значением индекса.
У этого метода эффективность доступа не очень высокая, так как для поиска одной записи нужно сделать как минимум два обращения – одно к индексу, другое к базе данных. Эффективность хранения может быть достаточно высокой.
Прямой метод доступа
При этом методе между ключом записи и ее физическим адресом устанавливается взаимно-однозначное соответствие.
Эффективность доступа метода максимально высокая, но при этом требуется, чтобы ключ был уникальным, что не всегда возможно.
Эффективность хранения будет достаточно высокой, если в базе данных нет пропущенных значений ключа. Если пропущенных значений ключа много, то под каждый соответствующий физический адрес будет все равно резервироваться память, что ведет к перерасходу памяти .
Доступ через хеширование
Как и прямой метод доступа , данный метод базируется на определении физического адреса памяти по значению ключа. Но если при прямом методе требовалось взаимнооднозначное соответствие, то при хешировании допускается, чтобы несколько значений ключа отображались в один физический адрес.
Записи, отображаемые в один адрес называются синонимами.
Алгоритм отображения ключа в физический адрес называется хешированием.
Синонимы связываются в цепочку с помощью ссылок друг на друга. Таким образом, нахождение одной записи позволяет найти всю цепочку. Эффективность доступа и хранения зависят от самого алгоритма хеширования и длины цепочек
Читайте также: