
Почему на компьютере на котором запущен сервер защиты не должно быть 100 загрузки
Всем, у кого проблемы с постоянной высокой загруженностью процессора:
Сразу прошу прощения - помнится, такая тема уже всплывала, но я её не нашёлСуть проблемы: иногда, причём абсолютно беспочвенно, проц (по данным из Task Manager'а) загружается на 80 - 100%, причём если перейти на вкладку "Процессы", то там только System Idle Process занимает 99% (а значит другие процессы не занимают проц на столько). При этом комп довольно прилично тормозить (нет, курсор не дёргается, Винамп играет исправно, но стоит, скажем, открыть видео, чтобы понять, что больше, чем на слайд-шоу из видео этот комп не способен). Через некоторое время, точно так же "от балды", загрузка снова падает на 0%. Ещё обратил внимание на то, что ASUS'овский Q-Fan (снижает обороты кулера при снижении температуры) работает тихо, а значит проц при этом не греется (это чем же он так занят?).
Что-то я ничего не могу придумать, чтобы от этой проблемы избавиться. Посоветуйте что-нибудь!
З.Ы.: Проц работал нормально совершенно первые недели 3 - 4. С тех пор драйверов новых не ставил, программ тоже. System Idle Process - это обозначение, на сколько процессор свободен (Idle-простаивать).
А на графике в TaskManager тоже загрузка 100%? Да, знаю я, что такое System Idle Process, спасибо. ;)
А когда я говорю про загрузку в 80 - 100%, я и говорю, про график на вкладке "Perfomance".
Не сразу въехал в текст :)
График один к одному отражает процессы и не может так отличаться.
А что показывает график загрузки ядра (ShowKernelTimes)?
еще раз внимательно :) прочитал текст.
Похоже система (процессор) кого-то ждет.
Может диск дефрагментировать?
Дефрагментация, конечно, штука полезная, но я, если честно сомневаюсь, что это поможет. НЖМД молчит, как партизан, да и как-то не объясняет это столь странной загрузки процессора - время от времени, причём промежутки случайные, как и длительность загрузки. Хотя, конечно, попробую, когда домой приеду, но пока надо бы ещё чего-нибудь придумать. ;) Т.е. основная загрузка идет от ядра.
Такое бывает при кривых драйверах (самписал :))
Кстати, десяток пикслей на мониторе - это много если под график обчно выделяется около 50-100 пикселей.
Vanya
Вот, это уже интереснее.
Правдо, я пробовал снимать через Task Manager все процессы, что не относятся непосредственно к системе - не помогло.
А можно, не переустанавливая каждый драйвер, узнать, какой из них грузит систему?
| Кстати, десяток пикслей на мониторе - это много если под график обчно выделяется около 50-100 пикселей. |
Еще можно в EventViewer посмотреть. Там скорее всего висит ругательство о конфликте или превышении времени ожидания. Vanya
О! Об Event Viewer'е я как-то не подумал. Спасибо! Ещё один дельный совет в копилку. есть такой вирь , DonalDick называется , вот он может такие шутки шутить Я тоже склонен к виру, как у нас с "предохранением" :spy:
Zourg Q0011er
"Предохранение" отсутствует как класс, но у компьютера нет выхода в интернет (это я про домашний. Сейчас сижу на работе), так что вероятность подхватить вирус существенно меньше. Впрочем, вчера я провериться всё равно не успел.
Решил загрузиться в Safe Mode и посмотреть, что будет, если не загружать никаких драйверов - только совместимые, встроенные в винду. Глюк всё равно проявился, и я стал было уже грешить на дистрибутив Windows.
Решил поковыряться в биосе. У моей материнской платы есть встроенная сетевая карта, но т.к. я ей не пользуюсь, то я отключил её, но отключил в самом Windows (вообще сижу обычно в Win2k, WinXP держу только для совместимости и пользуюсь ей редко). Но, после того как я отключил её в биосе, глюк сей, вроде бы (долго тестировать времени не было, ибо, как я уже упоминал, глюк появляется сам и "от балды"), исчез. Однако (ну, как всегда, короче), стало интересно, она была виновата, всё таки, или нет. Включил её снова, загрузил винду - глюк на месте. Поставил все возможные драйверы и утилиты для неё и заметил ещё, что без драйверов остался "USB 2.0 controller" в диспетчере оборудования.
Тут самое смешное: стал обновлять драйвер этого контроллера, указал путь, всё установилось, но на последней страничке мастера установки было написано, что, мол, "файл не найден. Драйвер установлен не был", но, тем не менее, устройство перестало быть нераспознанным, переместилось куда надо, и вообще никаких нареканий :D
После этого глюк, тоже "вроде бы", исчез.
З.Ы.: Да, ещё один ньюансик, который я забыл упомянуть: если у процессора в биосе включить HyperThreading, то процессор загружается на 45 - 50%. По идее, это значит, что процессор грузит всё таки какой-то процесс, причём один, а значит версию с вирусом отвергать нельзя. :/
З.З.Ы.: Маленький оффтоп: почему, перед тем, как я первый раз отключил сетевуху в биосе, у меня в диспетчере задач висели ещё какие-то Wi-Fi Adapter'ы (в списке сразу под отключенной сетевой)? Причём штуки четыре и все назывались по-разному. После того, как я включил сетевую снова, никаких подобных устройств уже не появлялось. Может, материнская глючит?
Сегодня постараюсь принести домой антивирус какой-нибудь, проверюсь. Даже если глюк и исчез, надо выяснить, что же это было, чтоб другие потом так не маялись. :fie:
Q0011er Zourg Vanya
Спасибо за помощь! ;)
Значит дело было в драйверах. Идет постоянная загрузка примерно на 40-50 процентов.это не вирус. Лишние процессы убил. Каких то левых процссов не видно, смотрел програмулькой process Explorer. Да, грузит его системный процесс interrupts и system ldle process и более ничего.
Как с этим бороться??
В Пуск-Выполнить- regsvr32 /u shmedia.dll - Ok, если фильмов DivX много на компе.
Эта библиотека пытается информацию из них вытянуть, например разрешение, битрейт и прочую ненужную ерунду, чтобы отображать ее в папке с фильмом.
Че за системный процесс interrupts? Первый раз о нем слышу. И яндекс молчит.
С какого момента это началось? Что при этом делал?
Скорее всего проблемы с каким-то устройством. В диспетчере устройств никаких неопознаных или неработающих устройств нет?
Материал, перевод которого мы сегодня публикуем, посвящён поиску узких мест в производительности серверов, исправлению проблем, улучшению производительности систем и предотвращению падения производительности. Здесь, на пути к решению проблем перегруженного сервера, предлагается сделать следующие 4 шага:
- Оценка ситуации: определение узкого места производительности сервера.
- Стабилизация сервера: применение срочных мер по улучшению ситуации.
- Улучшение системы: расширение и оптимизация возможностей системы.
- Мониторинг сервера: использование автоматизированных средств, позволяющих предотвращать возникновение проблем.
1. Оценка ситуации
Когда трафик перегружает сервер, узким местом производительности могут стать процессор, сеть, память, дисковая подсистема ввода-вывода. Определение того, что именно вызывает проблему, позволяет сконцентрировать усилия на самом важном. Рассмотрим некоторые особенности анализа важнейших серверных подсистем.
- Процессор. Если использование процессора постоянно находится на уровне, превышающем 80%, это значит, что сервер перегружен и нужно выяснить причины возникновения подобной ситуации. Дело в том, что производительность серверов часто падает при достижении нагрузки на процессор 80-90%. Если же нагрузка близка к 100%, падение производительности становится более заметным. Нагрузка на процессор, которую создаёт обработка единственного запроса, крайне мала. Но когда запросов очень много, например, на пиках активности пользователей, даже «лёгкие» запросы могут перегрузить сервер. Уменьшить уровень использования процессора можно, перенеся сервер в другое окружение, снизив объём сложных вычислительных операций, ограничив количество запросов, поступающих к серверу.
- Сеть. В периоды, когда к серверу поступает очень много запросов, сеть, к которой подключён сервер, должна справляться с передачей данных от пользователя серверу и в обратном направлении. Некоторые сайты, зависящие от хостинг-провайдеров, могут испытывать проблемы, достигая лимитов на передачу данных. Избавиться от этой неприятности можно, снизив объёмы данных, которыми обмениваются сервер и клиентские системы.
- Память. Если в системе недостаточно памяти, данные приходится выгружать на диск. Диск работает значительно медленнее, чем память. В результате такая ситуация может привести к замедлению работы серверного приложения. Если вся память сервера заполнена, это может привести к ошибкам нехватки памяти (Out Of Memory, OOM). Устранить эту проблему, можно, оптимизировав выделение памяти, исправив утечки памяти и оснастив сервер большим количеством памяти.
- Дисковая подсистема ввода/вывода. То, с какой скоростью данные можно записывать на жёсткий диск, и то, с какой скоростью их можно с него читать, зависит от самого диска. Если пропускная способность дисковой подсистемы является узким местом сервера, смягчить эту проблему можно, увеличив объём данных, кешируемых в памяти (правда, платой за это станет повышенное потребление памяти). Если кеширование не помогает — вполне возможно, что решить проблему поможет обновление дисковой подсистемы сервера.
Начать работу по выявлению проблем сервера можно, воспользовавшись командой top. Если есть такая возможность, здесь можно прибегнуть к историческим данным хостинг-провайдера и к данным, собранным системами мониторинга.
2. Стабилизация сервера
Наличие в системе перегруженного сервера может быстро привести к каскадным отказам в других частях системы. В результате важно, после того, как стало известно о том, что сервер перегружен, стабилизировать его, а уже потом исследовать ситуацию на предмет внесения в систему неких серьёзных улучшений.
▍Ограничение скорости обработки запросов
Ограничение скорости обработки запросов позволяет защитить инфраструктуру, ограничивая количество входящих запросов. Это очень важно при падении производительности сервера. По мере того, как растёт время ответа сервера, пользователи имеют свойство агрессивно обновлять страницу, что ещё сильнее повышает нагрузку на сервер.
Хотя отказ от обработки запроса — мера простая и действенная, лучше всего снижать нагрузку на сервер, занимаясь ограничением числа поступающих к нему запросов средствами некоей внешней системы. Это может быть, например, балансировщик нагрузки, обратный прокси-сервер или CDN. Ниже приведены ссылки на инструкции по работе с несколькими системами такого рода:
Диагностика
Запустите Lighthouse и взгляните на показатель Serve static assets with an efficient cache policy для того чтобы увидеть список ресурсов с коротким и средним временем кеширования (Time To Live, TTL). Проанализируйте ресурсы, перечисленные в списке, и рассмотрите возможность увеличения их TTL. Вот ориентировочные сроки кеширования, применимые к различным ресурсам.
- Статические ресурсы нужно кешировать на длительный срок (1 год).
- Динамические ресурсы нужно кешировать на короткий срок (3 часа).
Настройка кеширования
Нужно записать в директиву max-age заголовка Cache-Control необходимое время кеширования ресурса, выраженное в секундах. Вот инструкции по настройке этого заголовка в разных системах:
▍Постепенное сокращение возможностей системы
Постепенное сокращение возможностей системы — это стратегия временного ограничения функционала, направленная на снятие с сервера чрезмерной нагрузки. Эта концепция может быть применена множеством различных способов. Например, выдача клиентам статической текстовой страницы вместо полномасштабного приложения, отключение поиска или возврат меньшего, чем обычно, количества результатов поиска. Сюда относится и отключение ресурсоёмких возможностей проектов, не влияющих на их основной функционал. Основное внимание тут должно быть уделено отключению функционала, от которого можно отказаться, не слишком сильно воздействовав на основные возможности приложения.
3. Улучшение системы
▍Использование CDN
Задача по обслуживанию статических ресурсов может быть переложена с сервера на сеть доставки контента (Content Delivery Network, CDN). Это позволит снизить нагрузку на сервер.
Основная функция CDN заключается в быстрой доставке материалов пользователям благодаря использованию большой сети серверов, расположенных поблизости от пользователей. Кроме того, некоторые CDN предлагают дополнительные возможности, связанные с производительностью. Среди них — сжатие данных, балансировка нагрузки, оптимизация медиа-файлов.
Настройка CDN
Преимущества CDN раскрываются в том случае, если компания, владеющая сетью, имеет большую группировку серверов, распределённых по всему миру. Поэтому поддержка собственного CDN-сервиса редко имеет смысл. Обычная настройка CDN — это достаточно быстрая процедура, занимающая около получаса. Она заключается в обновлении DNS-записей таким образом, чтобы они указывали бы на CDN.
Оптимизация использования CDN: исследование ситуации
Для того чтобы идентифицировать ресурсы, которые обслуживаются не с помощью CDN (но должны выдаваться пользователям с CDN), можно воспользоваться WebPageTest. На странице результатов щёлкните по прямоугольнику, подписанному как Effective use of CDN и просмотрите список ресурсов, которые следует обслуживать средствами CDN.
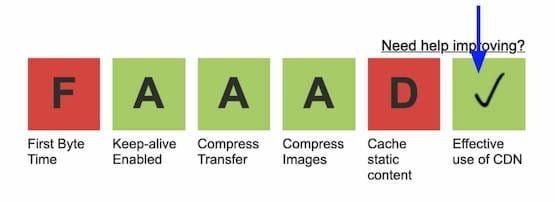
Результаты, выдаваемые WebPageTest
Решение проблем
Если ресурсы не кешируются с помощью CDN, выясните, выполняются ли следующие условия:
- У ресурса есть заголовок Cache-Control: public.
- У ресурса есть заголовки Cache-Control: s-maxage, Cache-Control: max-age или Expires.
- У ресурса есть заголовки Content-Length, Content-Range или Transfer-Encoding.
▍Масштабирование вычислительных ресурсов
Решение относительно масштабирования вычислительных ресурсов следует принимать с осторожностью. Хотя часто решить некие проблемы можно, прибегнув к масштабированию, сделав это несвоевременно, можно неоправданно усложнить систему и необоснованно повысить затраты на её поддержку.
Диагностика
Высокий показатель, характеризующий время до первого байта (Time To First Byte, TTFB), может быть признаком того, что сервер приближается к пределам своих возможностей. Найти сведения о TTFB можно в разделе Reduce server response times (TTFB) отчёта Lighthouse.
Для более глубокого исследования ситуации нужно воспользоваться каким-нибудь средством мониторинга и проанализировать использование процессора. Если текущее или прогнозируемое значение загрузки процессора превышает 80% — это значит, что нужно задуматься о повышении мощности сервера.
Решение проблем
Добавление в систему балансировщика нагрузки позволяет распределять трафик между множеством серверов. Балансировщик нагрузки находится перед пулом серверов и распределяет трафик на подходящие серверы. Облачные провайдеры предлагают пользователям балансировщики нагрузки (GCP, AWS, Azure), но можно пользоваться и собственным балансировщиком, применив HAProxy или NGINX. После того, как балансировщик нагрузки готов к работе, в систему можно добавлять дополнительные серверы.
В дополнение к балансировке нагрузки большинство облачных провайдеров предлагает услуги по автоматическому масштабированию вычислительных мощностей (GCP, AWS, Azure). Автоматическое масштабирование связано с балансировкой нагрузки. А именно, при автоматическом масштабировании ресурсов в моменты высокой нагрузки производится выделение дополнительных ресурсов, а в периоды низкой — отключение ненужных ресурсов. Но, даже учитывая это, нужно отметить, что автоматическое масштабирование — это тоже не универсальное решение. Для автоматического запуска серверов нужно время. Конфигурации автоматического масштабирования требуют серьёзной настройки. Поэтому до применения сложной системы автоматического масштабирования стоит опробовать сравнительно простую конфигурацию с балансировщиком нагрузки.
▍Использование сжатия данных
Текстовые ресурсы нужно сжимать с использованием алгоритма gzip или brotli. В некоторых случаях сжатие может помочь в сокращении размеров таких ресурсов примерно на 70%.
Диагностика
Для того чтобы найти ресурсы, нуждающиеся в сжатии, можете воспользоваться показателем Enable text compression из отчёта Lighthouse.
Решение проблем
Для включения сжатия нужно отредактировать настройки сервера. Вот подробности об этом:
▍Оптимизация изображений и других медиа-материалов
На изображения приходится основной объём материалов большинства веб-сайтов. Оптимизация изображений может привести к значительному уменьшению размеров материалов сайта. При этом такая оптимизация выполняется достаточно быстро.
Диагностика
В отчёте Lighthouse есть разные показатели, которые указывают на потенциальные возможности по оптимизации изображений. Для поиска крупных изображений, нуждающихся в оптимизации, можно воспользоваться и обычными инструментами разработчика браузера. Такие изображения вполне могут стать хорошими кандидатами на оптимизацию.
Вот список показателей отчёта LightHouse, на которые стоит обратить внимание, исследуя возможность оптимизации изображений:
-
сетевую активность страницы.
- Щёлкните по Img для того чтобы отфильтровать ресурсы, не являющиеся изображениями.
- Щёлкните по столбцу Size для того чтобы отсортировать файлы изображений по размеру.
Решение проблем
Сначала поговорим о том, что стоит предпринять в том случае, если у вас мало времени.
В такой ситуации стоит обратить внимание на большие изображения, и на изображения, которые загружаются чаще других. Обнаружив их, их надо подвергнуть ручной оптимизации, воспользовавшись инструментом наподобие Squoosh. Хорошими кандидатами на оптимизацию обычно являются большие фотографии. Например, взятые с ресурса вроде Hero Images.
Вот на что надо обращать внимание, оптимизируя изображения:
- Размер: изображения не должны быть больше, чем нужно.
- Сжатие: в целом можно отметить, что сжатие с уровнем качества 80-85 обычно почти не ухудшает внешнего вида изображений, но при этом позволяет избавиться от 30-40% размеров файлов изображений.
- Формат: храните фотографии в формате JPEG, а не PNG. Для анимированного контента используйте MP4, а не GIF.
Если изображения составляют значительную долю материалов сайта — рассмотрите возможность использования для их обслуживания специализированного CDN-сервиса, рассчитанного на работу с изображениями. Такие сервисы позволяют снять нагрузку по работе с изображениями с основного сервера. Настройка проекта на использование подобного CDN-сервиса проста, но она требует обновления существующих ссылок на изображения таким образом, чтобы они указывали бы на CDN-ресурсы. Вот материал, посвящённый использованию специализированных CDN-сервисов, рассчитанных на изображения.
▍Минификация JavaScript- и CSS-кода
Минификация кода позволяет уменьшать его размер, удаляя ненужные символы.
Диагностика
Взгляните на показатели Minify CSS и Minify JavaScript отчёта Lighthouse для того чтобы выявить ресурсы, нуждающиеся в минификации.
Решение проблем
Если у вас мало времени — сосредоточьтесь на минификации JavaScript-кода. На большинстве сайтов объём JavaScript-кода превышает объём CSS-кода, поэтому такой ход даст лучшие результаты. Вот материал о минификации JavaScript, а вот — о минификации CSS.
4. Мониторинг сервера
Инструменты для мониторинга серверов поддерживают сбор данных и их визуализацию с использованием панелей управления. Они умеют оповещать пользователей о различных событиях, имеющих отношение к производительности серверов. Использование таких инструментов может помочь в предотвращении и смягчении проблем с производительностью серверов.
В уведомлениях должны содержаться метрики, которые последовательно и точно описывают проблемы. Например, время ответа сервера (latency) — это метрика, которая особенно хорошо для этого подходит: она позволяет выявить большое количество проблемных ситуаций и напрямую связана с тем, как сервер воспринимается пользователями. Уведомления, основанные на низкоуровневых метриках, вроде уровня использования процессора, могут играть роль полезного дополнения, но они способны указать лишь на небольшую часть возможных проблем. Кроме того, уведомления должны быть основаны не на средних показателях, а на показателях, соответствующих 95-99 перцентилям. В противном случае анализ средних значений может легко привести к пропуску проблем, которые не затрагивают всех пользователей.
Настройка мониторинга
Все основные облачные провайдеры предоставляют клиентам собственные инструменты мониторинга (GCP, AWS, Azure). Кроме того, тут можно отметить инструмент Netdata — отличную бесплатную опенсорсную альтернативу инструментам провайдеров. Вне зависимости от того, чем именно вы пользуетесь, вам понадобится установить на каждый сервер, который нужно мониторить, приложение-агент. После завершения настройки системы не забудьте настроить уведомления. Вот инструкции по настройке разных средств мониторинга:
Итоги
У одного из наших клиентов на новых и мощных серверах кластер «1С:Предприятия» демонстрировал низкую производительность, время ожидания пользователей при выполнении рабочих операций превышало все разумные пределы. Быстрый анализ показал периодический дисбаланс нагрузки между физическими процессорами — в отдельные моменты один мог быть загружен на 100 %, второй на 5–10 %. В статье рассказываем, как локализовали и решили эту проблему.
Общая схема работы при устранении проблемы
Забегая вперед, вот действия, которые мы выполняли при диагностировании и устранении проблемы клиента:
- Проверка платформы и конфигурации «1С:Предприятия».
- Внесение изменений в настройки платформы.
- Проверка изменений в производительности.
- Исследование аппаратного и программного комплекса у клиента.
- Поиск схожих проблем на имеющемся железе в базах знаний производителей оборудования и в публичных источниках.
- Внесение изменений в настройки аппаратного обеспечения.
Оптимизируем «1С:Предприятие»
В первую очередь мы стали отслеживать поведение кластера, динамику нагрузки, ее распределения и условия, при которых проявлялась проблема снижения производительности.
Мы обратили внимание, что пик нагрузки и перекос по ней приходится на момент запуска новых процессов кластера — при подключении новых пользователей, при запуске новых процессов во время автоматической балансировки нагрузки и распределении соединений между новыми и старыми процессами. В этот момент приложение зависало на несколько минут и система была неработоспособной для тех пользователей, которые назначались на новый процесс.
Стали разбирать инцидент совместно с фирмой «1С» в рамках ИТС КОРП. В результате была выявлена ошибка платформы 30158420, зафиксированная фирмой «1С» еще в ноябре 2017 года, но не исправленная на момент возникновения сложностей у нашего клиента. По итогам переговоров с корпоративной поддержкой «1С» информация об ошибке весной 2018 года была опубликована, а для нашего клиента выпустили внеочередную сборку платформы с исправлением. Вот суть ошибки:
В клиент-серверном варианте информационной базы при одновременном запуске нескольких клиентских сеансов с одинаковым набором расширений конфигурации наблюдается избыточная нагрузка на процессор и увеличенный расход оперативной памяти.
В текущий момент ошибка исправлена в актуальных релизах платформы «1С:Предприятие».

Мы внесли изменения в платформу у клиента и проверили результат. Пользователи почувствовали улучшение ситуации, но в глобальном плане проблема сохранилась. Нагрузка все еще распределялась между двумя процессорами неравномерно:

Проверили еще несколько вариантов, приводящих к снижению производительности, в том числе давно известные — про ограничения, описанные в 2015 году о работе платформы «1С» с многопроцессорными системами:
Поддержка NUMA в кластере серверов 1С полноценно пока не реализована. Сервер «1С» не управляет распределением ресурсов по NUMA узлам, полностью полагаясь в этом на операционную систему, что не всегда даёт оптимальный результат. Поэтому при работе на современных многопроцессорных системах Intel и AMD, в зависимости от характера нагрузки, может наблюдаться неравномерная загрузка процессоров/ядер.
Выполнили все рекомендации по оптимизации «1С» для многопроцессорных систем. Однако, к улучшению ситуации это не привело.
Настраиваем серверное окружение
Перешли к проверке системного ПО и аппаратной части вместе с ИТ-отделом заказчика. Система построена на базе двухпроцессорной системы с 32 ядрами, по 16 на процессор.
Поиск и исследование информации о схожих с нашей задачей сложностях, материалов от поставщиков оборудования и серверной ОС дало нам три направления работы:
- Механизмы работы операционной системы на многоядерном/многопроцессорном сервере.
- Настройка аппаратной части — BIOS сервера.
- Ограничение на выполнение приложения одной группой процессоров.
Серверные операционные системы семейства Windows начиная с WinServer2008R2 64bit поддерживают работу с более чем 64 логическими процессорами на одном компьютере. Для того, чтобы это реализовать в ОС используется механизм группировки процессоров (processor group, kernel group, kgroup). Каждая из групп может содержать до 64 логических процессоров и если на сервере менее 64 логических процессоров, то должна создаваться только одна группа с порядковым номером 0. Следуя этой логике на испытуемом сервере должна быть только одна группа (Group 0), что подразумевает более-менее равномерное распределение нагрузки между ядрами наших двух физических CPU.
Проверка аппаратной части дала пищу для размышлений. Во-первых, нашлись кейсы, где наблюдалось падение производительности, похожее на наше, для различных приложений. В этих кейсах проводилось тестирование аналогичных серверов двух вендоров. У вендора, которого использует наш клиент, проблема была. А у иного — нет. Проблему на момент размещения кейса частично решали использованием неофициальной (unpublished) версии BIOS с добавленным в настройки параметром NUMA Group Size Optimizations.
Во-вторых, на сервере клиента использовалась устаревшая версия BIOS, для которого вендором была уже зафиксирована и исправлена ошибка, из-за которой серверные ОС Windows могли использовать только половину или менее логических процессоров определенной линейки Intel Xeon. BIOS был обновлен до актуальной версии. В этой версии BIOS уже штатно присутствует параметр NUMA Group Size Optimization.

В-третьих, по умолчанию BIOS настроен таким образом, чтобы обеспечивать работу максимального количества логических процессоров в системе. У сервера два процессорных сокета и параметр NUMA Group Size Optimization выставлен в значение Clustered, обеспечивающее работу максимального количества ядер/процессоров. Получается, что настройка BIOS (напомним, что у сервера клиента всего 32 ядра) разбивала имеющиеся ядра/процессоры на 2 kgroup.
Получается, что в платформе «1С:Предприятие» поддержка NUMA пока не реализована и отдается на откуп ОС. ОС объединяет по умолчанию все ядра в количестве менее или равно 64 в одну группу процессоров. А на уровне оборудования выставлена настройка разбивать на несколько групп имеющиеся ядра. Явная нестыковка.
Особенность отслеживания загрузки процессоров в perfmon
Дополнительную сложность в работе принесло использование Performance Monitor Windows. В Perfmonitor есть счетчик в разделе Processor, который должен показывать общую загрузку процессоров на сервере. «1С» рекомендует этот счетчик включать. А вот Microsoft его обозначает как устаревший. При наличии нескольких групп процессоров вместо общей загрузки системы в графики и показатели попадает значение только той группы, на которой исполняется сам Performance Monitor. Ниже скриншоты. На графиках синей линией обозначены некорректные данные только по одной группе процессоров. А красной указано то, как на самом деле должен был выглядеть график. Поэтому для многопроцессорных систем не используйте неправильный счетчик в мониторе производительности.

Выводы и предупреждение
Итак, у клиента меньше 64 ядер, но BIOS сервера всё равно использовал две процессорные группы и таким образом ограничивал каждый процесс в системе лишь половиной мощностей.
При запуске нескольких процессов кластера «1С» можно было бы ожидать, что они равномерно распределятся между двумя группами, но это не всегда происходило. ОС заточенная под механизмы работы NUMA-архитектуры могла принять решение, что работать с одним процессором быстрее, чтобы использовать память адресованную для этого процессора. Получается, что несколько процессов «1С:Предприятия» оказывалось в одной группе, создавая загрузку на 100%, а вторая группа процессоров в этот момент простаивала. Очередь заданий росла, пользователи чувствовали замедление работы «1С» и выказывали недовольство.
Переключение в BIOS параметра NUMA Group Size Optimization с Clustered на Flat в данном конкретном случае вернуло производительность кластера «1С:Предприятия» на должный уровень. Для пользователей пропали нестерпимые периоды ожидания и работа стала комфортной.
Но не всё так радужно. Платформа «1С:Предприятие» не умеет на момент написания статьи работать с несколькими группами процессоров. Значит, если в сервере будет установлено больше 64 ядер мы окажемся в ловушке — необходимо будет переключить в BIOS параметр NUMA Group Size Optimization в значение Clustered. А это снова вернет нас в исходную ситуацию, когда часть ядер простаивает. Фирма «1С» знает об этой проблеме и прорабатывает необходимые решения.
Отдельно стоит отметить особенности измерения общей загрузки процессора с помощью утилиты perfmon в случае использования групп процессоров, то есть на любом крупном сервере с более чем 64 ядрами.
Мы будем дальше работать над вопросами производительности информационных систем и готовы поделиться знаниями и опытом.
Обращайтесь! Высокой вам производительности и консистентности данных!
В данной инструкции рассмотрим каким образом настраивается СЛК для работы на нескольких компьютерах. В примере будет рассматриваться работа на двух компьютерах, объединенных в единую сеть. Используются два аппаратных ключа защиты: на основное рабочее место красного цвета и на дополнительное рабочее место желтого цвета.
Примечание: инструкцию по работе с программными ключами защиты можно посмотреть здесь
Настройка СЛК
В первую очередь нужно установить саму систему лицензирования (СЛК), подробную инструкцию можно посмотреть по ссылке. СЛК нужно устанавливать только на основной компьютер, на котором будут располагаться и ключи защиты.
После установки СЛК оба ключа устанавливаем на основной компьютер, запускаем консоль СЛК. Консоль можно открыть через меню «Пуск»:

Если ключи работоспособны и все установлено корректно, они будут отображены в консоли:

По каждому ключу пишется его тип и количество лицензий.
В данном случае имеется основной ключ на 1 рабочее место и дополнительный ключ на 5 рабочих мест.
ВАЖНО: дополнительный ключ не будет работать без основного. Если установить на компьютере только его, то в консоли выйдет предупреждение о том, что требуется основной ключ:

Если ключи не отображаются в консоли, нужно проверить следующее:
горят ли ключи: они должны светиться красным цветом. Если нет – можно попробовать установить ключи в другой USB-порт, либо проверить на другом компьютере (ноутбуке). Если ключ нигде не работает, возможно он сломан;
открыть диспетчер устройств на компьютере, проверить, найден ли там ключ защиты:



Запускаем программу 1С.


После этого закрываем окно настроек по кнопке «Записать и закрыть».
При следующем открытии программы настройки сохранятся.
Примечание: Если проверка не проходит, возможно брандмауэр или антивирус блокируют порт 9099 или другой используемый. Следует проверить, открыт ли этот порт. Если порт закрыт, можно либо отключить антивирус и брандмауэр, либо настроить правила для этого порта.
Примечание: Узнать, какой порт используется, можно в консоли СЛК:

Что делать если СЛК «не видит» ключ защиты
Полное наименование и релиз программы.
Режим работы в 1С: файловый, клиент-серверный, веб-сервер. Где посмотреть режим работы, смотрите здесь.
Версию СЛК, информацию по используемым лицензиям:
аппаратные или программные ключи;
на сколько рабочих мест имеются лицензии.
Подробное описание вопроса:
горят ли ключи защиты. Если нет - пробовали ли проверить их работоспособность на других портах или компьютерах;
отображаются ли ключи в консоли СЛК;
на каком компьютере не получается настроить работу: на основном или на дополнительных.
Читайте также: