Настройки конфигурации ноутбука со значением svg для более четкого отображения графиков
Читайте, как управлять производительностью графики с помощью стандартных инструментов Windows 10 . Как установить производительность графики отдельно для каждого приложения.
Средние и высокопроизводительные персональные компьютеры обычно имеют специальный графический процессор «GPU» . Специальный графический процессор используется вашей системой для запуска приложений, требующих интенсивных ресурсов (например, современные виды игр), которые не может обработать обычная видеокарта. Графический процессор обычно представляет собой чип «NVIDIA» или «AMD» , и оба имеют собственную специализированную панель управления.
Панель Windows 10 “Настройки производительности графики”
Панели управления позволяют пользователям принудительно использовать графический процессор для обработки приложения. Когда запущенное приложение вынуждено использовать графический процессор, это означает, что ваш компьютер работает в режиме высокой производительности. Как правило, ваша операционная система сама решает, какое приложение должно использовать выделенный графический процессор, но вы можете, конечно, и самостоятельно выбрать его. «Windows 10» добавляет новую панель, которая позволяет вам устанавливать производительность графики для каждого конкретного приложения.
Эта новая функция доступна только в «Windows 10» с установленным обновлением «Insider Build 17093» . Она не позволяет выбирать между встроенной графической видеокартой и графическим процессором. Вместо этого она позволяет устанавливать параметры производительности по умолчанию для каждого из приложений. Приложение можно настроить так, чтобы оно всегда работало в режиме энергосбережения или в режиме высокой производительности. Некоторые приложения могут не использовать выделенный графический процессор, и в этом случае, вы ничего не сможете с этим поделать. Вы можете попытаться принудительно заставить приложение использовать выделенный графический процессор с панели управления вашего «GPU» , но он может и не заработать. В соответствии с обновлениями «Microsoft» эта новая панель настроек заменяет такую функцию на панели управления вашего «GPU» . Вы можете использовать ее или воспользоваться панелью управления для вашей видеокарты.
Производительность графики для каждого приложения
Откройте приложение «Параметры Windows» , нажав в нижней части экрана кнопку «Пуск» и выбрав в левом боковом меню кнопку с изображением шестеренки.
Python for Data Science
Education
Python для Data Science
Учебные задания на портале GeekBrains.
Lesson 02. Pandas. NumPy
Практическое задание NumPy
- Импортируйте библиотеку Numpy и дайте ей псевдоним np. Создать одномерный массив Numpy под названием a из 12 последовательных целых чисел чисел от 12 до 24 невключительно Создать 5 двумерных массивов разной формы из массива a. Не использовать в аргументах метода reshape число -1. Создать 5 двумерных массивов разной формы из массива a. Использовать в аргументах метода reshape число -1 (в трех примерах - для обозначения числа столбцов, в двух - для строк). Можно ли массив Numpy, состоящий из одного столбца и 12 строк, назвать одномерным?
- Создать массив из 3 строк и 4 столбцов, состоящий из случайных чисел с плавающей запятой из нормального распределения со средним, равным 0 и среднеквадратичным отклонением, равным 1.0. Получить из этого массива одномерный массив с таким же атрибутом size, как и исходный массив.
- Создать массив a, состоящий из целых чисел, убывающих от 20 до 0 невключительно с интервалом 2. Создать массив b, состоящий из 1 строки и 10 столбцов: целых чисел, убывающих от 20 до 1 невключительно с интервалом 2. В чем разница между массивами a и b?
- Вертикально соединить массивы a и b. a - двумерный массив из нулей, число строк которого больше 1 и на 1 меньше, чем число строк двумерного массива b, состоящего из единиц. Итоговый массив v должен иметь атрибут size, равный 10.
- Создать одномерный массив а, состоящий из последовательности целых чисел от 0 до 12. Поменять форму этого массива, чтобы получилась матрица A (двумерный массив Numpy), состоящая из 4 строк и 3 столбцов. Получить матрицу At путем транспонирования матрицы A. Получить матрицу B, умножив матрицу A на матрицу At с помощью матричного умножения. Какой размер имеет матрица B? Получится ли вычислить обратную матрицу для матрицы B и почему?
- Инициализируйте генератор случайных числе с помощью объекта seed, равного 42. Создайте одномерный массив c, составленный из последовательности 16-ти случайных равномерно распределенных целых чисел от 0 до 16 невключительно. Поменяйте его форму так, чтобы получилась квадратная матрица C. Получите матрицу D, поэлементно прибавив матрицу B из предыдущего вопроса к матрице C, умноженной на 10. Вычислите определитель, ранг и обратную матрицу D_inv для D.
- Приравняйте к нулю отрицательные числа в матрице D_inv, а положительные - к единице. Убедитесь, что в матрице D_inv остались только нули и единицы. С помощью функции numpy.where, используя матрицу D_inv в качестве маски, а матрицы B и C - в качестве источников данных, получите матрицу E размером 4x4. Элементы матрицы E, для которых соответствующий элемент матрицы D_inv равен 1, должны быть равны соответствующему элементу матрицы B, а элементы матрицы E, для которых соответствующий элемент матрицы D_inv равен 0, должны быть равны соответствующему элементу матрицы C.
Создайте массив Numpy под названием a размером 5x2, то есть состоящий из 5 строк и 2 столбцов. Первый столбец должен содержать числа 1, 2, 3, 3, 1, а второй - числа 6, 8, 11, 10, 7. Будем считать, что каждый столбец - это признак, а строка - наблюдение. Затем найдите среднее значение по каждому признаку, используя метод mean массива Numpy. Результат запишите в массив mean_a, в нем должно быть 2 элемента.
Вычислите массив a_centered, отняв от значений массива а средние значения соответствующих признаков, содержащиеся в массиве mean_a. Вычисление должно производиться в одно действие. Получившийся массив должен иметь размер 5x2.
Найдите скалярное произведение столбцов массива a_centered. В результате должна получиться величина a_centered_sp. Затем поделите a_centered_sp на N-1, где N - число наблюдений.
Число, которое мы получили в конце задания 3 является ковариацией двух признаков, содержащихся в массиве а. В задании 4 мы делили сумму произведений центрированных признаков на N-1, а не на N, поэтому полученная нами величина является несмещенной оценкой ковариации. В этом задании проверьте получившееся число, вычислив ковариацию еще одним способом - с помощью функции np.cov. В качестве аргумента m функция np.cov должна принимать транспонированный массив a. В получившейся ковариационной матрице (массив Numpy размером 2x2) искомое значение ковариации будет равно элементу в строке с индексом 0 и столбце с индексом 1.
Подробнее узнать о ковариации можно здесь: Ссылка
Практическое задание тема NumPy
A. Импортируйте библиотеку Pandas и дайте ей псевдоним pd.
B. Создайте датафрейм authors со столбцами author_id и author_name, в которых соответственно содержатся данные: [1, 2, 3] и ['Тургенев', 'Чехов', 'Островский'].
C. Затем создайте датафрейм book cо столбцами author_id, book_title и price,в которых соответственно содержатся данные: [1, 1, 1, 2, 2, 3, 3], ['Отцы и дети', 'Рудин', 'Дворянское гнездо', 'Толстый и тонкий', 'Дама с собачкой', 'Гроза', 'Таланты и поклонники'], [450, 300, 350, 500, 450, 370, 290].
Получите датафрейм authors_price, соединив датафреймы authors и books по полю author_id.
Создайте датафрейм top5, в котором содержатся строки из authors_price с пятью самыми дорогими книгами.
A. Создайте датафрейм authors_stat на основе информации из authors_price.
B. В датафрейме authors_stat должны быть четыре столбца: author_name, min_price, max_price и mean_price, в которых должны содержаться соответственно имя автора, минимальная, максимальная и средняя цена на книги этого автора.
Создайте новый столбец в датафрейме authors_price под названием cover, в нем будут располагаться данные о том, какая обложка у данной книги - твердая или мягкая. В этот столбец поместите данные из следующего списка: ['твердая', 'мягкая', 'мягкая', 'твердая', 'твердая', 'мягкая', 'мягкая']. Просмотрите документацию по функции pd.pivot_table с помощью вопросительного знака. Для каждого автора посчитайте суммарную стоимость книг в твердой и мягкой обложке.Используйте для этого функцию pd.pivot_table. При этом столбцы должны называться "твердая" и "мягкая",а индексами должны быть фамилии авторов. Пропущенные значения стоимостей заполните нулями,при необходимости загрузите библиотеку Numpy. Назовите полученный датасет book_info и сохраните его в формат pickle под названием "book_info.pkl".Затем загрузите из этого файла датафрейм и назовите его book_info2.Удостоверьтесь, что датафреймы book_info и book_info2 идентичны
Lesson 04. Визуализация данных в Matplotlib.
Загрузите модуль pyplot библиотеки matplotlib с псевдонимом plt, а также библиотеку numpy с псевдонимом np.
Примените магическую функцию %matplotlib inline для отображения графиков в Jupyter Notebook и настройки конфигурации ноутбука со значением 'svg' для более четкого отображения графиков.
Создайте список под названием x с числами 1, 2, 3, 4, 5, 6, 7 и список y с числами 3.5, 3.8, 4.2, 4.5, 5, 5.5, 7.
С помощью функции plot постройте график, соединяющий линиями точки с горизонтальными координатами из списка x и вертикальными - из списка y.
Затем в следующей ячейке постройте диаграмму рассеяния (другие названия - диаграмма разброса, scatter plot).
С помощью функции linspace из библиотеки Numpy создайте массив t из 51 числа от 0 до 10 включительно.
Создайте массив Numpy под названием f, содержащий косинусы элементов массива t.
Постройте линейную диаграмму, используя массив t для координат по горизонтали, а массив f - для координат по вертикали. Линия графика должна быть зеленого цвета.
Выведите название диаграммы - 'График f(t)'.
Также добавьте названия для горизонтальной оси - 'Значения t' и для вертикальной - 'Значения f'.
Ограничьте график по оси x значениями 0.5 и 9.5, а по оси y - значениями -2.5 и 2.5.
С помощью функции linspace библиотеки Numpy создайте массив x из 51 числа от -3 до 3 включительно.
Создайте массивы $y_1$, $y_2$, $y_3$, $y_4$ по следующим формулам:
$$y_1 = x^2$$
$$y_2 = 2 * x + 0.5$$
$$y_3 = -3 * x - 1.5$$
$$y_4 = \sin(x)$$
Используя функцию subplots модуля matplotlib.pyplot, создайте объект matplotlib.figure.Figure с названием fig и массив объектов Axes под названием ax, причем так, чтобы у вас было 4 отдельных графика в сетке, состоящей из двух строк и двух столбцов. В каждом графике массив x используется для координат по горизонтали.
В левом верхнем графике для координат по вертикали используйте $y_1$, в правом верхнем - $y_2$, в левом нижнем - $y_3$, в правом нижнем - $y_4$.
Дайте название графикам: 'График $y_1$', 'График $y_2$' и т.д.
Для графика в левом верхнем углу установите границы по оси x от -5 до 5.
Установите размеры фигуры 8 дюймов по горизонтали и 6 дюймов по вертикали.
Вертикальные и горизонтальные зазоры между графиками должны составлять 0.3.
В этом задании мы будем работать с датасетом, в котором приведены данные по мошенничеству с кредитными данными: Credit Card Fraud Detection (информация об авторах: Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015). Данный датасет является примером несбалансированных данных, так как мошеннические операции с картами встречаются реже обычных. Импортруйте библиотеку Pandas, а также используйте для графиков стиль “fivethirtyeight”. Посчитайте с помощью метода value_counts количество наблюдений для каждого значения целевой переменной Class и примените к полученным данным метод plot, чтобы построить столбчатую диаграмму. Затем постройте такую же диаграмму, используя логарифмический масштаб. На следующем графике постройте две гистограммы по значениям признака V1 - одну для мошеннических транзакций (Class равен 1) и другую - для обычных (Class равен 0). Подберите значение аргумента density так, чтобы по вертикали графика было расположено не число наблюдений, а плотность распределения. Число бинов должно равняться 20 для обеих гистограмм, а коэффициент alpha сделайте равным 0.5, чтобы гистограммы были полупрозрачными и не загораживали друг друга. Создайте легенду с двумя значениями: “Class 0” и “Class 1”. Гистограмма обычных транзакций должна быть серого цвета, а мошеннических - красного. Горизонтальной оси дайте название “Class”.
Lesson 06. Обучение с учителем в Scikit-learn
Импортируйте библиотеки pandas и numpy.
Загрузите "Boston House Prices dataset" из встроенных наборов данных библиотеки sklearn. Создайте датафреймы X и y из этих данных.
Разбейте эти датафреймы на тренировочные (X_train, y_train) и тестовые (X_test, y_test) с помощью функции train_test_split так, чтобы размер тестовой выборки составлял 30% от всех данных, при этом аргумент random_state должен быть равен 42.
Создайте модель линейной регрессии под названием lr с помощью класса LinearRegression из модуля sklearn.linear_model.
Обучите модель на тренировочных данных (используйте все признаки) и сделайте предсказание на тестовых.
Вычислите R2 полученных предказаний с помощью r2_score из модуля sklearn.metrics.
Создайте модель под названием model с помощью RandomForestRegressor из модуля sklearn.ensemble.
Сделайте агрумент n_estimators равным 1000, max_depth должен быть равен 12 и random_state сделайте равным 42.
Обучите модель на тренировочных данных аналогично тому, как вы обучали модель LinearRegression, но при этом в метод fit вместо датафрейма y_train поставьте y_train.values[:, 0], чтобы получить из датафрейма одномерный массив Numpy, так как для класса RandomForestRegressor в данном методе для аргумента y предпочтительно применение массивов вместо датафрейма.
Сделайте предсказание на тестовых данных и посчитайте R2. Сравните с результатом из предыдущего задания.
Напишите в комментариях к коду, какая модель в данном случае работает лучше.
Вызовите документацию для класса RandomForestRegressor, найдите информацию об атрибуте feature_importances_.
С помощью этого атрибута найдите сумму всех показателей важности, установите, какие два признака показывают наибольшую важность.
В этом задании мы будем работать с датасетом, с которым мы уже знакомы по домашнему заданию по библиотеке Matplotlib, это датасет Credit Card Fraud Detection.
Для этого датасета мы будем решать задачу классификации - будем определять, какие из транзакциции по кредитной карте являются мошенническими.
Данный датасет сильно несбалансирован (так как случаи мошенничества относительно редки), так что применение метрики accuracy не принесет пользы и не поможет выбрать лучшую модель.
Мы будем вычислять AUC, то есть площадь под кривой ROC.
Импортируйте из соответствующих модулей RandomForestClassifier, GridSearchCV и train_test_split.
Загрузите датасет creditcard.csv и создайте датафрейм df.
С помощью метода value_counts с аргументом normalize=True убедитесь в том, что выборка несбалансирована.
Используя метод info, проверьте, все ли столбцы содержат числовые данные и нет ли в них пропусков.
Примените следующую настройку, чтобы можно было просматривать все столбцы датафрейма:
- pd.options.display.max_columns = 100.
- Просмотрите первые 10 строк датафрейма df.
- Создайте датафрейм X из датафрейма df, исключив столбец Class.
- Создайте объект Series под названием y из столбца Class.
- Разбейте X и y на тренировочный и тестовый наборы данных при помощи функции train_test_split, используя аргументы: test_size=0.3, random_state=100, stratify=y.
- У вас должны получиться объекты X_train, X_test, y_train и y_test.
- Просмотрите информацию о их форме.
Для поиска по сетке параметров задайте такие параметры:
parameters = [ 'max_features': np.arange(3, 5),
'max_depth': np.arange(4, 7)>]
Создайте модель GridSearchCV со следующими аргументами:
estimator=RandomForestClassifier(random_state=100),
param_grid=parameters,
scoring='roc_auc',
cv=3.
Обучите модель на тренировочном наборе данных (может занять несколько минут).
Просмотрите параметры лучшей модели с помощью атрибута best_params_.
Предскажите вероятности классов с помощью полученнной модели и метода predict_proba.
Из полученного результата (массив Numpy) выберите столбец с индексом 1 (вероятность класса 1) и запишите в массив y_pred_proba.
Из модуля sklearn.metrics импортируйте метрику roc_auc_score.
Вычислите AUC на тестовых данных и сравните с результатом,полученным на тренировочных данных, используя в качестве аргументов массивы y_test и y_pred_proba.
- Загрузите датасет Wine из встроенных датасетов sklearn.datasets с помощью функции load_wine в переменную data.
- Полученный датасет не является датафреймом. Это структура данных, имеющая ключи аналогично словарю. Просмотрите тип данных этой структуры данных и создайте список data_keys, содержащий ее ключи.
- Просмотрите данные, описание и названия признаков в датасете. Описание нужно вывести в виде привычного, аккуратно оформленного текста, без обозначений переноса строки, но с самими переносами и т.д.
- Сколько классов содержит целевая переменная датасета? Выведите названия классов.
- На основе данных датасета (они содержатся в двумерном массиве Numpy) и названий признаков создайте датафрейм под названием X.
- Выясните размер датафрейма X и установите, имеются ли в нем пропущенные значения.
- Добавьте в датафрейм поле с классами вин в виде чисел, имеющих тип данных numpy.int64. Название поля - 'target'.
- Постройте матрицу корреляций для всех полей X. Дайте полученному датафрейму название X_corr.
- Создайте список high_corr из признаков, корреляция которых с полем target по абсолютному значению превышает 0.5 (причем, само поле target не должно входить в этот список).
- Удалите из датафрейма X поле с целевой переменной. Для всех признаков, названия которых содержатся в списке high_corr, вычислите квадрат их значений и добавьте в датафрейм X соответствующие поля с суффиксом '_2', добавленного к первоначальному названию признака. Итоговый датафрейм должен содержать все поля, которые, были в нем изначально, а также поля с признаками из списка high_corr, возведенными в квадрат. Выведите описание полей датафрейма X с помощью метода describe.
Lesson 08. Обучение без учителя в Scikit-learn.
Импортируйте библиотеки pandas, numpy и matplotlib. Загрузите "Boston House Prices dataset" из встроенных наборов данных библиотеки sklearn. Создайте датафреймы X и y из этих данных. Разбейте эти датафреймы на тренировочные (X_train, y_train) и тестовые (X_test, y_test) с помощью функции train_test_split так, чтобы размер тестовой выборки составлял 20% от всех данных, при этом аргумент random_state должен быть равен 42. Масштабируйте данные с помощью StandardScaler. Постройте модель TSNE на тренировочный данных с параметрами: n_components=2, learning_rate=250, random_state=42. Постройте диаграмму рассеяния на этих данных.
С помощью KMeans разбейте данные из тренировочного набора на 3 кластера, используйте все признаки из датафрейма X_train. Параметр max_iter должен быть равен 100, random_state сделайте равным 42. Постройте еще раз диаграмму рассеяния на данных, полученных с помощью TSNE, и раскрасьте точки из разных кластеров разными цветами. Вычислите средние значения price и CRIM в разных кластерах.
Примените модель KMeans, построенную в предыдущем задании, к данным из тестового набора. Вычислите средние значения price и CRIM в разных кластерах на тестовых данных.
Курсовой проект для курса "Python для Data Science"
Материалы к проекту (файлы): train.csv test.csv
Задание: Используя данные из train.csv, построить модель для предсказания цен на недвижимость (квартиры). С помощью полученной модели предсказать цены для квартир из файла test.csv.
Целевая переменная: Price
Основная метрика: R2 - коэффициент детерминации (sklearn.metrics.r2_score)
Вспомогательная метрика: MSE - средняя квадратичная ошибка (sklearn.metrics.mean_squared_error)
- Прислать в раздел Задания Урока 12 ("Вебинар. Консультация по итоговому проекту") ссылку на программу в github (программа должна содержаться в файле Jupyter Notebook с расширением ipynb).
- Приложить файл с названием по образцу SShirkin_predictions.csv с предсказанными ценами для квартир из test.csv (файл должен содержать два поля: Id, Price).
Сроки сдачи: Сдать проект за 72 часа до начала Урока 13 ("Вебинар. Результаты итоговых проектов и закрытие курса").
Примечание: Все файлы csv должны содержать названия полей (header - то есть "шапку"), разделитель - запятая. В файлах не должны содержаться индексы из датафрейма.
Второй сюрприз: не будет, пока мы не установим плагин — например, Adobe SVG Viewer. Правда, Adobe, вроде бы, прекратила его поддержку с 1 января 2009 г., но уже сделанного пока что должно хватить, да и, в конце концов, есть ещё RENESIS Player 1.0 for Internet Explorer и Ssrc SVG Plugin. Кроме того, как ни разобижена Microsoft за свой VML , с коим W3C её кинул в 1999 г., ввести нативную поддержку SVG её уламывают такие авторитеты как Google и Wikimedia Foundation. Обнадёживающая новость, что «Microsoft подала заявку на вступление в рабочую группу развития формата SVG в организации W3C» на Хабре уже обсуждалась. Так что тут есть все основания для оптимизма.
Далее. В описаниях тега embed во множестве мест в Интернете можно прочитать, что у него есть такой замечательный атрибут pluginspage , указывающий адрес, по коему, якобы, «будет направлен пользователь в том случае, если его браузер не поддерживает SVG -графику».
Не верьте! Это — третий сюрприз: в реальности IE игнорирует сей атрибут.
А чтобы заставить его работать, существует весьма малоизвестный (судя по тотальному отсутствию ссылок в тематических материалах в Интернете) хитрый способ с применением скриптов на JScript и VBScript . В принципе, ничего страшного, но об этом нужно знать.
Решение это, однако же, не вполне хорошо. Во-первых, оно не валидно, во-вторых, рассчитано на какие-то допотопные браузеры, коими уже никто не пользуется, но, в-третьих, не работает с современными браузерами (строго говоря, оно вообще не работает в том виде, в каком дано). Однако, основная идея решения верна, поэтому попытаемся сделать его работоспособным и современным.
Для начала, есть проблема вот с этой строчкой:
Функция в ней не выполняется, если только мы не перенесём её вызов на новую строчку. Только в XHTML экранирование будет выполняться ещё сложнее, посему вынесем-ка мы вызов функции во внешний скрипт:
Тогда все три подключенных скрипта можно скрыть от прочих браузеров в условный комментарий (ну и насчёт языка перестаём притворяться, что это — JavaScript):
В сумме получается довольно громоздкая конструкция, да ещё смешивающая представление с поведением. На самом деле можно просто написать:
Можно писать просто:
Впрочем, если кому-то вышеописанный вариант дорог, как память, можно и так:
В заголовочной части страницы, как уже указано, пишем:
Файл fixSVG.js выглядит так (с использованием уже скриптового условного комментария):
Содержимое fixSVG_IE_5-8.html , подгружающееся в динамически созданный плавающий фрейм:
Скрипты svgcheck.js и svgcheck.vbs — адоубивские, нетронутые. А fixSVG_IE_5-8.js — наш:
Вторая проблема серьёзней: если у вставленной через object SVG-картинки прозрачный фон, он заливается белым (это баг! причём очень старый, более чем двухлетней давности — и в 5-х версиях этих браузеров он не исправлен), как и в IE (но там мы можем просто добавить embed -элементу атрибут wmode со значением transparent ).
Увы, но на вставленных таким образом картинках перестают работать скрипты, так что решение не универсально!
Проблемы возникают в Internet Explorer. В нём мы можем после загрузки страницы получить элемент embed и у него даже уже доступен SVG -документ, но только — вот беда! — он совершенно пуст. Навесить на элемент embed событие load мне не удалось; похоже, оно вообще не поддерживается (впрочем, те из якобы поддерживаемых событий, что я пробовал, тоже не работают).
Кроме того, выяснилась ещё одна подлянка: содержимое таких элементов, как object и embed загружается асинхронно, в отдельном потоке. Это означает, как я понимаю, что, с одной стороны, пока не закончен парсинг основной страницы, элемент ещё недоступен для навешивания на него обработчика события, а когда он закончен — событие загрузки элемента может уже сработать и тогда обработчик навешивать уже бесполезно. Кажется, именно последний случай я периодически наблюдал в экспериментах, не улавливая никакой закономерности в глюке.
Да и по спецификации, кстати, событие load у элемента object отсутствует — оно есть в HTML только у элемента body . Так что то, что оно вообще где-то работает — это неправильно!
Выход найден следующий (не очень элегантный, но… будем ещё думать!): событие load пишем внутри SVG -кода у элемента svg , вызывая оттуда функцию HTML -документа. Как-нибудь так:
Ну, или, чтобы, уж, единообразно работало во всех браузерах:
Или даже просто (поскольку parent в окне верхнего уровня указывает на само это окно):
Забавно, что этот способ перестал работать локально в Chrome 5.0 из-за каких-то его заморочек с безопасностью. Совсем не забавно, что, как уже указано, в Webkit-браузерах он вообще не работает, если мы используем тег img .
Как отдавать с сервера SVGZ
Заархивировали, сменив расширение с образующегося автоматически .svg.gz на .svgz , после чего с изумлением убеждаемся, что получившийся файл адекватно воспринимают только Opera и Internet Explorer, а Firefox, Safari и Chrome воротят нос, ругаясь на синтаксис XML . Ну, конечно, какой там XML , пока не разархивируешь? А почему, собственно, они не разархивируют?
Встречался мне ещё совет дописывать туда же (ради Firefox) следующее:
Возможно, это имеет смысл, если на сервере настроено автоматическое gzip -ование отдаваемых файлов; не знаю.
Недавно я имел по этому вопросу смешные бодания с техподдержкой своего хостера, кои продолжались месяц. Я так понял, что перед Apache там стоит фронт-ендом nginx, что неким образом ограничивает возможность использования директив Apache. Конкретнее, директива AddType срабатывает, а AddEncoding — нет. Разумеется, раздел «Помощь» на сайте провайдера не содержит про эту закавыку ни слова и даже вообще ни единого упоминания про nginx. Техподдержка упорно не хотела мне внимать и выдавать свои тайны, потчуя меня безумными отписками: «Заголовок не отдается, поскольку на сервере не установлен необходимый для
работы директивы AddEncoding модуль Apache Mod_gzip», «За сжатие отвечает nginx, остальные директивы Apache поддерживаются в полном объёме» (неправда, кстати), «Приносим извинения. Передавать формат svgz можно лишь при наличии модуля mod_deflate, который, к сожалению, отсутствует на серверах, используемой Вами услуги» (и тут же предложение купить впятеро более дорогой план!). В конце концов, мне так и не объяснили, в чём у них закавыка, но сдались и стали отдавать правильный заголовок сами.
По умолчанию контроль над производительностью графики выполняет сама операционная система Windows 11, но администраторы устройств могут изменять стандартное значение, чтобы повысить быстродействие или сэкономить энергию.
Основная идея новой функции настройки графики — динамическая регулировка производительности графики в зависимости от текущего плана электропитания. Данная функциональность позволяет продлить автономную работу ноутбуков, планшетов и портативных устройств под управлением Windows 11.
Пользователи Windows 11 могут использовать новые возможности для назначения конфигурации питания определенной программе. Таким способом можно на постоянной основе повысить производительность компьютерной игры или снизить производительность других приложений для экономии энергии.
Как настроить графические параметры для приложений в Windows 11
- Перейдите в приложение Параметры. Вы можете использовать для этого горячую клавишу Win + I или перейти в меню «Пуск» > Параметры.
- Перейдите в раздел Система > Дисплей.
- На открывшейся странице в секции Сопутствующие параметры выберите пункт Графика.

Windows 11 выводит список установленных приложений и дает возможность найти конкретную настольную программу или приложение Microsoft Store вместе с текущим значением.
- Если вы нашли нужную программу, кликните по ней, а затем нажмите кнопку Параметры.
- В окне настроек графики доступно три варианта:
- Разрешить Windows принимать решение (экономия энергии)
- Энергосбережение
- Высокая производительность
![]()
Для каждого значения производительности отдельно указывается графический процессор. Это полезная опция для устройств с интегрированной и дискретной видеокартами. Некоторые приложения или программы могут иметь ограничения по использованию графического адаптера.
Для применения изменений может понадобиться перезапуск приложения.
Если конкретного приложения нет в списке, используйте опцию Обзор, чтобы вручную добавить его на страницу. Остальные шаги после добавления программы будут идентичны.
Приложения, отображаемые в интерфейсе Графика по умолчанию, удалить нельзя, но если им был назначен специальный параметр, то вы можете сбросить значения. Если программа была добавлена вручную, то сброс выполнить нельзя, доступно только удаление.
Настройка графических параметров для отдельных приложений может быть полезна в некоторых ситуациях, например когда вы хотите, чтобы ресурсоемкие приложения или игры всегда работали в режиме высокой производительности, даже если это негативно сказывается на энергопотреблении. Или наоборот, вы хотите убедиться, что приложение постоянно работает в режиме энергосбережения, чтобы продлить работу портативного устройства от аккумулятора.
Очень заметного эффекта при переключении режимов не получите. Тем не менее, дополнительная оптимизация производительности или энергопотребления для определенных приложений будет не лишней.
На рынке доступно несколько сторонних приложений для оптимизации энергопотребления, например Easy Power Plan Switcher, Laptop Power Plan Assistant или PowerSchemeSwitcher.
От автора: оптимизация SVG (масштабируемой векторной графики) для веб-проектов имеет два преимущества: уменьшение размера файла и упрощение работы с ним. Но много раз я открывала веб-проект и обнаруживала, что ресурсы SVG можно сделать значительно меньше с помощью простых оптимизаций. В этой статье я расскажу о своем процессе оптимизации ресурсов SVG. Это может помочь вам, если вы дизайнер или разработчик, не знакомый с работой с SVG в Веб.
Многие библиотеки иконок предоставляют ресурсы SVG, которые уже хорошо оптимизированы. Но если вы создаете собственную графику или она предоставлена другим дизайнером, вы можете сделать это с помощью нескольких шагов. В основном я использую для создания и редактирования SVG Adobe Illustrator. Вот довольно простая иконка, созданная в Illustrator:
![Оптимизация SVG для Веб]()
![]()
JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
< ! -- Generator : Adobe Illustrator 22.1.0 , SVG Export Plug - In . SVG Version : 6.00 Build 0 ) -- >У каждой графической программы свой собственный способ сохранения SVG, но независимо от того, которую из них вы используете, код все равно может содержать много дополнительных данных, если их не оптимизировать. Давайте рассмотрим некоторые способы решения этой проблемы.
Запуск пакета
Быстрое решение с помощью SVGOMG
![Оптимизация SVG для Веб]()
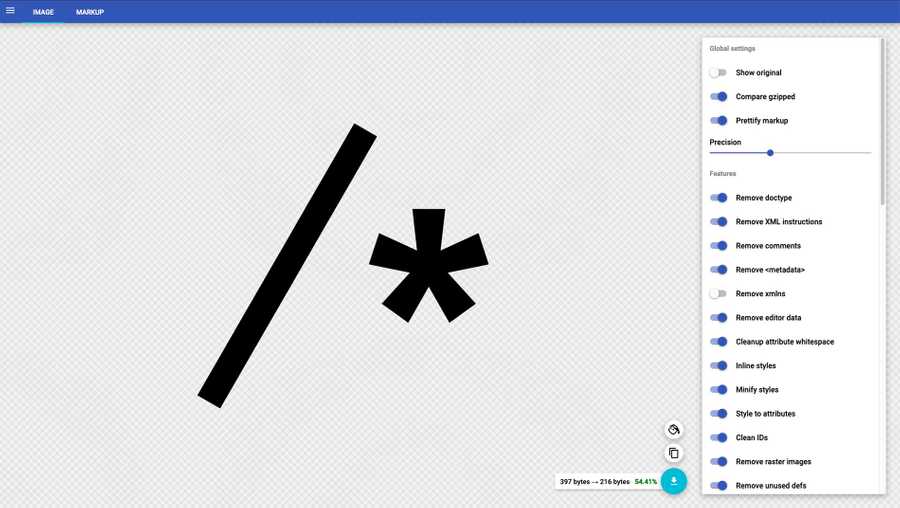
Пропустив код через SVGOMG, мы получим следующее:
Это гораздо лучше, чем оставлять графику неоптимизированной, но она содержит посторонний элемент <defs/>. И если оригинальный SVG содержит группы, слои и эффекты, то существует предел того, насколько инструмент, наподобие SVGOMG, сможет его оптимизировать. Намного лучше, если мы вернемся к графической программе и внесем некоторые изменения, прежде чем пропускать ее через инструмент оптимизации.
Редактирование SVG
Если вы знаете, как писать SVG-код, то это поможет получить самый чистый и минимизированный результат. Посмотрите документацию MDN с руководством по рисованию контуров SVG и это видео от Хейдона Пикеринга, если вы хотите получить дополнительную информацию.
Но для подавляющего большинства из нас редактирование SVG возможно только с помощью визуального инструмента. Для этого примера я использую Adobe Illustrator, но другие инструменты, такие как Sketch, имеют схожие функции редактирования.
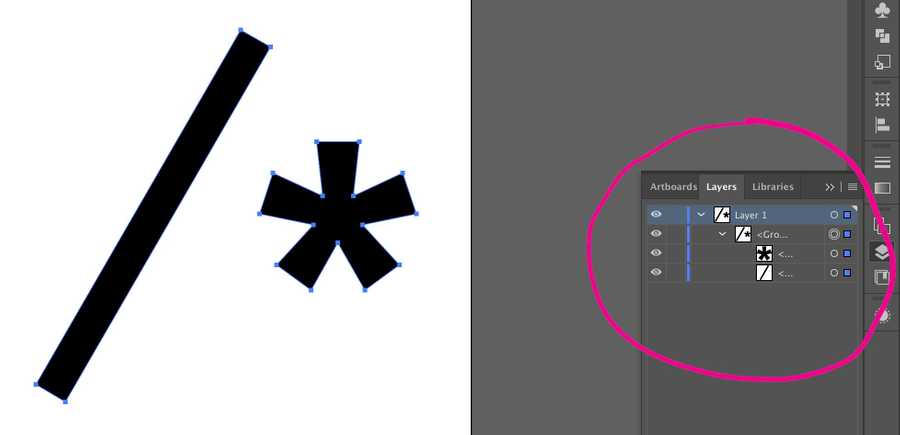
Разверните группы
Первое, что я делаю при оптимизации SVG, это удаляю все скрытые слои и разворачиваю группы, где это возможно. Это удаляет все группы контуров в тегах <g> кода SVG. Возможно, вы захотите сохранить некоторые группы, если планируете стилизовать или анимировать их. Вы можете развернуть группу в Illustrator с помощью сочетания клавиш Shift+CMD+G.
![Оптимизация SVG для Веб]()
Преобразование в контуры
Затем я конвертирую все штрихи в контуры, где это возможно (Рис 04). В Illustrator мы можем сделать это, используя Объект> Расширить. Могут быть некоторые исключения: если вы стилизуете или анимируете stroke-dasharray или stroke-dashoffset, вам нужно оставить их нетронутыми, а также, если вы хотите сохранить ширину обводки при масштабировании SVG.
![Оптимизация SVG для Веб]()
Вы также можете использовать параметр «Развернуть» в Illustrator для преобразования областей изображения, например простых рисунков, в индивидуально выбираемые контуры. Для сложных или детализированных узоров, возможно, лучше этого не делать.
Преобразование текста в контуры
Иногда полезно преобразовать текст в контуры, если текст носит чисто декоративный характер, или содержимое будет передаваться другим способом, например с заголовком, текстом кнопки или aria-label. Несмотря на то, что использовать элемент SVG <text> полезно, это не всегда имеет смысл, особенно если вам нужно загрузить другой веб-шрифт для отображения текста SVG. Мы можем преобразовать текст в контуры в Illustrator, выбрав его и нажав «Текст»> «Преобразовать в контуры».
Объединение контуров
![]()
JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
Чтобы объединить контуры в Illustrator, мы выбираем их и используем параметр объединения в меню «Навигатор».
![Оптимизация SVG для Веб]()
Удалите дополнительные контуры или группы
Когда контуры объединены, я выполняю последнюю проверку слоев и удаляю все пустые слои или дубликаты контуров, которые могли быть созданы в процессе.
Подгонка артборда
Когда я использую в HTML SVG-иконки, я не хочу, чтобы вокруг них оставалось дополнительное пространство, от которого я не могу избавиться. Это может произойти в случае, если SVG viewBox больше, чем содержимое. В Illustrator я выбираю «Объект»> «Артборды»> «Подогнать к границам графического объекта», чтобы размеры viewBox соответствовали графическому объекту.
![Оптимизация SVG для Веб]()
Экспорт
Теперь мы готовы сохранить SVG. В Illustrator мы можем выбрать «Файл»> «Сохранить как» и выбрать в качестве формата SVG. В появившемся окне нам будет предложено несколько параметров SVG. Я обычно выбираю «Атрибуты представления», чтобы настроить параметры стиля.
SVG теперь готов к запуску через инструмент оптимизации. Для иконок я обычно в SVGOMG могу настроить большинство параметров. Вы заметите, что код стал намного чище! Но даже это не всегда удаляет все, что можно удалить. В приведенном ниже коде у меня все еще остается пустой элемент <defs>, поэтому стоит выполнить еще одну окончательную ручную очистку и удалить его в редакторе кода. Теперь SVG готов к использованию!
Использование SVG
SVG можно использовать в Интернете различными способами, в том числе:
В свойстве CSS background-image
Встроенным в HTML
Спрайты
Затем, когда дело доходит до их использования, вместо вставки всего SVG, мы можем ссылаться на них с помощью элемента <use>:
Читайте также: