
Операции над данными в компьютере выполняются точно если эти данные являются
Обработка данных (англ. “Data processing”) - процесс выполнения последовательности операций над данными. Это процесс управления данными (цифры, символы и буквы) и преобразования их в информацию. Обработка данных может осуществляться в интерактивном и фоновом режимах.
Обработка информации - переработка определённого типа информации (текстовой, звуковой, графической и др.) и преобразование её в информацию другого типа. Например, различают обработку текстовой информации, обработку изображений (графика, фото, видео и мультипликация), обработку звуковой информации (речь, музыка, другие звуковые сигналы).
Технологией обработки информации называют взаимосвязанные действия, выполняемые в строго определённой последовательности с момента возникновения информации до получения заданных результатов.
Информационная технология обработки предназначена для решения хорошо структурированных задач, по которым имеются необходимые входные данные, известны алгоритмы и другие стандартные процедуры их обработки. Эта технология применяется в целях автоматизации рутинных постоянно повторяющихся операций, что позволяет повышать производительность труда, освобождая исполнителей от рутинных операций, а порой и сокращая численность работников.
Вариантом технологии автоматического сбора информации является RFID (Radio Frequency Identification). RFID - встраиваемый в какой-либо объект специальный микрочип размером в несколько сантиметров, который с помощью имеющейся в нём антенны обеспечивает обмен информацией с внешними устройствами (компьютером и др.). Он позволяет проводить диагностику оборудования, выявлять нуждающиеся в замене комплектующие и т.д. Внедрение этой технологии обеспечит высокоэффективные методы учёта и сервисного обслуживании различных изделий и объектов.
Технологический процесс обработки информации с использованием ЭВМ включает следующие операции:
приём и комплектование первичных документов (проверка полноты и качества их заполнения, комплектности и т.д.);
подготовка электронного носителя и контроль его состояния;
ввод данных в ЭВМ;
контроль, результаты которого выдаются на внешние устройства (принтер, монитор и т.д.).
Технологические операции контроля данных
В различных ситуациях приходится контролировать получаемые или распространяемые данные и информацию. С этой целью широко применяются информационные технологии. Различают визуальный и программный контроль, позволяющий отслеживать информацию на полноту ввода, нарушение структуры исходных данных, ошибки кодирования. При обнаружении ошибки производится:
Важными элементами информационных технологий являются технологии хранения и сохранности информации, данных и знаний.
Информационная технология хранения данных, информации и знаний могут выступать как разновидность технологии обработки данных или как самостоятельная информационная технология. Хотя существуют отличия в технологиях хранения информации, данных и знаний, в данном случае будем рассматривать их как единый процесс, а термины - как синонимы.
Хранение информации необходимо для того, чтобы: иметь в памяти ЭВМ системные и другие, необходимые пользователям программы и данные; осуществлять различные виды работ на компьютере; её можно было в любой момент предоставить пользователю. Различные виды информации, данных и знаний хранятся на разнообразных носителях электронных данных (жёстких, гибких магнитных и лазерных дисках, микросхемах и др.). Она может редактироваться, удаляться, копироваться на другие носители, пересылаться на другие компьютеры, архивироваться с разной степенью регулярности.
Хранение - это базовая основа обеспечения сохранности.
Если документ повреждён, разрушен и может быть утрачен, то говорить об обеспечении сохранности бессмысленно.
Технологические операции передачи данных
Операции передачи данных, информации и знаний представляют процессы их распространения среди пользователей путём применения средств и систем коммуникации. Эти системы позволяют перемещать (т.е. пересылать) различные виды информации от их отправителя (источника) к получателю (приемнику). Системы и средства коммуникации состоят из:
аппаратуры передачи данных (АПД), которая соединяет средства обработки и подготовки данных с каналами связи;
устройств сопряжения ЭВМ с АПД, управляющих обменом информацией.
Передача данных осуществляется в виде трансляции электрических сигналов, которые могут быть непрерывными и дискретными во времени, т.е. прерываться в какие-то промежутки времени. Несколько линий или каналов связи, предназначенных для передачи данных или организации компьютерной связи, принято называть телекоммуникациями. Английское слово “telecommunication” означает дистанционную связь, дистанционную передачу данных или сеть связи. Телекоммуникации делятся на проводные и беспроводные. С помощью проводов или кабелей, а также без них (беспроводная связь) телекоммуникации обеспечивают устойчивую передачу данных между источниками и потребителями информации.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером , а потребителя - клиентом ; • преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы .
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление , наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 79.
Здесь и далее сплошные линии означают управляющие связи, пунктирные - информационные связи.
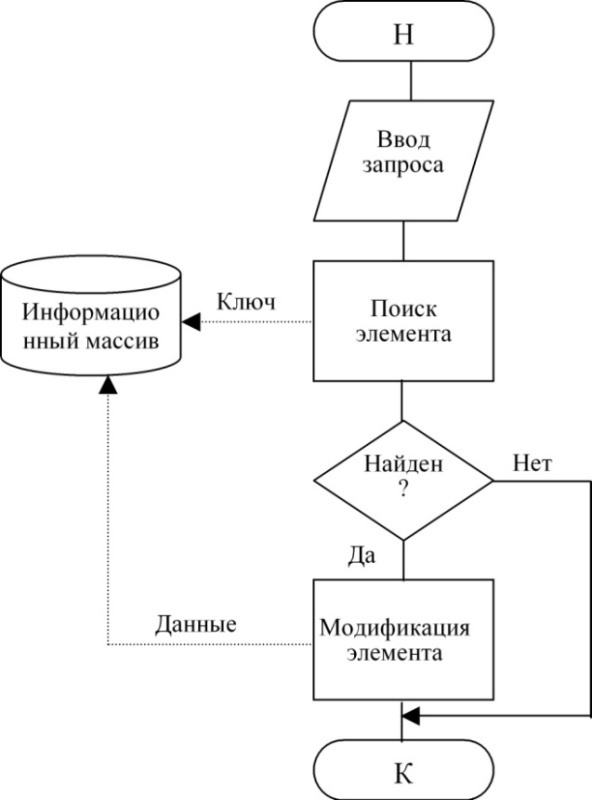
Рисунок 79. Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 80:
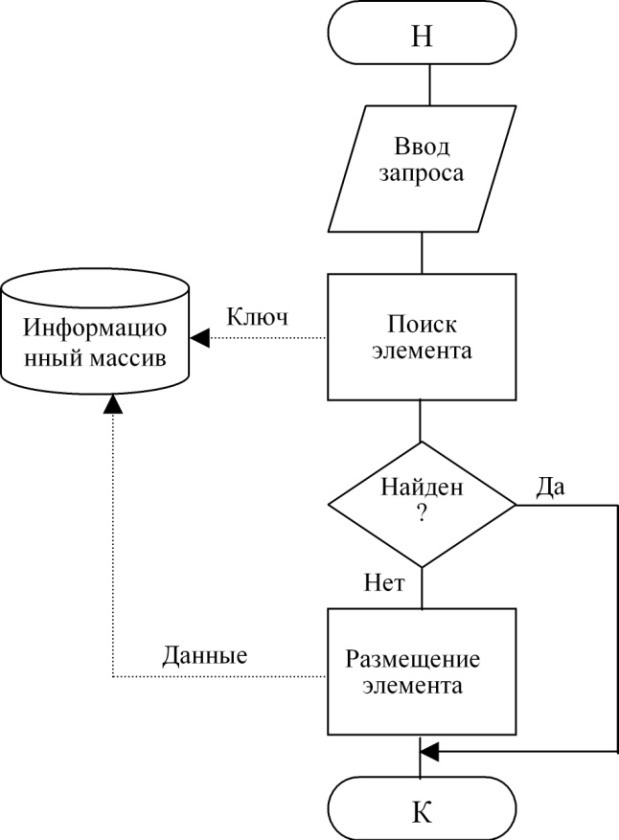
Рисунок 80. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 81.
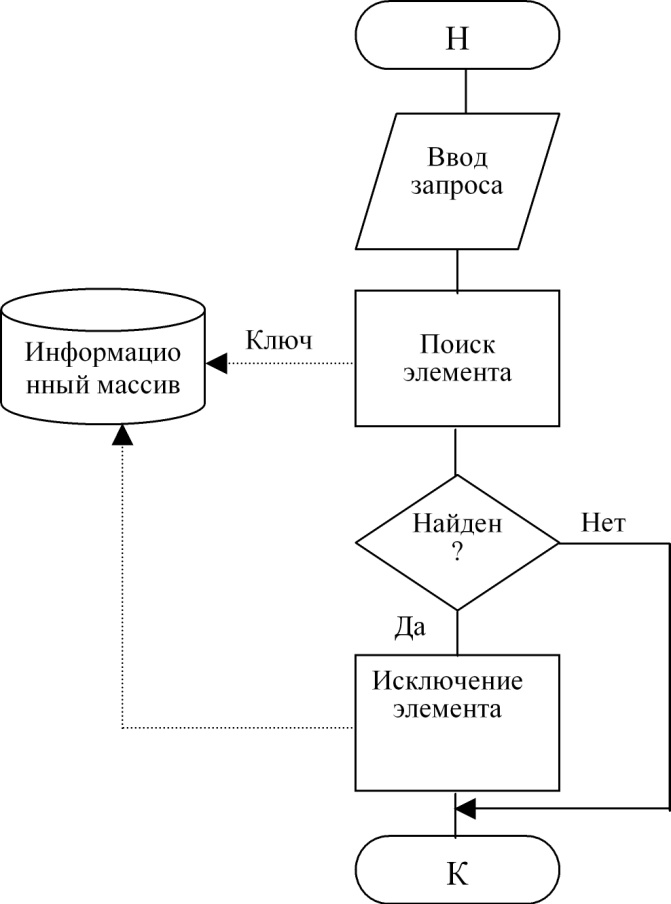
Рисунок 81. Технология удаления элемента
Технология просмотра элемента приведена на рис. 82. Различие в схемах состоит в том, что по технологии рис. 79 и 80 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 81 воздействие не связано с передачей данных, а по схеме рис. 82 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
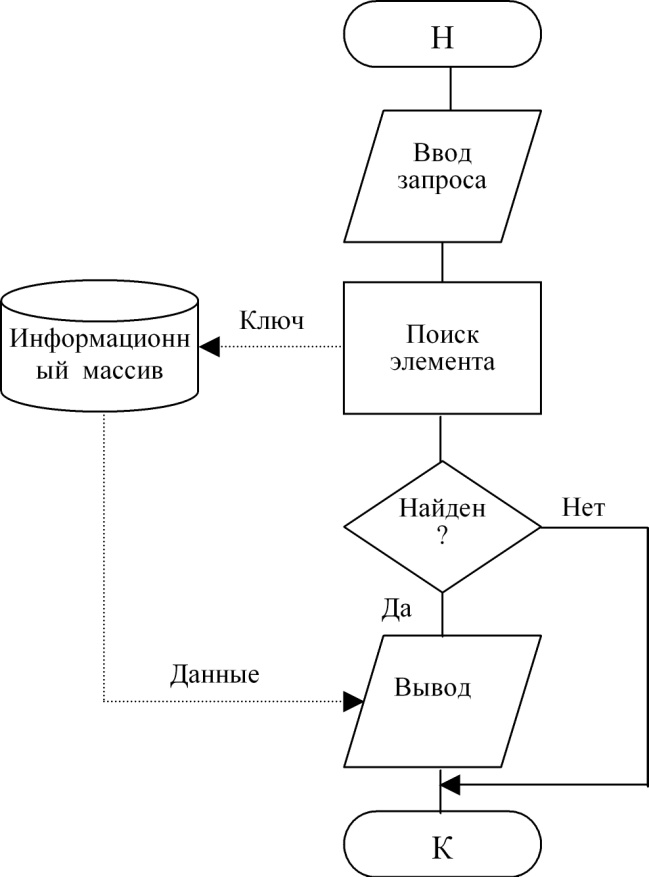
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
В силу вышесказанного, основное внимание в данном разделе уделено задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (напомним, что удаление является обратным действием по отношению к добавлению), а просмотр - это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно короткое время и с достаточно большой точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше объем таблицы, тем выше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Выражением называется последовательность операций, операндов и знаков препинания, задающих определенное вычисление. Вычисление выражений выполняется по определенным правилам преобразования и приоритета, которые зависят от используемых в выражениях операций, наличия круглых скобок и типов данных операндов.
Операндами называются данные (переменные, константы), над которыми выполняются операции.
В языке С имеется достаточно большой набор операций. Для удобства рассмотрения все операции можно классифицировать, например, по количеству используемых операндов. По этому признаку все операции делятся:
- • па унарные (с одним операндом);
- • бинарные (с двумя операндами);
- • операция с тремя операндами.
Унарные операции в языке С могут использоваться в префиксной и постфиксной формах. Общий синтаксис операций:
Выбор определенной формы записи зависит от конкретной операции.
К унарным операциям относятся следующие:
- • операции изменения знака операнда;
- • операция побитового отрицания;
- • операция логического отрицания;
- • операция определения размера;
- • инкремент и декремент;
- • операция доступа;
- • адресные операции.
Операции изменения знака операнда унарный плюс (+) и унарный минус (-) могут выполняться над любыми выражениями арифметического типа. Унарный минус эквивалентен умножению значения операнда на -1. Унарный плюс эквивалентен умножению значения операнда на +1. Эта операция фактически ничего не делает, но может быть использована для явного указания того, что используемая в качестве операнда константа является положительным значением.
Операция побитового отрицания (
) выполняется над операндом целочисленного типа и заключается в побитовом инвертировании двоичного кода операнда (все единицы в этом коде заменяются нулями, а нули — единицами). Результатом операции является число, имеющие таким образом сформированный двоичный код.
Операция логического отрицания (!) выполняется над операндом арифметического типа. Любое значение операнда, отличное от нуля, в языке С считается истинным (числовой эквивалент этого значения — 1), значение, равное нулю, — ложным. Операция меняет логическое значение операнда: если он был равен нулю, то возвращается значение 1, если операнд был не равен нулю, то возвращается значение 0.
Операция определения размера (sizeof) может выполняться над выражением любого типа или над типом данных. В первом случае результатом выполнения операции являетея размер значения выражения в байтах, во втором — размер указанного типа данных в байтах. Результат операции имеет тип size_t, относящийся к целочисленному беззнаковому типу. Синтаксис операции:
j = sizeof(i); // значение j равно 4;
k = sizeof(int); // значение k равно 4.
К операциям увеличения и уменьшения значения относятся:
Инкремент увеличивает значение операнда на 1, декремент — уменьшает значение операнда на 1.
Эти операции могут использоваться в префиксной и постфиксной формах. В префиксной форме в вычислении значения выражения используется уже измененное значение операнда (в результате значение выражения совпадает со значением операнда), в постфиксной форме сначала производится вычисление выражения, а потом изменение значения операнда (в результате значение выражения оказывается на единицу больше или меньше значения операнда). Например:
j=++i; // использована префиксная форма. Значение i // сначала увеличено на 1 (i=2), а потом // присвоено j // (j=2)
j=i++; // использована постфиксная форма. Значение i // сначала присвоено j (j=l), а затем i // увеличено на 1 (i=2)
К адресным операциям относятся:
- • операция получения адреса операнда (&);
- • операция обращения по адресу (*).
Эти операции выполняются над данными, имеющими тип указателя, и будут рассмотрены ниже.
Бинарные операции выполняются над двумя операндами. Общий синтаксис этих операций:
К бинарным операциям относятся следующие:
- • арифметические операции;
- • операции сравнения;
- • побитовые операции;
- • логические операции;
- • операция присваивания;
- • прочие бинарные операции.
Арифметические операции выполняются над операндами числового типа. Результатом также является значение числового типа. К разряду арифметических относятся операции:
- • сложения (+) и вычитания (-). Операнды в этих операциях, кроме числового типа, могут иметь и тип указателя, который будет рассмотрен позднее;
- • умножения (*) и деления (/);
- • получения остатка от деления (деление по модулю %). Операндами для этой операции являются целочисленные значения. Если изначально операнды не являются целыми числами, то они будут приведены к целому тину. Результат операции будет положительным, если оба операнда неотрицательны, в противном случае знак результата зависит от конкретной реализации компьютера.
Операции сравнения выполняются над операндами числового типа. Результатом операции является одно из двух целочисленных значений: 0 соответствует лжи (FALSE), 1 соответствует истине (TRUE). К операциям сравнения относятся:
- • — больше;
- • >= — больше или равно;
- • == — равно;
- • != — не равно.
int i,j; // объявлены целочисленные переменные
char resl, res2; // объявлены символьные переменные
i = 5; // переменной i присвоено значение 5
j = 8; // переменной j присвоено значение 8
resl = i == j; // переменной resl присвоено значение
// результата операции i == j,
// в результате эта переменная получит // значение О (FALSE)
res2 = i > 2; // сдвиг вправо дает значение 00101000,
k= i конъюнкция (&), дизъюнкция (|), исключающая дизъюнкция ( Л ). Двоичный код результата формируется путем выполнения соответствующих побитовых операций над двоичными кодами операндов. Результаты побитовых операций приведены в табл. 5.3. Например:
Основным назначением любой прикладной программы является преобразование исходных данных в соответствии с заданным алгоритмом, а большая часть исходных данных обычно представлена числовой информацией. В этом разделе мы познакомимся с формой записи числовых данных в программах на языках C, C++ и набором операций, которые можно использовать для различных типов числовых данных. Термин системные, использованный в заголовке раздела, означает, что данные этого типа являются "родными" для системы программирования. Их не надо описывать, не надо определять, как выполняются арифметические или какие- либо другие операции над данными этих типов. Иногда такие данные называют базовыми. Как правило, системные типы данных в алгоритмических языках повторяют те числовые форматы, которые предусмотрены системой машинных команд ПК.
3.1. Типы числовых данных и их представление в памяти ЭВМ
Числовые данные условно можно разбить на три категории - положительные целочисленные данные (их значения в компьютере представлены целыми двоичными числами без знака), произвольные целочисленные данные (один из двоичных разрядов их представления играет роль знакового разряда) и числовые данные вещественного типа.
3.1.1. Внутреннее представление целочисленных данных
Для хранения целочисленных данных со знаком в IBM PC используется дополнительный двоичный код. Эта особенность распространяется только на отрицательные числа. Для получения дополнительного кода отрицательного числа нужно перевернуть все двоичные разряды соответствующего положительного числа и прибавить единицу в старший разряд. Например:

Дополнительный код позволяет примерно на 25% ускорить выполнение таких операций как сложение и вычитание.
3.1.2. Однобайтовые целочисленные данные
Самые короткие целочисленные данные со знаком представлены в памяти IBM-совместимых ПК одним байтом, в котором может разместиться любое число из диапазона от -128 до 127 , записанное в дополнительном коде. В языках C, C++ для описания переменных такого типа используется спецификатор char . В одном же байте может быть расположено и самое короткое целое число без знака. По терминологии C таким числам соответствует спецификатор unsigned char . Диапазон допустимых данных при этом смещается вправо и равен [0, 255] .
3.1.3. Двухбайтовые целочисленные данные
Вторая категория целочисленных данных в системах программирования, эксплуатируемых на IBM PC, представлена двухбайтовыми целыми числами. В варианте со знаком они поддерживают диапазон от -32768 до +32767 , в варианте без знака - от 0 до 65535 .
Язык системы BC 3.1 использует для описания двухбайтовых целочисленных данных спецификаторы int (короткое целое со знаком) и unsigned int (короткое целое без знака). При их использовании арифметические операции над короткими операндами выполняются корректно при условии, что результат не выходит за пределы разрешенного диапазона. Однако если к максимальному целому числу прибавить 1, то вместо положительного числа +32768 в компьютере окажется отрицательное число -32768 . И никакого предупреждения о нарушении допустимого интервала система не выдаст. Считается, что программист сам должен позаботиться о соответствующих проверках. В версии Borland C++ Builder для объявления двухбайтовых целочисленных данных используются спецификаторы short и unsigned short .
3.1.4. Четырехбайтовые целочисленные данные
Третья категория целых чисел в IBM PC представлена четырехбайтовыми данными. В варианте со знаком они перекрывают диапазон от -2147483648 до +2147483647 , в варианте без знака - от 0 до 4294967295 .
Для описания четырехбайтовых данных целого типа в языках C, C++ используются спецификаторы long (эквивалент long int ) и unsigned long . В среде визуального программирования C++ Builder спецификаторы int и long эквивалентны.
3.1.5. Восьмибайтовые целочисленные данные
Несмотря на то, что микропроцессоры IBM PC уже давно поддерживают восьмибайтовый целочисленный формат, обеспечивающий диапазон от -2 63 до 2 63 -1 , системы программирования довольно долго обходили этот формат или использовали его особым образом. Так, например, системы Turbo Pascal на базе этого формата предложили тип данных comp, который был причислен к разряду данных вещественного типа. В современных визуальных средах этот тип данных в своем естественном виде представляет числовые объекты типа int64 . В недалеком будущем системы программирования воспользуются и сверхдлинными целочисленными данными типа int128 .
3.2. Внутреннее представление данных вещественного типа
Для внутреннего представления данных вещественного типа характерно то, что в соответствующей области оперативной памяти хранятся две компоненты числа - мантисса m и порядок p . Само число x при этом равно произведению m*2 p . Таким образом, мантисса определяет значащие цифры числа и его знак, а порядок - положение запятой, которая благодаря этому как бы "плавает" между значащими цифрами (отсюда и термин - формат с плавающей запятой ). Такой способ представления числовых данных позволяет при одинаковом количестве двоичных разрядов, отведенных для хранения чисел существенно расширить диапазон допустимых данных.
Попробуем оценить тот выигрыш в диапазоне допустимых чисел, который обеспечивает формат вещественных данных по сравнению с целочисленным форматом. Рассмотрим 32-битные двоичные числа. Целочисленные значения со знаком в этом формате позволяют работать с числами, принадлежащими по модулю интервалу [0, 2*10 9 ] . Предположим, что для числа с плавающей запятой в 32-битном слове отведены 1 двоичный разряд под знак числа, 8 двоичных разрядов под порядок и оставшиеся 23 разряда - под мантиссу . Тогда минимально представимое число равно произведению минимальной мантиссы ( 2 -1 ) на минимальный порядок ( 2 -128 ), т.е. 2 -129 , что примерно соответствует 10 -39 . Самое большое по модулю число представляет произведение (1-2 -23 )*2 +127 , что примерно соответствует 10 +38 . Таким образом, если целые числа перекрывали диапазон в 9 десятичных порядков, то формат с плавающей запятой при той же разрядности слова перекрывает диапазон в 77 порядков. Однако нельзя не заметить и проигрыш в количестве значащих цифр. Целочисленный 32- битный формат поддерживает 10 значащих цифр, тогда как 23-битные мантиссы вещественных данных позволяют работать с 7-8 десятичными знаками.
В системах программирования Borland C++ для объявления данных вещественного типа используют спецификаторы float (короткое вещественное, 4 байта), double (вещественное с удвоенной точностью, 8 байт ) и long double (длинное вещественное с удвоенной точностью, 10 байт ).
В машинном представлении вещественных данных разного типа на IBM PC не выдержана какая-то общая идеология. Объясняется это, по всей вероятности, разными наслоениями на прежние аппаратные решения, которые принимались при разработке процессоров в разных отделениях фирмы Intel. Поэтому здесь имеют место такие нюансы, как сохранение в оперативной памяти или не сохранение старшего бита мантиссы , представление мантиссы в виде чисто дробного ( 0.5 <= m < 1 ) или смешанного ( 1 <= m < 2 ) числа и т.п. Прикладных программистов эти детали мало интересуют, однако при создании специальных системных компонент с точным представлением данных приходится считаться.
3.3. Внешнее представление числовых констант
В программах на языках C, C++ встречаются литеральные и именованные числовые константы целого или вещественного типа. Числовые константы , употребляемые в тексте программ в арифметических или логических выражениях, называют литеральными. Они представлены числовыми литерами - цифрами, знаками + или -, точками, отделяющими целую часть числа от дробной, показателями десятичного порядка. Например:
В отличие от литеральных констант программисты часто прибегают к константам, которые подобно переменным имеют индивидуальные имена:
Удобство именованных констант заключается в минимальных переделках программы, связанных с изменением размерности массивов и точности других управляющих констант. Достаточно изменить одну строку программы с объявлением той или иной константы и не менять другие операторы , использующие эту константу.
Под внешним представлением числовой информации мы подразумеваем способы записи данных, используемые в текстах программ, при наборе чисел, вводимых в ЭВМ по запросу программы, при отображении результатов на экране дисплея или на принтере.
Наличие в естественной записи числа точки ( 3.1415 ) или указателя десятичного порядка ( 314.159265e-02, 314.159265E-02 ) означает, что соответствующее значение представлено в ЭВМ в виде вещественного числа с плавающей запятой.
Кроме естественного представления числовых констант в виде целого или вещественного числа языки программирования допускают различные добавки в начале (" префиксы ") или конце (" суффиксы ") числа, определяющие способы преобразования и хранения данных в памяти компьютера.
В алгоритмическом языке C активно используются как префиксы, так и суффиксы:
- 0x5,0X5 - шестнадцатеричное целое число (префикс - 0x или 0X );
- 05 - восьмеричное целое число (префикс - незначащий нуль в начале);
- 5H,5h - короткое целое число (суффикс - h или H от sHort )
- 5U,5u - целое число без знака (суффикс - u или U , от Unsigned );
- 5HU,5hu,5Hu,5hU - короткое целое число без знака;
- 5L,5l - длинное целое число (суффикс - l или L , от Long );
- 5LU,5lu,5Lu,5lU - длинное целое число без знака;
- 5f,5F - короткое вещественное число (суффикс - f или F , от Float );
- 5LF,5FL,5fl,5lf,5Lf,5lF,5Fl,5fL - длинное вещественное число.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств хранения и доставки данных.
В структуре возможных операций с данными можно выделить следующие основные:
· сбор данных – накопление данных с целью обеспечения достаточной полноты информации для принятия решений;
· формализация данных – приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
· фильтрация данных – отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
· сортировка данных – упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
· группировка данных – объединение данных по заданному признаку с целью повышения удобства использования; повышает доступность информации;
· архивация данных – организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат на хранение данных и повышает общую надежность информационного процесса в целом;
· защита данных – комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
· транспортировка данных – прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя – клиентом;
· преобразование данных – перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства – телефонные модемы.
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Читайте также: